基于PCA-GRA-BK算法的医疗大数据分析
2023-06-01郑欣丽朱嘉辉李天意
吴 珺, 郑欣丽, 朱嘉辉, 李天意
(1.湖北工业大学计算机学院, 武汉 430068; 2.武汉理工大学材料学院, 武汉 430070)
在大数据时代,可穿戴及人体感知设备每时每刻正通过5G高速网络源源不断地收集人们的个人健康数据和医疗信息;个人健康医疗大数据具有可获得性、可存储性、可共享性以及可分析性四个主要特点.个人健康医疗大数据同样具备大数据的5V特征[1],即:1) 规模(volume)——智能穿戴设备采集的实时数据和医疗全息诊疗数据;2) 快速(velocity)——5G网络实时采集传输个人健康医疗数据;3) 多样(variety)——多种类设备采集,多维空间及多时间的多模态数据;4) 价值(value)——基于个人健康医疗大数据的智能分析和数据挖掘,可以预测传染性及发病规律,关联分析多种疾病的相互影响,精准分类诊疗病患;通过强大的机器算法来挖掘健康医疗的数据价值,全面提升个人、医疗机构和政府的价值和效率;5) 质量(veracity)——个人健康医疗大数据的准确性和可信赖度,它相较于其他电商或文娱类大数据具备极高数据质量.
同时个人健康医疗大数据还具备特有的性质:1) 高敏感性(high sensitivity)——个人健康医疗大数据详细记录了实时和过往个人信息及身体健康状况,具有极强的个人隐私,数据敏感性极高;2) 时间性(temporal)——个人健康医疗大数据可以视为多个不同类别的时间序列,具备时序性和动态性;3) 不完整性(incomplete)——个人健康医疗大数据不能全部被及时完整地存储和分析,而且相关数据不能被及时有效地进行数据挖掘和关联分析,影响了个人健康医疗大数据的真实价值.
数据挖掘旨在利用机器学习等智能数据分析技术,发掘数据对象蕴含的知识与规律,为任务决策提供有效支撑.数据挖掘是建立新一代人工智能关键共性技术体系的基础支撑.然而在大数据时代背景下,面向个人健康医疗大数据的数据挖掘与其他金融、医疗、教育、交通、媒体等应用领域不同,需要解决个人数据隐私保护问题[2-3].因此面向健康医疗大数据隐私保护的数据挖掘在理论、方法、应用等多个层面均面临新的挑战.
相较于其他应用领域的大数据,个人健康医疗大数据面临的严峻问题就是隐私泄露.面对海量的个人健康医疗大数据,只有运用机器学习方法才能深入挖掘其关联信息和真实规律价值.那么如何首先实现个人健康医疗大数据的隐私保护,再进一步通过高效用的机器学习方法进行数据挖掘和关联分析就是大数据时代个人健康医疗数据应用面临的巨大挑战.
本文的主要贡献包括如下3个方面.
1) 提出了PCA-GRA-BK算法(主成分分析灰度关联分析BiK-means K匿名算法),通过实验分析该算法的可行性,并获得68%信息损失率,相较其他算法结果较优.
2) 通过与其他算法的实验比较,PCA-GRA-BK算法优化了数据集中簇的划分过程,对最佳聚类簇中的数据进行K匿名化,减少了全局泛化造成的数据丢失;进一步降低了数据的丢失率为68%;关键的是在医疗数据的匿名化过程中,最大化地保留原始数据信息;证明了PCA-GRA-BK算法在实现健康医疗数据隐私保护的前提下,具备较好的泛化和高效用关联分析能力.
3) 解决了健康医疗大数据的隐私保护和关联分析2个主要问题.
1 相关工作
随着医疗技术的发展,医疗数据的共享程度越来越高,医疗数据的泄露问题也愈发普遍.孟小峰等[4]针对移动应用程序用户隐私风险状况及隐私保护进行了研究分析.基于移动应用程序的权限分析方法,提出一种用户隐私风险量化模型.该模型首先通过39个敏感权限识别移动应用程序内个人隐私数据收集状况,并以此为数据泄露源,考虑数据泄露的可能性及数据的隐私危害程度.然后利用3 000万移动设备上的移动应用程序数据,构建隐私风险量化模型,并基于该模型分析单个用户的隐私风险值分布,进一步研究各用户群体的隐私风险趋势,从而构建中国隐私风险指数体系,以区域隐私风险指数、人群隐私风险指数、行为隐私风险指数分别反映不同属性用户群体面临隐私风险的差异.郭子菁等[5]深入研究了医疗大数据发展规律,探讨在提高对医疗大数据真实价值认识的同时,如何有效保护数据的隐私安全.文献首先介绍了医疗大数据的相关概念以及特点,并描述了医疗大数据的4个生命周期阶段以及相应的隐私保护技术,如图1所示.然后在数据分析阶段,在机器学习框架下对医疗健康大数据进行隐私保护.最后,针对贯穿医疗大数据生命周期的普遍隐私保护挑战,从管理层面提出合理的建议.胡荣磊等[6]提出了一种大数据环境下的隐私保护方案.该方案结合大数据平台技术和存储技术对医疗数据进行脱敏处理,制定隐私保护策略,根据不同的脱敏方案调用不同的脱敏方法,有效保护了隐私信息.尚靖伟等[7]从大数据的基本概念入手,通过对现阶段隐私泄露及医疗大数据的研究,结合大数据领域的研究对当前隐私泄露行为、保护技术等问题分类阐述.谭作文等[8]在利用机器学习模型训练大数据过程中,针对隐私数据进行讨论,阐述了机器学习及其隐私定义和隐私威胁,并重点对机器学习隐私保护主流技术的工作原理和突出特点进行了阐述,分别按照差分隐私、同态加密和安全多方计算等机制对机器学习隐私保护领域的研究成果进行了综述.在此基础上,对比分析了机器学习不同隐私保护机制的主要优缺点.最后,对机器学习隐私保护的发展趋势进行展望,提出该领域未来可能的研究方向.
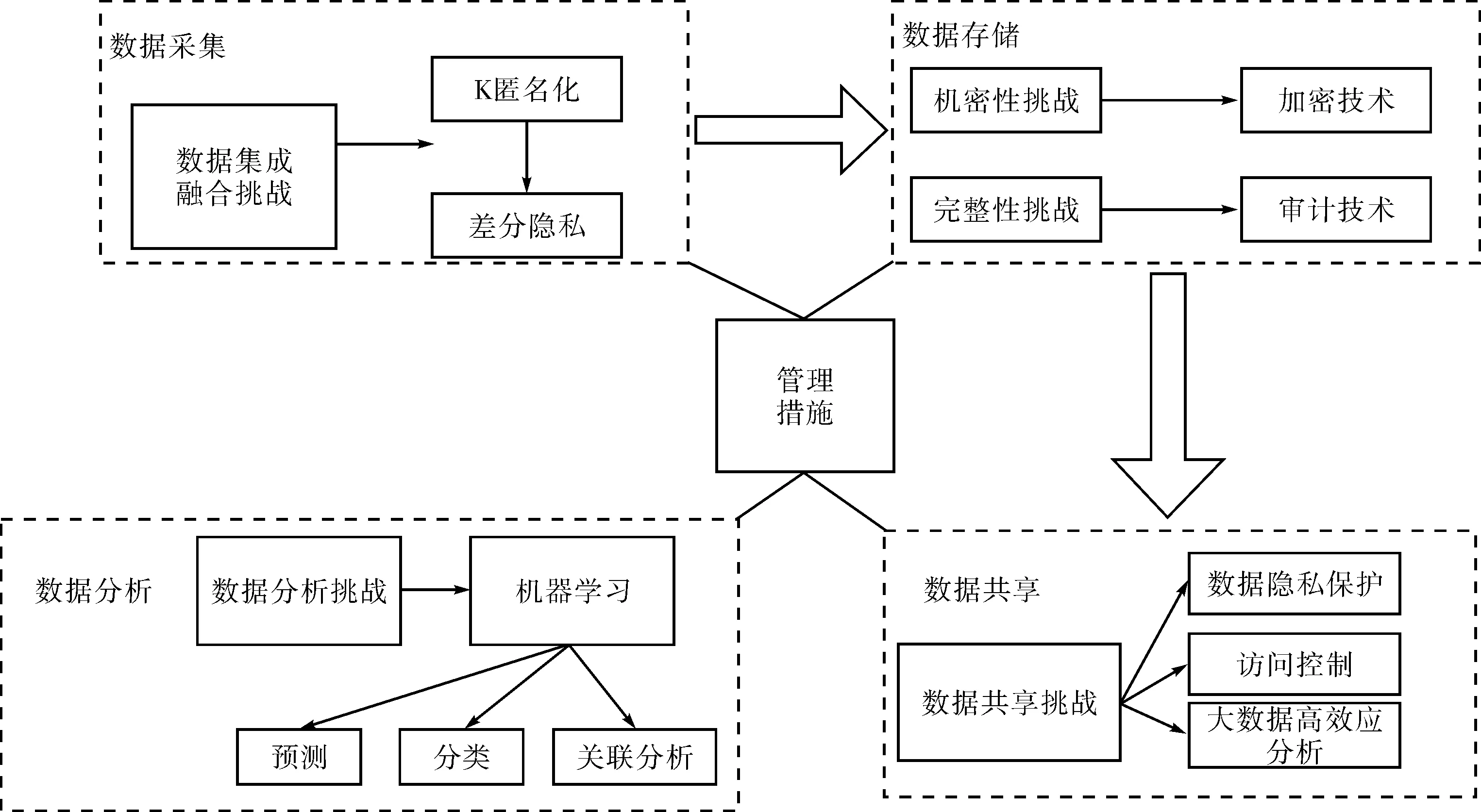
图1 健康医疗大数据生命周期图Fig.1 Lifecycle of healthcare big data
2 面向健康医疗大数据的数据隐私及高效用性分析
2.1 医疗大数据的数据隐私性
随着物联网及大数据技术的不断推荐,基于健康医疗方面的数据正以前所未有的速度增长,构成了一个十分特殊的“健康医疗大数据”.它涵盖个人日常健康大数据、临床诊疗大数据、生物特性大数据、医疗行业大数据.这些大数据不仅仅是医院的一份电子病历,同时产生于电子手环、网络问诊、医保记录、基因检测、网络购药等多个不同的地方[9-12].以上相关交易记录也往往暴露了用户的身体状况、财政状况等隐私信息,在隐私保护中也是不可忽视的内容.
文献[13]使用PCA算法对糖尿病患者的各项指标数据进行特征提取,投射到新的特征空间并建立线性回归模型,有效地提高了预测疾病的准确率.文献[14]使用PCA算法准确找出数据的主要属性,对数据进行降维,大大缩短了匿名化过程所需要的时间;而且使用PCA算法能够保持微识别过程中整个数据集的质量,降低数据失真的程度,提高数据的效用率.GRA是根据数据之间变化趋势的相似或相异程度,来衡量数据间关联程度的一种方法.文献[15]使用GRA方法计算目标层与评价等级之间的关联系数以判断其关联程度,获取网络服务质量,并利用现有的数据信息将实际方案与最优方案进行比较,做出最优决策.文献[16]提出个性化(α,l)多样性K匿名模型,根据数据集中不同属性的敏感程度,对敏感属性设置不同的隐私保护级别,并且为特定的用户提供个性化的隐私保护,达到更好的隐私保护效果.文献[17]提出基于聚类算法簇的合并、调整和概化策略,建立(k,1)-多样性数据发布模型寻找动态规划模型的最优解,使用概率联合分布度量数据对象和连续属性的相似性,有效减少了匿名化所需时间,并减少信息损失,提高查询精度.文献[18]将聚类算法与手肘法结合,确定中小企业中群集客户数据分割的最佳数量,根据由(k,SSEk)坐标绘制的坐标图,找到最佳K值作为最佳簇的数量,利用K-means算法进行数据分割.文献[19]提出了一种建立在(α,k)匿名数据基础上的支持数据动态更新的算法,对数据进行语义贴近的计算,根据计算结果在匿名数据集中选择等价类,既保证了医疗数据实时一致性,又具有运行时间短,信息损失度小的优点.文献[20]基于K匿名的位置隐私保护,利用隐私需求量和服务质量构建目标函数,提高用户位置的随机性,利用四叉树结构实现位置K匿名,有效地防止边界信息被攻击.
以上方法都未在数据降维基础上结合QI属性的关联度以及局部K匿名进行数据的隐私保护,本文通过PCA-GRA达到对数据降维以及QI属性的关联度分析,再使用聚类算法进行局部的K匿名研究,减少需要处理QI属性,再根据QI属性与敏感属性的关联度进行泛化层次的划分,优化了泛化过程中造成的信息丢失,在聚类算法的基础上进行局部K匿名,有效地降低了数据的丢失,最大化地保护隐私数据.
K匿名是保护用户隐私的一种匿名技术,若存在一个表格T(A1,A2,…,An)和准标识符(quasi-identifier),对于表格中的任一记录,都存在至少k个与其数值相同的记录,则该表格T满足K匿名.经过对准标识符的泛化或者抑制操作,当表格中的数据存在k个等价类时,数据攻击者只有1/k的概率能够获取到特定人员的敏感信息,降低了隐私泄露的风险.表1显示了医院诊断信息的初始数据.
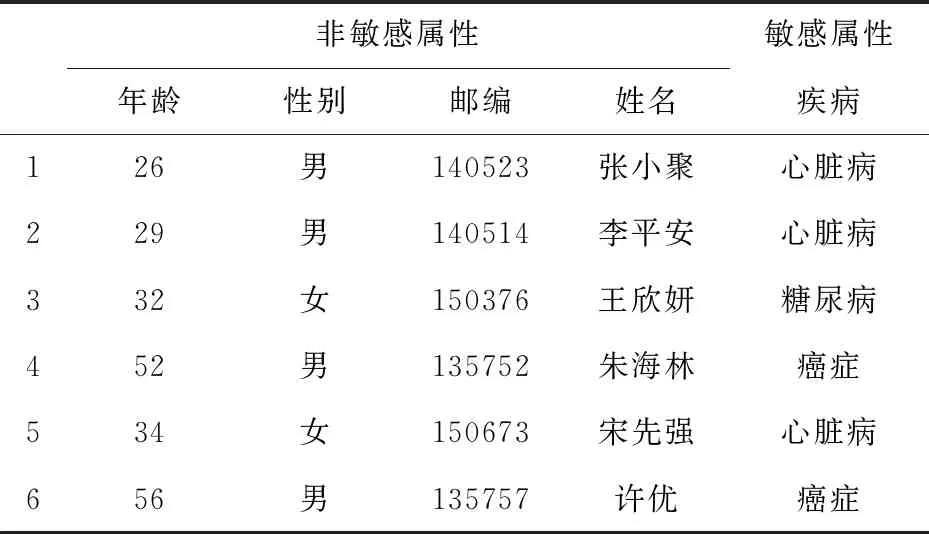
表1 初始数据表
未对数据进行K匿名时,若对患者的姓名、年龄、邮编和性别等敏感属性进行链接攻击,可以迅速推断出特定患者的患病情况,患者的隐私很容易遭到泄露.因此,在数据发布前,需要对数据进行K匿名,K匿名后的数据如表2所示.
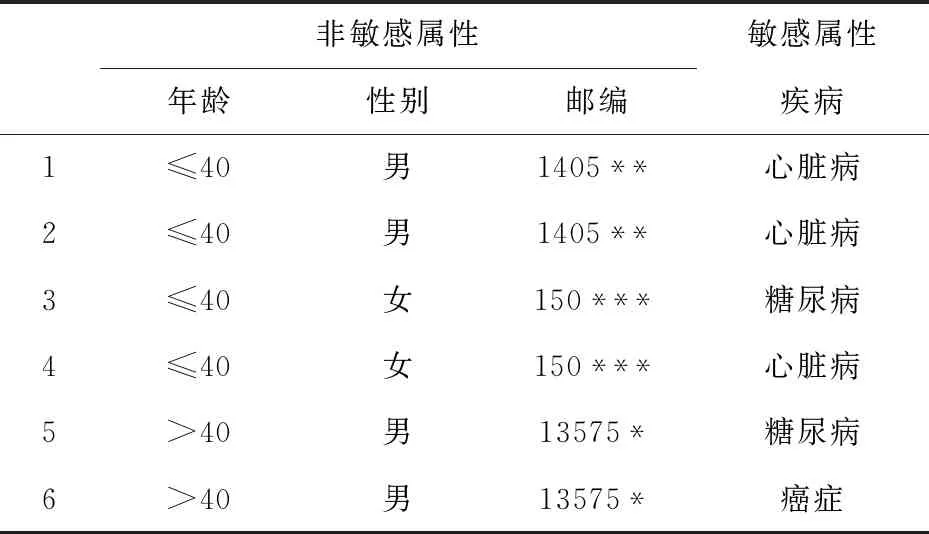
表2 K匿名数据表
在匿名处理前,表格中的数据均带有明确的身份标识信息,对于这类信息,应当直接抑制其发布.例如,表2删除了表1的姓名属性,表2可视为满足k=2的K匿名数据表.
2.2 灰度关联分析
灰度关联分析法用来计算主成分分析所选出的属性与敏感属性之间的关联度,建立QI属性的泛化层次.
该方法的具体流程如下:
1) 在灰度关联分析中,需要确定反映系统行为特征的参考数列和影响系统行为的比较数列.反映系统行为特征的数据序列称为参考数列,用于测量和对比数列之间的关联度,表示为:Y=Y(k)|1,2,…,n,一般是将敏感属性作为参考数列.Y(k)表示参考数列对应的数据值.影响系统行为的因素组成的数据序列称为比较数列,表示为:
Xi=Xi(k)|k=1,2,…,n,i=1,2,…,m,
xi(k)表示第i个比较数列中的第k个值,m表示QI属性的个数.
2) 由于数据的度量单位可能不同,在灰度关联分析之前,需要通过均值化的方式对数据进行归一化处理,将序列中的每个数据值除以该序列数据的均值,使处理后的数据值在1的量级附近.具体公式为:
(2)
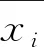
3) 经过归一化处理后,数据之间的量级差别变小了,更方便计算灰度关联系数,具体公式为:
(3)
|y(k)-xi(k)|是参考数列与第i个比较数列中对应的第k个数据之间的距离,max表示最大距离,min表示最小距离.ρ称为分辨系数,一般ρ的取值区间为(0,1),当ρ≤0.5463时,分辨力较高,通常取ρ=0.5.
4)关联系数体现了比较数列与参考数列在各个时刻的关联程度,在度量关联程度时,需要利用各个时刻的关联系数求平均值.关联度ri的计算公式如下:
(4)
计算出的关联度越接近1,则数列之间的关联度越高,也就表明敏感数据与该标识符属性的关联度越高.
3 基于灰度关联的医疗大数据高效用分析方法——PCA-GRA-BK算法
结合本文第二部分讨论的面向健康医疗大数据的隐私性,及其匿名化后的数据高效用性,提出PCA-GRA-BK算法,用来实现医疗大数据的隐私性和高效用分析.
PCA-GRA-BK算法即算法1结合了PCA算法、GRA算法、聚类算法以及K匿名化的方法.其中,PCA算法用于降低数据的维度,GRA算法用于计算QI属性与敏感属性之间的关联度,确定QI属性适合的泛化层次.在处理数据的过程中,Datafly算法需要从全局数据集中选取QI属性数值最大的属性进行泛化,扩大了部分QI属性的泛化层次.为了避免K匿名中过度的QI属性泛化,需要在匿名化之前进行数据相似等价类划分.本文引入聚类算法的思想,使用手肘法确定最佳簇数量,然后对聚类后的局部数据进行K匿名化,能够加快搜索等价类的速度,提升匿名化的效率,降低数据丢失率.选择数据集T中符合K匿名的记录,列入K匿名表;通过算法2,确定聚类算法的最佳m值,将最佳簇m的值作为Bikmeans聚类算法簇的数量;通过算法3,将数据集T分为m个数据集(T1,T2,…,Tm),分别找出m个数据集中数据值最多准标识符.
算法1PCA-GRA-BK算法
输入:PCA-GRA处理后的数据集(T)、准标识符、K的值、m(簇)的值、每一个准标识符属性的域归纳等级树.
if 统计Ti中每个准标识符属性的取值个数,找到取值个数最多和关联度最高的准标识符属性A;构造满足K匿名表的数据集Ti;
else 不满足K匿名的Ti的记录组合成新表TS;
循环执行,直到表TS满足k匿名为止;
输出:K-匿名表.
算法2手肘法
输入:PCA-GRA算法得到的具有簇标签的数据集D(其中包含n条记录和c个准标识符),簇数量m.
首先计算簇Bi(i=1,2,…,m)的质心到Bi中每个数据点的欧氏距离,以及Bi中所有数据的误差平方和;然后记录簇数量m与其对应的总误差平方和,循环执行到i=m为止;最后将得到的结果,在直角坐标系中绘制(m,SSEm)的坐标,确定最佳m值.
输出:每个m值对应的误差平方和.
算法3Bikmeans算法
输入:PCA-GRA算法得到的具有簇标签的数据集D(其中包含n条记录和c个准标识符),簇数量m.
首先将所有数据样本作为一个簇放入队列;循环执行从队列中选择一个簇进行m=2的均值聚类,并计算每个簇的SSE;然后选择SSE最小的簇进行m=2的均值聚类,放入队列;
输出:聚类后的T1,T2,…,Tm数据表.
4 实验分析
4.1 实验环境及数据集
实验选取美国加州大学机器学习数据库中的心脏病数据集,数据集中有14个属性,包括年龄、性别、胸疼类型、静息血压、血浆类固醇含量、空腹血糖、静息心电图结果、最高心率、运动型心绞痛、运动引起的ST下降值、最大运动量时心电图ST的斜率、使用荧光法测定的主血管数、THAL(地中海贫血)以及是否患有心脏病.经过数据清洗操作,删除重复的数据,处理之后的数据共有271条.实验环境为:Intel Core i5-6200U 2.30GHz CPU,12GB RAM,Windows 10 专业版64位操作系统.
4.2 实验步骤
对数据集进行主成分分析法之后,需要进行KMO(Kaiser-Meyer-Olkin)检验,比较变量之间的简单相关系数和偏离相关系数[21].KMO检验的结果为0.686,表明该数据集适用于主成分分析.
表3是对原始14个属性进行主成分分析后,根据相关系数大小,选择维度最小的主成分,确定将表里的5个属性作为QI属性,进行后续实验.
进行主成分分析和灰度关联分析后,将性别、血浆类固醇量、静息心电图结果、最高心率以及运动型心绞痛这5个属性作为准标识符.表4显示了选定准标识符与敏感属性之间的关联度.

表4 准标识符QI的关联度
利用这些关联度数值建立泛化层次结构,关联度越高表示数据之间的粘性越强,数据的泛化层次结构应该更加细致;关联度越低则表示数据之间的粘性较低,数据的泛化层次结构相对模糊.
1) 对于非数值类型的数据,需要转化为数值型数据再进行泛化层次结构的划分.例如,对于性别这一非数值数据,需要先将性别类型进行数值化,将女性数值化为“0”,男性数值化为“1”,最高层次定义为“人”,数值表示为“2”.
2) 对于数值属性,根据属性与敏感属性之间的关联度进行泛化.例如,通过将血浆固醇含量和最高心率数据控制泛化层次的深度,使得数据分布更加均匀,有效减少了泛化过程中的信息损失,降低隐私泄露的风险.血浆固醇含量和最高心率的泛化层次均为二层,性别的泛化层次为一层.根据关联度以及准标识符属性的取值范围,运动型心绞痛的泛化层次为二层,静息心电图的泛化层次为三层.对QI属性进行泛化之后,需要使用聚类算法确定最佳簇的数量,提高数据的实用性.
本文中的实验使用手肘法确定最佳簇的数量,计算所有簇的误差平方和(SSE),并将每个簇与其对应的SSE值在坐标轴中用点表示,坐标轴中与手肘形状最相似的拐点值被确定最佳的簇的数量,SSE的计算公式如下:
(5)
其中,Ci表示第i个簇,p表示Ci中的样本点,mi表示Ci中所有样本的均值.
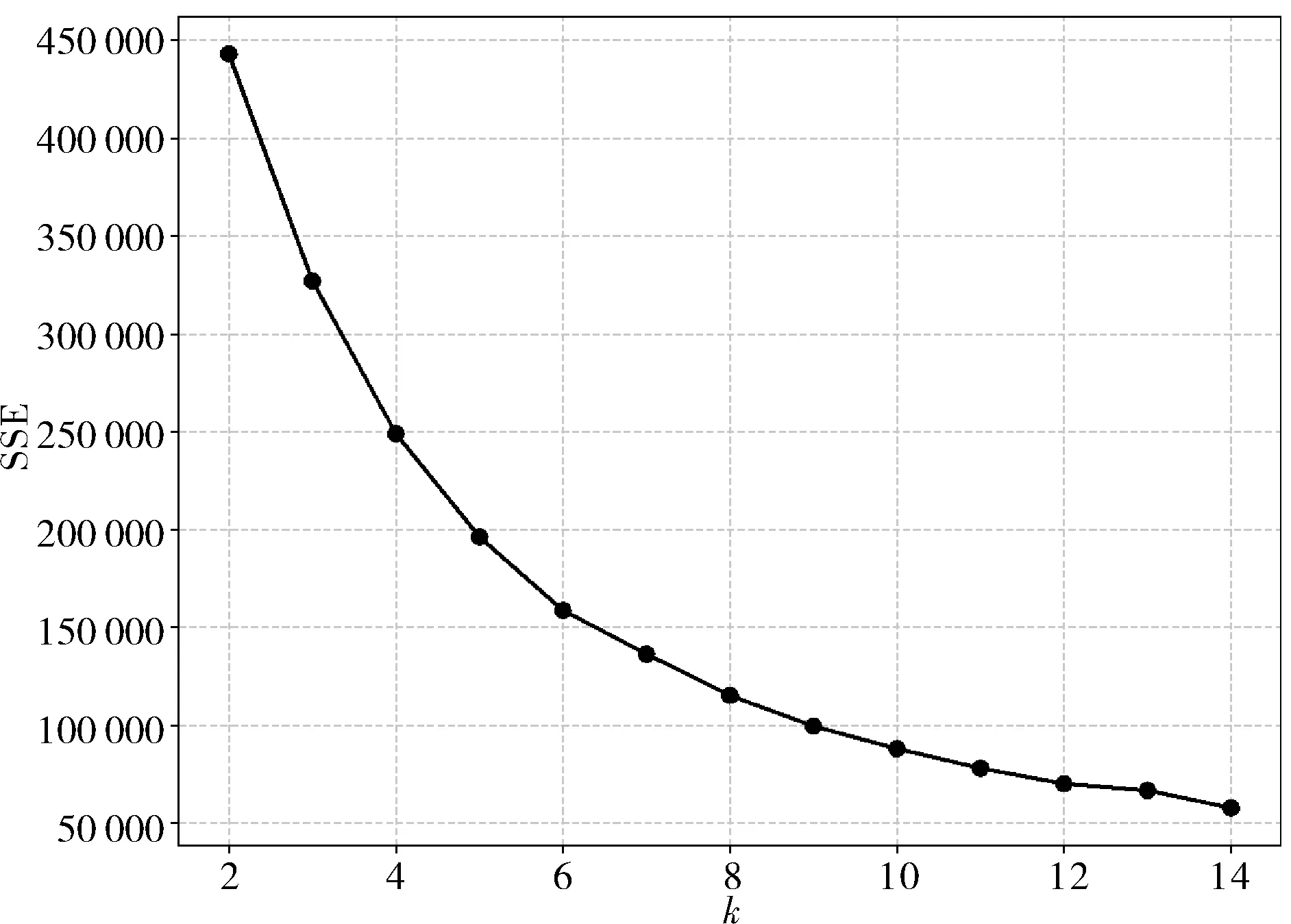
图2 手肘图Fig.2 Elbow method of data
根据坐标点(k,SSEk)绘制出坐标图后,利用手肘法对实验数据进行分析,确定合适的簇的数量.
由图2可以看出,当簇的数量等于6 时,符合手肘法的判定标准,因此,将该数据集的最佳簇的数量定为6,根据最佳簇的大小,完成对数据的聚类分析.为了比较数据匿名化后的效用性,本文从信息丢失以及执行时间两个方面对Datafly算法、PCA-GRA Datafly算法、PCA-GRA-KK算法以及PCA-GRA-BK算法进行比较.
信息损失量是衡量匿名算法优劣的基本标准,信息损失量越低,表示匿名过程对原始数据信息的丢失率越小,数据的效用率更高,文献[22]提出了信息损失量的计算公式:
(6)
其中,T表示原始的数据表,RT表示匿名化之后的数据表,n表示数据表中包含的元组个数,nq表示准标识符属性的数量,h表示第i条记录的第j个准标识符在泛化树中上升的层数,|DHGA|表示属性A的泛化树高度,|t[Q]|表示记录中准标识符Q的取值,m表示被抑制的元组个数.
在K匿名化的过程中,QI属性被泛化到高层次或被抑制到泛化结构顶层的数据越多,表明信息的实用性被钳制化,信息的损失率就越高.因此,K匿名是通过损失信息的实用性成本来达到匿名化的效果.
图3显示了四种算法的信息损失率,Dataly算法只对准标识符中数量最多的属性值进行K匿名化,造成的信息损失率较大;PCA-GRA Dataly算法将主成分分析法和灰度关联分析法与Dataly算法相结合,根据属性之间的关联度划分泛化层次,降低了信息损失率.
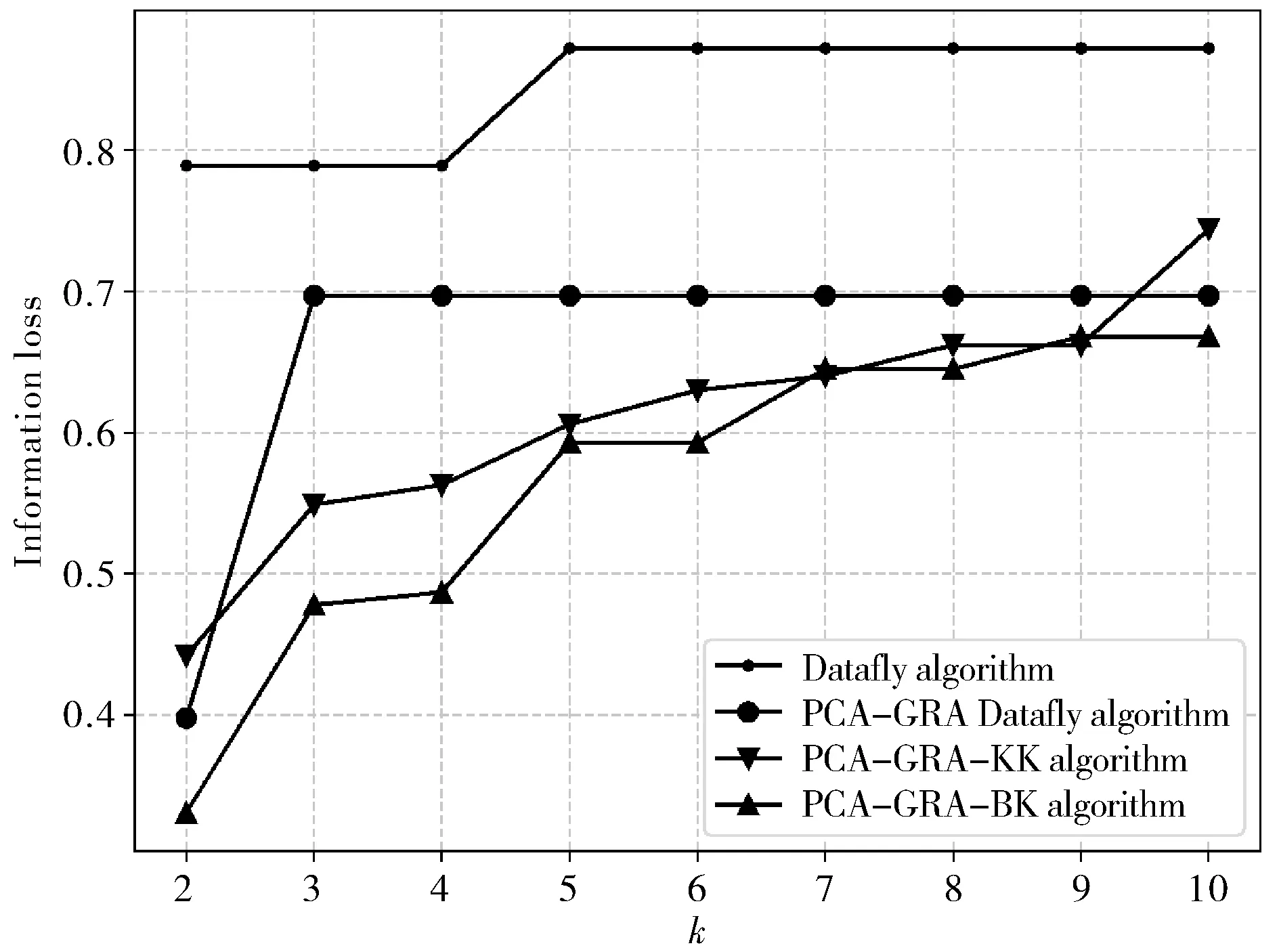
图3 信息损失率的变化曲线图Fig.3 Change curve of the information loss rate
PCA-GRA-KK算法与PCA-GRA-BK算法在PCA-GRA Dataly算法的基础上增加聚类算法,对相似度高的元组进行聚类,局部泛化QI属性,对最佳聚类簇中的数据进行K匿名化,减少了全局泛化造成的数据丢失;PCA-GRA-BK算法优化了数据集中簇的划分过程,进一步降低了数据的丢失率;在医疗数据的匿名化过程中,关键是最大化地保留原始数据信息.显然,在四种算法中,PCA-GRA-BK算法效果最优.
4.3 实验结果验证
算法的运行时间也是衡量一个算法性能的关键,运行时间越短,则算法的时间复杂度更低,处理数据的速度更快.四种算法的时间复杂度和空间复杂度分别为O(n3),O(1).图4显示了四种算法的运行时间.
综合比较Datafly算法时间消耗更高;PCA-GRA Datafly算法对数据进行降维,减少了算法的计算量,明显降低了匿名化过程的时间消耗;与PCA-GRA-KK算法和PCA-GRA-BK算法相比,PCA-GRA Datafly算法通过使用聚类算法,大大减少了匿名化过程中寻找等价类的时间,而且算法运行时间更加稳定;PCA-GRA-BK算法对初始簇划分进行了优化,避免在全局数据聚类过程中陷入局部最优,在运行时间上明显优于PCA-GRA-KK算法.综合比较得出,PCA-GRA-BK算法在运行时间上稳定而且消耗时间少,更加具有优势.
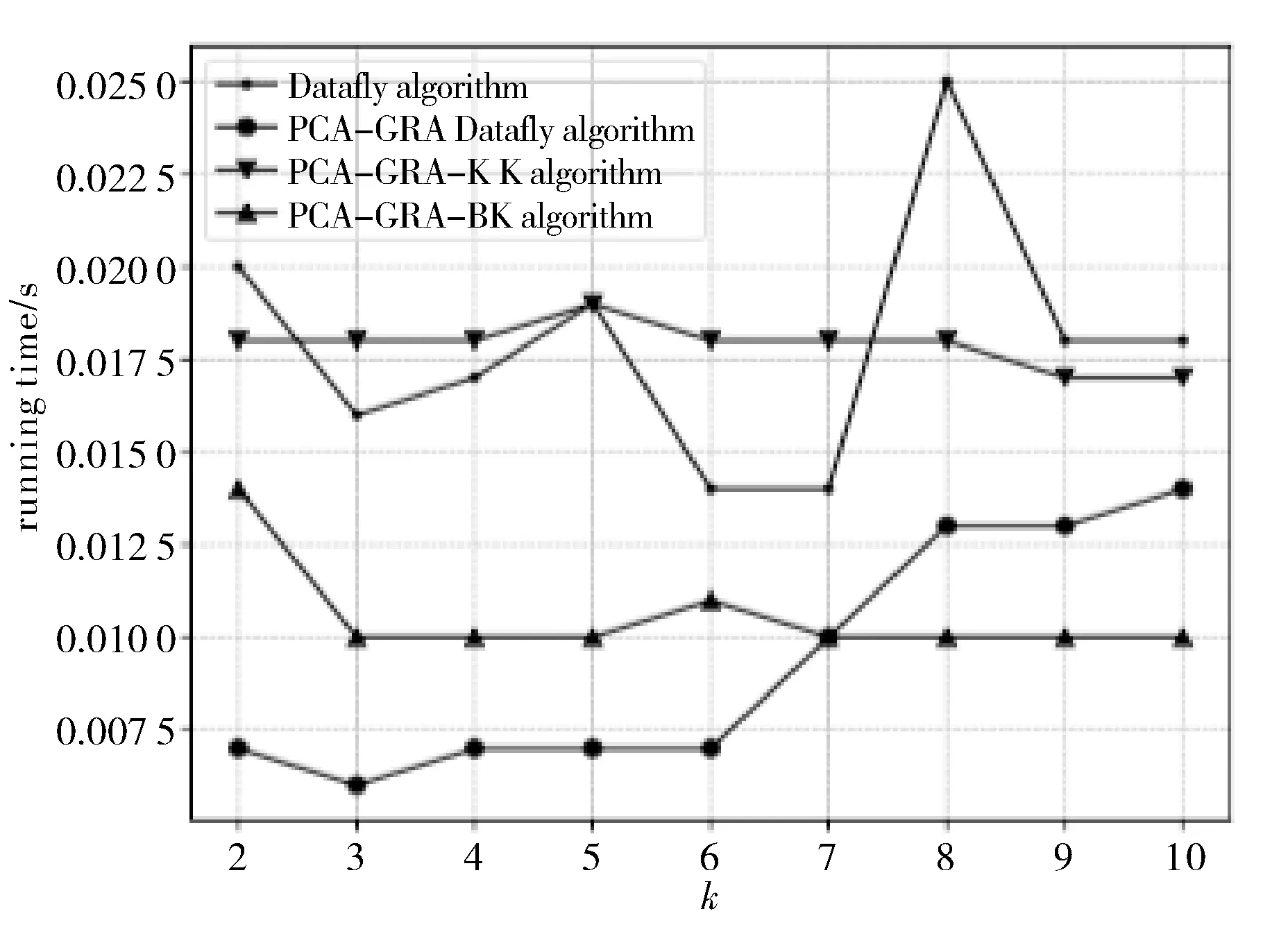
图4 算法运行时间的变化曲线图Fig.4 Change curve of the running time of the algorithm
5 结论
本文基于Datafly算法,为了解决数据维度高、传统算法的QI属性过度泛化的问题及K-means算法的局部最优问题,提出PCA-GRA-BK算法.首先利用主成分分析法确定不同维度之间数据的关联性,对原始数据进行降维;再利用灰度关联分析法划分准标识符的泛化结构层次,数据关联度越高,则泛化层次越密集;最后对不同泛化层次的数据进行匿名.在数据集的划分过程中,将相似的数据元组划分到同一个簇,避免了全局数据匿名化造成的相近元组数据的信息损失.通过四种算法的信息损失率和运行时间的比较,证明了PCA-GRA-BK算法的数据损失率更低,运行时间稳定而且消耗时间少.因此,PCA-GRA-BK算法能够对原始数据降维的同时,减少医疗数据的泄露概率,保护患者的隐私.如何降低信息损失度,是未来研究需要解决的重要问题.在接下来的工作中,将进一步对多敏感属性数据进行研究,使其能够更好地应用于医学领域.
