基于双向时序和多交互类型的人物交互动作检测
2023-06-27王夺魁
王夺魁
(西南交通大学计算机与人工智能学院,成都 611756)
0 引言
为了理解现实场景中的信息,计算机需要识别人与周围物体的交互方式,而人物交互(human-object interaction, HOI)检测则是实现以人为中心的场景的更高层次语义理解的重要关键技术,它在视频理解、智能监控、人机交互等方面发挥着重要作用。HOI 检测的目标是得到三元组<人,交互动作,对象>,三元组的主体是人,对象包含人和物体,主体和对象的相互作用是动作。
HOI 检测的输入数据类型包括图像和视频两类。图像主要应用于人物交互时间较短的动作,视频涉及到时序信息,可以基于前序特征,更有利于检测人物交互时间较长的动作。由于现实生活中人物交互过程主要是视频信息,更具有社会应用价值,并且需要聚合分析视频在不同时序上各实例的动态关系,难度大,更有研究价值,因此,本文做的是基于视频的人物交互动作的检测工作。
视频中人物交互动作的检测方法主要归纳为三类:双流网络、3D 卷积网络、计算高效的网络。双流网络[1]是在一个卷积网络提取空间特征的基础上,新增一个卷积网络分支利用光流信息提取视频中人物运动的时序特征,最后融合两个分支的时空特征。双流网络能够有效提取短期的运动信息,但是无法很好地捕捉长期运动的信息,并且光流计算量大,存储空间大,时间成本高,不利于大规模训练和实时部署。因此,后续的工作主要针对于光流的改进或者思考提出新的解决范式—3D 卷积网络。3D卷积网络主要使用3D 卷积核对时间信息进行建模。I3D[2]根据Inception[3]网络架构实现的,将原先的卷积核和池化核增加一个时间维度进而从2D 扩展到3D,并且有效地将2D 网络的预训练权重迁移到3D 网络中。然而3D 网络仍具有较大的参数量,更难训练和优化。近几年,由于基于自注意机制的Transformer 模型在计算机视觉领域的性能显著提升,涌现出许多优秀的相关工作,Girdhar 等[4]设计Transformer 结构来聚合人体周围时空上下文的特征,并构建动作Transformer 模块来识别和定位视频片段中人物的交互动作。
本文的主要工作包括以下四点:
(1)为了丰富特征空间,提高对交互时长较短动作的检测能力。本文提出了双向时序增强模块,引入了双向视频帧特征库和双向交互动作适配器,用于存储前向时序和反向时序的视频帧特征以辅助提高当前帧的表征能力,以及正确将反向特征唯一映射到正向特征空间内。
(2)本文构建了多交互类型模块,包括人与人特征融合和人与物体特征融合两个子模块,细化了特征融合方式,针对性地自适应实现人-人交互、人-物交互的建模,提高了检测精度,而且这两个子模块并行运作,提高了检测速率。
(3)本文引入Transformer 编码器对多种自建模块的输出特征进行融合,含有丰富的上下文信息和全局人物位置信息,提高了检测精度。
(4)本文模型在处理过的公开视频数据集AVA-HOI 上进行了验证。实验结果表明本文方法的交互动作检测准确度高于多个主流的模型,mAP@0.5IoU 为25.81%,较TubeR 方法[5]提升了1.29个百分点。证明了本文模型可以完成视频中人物交互行为检测任务,具有不错的性能表现。
1 总体网络模型
本文设计的总体网络模型如图1 所示,该模型主要包括三大部分:双向时序增强模块、多交互类型建模模块、多头注意力特征融合模块。双向时序增强模块包括双向视频帧特征库和双向交互动作适配器,这两个子模块是串联起来的。多交互类型建模模块包括人与人交互建模H-H 和人与物交互建模H-O,这两个子模块是并行处理的。
网络模型的输入可能含有人物交互行为的视频片段中的关键帧,视频帧的大小会调整成464 × 464,将视频帧输入到目标检测器和特征提取器分别获取人体框和物体框以及特征图,经过ROI 将特征图和目标框进行对齐得到准确匹配的当前帧的特征图。该特征图经过两个并行的处理操作:一是输入到视频帧序列长度为64帧的双向视频帧特征库中的前向特征存储库,经内置的反向算法得到反向特征图序列并实现双向特征图的张量拼接,通过双向交互动作适配器完成反向时序特征与前向时序特征的唯一映射;二是从整个特征图中拆解出人体特征图Ht和物体特征图Ot,以及经过mask 掩码机制获取到的空间位置特征St。然后将Ht和Ot输入到多交互类型建模模块得到融合后的特征HHt和HOt。再引入Transformer编码器对上述多种自建模块的输出特征进行融合,得到丰富的上下文信息和全局信息。最后输入到人物交互分类器中进行判别,即可输出当前视频帧中含有的人物交互动作类别。

图1 总体网络模型框架
2 算法设计与实现
2.1 双向时序增强
在视频中,人和物体的位置会随着时间而发生移动,当前视频帧中的人物交互动作会与前后帧之间存在时序上的关联性,因此,模型在检测当前帧中的交互动作类别时需要考虑到相邻帧的特征以提高检测精度。通常情况下,一个物体从a点运动到b点,从相反角度可看成从b点运动到a点。借鉴这种思想,沿着时间顺序进行的交互动作也可看成逆时间顺序的交互动作,以达到为视频帧中的人和物体构造出具有互补信息的时间运动轨迹信息。只要把反向的交互动作正确映射到正向的交互动作上,即实现双向动作匹配,便可以丰富视频帧特征,将同一交互动作的人物特征图扩充为原先的2倍,实现特征增强,该模块有利于提高对交互时间较短的动作的检测能力。
基于以上思考,本文首先构建了双向视频帧特征库,用于存储一定数量(本文设定的是64帧)的视频帧的特征图,并内置了反向置换算法,将传入的正向视频帧逆向存储,因提前进行了反向处理,则在模型训练过程可以直接加载反向视频帧特征,以空间换时间的思想提高模型的训练速度。
双向视频帧特征库的写入和更新算法的主要步骤如下:
(1)模型数据加载器一次读取指定帧数N的视频帧送入网络模型中,经特征提取器和目标检测器之后进行ROI 对齐获取到当前帧序列的特征图,按照顺序依次存储到双向视频帧特征库的前向特征内存池(forward-feature memory pool,FFMP)中,并且按照次序给每一视频帧特征图标记为
其中Ft表示当前检测的视频帧。
(2)当检测到有新的视频帧特征图输入到特征库时,则触发反向置换算法,该算法将按照逆序依次存储到反向特征内存池(backwardfeature memory pool,BFMP)中,视频帧特征图序列标记为
(3)因为特征库的长度设置成64 帧,即最多只能存储64 帧的时序特征图,所以后续输入的特征图将采用滑动窗口的机制,丢弃旧帧以替换成新帧的特征图,始终保持特征库中含有最新的特征图。
双向视频帧特征库的读取算法的主要步骤如下:
(1)从特征库中读取当前帧的相邻m区间内的视频帧特征,组成前向时序特征序列FFm和反向时序特征序列BFm,见公式(3):
(2)双向时序特征拼接:相邻区间内关键帧与当前关键帧Ft的距离远近意味着时序上的相关性程度,距离越近,则相关性越强,越有助于当前帧中交互动作的检测。因此,引入反距离加权函数来赋予其他关键帧对当前帧的权重值,进而确定在拼接后的特征中不同关键帧的影响程度。定义当前帧Ft在[t-m,t+m]区间内每个关键帧Fi对其影响权重值为Wi,则采用反距离加权函数可表示为
将特征库中区间内的正向时序特征和反向时序特征在时间序列上进行张量的拼接,拼接后的特征分别为FFconcat和BFconcat,则表示如下:
因为拼接后的特征通道维度会增加,需要降维到与拼接前当前帧特征相同的形状,所以将FFconcat和BFconcat经过3D 卷积和池化操作实现形状的匹配,表示如下:
双向时序特征拼接的过程如图2所示。
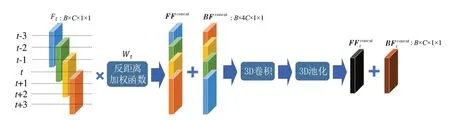
图2 双向时序特征序列拼接
在设计双向交互动作适配器时,还需要考虑到两两交互动作类别之间是否与时序强相关的,避免由于某个交互动作的反向特征与其他交互动作的正向特征相似而产生的干扰。例如“开门”和“关门”是两个相反的交互动作,“开门”经过反向特征置换后与“关门”的行为是相同的,因此需要制定一种策略使其产生的虚拟“关门”特征归属于“开门”类别,而不能错误地归类于实质性的“关门”。
因此,在双向交互动作适配器中为每个交互动作分配唯一的ID,将反向交互动作绑定到对应的正向交互动作。根据其ID 便可将模型在反向特征空间内检测到的结果映射到正向特征空间,增强特征的表达能力,提高交互动作检测精度。
2.2 多交互类型建模
视频帧经过目标检测器和特征提取器后进行ROI 对齐后,则会得到当前帧的特征图。以前大多数工作是直接使用这个特征图经过某些处理操作完成人物交互动作的检测,这种特征图的使用方式相对粗糙,没有针对性,并且当特征图中仅有人的情况时不能较好地表征,检测效果较弱。本文针对上述问题并借鉴了Tang等[6]的交互模型思想,构建了多交互类型模块,该模块包括两个类似的子模块:人与人特征融合模块和人与物体特征融合模块,记作H-H 和H-O。
多交互类型模块首先根据特征图中检测框的类别,提取出人体特征Ht和物体的特征Ot。并且采用mask掩码机制提取到空间位置特征St,即将含有人物目标的特征像素赋值为二进制的1,而其他位置赋值为0。H-H 模块针对人与人之间的交互进行自适应的建模,查询、键以及值的输入都是人的特征Ht,经过Linear 层、点积、Scale、Softmax 层、LayerNorm 层实现特征的融合,输出增强后的特征HHt。H-O 模块则针对人与物体之间的交互进行自适应的建模,查询是人的特征Ht,而键和值是物体的特征Ot,通过与上述相同的处理操作完成特征的融合,输出增强后的特征HOt。这两个子模块是并行运作的,最后将HHt与HOt合并后输入到Transformer编码器模块中。
2.3 多头注意力特征融合
本文模型采用含有多头注意力机制的Transformer 编码器[7]对其他模块生成的特征进行编码增强,包括双向时序特征、多交互类型特征以及人物空间位置特征。编码后的特征含有丰富的上下文信息以及全局信息。为了进一步提高交互动作的检测精度,这里引入了N个Transformer编码器,多次编码会使得特征的表征能力更强,最后将其输入到人物交互分类器中,选择置信度大于指定阈值的交互动作类别作为当前帧的结果输出。
3 实验
3.1 实验环境和训练参数
实验硬件和软件环境参数见表1。

表1 实验软硬件环境
每次迭代输入骨干网络中视频帧数为64 帧关键帧,4 个数据加载进程,初始学习率为0.0004,学习率偏置因子是2,优化器采用随机梯度下降算法SGD,权重衰减值是1e-7,衰减步长位于(105000, 135000),最大迭代次数为165000,迭代次数前2000送入模型预热调度器。模型训练阶段选择4张显存为11 GB 的RTX2080 Ti显卡进行分布式训练,总共批量大小为8,即每张显卡每次训练2个短视频。候选框的阈值设定为0.8,网络模型的Dropout值为0.2。输入视频帧的尺寸最小为256,最大为464。输入数据增强包括旋转、缩放和颜色抖动。
3.2 实验数据集
实验数据集基于时空动作检测常用的AVA数据集[8]进行改造,因为本文研究的是人物交互动作的检测,所以删除了前14 个单人姿势动作的标签,并且对相关标注文件进行了处理,提出了名为AVA-HOI 数据集。AVA-HOI 共有299 个标注时长为15 分钟的视频片段,其中235个作为训练视频,64 个作为验证视频。AVAHOI 具有66 种常见的人物交互动作标签,标注数量多达67 万,涵盖人与人的交互动作和人与物体的交互动作。
3.3 评价指标
采用人物交互动作检测通用的mAP(mean average precision)@0.5IoU 作为评价指标,mAP表示模型在所有人物交互动作上的检测性能,mAP值越高表示检测准确率越高。mAP@0.5IoU的计算公式如下:
其中,HOI-C 表示AVA-HOI 的某个交互动作类别,N(HOI-C)表示所有交互动作类别总数,表示某个交互动作类别的检测准确率,计算公式如下:
其中:TP(true positive)表示正确预测的样本数目,FP(false positive)表示错误预测的样本数目。
3.4 实验结果与分析
为了验证本文提出的算法模型的有效性及性能表现,将本文方法与其他主流方法都在AVA-HOI 数据集上进行了模型训练和测试,同时,实验方法都采用参数量和计算量相近的骨干网络进行实验,实验结果见表2。
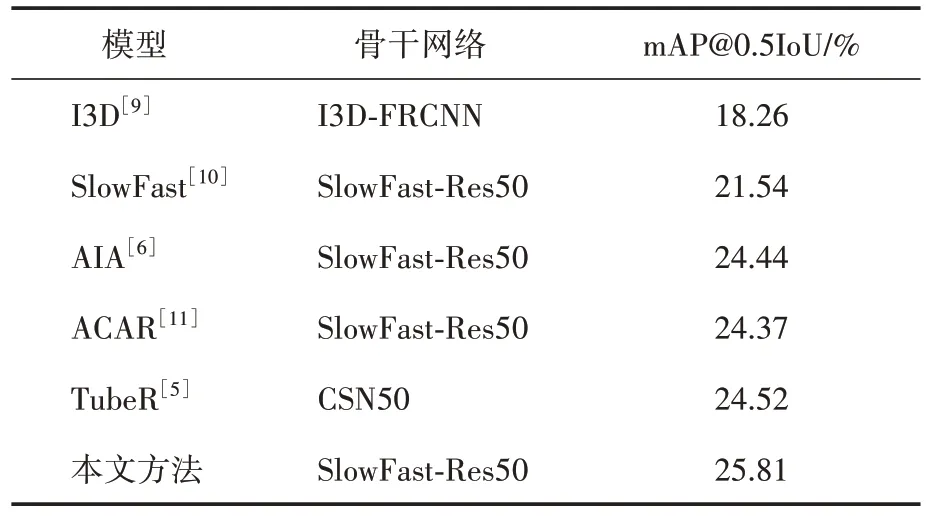
表2 本文方法与其他主流方法的对比结果
通过对比实验结果,可知本文网络框架模型较主流方法都有一定的提升,mAP@0.5IoU 为25.81%,较TubeR 方法提升了1.29 个百分点。原因是采用了双向时序增强模块,引入了反向特征及对应的双向动作适配器,将同一人物交互动作的特征图扩充到原先的2 倍,提高了模型训练过程中人物特征图的表达能力,并且这一处理可以增加对人物交互时长较短的动作的识别能力,同时应用了双向视频帧特征库,在检测当前帧的交互动作类别时可以很好地参考前后帧的特征,利用到了视频中交互动作会存在时序相关性。此外,模型采用了多交互类型建模机制,分别针对人与人交互和人与物交互单独进行特征融合,提高了检测精度和速度。最后引入Transformer 编码器对空间位置特征、多交互类型融合特征、双向时序增强特征进行融合,生成最佳的人物交互特征送入人物交互分类器进行判别。该对比实验证明了本文模型的有效性,性能表现不错。
此外,将基线模型和本文模型在AVA-HOI验证集上每个人物交互类别的AP@0.5IoU 结果进行对比,结果如图3所示。
通过图3所示,可知本文模型相比基线模型在各个人物交互类别上都有所提升。对于不同的交互动作类别,AP@0.5IoU 的相差较大,存在明显的长尾分布,部分交互动作的AP@0.5IoU 较小是因为交互双方实体不明显、交互尺度差异大、交互存在遮挡以及交互行为弱依赖于时序关系。
为了确定本文模型的流程和训练过程是否正确,对经过多头注意力融合后的特征进行可视化,结果如图4所示。
图4 中第一行是视频帧,第二行是注意力图可视化的结果,第三行是对应的交互类别。由图4分析可得以下三点:
(1)多交互类型建模效果不错,只关注存在交互行为的区域。
该模型适用于人和人之间的交互、人和物体之间的交互。见图4 中的“举杯”“抽烟”和“看电视”是人与物体间的交互,而“拥抱”是人与人之间的交互。针对于多人多物体等复杂场景,模型只关注真正存在交互行为的区域,如图4第4列“拥抱(多人)”只关注到了存在拥抱行为的三个人,而不会将其他无关人员和物体的特征输入到人物交互分类器中导致检测干扰。
(2)本文模型也可以识别到非接触式的交互行为。

图3 基线模型和本文模型在AVA-HOI验证集上每个交互类别的结果

图4 注意力图可视化
非接触式的交互行为的识别是业界的研究难点之一,虽然本文并没有针对此点进行深入研究,但模型仍可以较好地检测出来,原因是本文使用了掩码机制对视频帧中的人物的空间位置特征进行表征,并输入到多头注意力模块中进行特征融合,因此考虑到了全局空间特征和人物之间的空间关系。见图4 第5 列“看电视”,在视觉特征上人与电视并没有接触,但在空间关系上是存在实质性的交互行为的,本文模型针对这种类型的交互也可以检测出来。
(3)多头注意力融合后的特征是有效的,进而证明了本文网络模型可以很好地完成视频中人物交互行为检测任务。
多头注意力机制融合了模型处理过程中生成的多交互类型建模特征、空间位置特征以及双向时序增强后的特征,这是输入到人物交互分类器的最后一步。因此,如果融合后的特征是有效表征的,则说明本文网络模型的整个过程中涉及到的模块都是有效且相互促进的,整体是可以完成人物交互行为检测任务的,而通过图4 针对于融合后的特征进行可视化正是验证了这一点的有效性。
3.5 消融实验
为了验证本文提出的网络模型中各模块的有效性,使用同一个基准模型,设计了多组消融实验,结果见表3。

表3 模型中各模块消融实验结果
由表3 可得,通过在基线模型上分别单独添加双向时序增强模块、多交互类型建模模块、多头注意力特征融合模块效果都是有提升的,提升约1.8个百分点。若同时引入其中的两种模块则可以提高约2 个百分点,说明这些模块两两间是相互促进的,并不会抑制干扰。若将三种模块同时使用,则效果最佳,性能为25.81%,提升约2.8个百分点,这也是本文所采用的最终的模型架构。因此,通过上述消融实验,可以得到本文模型使用的各模块都是有效的,对人物交互检测任务都存在促进作用,相互间不存在干扰。
本文采用了多头注意力Transformer 编码器进行特征的融合,为了确定合适的特征融合次数,进行了消融实验,实验结果见表4。

表4 多头注意力融合消融实验结果
其中,N是图1中Transformer 编码器的数目,经实验可得多次进行特征融合可以增强人物交互动作识别的准确度,当融合次数为3 时,性能最佳为25.81%,相较于单个多头注意力融合提升了0.95 个百分点,这是因为当第一次进行特征融合后,可能无法准确推断出交互动作类别,但在第二次或更多次特征融合时,已经对上次的多交互类型特征、人物空间位置特征和双向动作时序特征进行了融合,交互信息得到了增强,进而提高了交互动作的检测能力。此外,并不是融合次数越高,模型性能越好,原因是更多的融合次数会引入更多的网络参数,增大计算成本,降低模型的训练速度,可能引起过拟合而导致性能下降。
4 结语
本文针对视频中人物交互动作的检测任务进行研究,交互动作在时序上存在关联性,因此,本文设计了双向时序增强模块以存储时序特征并进行唯一映射,丰富了视频帧的特征空间,解决了交互时长较短的动作的检测效果差的问题。此外,构建了多交互类型模块以针对性的自适应实现人与人交互和人与物交互的建模,提高了检测精度和速率。还引入了Transformer编码器对特征进行融合增强,提高检测精度,并且具有全局性人物关系位置信息,解决了非接触式的交互动作的识别问题。最后通过多组对比实验和消融实验证明了模型的有效性并且有较大的性能提升。该研究可对监控视频下人物交互行为进行智能化检测,提高安防水平,达到实际应用价值。
