基于深度学习的需求自动抽取研究
2023-06-27石玉敬赵亚蛟华传健
石玉敬,陈 超,邹 昆,赵亚蛟,华传健,何 沧
(凯德技术长沙股份有限公司,长沙 410003)
0 引言
需求分析工作是需求工程的研究以及其应用中的重中之重,同时体系需求工程的研究也是目前体系工程研究的关键,需求是系统或者体系为解决问题或完成目标所必须满足的条件或能力。文献[1]重点针对网络信息体系等重难点问题的研究思路进行了探讨,在体系需求工程关键技术上有一定的突破。文献[2]提出了装备体系需求论证的研究框架,能够在理论方法上为装备体系需求论证和顶层设计提供支撑。文献[3]利用UML(unified modeling language)对装备体系需求工程建模技术进行研究,结果表明该方法更适合进行需求描述。从上文可知,在需求分析之前的一个重要任务就是将一条条隐藏在非结构化文本中的需求条目全部抽取出来,如果忽略掉某些需求可能会导致整个项目的失败,因此需求的提取成功与否是需求分析乃至需求工程能够顺利进行下去的关键。
相较于软件开发中的其他语句,需求的描述通常分散甚至隐含在不同语句、段落、文档之中,同时某些非需求条目与软件需求十分相似,导致它们之间难以辩别,因此需求相对来说不易被提取。而面对海量的非结构化文本,通过人工提取的方法付出的人力、时间和经济的成本太大,并且可能会出现疏漏的地方。所以,将需求抽取的工作进行一定程度的自动化,即在需求分析软件中添加一个对需求条目进行识别和分类的功能,对需求分析过程的效率和质量能够有巨大的提升。同时目前对于需求抽取的研究成果较少,因此本研究将基于深度学习模型探究更有效的需求抽取方法并解决工业界实际案例需求。
1 相关研究
1.1 研究背景
由于需求分析的重要性,自动化的需求文本分析工具一直是需求工程领域的研究热点。而目前的主流研究方法是将需求提取当成文本分类任务,主要的需求分类方法有三种:基于规则和词性的分类方法[4]、基于传统机器学习的分类方法[5]和基于深度学习的分类方法[6]。基于规则和词性的分类方法除了要求对语言学参与规则制定之外,同时还需要领域内专家进行辅助,不仅需要大量时间来制定规则模型,而且模板的泛化能力较差,如果用于其他领域,抽取结果往往不尽人意,因此该方法逐渐被其他两种方法取代。文献[7]提出了一种基于支持向量机(support vector machine,SVM)的需求分类方法,能够较为不错地对功能需求和非功能需求进行分类。文献[8]使用用户评论作为数据集对比四种分类技术和三种传统机器学习算法组成的十二种组合方法的分类性能,最后挑选出最适合作需求分类的方法。文献[9]基于词性规则和依存句法规则结合特征提取和分类的方法将安全关键软件需求实现自动分类,与其他方法相比,准确率有了明显的提升。由此可见基于传统机器学习的方法能有效对需求进行分类,但是传统机器学习模型需要手动构建离散变量特征值作为模型的输入,由于人工输入存在一定的主观性和局限性,在一定程度上影响分类的准确性,随着硬件的更新和算法的突破,基于深度学习的分类方法已经成为大势所趋。文献[10]采用深度学习特征提取和分类技术,提出一种基于BERT(bidirectional encoder representation from transformers)模型和长短期记忆网络LSTM(long short term memory)相结合进行文本分类的BERT-LSTM 网络模型进行需求分类,最终结果与其他方法相比达到了最佳。文献[11]使用基于提示学习的BERT 模型,将K分类选择问题转化为二分判断问题,获得了最佳的分类结果。文献[12]将Word2vec 向量与卷积神经网络TextCNN 相结合,实验结果证明深度学习的方法要明显优于其他方法。
由上文可知,目前有关于需求抽取和需求分类的研究大都集中在软件需求上面,而关于需求抽取的研究成果极少,同时需求的提取难度相对较高。因此,本研究将构建首个中文需求抽取语料库,并且提出一种基于深度学习的需求抽取方法,同时对比目前的主流文本分类方法探究更适合工业界实际的需求抽取方法。
1.2 相关技术
1.2.1 BERT模型
BERT[13]是一种Transformer 的多层双向编码器,其本质是通过神经网络特有的结构进行训练得到BERT 模型,基于预先训练好的BERT 模型能够完成绝大部分自然语言处理任务。这是因为BERT模型的训练语料包括维基百科和图书语料库,规格十分庞大。同时BERT模型是一个“深度双向”的模型,这意味着BERT 模型能够获取文本中上下文的信息,这也能确保BERT模型能够完整地提取到文本信息。
BERT 使用输入掩码和基于Transformer 的片段标记,将大量的无标签文本转化为一个引导式学习问题。输入掩码用于引导模型根据上下文判断当前单词是否合适,而片段标签则用于判断下一句话是否连贯。其网络结构模型如图1所示。
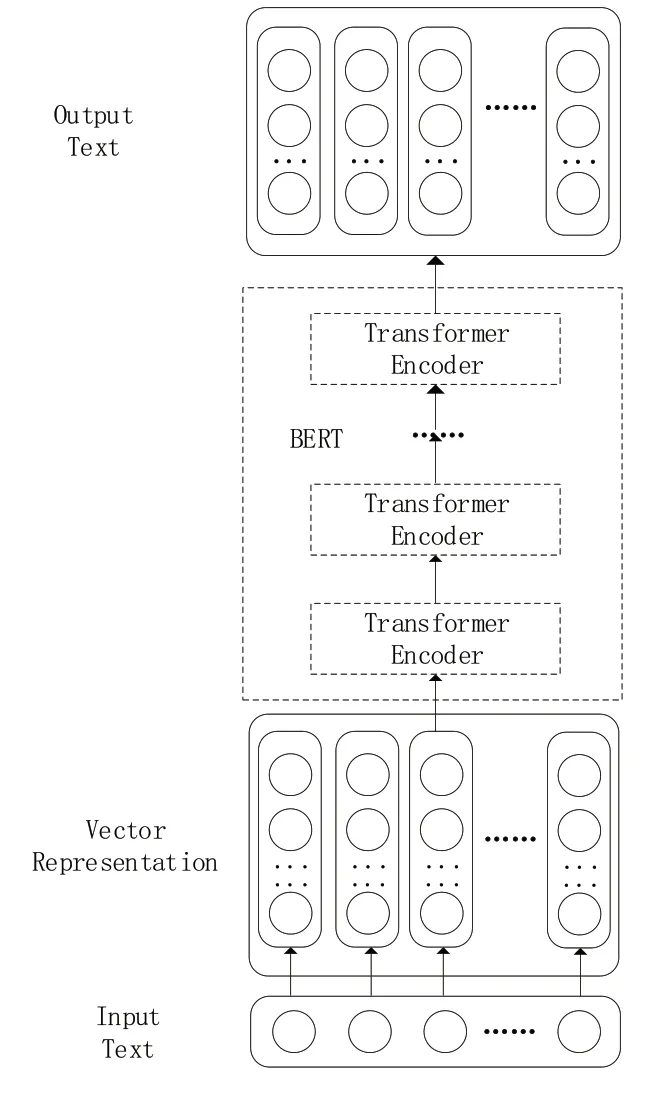
图1 BERT网络结构
RoBERTa-wwm[14]模型是BERT 模型的变种,RoBERTa-wwm 与BERT 相比主要有两方面提升,首先是RoBERTa 预训练模型与BERT 相比具有动态Mask、取消NSP 任务、设置更大的batchsize训练、更多的训练数据、更长的训练时间等优化策略,因此泛化能力更强;其次是Ro-BERTa 使用基于全词掩码的中文训练方式,该训练方式可以有效提高预训练模型效果。
1.2.2 BiLSTM 模型
长短期记忆网络(long short-term memory network,LSTM)在1997 年被提出,LSTM[15]结构内部有三个门:输入门、遗忘门和输出门。遗忘门决定从神经网络的单元状态中丢弃哪些信息,输入门决定在单元状态中存储哪些新信息,输出门根据过滤后的新单元状态决定输出值。输出层根据过滤后的新细胞状态决定输出的值。BiLSTM(bi-directional long short-term memory)[16]在网络结构上与LSTM 网络类似,主要由前向LSTM 和后向LSTM 组成,相较于单向的LSTM模型,BiLSTM 算法能够学习到更多的上下文信息。BiLSTM的网络模型如图2所示。

图2 BiLSTM网络模型
1.2.3 BERT-BiLSTM 模型
BERT-BiLSTM 模型的构建流程首先是将BERT预训练模型输出的文本向量输入到BiLSTM层进一步做特征提取,在BiLSTM 层中将双向加权向量进行全连接处理,输出层由全连接层和Softmax 组成,Softmax函数接收到新输出的向量之后对文本进行分类操作。BERT-BiLSTM网络模型结构如图3所示。研究所用模型是将BERT-BiLSTM模型中的BERT 替换为RoBERTa-wwm,通过RoBERTa-wwm 的优势提高需求抽取的准确性。
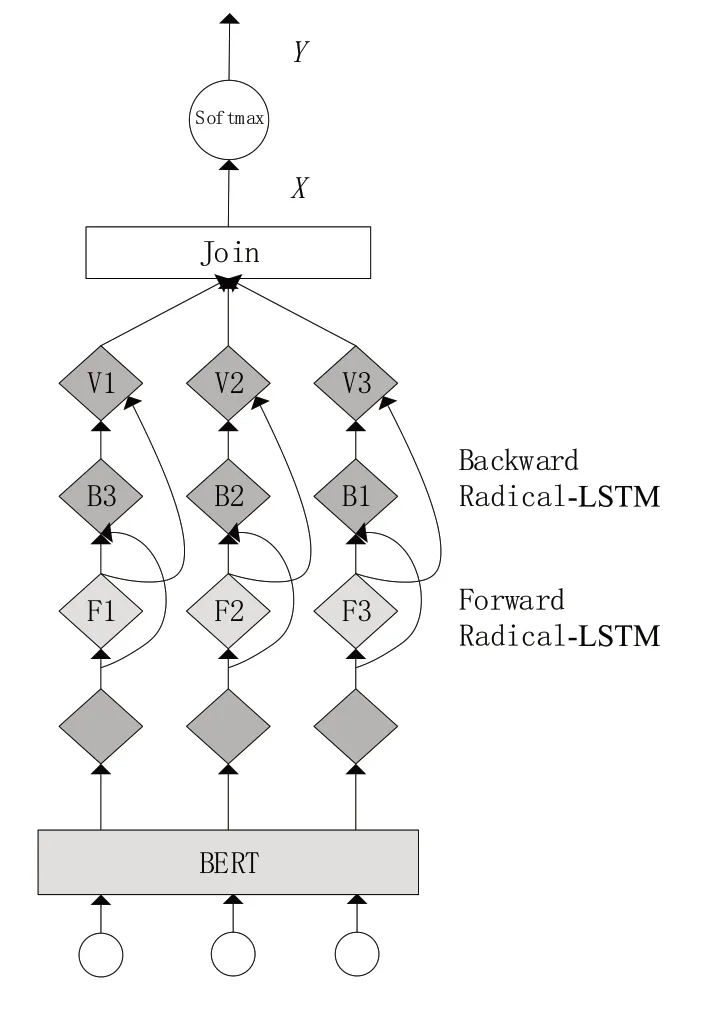
图3 BERT-BiLSTM 网络模型结构
2 实验与分析
2.1 数据集的构建
由于目前缺少中文软件需求的数据集,因此该研究的数据集主要来源于凯德股份的需求池、需求规格说明书以及网络上有关需求工程研究的博客和文档等一系列需求相关的文档。其中需求条目和非需求条目的数量见表1。同时该研究将数据集中的80%作为训练集,20%作为训练集。

表1 需求条目数量表
2.2 评测标准
该研究用于评价需求抽取效果的评价指标为精确率(Precision)、召回率(Recall)和F1 值(F1-mesure)。其具体公式见式(1)~式(3)。
其中:TP表示真阳性(true positive,TP);FP表示假阳性(false positive,FP);TN表示真阴性(true negatives,TN);FN表示假阳性(false negative,FN)。
2.3 实验参数设置
实验采用的BERT模型为BERT-Base-Chinese版本,RoBERTa-wwm 版本为RoBERTa-wwm-ext-Chinese,实验相关超参数设置见表2。

表2 实验超参数取值
2.4 实验结果
研究选取了几种主流的深度学习的分类方法作为基准模型来评估本方法的有效性,主要包括TextCNN、BERT、BiLSTM、BERT-BiLSTM。各模型在需求条目数据集上的分类效果见表3。

表3 需求抽取效果对比
2.5 实验结果分析
由上文的分类效果对比可得,研究构建的模型在各方面皆优于当前文本分类主流的几种算法,由此可见本研究算法的优越性。
对比表3 中的结果可以看出,TextCNN 模型相较BiLSTM 模型F值提升了1.49 个百分点,这是由于TextCNN 擅长捕获更短的序列信息,Bi-LSTM擅长捕获更长的序列信息,而数据集中大部分需求条目都是字符长度较短的句子,因此BiLSTM 无法最大程度发挥自身的长处,导致准确率不如TextCNN。而BERT 模型属于预训练模型,模型一开始就能更好地理解文本,同时Transformer 的双向特征能够使模型更容易学习到前后文信息,因此F值相较TextCNN 提升了1.61 个百分点。BERT 和BiLSTM 都能够很好地提取到字符特征,因此这两个模型的组合能够对词向量做进一步处理,使得需求抽取的效果更佳,因此BERT-BiLSTM 相较BERT 的F值提升了4.73 个百分点。RoBERTa-wwm-BiLSTM 模型效果是所有算法中表现最出色的,这是因为RoBERTa-wwm 与BERT 相比具有的两大优势,这两大优势能够让RoBERTa-wwm 有更好的表现。所以RoBERTa-wwm-BiLSTM 模型的最终效果要明显优于其他需求抽取模型。
3 结语
随着需求工程研究逐渐深入,需求分析等任务的研究同样进行得如火如荼,而在进行这些研究之前将需求抽取出来对于需求工程的研究进展有很大的积极意义。但是需求条目相较于其他语句和其他分类任务难度较大,且目前也没有需求条目公开的中文训练集。这导致需求工程的研究在工业界和学术界的进展都十分缓慢。
因此本研究首先基于凯德股份数据库以及网络上的有关于需求工程研究的博客和文档,构建首个中文需求抽取数据库,再针对需求条目描述提出了一种RoBERTa-wwm-BiLSTM 抽取方法,并对其效果进行了实际测试。结果表明其精确率、召回率和F值依次达到94.74%、93.33%和93.65%,说明该方法与目前主流的分类方法相比有了比较明显的提升,是比较适合在工业界进行需求抽取的一种方法。该研究所构建语料库和所提方法能够为之后需求抽取的研究打下基础,同时为其他需求抽取任务甚至其它文本分类任务提供借鉴。
尽管本研究取得了一定的成果,但是也存在一定的不足,后续研究将会继续扩大需求抽取的数据集,针对工业界的特点,在算法层面上提高需求抽取的速度和准确率,最后与凯德股份开发的KD-DSP 凯德数字体系工程平台进行结合,研发出更强大的体系工程平台。
