基于中风数据的不平衡样本最优化预测模型
2023-07-04韩朝怡连高社
韩朝怡,连高社
(太原工业学院理学系,山西太原 030008)
在医疗诊断、金融欺诈、信息安全、工业生产异常检测领域,存在着大量的不平衡数据,即分类样本中某一类的样本数量远小于另一类样本数量。面对不平衡数据,在应用中经常需要预测数据的分类问题,机器学习中的分类和预测算法是主要技术之一。然而传统的机器学习分类算法的假设是训练数据集中的各类样本数均衡,且错分代价均等。但是机器学习分类算法在训练不平衡数据时,更集中于训练多数类的样本,从而降低了少数类样本的精度,然而少数类样本比例错分的代价更高。因此,对现有的不平衡数据分类算法进行改进,以提高对少数类样本的分类精度是非常有必要的。
学者解决不平衡分类问题从以下方面展开,一是数据预处理层面,通过抽样技术平衡少数类与多数类样本,LIN W C et al[1]在欠采样的基础上融入了K 近邻规则,提出了基于聚类的欠采样算法;NG W W Υ et al[2]将欠采样方法与灵敏度测度结合,以保持原数据集的分布;Batista G et al[3]融合了SMOTE 与Tome Link 两种算法,以减弱传统的混合采样中存在的样本噪声;陶新民等[4]对多数类样本优化欠采样,然后将边界样本过采样,以消除样本噪声和重复信息,提高数据的有效性。二是改进分类算法,以提高对少数类样本的识别准确率,应用较为广泛的分类算法是集成学习方法Bagging、Boosting 等[5-7],通过集成多个基分类器,根据基分类器地分类结果按某种规则投票得到最终的分类结果。
然而,不平衡的样本分布也会造成数据集中某些特征分布的不平衡,增加少数类识别的误差,因此,在数据预处理层、分类算法层的基础上,增加了特征选择层,通过特征选择算法,找到影响分类的关键因素,去掉冗余因素,以期提高少数类的分类准确度和模型构建效率。
以中风数据集为例进行探究,利用传统的机器学习算法发现对于少数类样本的预测精度较低,误诊的代价很高,因此从数据层、特征层、算法层三个层面构建模型,以提高中风风险预测精度。
1 模型架构
模型架构如图1:中风数据集中,中风患者比例明显低于正常人比例,属于典型的不平衡数据集,为对就诊人进行中风患病风险预测,从数据层、特征层、算法层三个层面构建分类预测模型。
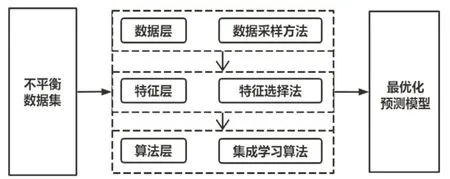
图1 模型架构图
1.1 数据层
在数据层面,由于中风数据属于不平衡数据,最常用的方法为通过采样技术平衡样本数据。目前主流的采样技术为混合采样技术,其中少数类样本合成技术(SMOTE)应用最为广泛,其原理为少数类样本周围找到K 个近邻样本,通过线性插值运算合成新样本。然而,SMOTE 采样容易产生新生成的少数类与多数类样本重叠难以区分的问题,因而衍生了基于SMTOTE的改进采样方法。
采样方法为少数类样本合成技术(SMOTE)与聚类算法(KNN)结合的SMOTEENN 采样方法。首先基于SMOTE 算法生成少数类样本,得到新生成样本,然后利用聚类算法(KNN)对新生成样本进行聚类,如在某点的分类结果与其K 近邻样本的聚类结果相同则保留,否则删除该新生成样本,直到得到的少数类数据样本与多数类样本达到平衡。
1.2 特征层
在特征层面,由于样本的不平衡会造成数据集中特征分布的不平衡,进而影响少数类识别的误差,此外,模型特征太多会影响模型构建和预测速度,因此,需通过特征选择算法,去掉冗余特征,找到关键特征。采用的特征选择算法为基于随机森林的递归特征消除方法(RFRFE),其基本思想是基于多棵随机数建模,使用袋外数据预测,然后随机置换特征的值进行重复建树,根据预测准确率的平均减少量对每个特征进行评分,在递归消除特征的过程中,置换重要性低的特征会被移除,便可找到影响分类的关键特征子集。
1.3 算法层
在算法层面,目前机器学习领域的主流建模方法是集成学习算法,其基本思想是通过组合多个弱分类器,形成强分类器,进而提高分类准确率,而集成算法的主流是Boosting 算法,采用Boosting 算法的分支CatBoost和XGBoost算法。
CatBoost 算法[8]是一种基于梯度提升的集成算法,特点在于,一是可以直接训练类别型特征,二是通过排序提升策略解决梯度提升树存在的梯度偏移和预测偏移,以减少过拟合,三是采用对称树为基学习器,使用参数少。XGBoost 算法采用Boosting 思想,通过串行方式产生子树,使用二阶泰勒方法逼近目标,以加权方法得到结果,准确率更高。
2 模型评价指标
通过数据层、特征层、算法层的训练,可分别得到Catboost和XGBoost的组合模型,需对两种分类模型进行性能评价,以找到最优化模型。目前,针对针对不平衡数据的分类模型的典型评价指标是,基于混淆矩阵计算的F 值(F-measure)、几何平均准则(Gmeans)和接收者操作特征曲线(ROC)。
在不平衡分类建模中,为便于混淆矩阵的表示,将关注度更高的少数类定义为正类,多数类定义为负类,混淆矩阵如表1:

表1 混淆矩阵
对于不平衡分类模型的评价指标包括几何平均值(Gmeans)、F值(F-measure)、操作者接收曲线(ROC值)。
2.1 几何平均值(G-means)
G-means 综合考虑了少数类和多数类样本的分类准确率,计算方法为:
2.2 F值(F-measure)
F值计算公式为:
2.3 接收者操作特征曲线(ROC)
ROC 曲线如图2,横坐标为假正率FPR=纵坐标为真正率ROC曲线越靠近左上角表明分类器效能越好,但是不同分类器ROC 曲线如何比较,就需要用到ROC 曲线下方面积(AUC值),AUC值越大表明分类器分类效果越好。
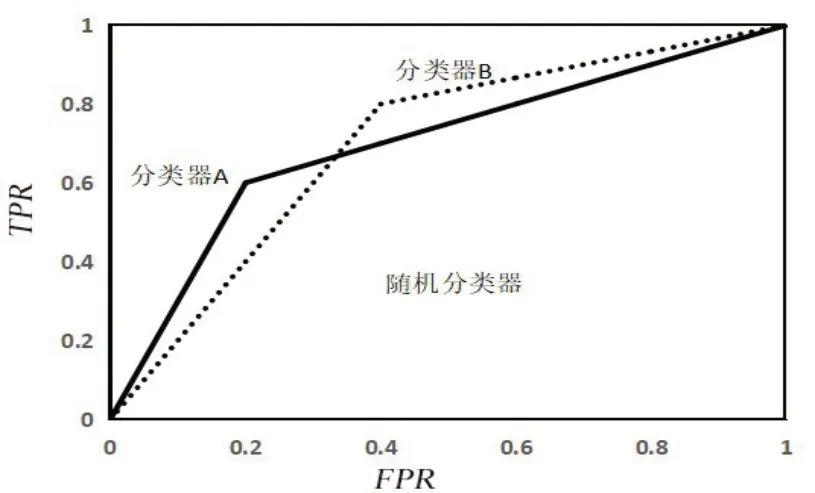
图2 ROC曲线示意图
3 数据来源
数据源来自公开数据集Kaggle 网站中的中风数据集,共有5110 条数据,特征信息如表2。其中有249 条中风患者,类别标签为1,剩余的4861 条为未中风患者,类别标签为0,可见该数据集为典型的类别不平衡数据集,这与现实也相符,中风事件相对于正常人群而言是“小概率事件”。数据整体质量较高,无异常值,存在201条缺失数据,删除缺失值后样本集共剩余4909条有效数据。

表2 中风数据集特征
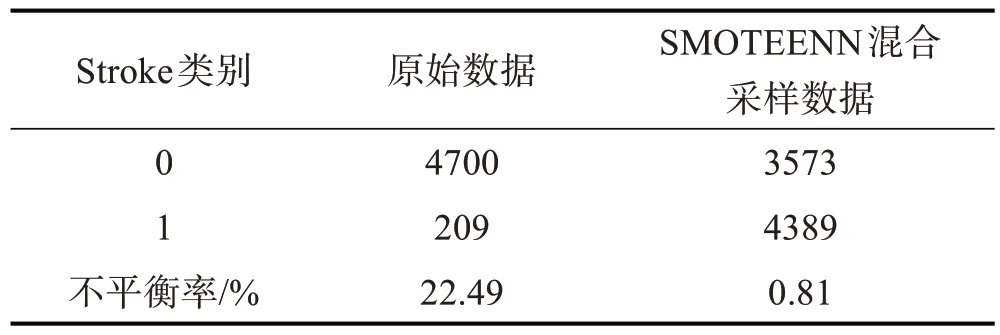
表3 SMOTEENN算法平衡数据集
4 模型构建
4.1 数据层
由于数据集中中风患者(Stroke类别为1)与非中风人群(Stroke类别为0)样本不平衡比例高达22.49,首先需在数据层利用混合采用技术,基于Ρython3.7软件,利用SMOTEENN 抽样技术,最终生成少数类样本——中风患者(Stroke 类别为1)的样本量4389个,将多数类样本——非中风(Stroke 类别为0)按照KNN聚类算法删减至3573个,比例为0.81,分类数据整体达到平衡。经过采样处理后得到的平衡数据集,再进行模型训练,可克服由于数据不平衡所造成的分类误差。
4.2 特征层
在特征层,为找到影响数据分类的关键特征,采用随机森林递归消除法(RFRFE)对特征的重要性进行排序,特征结果如表4。
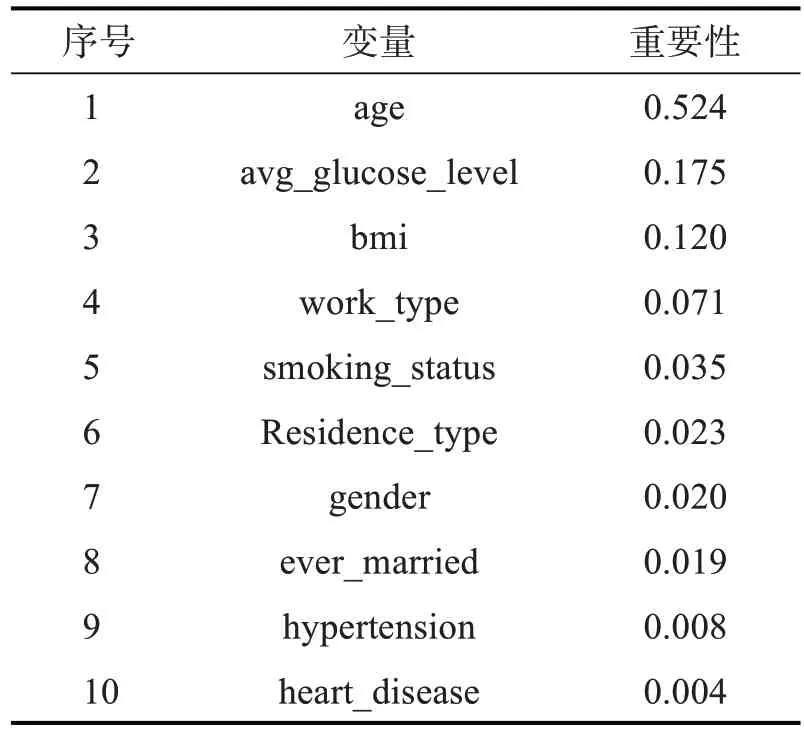
表4 随机森林递归特征消除法
在进行递归消除的过程中,置换重要性低的特征会被移除,因此,消除了是否患有高血压(hypertension)、是否患有心脏病(heart_disease)两个特征,其余8个特征进入分类算法的模型训练。
4.3 算法层
中风数据在经过数据层、特征层处理后,在算法层分别采用CatBoost、XGBoost两种算法进行模型训练,最终选择模型分类性能最优的分类算法进行推广应用。进一步,为了对比数据层、特征层的处理效果,将“中风原始数据”作为对照组,“只进行SMOTEENN 采样”、“SMOTEENN 采样后进行特征选择”作为实验组,分别训练CatBoost、XGBoost模型,通过模型性能评价指标,评估模型的预测能力和泛化能力,结果如表5和图3。
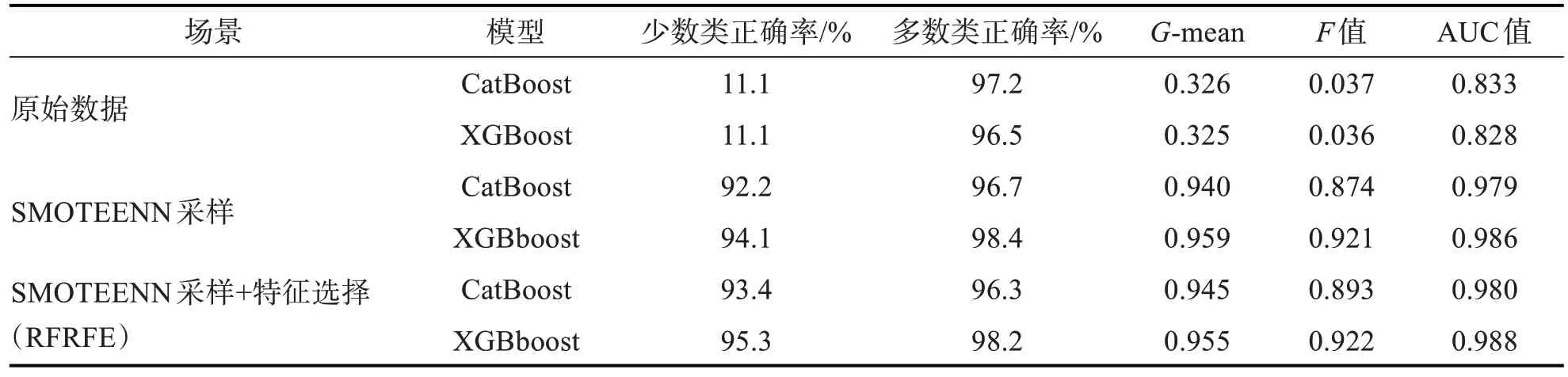
表5 分类算法模型性能评估表
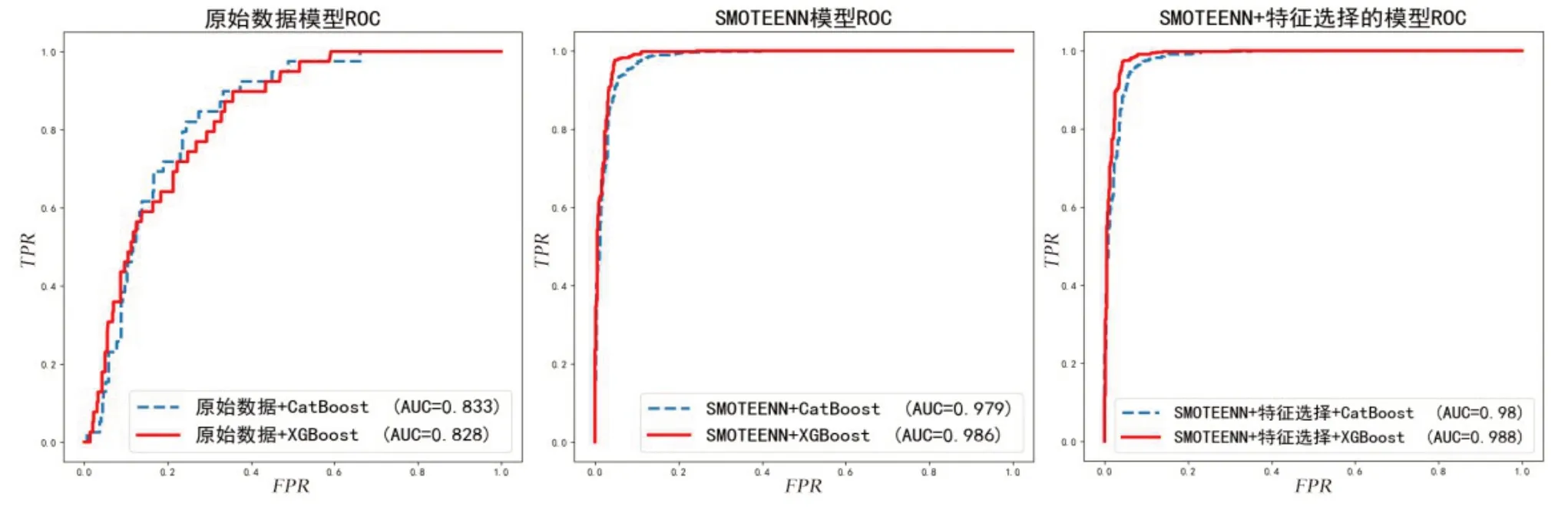
图3 各模型的ROC曲线图
从表5可知,原始数据构建的CatBoost、XGBoost分类模型在少数类(即患有中风)的分类正确率仅为0.11,F 值和G-mean 也很低。如果只在数据层SMOTEENN 采样,不经过特征层,CatBoost、XGBoost 分类模型的性能大幅提高。但在经过SMOTEENN 采样和特征选择后,少数类分类正确率G-mean、F 值、AUC 值又能有所提高。进一步比较分类算法发现,XGBoost 算法比CatBoost 算法的分类性能表现上更好。从图3 的ROC 曲线可以看到,“SMOTEENN 采样+特征选择(RFRFE)+XGBoost”模型的ROC 曲线明显更陡峭,AUC的值最大。
因此,最终选择“SMOTEENN 采样平衡数据+随机森林递归特征选择法(RFREE)+XGBoost 集成算法”模型作为中风风险的最优化预测模型。
4 结语
基于中风不平衡数据,从数据层、特征层、算法层构建最优化预测模型,首先,在数据层利用SMOTEENN 采样技术平衡样本;其次,在特征层,利用随机森林法递归特征消除法,找到影响分类的关键特征;最后,在算法层利用CatBoost、XGBoost分类集成算法训练模型,通过模型性能比较,最终得到了“SMOTEENN 采样+随机森林的特征递归消除法(RFREE)+XGBoost 分类算法”的最优化预测模型。该模型可根据就诊人的身体状况进行患病风险预估,为就诊人提供身体预警,同时也能为医生决策提供参考。类似地,可以将中风风险最优化预测模型,推广到疾病类不平衡数据集的风险预测中。
