关联语义和对比语义指导注意力的小样本学习
2023-06-25谢少军袁鑫攀曾志高
谢少军 袁鑫攀 曾志高


摘 要:小样本学习的核心问题是将学习过程中不可靠的经验风险最小化,优化这一问题的关键是在学习过程中如何获取蕴含在少量样本中更多的先验知识,以使得模型最终获取的特征更加准确和稳定。为了充分挖掘先验知识,文章提出了关联语义和对比语义联合的注意力机制,来指导模型在视觉特征中更好地学习和区分共性与个性。对比实验和消融实验证明,文中这种注意力指导机制提升了模型的性能,尤其在5way-1shot的情况下,模型达到了最优。
关键词:小样本学习;注意力机制;多模态;关联语义;对比语义
中图分类号:TP18;TP391 文献标识码:A 文章编号:2096-4706(2023)10-0088-04
Abstract: The core problem of small sample learning is to minimize the unreliable empirical risk in the learning process. The key to optimizing this problem is how to obtain more prior knowledge contained in a small number of samples during the learning process, in order to make the final features obtained by the model more accurate and stable. In order to fully explore prior knowledge, this paper proposes an attention mechanism that combines associative semantics and contrastive semantics to guide the model in better learning and distinguishing commonalities and personalities in visual features. Comparative experiments and ablation experiments have shown that this attention guidance mechanism proposed in this paper improves the performance of the model, especially in the case of 5way-1shot, the model reaches its optimal performance.
Keywords: small sample learning; attention mechanism; multi-modal; associative semantic; contrastive semantic
0 引 言
目前的深度学习模型从大量带标签的基类数据集中学习后,在面对属于基类样本的分类测试中,其性能已经非常优秀了,甚至在ILSVRC(ImageNet Large Scale Visual Recognition Challenge)比赛中超过了人类平均水平(例如:ResNet[1])。然而,当模型在面对从未见过的类别(新类)样本时,特别是在这类样本数量非常少,不足以提供丰富的信息支持模型训练时,此时模型表现的分类能力就显得不尽人意。
但对比于人类学习,以一个学龄小孩为例,他只需要在原有知识储备基础上,通过几个样本就能学会一个知识点。例如:当小孩在学会加法运算之后,通过几个简单的乘法例
子,就能领悟乘法运算(如:2×3=2+2+2,1×3=1+1+1)。还如:当给小孩一张陌生人照片,小孩可以很容易从一些人像照片中快速识别出这个陌生人是否包含其中。
上述两个例子体现了目前深度学习与人类学习在学习过程中样本数量这个因素上之间的差距,为了缩小这种学习能力的差距,计算机视觉领域提出了小样本学习(Few-ShotLearning, FSL)来研究和模拟这种行为。小样本学习旨在预训练模型的基础上,通过对新类的少量样本进行学习后,获得这些新类的丰富特征,以便进行下游任务,例如分类任务。这种研究是非常具有应用价值的,并且也非常符合現实生活场景,因为有些类别样本存在伦理、安全、法律、隐私等各种因素难以获取。
为了缩小模型与人类的学习能力差距,计算机视觉领域提出了小样本学习(Few-ShotLearning, FSL)来研究和模拟这种行为。现在的小样本学习大都是将预训练模型学到提取特征的能力转移到没见过的新类别上来,即都是考虑如何将先验知识从基类转移到新类上,Wang[2]指出这种转移在小样本情景下是不可靠的经验风险最小化过程。为了缩小这种不可靠性,Yang提出了SEGA[3]机制,认为语义先验知识在人类学习中也起着关键作用,于是提出了基于类标签的语义注意力指导模块,来指导视觉特征,以便获得更加准确的特征。
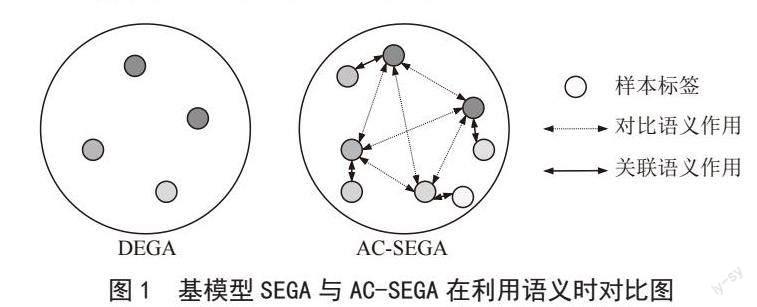
但家长在教孩子认识新类别的过程中,除了对样本和样本标签做一对一的语义解释之外,在不同样本间,还有联系和比较等学习总结过程,例如在对动物进行学习时,会比较和联系身体、眼睛等同类属性,在对动物与植物类别学习时,会比较动物与植物的区别,使得小孩对物体是否有生命状态进行思考。因此,我们不应该忽略在学习过程中对不同物体的联系与比较过程。所以,在SEGA机制的基础上,我们提出了关联语义和对比语义指导注意力(Associative and Contrastive Semantics Guided Attention, AC-SEGA)的小样本学习。SEGA与AC-SEGA的区别如图1所示,可以看出,SEGA是单点的,离散的,没有关系的,而AC-SEGA通过丰富样本标签,形成了关联的,有联系的语义。
综上所述,我们的贡献主要有以下几点:1)提出了关联语义和对比语义联合的注意力机制来指导小样本学习;2)设计了关联语义和对比语义的语义特征提取器;3)模型在两个著名的小样本学习训练集上性能表现突出。
1 近期相关工作
从如何优化模型训练时不可靠的经验风险最小化过程,以及利用先验知识的不同方式,近期工作可以分为三类,分别是对模型进行改进,对算法进行优化以及引入多模态信息。
在模型改进方面,目前关于嵌入/度量学习研究比较热门,在嵌入/度量学习中,通过将样本嵌入到低维空间中,使得相似的距离近,不相似的距离远。比较典型的三种网络结构为MatchNetwork及其变种[4,5]、Prototype Network及其变种[6,7]和RelationNetwork[8]。在此基础之上,有的还通过注入各种注意力机制或以任务为导向来改进模型[9,10]。我们的方法在学习视觉特征层面属于这一类型。
在优化算法方面,大都是基于随机梯度下降算法(Stochastic gradient descent, SGD)演化而来。目前比较热门的是基于模型未知的元学习(Model-Agnostic Meta-Learning, MAML)及其变种[11,12]。不像经典的学习范式,在计算损失后通过求梯度对模型直接更新,MAML有两次更新,可以把第一次认为是临时模型参数更新,第二次则是对模型的参数更新。我们方法中的元学习属于这一类型。
近年来,随着多模态融合和自然语言处理的发展,将语义这一模态融入小样本学习也非常火热。AM3[13]使用标签嵌入生成语义原型,用于与视觉原型进行融合,形成最终的类表示。此除了来自语言的语义知识外,还可以从知识图(如NEIL[14]、WordNet[15]等)中获得的先验知识。我们的方法因为融入了标签语义性这一模态,所以也属于这一类别。
2 方 法
2.1 符号描述与小样本问题定义
Dbase表示预训练模型的数据集,它的每个类包含了大量样本;Dnovel表示元学习阶段的数据集;Dtest表示测试数据集;这些数据集分别對应的标签集合为C base、C novel和C test,其约束条件为C base ∩ C novel ∩ C test=?。在小样本学习过程中,模型的输入是以任务(Task)为单位的,用T={T base, T novel, Ttest}中的元素分别表示从训练集,验证集和测试集中抽样得到的任务集合,其中任务Ti ={S, Q},S表示这个任务的训练集或支持集(supportset),Q表示这个任务的测试集或查询集(query set)。,n表示从对应数据集中任取n个类别,k表示在对应类别中任取k个样本,通常在小样本学习的任务配置中,n与k的取值都非常小,例如n=5、k=1or5,这种配置被称为n-way k-shot。Q表示在S对应的n个类别中随机抽取的一些样本。
小样本学习过程为首先在Dbase数据集上进行主干模型进行预训练,公式为:
其中,Θ0表示预训练模型参数,?表示交叉熵损失函数。然后再在Dnovel数据集上进行元学习,公式为:
其中,Θ表示元学习阶段学到的参数。最后小样本学习问题可以定义为元学习者在对从未见过的新类别的分类映射能力,即:fΘ:{S, Q}∈T test?C test。
2.2 语义联系与语义对比的标签构建
对于S中的样本,在SEGA基础上分别找标签的一个上义词和一个随机噪声词进行样本标签扩充。上义词指的是标签所从属的类别词,例如老虎属于动物,则老虎的上义词即为动物。这样,,其中ylabel、yassociative和ycontrastive分别属于样本x的原类别标签,上义词标签和噪声标签,这样(ylabel, yassociative)就形成了语义联系标签对,(ylabel, yassociative)就形成了语义对比标签对。我们使用WordNet这个工具来对标签进行构建,然后使用Glove[16]语义嵌入模型将一个标签对转换为对应语义向量Slabel、Sassociative、Scontrastive。
2.3 语义联系与语义对比的特征提取
对于一个样本语义信息,我们分别设计两个多层感知机(MLP)来分别对(ylabel, yassociative)与(ylabel, ycontrastive)提取语义特征。MLP是由全连接层,Leak ReLU激活函数层,Dropout层,全连接层和Sigmoid层组成,最后Sigmoid层使得输出的每个维度都在[0, 1]之间。S1=MLP([Slabel, Sassociative])∈Rs,S2=MLP([Slabel, Scontrastive])∈Rs,最终的语义向量通过对这两个向量取均值得到,即:S=(S1+S2) / 2 ∈ Rs。
2.4 语义特征与视觉特征融合
对于一个样本图像信息,我们使用卷积神经网络来对x提取视觉特征V,即。V=Conv(x) ∈ Rv=Rs。这样当语义特征S与视觉特征V都获取到后,将两者通过Hadamard积运算,得到该样本的最终特征Feat=S?V。模型框架图如图2所示,在关联语义和特征语义特征提取器中(Associative and Contrastive Semantic feature extractor),左边从上到下分别是关联语义词向量和对比语义词向量。“?”表示向量相加,“?”表示向量做Hadamard积,“cos”代表余弦分类器。
3 实验分析
3.1 数据集描述
miniImageNet数据集是ImageNet数据集子集,从中随机抽取100个类别,每个类包含600张图像,按照64、16、20的类别数量分为训练集、验证集和测试集。tieredImageNet数据集也是ImageNet的子集,但它比miniImagenet更大,tieredImageNet将类别与ImageNet层次结构中的节点相对应,它共有34个大类别,其中20个用于训练(351个子类),6个用于验证(97个子类)和8个用于测试(160个子类)。它共计608个子类,而miniImageNet则为100个类。
3.2 实验过程
模型的所有实现都是在PyTorch深度学习框架下实现的,模型的所有训练和测试都是在一张NVIDIA 3060 GPU上运行的。训练分为两个阶段。第一阶段是训练主网络中提取不同特征的卷积核参数,与SEGA一样,这阶段模型训练周期是60个epoch(tieredImageNet为90个),其中每个epoch由1 000个episode组成。在第二阶段训练与标准的元学習过程一样,训练周期是20个epoch,每个epoch中包含1 000个episode。注意,在第二阶段开始训练我们提出的语义对比和语义关联注意力模块。同时,我们在训练过程中与大多数现有工作一样,采用了随机裁剪等方式来避免过拟合,期间还采用了经验学习率调度器。模型在miniImagenet数据集上两个阶段训练的损失与准确率折线图如图3所示。
4 实验结果
表1和表2数据都是在5 000 episodes的测试阶段中,对新类的分类平均准确率(%)。“Semantic列”代表模型是否加入了语义,“base”代表基模型。
4.1 对比实验
我们分别在miniImagenet数据集和tieredImageNet数据集上进行了大量的实验,实验表明我们的结果都优于我们的基模型SEGA,尤其在5way-1shot情景下,我们的模型性能达到了最优。实验数据如表1所示。
4.2 消融实验
我们也在miniImagenet数据集上进行了消融实验,通过控制变量法,分别在只有语义关联、只有语义对比和两者都有的情况下进行了从5way-1shot到5way-5shot的实验,实验数据如表2所示。
4.3 实验总结
通过对比实验数据可以发现,加入关联语义和对比语义的注意力指导小样本学习模型在性能上提升比较大。而通过消融实验数据可以看到,在仅只有关联语义或仅只有对比语义的注意力指导情况下,模型性能表现效果不如基模型。这说明我们加入的这两种语义是在一起叠加相互后,使得模型最终性能提升。另外,从消融实验结果来看,随着shot值增加,即同一类样本数增加,准确率的增长率越来越慢,这说明随着视觉样本数增加,模型在视觉层面获取的可分类特征越来越准确,语义指导作用慢慢减弱,但在1shot或2shot情况下,语义指导是非常有用的。
5 结 论
在本文中,我们通过分析认为人类在学习新概念时,关联和对比能力非常重要,因此提出了关联语义和对比语义联合的注意力机制来指导视觉特征学习。与基模型仅引入样本标签这种单点语义不同,我们对样本的标签做了扩充,构造了关联语义和对比语义标签,设计了对应的语义特征提取器,然后将语义特征与视觉特征融合来进行分类任务,通过对比和消融实验可以得出,我们加入的关联语义与对比语义在联合作用下,使得模型的性能得到了提升,从而证明了我们提出的机制有效性。
参考文献:
[1] HE K M,ZHANG X Y,REN S Q,et al. Deep Residual Learning for Image Recognition [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Las Vegas:IEEE,2016:770-778.
[2] WANG Y Q,YAO Q M,KWOK J T,et al. Generalizing from a Few Examples: A Survey on Few-Shot Learning [J].ACM Computing SurveysVolume,2021,53(3):1-34.
[3] YANG F Y,WANG R P,CHEN X L. SEGA: Semantic Guided Attention on Visual Prototype for Few-Shot Learning [J/OL].arXiv:2111.04316 [cs.CV].[2022-11-28].https://arxiv.org/abs/2111.04316.
[4] VINYALS O,BLUNDELL C,LILLICRAP T,et al. Matching Networks for One Shot Learning [J/OL].arXiv:1606.04080 [cs.LG].[2022-11-29].https://arxiv.org/abs/1606.04080v1.
[5] CHOI J,KRISHNAMURTHY J,KEMBHAVI A,et al. Structured Set Matching Networks for One-Shot Part Labeling [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City:IEEE,2018:3627-3636.
[6] SNELL J,SWERSKY K,ZEMEL R. Prototypical Networks for Few-shot Learning [J/OL].arXiv:1703.05175 [cs.LG].[2022-11-28].https://arxiv.org/abs/1703.05175.
[7] LAENEN S,BERTINETTO L. On Episodes,Prototypical Networks,and Few-Shot Learning [J/OL].arXiv:2012.09831 [cs.LG].[2022-11-29].https://arxiv.org/abs/2012.09831.
[8] SUNG F,YANG Y X,ZHANG L,et al. Learning to Compare: Relation Network for Few-Shot Learning [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake:IEEE,2018:1199-1208.
[9] HOU R B,CHANG H,MA B P,et al. Cross Attention Network for Few-shot Classification [J/OL].arXiv:1910.07677[cs.CV].[2021-12-17].https://arxiv.org/abs/1910.07677v1.
[10] HONG J,FANG P F,LI W H,et al. Reinforced Attention for Few-Shot Learning and Beyond [C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Nashville:IEEE,2021:913-923.
[11] FINN C,ABBEEL P,LEVINE S. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks [J/OL].arXiv:1703.03400[cs.LG].[2022-11-29].https://arxiv.org/abs/1703.03400v1.
[12] YE H J,CHAO W L. How to Train Your MAML to Excel in Few-Shot Classification [J/OL].arXiv:2106.16245[cs.LG].[2022-11-30].https://arxiv.org/abs/2106.16245v3.
[13] XING C,ROSTAMZADEH N,ORESHKIN B N,et al. Adaptive Cross-Modal Few-Shot Learning [J/OL].arXiv:1902.07104 [cs.LG].[2023-02-08].https://arxiv.org/abs/1902.07104.
[14] MITCHELL T,COHEN W,HRUSCHKA E,et al. Never-Ending Learning [C]//Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence. Austin:AAAI Press.2015:2302–2310.
[15] MILLER A G. WordNet: A Lexical Database for English [J].Communications of the ACM,1995,38(11):39-41.
[16] PENNINGTON J,SOCHER R,MANNING C. Glove: Global Vectors for Word Representation [C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP).Doha:Association for Computational Linguistics,2014:1532-1543.
作者简介:谢少军(1995—),男,汉族,湖南衡阳人,硕士研究生在读,研究方向:计算机視觉、小样本学习。
