改进YOLOv5网络模型的车位检测方法
2023-05-31马中原彭育辉黄炜
马中原,彭育辉,黄炜
(福州大学机械工程及自动化学院,福建 福州 350108)
0 引言
随着我国汽车保有量不断增长,城市停车难问题日益突出,自动泊车技术作为解决停车难问题的有效手段成为智能驾驶交通领域研究的重点之一[1].车位检测是实现自动泊车的重要前提,相较于基于超声波雷达的车位检测方法,基于图像的车位检测方法可以获得汽车周围更丰富的环境信息,是车位识别的重要技术路线.
基于视觉图像的车位检测方法近年来取得了积极进展.Hamada等[2]使用Hough变换提取车位线,并根据几何约束推断停车位.Zhang等[3]利用滑动窗口和AdaBoost分类器技术检测车位角,通过角点组合推断车位.Li等[4]将车位线和车位角检测结合起来,进一步提高车位检测性能.但这些方法都是基于低级的视觉特征,容易受到阴影等环境因素干扰.随着卷积神经网络技术的快速发展,Zhang等[5]提出一种基于深度学习的车位检测方法DeepPS,首先利用YOLOv2检测车位角点,然后通过局部图像分类网络和模板匹配获取车位类型和车位方向,该方法能有效检测出各种车位,但需要两个深度神经网络配合,使得检测效率较低.Huang等[6]使用深度学习方法对车位角点的位置、类型和方向进行预测,然后利用几何规则对角点进行分组以推断车位,但该方法只能检测平行或者垂直车位.Jiang等[7]使用语义分割方法检测车位,利用Mask RCNN检测车位角点,并生成掩码,然后利用线段检测等后处理方法提取、组合车位线来推断车位.Li等[8]应用YOLOv3检测车位槽头和角点,然后利用先验几何信息推断出车位,但该方法需要复杂的基于规则的方案来推断车位方向,并且由于网络参数量较大,使检测过程计算较为复杂,难以用于工程实践.Min等[9]使用图神经网络方法检测车位,基于深度神经网络检测车位角点,利用图神经网络聚合相邻角点以生成停车位,但该方法缺少方向性信息,无法用于斜车位检测.
综上所述,本研究提出一种基于改进YOLOv5的车位检测方法(orientation and Ghost YOLOv5,OG-YOLOv5),在实现车位检测网络轻量化的同时保证了检测精度.与以往的车位检测方法相比,所提方法基于单阶段网络实现端到端训练,无需经过复杂的后处理程序便可以获得完整的车位信息.
1 算法概述
1.1 算法总体架构
与DeepPS[5]和VPSNet[8]方法不同,所提算法将车位角点、入口线检测和分隔线方位回归结合起来,把车位检测问题转化为基于单阶段网络的多目标检测和方位回归问题.算法的总体架构如图1所示,将车位图输入OG-YOLOv5网络中,通过角点配对算法对预测结果中的角点进行配对,进而推理出各种类型的完整车位,且不受车辆自身位置的影响.同时,通过检测尺度裁剪、Ghost卷积替换、添加ECA注意力机制和优化损失函数对网络进行改进,在提高推理速度的同时保证检测精度.

图1 算法总体架构Fig.1 Algorithm architecture
1.2 相关定义
图2为车位角点和入口线的示例图像,它们之间的几何位置关系如图3所示.

图2 车位角点和入口线Fig.2 Marking points and entrance lines

图3 几何位置关系Fig.3 Geometric position relationships
图中,车位角标注信息由中心点m(x,y)、边框宽度Wm和高度Hm等参数组成.入口线标注信息的计算式为

(1)
式中:t(x,y)为入口线的中心点;Wt和Ht分别为入口线边框的宽度和高度.
分隔线方位信息由2D单位向量表示,通过车位角点mi和分隔线另一端点si来计算,为方便网络的读取和训练,将其归一化处理,即

(2)

2 YOLOv5网络改进
2.1 检测尺度裁剪
考虑到本研究基于逆透视图进行车位检测,待检测目标尺度稳定,为减少网络模型的参数量和计算量,提出在网络特征融合部分对尺度变化范围进行精简,即将3个检测尺度减少至2个,相应地减少C3模块、卷积层和上采样操作等,从而降低计算成本.
2.2 Ghost模块
本研究应用GhostNet网络[10]中的Ghost模块替换YOLOv5网络中的部分卷积层,实现模型的轻量化.Ghost模块由普通卷积得到基础特征图,进行线性操作获得冗余特征图,在指定维度将这两部分特征图拼接起来,既保证检测精度,又减少网络计算复杂度,获得更轻量的车位检测网络.
2.3 ECA注意力机制
轻量卷积神经网络的参数量越少则运行效率越高,但有限的参数量也是限制检测效果的主要因素.为此,通过在网络主干中添加ECA注意力机制[11]达到提升模型性能的目的.
构建OG-YOLOv5模块如图4所示.其中,图4(a)为Ghost模块,引入ECA注意力机制,设计如图4(b)所示的ECA-Ghost Bottleneck模块,得到如图4(c)所示的ECA-C3Ghost模块.OG-YOLOv5网络结构如图5所示.

图4 构建OG-YOLOv5网络所用的模块Fig.4 Modules used to construct the OG-YOLOv5 network

图5 OG-YOLOv5网络结构Fig.5 Network structure of OG-YOLOv5
2.4 损失函数优化
在本研究车位检测任务中,损失函数由分类损失、置信度损失、边框预测损失和方位回归损失这4部分组成.对于置信度损失和分类损失,本研究任务中采用深度学习中常见的交叉熵损失函数进行计算,以加快模型收敛.常见的目标框位置损失函数有GIoU、DIoU、CIoU,以及基于IoU损失的统一幂化α-IoU[12].经过对比实验,使用α-CIoU来计算目标框的定位损失,可表示为

(3)
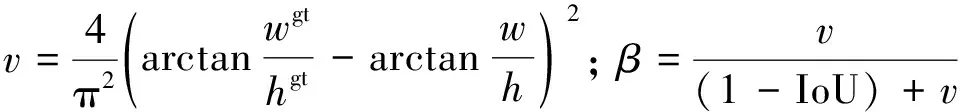
(4)
式中: IoU为预测框和真实框(ground truth,gt)的交并比;b和bgt分别为预测框和真实框的中心点;ρ(·)为欧式距离;c为包围预测框与真实框最小外接矩形的对角线长度;β为权重系数;v为长宽比一致性参数;wgt/hgt和w/h分别为真实框和预测框的宽高比;α为power参数.
在方位回归任务分支中,采用SmoothL1损失函数,即

(5)

(6)
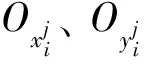
OG-YOLOv5车位检测网络的预测元素如图6所示.图中,Cx、Cy代表预测框的中心,W、H代表预测框的宽和高,P0代表物体置信度,P1、P2分别代表预测类别概率,Ox、Oy代表预测的方位信息.

图6 OG-YOLOv5网络的预测元素Fig.6 Components of the OG-YOLOv5 network prediction
3 完整车位推理
为得到完整车位信息,利用角点配对算法对预测到的车位角进行配对,实现完整车位信息推理.如图7所示,将车位角m1、m2和入口线边界框ti之间的关系分为6种情况.
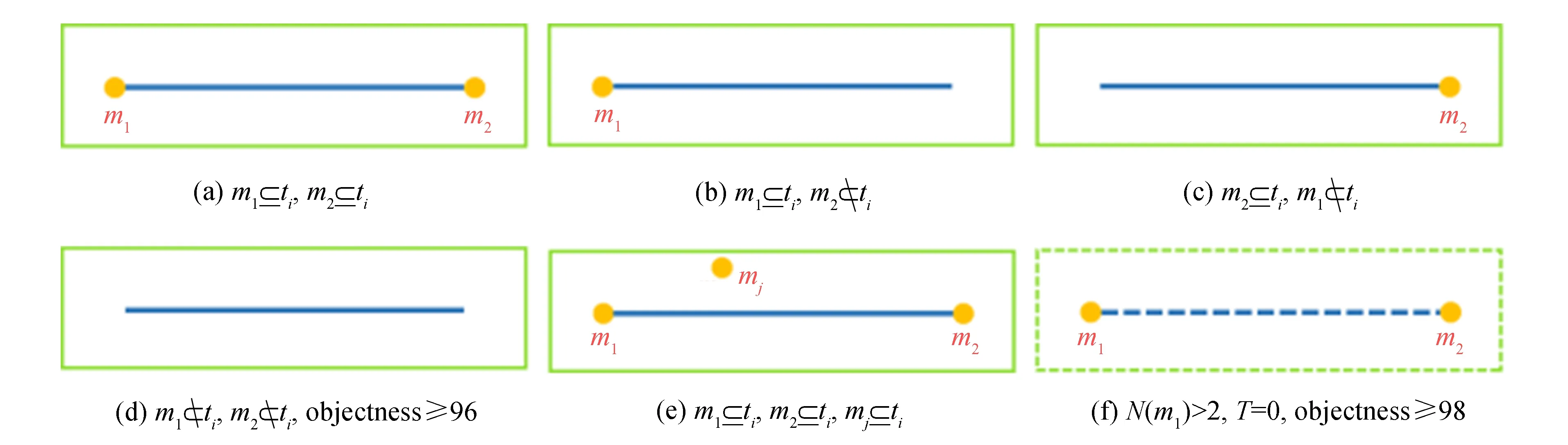
图7 入口线和车位角点的位置关系Fig.7 Location relationship of marking points and entrance line

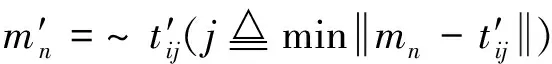
(7)

对于情况(d),入口线边框ti中不包含车位角,且ti的置信度大于98%,则认为ti包含有效的入口线.通过计算边界框ti对角线及其附近区域的像素平均值,确定角点所在的对角线,即有

(8)
式中: APVi是对角线区域A的平均像素值;(x,y)和N分别为区域A中像素的坐标及像素总数.
为获得完整车位,根据配对角点间的距离来判断车位类型,如图8所示.如果角点距离大于阈值dt,则为平行车位,其分隔线长度为d1;如果角点间的距离小于阈值dt,则为垂直车位或者斜车位,其分隔线长度为d2.
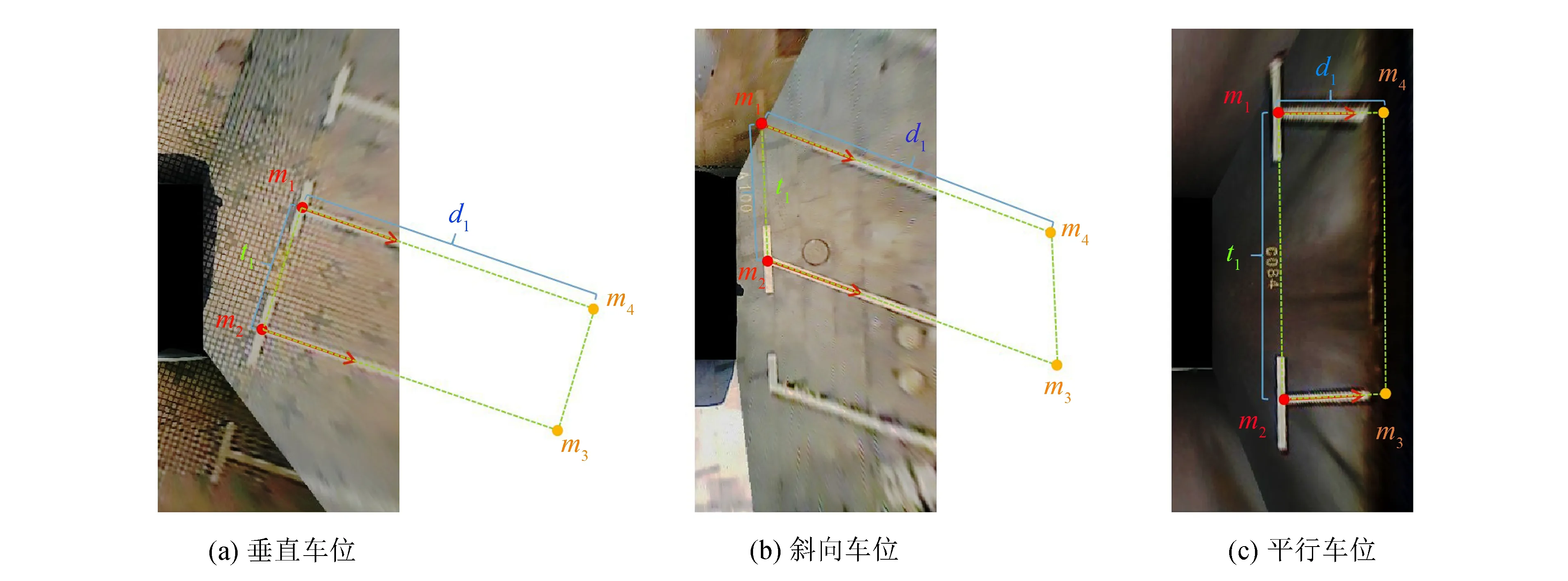
图8 完整车位推理Fig.8 Complete parking slot inference
图中车位的4个顶点,m1和m2是成功配对的车位角点,m3和m4是车位的另两个不可见角点,其计算式为
m3=diOp+m2;m4=diOp+m1
(9)
式中:Op为角点配对算法得到的方位值;di为对应分隔线的长度.
4 实验结果与分析
实验环境为Ubuntu1 6.04操作系统,服务器硬件配置为Intel Xeon Silver 4108处理器、NVIDIA GTX 1080 Ti显卡、32 GB运行内存.使用Pytorch 1.7深度学习框架和Python 3.8 编程语言实现本研究的车位检测网络,并使用cuda 10.1和cudnn 7.6.5对GPU进行加速.
4.1 实验数据集及训练参数设置
实验数据集共包含27 536张车位图像[5,13],涵盖平行车位、垂直车位和斜车位,以人工方式标注定

表1 超参数设置
义的车位信息,通过调整亮度、添加高斯噪声进行数据增强.为更准确地预测分隔线方位,每隔5°对数据集进行一次旋转增强.在模型训练阶段,训练集和验证集比例为7∶3,迭代批量大小设置为64,初始学习率为1×10-3,采用SGD优化算法,动量为0.843,衰减系数为0.000 36,最大迭代Epoch为120,文中设置的超参数如表1所示.
模型的评价指标为mAP@0.5、参数量、浮点运算量(FLOPs)、GPU和CPU检测时间及模型大小.OG-YOLOv5训练时的总损失值、方位预测损失值及mAP@0.5随着迭代次数的变化趋势如图9所示.
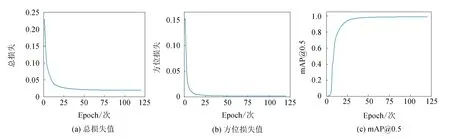
图9 OG-YOLOv5训练结果Fig.9 Results of OG-YOLOv5 training
从图9(a)中可以看出,总损失在训练初期迅速下降,表明网络正在快速拟合,模型的学习效率较高;当Epoch为70时,损失曲线开始变得平缓,损失值稳定在0.019 0附近,模型达到稳定状态.从图9(b)中可以获知方位回归损失值也有类似变化,最终稳定在0.001 8,表明所添加的方位回归分支可以得到很好训练.训练时的mAP@0.5的变化趋势如图9(c)所示,模型在经过30个Epoch的训练后,模型在验证集上的平均精度约为90%,并随着迭代次数的增加稳步上升,最终稳定在98.8%.
为了验证本网络改进方法的有效性,通过消融实验来逐步验证OG-YOLOv5网络结构改变所引起的性能变化,消融实验结果如表2所示.

表2 实验对比
由表2可知,基础网络的mAP@0.5为98.2%,模型1裁剪了80 px × 80 px检测输出层,参数量和计算量分别减少8.1%和17.6%,对应的mAP@0.5减少0.4%;模型2通过卷积替换,网络参数量和计算量分别降至原来的32.0%和28.3%,但mAP@0.5也较原始网络降低2.0%;模型3引入ECA注意力机制,在参数量和计算量几乎不变的情况下,mAP@0.5提高1.9%,表明ECA在参数有限的情况下更加关注重要特征通道的学习,起到提高模型检测精度的作用;最后,采用α-CIoU作为边界框回归损失函数,相较于模型3,mAP@0.5提高0.7%,表明α-CIoU作为边界框回归损失函数可改善模型的检测精度.另外,OG-YOLOv5在GPU和CPU上的检测时间相较于原始YOLOv5分别减少16.2%和28.1%,表明OG-YOLOv5部署在计算资源有限的车载平台上更具优势.
为进一步验证OG-YOLOv5在精度和效率方面的优越性,与其他SOTA模型进行对比实验,结果如表3所示.

表3 不同网络模型对比
由表3可知,相较于YOLOv3和SSD模型,OG-YOLOv5在具有相近mAP的同时,大幅降低了模型参数量、计算量和模型大小.相较于轻量级的YOLOv3-tiny和YOLOv5s模型,OG-YOLOv5的平均精度分别提高9.9%和0.6%,且计算量减少65.1%和71.7%,模型规模也减少73.0%和67.1%,体现本改进模型具有较好的应用价值.
4.2 车位检测实验
采用文献[5]提供的评价标准对所提车位检测方法进行定量评价,与车位检测领域的SOTA方法(DeepPS和VPSNet)在验证集上进行比较,检测性能如表4所示.其中,Δ位置表示位置误差,Δ方向表示方向误差.

表4 不同车位检测方法性能比较
由表4可知,本方法在准确率和召回率方面比DeepPS方法分别高出3.17%和2.62%,其原因在于DeepPS方法组合了深度学习和人工设计的规则,无法实现综合优化;而本方法基于端到端可训练的单阶段网络实现,可以进行综合优化.相比于VPSNet方法,本方法检测准确率和召回率分别提高3.51%和1.24%,其原因在于针对车位检测任务对深度学习网络做了适应性改进,且本方法将车位方位加入到网络中进行训练,在预测阶段直接从模型中获得车位方位,能提供更准确的车位信息.由于本方法对YOLOv5网络做了轻量化改进,在检测时间方面具有较大优势.在车位定位方面,本方法取得最好效果,主要原因在于应用α-CIoU作为边界框回归损失函数,能更准确地预测目标边界框,相对应地提高了车位定位精度.另外,本方法的方向误差较DeepPS方法减少36.4%,主要原因在于DeepPS方法是使用传统的模板匹配方法估计车位方向,更容易受到光照等环境条件影响,而本方法的车位方位是由网络预测得到,具有更高精度.本方法车位检测结果如图10所示.当图像出现车位线严重破损、车位线被遮挡,以及地面光线反射等情况时,如图11所示,目标置信度较低,会导致本车位检测方法失败.在后续的工作中将针对性地增加此类训练集样本,以解决上述问题.

图10 车位检测结果Fig.10 Results of parking slot detection

图11 本方法检测失败情况Fig.11 Failure cases of the proposed method
5 结语
针对自动泊车过程的车位检测,提出一种基于改进YOLOv5的轻量级车位检测方法OG-YOLOv5.该方法将车位角点、入口线检测与分隔线方位回归相结合,根据网络预测结果可直接推断出完整车位.与以往基于深度学习的车位检测方法相比,本方法无需复杂后处理阶段,即可实现车位检测过程的综合优化.另外,通过检测尺度裁剪、卷积替换实现模型轻量化;通过引入ECA模块、优化损失函数提高目标预测精度.实验结果表明,本方法在检测性能和定位精度方面优于以往的方法,且大幅度降低网络复杂度,提高车位检测效率.后续研究将围绕模型量化、车载设备端部署展开,逐步提高自动泊车系统的智能化水平.
