基于改进YOLOv5s 模型纸杯缺陷检测方法
2023-06-15蒋亚军曹昭辉丁椒平文煜超张闯胡志刚
蒋亚军,曹昭辉,丁椒平,文煜超,张闯,胡志刚
(1.武汉轻工大学 机械工程学院,武汉 430048;2.湖北克拉弗特实业有限公司,武汉 430048)
随着我国工业技术进入数字化、智能化的新发展阶段,大量工业企业实现智能化技术,越来越多的工业检测设备与机器视觉技术相结合[1-3]。早期的纸杯缺陷检测任务主要依靠人工筛选和基于传统图像处理技术的检测方法完成。人工筛选存在漏检、效率低、主观随意性大等缺点,已无法满足现代生产需求[4]。传统检测方法在提取特征过程中需要进行灰度化、二值化等一系列预处理操作,过程烦琐,难以满足实际生产需求[5]。
传统检测方法的流程分为输入图像、区域选取、提取特征、分类器、后处理以及最终检测结果6 个阶段[6]。王宇轩等[7]通过OpenCV 的边缘检测和形态学处理等算法实现了纸杯污渍缺陷检测。高雅等[8]通过对输入图像进行预处理、定位等流程,实现了杯底破洞、杯口变形、杯底油污的缺陷检测。此类检测方法受其检测原理的影响,对检测环境的光照条件要求较高,容易对小尺寸和特征不明显的纸杯缺陷出现漏检和错检现象。小尺寸缺陷是指以小点或细短线形式出现的油渍,特征不明显缺陷主要是指痕迹较浅的缺陷形式,例如压痕较轻的褶皱、不明显的翘边以及轻微的破损等缺陷。
相比传统检测方法,深度学习技术只需构造卷积神经网络,就可实现对图像特征的主动学习,完成特征提取,且具有更好的鲁棒性和检测精度[9]。目前,深度学习的目标检测算法分为双阶段检测和单阶段检测2 类算法[10]。双阶段检测算法以R–CNN[11]、Fast R–CNN[12]、Faster R–CNN[13]为代表,具有检测精度高、漏检率低等优点,但存在检测速度慢、计算量大等问题,难以应用于实时检测。单阶段检测算法以SSD[14]、YOLO 系列算法[15]为代表,具有检测速度快、计算量少等优点,能够满足实时检测的需求,但检测精度逊于双阶段目标检测算法[16]。随着单阶段目标检测算法的不断优化,其检测精度已得到了很大改善。
综上所述,本文以YOLOv5s 模型为基础模型进行相关研究改进。首先,在Backbone 部分中引入CBAM 注意力机制模块,增强模型对纸杯缺陷特征的提取能力;其次,在模型中增加一层尺度为160×160的浅层检测层,将三尺度检测改为四尺度检测,提升模型的检测能力;最后,在Neck 部分借鉴加权双向特征金字塔网络BiFPN,对原始模型中的PANet 进行部分改进,提高模型的特征融合能力。
1 YOLOv5 介绍
YOLOv5 算法是Ultralytics 团队提出的一种典型One Stage 目标检测算法,该算法可通过修改深度和宽度倍数实现对模型大小的调整,兼顾了检测精度和速度,具有检测精度高、推理速度快等特点[17-19]。从YOLOv5 算法提出至今,版本一直在更新迭代。本文选用v6.0 版本,根据其模型深度和权重的大小可分为5 种不同版本,分别为YOLOv5n、YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x,本文以YOLOv5s为基础模型进行相关研究改进,模型的主体架构分为Input、Backbone、Neck 和Output 等4 个部分,具体结构如图1 所示。

图1 YOLOv5s 网络结构Fig.1 Network structure of YOLOv5s
相比旧版本模型,v6.0 版本模型在Backbone 部分去掉了Focus 结构,用Conv(k=6,s=2,p=2)代替,提高了模型导出效率。用SPPF 模块代替SPP 模块,在保留对不同感受野特征图的融合和表达能力情况下,进一步提高了模型运行速度。
2 YOLOv5s 改进
2.1 引入CBAM 注意力机制模块
为了提高模型对纸杯缺陷特征的提取能力,改善在复杂环境下缺陷特征的表达能力。本文在原始模型中引入CBAM[20]注意力机制模块,其结构如图2 所示。
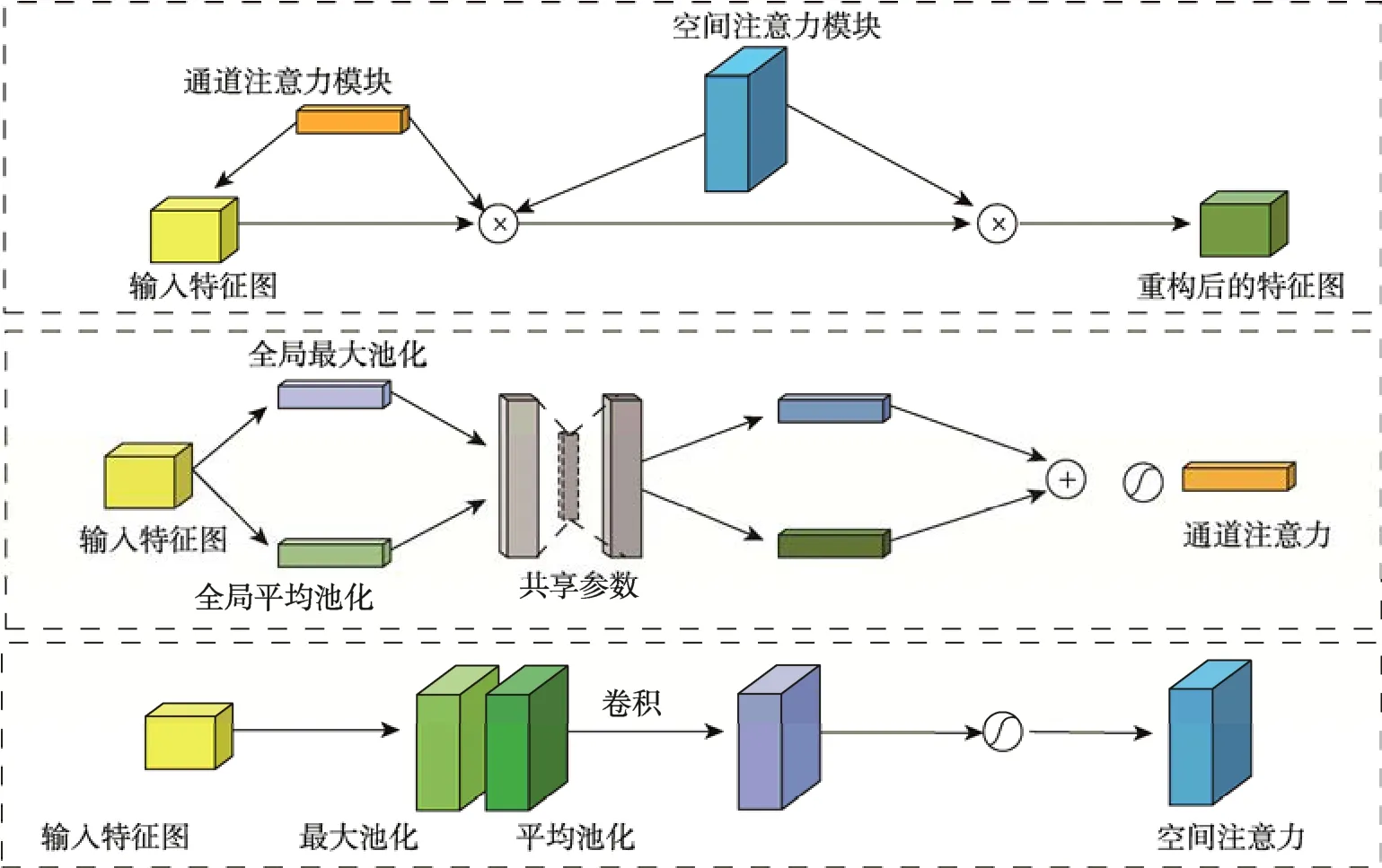
图2 CBAM 注意力机制模块结构Fig.2 Module structure of CBAM attention mechanism
由图2 可知,CBAM 注意力机制由通道注意力模块和空间注意力模块组成。通道注意力模块对输入特征图按其宽和高2 个方向进行全局最大池化和全局平均池化,将得到的2 个1×1×c特征向量送入一个2 层神经网络,共享参数后进行加和操作,并对输出结果进行Sigmoid 归一化处理,最终得到通道注意力特征。空间注意力模块是将经过通道注意力模块得到的特征图作为输入特征图,并按其通道方向进行全局最大池化和全局平均池化。将得到的2个H×W×1 特征图在通道方向上进行Cancat 操作,压缩通道个数至1,再经Sigmoid 归一化处理获得空间注意力特征。
通过以上对通道和空间注意力模块的分析,可以发现通道注意力模块重点关注检测目标的内容信息,空间注意力模块重点关注检测目标的位置信息。通过两者结合,可使输出特征信息聚焦于重点特征信息,提高模型的检测精度。由于YOLOv5s 模型依靠C3模块进行特征提取,图片中所包含的细节特征信息会随C3 模块数量的增加逐渐丢失。所以为了弥补细节特征信息的丢失和加强其在特征图中的表达权重,本文在Backbone 部分中的最后一层C3 模块后面引入CBAM 注意力机制。将改进后的模型命名为YOLOv5s–C,具体改进结构如图3 所示。

图3 加入CBAM 注意力机制模块后的模型结构Fig.3 Structure of the model after addition of CBAM attention mechanism module
2.2 多尺度检测的改进
YOLOv5s 模型采用20×20、40×40、80×80 等3 种不同尺度进行检测,虽然可以得到较好的检测效果,但由于不合格纸杯包含有细小和特征不明显的缺陷形式,这些细节特征信息随着模型深度的加深大幅度丢失,造成原始模型在检测时出现漏检和错检的现象。为了提高模型对细小和特征不明显缺陷的检测能力,本文在加入CBAM 注意力机制模块的基础上,将三尺度检测改为四尺度检测,增加尺度为160×160的浅层检测层,并将尺度为80×80 的检测层进行2 倍上采样与其进行特征融合,将改进后的模型命名为YOLOv5s–CX。改进后的具体结构如图4 所示。
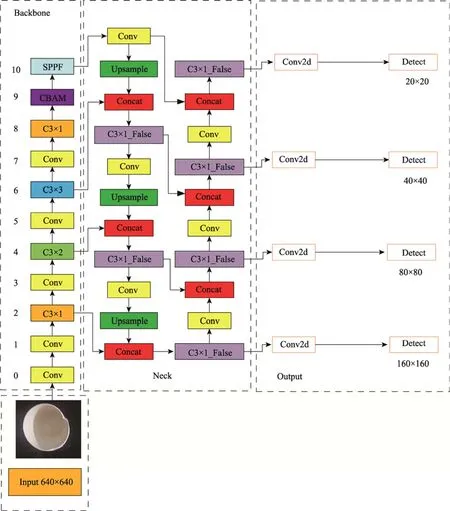
图4 改进多尺度检测后的模型结构Fig.4 Model structure after improvement of multi-scale detection
2.3 Neck 部分的改进
YOLOv5s 模型采用PANet 结构对不同尺度的特征信息进行融合,其结构如图5a 所示。可以发现PANet 通过采用由深到浅和由浅入深的双向传递路线,将深层特征层具有的高阶语义信息传递到浅层特征层,同时将浅层特征层的定位信息传递到深层特征层,保证了模型对不同尺度特征信息的融合能力。不同尺度的特征信息在融合时,对输出特征图的贡献是不均等的,PANet 没有对不同尺度的特征信息加权,只是将其不加侧重地进行相加,这就会使同一种类型但不同大小的缺陷特征对融合后的特征图产生不均等的权重。也就是说尺寸大的缺陷特征被更多地融入输出特征图,而一些细小的特征信息融入得较少,被边缘化。由于纸杯缺陷数据集中就包含有小尺寸和特征不明显的缺陷形式,所以为了改进上述原始模型存在的不足,本文借鉴加权双向特征金字塔网络BiFPN 对检测网络进行改进。BiFPN结构如图5b 所示。相较于PANet 的融合方式,BiFPN引入了加权策略。根据输入特征信息的重要性对其设置了相应的权重,可以有侧重性地调节输入特征信息在输出特征图中的贡献程度,从而实现更好的特征融合。在特征信息传递路线上,BiFPN 去掉了只有一条输入边和输出边的节点,并提出了跨尺度连接的方法。直接将特征提取网络中的特征信息与由浅入深传递路线中的特征信息进行融合,这样的传递方式可以保留更多深层的高阶语义信息和浅层的定位信息。
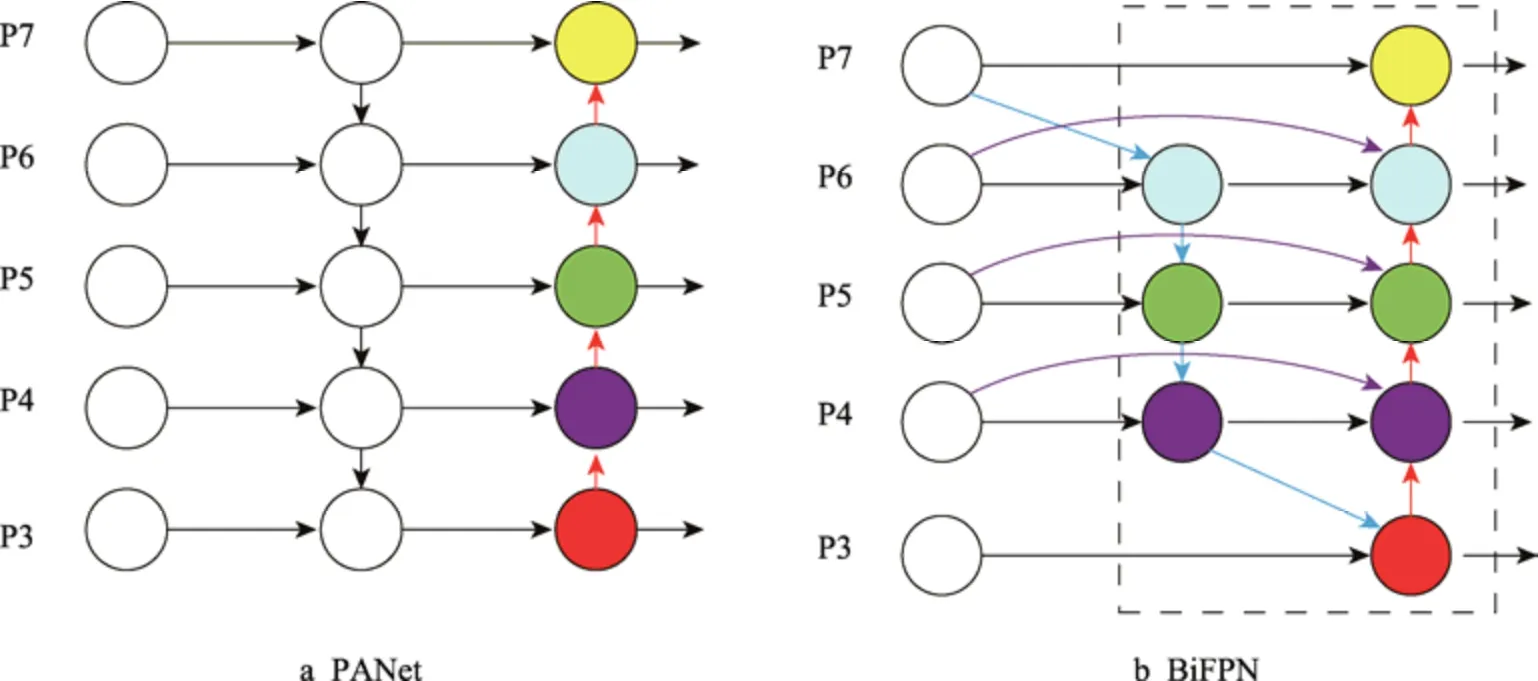
图5 PANet 和BiFPN 的网络结构Fig.5 Network structure of PANet and BiFPN
本文先将PANet 完全用BiFPN 替换,并把完全替换后的模型命名为YOLOv5s–CXF。通过实验发现,完全替换后的模型召回率低于原始模型的召回率。若在PANet 的基础上借鉴BiFPN 的加权策略和跨尺度连接方法对其进行部分改进,反而会使改进后的模型训练结果有所提升。本文分析认为:纸杯缺陷数据集的部分图片中含有不同类型的缺陷形式,且在特征表达上较为相似,例如轻微的翘边和压痕较浅的褶皱,在形式表达上较为相似。若将这种类型的图片输入到完全替换成BiFPN 的模型中进行特征融合时,特征表达相似的不同类型缺陷在每个尺度的BiFPN加权操作下,会使得模特征融合效果降低。所以本文选择在PANet 的基础上借鉴BiFPN 的加权策略和跨尺度连接方法对其进行部分改进,并把改进后的模型命名为YOLOv5s–CXO,具体改进后的模型结构如图6 所示。
3 样本数据集
由于没有专门用于纸杯缺陷检测的开源数据集,所以本文数据集针对纸杯成型过程中出现的各种缺陷形式进行制作。为提高数据集的丰富性和模型训练的泛化能力,在不同生产环境中拍摄图片。缺陷形式主要分为褶皱、破损、露底、油渍、翘边等5 类。数据集共1 000 张图片,训练数据集和测试数据集的比例为8∶2。纸杯缺陷形式采集示例如图7 所示。

图7 纸杯缺陷形式采集示例Fig.7 Example of paper cup defect form collection
将采集好的数据集进行筛选和整理,去掉不合格图片,最后对整理好的数据集使用标注软件Labelimg进行标注。数据标注示例如图8 所示。

图8 纸杯缺陷标注示例Fig.8 Example of paper cup defect labeling
4 实验结果及分析
4.1 实验数据及参数设定
本文将原始模型在coco 数据集上训练好的权重作为此次训练模型的初始权重,训练使用的数据集为以上拍摄制作的数据集,迭代次数epoch 设置为200 轮,每次迭代输入的图片数量设置为16,输入图片的大小调整为640×640,学习率设置为0.001。为了客观评判改进后模型的性能,本文采用目标检测模型常用的3 项评估指标,分别为精度(Precision,P)、召回率(Recall,R)、平均精度均值(Mean Average Precision,δmAP)来衡量检测效果[21-23],具体计算见式(1)—(4)。
式中:TP(True Positives)为被正确检测出的纸杯缺陷数量;FP(False Positives)为被检测错误的纸杯缺陷数量;FN(False Negatives)为未被检测出的纸杯缺陷数量;C为纸杯缺陷共需分类的类别数;δAP(Average Precision)为某个纸杯缺陷类别的平均精度;i为当前类别的序号。
4.2 实验结果分析
为了验证前文所述改进方法的有效性,本文将各改进方法改进后的模型训练结果进行直接对比,具体对比结果如表1 所示。

表1 各模型训练结果对比Tab.1 Comparison of training results of each model
对比表1 中模型 YOLOv5s–C 和原始模型YOLOv5s 的训练结果可以看出,模型YOLOv5s–C的召回率和每帧检测时间虽然没有发生明显变化,但精度和平均精度均值分别提高了1.1%和0.9%,可以表明引入CBAM 注意力机制模块的有效性。多尺度检测改进实验是在模型YOLOv5s–C 中增加一层尺度为160×160 的浅层检测层,提高模型的检测能力,从表1 中模型YOLOv5s–CX 与模型YOLOv5s–C 的训练结果对比可知,浅层检测层的增加使得模型YOLOv5s–CX 的精度提高了1.1%、平均精度均值提高了0.4%,表明了该改进方法的有效性。但召回率下降了0.5%,且低于原始模型的召回率。本文分析认为:浅层检测层的增加虽然提高了模型对细节特征的捕捉能力,但各尺度之间的特征融合效率没有得到改善,捕捉到的细节特征与其他尺度的特征没有进行很好的融合,造成召回率降低。Neck 部分的改进实验分为两部分,分别为将模型YOLOv5s–CX 中的PANet 用BiFPN 进行完全替换以及借鉴BiFPN 的优点对PANet 进行部分改进。对表1 中YOLOv5s–CXF 和YOLOv5s–CXO 这2 种模型的训练结果与YOLOv5s–CX模型的训练结果进行对比,可以看出YOLOv5s–CXF和YOLOv5s–CXO 这2 种模型的精度和平均精度均值均降低,且降低主要表现在精度上,2 种改进模型的精度分别降低了0.5%和0.7%。也可以看出Neck部分的改进方法都不同程度地提高了2 种模型的召回率,分别提高了0.2%和1.6%。YOLOv5s–CX 和YOLOv5s–CXF 2 种模型的精度虽然都高于模型YOLOv5s–CXO 的精度,但召回率均低于原始模型的召回率。模型YOLOv5s–CXO 召回率为90.4%,高于以上所有模型的召回率,从而表明了本文选择的Neck 部分改进方法的有效性。
综合以上各模型训练结果的对比分析,本文选择的改进模型为YOLOv5s–CXO,比原始模型YOLOv5s的精度、召回率、平均精度均值分别提高了1.5%、1.3%、1.2%。虽然每帧检测时间增加了57 ms,但仍可满足实际生产需求。改进模型的优越性主要体现在检测能力的提高。为了进一步证明模型YOLOv5s–CXO 具有更好的检测能力,本文将改进模型YOLOv5s–CXO 与原始模型YOLOv5s 的平均精度均值变化曲线进行对比,如图9 所示。

图9 2 种模型平均精度均值曲线对比Fig.9 Comparison of average precision mean curves of two models
从图9 中2 种模型曲线的变化趋势可以看出,在训练初期模型YOLOv5s–CXO 的训练值低于原始模型YOLOv5s 的训练值。但随着引入各模块发挥作用,模型YOLOv5s–CXO 的训练值逐渐提高,最终在迭代到110 轮时,超过原始模型,并一直保持高于原始模型训练值的水平。表明本文改进方法提高了模型的检测能力。以上对比分析可以证明模型YOLOv5s–CXO 比原始模型更优。
为了更加直观地验证在检测过程中模型YOLOv5s–CXO 相较于原始模型YOLOv5s 的优越性,本文将2 种模型的检测效果进行直接对比。对比效果如图10 所示。

图10 2 种模型的检测效果对比Fig.10 Comparison of detection effect between two models
从图10 中所展示的检测效果可以看出,原始模型YOLOv5s 在检测过程中对以小点和细短线形式出现的油渍,压痕较浅的褶皱、翘边以及轻微破损的检测效果较差,出现了漏检、错检现象。可以表明原始模型YOLOv5s 在检测过程中对小尺寸和特征不明显缺陷的检测效果较差,存在不足。相比之下,模型YOLOv5s–CXO 的检测效果表现较好,纠正了原始模型漏检和错检的地方,更加直观地表明了模型YOLOv5s–CXO 的优越性。尤其对小尺寸和特征不明显纸杯缺陷的检测效果,较原始模型有明显提升。
5 结语
本文为了解决小尺寸和特征不明显的纸杯缺陷在检测过程中易出现漏检、错检的问题,提出了一种基于改进YOLOv5s 模型的纸杯缺陷检测方法。该方法首先通过在Backbone 部分引入CBAM 注意力机制模块,提升了模型对纸杯缺陷特征的提取能力;其次在模型中增加了一层尺度为160×160 的浅层检测层,有效提高了模型对小目标和特征不明显目标的检测能力;最后在Neck 部分中借鉴加权双向特征金字塔网络BiFPN,对原始模型中的PANet 进行了部分改进,加强了模型的特征融合能力。实验结果表明:改进后的模型YOLOv5s–CXO 比原始模型YOLOv5s 的精度提高了1.5%、召回率提高了1.3%、平均精度均值提高了1.2%,有效提高了模型的检测能力和鲁棒性。相较于原始模型,具有更好的目标分辨能力,尤其是对小尺寸和特征不明显纸杯缺陷的检测效果有明显提升。
