基于数字孪生的自动驾驶仿真测试研究
2023-06-27罗健炜胡哲铭郑开超
罗健炜,胡哲铭,郑开超,廖 政
(广东工业大学自动化学院,广州 510006)
0 引言
进入21 世纪以来,全世界范围内的汽车保有量日渐增长,由此造成的能源匮乏、环境污染和交通拥堵等问题日渐严重[1],自动驾驶是解决这些问题的最佳方法,自动驾驶是未来汽车行业最有前景的发展方向。随着计算机技术、人工智能技术的发展,通过将人工智能、边缘计算等新兴技术与传统汽车行业进行深度的结合给自动驾驶的发展注入了全新的活力。通过自动驾驶技术可以有效地降低交通事故发生的概率,提高民众出行的安全性[2]。2017 年Strategy Analytics 发布的自动驾驶市场研发报告预测,自动驾驶在2035 年至2045 年的十年期间将能够间接地使58.5 万条生命受到有益的影响。《欧洲自动驾驶智能系统技术路线报告》指出:到2050 年,由于自动驾驶技术在汽车行业的应用,污染物排放降低50%,交通伤亡率接近零[3]。
自动驾驶技术是未来汽车行业最热门的技术方向,国内外许多大型汽车企业和科研院所都在智能驾驶领域进行了巨额的投入和研究。然而,最近几年,自动驾驶汽车经常性地出现安全事故问题,搭载了NOP(领航辅助系统)的蔚来汽车ES8 车型在2021 年造成了一起安全事故导致驾驶员的死亡,特斯拉的汽车在辅助驾驶系统状态下也曾发生很多次的交通事故[4],这让人们不得不认真思考现在的自动驾驶发展到了什么水平,它的安全性是否能够得到充分的保障。为了保障自动驾驶汽车的安全性,对自动驾驶汽车进行全面、科学、有效的测试就显得特别有必要。在自动驾驶汽车被商业化之前,必须要经历一层一层的测试才能被允许进行销售使用。
现在主要的自动驾驶测试方法有:软件在环测试、硬件在环测试、封闭道路测试和真实开放道路测试[5]。软件在环测试存在着虚拟测试场景与真实道路场景存在差距和车辆模型精度欠缺的问题。封闭道路测试存在着测试成本高、测试场景有限的问题。真实开放道路测试存在测试成本高、测试周期长、安全性低、缺乏极端测试场景的问题。针对这些问题,提出一种基于数字孪生的自动驾驶硬件在环仿真测试架构,能够高精度地将真实场景映射到虚拟场景中[6],将算法模型搭建到硬件平台中能够更加逼真地模拟出自动驾驶汽车的运行状态,在提高测试效率和降低测试成本方面具有巨大的优势[7]。从使自动驾驶测试变得安全、高效方面考虑,采用硬件在环仿真测试能够更好地推进自动驾驶的开发。
本文首先介绍了基于数字孪生的自动驾驶硬件在环仿真测试架构的设计,然后提出了一种基于深度学习的自动驾驶控制算法模型结构,并介绍了模型的训练过程和模型评估指标,最后对自动驾驶控制算法模型实验进行结果分析。
1 基于数字孪生的自动驾驶硬件在环仿真测试架构设计
基于数字孪生的自动驾驶硬件在环仿真测试架构主要由三个模块组成,分别是:仿真测试场景构建模块、算法控制模块、仿真测试评价模块,它的整体架构如图1所示。

图1 基于数字孪生的自动驾驶硬件在环仿真测试架构
其中仿真测试场景构建模块和通信信道是搭载在实时机上的,算法控制模块部署在AGX 上。在仿真测试场景构建模块中,采集真实场景数据,根据真实场景数据构建数字孪生仿真测试场景并与真实场景的数据实时映射[8]。对于构建好的数字孪生仿真测试场景,将场景中的传感数据输入到算法控制模块中,经过算法控制模块的计算得到对应的驾驶输出量,将驾驶输出量输入到车辆模型中控制虚拟场景中的车辆运行,形成了一个控制闭环[9]。对于仿真测试的结果,利用仿真测试评价模块对测试结果进行评价。
1.1 算法控制模块
本架构中的算法控制模块搭载的是深度学习算法控制器,它的工作流程如图2所示。先从仿真测试场景中采集当前车辆正对的场景图片数据,将场景图片进行几何变换、裁剪、去噪以及图像增强等数据预处理操作,然后设计并搭建好一个神经网络结构,将预处理后的场景数据导入到神经网络中进行训练,通过训练构建一个神经网络驾驶模型,对驾驶场景信息进行识别,最后生成方向盘转角、油门增量、刹车增量等驾驶指令对车辆进行控制。
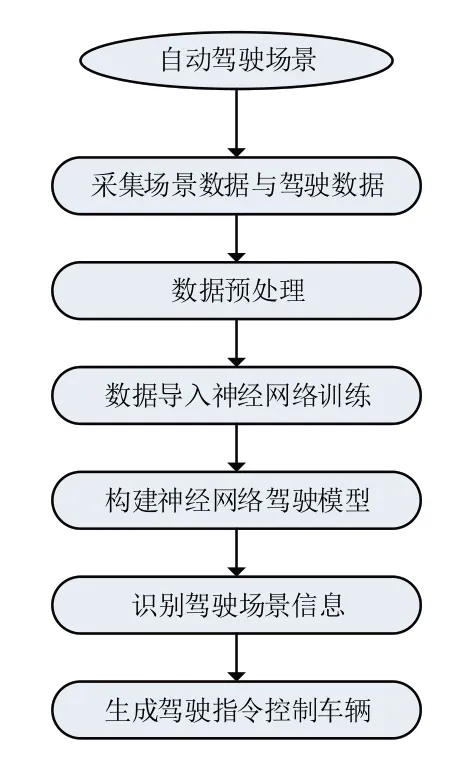
图2 算法控制模块流程
1.2 仿真测试场景构建模块
仿真测试场景构建模块是利用数字孪生技术进行仿真测试场景的构建,该模块的工作流程分为以下几步:①通过激光雷达和摄像头从真实道路场景中获取车辆数据、交通流数据、行人数据、路网数据、环境数据[10];②对获取到的数据进行清洗,将不符合规则的数据删除掉,将符合规则的数据保留,然后对数据进行格式化处理,并进行数据挖掘分析以及数据的分类,最后将结构化的数据保存到自动驾驶场景数字孪生系统数据库中;③根据自动驾驶场景数字孪生系统数据库中的结构化数据对虚拟模型进行构建和组装[11],将模型构建完成之后对虚拟模型进行验证,若验证通过,则加入到虚拟模型库中以便后期运行和管理;若验证失败,则对虚拟模型进行修正直到验证通过为止;④将模型库中的环境、车辆、行人、交通流和路网三维模型导出并与真实道路场景进行数据的实时映射,利用三维构图技术使数字孪生仿真测试场景三维动态可视化[12]。
在本文中仿真测试场景构建模块是基于Airsim 和Unity3D 来进行搭建实现的,利用Unity3D来搭建自动驾驶场景,再利用Airsim 中集成的真实地图数据,将地图数据与自动驾驶场景结合搭建数字孪生仿真测试场景。同时,Airsim中还提供了不同的车辆模型来导入调用,可以设置并调用相关的传感器来获取场景数据和车辆数据以及搭建并调用车辆模型。
1.2.1 场景数据感知
在利用真实汽车数据进行物理建模并搭建虚拟车辆模型时,应该将虚拟汽车模型与不同的传感器组合起来进行测试,确保虚拟传感器性能接近真实传感器,使得仿真测试更加贴近实际场景[13]。
在虚拟车辆上的传感器对周围环境进行检测时,需要有一套规则来规定当前传感器当前时刻所检测到的是哪一个物体从而能得到一些具体的传感数据,在本文中采用的传感器检测规则是最近点检测法[14],在传感器检测范围内,选取离传感器最近的物体作为传感器的检测目标点,如图3所示。

图3 最近点检测法原理图
1.2.2 车辆模型
虚拟的车辆模型由车辆的动力学关系形成,根据虚拟车辆的速度、前后轮的距离、前轮和后轮的角度关系、虚拟车辆的长度建立虚拟车辆的数学模型从而模拟车辆的运行[15]。本文的车辆模型简化后如图4所示。

图4 车辆模型简图
根据车辆动力学模型可得:
由以上动力学模型简化车辆模型可得:
上式可用通式表示为
其中:W=(xb,yb,α)T,m=(mb,θ)T,W描述了当前车辆的状态信息,m表示对车辆的控制输入。对于这个m有3个自由度,分别是方向盘转向角、油门增量和刹车增量。
1.3 仿真测试评价模块
对自动驾驶进行仿真测试就是为了检测这个自动驾驶汽车是否安全、是否按照我们所设定的运行。因此,提出一种仿真测试评价方法就非常有必要。在本架构中就引入了一个仿真测试评价模块,仿真测试评价模块主要用于对仿真测试的结果进行一个评价,从而直观地展示测试结果的好坏。通过对同一驾驶场景的算法控制模块的驾驶指令输出和人工操纵驾驶舱的驾驶指令输出进行比较,从而对仿真测试的结果进行评价[16],仿真测试评价模块的工作流程如图5所示。在该仿真测试评价模块中,首先将驾驶场景输入到算法控制模块中,得到模型输出的驾驶指令,然后将驾驶场景导入到驾驶舱中,人工操纵驾驶舱面对驾驶场景进行驾驶,得到人工输出的驾驶指令,对模型输出的驾驶指令和人工输出的驾驶指令计算偏差,利用聚类分析方法对偏差数据进行聚类分析[17],将聚类分析结果导入到设计的评分模型中,对测试结果进行分等级评价,等级分别为优、良好、合格、不合格四个评价等级。

图5 仿真测试评价流程
2 基于CNN-BiLSTM 的自动驾驶控制算法模型
为了实现搭建基于数字孪生的自动驾驶硬件在环仿真测试架构,针对架构中的算法控制模型,本文利用一种基于CNN-BiLSTM 的端到端深度学习算法模型来实现自动驾驶的算法控制,CNN-BiLSTM 是由卷积神经网络模型和双向LSTM 模型结合而成,通过Airsim 的图像传感器采集当前车辆驾驶员视角的图像,将该图像传入CNN-BiLSTM 模型,通过CNN-BiLSTM 模型的计算得到控制车辆行驶的驾驶量:刹车增量、油门增量、方向盘转角[18]。
2.1 CNN卷积神经网络简介
卷积神经网络是一种通过将卷积核矩阵与输入图像矩阵进行点乘运算的神经网络,具有深度结构,能够对图像信息进行有效分类和完成回归任务,能够有效地提取出输入中包含的特征[19]。一个完整的卷积神经网络由很多不同的层来构成,主要有输入层、输出层、卷积层、池化层和全连接层,每种隐含层中都有着复杂的运算关系,通过这些复杂的运算能够有效地获取到输入图像的特征,对图像的特征行为进行学习,从而训练出一个精确度高的卷积神经网络模型完成回归任务[20]。每个层中会包含一些神经元,每个层中的神经元都有一个权值,这个权值通过一定的梯度下降规则在训练过程中会不断地更新调整[21]。
2.2 RNN循环神经网络简介
RNN 循环神经网络是一种能够有效保存前几层计算结果的神经网络,它的元素之间不是相互独立的,它的计算方式是将当前的输入与上一个时刻的状态进行运算,从而得到当前层的输出,经常用于解决具有序列特征的问题[22]。RNN循环神经网络的简单结构如图6所示。
在RNN 循环神经网络结构图中,st表示的是t时刻的隐藏层状态,xt和ot表示的是t时刻的输入和输出,f代表的是神经网络的激活函数,这个激活函数一般为ReLU 函数,b表示偏置。因此,RNN循环神经网络的计算公式定义为
2.3 LSTM简介
RNN 循环神经网络由于其具有记忆的特征,经常被用于序列模型中,但是RNN 也存在梯度消失和梯度爆炸的问题,这个问题主要出现在解决长期依赖问题过程中[23]。LSTM 是RNN 的一种变体,能够将输入信息中的长期信息和短期信息有效地保存下来,能够有效地解决RNN存在的问题。LSTM 引入了输入门、输出门、遗忘门三种门结构来控制特征信息的流动和丢弃[24],LSTM的单元结构如图7所示。
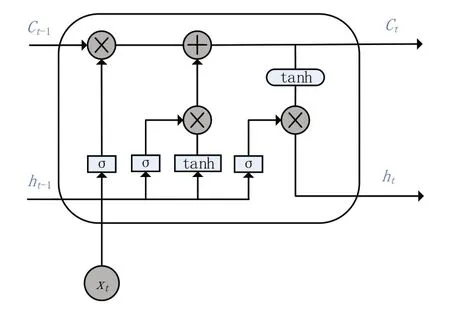
图7 LSTM单元结构
LSTM 的单元结构中包含了遗忘门ft、输入门it和输出门ot,它的计算公式如下:
在上式中,W表示权重,b代表偏移量,σ表示Sigmoid 函数,Ct是单元状态,ht表示隐藏层的状态。
2.4 模型结构
本文提出的CNN-BiLSTM 模型的具体结构见表1。

表1 CNN-BiLSTM 模型结构表
它主要由3 个卷积层、3 个池化层、3 个全连接层和1 个双向LSTM 层组成,同时引入一个Flatten 层作为从卷积层到全连接层的过渡,把多维的输入转换为一维,即一维化。为了减少模型的过拟合现象,还引入了3 个Dropout 层来在训练的过程丢弃一定数量的神经元。
2.5 模型训练
2.5.1 模型训练过程
根据前面提出的CNN-BiLSTM 模型结构,对CNN-BiLSTM 模型的训练过程进行研究,CNN-BiLSTM模型训练流程如图8所示。在CNNBiLSTM 模型训练过程中,先输入图像信息,对图像数据进行预处理,在数据预处理的过程中将图像中对自动驾驶影响最大的部分截取出来,丢弃图像中的其他干扰部分,同时为了使数据更加多样化,得到更多的信息特征,将部分图像和标签进行反转处理,以及随机地添加或者删除图像中的亮度,以便模型可以获取到亮度的全局变化。对于数据集中数据为零的数据点,为了使数据集更加平衡,需要根据一定的策略丢弃这些数据点。在完成数据的预处理之后,通过CNN-BiLSTM 模型的卷积、池化、全连接等操作提取出数据集的特征,CNN-BiLSTM 模型通过不断地更新神经元权值来不断地对特征进行学习,最终完成模型训练。
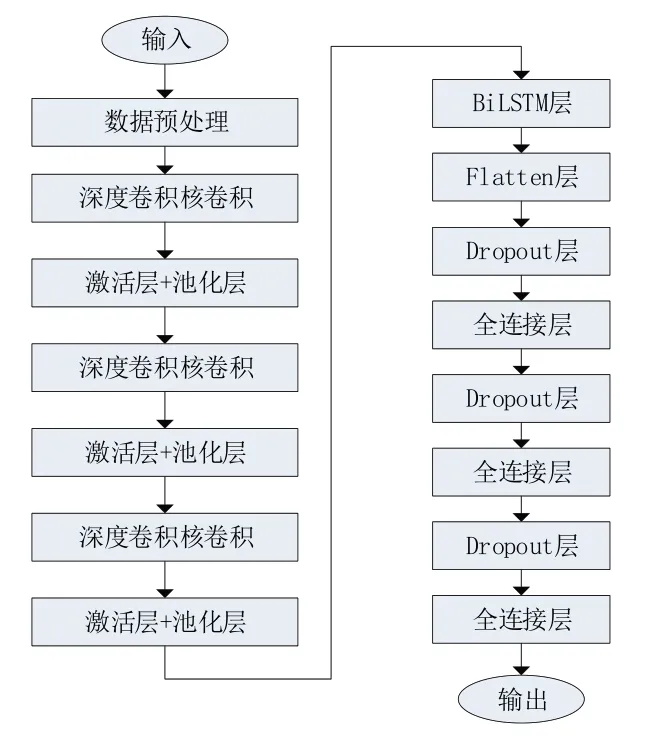
图8 模型训练流程
2.5.2 模型评价指标
本文选取平均绝对误差(mean absolute error,MAE)、均方误差(mean square error, MSE)、决定系数(R squared)、预测值与真实标签的余弦距离平均值的相反数(Cosine_Proximity)、均方对数误差(mean_squared_logarithmic_error, MSLE)作为卷积神经网络模型精度的评估指标[25]。
平均绝对误差(MAE)表示的是绝对误差的平均值,它的函数式是:
均方误差(MSE)通过将真值与模型估值误差的平方求平均值,用来检验模型的预测效果,它的函数式是:
决定系数(R squared)可以反映训练出来的模型对数据的拟合度,它的范围一般在0~1 之间,它的值越接近1,表示这个模型的拟合程度越好,它的函数式是:
Cosine_Proximity 是通过余弦值来判断真实值向量和预测值向量的相似程度,它的值越趋近于1,表示两个向量的方向越一致,也就是说预测值越接近真实值,它的函数式是:
均方对数误差(MSLE)是通过对数来表示真实值与预测值之间的偏差,它的函数式是:
3 实验与结果分析
3.1 实验环境
本文实验是基于深度学习开源库Tensor-Flow、Python 和Keras 深度学习框架搭建卷积神经网络模型并对模型进行训练的,具体的实验仿真环境见表2。

表2 实验仿真环境
3.2 数据处理
本文实验采用的数据集来自于Airsim 仿真平台提供的自动驾驶数据,Airsim 是微软公司开源的一个跨平台的基于虚拟引擎的仿真模拟平台,可以在Airsim 平台上利用平台的仿真环境采集自动驾驶训练数据,Airsim 平台官方本身也提供了面向自动驾驶训练的数据集。数据集主要由两部分组成,一部分是驾驶员视角的图像,另一部分是一个文本文件,文本文件中记录着与图像文件相对应的驾驶数据,由时间戳、速度、油门量、方向盘转角、刹车量、档位、图像名称,每个图像都对应了一行驾驶数据,驾驶数据的采集是连续的。在数据集中还分为两种数据,这两种数据的数据结构一致,代表了两种不同的驾驶策略和驾驶风格,一种是正常的驾驶风格,即方向盘转角的变动相对平缓;一种是剧烈转向的驾驶风格,即方向盘转角的变动相对剧烈,通过两种截然不同的驾驶风格数据的结合使得数据集更加多样化、普适化。
对于数据集的处理,由于在自动驾驶中并不是整个驾驶员视角都是对自动驾驶重要的部分,因此会对数据集中的图像进行截取处理,丢弃对自动驾驶训练会造成干扰的部分,集中关注重要特征。本文实验对数据集进行了划分,训练集、验证集和测试集的比例为7∶2∶1,同时设置训练的批量大小为32来进行训练。
3.3 实验结果分析
本实验通过平均绝对误差(MAE)、均方误差(MSE)、决定系数(R2)、预测值与真实标签的余弦距离平均值的相反数(cosine_proximity)、均方对数误差(MSLE)来评估模型精度。实验采用CNN、CNN_LSTM、CNN_GRU、CNN_BiLSTM 四个模型进行分析对比,四个模型在训练过程中的评估指标的变化如图9 所示。MAE、MSE和MSLE越接近0,Cosine_Proximity和R2越接近1,表示模型回归精度越高,真实值与预测值越相似,模型的预测效果越好,从四个模型的评估指标随着Epoch变化的趋势可以看出,MAE、MSE和MSLE不断地收敛于0,Cosine_Proximity和R2不断地收敛于1,在训练过程中略有波动,但最终仍不断收敛。随着Epoch的不断增大,模型训练逐渐收敛于某一个值,当收敛值在设定的Epoch范围内变化值小于阈值时,则训练停止。
当Epoch=200时,四种深度学习模型的性能指标如表3所示,从表3可以看到,CNN_BiLSTM模型的MAE、MSE和MSLE指标值是四种模型中最接近0的,它的R2和Cosine_Proximity指标值是四种模型中最接近1的,即CNN_BiLSTM模型在四种模型中回归精度最好、拟合优度最高。在Epoch=200 时,CNN_BiLSTM 模型的拟合优度R2达到了0.9654,均方误差MSE为0.0030,平均绝对误差MAE为0.0334,均方对数误差MSLE为0.0013,Cosine_Proximity达到了0.9800。

表3 四种深度学习模型性能指标
4 结语
随着自动驾驶的不断发展,对自动驾驶汽车进行充分的测试成为了最重要的难题。针对开放道路测试成本高、安全性低和软件在环测试逼真度和精度不足的问题,本文提出了一个基于数字孪生的自动驾驶硬件在环仿真测试架构,大大降低了自动驾驶的测试成本,该架构由仿真测试场景构建模块、算法控制模块、仿真测试评价模块三个模块组成,并针对基于数字孪生的自动驾驶硬件在环仿真测试架构的算法控制器,提出一种基于CNN_BiLSTM 模型的端到端深度学习自动驾驶控制方法,经过实验证明,CNN_BiLSTM 模型相比其他三种深度学习模型更能挖掘到数据特征,回归拟合效果最佳,该模型在Airsim 平台数据集上的拟合优度达到了0.9654,能够更好地实现自动驾驶控制。
