基于改进强化学习的多无人机协同对抗算法研究
2023-05-31侯进永
张 磊,李 姜,侯进永,高 远,王 烨
(1.中国科学院 长春光学精密机械与物理研究所, 长春 130033;2.中国科学院大学,北京100049; 3. 32802部队, 北京 100191)
0 引言
近年来,随着以机器学习为代表的人工智能技术的进一步突破,无人控制系统领域飞速发展[1],无人机和无人车广泛应用于物流配送[2]、航拍[3]、电力检修、工厂车间运输和军事侦察[4]。特别是在军事应用领域,各国都致力于研究控制无人机自主决策执行特定任务[5]。到目前为止,在自主决策空战算法研究领域,有3个主要研究方向:① 采用数学求解法,这个方法自从20世纪60年代就已经被提出,但是早年研究的任务较为简单,对于目前的复杂任务而言,具有很大的局限性,除此以外,这种方法需要严格的数学推导证明和复杂的数学模型。② 机器搜索方法[6],典型的方法有蒙特卡洛搜索[7]、决策树等,该类算法根据无人机所面对的不同情形进行态势评估并对威胁目标进行排序[8],最后根据评估结果和威胁目标排序进行动作决策[9],机器搜索方法的核心在于专家经验,所以要求研究人员具有很强的战场经验,模型泛化能力较弱,且难以应对复杂多变的战场情况。③ 处于研究前沿的深度强化学习方法,利用智能体的不断试错提升动作决策水平。
2013年DeepMind发表了一篇利用强化学习算法玩Atari游戏的论文,强化学习真正意义走上了大众舞台。
不同于监督学习,强化学习不需要大量已标记的数据,只需通过与环境交互进行大量的强化训练[10]。当面对不同的环境状态,智能体会根据算法选择不同的动作,环境会根据所做的动作更新下一个环境状态,同时还会根据不同的动作给予智能体一个奖励值。智能体训练的目标就是使得总奖励值最大,经过大量的训练,智能体将一步步优化决策策略。深度强化学习是强化学习的进一步发展,是与深度学习的有机结合。利用神经网络拟合策略函数或者价值函数,从而达到控制要求。相较于强化学习,深度强化学习更能胜任连续动作和复杂的任务[11]。
现如今,强化学习逐步应用于游戏、自动驾驶决策、推荐算法等领域。根据环境中智能体的数量,强化学习划分为单智能体强化学习和多智能体强化学习[12]。单智能体强化学习是指环境中只有一个智能体需要进行动作决策,AlphaGo就是典型的单智能体算法。由于环境中只有一个智能体进行决策,状态转移简单,控制相对容易。无人机群协同自主对抗属于多智能体强化学习,环境中存在多个智能体,竞争关系、合作关系以及合作竞争关系等复杂的关系存在于各个智能体之间。随着智能体数量的增加以及智能体之间的复杂关系让强化学习任务变得愈发困难。目前主流的单智能体强化学习算法包括DQN[13]、DDPG[14]、PPO[15]、A3C[16]等,主流的多智能体强化学习算法包括MADDPG[17]、QMIX[18]、VDN[19]等。
目前强化学习技术在无人机自主决策领域被广泛研究,在多无人机协同搜索、路径规划和编队控制等研究中,已经获得了不俗的成果[20]。
文献[21]提出了一种基于深度强化学习的任务动态分配方法。该方法使无人机进行实时交互,对任务执行的优先级顺序和执行时间加以约束,提高了有限时间内总体的任务完成度。文献[22]提出一种基于深度确定性策略梯度算法的改进算法,提高了算法训练速度以及无人机在导航过程中对环境的适应能力。文献[23]提出了一种多机协同空战决策流程框架,该框架提高了在多架无人机协同对抗场景下智能体间的协同程度。
结合现有的成熟算法研究以及目前所遇到的工程项目难题,发现现有算法在工程应用中存在了以下的不足之处:
1) 随着实验环境中无人机数量的增加,算法适应能力下降,任务完成度低,且精度不高。
2) 状态空间和动作空间过于庞大,经验回收池中有效经验较少,有时候会出现不收敛的问题。
3) 训练时间过长,且收敛效果不理想。
针对目前算法的不足之处和实际的工程项目需求,作者在现有多智能体算法MADDPG的基础上,在经验存储过程中引入了选择性经验存储机制,设置经验回收标准以及选择性因子。并根据实际任务环境合理设定奖励函数,最后通过仿真验证,证明了改进后的算法相较其他强化学习算法,在保证算法时间复杂度的前提下,有了更好的收敛效果。
1 任务描述及模型建立
1.1 任务描述
红蓝双方展开军事对抗仿真,红方出动无人机集群,无人机具有侦察和干扰功能,蓝方阵地布设雷达、空中预警机和防空导弹发射系统。红方的任务为出动无人机集群对蓝方雷达进行协同侦察,确定蓝方雷达位置,并对雷达进行协同干扰,掩护后方轰炸机进入投弹区域。无人机群自主决策飞行路线,自主分派干扰任务,并快速完成既定任务要求。蓝方的任务为阻挡红方的进攻并保护指挥部,在指挥部周围布设地面雷达和火力打击系统,并在空中布设预警机一架,围绕蓝方阵地进行飞行预警。场景示意图如图1所示。
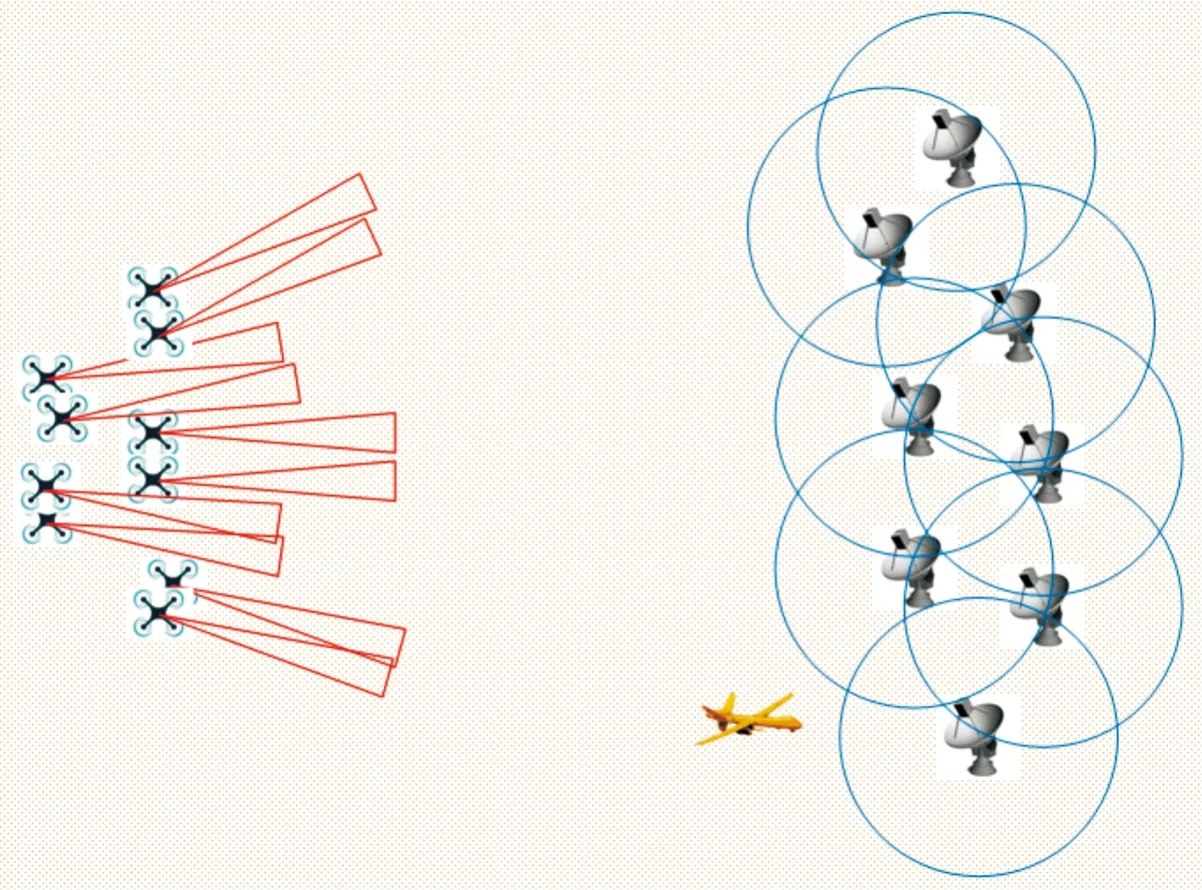
图1 对抗过程示意图
1.2 模型建立
1.2.1红方模型的建立
红方无人机群在执行任务时,受到包含风力、天气状况、地形地貌等自然因素的影响,以及蓝方防空雷达、预警机以及地面火力单元的威胁。构建智能体训练环境所需的计算模型概述如下。
红方无人机侦察到蓝方雷达信号的概率为:
(1)
式中:ξ为目标的横坐标;ζ为目标的纵坐标。该公式表示在时间(t0,t1)内发现目标的概率。
1.2.2蓝方模型的建立
蓝方地面雷达侦察到红方的概率:当目标进入到雷达的探测区域后,雷达不一定发现目标,目标只是存在一定的概率会被发现。这个概率取决于雷达与目标发生直接的能量接触。一般而言,雷达的技术性能、目标的反射面积、目标的飞行高度与距离、雷达阵地(天线)高度等是影响目标被发现的主要概率。通常雷达有多种工作方式,为讨论方便,这里仅针对雷达的慢速扫描和快速扫描进行讨论[24]。
1) 雷达慢速扫描。
当雷达慢速扫描时,可将雷达对目标的探测视为离散观察,此时雷达的发现概率PD为:
(2)
式中:m为在持续搜索时间t时间段内,雷达与探测目标的接触次数,可按式(3)计算;Pdi(1≤i≤m)为第i次与目标接触时的发现概率。
m=「t/tsearch⎤
(3)
式中,tsearch为雷达的周期[24]。
在无电子干扰条件下,Pdi(1≤i≤m)的计算表达式为:
(4)
式中:n0为一次扫描的脉冲累积数;SNi为第i次与目标接触时单个脉冲的信噪比[24]。
2) 雷达快速扫描。
当雷达快速扫描时,可视为连续观察,在无干扰的情况下,雷达对点目标的发现概率为:
(5)
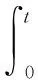
(6)
令y0+Vδt=X0tanφ,则
(7)
在该段上发现目标的概率为:
PX0=1-e-U(x0)
(8)
单发防空导弹打击的概率为:
(9)
式中:Wd为导弹的战斗部质量;σd为没有干扰情况下导弹精度误差的均方差值;α、β、γ为比例系数,在此α取0.6,β取0.5,γ取0.7。
2 MADDPG算法与SES-ADDPG算法
2.1 MADDPG算法
多智能体强化学习以马尔科夫决策过程(MDP)作为算法的研究基础,可以利用一个高维元组(S,A1,…,An,R1,…,Rn,P,γ)进行描述。其中S是马尔科夫决策过程的状态集合,n代表智能体的数量,A1,…,An代表各个智能体所选择的动作,R1,…,Rn代表每个智能体的收到环境给予的奖励回报,P代表状态的转移函数,γ代表折扣率。
多智能体深度确定性策略梯度(multi-gent deep deterministic policy gradient,MADDPG)算法是OpenAI团队在2017年提出的专门用来解决多智能体问题的算法,该算法可应用于合作、竞争以及竞争合作等多种环境场景下。它可以使多个智能体在高维度、动态化环境下通过智能体之间的通信以及智能体与环境之间的交互。能够使得多个智能体协同决策完成较为复杂的任务,是分布式计算方法在多智能体领域的优秀应用。除此之外,还能利用其他智能体的观测信息进行集中训练。训练过程采用集中训练,分散执行(centralized training with decentralized execution)的算法思想[17]。
MADDPG是单智能体强化学习算法在多智能体领域的扩展,系统中的每个智能体都采用DDPG框架,每个网络学习策略函数(policy)πactor和动作价值函数(action value)Qcritic;同时具有目标网络(target network),用Q-learning算法的异策略(off-policy)学习。Q值计算公式为:
Q=Q(st,a1,a2,…,an,θ)
(10)
每个智能体都有一个Actor和Critic网络,当训练Actor网络时给予Critic更多的信息(其他智能体的观测信息以及动作信息),而在测试时去掉Critic部分,使智能体在得到充分的训练之后,可以只通过Actor获取自己下一步的动作。这种获取全局信息的训练策略,可以避免像Q-Learning、Policy Gradient等单智能体算法直接迁移到多智能体环境下,由于只能获取自己的状态和动作,而产生的环境不稳定、经验回放失效等问题。MADDPG算法能够使得每个智能体所面临的环境仍然可以视为稳定的,其原因为,系统的动力学模型可以描述为:
P(s′∣s,a1,a2,…,an,π1,π2,…,πn)=
P(s′∣s,a1,…,an)=
(11)
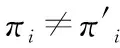
利用θ=(θ1,θ2,…,θn)代表n个智能体策略函数的参数,用π=(π1,π2,…πn)表示n个智能体的策略函数[25]。针对第i个智能体,我们把累计奖励期望值定义为:
(12)
式中:γi为第i个智能体的奖励;γ为折扣率。
针对随机策略梯度,求解策略梯度的公式为:
(13)
式中:oi为第i个智能体的观测值;s=[o1,o2,…,on]为所观测的向量,也就是状态。
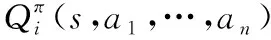
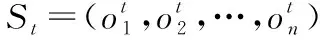
系统的损失函数定义为:
(14)
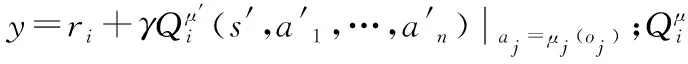
对于actor网络,参数的更新公式为:
θu=θu+αu▽θπJ
(15)
(16)
其中:θμ为actor网络的参数值;αμ为actor网络的学习率。
2.2 SES-MADDPG算法
选择性经验存储策略的多智能体深度确定性策略梯度(selective experience storage multi-agent deep deterministicpolicy gradient,SES-MADDPG)算法是MADDPG算法的改进提升。经过前期仿真实验可知,随着环境系统内智能体的数量增加,状态空间爆炸式扩张,导致算法训练时间延长,算法的奖励值收敛缓慢或者收敛值不理想。MADDPG算法流程中存在经验池机制,智能体与环境交互产生的经验被存入经验池中,经验池里的经验将会被二次抽取,重新用于训练。经验池无保留地存储了所有的经验,其中高质量的经验便于算法的快速收敛,低质量的经验将不利于算法训练。其中低质量的经验占大多数,采用随机抽取将会抽取大量的低质量经验,因此将会消耗了大量的训练时间。前人研究者们为了改善这种问题,提出了一种优先经验抽取的机制[27],该机制为了抽出更好的经验,不再采用随机抽取,而是将进入经验池的经验根据损失进行排序,损失越大,排序越靠前。这种改进可以优先抽取高质量经验,加快算法的收敛速度,但是该机制存在时间复杂度较高的问题。每当一条新的经验进入经验池,该经验将会与经验池里的其他经验进行排序,排序的时间复杂度较高,大大增加了系统开销。
一方面为了改善经验优先回放算法时间复杂度过高的问题,另一方面需要控制经验池中经验的抽取。除了控制抽取的过程,还可以控制经验存储经验的过程。在经验回收存储时,并非无选择性地将交互产生的经验逐条存储至经验池内,而是设立经验回收标准,回收标准的具体数值应该根据奖励函数和实际问题进行设定。对于每条经验里的奖励值参量,对其求累积均值,当均值大于回收标准时,该条经验将会被存入经验池中 ,当小于回收标准时,系统产生0~1的随机数,当随机数小于选择性因子时,该条经验将会被存入经验池。该经验选择机制,既保证了对低质量经验的过滤,又避免了训练初期经验池内缺乏经验数据。除此之外,该算法实现简单,算法的时间复杂度为常数级别,有效地减轻了系统的开销。算法基本框架示意图如图2所示,SES-MADDPG算法示意图如图3所示。
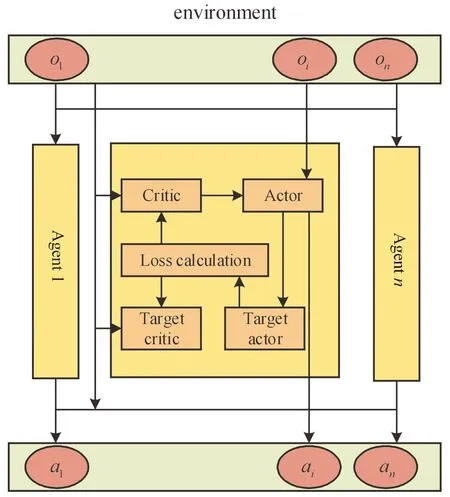
图2 基本算法框架示意图
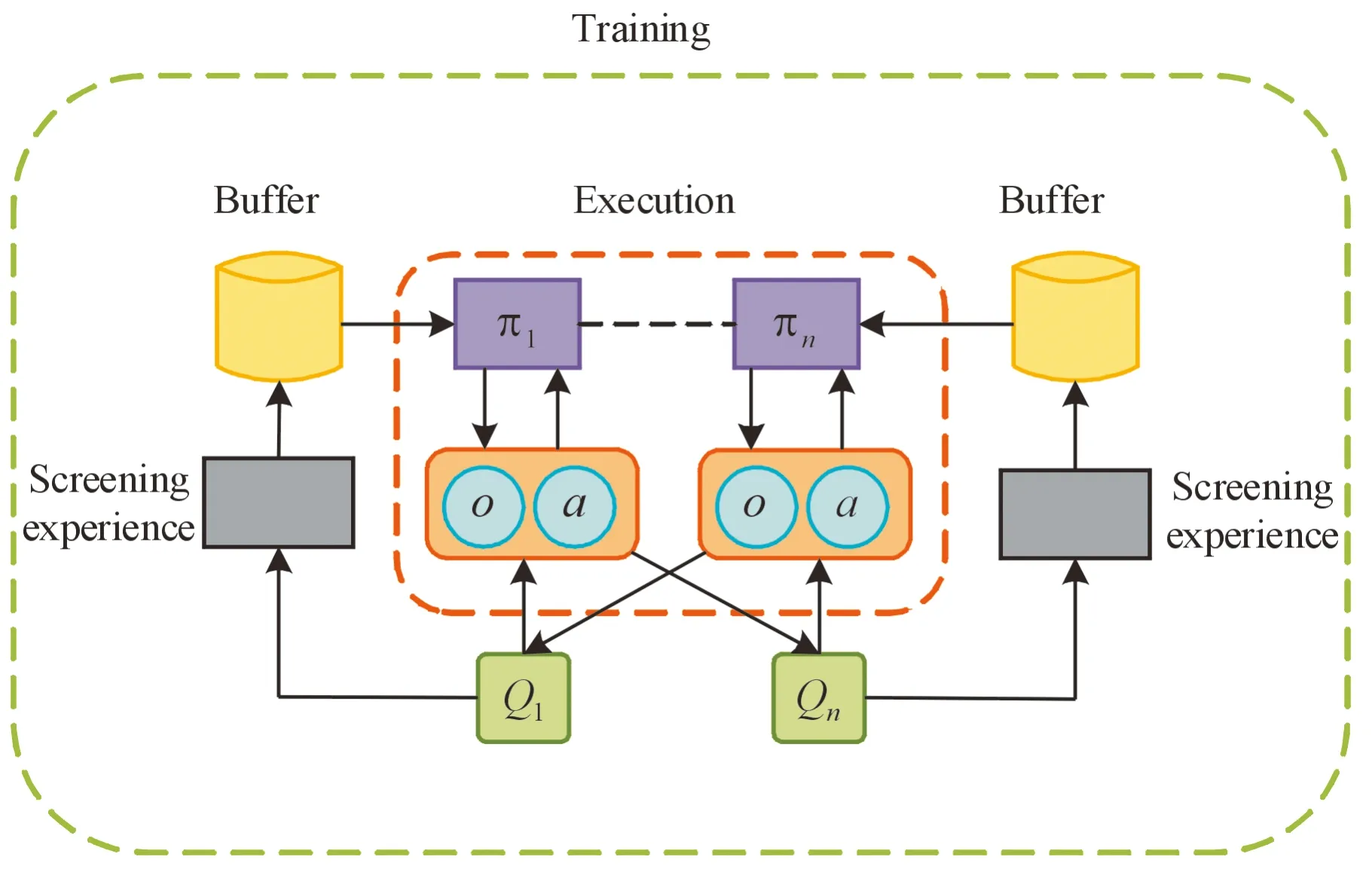
图3 SES-MADDPG算法示意图
算法的伪代码实现如下。
对超参数进行随机初始化
对价值网络和策略网络的参数进行随机初始化
对目标价值网络和目标策略网络的参数进行随机初始化
初始化经验池D和动作噪声Nt
for episode from 1 to num_episode do:
对环境和所有智能体的状态集合进行随机初始化
for step from 1 to max_episode_length do:
对于每个智能体进行动作选择,其中ai=μθi(oi)+Nt
执行动作a=(a1,…,an),环境给与奖励r,进入下一个环境s′
获得到一条经验(s,a,r,s′)
if (r>W):
存储经验进入经验池D
else:
if(random(0,1 )<β):
存储经验进入经验池D(其中W是回收标准,β是选择因子)
结束if判断语句
结束else判断语句
更新环境s←s′
for agent from 1 tondo:
从回收池随机抽取一条经验(s,a,r,s′)
根据目标评估网络计算每个动作的期望回报y
通过最小化损失更新critic网络的参数
使用随机梯度下降更新actor
结束(agent) 循环
对于每个智能体更新目标网络参数
θQ′=τθQ+(1-τ)θQ′
结束(step)循环
结束(episode)循环
3 基于SES-MADDPG的协同对抗算法
3.1 状态空间的设计
本文中将无人机集群侦察、干扰敌方雷达的问题求解过程抽象为序列化决策过程,将作战环境中每个无人机视为一个智能体。强化学习的训练目标是构造一个智能网络模型,在每个状态都能做出决策,在避免被敌方发现的情况下,实现对敌方雷达的侦察与干扰。为了减少维度,训练环境在二维空间内进行。
无人机群的状态空间分为2个部分:第一部分为环境状态空间S,代表了总体的环境状态;第二部分是智能体的观测状态O,代表了无人机自身的状态以及对环境的捕获数据。分别如表1和表2所示。
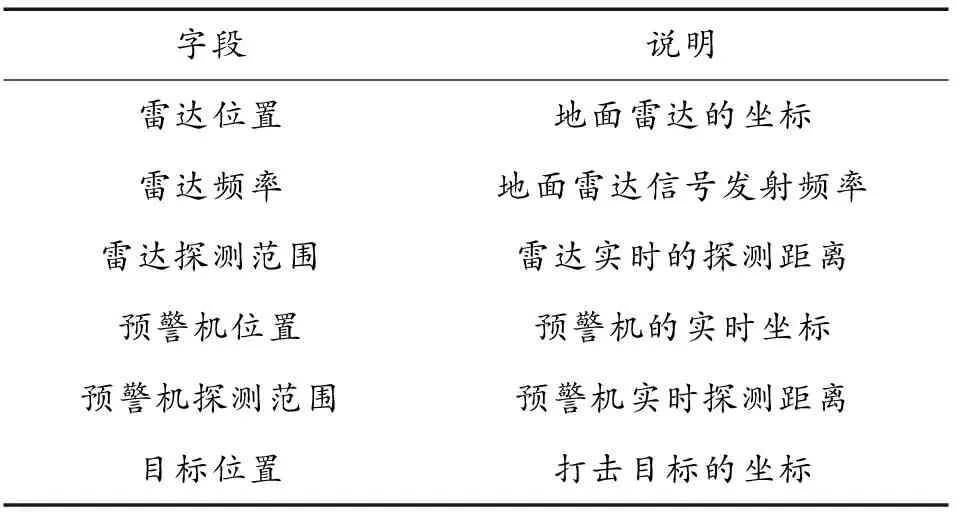
表1 环境状态空间
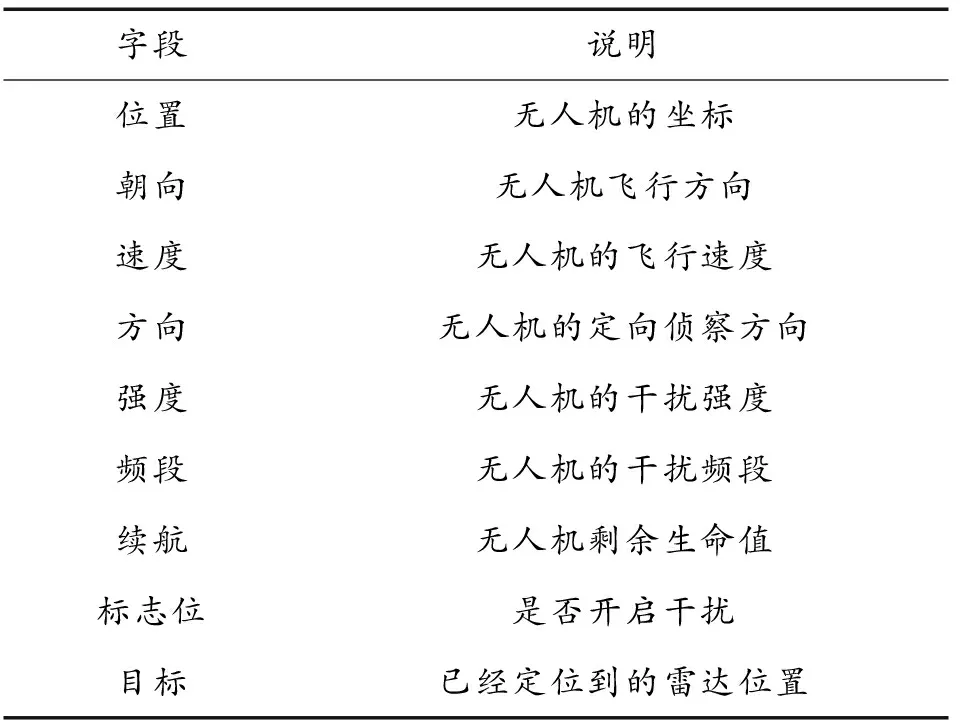
表2 智能体观测状态空间
3.2 动作空间的设计
为了减小动作空间的维度,对部分动作做了离散和简化处理,具体动作可分为以下6个方面。① 飞行动作:无人机的飞行动作可以选择前、后、左、右和悬停等5个飞行动作。② 飞行速度:无人机的飞行速度可以选择低速、中速和高速等3个飞行速度。③ 定向侦察方向:无人机的定向侦察方向可以选择左前方、正前方和右前方等3个方向。④ 定向干扰强度:无人机的定向干扰强度可以选择不开干扰、低强度、中强度和高强度等4个强度。⑤ 干扰频段:无人机的干扰频段可以选择低频段(0.03~1 GHz)、中频段(1~15 GHz)和高频段(15~30 GHz)等3个频段。⑥ 干扰目标:无人机可以选择7个雷达的任意一个,共有7个选择目标。
根据以上6个方面进行动作组合选择,可产生3 780种不同的动作,即为动作空间,所有的动作选择采用独热编码格式。
3.3 奖励函数的设计
强化学习的目标是要获取最大的奖励值,根据任务场景设定奖励值,将有利于完成任务的状态设置正奖励值,将不利于完成任务的状态设置负奖励值。
由于无人机群之间需要协同完成任务,如果距离太远,将无法完成通信,因此需要设置无人机之间的距离奖励。
(17)
式中:D(i,j)为无人机i和无人机j之间的距离;(xi,yi)为无人机i的坐标;(xj,yj)为无人机j的坐标。
无人机之间的距离奖励为:
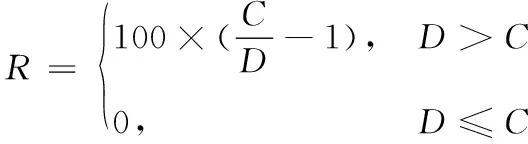
(18)
式中,C为无人机之间的通信距离。
接近目标区域的奖励为:
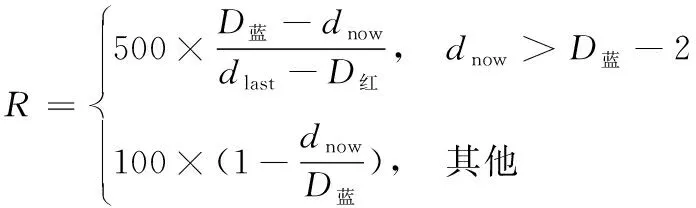
(19)
式中:D蓝代表蓝方雷达的探测距离;dnow代表此时无人机与蓝方雷达中心的距离;dlast代表上一时刻无人机与蓝方雷达中心的距离;D红代表无人机的探测距离。
被雷达发现的奖励为:
R=-10
(20)
发现雷达的奖励为:
R=20
(21)
对雷达的干扰奖励为:
(22)
式(22)中:D蓝now代表被干扰后雷达的探测距离;D蓝代表雷达最大的探测距离。
无人机被火力击落的奖励为:
R=-100
(23)
开辟投弹区域的奖励为:
R=200
(24)
4 仿真实验
4.1 仿真环境介绍
为了验证由SES-MADDPG算法控制的无人机集群在战场对抗的有效性,在自建的多无人机智能对抗仿真推演平台进行对比实验验证。该仿真平台以海上登陆战为作战背景,以固定空域为作战环境,红方无人机集群在前方负责对蓝方的地面雷达和空中预警机进行侦察、干扰,为后方的轰炸机开辟投弹通道,使之顺利进入投弹范围进行投弹,对蓝方阵地进行火力打击。该仿真模拟环境选取了1 000 km×850 km的空域范围作为作战区域,以1 km为一单位进行划分,将整个作战区域划分为1 000 km×850 km的网格区域,便于多无人机集群在此区域进行飞行动作模拟和侦察动作模拟等。红方配备由10架侦干一体机构成的无人机集群,通过强化算法进行自主决策。蓝方配备7台地面雷达,1架空中预警机和数发航空导弹,其中地面雷达位置固定,预警机绕蓝方阵地作“8”字形或者沿跑道飞行。
红方无人机集群需要自主决策飞行路线,自主选择侦察方向等,对雷达进行侦察,同时锁定雷达位置,并对其进行干扰,为后方的轰炸机开辟投弹通道(即通道内无雷达探测信号覆盖)。
4.2 仿真实验设置
在自建的多无人机智能对抗仿真推演平台分别采用DQN算法、DDPG算法、MADDPG算法和SES-MADDPG算法进行 20 000个实验周期的训练。每个周期的最大时间步为1 900步,当环境内的无人机个数不满足完成任务的最低个数或者任务提前完成时,该实验周期将会提前结束。通过对4种不同的算法进行对比,对算法进行评价比较。
以每个实验周期内的累积奖励以及任务的完成率作为评价指标。由于长机的设置与其他无人机稍有区别,因此当对比每个实验周期的奖励时,不仅比较10架无人机的平均奖励,也对长机获得的奖励进行单独比较。实验代码中部分超参数如表3所示。
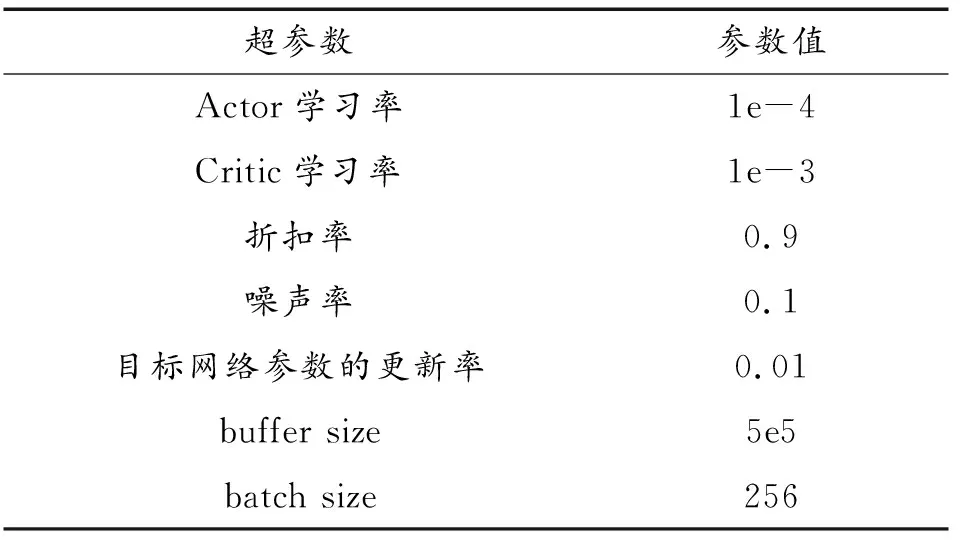
表3 超参数
5 仿真实验分析
5.1 训练奖励值分析
在自建的多无人智能仿真推演平台分别使用了DQN算法、DDPG算法、MADDPG算法和SES-MADDPG算法进行20 000个周期的训练。其中图4为集群内所有无人机平均奖励的对比图片,图5为长机平均奖励的对比图片。由图4、图5中可以看出,大约5 000个周期后,训练过程进入了较为平稳的收敛状态。MADDPG算法和SES-MADDPG算法的奖励收敛值明显高于DQN算法和DDPG算法。其中SES-MADDPG算法的收敛效果最好,相较于没有选择性回收机制的MADDPG算法,收敛值有了一定的提升。
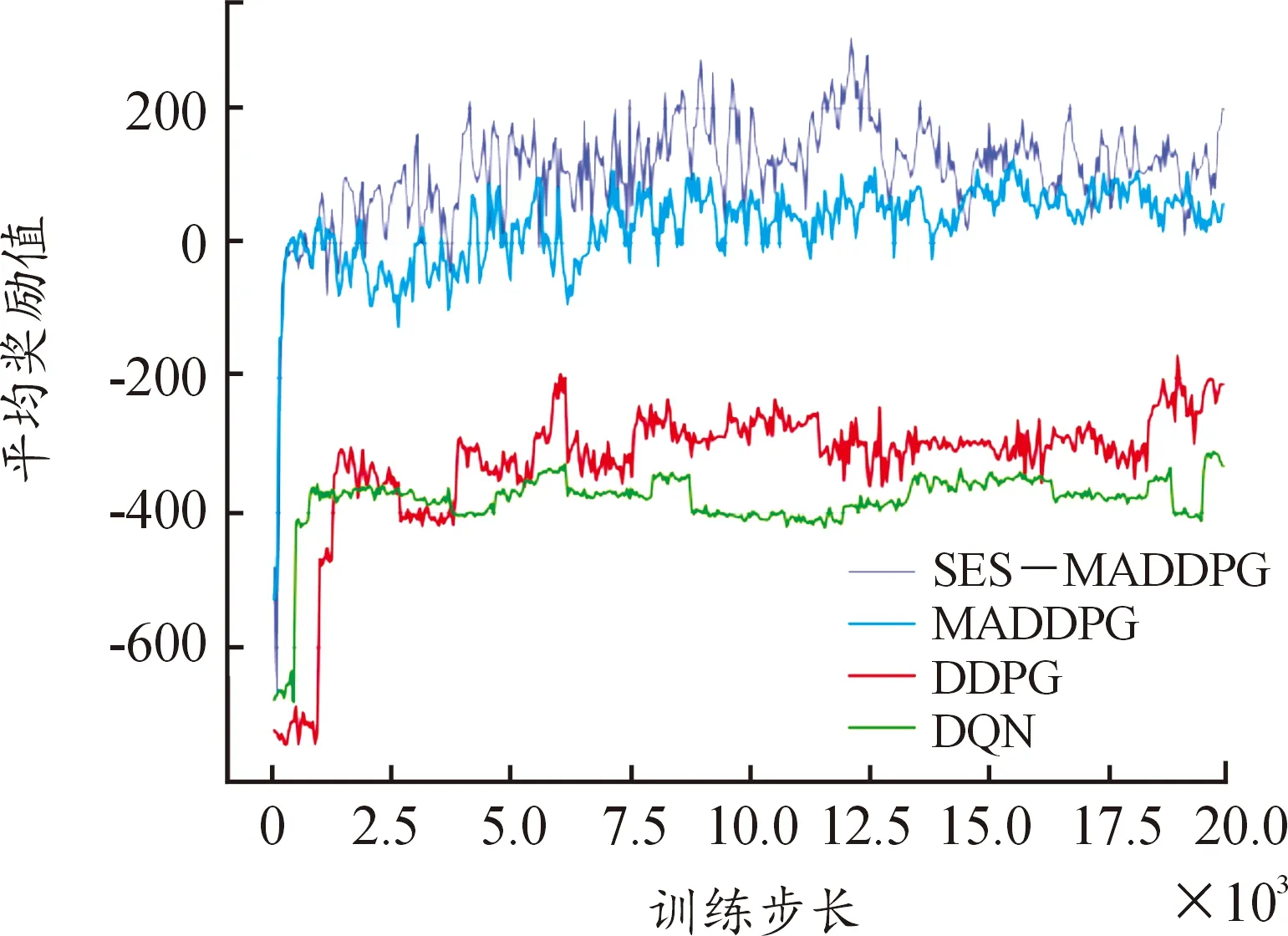
图4 所有无人机平均奖励对比图

图5 长机的奖励对比图
表4和表5分别展示了不同强化学习算法在20 000个实验周期内的每架无人机的平均奖励和长机的奖励,由实验数据可看出,DQN和DDPG算法的平均奖励值均为负数,而SES-MADDPG算法的奖励值在100左右,远远高于其他的算法,充分证明了该算法的优越性。

表4 每架无人机前20 000轮的平均奖励对比

表5 长机前20 000轮的平均奖励对比
评估算法好坏的另一种方式是任务的完成度,为了避免训练前期收敛值不稳定对实验产生的影响,分析了后10 000个实验周期的任务完成情况,如表6所示,展示了在10 000次的训练过程中,成功完成任务的次数。虽然任务的完成率不高,但是相较于MADDPG算法,任务完成率提高了25.427%。
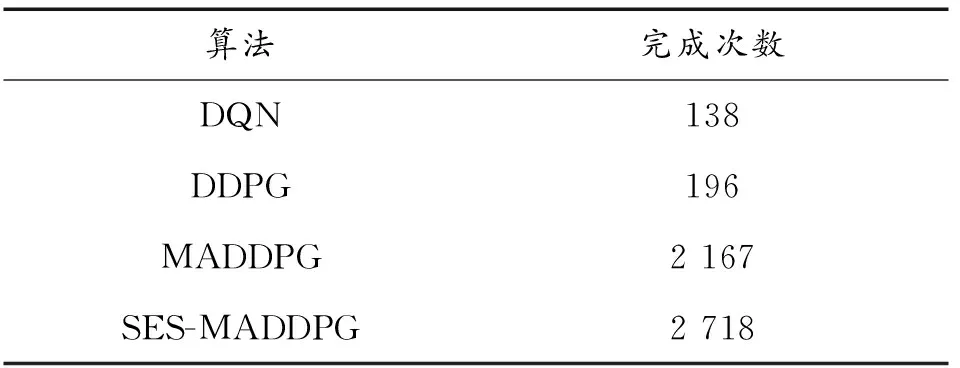
表6 任务成功完成的次数
5.2 单次仿真可视化结果分析
利用SES-MADDPG算法经过20 000次训练后得到的模型,执行单次仿真推演进行效果的可视化评估分析。
可视化演示如图6所示。图6(a)为仿真开始,10架侦干一体机构成的集群做好出发准备,设置0号为长机。图6(b)集群内的无人机试探前进,对范围内的信号进行扫描探测。图6(c)无人机集群进入蓝方阵地,开始对雷达进行分散探测定位。图6(d)无人机确定雷达方位,对雷达进行持续干扰,被干扰后的雷达的探测范围大大降低。图6(e)集群内无人机团结协作,在蓝方阵地开辟出投弹通道,任务成功结束。
图7为DQN算法模型经过20 000次训练后得到的无人机运动轨迹图,图7中蓝色点代表雷达的位置。有4架无人机被蓝方雷达发现并被击毁。其余无人机没有进行有效的侦察和干扰,运动无规律性,仅仅在某个区域进行徘徊。图8为SES-MADDPG算法模型经过20 000次训练后得到的无人机运动轨迹图,从图8中可以看出,在未发现雷达前,无人机集群试探性前进,当发现蓝方雷达后,0号无人机绕着蓝方阵地进行往复移动,其目的是对运动的侦察机进行持续性干扰。其余的无人机各自进行任务分配,对蓝方的地面雷达进行持续性干扰,最后成功压制了雷达的探测范围,为轰炸机开辟了投弹通道。
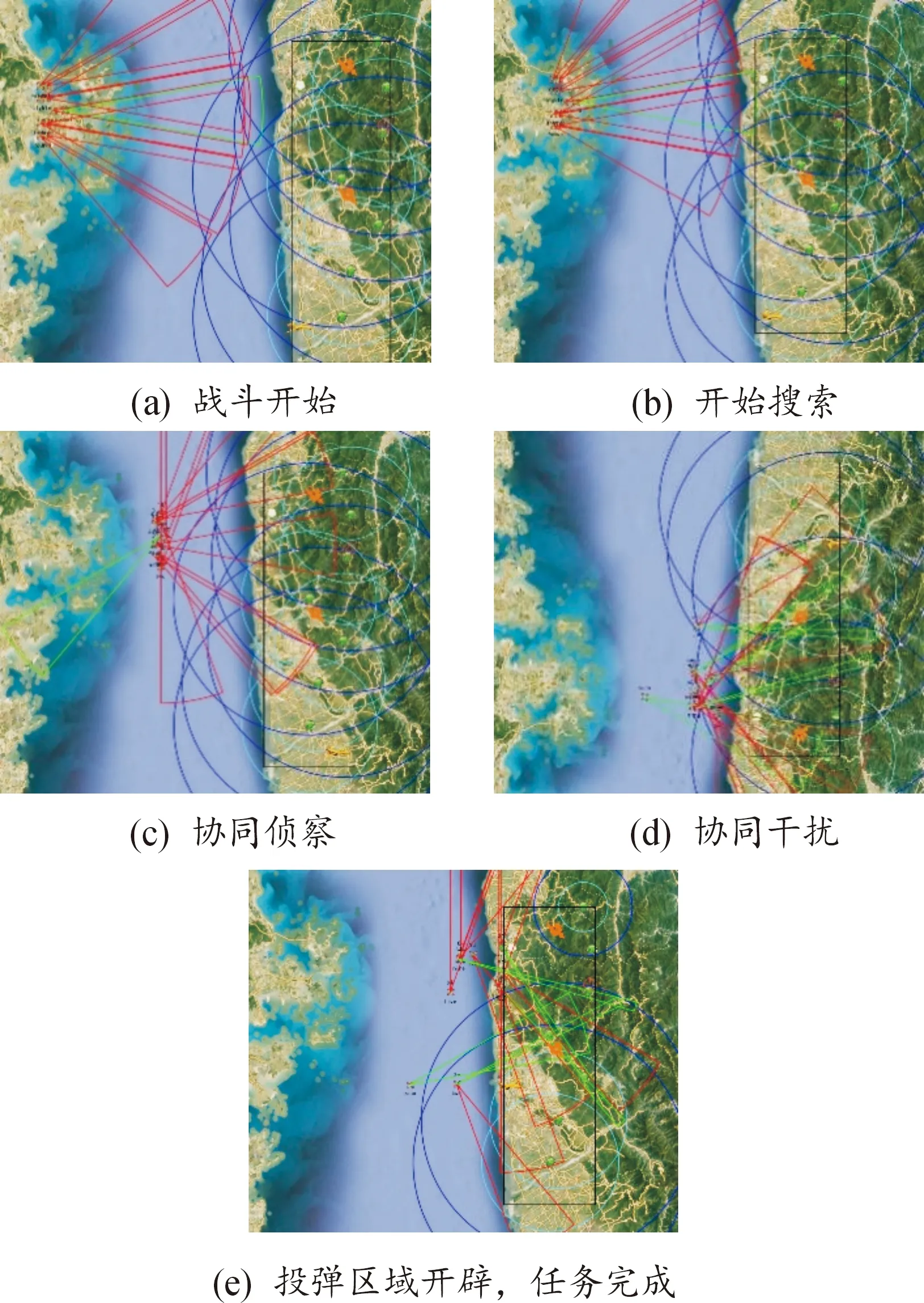
图6 对抗的仿真结果
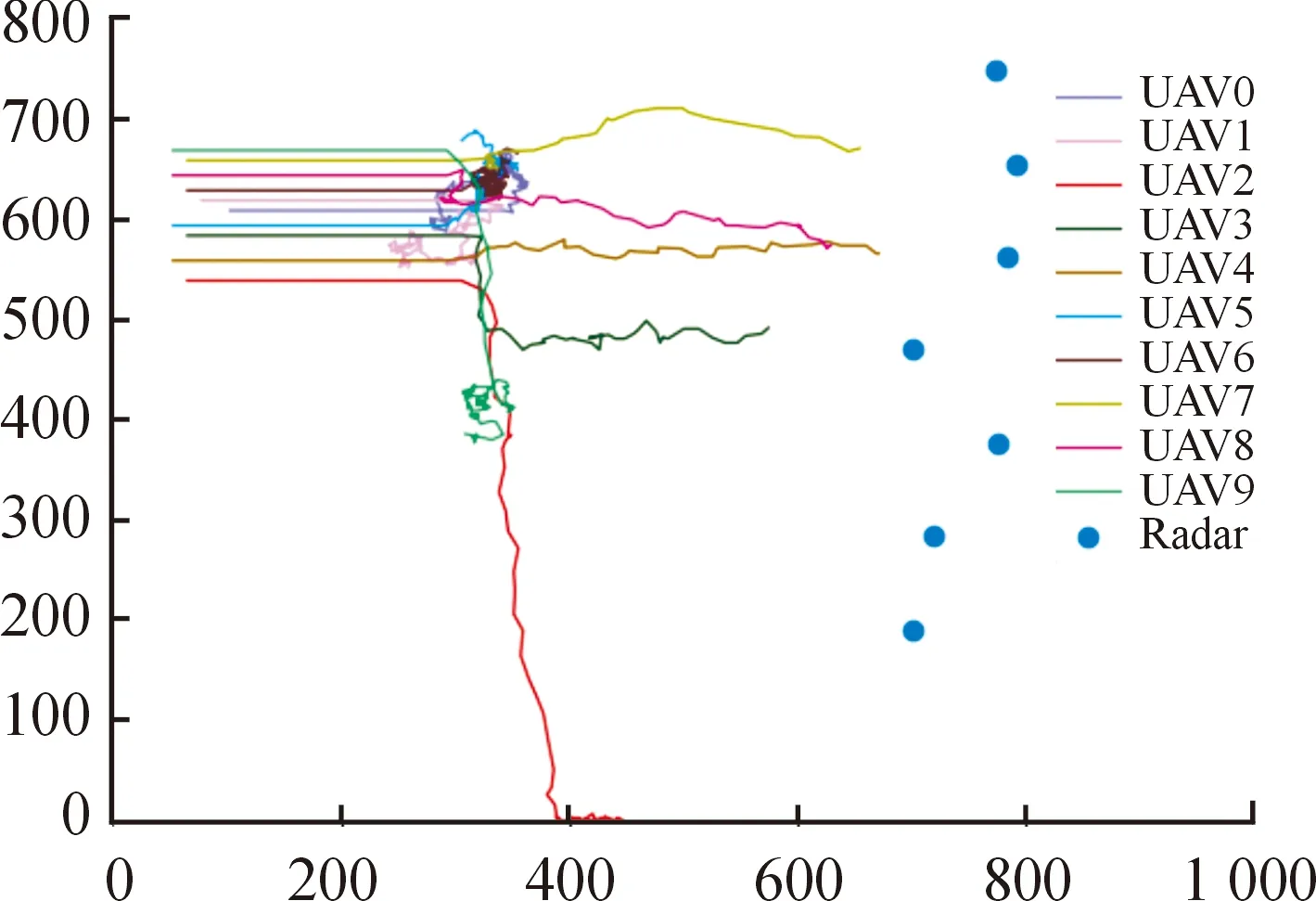
图7 基于DQN算法的无人机飞行轨迹
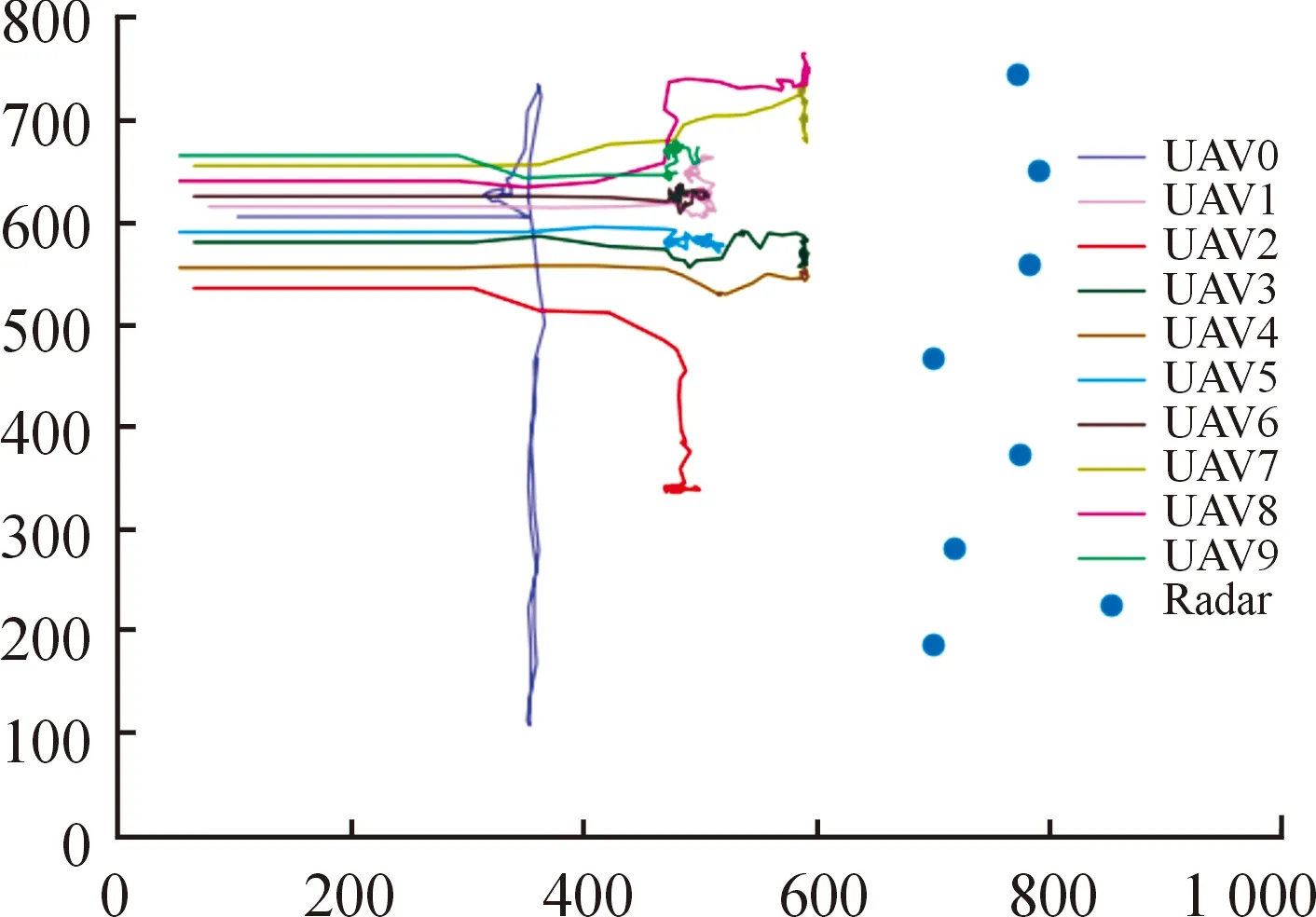
图8 基于SES-MADDPG算法的无人机飞行轨迹
6 结论
针对红蓝对抗问题,将深度强化学习算法引入到无人机集群协同侦察、干扰雷达的任务中。为了解决收敛效果差、任务完成率低的问题,在MADDPG算法的基础上,加入选择性经验回收机制,提出了SES-MADDPG算法。仿真实验结果表明:SES-MADDPG算法比其他几种强化学习算法具有更好的收敛效果,同时任务完成率相较于MADDPG算法提高了25.427%。
该算法虽然提高了收敛效果和任务完成率,但是会存在一定概率陷入局部最优的情况。下一步研究方向:一方面要克服陷入局部最优的缺陷,另一方面将该算法的环境推广至三维空间环境中。
