基于行程数据的公交车到站时间预测
2023-05-31姚江涛邬群勇余丹青罗建平
姚江涛,邬群勇,余丹青,罗建平
(1.福州大学空间数据挖掘与信息共享教育部重点实验室,卫星空间信息技术综合应用国家地方联 合工程研究中心,数字中国研究院(福建),福建 福州 350108;2.广州交信投科技股份有限公司,广东 广州 510000)
0 引言
提升公交车到站时间预测的准确性,可有效提高乘客的出行体验,提高公交车的满载率、分担率、运行效率和服务质量,有助于进一步优化城市交通系统,缓解城市交通拥堵,促进市民出行体验和城市交通发展的良性互动[1-3].
目前公交车到站时间预测根据应用主体的不同,可以分为两大类.一类是面向公交车公司的终点站到站时间预测,又称行程时间预测.该类方法仅能提供终点站的预计到站时间,而无法提供中间站点的预计到站时间,主要用于公交调度.另一类是面向公交车乘客的中间站点到站时间预测,它可以向乘客提供公交车到达上车站点的预计到站时间.传统的中间站点到站时间预测模型包括历史数据模型[4]、粒子滤波模型[5]、支持向量机(support vector machines,SVM)模型[6]、卡尔曼滤波模型[7-8]等.上述传统模型的适用性和实时性相对较差,在长距离预测中会出现精度下降的现象,无法较好地捕获公交车行驶过程中的时空规律.随着机器学习的发展,较多学者将神经网络模型应用到公交车中间站点的到站时间预测中.邝先验等[9]提出基于天牛须搜索算法的小波神经网络预测模型;谢芳等[10]提出一种基于MapReduce聚类和BP神经网络的预测模型;Xie等[11]创建多层循环神经网络(recurrent neural network,RNN)预测模型;安宇航等[12]建立一种基于长短期记忆(long short-term memory,LSTM)神经网络和粒子滤波的预测模型;Han等[13]提出一种基于位置校准的LSTM预测方法,在对GPS轨迹数据进行校正后,利用LSTM对公交车到站时间进行预测.
但是,上述方法仍存在以下不足: 1) 仅仅采用归一化的方式对模型的输入特征进行处理,未能较好地体现各个特征之间的重要性差异;2) 在应用循环神经网络时,未能较好地体现不同时间距离的公交车行程时间和当前公交车到站时间的关联性;3) 往往采用站点间分开预测再累计求和的预测方法,在长距离预测中会出现误差累积的现象,无法同时为乘客提供上下车时间参考.
针对上述问题,为向乘客提供目标班次的动态到站时刻表,本研究利用行程数据,构建基于双层、双注意力、双向LSTM的公交车到站时间预测模型(简称DLA-BLSTM模型).首先,通过注意力机制区分不同时刻各个因素对于公交车行程时间影响的差异性;其次,将自注意力与LSTM相融合,优化LSTM网络的记忆能力,使其能够自主分析不同时间距离公交车行程时间之间的关联性,充分挖掘公交车行程时间的时序性,实现对公交车行程时间的预测;最后,将公交车到站时间问题转化为行程时间预测子问题,基于预计行程时间和公交车站点间的行驶规律,对公交车到站时间进行估算,获得公交车预计到站时间,同时为乘客提供上下车时间参考.
1 DLA-BLSTM模型构建与实现
1.1 DLA-BLSTM模型

图1 DLA-BLSTM模型结构图Fig.1 DLA-BLSTM model structure diagram
DLA-BLSTM模型结构如图1所示,模型的构建步骤如下:
1) 对公交车行程时间的影响因素进行分析,确定模型的输入特征,构建模型输入特征矩阵;
2) 在多层感知机的基础上,利用注意力机制构建特征重要性提取模块,利用特征提取模块提取各个特征的重要性权重,并将其与模型的输入特征矩阵进行拼接,输入到行程时间预测模块中;
3) 将自注意力机制融入到LSTM的时间步中,基于双层、双向长短期记忆神经网络(bi-directional LSTM,BiLSTM)构建行程时间预测模块,使LSTM网络可自主分析不同时间距离公交车行程时间之间的关联性,将均方根误差作为模型的损失函数对模型进行训练,最后输出公交车的预计行程时间;
4) 基于各个相邻站点的平均行驶时间占比和预计行程时间,对该运行班次相邻站点之间的行驶时间进行预估,获得该运行班次各站点的预计到站时间.
1.2 特征重要性提取模块
不同因素对公交车行程时间会产生不同程度的影响.为更好地区分不同特征的影响程度,在多层感知机的基础上,利用注意力机制构建特征重要性提取模块,使模型能够基于不同时刻、不同特征的输入值,计算它们的注意力权重,生成不同的特征重要性矩阵,丰富模型的输入信息.
首先,将模型输入特征矩阵输入到特征重要性提取模块中;其次,结合上一时刻行程时间预测模块中的隐藏层输出的元胞隐状态,计算当前时刻各个特征的重要性大小,获取当前时刻的特征注意力权重矩阵;最后,将各个维度的注意力权重矩阵和模型特征矩阵进行拼接,获得DLA-BLSTM模型的特征重要性矩阵.上述实现过程的计算公式为
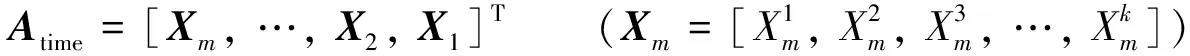
(1)
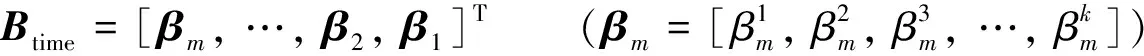
(2)
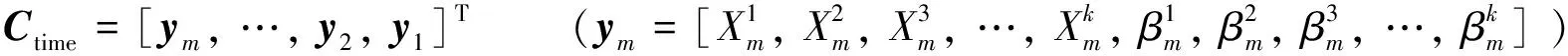
(3)
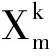
1.3 行程时间预测模块
传统LSTM网络由一系列LSTM记忆单元组成[14-16].LSTM的核心由遗忘门、输入门和输出门组成.其中,遗忘门用于决定上一时刻元胞状态中所要遗忘的内容;输入门用于决定要添加到当前元胞状态中的新信息,对当前的元胞状态进行更新;输出门用于保留当前元胞状态中的重要信息,输出元胞隐状态.
在传统LSTM网络的基础上,DLA-BLSTM模型在行程时间预测模块中搭建双层、BiLSTM网络,深入挖掘公交车行程时间的时序性,并将注意力机制融入到LSTM的时间步中,使LSTM网络可自主分析不同时间距离的公交车行程时间之间的关联性,优化LSTM网络的记忆能力.
1) 双层、双向LSTM网络的搭建.传统LSTM网络在训练过程中只能正向进行,BiLSTM可以从正向和逆向两个方向对模型输入进行处理,进一步挖掘近邻公交车行程时间之间的相关性.因此,在DLA-BLSTM模型的行程时间预测模块中,基于第一层LSTM网络,添加BiLSTM,将第一层LSTM网络输出的隐藏状态输入到第二层BiLSTM中,提取公交车运行过程中的双向时序特征.
2) 注意力机制与LSTM的融合.注意力机制是一种注意力资源分配的模型,可对事物的不同部分赋予不同的权重,从而降低其它无关部分的作用[17].自注意力机制是在注意力机制的基础上发展而来的,可以在编码和解码时单独使用.相较于注意力机制,自注意力更加关注模型输入之间的内在联系.DLA-BLSTM模型便是使用自注意力对BiLSTM输出的元胞隐状态进行处理,提取各个时刻LSTM输出的元胞隐状态内在联系,赋予不同时间距离的元胞隐状态不同的权重,进而体现处于不同时间距离的公交车对于当前公交车行程时间的影响,最终获得公交车的预计行程时间.
首先,将特征重要性提取模块中所获得的特征重要性矩阵输入到LSTM层中;其次,将LSTM层输出的元胞隐状态输入到BiLSTM层中,经过BiLSTM层处理,利用双曲正切曲线计算BiLSTM输出元胞隐状态的得分,获得各个时刻的元胞隐状态的得分矩阵,并利用softmax函数对该矩阵进行归一化,获取元胞隐状态的概率向量;再次,基于元胞隐状态得分矩阵和元胞隐状态概率向量,获取当前时刻的元胞隐状态;最后,通过全连接层获得当前公交车的预计行程时间.上述实现过程的计算公式为

(4)
etime=utanh (wHtime+b)
(5)
αtime=softmax(etime)
(6)

(7)
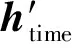
1.4 到站时间估算模块
到站时间估算模块主要用于获取当前班次在各站点的预计到站时间.首先,获取各个运行班次在各相邻站点间的行驶时间,计算各站间行驶时间在总行程时间中的占比;其次,公交车的发车时间间隔均在10 min左右,因此以10 min为时间间隔进行时间分片,获取每天各个10 min内各个运行班次在各相邻站点间的平均行驶时间占比,统计星期一至星期五各个10 min时间分片内各相邻站点的平均行驶时间占比;最后,基于在行程时间预测模块中获取的预计行程时间和星期一至星期五各个10 min时间片内各相邻站点的平均行驶时间占比,预估当前班次公交车在各相邻站点间的预计行驶时间,进而获取当前班次在各站点的预计到站时间.
2 数据预处理与特征预选取
2.1 研究数据
本研究选取广州市560路、B2路公交车作为研究对象,其中560路属于普通公交线路,B2路属于快速公交线路,两条线路沿线均途经较多居民小区、商业中心和高校等,公交乘坐需求度较高,具有较强的代表性.研究数据来源于广州交信投科技股份有限公司,包含2020年10-12月期间B2路和560路上行线路的公交车实际运行数据,主要字段包括当前运行班次的唯一标识、营运线路标识、车辆标识、驾驶员标识、该班次的发车时刻、到站站台标识、站台名称、站台经纬度和当前站台的到达时刻等.
2.2 数据预处理
由于本研究的数据主要来源于GPS定位数据,数据在传输、存储的过程中,会受到一些外部因素的干扰,导致数据有时会出现记录偏差或者记录缺失的情况,因而需要对数据进行预处理.数据预处理主要包括剔除重复数据、校准异常数据和插值缺失数据.首先,对于重复记录的数据直接剔除.其次,对异常数据进行处理,异常数据是指出现倒时、运行时间远小于平均站点运行时间等情况的数据,对其先进行剔除,再进行插值填充.最后,对缺失数据进行插值补全,插值补全的方法有两种: 1) 关注终点站到站时间缺失的数据,通过获取距离终点站最近邻的已知到站时间的站点,计算始发站到最近邻已知到站时间站点的行驶时间占行程时间的平均占比,基于始发站到最近邻站点的行驶时间和平均行驶时间占比,对缺失路段的行驶时间进行补全;2) 中间站点到站时间缺失值也按上述类似思路进行插值填充.
2.3 模型特征预选取

图2 平均行程时间对比图Fig.2 Comparison chart of average travel time
对模型的输入特征进行合理的选择,有助于降低模型冗余,提升模型预测精度和预测效率.按照国庆假期、工作日、周末,对公交车运行数据进行分类,分别统计在不同特征日下各个时刻的公交车平均行程时间,统计结果如图2所示.国庆假期、工作日、周末公交车具有明显不同的运行规律.其中,公交车在工作日的平均行程时间具有明显的早晚高峰,且晚高峰的峰值高于早高峰,变化幅度较大.
公交车在运行过程中,受到较多因素的影响.本研究从公交车运行过程中的基本属性特征和运行规律特征两方面进行考虑,对模型输入特征进行预选取.首先,预选取公交车的基本属性特征.考虑到公交车自身属性因素的影响,添加公交车编号和驾驶员编号.考虑到公交车在不同时刻具有不同的运行状态,添加公交车的发车时间、发车间隔、相对于当天首发车的相对发车时间.考虑到公交车运行时所处的天气状况,添加天气类型.其次,在基本属性特征的基础上,从天、周、月3个角度选取公交车运行规律特征,使用斯皮尔曼相关系数从天、周、月3个角度对运行规律特征与当前班次的行程时间之间的相关性进行分析.斯皮尔曼相关系数的计算公式为
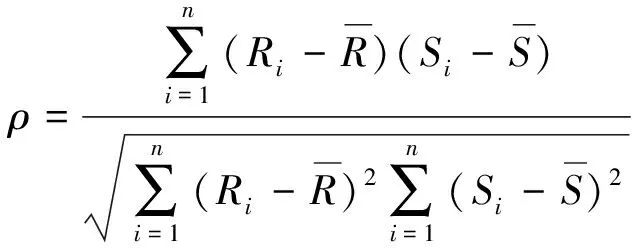
(8)
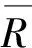
结果表明,当前班次的行程时间与前一工作日的平均行程时间的相关系数均大于0.70,与上一周相同特征日的平均行程时间的相关系数均大于0.75,与月平均行程时间的相关系数均都大于0.80.因此,所选取的运行规律特征与当前班次的行程时间之间具有较为明显的相关性.最终,将基本属性特征和运行规律特征作为模型的预输入特征,具体如表1所示.

表1 模型预输入特征
3 实验结果与分析
3.1 实验数据集
从图2中可发现,公交车在工作日和非工作日的运行规律存在明显差异,工作日的交通状况更为复杂.因此,选取2020年10-12月的工作日数据作为研究对象.其中,12月最后14 d中的工作日数据作为测试集,其他数据作为训练集.
本实验使用平均绝对误差(MAE)、平均绝对百分比误差(tMAPE)和均方根误差(tRMSE)作为模型的评价指标.其中MAE和tMAPE用来衡量模型的预测精度,tRMSE用来衡量模型预测的稳定性.
3.2 特征选取与参数选择
首先,对模型参数进行初始化.LSTM层、BiLSTM层和全连接层的隐藏节点个数分别设置为150、75和15.对模型预输入特征进行特征消融实验,结果如图3所示.以tMAPE为精度衡量指标,将未进行消融实验的预测结果与经过消融实验的预测结果进行对比,其精度相对提升比均大于0.由此可见,预输入的特征对于模型预测精度均可起到提升作用.其中,相对发车时间和发车时刻对于预测精度的提升最为明显,预测精度相对提升比分别为3.78%和3.43%.对比天、周、月3个维度的运行规律特征可发现,处于周维度的运行规律特征对于预测精度提升最为明显,预测精度相对提升比为2.05%.因此,最终确定预输入的特征为模型的最终输入特征.
对比不同批次大小、不同学习率、不同时间步长DLA-BLSTM模型的预测性能,实验结果如表2所示.当批次为64、学习率为0.000 5、时间步长为4时,模型可取得最优预测性能,由此可确定模型的最终参数.

图3 特征消融实验结果Fig.3 Feature ablation experiment results

表2 不同参数实验结果对比
3.3 不同预测模型对比
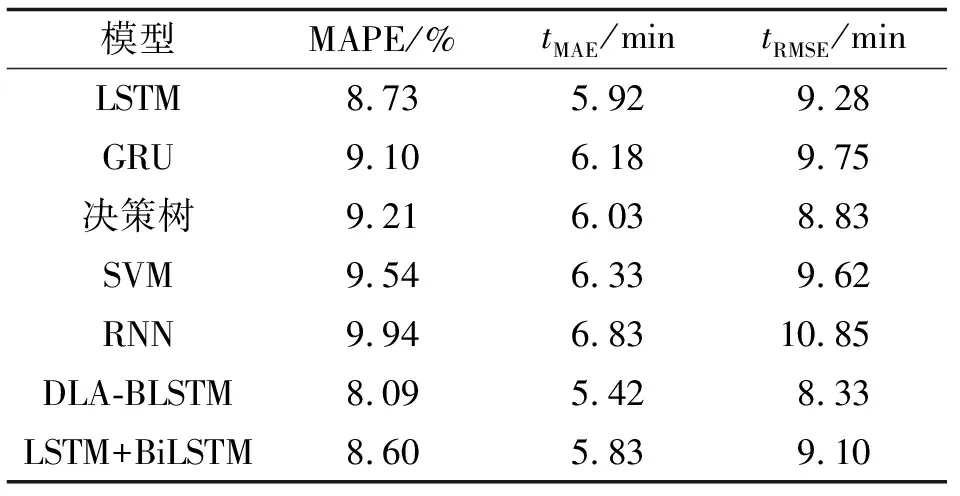
表3 不同预测模型实验结果对比
将DLA-BLSTM预测模型和其他行程时间预测模型进行实验对比,结果如表3所示.相较于未加入注意力的双层、双向LSTM模型,加入双注意力的DLA-BLSTM模型(LSTM+BiLSTM)的MAPE提升5.93%,说明注意力的加入对于模型预测精度提升起到促进作用;相较于传统的单层LSTM预测模型、门控循环神经网络(gate recurrent unit,GRU)模型、决策树模型、SVM模型、RNN模型,DLA-BLSTM预测模型的预测精度显著提升,其MAPE可分别提升7.33%、11.10%、12.16%、15.20%、18.61%,DLA-BLSTM预测模型在行程时间预测上具有更高的预测精度.
3.4 不同时间误差对比
分别对测试集的10 d数据进行全天平均预测误差分析.如表4所示,模型在12月25-31日的预测精度最差,其MAPE分别为11.35%和12.49%.这是由于12月25日是圣诞节,12月31日是跨年日,在这两个特殊日中,市民大量出行,导致城市拥堵情况频发,路段交通情况复杂,公交车行驶过程的规律性降低,DLA-BLSTM模型的预测精度有所下降.但除12月25日和12月31日这两个特殊日外,其余8 d都取得较为不错的预测效果,其余8 d的MAPE为7.15%、tMAE为4.50 min.
在不考虑特殊日的情况下,分析测试集中星期一至星期五的全天平均预测误差,结果如表5所示.模型在星期一至星期五的预测能力相对稳定,虽然在星期五的预测精度会略有不足,但总体上未出现误差明显增大的情况.这可能是由于星期五作为工作日的最后一天,会有较多市民选择在当晚出行,从而导致预测难度增大,模型的预测精度有所下降.

表4 不同工作日实验结果对比

表5 星期一至星期五实验结果对比
同样,在不考虑特殊日的情况下,对DLA-BLSTM模型在各个时间段的平均预测误差进行分析.模型在平峰期(6:00—7:00、8:30—17:00、19:30—22:30)的MAPE为6.54%,在早高峰(7:00—8:30)的MAPE为7.67%,在晚高峰(17:00—19:30)的MAPE为9.06%.由此可见,公交车在平峰期可以取得较高的预测精度,在早高峰误差仍可维持相对较低的水平,但在晚高峰阶段误差明显上升,预测能力有所下降.
3.5 到站时间估算分析
通过训练集获取星期一至星期五各个10 min时间分片内的相邻路段行驶时间占行程时间的平均占比,基于平均占比和预计行程时间,对各站点间的行驶时间进行估算,实现对公交车各站点到站时间的估算.按照当前运行班次距离目标站点(乘客上车点或乘客下车点)的累积站点数,统计B2路和560路公交车在不同累积站点数上的到站时间误差,实验结果如表6所示.由于公交车发车间隔短,因此最近邻乘客上车点的公交车的累积站点数相对较少.在本预测方法中,当累积站点数为5个时,tMAE为2.00 min左右,可以为乘客提供较为准确的上车时间参考.在乘客乘车过程中,途经站点数相对较多.通过本预测方法,当累积站点数为10个时,tMAE为3.00 min左右;而当累积站点数为15个时,tMAE为4.00 min左右.尽管随着途经站点个数的增加,公交车的预计到站时间误差也会随之增大,但误差增大速度较为缓慢,可以为乘客提供较为准确的下车时间参考.
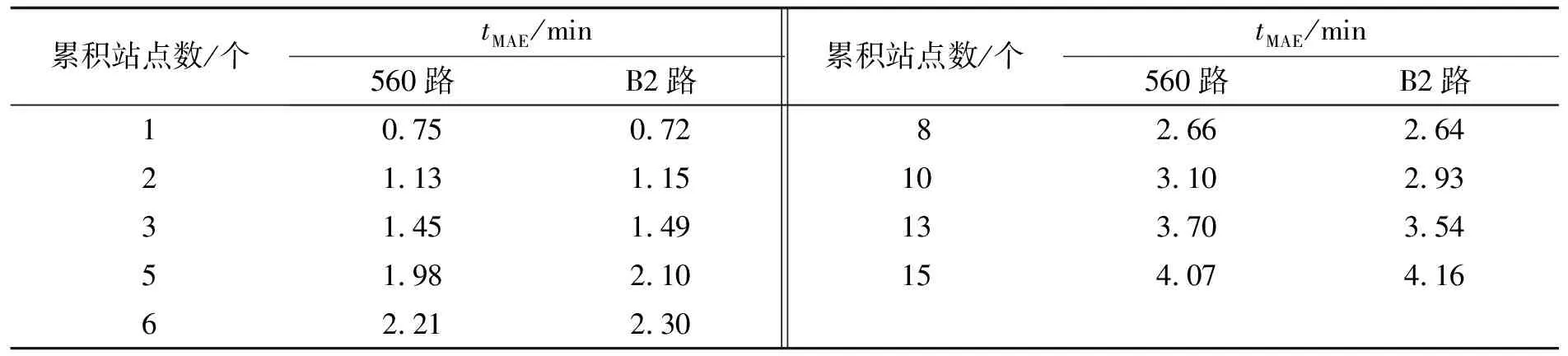
表6 到站时间预测实验结果
4 结语
DLA-BLSTM模型能够获得准确性较高的预计行程时间,其MAPE为8.09%.以MAPE为精度衡量指标,与未加入注意力的双层、双向LSTM模型、LSTM模型、GRU模型、决策树模型、SVM模型、RNN模型相比较,DLA-BLSTM模型的精度可分别提升5.93%、7.33%、11.10%、12.16%、15.20%、18.61%.通过将公交车到站时间问题转化为行程时间预测子问题,实现对公交车到站时间的估算,误差累积速度较慢.当累积站点数为5个时,误差可保持在2.00 min左右;当累积站点数为10个时,误差可保持在3.00 min左右;而当累积站点数为15个时,误差仍可保持在4.00 min左右.DLA-BLSTM模型可同时向乘客提供精度较高的预计上车时间和下车时间,满足乘客的出行需求,为乘客提供较为准确、全面的决策参考.下一步,将在提升DLA-BLSTM模型在高峰期、特殊日的预测能力方面展开研究,并基于该模型构建公交车预计到站时间可视化平台,提升其实际应用价值.
