基于双层随机森林的空袭目标识别
2023-05-31卢盈齐范成礼
李 威,卢盈齐,范成礼
(空军工程大学 防空反导学院, 西安 710000)
0 引言
空袭目标识别作为防空作战中目标分析判断的首要任务也是指控决策的关键环节,能够为拦截决策中的目标威胁判断排序和目标火力分配提供重要依据。因此,快速而又准确地识别出空袭目标的类型对防空作战指挥控制具有十分重要的意义。
目前,对于空袭目标类型的识别算法主要包括D-S证据推理[1-2]、贝叶斯网络[3-4]、聚类算法[5-6]、多属性决策[7]、支持向量机(SVM)[8]和模糊神经网络[9]、BP神经网络[10]、概率神经网络(PNN)[11]等神经网络类算法等。其中D-S证据推理存在高冲突证据组合和证据独立性问题;贝叶斯网络在对飞行高度、速度和发现距离等连续性数据进行离散化处理的过程中存在主观性较强的问题;神经网络模型对于样本数据量要求较高,且普遍存在收敛速度较慢和容易过拟合的缺点,而SVM虽然具有较强的泛化能力,但参数的调试以及核函数的选择是一大难点,不同核函数和参数的选择对于识别结果差异较大。
随机森林(Random Forest)属于机器学习[12]中的有监督学习,是通过集成学习的思想将多个决策树进行集成的一种算法,在处理分类问题上具有准确率高、泛化能力强和对于数据集要求低等优点,因此较为适合解决空袭目标识别问题。但由于战场传感器能够获得空袭目标的飞行高度、飞行速度、发现距离、加速度、RCS、航线特征和电磁辐射等较多的识别特征因素,如果将全部特征代入模型容易影响目标的识别性能模型,尤其是无用的特征会对识别过程造成干扰,进而降低目标识别的准确率、稳定性和识别速度,因此需要对特征进行筛选,去除冗余特征,选择对于识别模型更加重要的特征。但目前的识别方法往往依靠主观经验选择特征,存在主观性强、可解释性差以及忽略了特征与模型的适应性等缺点。
本文根据传统经验和归纳分析,提取了空袭目标的飞行高度、飞行速度、发现距离、加速度、RCS、航线特征和电磁辐射等常见的因素作为识别特征,并在传统随机森林的基础上进一步充分挖掘数据中的信息,通过计算基尼指数变化量对特征进行重要性评估和降维,提出了基于双层随机森林的空袭目标识别算法,并通过仿真实验与传统随机森林、神经网络模型和SVM进行对比分析,证明了该算法在提高空袭目标识别的速度和准确率上的有效性。
1 随机森林概述
随机森林[13-14]是一种基于集成学习的组合分类算法,首先采用Bootstrap重采样的方式从样本数据进行有放回的抽样,然后用抽取的样本构建决策树,在以决策树为基学习器构建Bagging集成学习的基础上,进一步在决策树的训练过程中加入了随机属性选择,最后通过投票得到最终的分类和预测结果。其算法结构如图1所示。

图1 随机森林算法结构
1) 决策树的基本思想是构造一个类似流程图的树形结构,首先从根节点开始通过基尼指数选择最优划分属性,在非叶子节点进行属性值的对比测试,然后根据测试结果确定相应分支,最后在叶子节点得到类别结果。决策树的结构如图2所示。
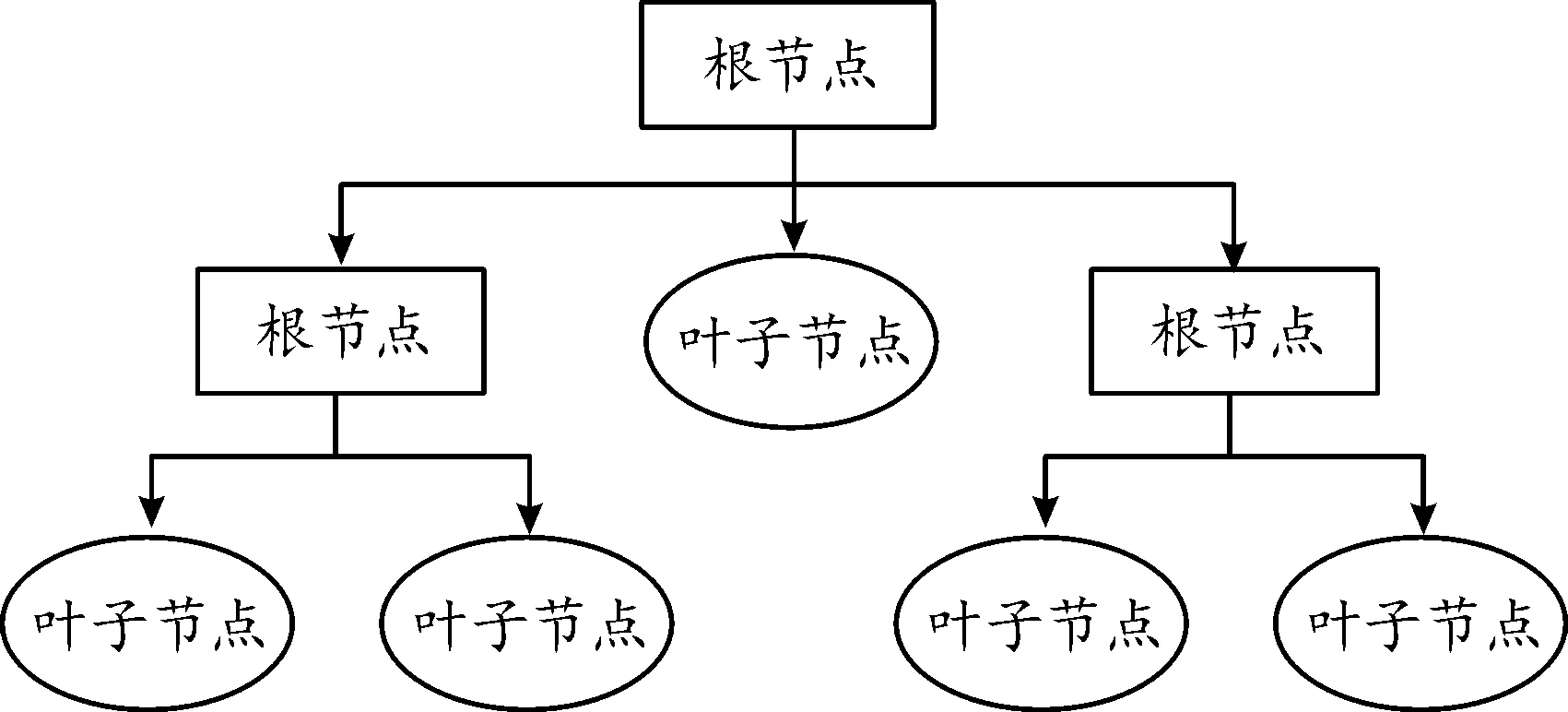
图2 决策树结构
2) Bootstrap的基本思想是在给定包含n个样本的原数据集中,每次有放回地从原数据集中随机抽取一个样本,将其拷贝放入新的数据集,然后将该样本放回原数据集中,此过程重复n次后,得到一个包含n个样本的新数据集。
3) Bagging集成的基本策略是首先利用Bootstrap采样随机生成T个训练集,然后基于每个采样集训练出一个对应的基学习器,然后将测试集放入每个基学习器进行测试分类,最后采取投票的算法将所有基学习器的结果进行结合。
2 基于双层随机森林的空袭目标识别算法
2.1 空袭目标分类
根据传统经验,防空作战面临的空袭目标一般分为5类[15]:
第1类:战术弹道导弹(TBM)。
第2类:大型目标类,包括歼击机、轰炸机和歼击轰炸机等。
第3类:小型目标类,包括空地导弹、反辐射导弹、巡航导弹和制导炸弹等。
第4类:武装直升机。
第5类:诱饵。
2.2 空袭目标识别主要特征
防空作战中对空袭目标的识别特征有很多,文献[3-4]提取了飞行高度、飞行速度、航线特征和发现距离作为识别特征;文献[5-8]考虑飞行高度、飞行速度、航迹特征和电磁辐射作为识别特征;文献[6]提取了飞行高度、飞行速度、发现距离、航迹特征、电磁辐射和雷达反射面积(RCS)作为识别特征;文献[7]考虑飞行高度、飞行速度、航线特征、电磁辐射和雷达反射面积作为目标识别的主要特征;文献[9]提取了飞行速度、发现距离、飞行高度、航迹特征和电磁辐射作为识别主要特征;文献[10-11]考虑飞行高度、飞行速度、加速度和雷达反射面积(RCS)作为目标识别的主要特征。
通过归纳分析发现,飞行高度、发现距离、飞行速度、加速度、雷达反射面积(RCS)、航线特征和电磁辐射是空袭目标识别中考虑的主要特征,这些特征能够充分反映目标的典型特性,提高目标识别精度,因此本文选取这7个特征作为空袭目标识别的特征集。
2.3 基于双层随机森林的目标识别模型
2.3.1特征评估与优选
随机森林中对特征评估的基本思想为:通过判断每个特征在随机森林中的每棵决策树生长过程中所做贡献的大小,然后比较特征之间贡献的大小。而贡献的计算方式采用每一个特征在森林中所有决策树上的基尼指数[16]变化量总和来表示该特征所做的贡献率,将特征贡献率作为特征重要性评估的依据。
2.3.2数据降维与目标识别
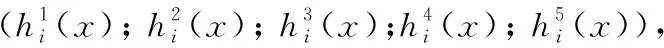
(1)

2.3.3识别结果评价
采用识别准确率对随机森林的识别结果进行评价,识别准确率定义为:
(2)
式中:H(xj)为随机森林在类别j上的识别结果;yj为实际结果;m为测试目标个数;I为逻辑运算,等式成立为1,否则为0。
3 仿真分析
3.1 数据选择与预处理
从目标威胁数据库选取了30批空袭目标,采用留出法区分训练集和测试集,其中前20批目标为训练数据,后10批目标为测试数据。受篇幅限制,仅显示前10批和后10批目标的空情数据如表1所示。

表1 空情数据

续表(表1)
由于航线特征和电磁辐射没有具体的数值,因此需要对这两类数据进行数值化预处理。
航迹特征中等高平直飞行数值化为1,爬升或俯冲数值化为2,下滑数值化为3,分岔数值化为4。电磁特征中有电磁辐射数值化为1,无电磁辐射数值化为0。
3.2 双层随机森林识别仿真
构建第一层随机森林,根据2.3.1的思想得到各特征的重要性的步骤为:
步骤1将表1中的训练数据放入规模为100棵决策树的随机森林进行训练,得到训练好的随机森林模型。
步骤2得到森林中每棵决策树上每一节点的基尼指数,其中节点m的基尼指数定义为:
(3)
式中:K为类别集合;pmk为当前节点m中第k类样本所占的比例。
步骤3计算每一特征的节点贡献率,将特征j在节点m的贡献率用节点m分支前后的基尼指数变化量来表示。
(4)
式中:GIl和GIr分别为分支后2个新节点的基尼指数。
步骤4计算每一特征的累计贡献率,将特征j的累计贡献率定义为:
(5)
式中:M为特征j在第i课决策树中出现的节点集合。
步骤5计算每一特征的重要性,将特征j的重要性定义为:
(6)
式中:n为森林中决策树的数量;C为识别特征集合。
最终得到7个识别特征的重要性程度分别为(2.759 3, 1.889 7, 2.284 9, 3.794 3, 3.348 8, 0.591 0, 0.617 0),对比情况如图3所示。
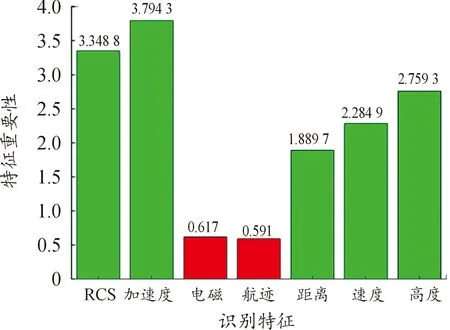
图3 特征重要性对比
从图中可以看出,航迹特征和电磁特征的重要性明显低于其他特征,说明这2个特征在随机森林的目标识别模型中作用不大,因此舍去这2个特征及对应的数据,对训练和测试数据进行降维处理。
根据随机森林算法结构思想,通过降维后的训练数据构建第二层随机森林对测试目标进行识别的步骤为:
步骤1利用Bootstrap法进行降维后的样本采样,随机生成100个采样集。
步骤2利用每个采样集生成对应的决策树,将降维后的5个属性作为每棵决策树的分裂属性集,每次分裂时选择最优的划分属性进行分裂。
步骤3每棵树都尽最大程度生长而不进行剪枝。
步骤4将测试集样本分别放入100棵决策树进行测试并得到对应的类别结果。
步骤5对于100个分类结果采用投票法得到测试样本最终的所属类别。
在实验条件为:Intel(R) Core(TM) i5-10210U,1.60 GHz,四核,内存16G,操作系统为Windows10,64位,仿真软件为Matlab 2019a的实验环境中仿真得到最终识别结果为矩阵H(其中hij表示目标i识别为类别j的决策树数量)
分析矩阵H可以看出,在100棵决策树的随机森林中,对于目标1,有9棵决策树的识别结果为类型1,2棵决策树的识别结果为类型2,4棵决策树的识别结果为类型3,76棵决策树的识别结果为类型4,9棵决策树的识别结果为类型5,所以目标1的最终识别结果为类型4。
同理可得测试集的10批目标识别结果分别为[4,1,5,3,2,3,1,5,2,4],即目标1和目标10为武装直升机,目标2和目标7为TBM,目标3和目标8为诱饵,目标4和目标6为小型目标,目标5和目标9为大型目标,识别结果与实际情况相符。
3.3 对比分析
分别将本文中提出的双层随机森林和传统随机森林、文献[8]的SVM算法以及文献[11]的PNN神经网络分别用于表1数据集的目标识别。
由于随机森林模型无需对数据进行归一化处理,能够简化识别流程并节约运算资源。而PNN神经网络和SVM均需要对数据进行归一化处理,因此对于训练和测试数据,将归一化公式定义为:
(7)
3.3.1特征降维方法对比
特征降维方法对于机器学习模型的识别性能和泛化能力具有一定的影响。为了对比基尼指数降维的有效性,将主成分分析、基尼指数降维和未降维的随机森林模型进行对比分析,对于指定的空袭目标识别问题,将每种方法分别重复实验50次,用式(8)
(8)
分别计算第k种降维方法得到随机森林模型的识别正确率。主成分分析结果和实验对比结果分别如图4和图5所示。
由图5可以得到,无特征降维方法的识别正确率为0.989,主成分分析的识别正确率为0.760。所提方法的识别正确率为0.999,仅在第94次实验时出现了识别正确率波动的情况。由于主成分分析是将原始特征进行线性组合得到新的成分,会损失较多的数据信息,而所提方法从随机森林原理出发,得到的特征与随机森林模型的契合度更高。同时相比于传统随机森林,降维后的模型对于模型的识别稳定性也有所提高。
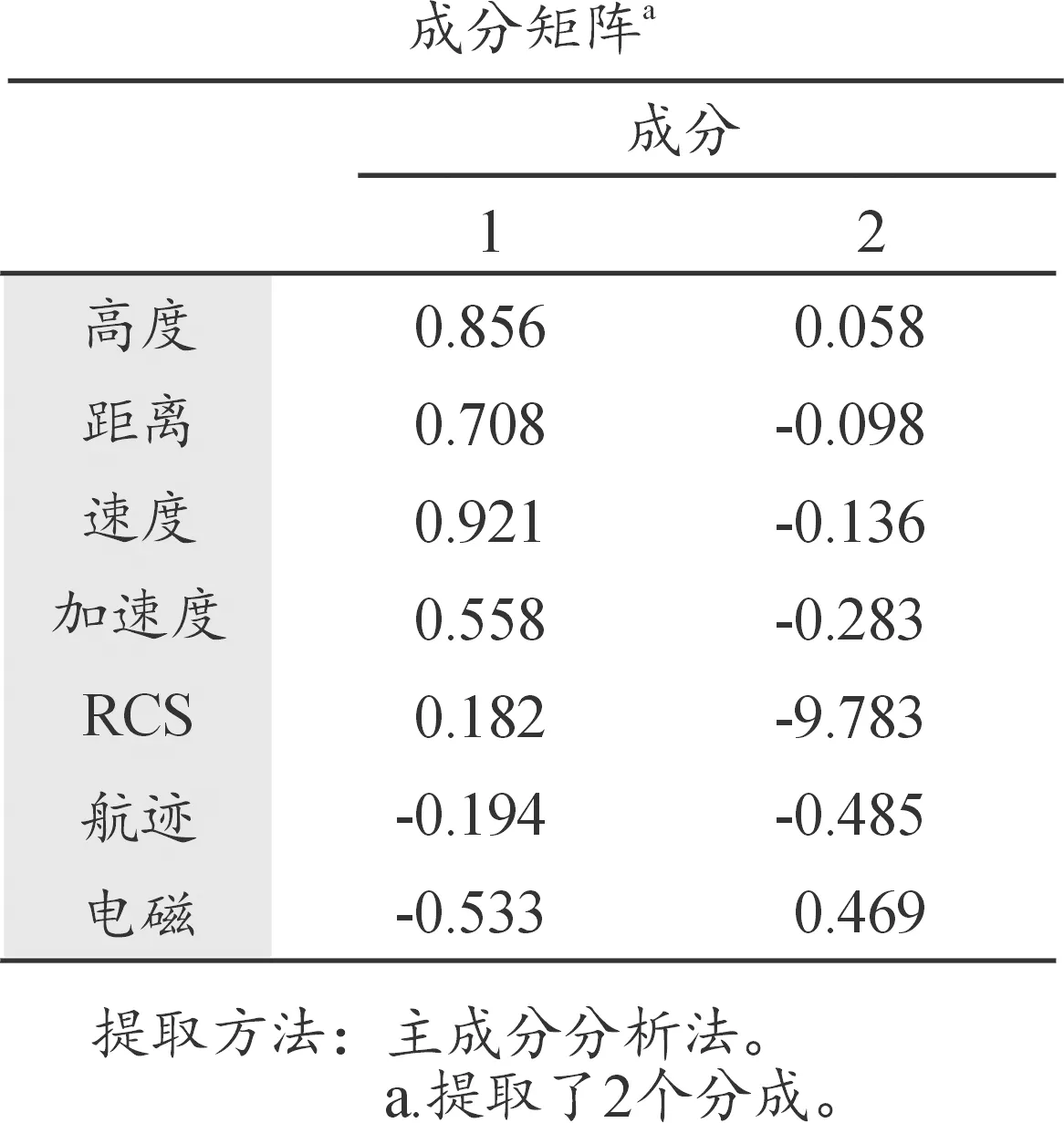
图4 主成分分析结果
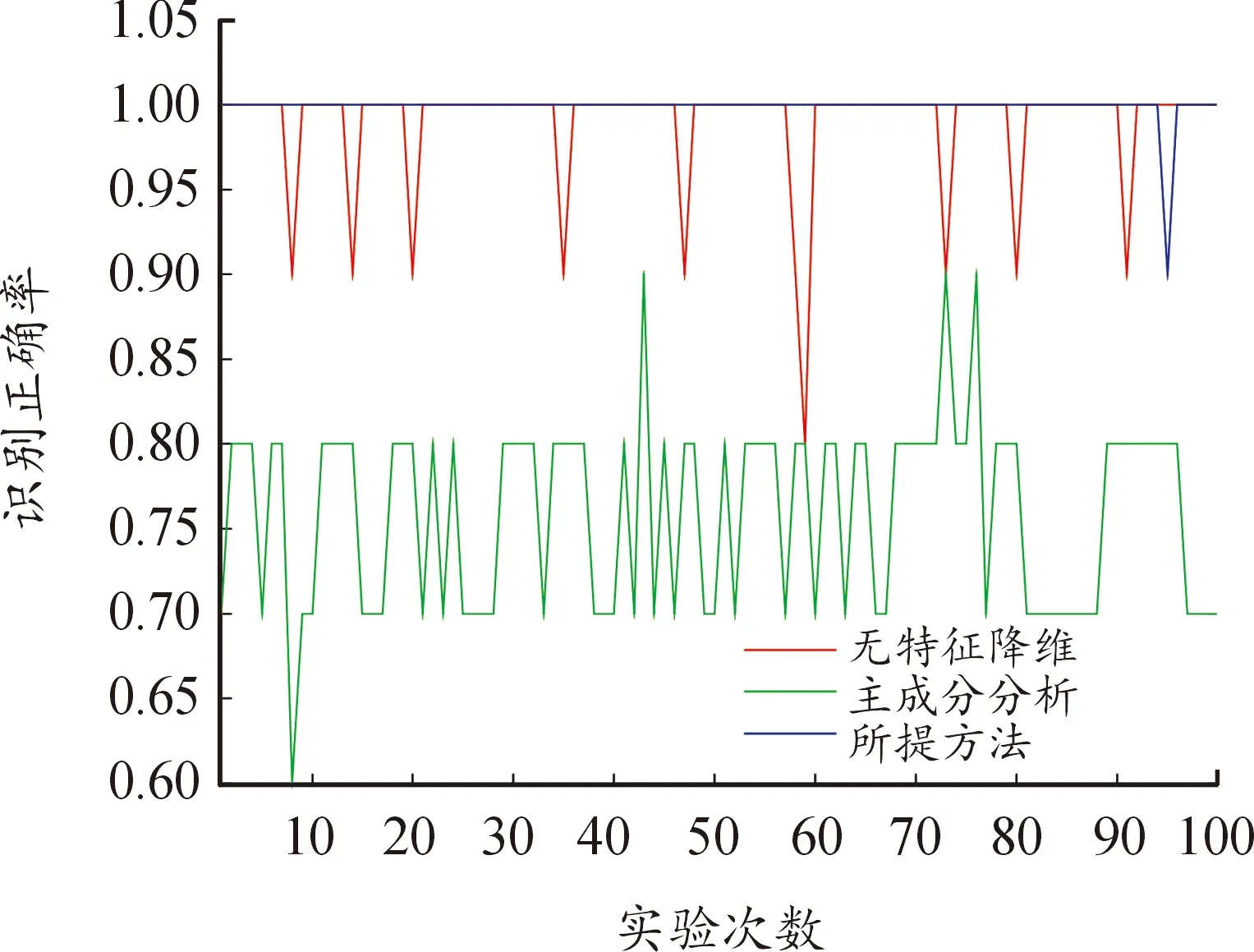
图5 特征降维方法对比
3.3.2目标识别算法对比
为了验证所提方法的有效性,采用文献[8]的SVM、文献[11]的PNN神经网络进行目标识别,其中SVM中的超参数通过交叉验证方法得到,并从加载空情数据开始记录3种方法的识别时间,得到3种方法的识别结果和识别速度分别如图6和表2所示。

图6 识别结果对比

表2 识别速度对比
可以看出,PNN神经网络对于目标7、目标8和目标10的识别结果与真实值不同,SVM对于目标6和目标8的识别结果与真实结果不同,而双层随机森林的识别结果与实际一致,说明所提算法相比于其他的识别算法具有更好的识别性能。在识别速度方面,SVM由于需要进行交叉验证寻找超参数因此识别的时间成本较高,难以满足作战实际。PNN神经网络和双层随机森林的识别时间都在0.1 s以下,满足作战实际的需求,但双层随机森林的所有时间要远小于PNN神经网络,约为其的十分之一,在识别过程中随着目标规模的增大会具有更大的优势。因此,综合对比发现,双层随机森林在目标类型识别中表现优秀,相比于PNN神经网络和SVM,双层随机森林不仅能保证快速、准确地识别目标,并且在目标数据处理上还省去了归一化处理步骤,简化了流程,能够在保证准确率的同时具有较高的识别速度。
3.3.3 模型泛化能力分析
为了减少单次留出法造成的样本数据集偶然性,验证模型的泛化能力,采用多次留出法构建10个新的数据集作为实验样本,其中将前20批目标作为训练集,后10批目标作为测试集,将每个数据集分别代入双层随机森林模型实验50次,实验结果如表3所示。
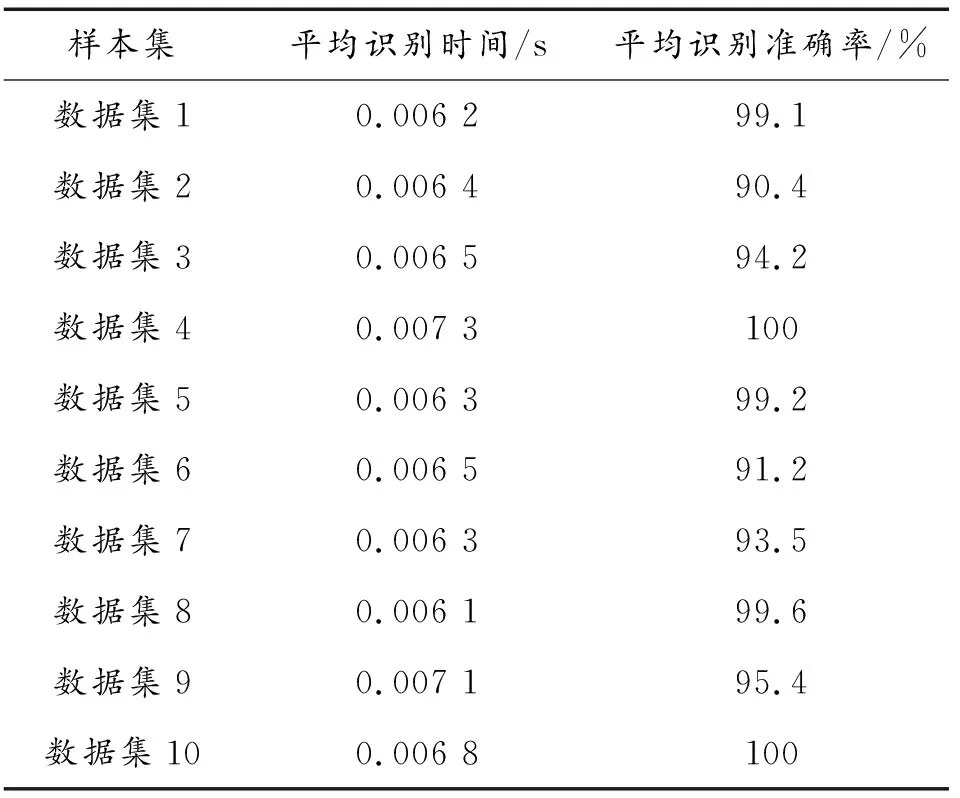
表3 不同样本集的识别结果
由表3可以得到,在10个样本集中,双层随机森林得到的平均识别准确率均在90%以上,平均时间都在0.01 s以下,说明识别模型在不同样本集中都能够保持较高的准确率和识别速度,但在数据2和数据6中的准确率低于其他样本集,这可能是由于样本的随机性导致训练集不全面引起的。因此,可以认为所提的目标识别模型具有较强的泛化能力和鲁棒性。
4 结论
1) 相比于传统随机森林,所提算法通过计算基尼指数变化量对空袭目标特征进行重要性评估和数据降维,提高了目标的识别准确率和稳定性,有效提高了随机森林的目标识别性能。
2) 相比于神经网络和支持向量机等其他目标识别算法,所提算法具有更强的泛化能力,能够在保证较高的识别准确率的同时具有较高的识别速度。此外,所提算法不需要对数据进行归一化处理,进一步简化了识别流程。
3) 但在未来防空作战中,受不确定和对抗性因素影响,空情数据可能是不完整的,传感器获得的数据也更加多样,如何从多个特征选择最合理的识别特征以及根据缺失的数据进行准确的目标识别是下一步研究的重点。
