基于2D先验的3D目标判定算法
2023-05-31东辉解振宁孙浩陈炳兴姚立纲
东辉,解振宁,孙浩,陈炳兴,姚立纲
(福州大学机械工程及自动化学院,福建 福州 350108)
0 引言
目标识别与检测是机器视觉领域的核心任务之一,被广泛应用在故障诊断[1]、电力巡检[2]等方面.起初,目标识别与检测主要以2D视觉作为主要研究对象,具体可分为基于传统机器视觉的方法和基于深度学习的方法.其中,基于传统机器视觉的方法主要通过手工设计并结合特征分类器来进行识别与检测,该类方法在速度和精度上都不理想.基于深度学习的方法主要分为双阶段和单阶段两大类.双阶段方法首先产生感兴趣区域的推荐框,再对推荐框进行分类和回归,代表算法有Faster R-CNN[3]、TridentNet[4]等.单阶段方法则直接在图片的多个位置进行分类和回归;代表算法有YOLO(you only look once)[5]、SSD(single shot multibox detector)[6]等.两类方法各有优劣,前者精度更高,后者速度更快.作为单阶段目标检测算法的代表,SSD在检测速度和精度上达到了较好的平衡.但SSD算法对低级特征提取不充分,容易造成对小目标的漏检.针对上述问题,Zhang等[7]提出一种基于多尺度特征图跳跃连接的改进SSD算法,有效融合高层和低层特征,但也造成了更多的信息丢失.刘涛等[8]通过引用空洞卷积和卷积核金字塔增加网络的特征提取能力,同时引入特征融合模块,提升对小目标的检测能力,但也增加了模型的计算复杂度.
目前,基于2D视觉的目标识别与检测技术已经趋于成熟.然而,由于缺乏深度信息,仅使用二维信息来表征三维物体,会不可避免地造成信息损失.为了解决此类问题,人们把目光投向3D视觉领域.其中,点云是一种典型的3D数据表示方法,具有获取简单、几何信息丰富等优势.基于点云的研究也有了长足的发展,其中,点云库 (point cloud library,PCL)是在吸收前人点云相关研究基础上建立起来的大型跨平台开源C++编程库[9],它实现了大量点云相关的通用算法和高效数据结构,被广泛应用在机器视觉、逆向工程、无人驾驶等领域.
利用点云的性质可以解决上述问题,但PCL中传统点云识别的方法一般包括点云预处理、关键点选取、特征描述、特征匹配等步骤,较为繁琐,识别周期较长;而基于深度学习的点云识别方法又面临着点云数据集制作难度较大的问题.事实上,目标识别与检测任务只要求从某一场景中提取出所需要的物体信息,其余信息并无太大价值.若仅采用三维点云来完成目标识别,会延长计算周期,不利于效率的提升.为此,本研究提出一种基于2D先验的3D目标判定算法.选择SSD作为2D目标检测算法,并将其主干网络VGG-16替换为轻量级网络MobileNet[10],通过深度相机结合改进的MobileNet-SSD网络模型找到目标物体的所在区域,即感兴趣区域(region of interest,ROI),然后利用透视变换将二维ROI转换成ROI点云,利用点云相关算法做进一步的处理.
1 算法框架及经典MobileNet-SSD介绍
1.1 一种基于2D先验的3D目标判定算法
提出一种基于2D先验的3D目标判定算法,其整体框架如图1所示.首先通过深度相机获取输入场景的彩色图及深度图,并利用改进的MobileNet-SSD算法对彩色图像中的物体进行目标检测,获取目标物体所在的ROI区域;然后利用彩色图和深度图像素一一对应的关系,通过透视变换将深度图ROI内的数据转换为点云数据;接着通过直通滤波算法对ROI点云数据进行滤波处理,并通过计算直通滤波前后的点云数目比来判定目标物体是否为真实场景物体.

图1 算法整体框架Fig.1 Overall framework of algorithm
1.2 经典的MobileNet-SSD目标检测算法
SSD算法结合YOLO的回归思想和Fast R-CNN的锚框机制,采用VGG-16作为主干网络,并增加一组辅助卷积层,用于在多个尺度上进行特征提取,通过卷积来预测从不同层提取特征信息的类别和位置,并使用非极大值抑制(non-maximum suppression,NMS )来获得最终的预测结果.SSD算法较好地解决了平移不变性与平移可变性之间的矛盾,达到较好的检测速度和精度,但VGG-16网络参数较多,体量较大.
MobileNet是由Howard等提出的一种轻量级网络模型,具有延迟性低、体量小的特点.其核心是使用深度可分离卷积替代标准卷积.深度可分离卷积包括深度卷积和逐点卷积,其中深度卷积作用于每个通道,而逐点卷积用来组合各个通道输出.MobileNet通过巧妙地分解卷积核,既实现了标准卷积的效果,又减少了卷积核的冗余表达、模型参数量和计算量,提高了模型的运算速度.
2 基于2D先验的3D目标判定算法实现
2.1 改进的MobileNet-SSD小目标检测算法
针对原SSD算法中对低级特征提取不充分,容易造成对小目标漏检的问题,做出如下两方面的改进.
2.1.1基础网络结构的改进
首先给出小目标的定义,即当目标像素与输入图像像素之比不大于12%时,称该目标为小目标[11];SSD的输入图像大小为300 px×300 px,因此,小目标的大小应不大于36 px×36 px.此外,对于深度学习目标检测模型来说,网络层越深,其提取图像特征的能力越好.在MobileNet-SSD的基础上,额外选择Conv3、Conv5两个卷积层作为新的预测特征层.Conv3和Conv5预测特征层大小分别为75×75、38×38,能够在提取图像特征能力与保留尽可能多的小目标信息之间达到较好的平衡,增加对小目标的检测能力.改进后的MobileNet-SSD网络结构如图2所示.

图2 改进后的MobileNet-SSD网络结构Fig.2 Improved MobileNet-SSD network structure
MobileNet-SSD网络模型的先验框计算公式为
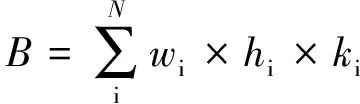
(1)
式中:B为先验框的总数量;i表示第i个预测特征层;N为预测特征层的总数;wi、hi分别表示第i个预测特征层的宽和高;ki表示第i个预测特征层的先验框的形状种类.
由式(1)可计算出原MobileNet-SSD网络模型的先验框总数量为1 917,而改进后的MobileNet-SSD网络模型的先验框总数量为27 456,增加了约14.3倍.因此,改进后的MobileNet-SSD网络模型可以更大范围地获取目标物体的候选区域,提高物体检出的可能性,为后续工作打好基础.
2.1.2损失函数的改进
在SSD算法中,输入图像中真实标记框的数目要远远少于先验框的数目,导致正负样本失衡.为了解决该问题,SSD采用难样本挖掘的方法,使得正负样本比例保持在1∶3左右,保证模型正常训练,但这样会导致训练被大量的易分样本主导,限制了算法精度的进一步提高.
本研究采用Focal Loss函数替代SSD原有损失函数中的置信度损失函数,通过调节输入网络中的正负样本比例参数,使得模型更加容易训练,进一步增强检测效果.
Focal Loss损失函数的计算公式为
Lfoc(pt)=-αt(1-pt)γlnpt
(2)
式中:pt为不同类别的分类概率;αt为正负样本平衡因子;γ为聚焦因子,用于调节易分和难分样本的权重.
由式(2)可知,对于易分样本,pt会比较大,权重(1-pt)自然就比较小;对于难分样本,pt较小,此时权重(1-pt)较大.这样可以减小易分样本损失的权重,使得网络模型更加关注难分样本,有利于模型准确地进行分类.
改进后的总的损失函数由置信度损失函数和定位损失函数组成,计算公式为

(3)
式中:Lfoc表示Focal Loss函数;Lloc(x,l,g)表示定位损失函数;N为匹配到的正样本的个数;α为定位损失函数的权重;x为先验框与真实框的匹配结果,若匹配x=1,否则x=0;l为正样本的回归参数;g为正样本匹配的真实框的回归参数.
2.2 基于点云的目标3D特征判定方法
图3给出了部分在2D视觉中有效,但在3D视觉中无效的场景.由图3可知,由于缺乏深度信息,导致2D目标检测无法区分非真实场景物体与真实场景物体.为此,提出一种基于点云的目标3D特征判定方法,利用ROI点云特性来解决图3中的问题及类似问题.

图3 2D目标检测部分不足Fig.3 2D object detection partial drawbacks
2.2.1ROI点云的获取
首先,通过深度相机获取输入场景的彩色图及深度图;接着,利用改进的MobileNet-SSD算法对彩色图像中的物体进行目标检测,获取目标物体所在的ROI区域;然后利用彩色图和深度图像素一一对应的关系,通过透视变换将深度图ROI内的数据转换为点云数据,完成ROI点云的获取.
通过上述方法,既省去了传统点云识别的诸多步骤又避免了点云深度学习中三维数据集制作难度较大的问题,取得了较好的效果,其检测示例如图4所示.

图4 算法检测示例Fig.4 Algorithm detection example
2.2.2基于点云直通滤波的3D特征判定方法
由图4可知,本研究提出的方法在二维检测阶段就得出检测类别结果,并没有判定是否出现图3中的问题及类似问题的能力.因此,为了解决该问题,本研究提出如下判定方法.
图5(a)展示了在2D视觉中有效、但在3D视觉中无效的场景示例,其对应的ROI点云如图5(b)所示,对应真实目标物体的点云如图5(c)所示.由图5(b)可知,当发生失效现象时,对应目标物体的ROI点云应为一个平面,其Z轴方向理论最大距离差应为0,但由于受到相机采集精度等因素的影响,经实测得到其Z轴真实最大距离差约为8 mm,而对应真实目标物体点云明显不是平面,其最大距离差要大于8 mm.因此,可以通过判断ROI点云是否为平面来完成相关判定工作.

图5 失效场景示例Fig.5 Example of failure situation
选择利用直通滤波来完成判断ROI点云是否为平面的工作,所谓直通滤波即对指定坐标范围进行裁剪.直通滤波示例如图6所示,其滤波轴为Z轴,滤波范围为8 mm.由图6可知,ROI平面点云滤波后的点云数与滤波前的点云数相比减少了约77 %,而对应真实目标物体滤波后的点云数比滤波前的点云数减少了约18%,存在较大差异.
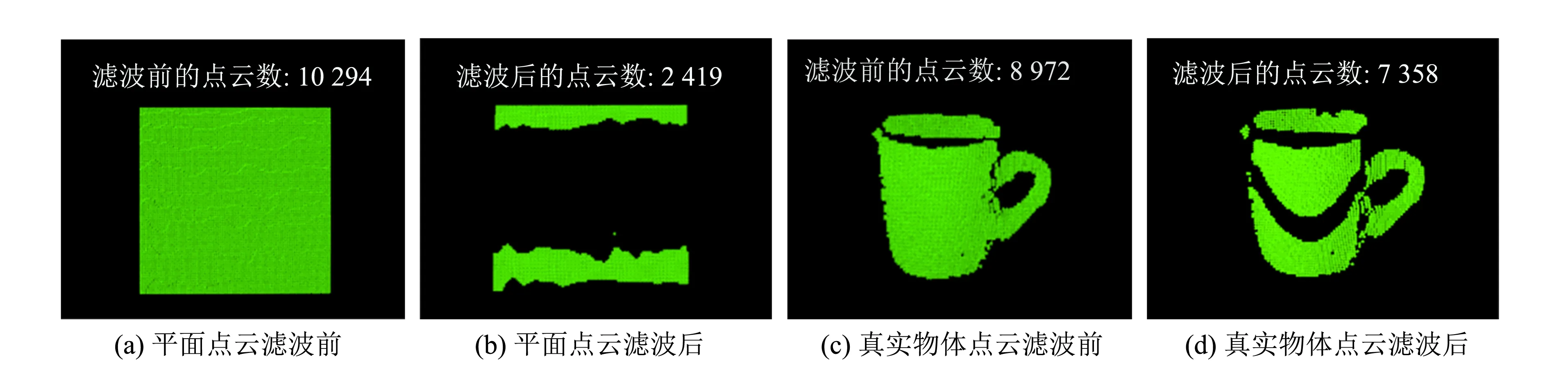
图6 直通滤波示例Fig.6 PassThrough filter examples
进一步地,为了提高算法鲁棒性,提出如下判定方法: 利用直通滤波,将Z轴设置为滤波轴,将滤波范围设置为6 mm,统计滤波前后的点云数量,若滤波后的点云数量不大于滤波前的30%,则判定ROI点云为平面,即出现在2D视觉中有效,但在3D视觉中无效的现象,否则判定ROI点云为真实目标物体,即检测有效.
3 实验验证
3.1 实验平台配置
本次实验采用的训练和部署环境所采用的操作系统为Ubuntu 18.04,CPU为Intel(R) Core (TM) i7-8700,GPU为NVIDIA GeForce RTX 1070,内存为16 GB,GPU加速库为CUDA9.0+CUDNN7.0,深度学习框架为Caffe,PCL版本为1.9.0,深度相机型号为Intel RealSense D435i.小目标推荐检测范围为0.5~2.0 m.
3.2 改进MobileNet-SSD算法的验证
3.2.1实验数据集
考虑到本研究所提出的算法需将二维ROI转换为ROI点云,并没有合适的公共数据集.因此选择生活中常见的5类物品作为检测对象来制作数据集,其分别为保温杯、苹果、碗、马克杯、眼镜盒.首先通过实际拍摄、网上搜集等方式获取原始图片3 500张,接着利用随机旋转、随机颜色等方式进行数据增强,数据增强后,最终数据集中包含10 000张图像.将数据增强后的数据集按照PASCAL VOC[12]的格式进行标注.通过分离验证的方法,将训练集和测试集图片数量比例设置为5∶1,再以9∶1的比例将训练集细分为测试集和验证集.
3.2.2训练方法及参数设置
采用迁移学习的方法先对PASCAL VOC数据集进行预训练,然后对数据集的参数进行微调.初始学习率设置为0.000 5,采用RMSProp算法及动量优化算法优化参数,动量因子设置为0.9,训练权重衰减项设置为0.000 1,批量大小为24,最大迭代次数设置为53 000,IoU阈值设置为0.5,αt为0.3、γ为1.9.
3.2.3评估指标
选择采用平均精度(mean average precision,mAP)、召回率(recall,R)、准确率(precision,P)、模型大小(Mbyte,MB)作为目标检测算法的评估指标,计算公式为

(4)
式中:TP表示被正确预测为正样本的数量;FP表示负样本被预测为正样本的数量;FN表示正样本被预测为负样本的数量;C为检测类别数目;N为图像中当前类的目标数量.
3.2.4实验结果分析与比较
在训练过程中,通过记录损失值变化以及准确率变化来观察训练的动态过程,其对应的损失值变化曲线以及精度值变化曲线如图7所示.

图7 模型变化曲线Fig.7 Model change curves
为了显示改进算法的优越性,在上述自制训练数据集样本上充分训练Faster R-CNN、YOLOv3、MobileNet-SSD及本文算法,并在同一测试集样本上对以上算法进行检测性能对比实验,各模型具体检测性能如表1所示.
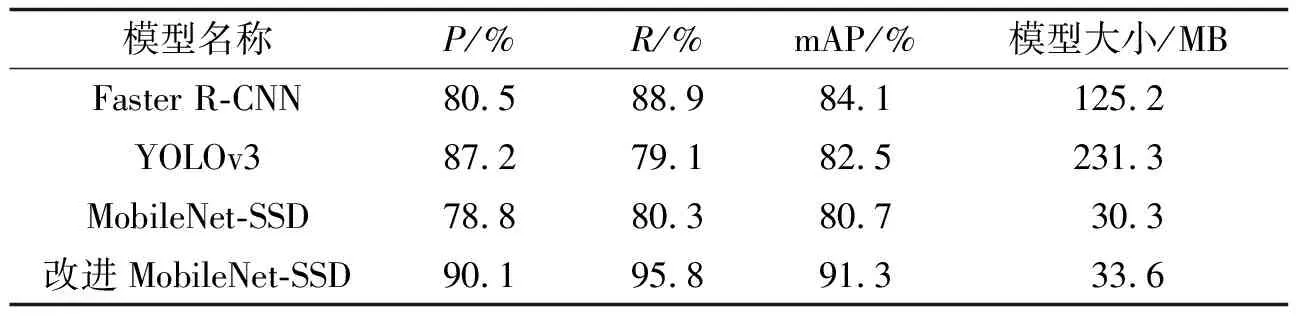
表1 不同算法检测性能对比

表2 消融实验结果
为了进一步验证对MobileNet-SSD算法改进的有效性,在相同训练和测试数据集上对本研究算法和MobileNet-SSD算法进行对比和消融实验,消融实验结果见表2.由表2可知,在分别引入改进网络结构和改进损失函数后,检测模型mAP值分别提高了6.3%、5.5%,表明在同时引入改进网络结构及改进损失函数后,检测模型mAP值提高了8.2%.表明在原MobileNet-SSD算法上的各项改进均能有效提高算法检测精度.
3种网络模型对小目标物体的检测实例如图8所示,由图8可以看出,改进后的MobileNet-SSD检测精度有着明显提升.

图8 网络模型检测对比Fig.8 Network model detection comparison
3.3 基于点云的目标3D特征判定实验
为了验证提出的判定算法能否分辨2D目标和3D目标,在相同的实验平台下,结合控制变量法的思想,通过有序调整目标距离、选择不同的检测目标等方式,分别用PCL中传统点云识别的方法及点云深度学习的方法和本文算法做对比实验,对比试验示例如图9所示.

图9 对比试验示例Fig.9 Comparative examples
参照上述示例,共做了200组对比试验,为进一步说明算法的有效性,将平均检测时间、检测正确率作为评估指标,对比实验结果如表3所示.

表3 对比实验结果
由表3可知,本研究提出的算法与传统点云识别方法相比,检测速度分别提高了10.14倍和9.68倍,而检测准确率仅降低了约1%,在保证检测准确率基本不变的前提下,大幅提高了检测速度.此外,将本研究算法与点云深度学习的方法相比,其检测速度分别降低了0.37倍和0.51倍,检测准确率降低了2%,虽然检测速度与检测精度都略有降低,但是避免了三维数据集制作难度较大的问题,从目标检测的整体流程来看,缩短了工作周期.
4 结语
针对2D目标检测无法区分非真实场景物体与真实场景物体,以及直接采用3D识别工作周期较长的问题,提出了一种基于2D先验的3D目标判定算法.用轻量级MobileNet网络替换经典SSD的VGG-16网络,降低了模型大小,并在此基础上额外增加两个预测特征层,提高模型对小目标的检测能力.通过引入Focal Loss函数替代SSD原有损失函数中的置信度损失函数,解决了MobileNet-SSD中正负样本不均衡和易分样本占比较高的问题.通过改进MobileNet-SSD算法获取ROI,利用深度相机将二维ROI转换为ROI点云,利用直通滤波来判断是否出现在2D视觉中有效但在真实三维空间中无效的现象,既省去了传统点云识别的诸多步骤,又避免了三维数据集制作难度较大的问题.在今后的研究工作中,将致力于进一步提高算法的泛化性能和鲁棒性.
