基于机器视觉的啤酒金属盖表面缺陷检测方法
2023-06-15金怡君李振宇杨絮
金怡君,李振宇,杨絮
(1.常州大学怀德学院,江苏 靖江 214500;2.江南大学,江苏 无锡 214122;3.南京理工大学,南京 210014)
啤酒瓶金属盖是酒品包装中重要组成部分,金属盖图案与结构的完整性,是消费者对产品质量的直观判别依据之一。但受瓶盖制造设备以及工艺等因素的制约,成品盖往往会包含一些缺陷,如:污渍、划痕、破损、形变等[1-2]。若含有包装缺陷的产品进入流通环节,势必会造成品牌形象下滑,加大企业的维护投入[3]。因而需借助缺陷检测手段对金属盖表面进行检测,确保产品包装的完整性,提高产品的竞争力。
目前,瓶盖缺陷检测多采用传统人工和机器视觉2 种方式。人工方式工作强度大、检测效率偏低且成本较高,无法满足自动化快速检测的需求[4]。基于机器视觉的检测技术不仅能够弥补人工检测方式的不足,缺陷检测的准确性和效率有了一定的提升,但其检测部分所用的算法模型仍存在一些不足,如:计算量大,参数较多,模型结构灵活性差[5];大规模训练样本难以实施,不适合规模化工业使用[6];小目标检测精度较低[7],导致整体识别准确率不高,无法满足实际检测需求。基于此,本文运用机器视觉技术,通过改进YOLO–v5 模型来完成啤酒金属盖表面缺陷的检测,从而实现缺陷目标的快速精准定位,以期进一步提升缺陷检测的效率。
1 实现方法
1.1 缺陷检测框架
根据金属盖内表面的缺陷类型、检测的精度和时间要求,设计了基于机器视觉的检测框架。结构如图1 所示。
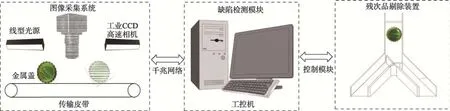
图1 基于机器视觉的金属盖缺陷检测框架Fig.1 Defect detection framework for metal cover based on machine vision
金属盖缺陷检测主要由图像采集、缺陷检测以及残次品剔除等部分构成。由采集部分的CCD 高速相机获取传输皮带上的金属盖图像,通过千兆网络将图像传输至缺陷检测检测模块。图像经平滑降噪等处理后,输入至YOLO–v5 检测模型,对金属盖表面缺陷的检测和识别。最终,工控机输出相应的信号控制剔除装置对残次品进行分流处理。
1.2 图像预处理
平滑降噪处理的目的是降低噪声对图像的干扰,避免由于图像质量偏低导致后续检测过程计算量的增加[8]。考虑到采集图像中易产生椒盐噪声以及边缘模糊现象,采用自适应中值滤波器来抑制图像噪声以及散斑,并利用高反差保留算法来强化图片的细节信息与边缘值,确保图像的感兴趣区域更为突出[9]。图2 为金属盖图像预处理结果。

图2 图像预处理结果Fig.2 Image preprocessing results
1.3 缺陷检测模型
1.3.1 YOLO–v5 网络
YOLO–v5 属于一种单阶段目标检测模型,主要包含输入端、Backbone 网络、Neck 端、Head 预测端等部分构成。网络的输入端设置有图像处理过程,用以完成图像的缩放和归一化等操作[10]。Backbone 部分采用CSPDarknet53+Focus 结构来提取高中低层的图像特征,有助于提升小目标特征信息的提取能力,还能够降低网格的敏感性。Neck 端将各层次的特征进行融合并提取出大中小的特征图,确保特征的多样性和鲁棒性。Head 预测端包含有一个分类分支和一个回归分支,通过在特征图上应用锚定框,利用GIOU Loss 反向传播更新模型的参数,最终生成包含类概率、包围框以及对象得分的输出向量[11]。YOLO–v5网络结构如图3 所示。
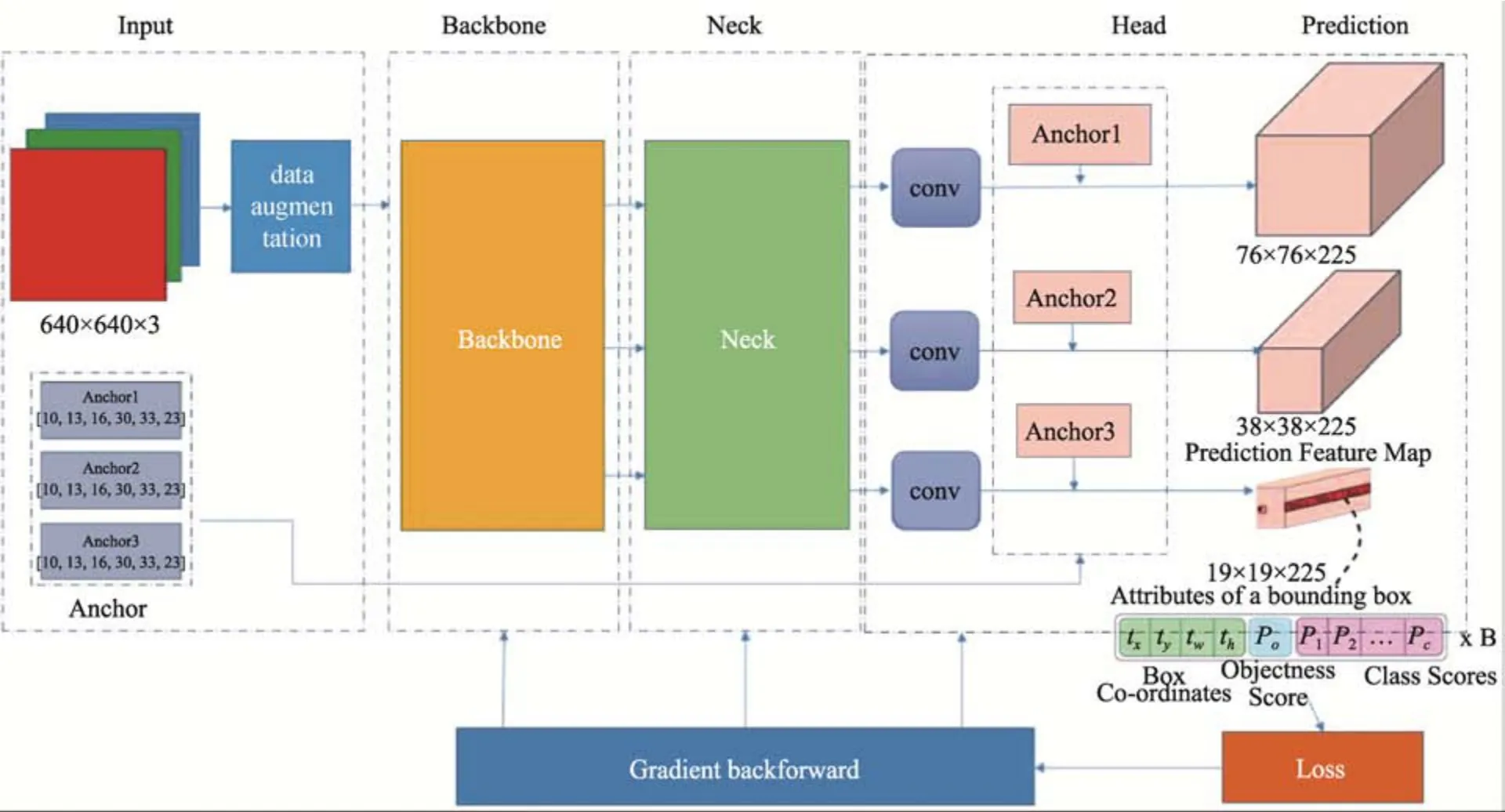
图3 YOLO–v5 网络结构Fig.3 YOLO-v5 network structure
YOLO–v5 网络初始输入为640 像素×640 像素的图像,经切片操作和卷积操作后,分别生成320×320×12 和320×320×32 的特征图。为了较好地保留图像的特征信息,卷积过程中特征图的H和W信息被集中到通道上,分别进行32 倍、16 倍和8 倍的下采样,以获取不同层次的特征图[12]。最后利用上采样和张量拼接的方式将不同层次特征图融合转化为维度相同的特征图。由于网络梯度的变化一直被集成在特征图中,避免了梯度信息的重复使用情况,使得模型参数量与FLOPS 数值有了较大幅度的降低,能够在保证识别准确率的同时,降低模型计算量,提高收敛速度。考虑到啤酒瓶金属盖存在多种尺度的表面缺陷,将像素为13×13、26×26、52×52 的特征图作为不同尺度目标回归检测的依据。
1.3.2 改进YOLO–v5 的检测模型
在实际情况中,YOLO–v5 模型对小型缺陷检测的准确率和速度并不理想。通过在主干网络Backbone 中添加注意力机制SE 模块,来抑制图像中的不重要特征,提升网络的表征能力[13]。同时,对模型的CIOU_Loss损失函数和预测框筛选方式进行改进,进一步提升小目标检测的准确率和模型的特征提取能力。
1)注意力机制SE 模块。注意力机制 SE 模块内部结构如图4 所示。

图4 SE 模块内部结构Fig.4 Internal structure of SE module
操作步骤如下:1)利用Global pooling 层对特征图(h,b,C)进行降维操作,以减少参数数量和计算量,并输出大小为1×1×C的特征图。
2)将特征图输入到包含有C/12 个神经元的FC1层进行线性变换,将特征空间映射到样本标记空间,并利用ReLU 激活函数将部分神经元的输出为0,使网络具备稀疏性,减少模型参数的相互依存关系[14]。特征z经全连接层FC2 变换以及Sigmoid 函数激活后,可得到大小为1×1×C的归一化权重因子s,其表达式见式(1)。
式中:σ为Sigmoid 激活函数;δ为ReLU 激活函数。
3)利用权重因子计算原始特征图各通道J= [j1,j2,…,jc]的 权 重 ,对 应 的 输 出 为Y= [y1,y2,…,yc]。元素yc的计算表达式见式(2)。
输出特征所对应的权重值表达了不同通道的重要程度。模型训练过程中,通过注意力机制SE 模块来加大重要特征通道的权值,减小非重要特征通道的权值,从而来提升模型的特征表达能力和图像识别准确率。
2)改进损失函数。YOLO–v5 采用GIoU Loss 损失函数来计算预测框(Predicted Box,PB)和真实框(Ground Truth,GT)之间的距离。GIoU Loss 具备尺度不变性的特点,不再考虑两矩形框相似性与空间尺度之间的关系,解决了不重叠条件下两框距离远近的判断问题[15]。当预测框或真实框被对方覆盖时,GIoU Loss 则会退化为IoU Loss,计算过程过于依赖IoU 项,致使模型的收敛速度变慢,预测精度偏低。CIoU Loss 函数由于考虑了矩形框的相对比例、IoU以及中心点距离等多项指标,不仅能够处理两矩形框距离远近的问题,还能够避免GIoU Loss 可能发生的退化问题。因此,文中的YOLO–v5 检测模型选用CIoU Loss 作为损失函数。图5 为CIoU 示意图。

图5 CIoU Loss 边框示意图Fig.5 Diagram of CIoU Loss border
CIoU Loss 中的相对比例指标用于惩罚预测结果与真实框不一致的情况。该惩罚项的定义见式(3)。
则CIoU 损失可表达为式(4)。
式中:κ2()表示求欧式距离;U为交并比;e、e′分别为 PB 框和 GT 框的中心点;c为两矩形框闭包区域的对角线长度;a为权重系数;μ为两矩形框长宽比的一致性参数,包含了要预测的b和h。a、μ的计算表达式见式(5)。
式中:b、h为PB 框的宽和高;b′、h′为GT 框的宽和高。
3)GA–Kmeans 算法调整锚框大小。卷积神经网络的特征图感受野随网络深度的增加而逐渐变大,其内部的像素点直接影响特征信息的输出。选择大小合理的Anchor 可有效提升模型检测召回率[16],如图6 所示。

图6 不同特征层感受野对比Fig.6 Comparison of receptive fields in different feature layers
Anchor 通过计算Bboxes 与Anchor 之间平均欧氏距离而得出。YOLO–v5 模型设计有多个不同大小和宽高比的Anchor,对各特征层级上不同尺度目标进行定位,但这些依靠人工设计的Anchor 无法保证很好地适应数据集。当Anchor 框的大小与目标尺寸存在较大差异时,会导致模型计算量增加,检测准确率偏低[17]。因此,本文采用GA–Kmeans 算法对训练集的Bounding box 进行聚类,继而自动生成一组更为适应当前数据集的Anchor,以确保网络具备更好的检测效果。
GA–Kmeans 聚类过程如下:
1)提取所有Bounding box 坐标,并将坐标数据转换为框的宽高大小。
2)随机选取k个Bounding box 作为Anchor 的初始簇中心,运用 1–IOU(Bboxes, Anchors)方法计算Bboxes 与每个簇之间的距离,并分配至距离它最近的簇中。
3)根据簇中的Anchors 数量,利用中值方法重新计算每个簇中的中心。
4)重复第2 步和第3 步操作,一直到各簇中的元素不再发生改变,即可获取k个宽、高组合的Anchor boxes。
5)运用GA 算法对Anchors 的高、宽进行变异操作。对变异后的Anchors 进行适应度评估,若变得更好,则将变异后的结果赋值给Anchors。反之,则跳过。
6)将变异操作得出的最优Anchors 按面积进行排序并返回。当k=3 时,Anchors 聚类过程如图7所示。

图7 Anchors 聚类过程Fig.7 Anchors clustering process
2 实验与分析
2.1 实验准备
2.1.1 运行环境及参数设置
使用Pytorch 深度学习平台来完成改进YOLO–v5网络的训练和测试,测试平台:酷睿™I9–12900K 中央处理器,美国INTEL 公司;GeFORCE RTX3090TI显卡,美国NVIDIA 公司;DDR5 5200 32G×2 内存,美国Kingston 公司;操作系统Ubuntu22.04,编程语言Python。为确保实验过程的合理性,将COCO 数据集上的预训练结果作为检测模型的初始化参数,配置情况如表1 所示。
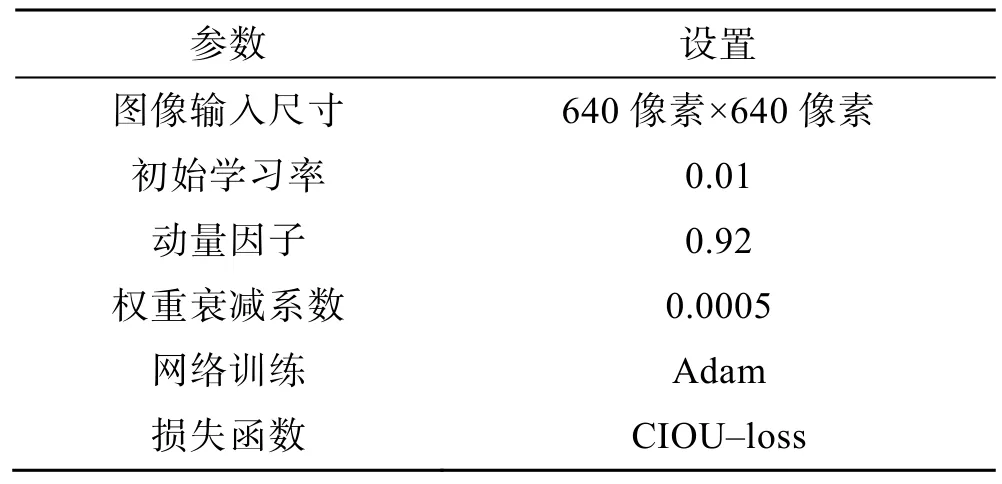
表1 训练参数及设置Tab.1 Training parameters and settings
2.1.2 样本集和评估指标
在某啤酒加工厂采集了2 595 张金属盖图像,经Labelimg 工具标注后,得到包含正常、污渍、破损、形变、划痕等5 种特征的样本集,并按8∶2 的比例随机划分为训练集和测试集。部分缺陷样本如图8 所示。样本划分情况见表2。

表2 金属盖样本数据划分Tab.2 Metal cap sample data division

图8 部分包含缺陷的数据样本Fig.8 Data samples partially containing defects
为了确定最优模型,将查准率(Precision)、召回率(Rcall)、平均检测精度(mAP)作为目标检测模型性能的评估依据,并将缺陷检测的准确率和用时作为整套方案的评价标准。
2.2 消融实验
为了验证文中针对YOLO–v5 改进项的有效性,利用数据集展开消融实验。在初始YOLO–v5 的基础上,通过使用CIoU Loss 函数,添加注意力机制SE模块以及经过GA–Kmeans 调整后的锚框逐步替代原网络的相关项,以检验各改进项对网络性能的影响。图9 为消融试验可视化结果的对比情况。

图9 消融试验可视化对比Fig.9 Visual comparison of ablation tests
由表3 可知,未改进YOLO–v5 模型的Precision、Rcall 以及mAP 指标相对较低。在修改损失函数并添加注意力机制SE 模块后,各项指标均有了一定的提升。但相较于SE 模块,CIoU Loss 的目的是提升预测框回归的速度和精度,对各项指标的提升较小。添加SE 模块目的在于进一步提升模型对特征的提取能力,因而各项指标提升较为明显。最终改进后模型的Precision、Rcall以及mAP 指标较于改进前分别提高了3.20%、2.31%、3.67%,表明文中改进项具备一定的合理性和有效性。

表3 多改进消融实验结果Tab.3 Result of multiple improvement ablation tests
2.3 不同模型检测结果对比
为了进一步验证文中检测模型的性能,分别选用Faster R–CNN、文献[5]、文献[6]的检测模型以及YOLO 系列模型分别在同一数据集上进行实验。对比各模型的检测精度、检测速度以及准确率。图10 为各模型可视化结果。

图10 不同模型检测结果对比Fig.10 Comparison of different model test results
由图10 可看出,改进的YOLO–v5 模型具备良好的特征提取能力,多目标检测能力突出,尤其在面对形变和破损缺陷时,检测精度较高,而其他检测模型的精度相对较低,存在目标特征提取不完整和部分缺陷无法检测的情况。表4 和表5 分别为不同模型的检测速度、平均精度以及缺陷识别的准确率情况。

表4 不同模型性能对比Tab.4 Performance comparison of different models

表5 检测准确率对比结果Tab.5 Detection accuracy comparison results
综合表4 和表5 可知,本文改进的YOLO–v5 模型各项性能指标均优于其他目标检测模型,检测速度达到了294 张/min,mPA 值相较于Faster R–CNN、文献[5]、文献[6]、YOLO–v4、YOLO–v5 等模型分别提升了13.95%、4.78%、3.87%、7.13%、5.19%。同时,改进后的YOLO–v5 模型针对不同类型的缺陷,均有较高的检测准确率。表明经改进后的YOLO–v5模型具备较高的检测精度,且漏检率较低,能够进一步提升金属盖表面缺陷的识别准确率。
3 结语
1)设计了基于机器视觉的缺陷检测框架,通过添加注意力机制SE 模块、改进损失函数和预测框筛选方式等技术手段对原YOLO–v5 模型进行优化。消融实验结果表明,改进后检测模型的Precision、Rcall以及mAP 指标相较于改进前分别提升了3.20%、2.31%、3.67%;小目标漏检率较低,整体识别准确率提升明显。
2)优化的YOLO–v5 模型各项性能指标均和识别准确率均优于目前常用的检测模型,检测速度为294 张/min,满足实时检测需求;mPA 指标相较于Faster R–CNN、文献[5]、文献[6]、YOLO–v4 和YOLO–v5 等模型分别提升了 13.95%、4.78%、3.87%、7.13%、5.19%,模型的检测精度较高;模型体积仅为61.08 MB,具备良好的移植潜力。
3)针对瓶盖污渍、破损、形变、划痕等不同类型的缺陷,所设计模型的检测准确率分别93.18%、94.24%、93.39%、87.97%,能够满足实际生产过程中的检测需求。
