基于F-CSGRU的入侵检测半监督学习方法
2023-05-31马泽煊岳韶华吕启斌
马泽煊,李 进,岳韶华,吴 暄,吕启斌
(1.空军工程大学 防空反导学院, 西安 710051; 2.军事科学院研究生院, 北京 100097)
0 引言
计算机和网络技术的快速发展,给人们的工作和生活带来了前所未有的方便与快捷,但随之而来的,是日益增多的网络入侵与攻击行为,它们通过网络对机构和用户的计算机进行入侵,从而达到破坏以及盈利的目的,对网络入侵行为进行检测已经刻不容缓。网络入侵检测系统作为一种集监视、检测和分析于一体的网络安全保护工具,能够对网络流量进行实时监控,并自动将网络流量区分为正常流量和恶意流量。近几年来,机器学习与深度学习已被广泛应用于网络安全与计算机防护领域。然而,现有的网络入侵检测技术大多为有监督学习,只能利用有标签的数据集对模型进行训练。但是在很多实际问题中,采集到的数据都不带有标签,且标签获取难度大、成本高。为了更好地利用这些数据,半监督学习技术应运而生,并逐渐成为网络入侵检测领域中的热点方向。
为提高网络入侵检测模型的性能,Xu等[1]提出了一种基于RNN的入侵检测系统,该模型使用GRU进行特征提取,同时使用多层感知器和Softmax分类器对网络入侵行为进行检测。我们使用KDD Cup-99和NSL-KDD数据集进行测试。实验结果表明,该方法整体检测率较高,但是对于少数攻击类的检测率偏低;Kasongo等[2]将信息增益(IG)与门控循环单元进行结合,提出一种IG-GRU-IDS方法。论文基于NSL-KDD数据集进行实验,结果表明,论文提出的方法具有较高的检测准确率,但是对于R2L和U2R攻击方面的检测效果较差;考虑到标签样本数量少、获得难度大,Ashfaq等[3]提出一种半监督学习方法,该方法使用具有随机权重的神经网络作为分类器对样本进行分类,同时依据模糊集对样本进行划分。论文能够较好的对无标签样本进行利用,但是所使用的分类器性能较差,导致整体效果不佳,同时对于U2R和R2L的检测准确率也偏低。
为解决上述问题,论文使用代价敏感方法增强模型对于少数类样本的判别能力;之后将其与门控循环单元相结合,从时间序列方面对特征进行提取,并为无标签样本生成标签;然后将模糊理论应用于半监督学习中,依据模糊熵对样本进行划分,选择低模糊熵样本对原始数据集进行补充,再次对模型进行训练;最后对损失函数和优化算法进行分析,选择最适合本模型的超参数,对模型整体性能进行提升。
1 模糊性和代价敏感
1.1 模糊性
模糊性最早由Zadeh在其著名的模糊集理论[4]中提出,它描述了存在于事件中的一种不精确性。这种不精确性既不能被精确定义,也不能用精确定义的点集合来表征。Zadeh还将事件的概率度量推广到模糊事件中,提出与模糊事件存在关联的各种不确定性都可以使用信息论中的熵理论来进行解释。De Luca等[5]认为模糊性是由模糊集描述的一种不确定性,并使用与香农信息熵较为相近的非概率熵对模糊性的定量度量进行了定义,具体如定理1所示。
定理1论域X上的一个模糊集A的模糊度D(A)∈[0, 1]是指,对于∀x∈X,有
1) 当且仅当A(x)=0或1时,即A退化为经典集时,D(A)=0,模糊度最小。
2) 当A(x)=0.5时,D(A)=1,模糊度最大。
3) 对于论域X上的2个不同模糊集A1和A2,若存在A1(x)≥A2(x)≥0.5或A1(x)≤A2(x)≤0.5,则有D(A1)≤D(A2)。
4) 当A2(x)=1-A1(x),∀x∈X时,D(A1)=D(A2)。
5)D(A1∪A2)+D(A1∩A2)=D(A1)+D(A2)。
定理1表明,在一个经典集合中,当其隶属度为0.5时,无法判断它是否属于某一类别,模糊性最强;当其隶属度等于0或1时,可以准确判断它与某一类别的隶属关系,此时不存在模糊性。
Chen[6]提出模糊集的模糊程度可以使用模糊熵进行表示,具体如定理2所示。
定理2设A为论域X={x1,x2, …,xn}上的模糊集,则A的模糊熵如式(1)所示。
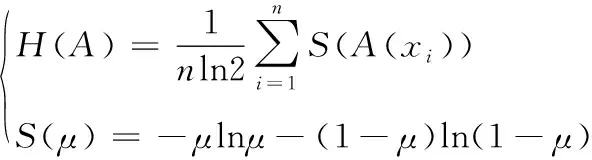
(1)
其中,H(A)为A的模糊熵。
熵常被用来对一个系统或一段信息的不确定性进行度量。与熵的性质相同,模糊熵的数值越大,说明集合的模糊性越强,对结果进行判定的难度越大。论文将模糊熵应用到半监督学习中,作为生成标签样本的置信度,选择模糊熵较低的样本对数据集进行补充,提高模型检测效能。
1.2 代价敏感
代价敏感主要用于对数据不平衡问题进行解决,它对不同的分类错误采用不同的惩罚力度,通过将分类成本最小化,达到提升少数类样本判别准确率的目标[7]。代价矩阵作为代价敏感方法的主要表示形式,常被用来对错误分类的惩罚项进行表示。因此代价敏感方法应用成功与否关键在于代价矩阵的构建是否合理。实验表明,在很多应用领域,使用代价敏感方法都能够对模型的效果进行提升[8]。
代价敏感方法的目标是训练一个分类器h:X→Y,对采集到的数据进行分类,同时产生的期望代价最小,即:
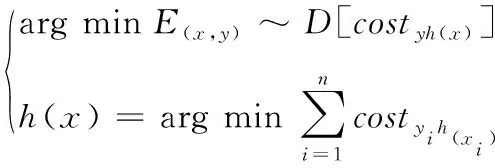
(2)
式中:D表示样本的分布;E表示期望代价;h(x)表示x的经验风险值;costyh(x)表示某个类别的分类代价值。
2 基于F-CSGRU的入侵检测系统半监督学习方法
论文基于上述方法,提出一种基于F-CSGRU的入侵检测半监督学习方法。首先,将训练集传入CSGRU网络中进行训练;之后,将无标签数据传入训练好的CSGRU网络,生成标签;然后依据模糊熵对生成标签的样本进行划分;最后将低模糊熵样本与训练集中原始数据一同传入CSGRU中再次进行训练,并使用测试集对模型训练效果进行验证。入侵检测过程共包括数据预处理、特征提取与训练、标签生成及样本选择、第二次特征提取与训练、测试5个阶段,模型结构如图1所示。

图1 F-CSGRU模型结构图
2.1 数据预处理
首先,采用标签编码方式将NSL-KDD、UNSW-NB15数据集中的字符串型特征转换成数值型,之后进行标准归一化处理。论文使用Min-Max归一化方法对数值进行归一化,公式如式(3)所示。
(3)
式中:x为将要归一化的数值;Mmin为该维的最小数值;Mmax为该维的最大数值。
2.2 特征提取与训练阶段
在特征提取与训练阶段,论文使用两层GRU对样本的时序特征进行提取[9-14],并使用Nadam优化算法对神经网络进行优化,同时设置Dropout层对训练过程中出现的过拟合问题进行一定程度的缓解,最后传入Softmax分类器完成分类。由于GRU没有解决数据集样本不平衡问题的能力,对于每个种类的样本,其分类错误的代价是一样的,所以在入侵检测过程中,模型对于数据集中的少数类样本的检测准确率偏低。为了解决这个问题,论文提出在标准损失函数中增加一个辅助的代价敏感损失项,从而将代价敏感约束引入到模型中。这一步骤赋予了少数类样本更大的错误分类代价,从而能够在后续训练过程中取得更好的检测效果。论文提出的CSGRU网络结构如图2所示。
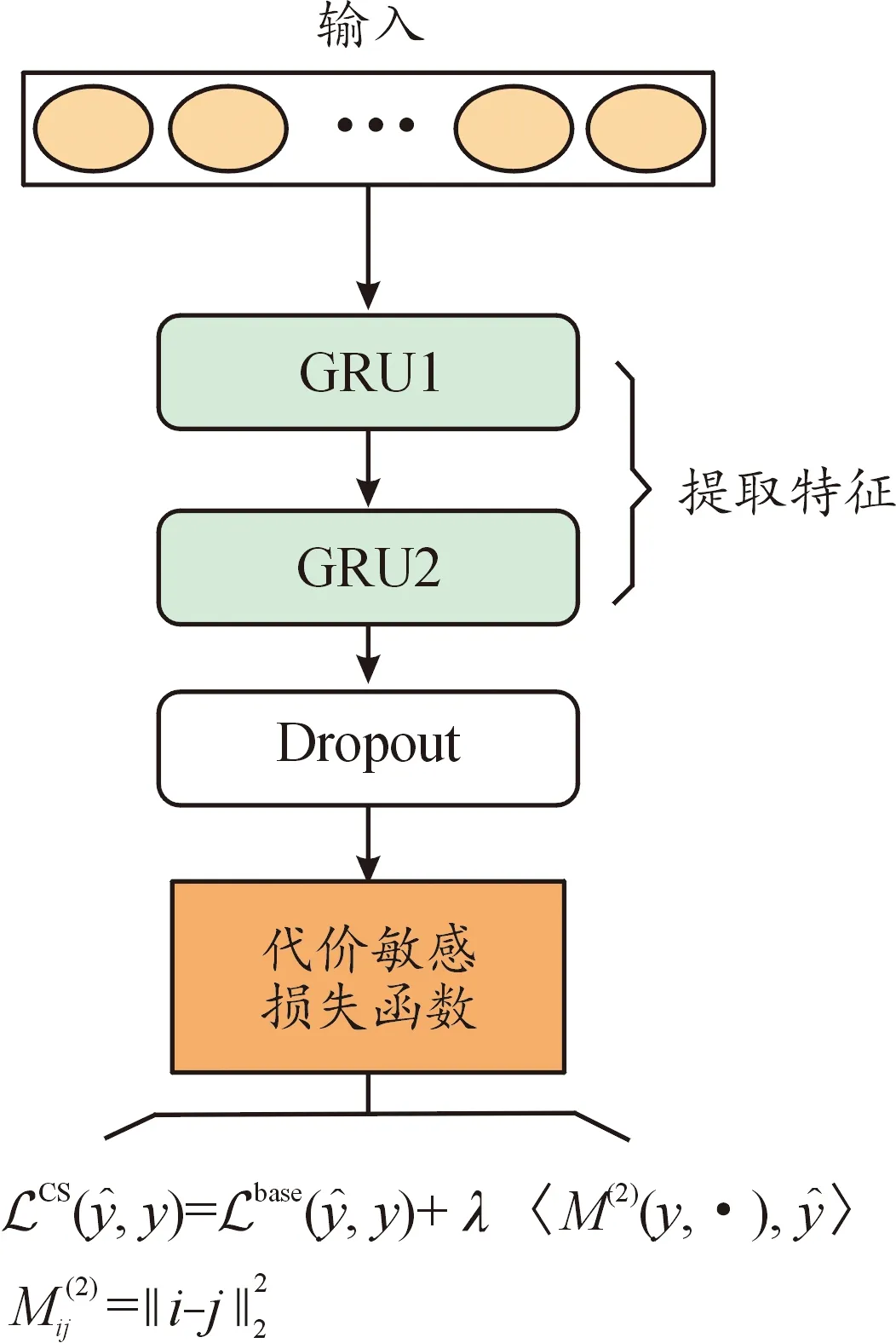
图2 CSGRU网络结构
论文使用交叉熵标准损失函数作为基准函数,公式如式(4)所示。
(4)
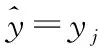
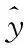
(5)
其中,M(2)为基于L2的基本成本矩阵,它能够较好地满足最大化二次加权kappa得分的目标。
2.3 标签生成及样本选择阶段
在标签生成及样本选择阶段,首先将无标签数据集传入训练好的CSGRU网络中,为样本生成相对应的标签。之后依据模糊熵将样本划分为低模糊熵样本和高模糊熵样本。最后将低模糊熵样本与原有数据集结合,再次对CSGRU网络进行训练。模型训练过程如算法1所示。
算法1基于F-CSGRU的半监督学习算法
输入:
Train:训练集(xi,yi|1≤i≤N)
Unlabel:无标签数据集
Test:测试集
网络模型:CSGRU
分类器:Softmax
输出:
TestAccuracy
流程:
CSGRU′=CSGRU(Train)
生成CSGRU′(Unlabel)
从CSGRU′(Unlabel)中获取每一个无标签样本的隶属度向量U
计算Unlabel中每一个样本的模糊熵Fe(U)
将样本划分为低模糊熵样本Felow和高模糊熵样本Fehigh
Trainnew=Train+Felow
CSGRU″=CSGRU′(Trainnew)
生成CSGRU″(Test)
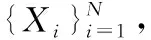
(6)
其中,μij=μi(xj)表示第j个样本xj属于特定类i的隶属度。
当分类器完成训练时,可以得到其隶属度矩阵U。对于第j个样本xj,经过训练的分类器将给出一个表示为模糊集μj=(μ1j,μ2j,…μcj)T的输出向量[19]。依据定理2,输出向量的模糊熵可通过式(7)获得。
(7)
其中,U=(μij)c×N为c类的N个训练样本上的分类器的隶属度矩阵。
2.4 第二次特征提取与训练阶段
在第二次特征提取与训练阶段,主要步骤与前一阶段相同。将低模糊熵样本和训练集样本一起传入CSGRU网络中,再次进行特征提取与训练,获得训练好的网络模型。
2.5 测试阶段
模型训练完成后,使用训练好的模型对测试集进行分类。为了确保测试结果的可信度,本文使用k折交叉验证方法对模型进行测试。本文使用Softmax函数来计算分类的结果概率,并将其与原始标签进行比较。Softmax的计算公式如式(8)所示。
(8)
3 实验和结果分析
3.1 实验设置
为了测试基于F-CSGRU的入侵检测半监督学习方法的性能,论文设计以下实验。
实验1:模型性能分析实验
实验2:模型消融实验
实验3:不同模糊组加入数据集对比
实验4:不同分类算法对比
实验5:与传统入侵检测方法的比较
实验6:与现有入侵检测模型的比较
本实验环境为64位Windows 10操作系统的TensorFlow学习框架,计算机配置为AMD Ryzen 9 5900HX with Radeon Graphics 3.30 GHz,32GB RAM。
通过使用贝叶斯优化算法对模型参数进行自动寻优,确定模型参数设置如表1所示。
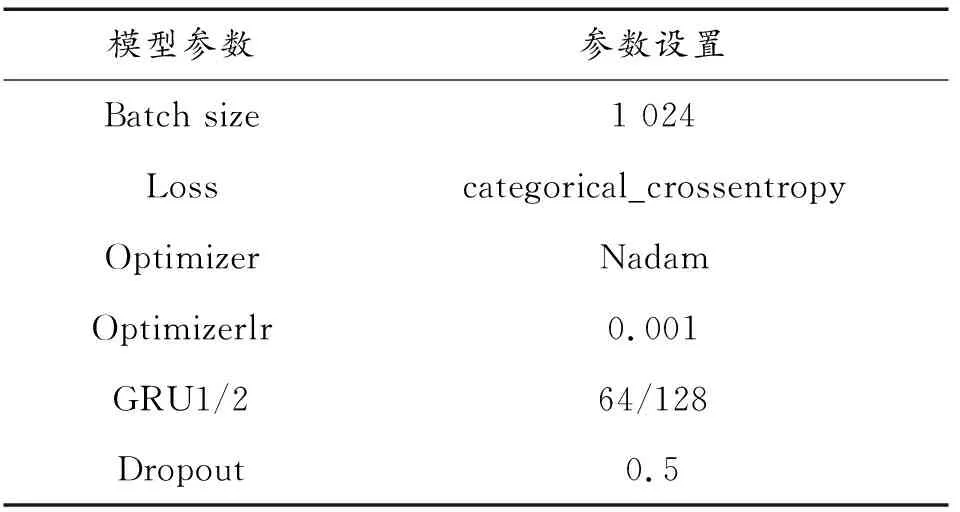
表1 模型参数设置
3.2 数据集和实验评价指标
论文中提出的模型在2个数据集上进行评估:NSL-KDD和UNSW-NB15数据集。
NSL-KDD数据集由Tavallaee等人在2009年对KDD99进行改进得到,消除了KDD99数据集中的重复实例,能够更加客观的对模型的检测准确率进行反映[20],NSL-KDD数据集共包含DoS、Probe、R2L和U2R4种攻击类型以及41个属性,但其中的数据量极不平衡,攻击实例数量远远低于正常实例的数量,且R2L和U2R攻击分别只有995和52个。
UNSW-NB15数据集由澳大利亚网络安全中心的网络范围实验室创建。该数据集相较于NSL-KDD包含攻击种类更多,分别为Fuzzers,Analysis,Backdoor,DoS,Exploits,Generic,Reconnaissance,Shellcode和Worms。同样,该数据集也存在数据不平衡的问题,攻击实例数据的数量远远小于正常实例数据的数量。
NSL-KDD数据集的训练集种类分布情况如图3所示。UNSW-NB15数据集的分布情况如图4所示。

图3 NSL-KDD训练集种类分布
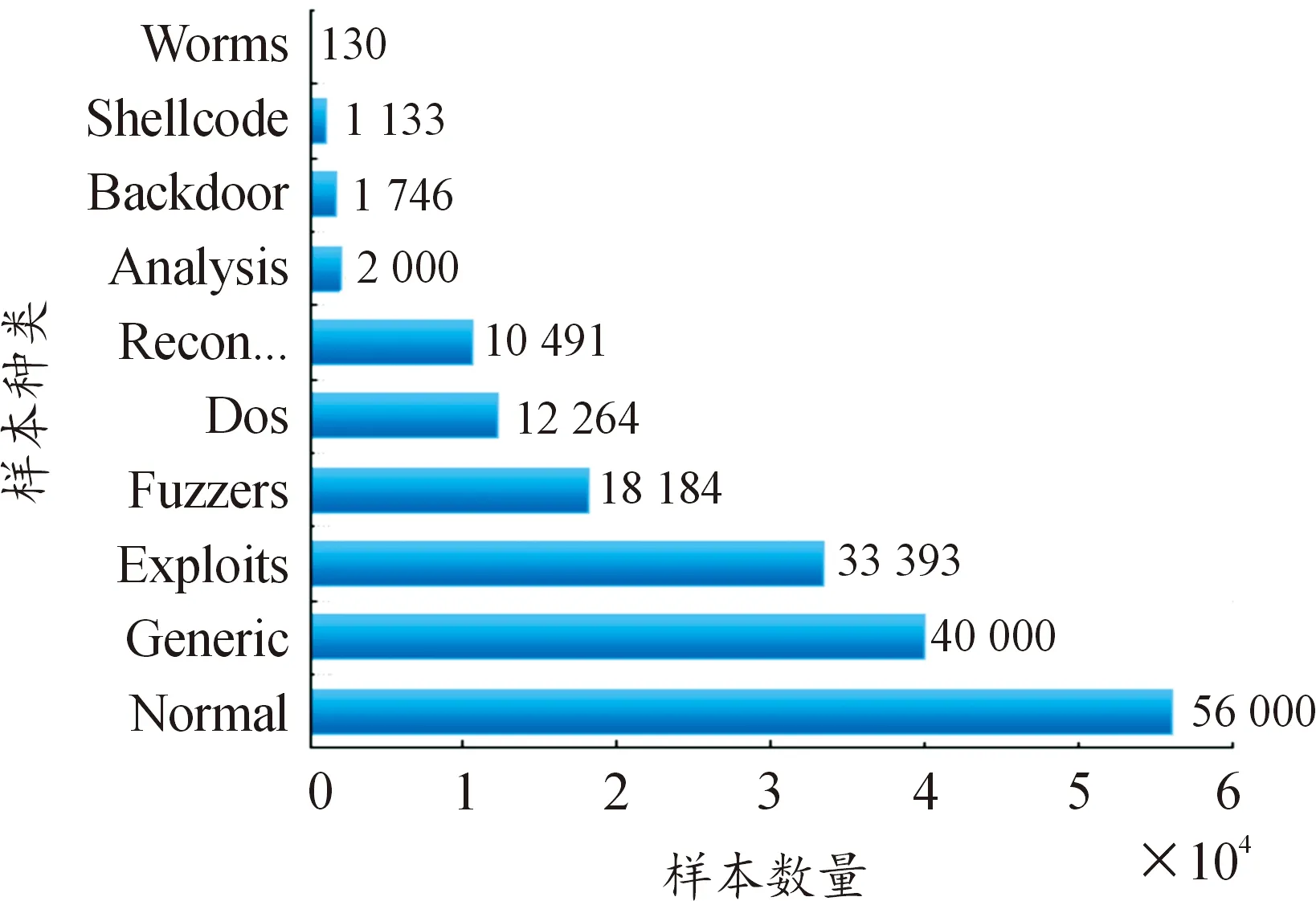
图4 UNSW-NB15训练集种类分布图
对比实验使用分类准确率(Acc)、精确率(Pre)、召回率(Rec)、特异度(Spe)和Fβ值对模型分类效果进行判断。分类混淆矩阵定义如表2所示。
表2 分类混淆矩阵定义
依据表2,得到上述5个评价标准的计算公式分别如式(9)—式(13)所示。
(9)
(10)
(11)
(12)
(13)
式(13)中,通常β取1。
3.3 实验结果和分析
3.3.1性能分析实验
为验证论文提出的模型对于网络入侵行为的检测效果,本节对基于F-CSGRU的入侵检测半监督学习方法设置性能分析实验。
模型在NSL-KDD和UNSW-NB15数据集上的检测效果分别如图5和图6所示。

图5 NSL-KDD性能分析雷达图
图6 UNSW-NB15性能分析雷达图
由图5和图6可知,模型的各项性能指标均能够取得较好的成绩。其中,使用论文模型对NSL-KDD数据集进行多分类,得到最佳的准确率为99.30%;UNSW-NB15数据集得到的多分类最佳准确率为84.53%。说明模型能够很好的对网络入侵攻击行为的种类进行区分,从而获得较高的检测准确率以及较好的检测效果。
各种类检出率分别如图7和图8所示。
由图7和图8可知,论文提出的模型能够较为准确的识别出两个数据集中的正常以及绝大多数攻击类别,对于少数类攻击类型的识别率也能够达到较高的标准,说明论文提出的代价敏感以及半监督学习方法,在很大程度上缓解了类不平衡问题产生的影响,从而提升整体的检测效果。
图7 NSL-KDD种类检出率雷达图

图8 UNSW-NB15种类检出率雷达图
3.3.2消融实验
为验证论文提出的代价敏感和半监督学习方法能够提升模型对于少数类样本的检测效果,本节设置模型消融实验。
在相同实验条件下,分别使用GRU、F-GRU、CSGRU以及本文模型在NSL-KDD数据集上进行对比,检测各个模型对于该数据集中各个种类的检出率,检测结果如表3所示。
表3 消融实验各种类检出率
由表3可知,论文提出的代价敏感和半监督学习方法对于少数类样本检测率的提升都起到了比较显著的作用。原因在于,将代价敏感与GRU网络相结合,可以增强网络对少数类样本的分类准确率,且不容易陷入局部最优。通过这样训练完成的网络,对于少数类样本的检测准确率更高。之后进行半监督学习,即将无标签样本输入到网络中时,网络对于少数类样本生成标签的准确度也会更高。同时使用模糊熵作为评价指标对样本进行筛选时,选取到的少数类样本相较于多数类样本的比重也会更大,从而在新的数据集中,少数类样本的比重就会更高。所以论文将两者结合使用,提高模型的检验效果。
3.3.3不同模糊组加入数据集对比实验
为验证在训练集中加入低模糊熵样本,能够使模型取得最好的检测效果,本节设置不同模糊组加入数据集对比实验。
在相同实验条件下,按照相同的步骤分别向训练集中不加入样本、加入全部样本、只加入高模糊熵样本和只加入低模糊熵样本对模型进行训练,对效果进行检验,检验结果如表4和表5所示。

表4 NSL-KDD数据集加入模糊组比较
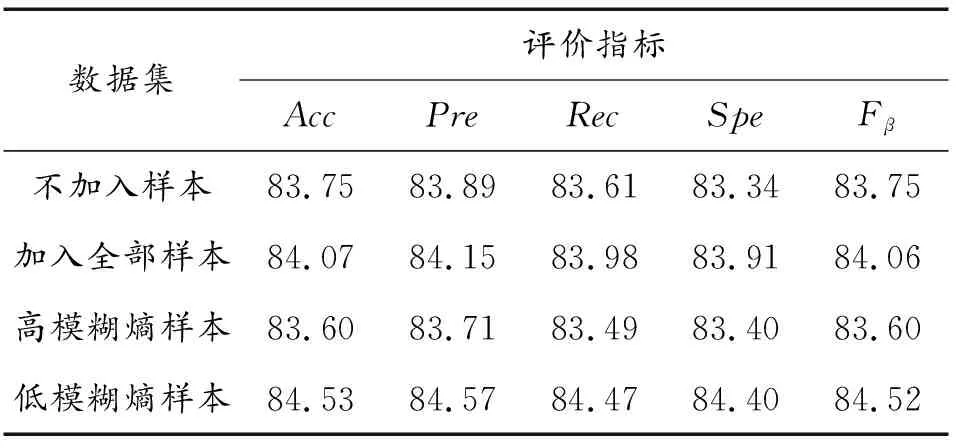
表5 UNSW-NB15数据集加入模糊组比较
由表4和表5可知,在数据集中仅加入低模糊熵样本,模型的各项指标所获得的效果最好。原因在于,分类器模糊熵的最合理的定义为整个样本空间的平均模糊熵,包括训练样本和不可见的测试样本。然而,无标签样本的模糊性通常是未知的,对于任何有监督学习问题,都有一个公认的假设,即训练样本的分布与样本在整个空间中的分布相同。结合式7,可以得出结论,模糊熵较低的样本表示其对于某一种类的隶属性质较明显,分类准确度较高;模糊熵较高的样本则意味着更大的误分类风险。所以论文只选择低模糊熵样本与数据集结合对模型进行再次训练。
3.3.4不同分类方法对比实验
为验证GRU网络对于网络入侵行为的分类能够取得更优的效果,本节设置分类方法对比实验。
在相同实验条件下,按照相同的训练步骤分别对RF、DNN、RNN以及论文中使用的GRU进行训练,对不同算法的入侵检测效果进行检验,检验结果如表6和表7所示。
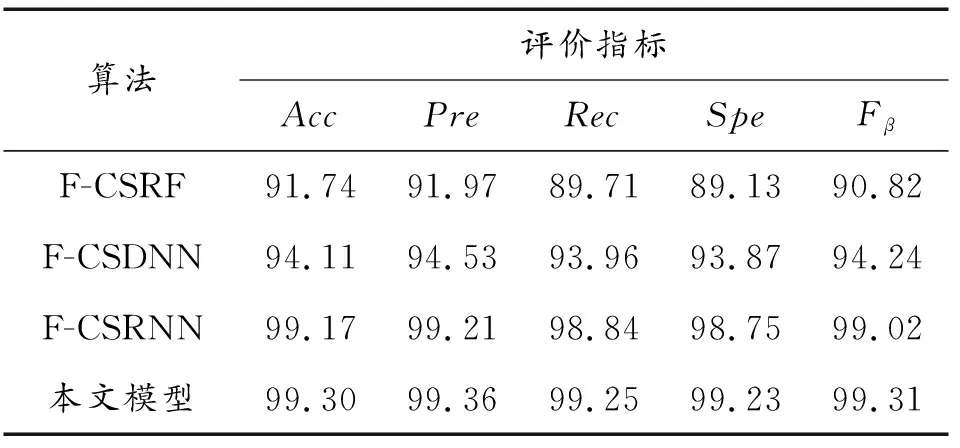
表6 NSL-KDD数据集分类算法比较
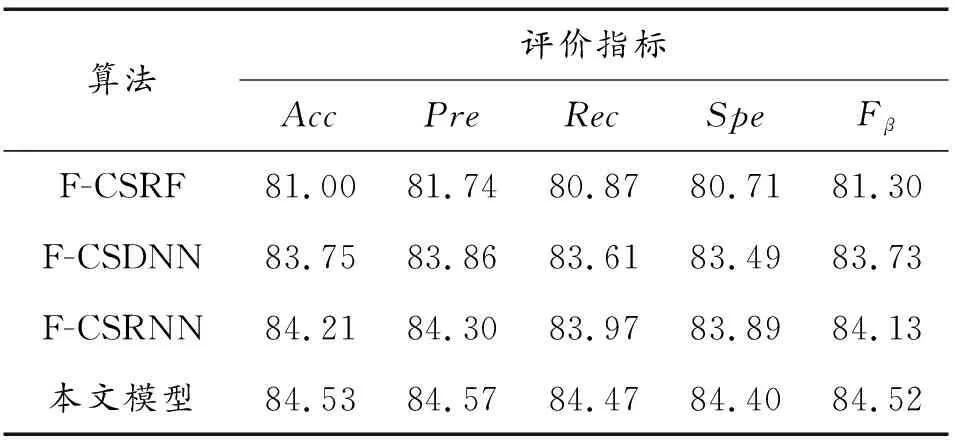
表7 UNSW-NB15数据集分类算法比较
由表6和表7可知,论文提出的F-CSGRU模型在准确率、精确率、召回率、特异度以及Fβ值上均高于其他检测方法,取得了最佳的检验效果,证明了GRU对于网络入侵检测问题具有特定的优势。原因在于,网络流量数据具有明显的时间序列特性,RNN和GRU所具备的时序处理能力能够对长时间序列数据进行更深层次的特征提取,因此使用该类方法处理网络入侵检测问题能够取得很好的效果。而RNN对于长时间序列数据的处理能力要远远不如GRU,所以论文使用GRU对入侵行为进行检测。
3.3.5传统的入侵检测方法对比实验
为验证基于F-CSGRU的入侵检测半监督学习方法相较于传统入侵检测方法能够取得更好的效果,本节设置传统的入侵检测方法对比实验。
在相同实验条件下,将传统的入侵检测方法,如决策树(DT)、随机森林(RF)、K均值聚类算法(K-means)、支持向量机(SVM)以及长短期记忆网络(LSTM)算法分别应用到NSL-KDD以及UNSW-NB15数据集上进行实验,其性能表现如表8和表9所示。
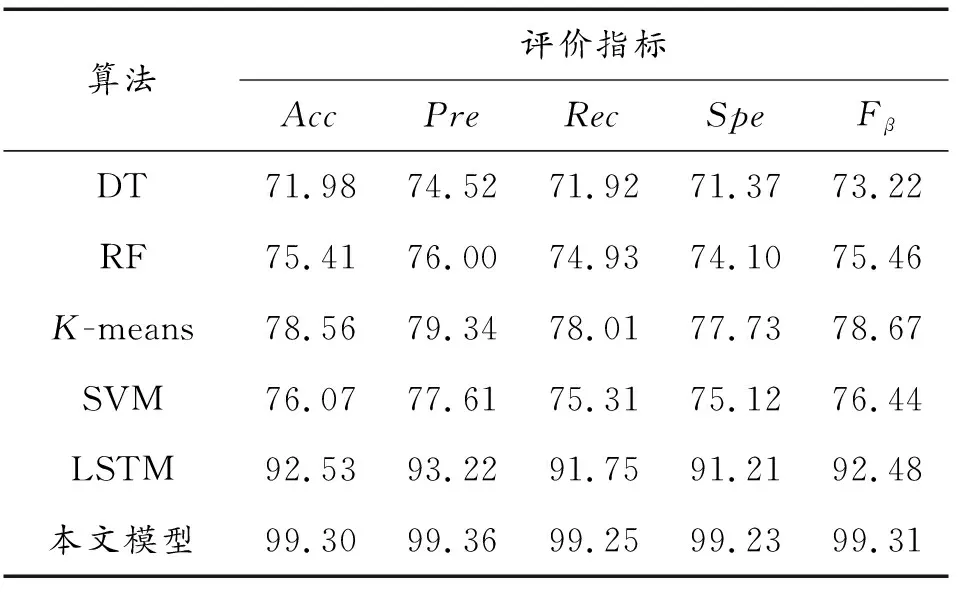
表8 NSL-KDD数据集分类效果比较
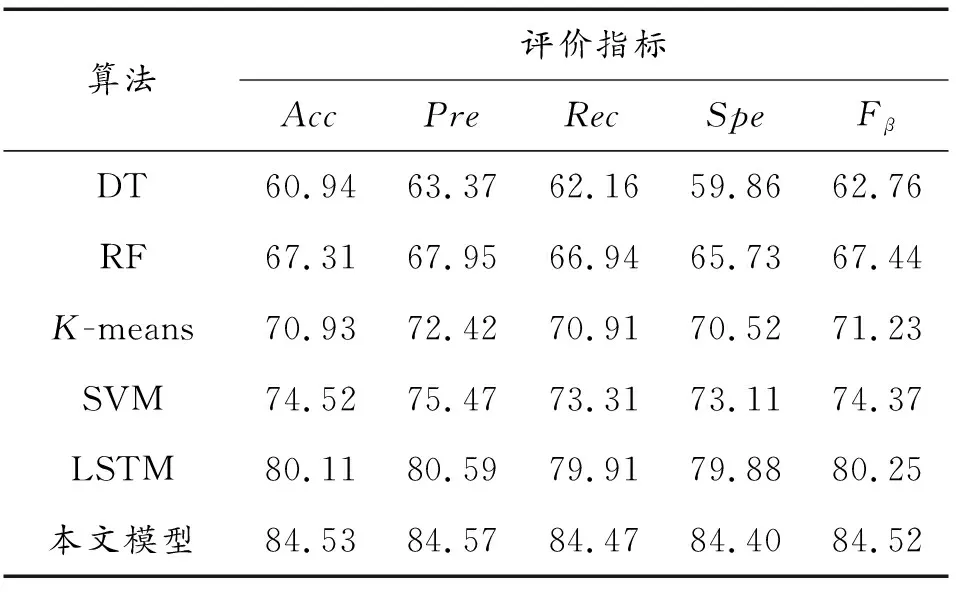
表9 UNSW-NB15数据集多分类比较
由表8和表9可知,论文提出的模型与传统的入侵检测方法相比,检测准确率获得了大幅度的提升,整体检测效果也达到了最佳水平。原因在于与决策树等传统机器学习算法相比,论文模型使用深度学习方法,能够自行对数据的深层次特征进行提取,解决了网络数据量大,机器学习特征提取困难的问题;与LSTM这类传统深度学习算法相比,论文模型使用模糊熵作为判定条件进行半监督学习,为无标签数据生成可信度较高的标签,补充数据集,弥补了监督学习方法标签获取困难,部分种类样本量不足的问题;同时使用代价敏感方法,增大模型在训练过程中对少数类样本分类错误的成本,降低误检率,也在很大程度上改善了样本不平衡问题对检测效果产生的影响。
3.3.6现有的入侵检测系统对比试验
为进一步验证基于F-CSGRU的入侵检测半监督学习方法的综合性能,本节设置性能对比实验。
在相同实验条件下,对现有文献中检测效果优越的模型,如CNN-BiLSTM[21]、SSAE-LSTM[22]、CWGAN-DNN以及AE-CGAN-RF算法根据其论文描述以及参数设置进行模型复现,并分别应用到NSL-KDD以及UNSW-NB15数据集上进行实验,其性能表现如表10和表11所示。
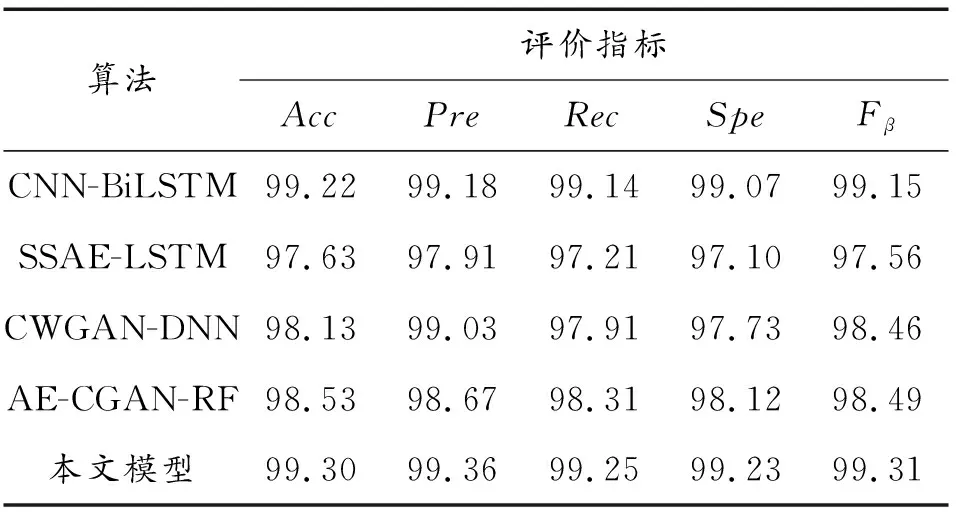
表10 NSL-KDD数据集多分类比较
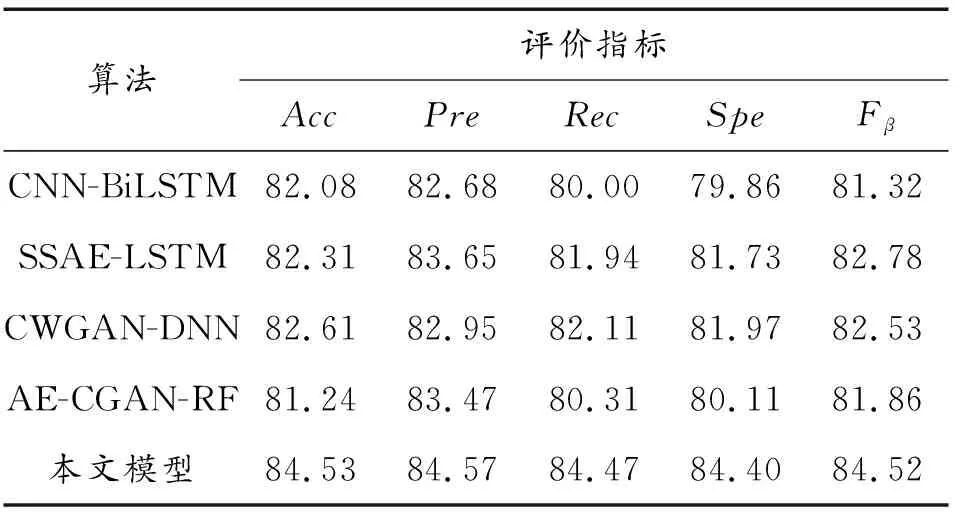
表11 UNSW-NB15数据集多分类比较
由表10和表11可知,论文提出的模型在所有指标上取得的检测效果均为最佳。原因在于与CNN-BiLSTM和SSAE-LSTM相比,论文模型使用代价敏感方法增大对少数类样本识别错误的成本,同时使用半监督方法对数据集进行补充,缓解了数据集的类不平衡问题对检测结果带来的影响,从而能够获得更好的检测效果。与CWGAN-DNN和AE-CGAN-RF相比,论文模型使用GRU进行特征提取与分类,能够从时间序列层面对数据特征进行更为深入全面的提取,从而得到的多分类效果更好。
4 结论
1) 论文提出一种基于F-CSGRU的入侵半监督学习方法。该方法将代价敏感与门控循环单元相结合,同时以模糊熵作为判定条件,进行半监督学习,在很大程度上改善了入侵检测领域标签获取难度大、成本高,且获得的样本易出现种类不平衡的问题。
2) 实验表明,论文提出的模型在NSL-KDD和UNSW-NB15数据集上的准确率能够达到99.30%和84.53%,和传统的LSTM相比分别提升了6.77%和4.42%,同时对于少数类样本的检出率也有较大提升。
3) 目前无标签数据的来源较为单一,导致论文提出的模型在UNSW-NB15数据集上的准确率仍存在较大的提升空间。下一步将重点针对这一不足之处,对入侵行为的获取以及转变方法进行研究,寻找提高检测准确率的方法。
