基于集成机器翻译的双语平行语料无监督质量评价
2023-06-05王琳刘伍颖
王琳,刘伍颖
(1.上海外国语大学 贤达经济人文学院,上海 200083;2.广东外语外贸大学 语言工程与计算实验室,广东 广州 510420)
0 引言
语料的质量通常决定着自然语言处理算法的有效性,而大规模高质量语料本身还蕴含着知识与智能。以机器翻译这类典型的自然语言处理应用为例,早在统计机器翻译时期,高质量统计机器翻译模型的重要基础就是大规模高质量的双语平行语料[1]。但是大部分容易获得的双语平行语料往往包含噪音和谬误,它们会影响统计机器翻译模型的性能。通过人工评价筛选高质量句对费时费力,也一定程度促使语料质量自动评价研究兴起[2],继而诞生了基于词对齐的平行语料评价[3]、基于句子特征向量的伪平行句对抽取[4]等一系列方法。
随着深度学习在自然语言处理诸多领域的进步,并行向量计算部件的超强算力、支持海量细粒度特征的超深度神经网络算法、网络语言大数据提供的超大规模算料三要素共同支撑起新一代人工智能[5]。当前的科学研究以及工业应用都不同程度地受到算力和算法趋同性的影响,而算料个性化则成为支撑各种自然语言处理特色应用的重要因素。
进入神经机器翻译时期,泛在计算设备和无线网络技术大大提升了人类语言信息生产力,网络语言大数据成为超大规模算料的主要来源。网络语言大数据的非结构化、不规范、甚至可能蕴含谬误使得超大规模算料的自动质量评价显得更加重要[6]。近来,与深度学习同步推进的语料质量评价研究提出了双语句对嵌入思路[7],也有从超大规模平行语料构建视角提出混合抓取架构[8],相关研究逐渐由双语平行语料质量评估[9]向着多语平行语料构建发展[10-11]。此外,国内围绕汉语的高质量领域平行语料[12]、多语平行语料[13]以及非通用语平行语料[14]筛选构建研究也取得了一定进展。这些已有方法往往注重理论研究和实验室算法探索,对于工业级语料质量评价而言,计算代价仍然过高。
围绕时空高效的工业级语料质量评价科学问题,我们重新审视机器翻译所需的双语平行语料人工质量评价过程。无论是统计机器翻译还是神经机器翻译,双语平行语料都是极其重要的语言资源[15]。为了训练得到源语言(S)到目标语言(T)的精准机器翻译模型,往往需要大规模高质量源目句对语料(C={<SSen,TSen>})。如果只有一位精通源语言和目标语言的译员p,那么对于待评价句对<SSen,TSen>,译员p将源句子SSen 翻译成目标语言句子TSenp,接着检测TSenp与TSen 的相似度,若相似度高则判断句对<SSen,TSen>质量高,反之质量低。同理,译员p也可以将目标句子TSen 翻译成源语言句子SSenp,再通过SSenp与SSen 的相似度检测判断句对质量。如果存在多位译员p1,p2,p3,…,那么对于待评价句对<SSen,TSen>,每位译员将源句子SSen 翻译成目标语言句子TSenp1,TSenp2,TSenp3,…,并分别计算与TSen 的相似度,再集思广益综合多个相似度进行最终质量评价。
受到上述两种人工质量评价过程的启发,本文针对双语平行语料的质量,提出基于集成机器翻译的无监督质量评价思路,并从翻译方向和翻译系统两个视角充分利用同一个机器翻译系统不同翻译方向的差异以及不同机器翻译系统之间的差异,分别设计实现单引擎和多引擎集成机器翻译无监督评价框架和算法。
1 单引擎集成机器翻译无监督评价
近来,结合超大规模语料与深度神经网络的神经机器翻译引擎的译文质量几乎接近人类译员的水平[16],使得我们可以用机器翻译引擎替代人类译员实现平行语料的无监督质量评价。参考上一节单译员评价过程,本文提出调用单一机器翻译引擎的单引擎集成机器翻译无监督评价方法。
1.1 框架
如图1 所示,单引擎集成机器翻译无监督评价框架主要包括机器翻译引擎(Machine Translator)、集成质量评价器(Ensemble Quality Evaluator)和二值分类器(Binary Classifier)。机器翻译引擎接收待评价的生句对(Raw Sentence Pair)数据流,针对每个句对<SSen,TSenmt,>并行双向翻译,即将源句子SSen 翻译成目标语言句子TSenmt,同时将目标句子TSen 翻译成源语言句子SSenmt,提交译文至集成质量评价器。集成质量评价器接收生句对<SSen,TSen>和机器翻译引擎提交的相应译文<TSenmt,SSenmt>,计算得到表示SSen 和SSenmt相似程度的置信度分数c1,同时计算出TSen 和TSenmt相似程度的置信度分数c2,再集成c1和c2得到最终置信度(Confidence)分数并发送给二值分类器。二值分类器根据预设的置信度阈值(Confidence Threshold)进行高质量或低质量句对的质量评价。

图1 单引擎集成机器翻译无监督评价框架Fig.1 Single-engine-based ensemble machine translation unsupervised evaluation framework
从上述框架运行机制可知机器翻译引擎必须能够实现源语言S 到目标语言T 以及目标语言T 到源语言S 的双向翻译。而集成质量评价器中的句子相似度计算是一个抽象模块,可以根据需要采用形态相似度、句法相似度、语义相似度等进行具体实现。同时两个相似置信度分数的集成计算也是一个抽象模块,可以采用线性加权也可以加入额外规则设置权重偏置,甚至可以当成一个在线增量机器学习问题进行模型化求解。由此可见基于我们提出的框架可以设计出多种具体的算法。
1.2 算法
出于计算有效性和高效性的综合考量,我们根据单引擎集成机器翻译无监督评价框架设计了一款如算法1 所示的单引擎集成机器翻译无监督评价算法。
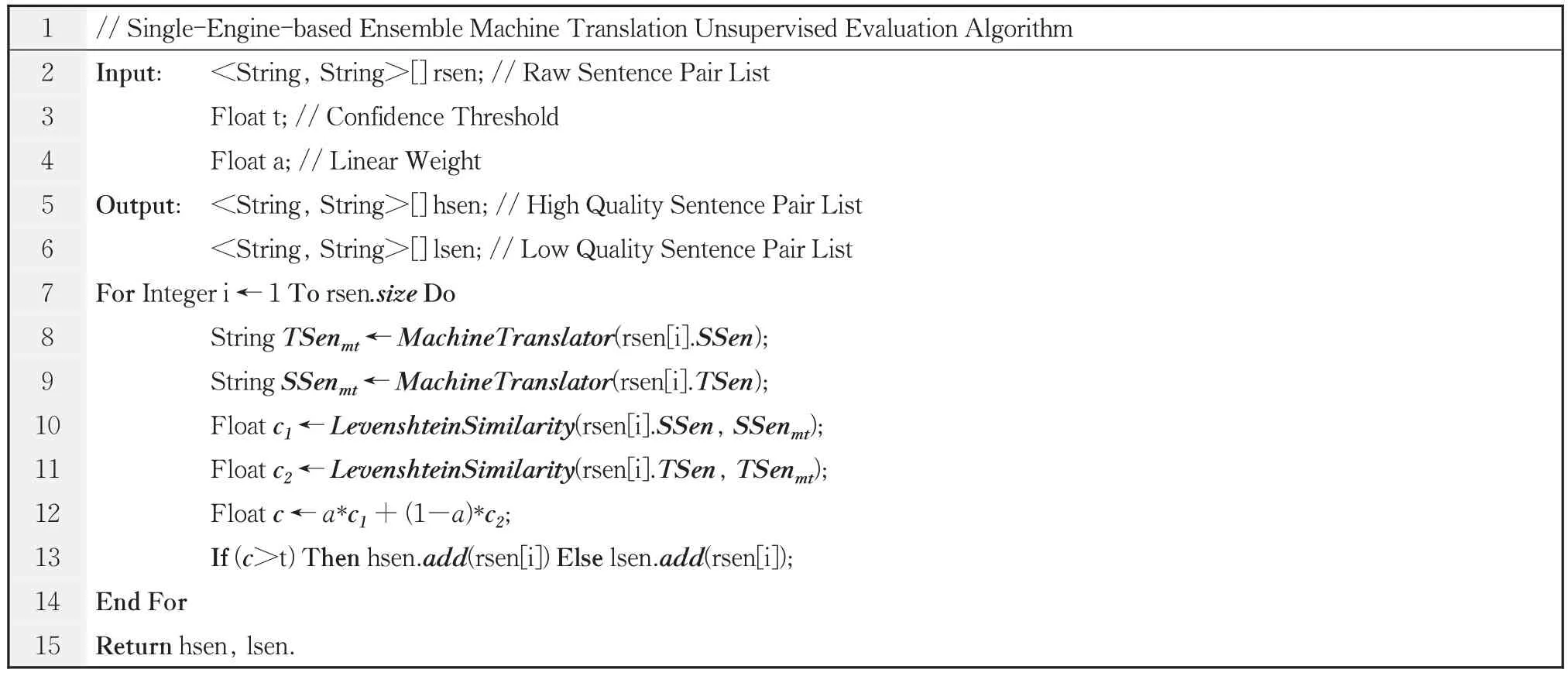
算法1 单引擎集成机器翻译无监督评价算法Algorithm 1 Single-engine-based ensemble machine translation unsupervised evaluation algorithm
该算法的输入除了待评价的生句对列表rsen 之外,还有线性权重a和置信度阈值t两个浮点型预设参数。在算法的第8、9 行需要调用双向机器翻译函数MachineTranslator。调用语言无关的莱文斯坦字符串形态相似度函数LevenshteinSimilarity实现相似置信度分数计算(第10、11 行)。在集成两个置信度分数时,采用高效的线性加权方法,预设的线性权重a能够调整源目语种语料的贡献度。最终采用预设的置信度阈值t分类得到高质量句对列表hsen 和低质量句对列表lsen。该算法时空高效且易于实现,在工业得到广泛应用。若机器翻译系统能够支持多个最优译文输出,则更趋平滑的集成结果还可以提升单引擎算法的效力。但由于单引擎算法只调用了一个机器翻译系统,因此分类结果可能过拟合该系统。如果存在多个不同的机器翻译系统,取长补短集成效果有望获得进一步提升。
2 多引擎集成机器翻译无监督评价
二人智慧胜一人,更何况多人参与的民主集中决策。参考第0 节多译员评价过程,我们提出调用多个机器翻译引擎的多引擎集成机器翻译无监督评价方法。
2.1 框架
如图2 所示,多引擎集成机器翻译无监督评价框架主要包括多个机器翻译引擎(Machine Translator1,Machine Translator2,Machine Translator3,…),一个集成质量评价器(Ensemble Quality Evaluator)和一个二值分类器(Binary Classifier)。每个机器翻译引擎接收待评价的生句对(Raw Sentence Pair)数据流,将每个句对<SSen,TSen>中的源句子SSen 翻译成目标语言句子TSenmt,提交译文至集成质量评价器。集成质量评价器接收生句对<SSen,TSen>和多个机器翻译引擎提交的相应译文TSenmt1,TSenmt2,TSenmt3,…,分别与TSen 计算得到相似置信度分数c1,c2,c3,…,再集成这些分数得到最终置信度(Confidence)分数并发送给二值分类器。二值分类器根据预设的置信度阈值(Confidence Threshold)进行高质量或低质量句对的质量评价。
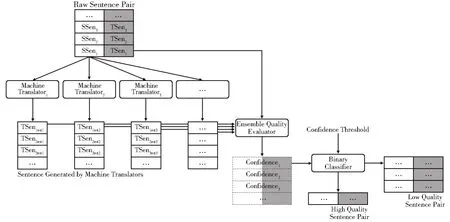
图2 多引擎集成机器翻译无监督评价框架Fig.2 Multi-engine-based ensemble machine translation unsupervised evaluation framework
框架中集成质量评价器包含一个句子相似度计算抽象模块,同时多个相似置信度分数的集成计算也是一个抽象模块,基于本文提出的框架可以设计出多种具体的算法。
2.2 算法
为了充分发挥多个机器翻译引擎的优势,挖掘利用多引擎之间有益的差异,控制抵消各自的缺点,根据多引擎集成机器翻译无监督评价框架设计了一款如算法2 所示的多引擎集成机器翻译无监督评价算法。
该算法的输入输出与算法1 的基本相同,稍有不同的是算法1 中的线性权重是单一的浮点型参数,而算法2 中包含多个预设的浮点型线性权重参数,它们的数量等于机器翻译引擎的数量。由于采用多个机器翻译引擎,所以在待评价生句对列表rsen 循环之内,还嵌套了一层按照不同机器翻译引擎MachineTranslatorj分别进行翻译的循环。当然对于翻译结果的相似置信度分数计算本文仍然采用语言无关的莱文斯坦字符串形态相似度函数LevenshteinSimi-larity实现(第10 行)。在集成多个置信度分数时,我们仍然采用简洁的线性加权方法,预设的线性权重(a1,a2,a3,…)能够调整不同机器翻译引擎的贡献度。最终采用预设的置信度阈值t分类得到高质量句对列表hsen 和低质量句对列表lsen。该算法不仅时空高效,而且能够取长补短集成多个不同机器翻译系统的各自优势,最终达到更加精准的评价效果。

算法2 多引擎集成机器翻译无监督评价算法Algorithm 2 Multi-engine-based ensemble machine translation unsupervised evaluation algorithm
接下来通过实验证明上述框架和算法的效力。
3 实验
实验选取了WikiMatrix 越南语汉语句对集合作为待评价语料[17]。原始的WikiMatrix 语料每行除了一句源语言句子和一句目标语言句子之外,还有一个实数型的边际得分(Margin Score),该分值越大表示两个句子是互相对译的可能性越大。下载的WikiMatrix 越南语汉语句对集合是以边际得分阈值1.02 截取得到的504 037 对越南语汉语句子。不过不容乐观的是该集合中最高边际得分(1.228 536 271 102 003)对应的句对<Ni đáp: "Hiện nay là ni ai chẳng biết!">和<”皋陶曰:“余未有知,思赞道哉。>并不对译。因此,有必要对WikiMatrix 越南语汉语句对集合进行质量评价。
一方面,采用谷歌翻译的越南语汉语双向翻译接口实现单引擎集成机器翻译无监督评价框架和算法。实验时从0.1 至0.9 间隔0.1 梯度设置9 个不同的置信度阈值,总共执行9 次评价。单引擎高质量句对结果如图3 所示。

图3 单引擎高质量句对结果Fig.3 Single-engine high quality sentence pair result
置信度大于0.5 的高质量句对总数只有23 677 对,而仅有250 对高质量句对置信度大于0.9。这一结果证实了WikiMatrix 中高质量的越南语汉语句对数量占比不大。表1 所示的是从置信度阈值为0.5 和0.9 的实验结果中各随机选取的10 个高质量例句。四列句子分别表示:第1 列是WikiMatrix 中的越南语句子,第2 列是WikiMatrix 中对应的汉语句子,第3 列是谷歌翻译根据第1 列句子译出的汉语句子,第4 列是谷歌翻译根据第2 列句子译出的越南语句子。

表1 单引擎高质量句对示例Table 1 Single-engine high quality sentence pair examples
表1 数据说明当置信度阈值等于0.5 时,源自谷歌翻译的单引擎评价算法能够挑选出高质量对译的句对。例如:“阿根廷核计划取得了巨大成功。”和“阿根廷的核计划非常成功。”以及“Tôi quay trở lại cửa sổ.”和“Tôi quay trở lại cửa sổ này.”语义基本等价。又由于在算法中采用了形态相似度,所以挑选出的高质量句对不仅与机器翻译结果语义相似,而且形态近似。
当置信度阈值等于0.9 时,挑选出的高质量句对与机器翻译结果只有细微差别。表1 数据一定程度上也反映了谷歌翻译的越南语汉语双向翻译效果。尽管源自谷歌翻译的单引擎评价算法偏拟合谷歌译文的形态,但挑选出的高质量句对的对译效果还是有保障的。
另一方面,采用谷歌翻译、微软必应翻译、百度翻译的越南语汉语翻译接口实现多引擎集成机器翻译无监督评价框架和算法。实验时也从0.1 至0.9 间隔0.1 梯度设置9 个不同的置信度阈值,总共执行9 次评价。多引擎高质量句对结果如图4 所示。
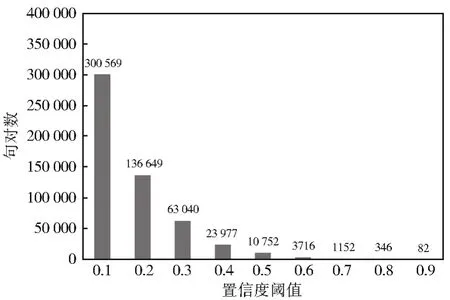
图4 多引擎高质量句对结果Fig.4 Multi-engine high quality sentence pair result
置信度大于0.5 的高质量句对总数只有10 752 对,而置信度大于0.9 还不到100 句对。表2 所示的是我们从置信度阈值为0.5 和0.9 的实验结果中各随机选取的10 个高质量例句。五列句子中第1、2、3 列与表1 前三列采用相同的表示,第4 列是必应翻译根据第1 列句子译出的汉语句子,第5 列是百度翻译根据第1 列句子译出的汉语句子。

表2 多引擎高质量句对示例Table 2 Multi-engine high quality sentence pair examples
对比表2 和表1 相同置信度阈值下的数据可知多引擎评价算法在挑选高质量句对时更加严苛。而多引擎评价算法倾向于挑选那些大家“共识”句对。这种集成“共识”有效性是基于统计、计算和表示三个方面的理论基础[18]。也就是要求每个参与集成的独立决策者都能作出略强于平庸的决策。而当前谷歌翻译、必应翻译、百度翻译完全超过了这个基线,甚至可以说都是强决策,这也成为本文算法的效力之源。尤其是当置信度阈值等于0.9 时,谷歌翻译、必应翻译、百度翻译的越南语汉语译文效果几乎趋同。由此可知,多引擎评价算法更加适合对高质量句对的对译效果要求更高的应用。
4 结论
围绕双语平行语料质量评价实际应用需求,模仿人工评价过程提出单引擎和多引擎集成机器翻译无监督评价框架。在这两种元框架之下,采用不同的相似度计算方法和不同的相似结果集成方法,能够导出多种具体的评价算法。本文采用最基本的莱文斯坦字符串形态相似度计算方法和线性加权集成方法分别设计了单引擎和多引擎集成机器翻译评价算法。实验结果表明单引擎评价算法能够集成同种机器翻译系统不同翻译方向的优势,多引擎评价算法能够集成不同机器翻译系统相同翻译方向的优势,最终实现高效工业级应用。
下一步研究主要关注相似度计算方法和相似结果集成方法创新。采用高效语义相似度计算方法降低同义异形语料的误杀率,采用增量学习方法动态优化线性集成权重进一步提升集成二值分类准确率。而且还希望将上述研究成果迁移到其他适合的语料质量评价之中。
