基于Stacking模型融合的ESG评级预测研究
2023-05-30李虹霖
李虹霖


关键词:ESG; Stacking算法;ADASYN算法;机器学习
1引言
ESG理念由环境(Environment).社会(Social)、公司治理( Governance)3方面组成,于2004年在联合国正式发布的报告中被首次提及,如今逐渐成为国际广泛认可的主流投资理念[1]。2022年5月27日,国资委发布《提高央企控股上市公司质量工作方案》,明确提出要构建具有中国特色的ESG信息披露规则、ESG绩效评级和ESG投资指引,并实现2023年相关专项报告披露“全覆盖”。这足以看出当下ESG的重要性。而研读文献后发现,我国的ESG研究还处在发展期,多数研究还集中在基本理论和ESG评级体系的构建与完善上[2-4]。这些研究中鲜有机器学习等算法理论的延伸:极少数采用数据挖掘算法,也仅仅是应用在数据采集、缺失值处理以及用单一模型建模探究ESG评级后的影响上[5-8]。如今,大数据繁荣发展,机器学习在ESG的表现上却鲜有人知。基于此,本文将机器学习渗透到ESG领域,并将多个模型集成分析,旨在为后续ESG评级相关研究奠定理论基础与拓宽研究道路,也为机器学习算法提供新的可适用场景;同时,本文针对Stacking融合算法存在的不足进行改进,在日后的研究中为其进一步精进提供帮助。
2基本理論方法
2.1Stacking算法理论
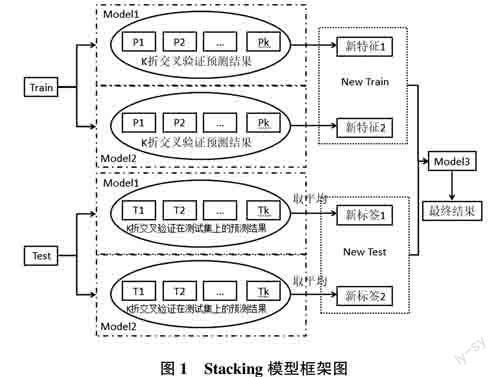
Stacking融合算法最早由Wolpert[9]于1992年提出,其基本思想是利用算法的差异性进行多层叠加,增强模型预测精度和泛化能力。它能够将多个模型的预测结果相融合,再投入其他模型中预测,实现将多个模型进行多层叠加。以2层Stacking融合为例,其基本算法理论如下。
其算法第一层框架为基学习器,通常选择多个不同分类器。并在每个基学习器训练时加入交叉验证,即对任意模型Mi,做K折交叉验证,且将每一次训练集交叉验证预测结果均储存为Pi,则对于每个模型Mi来说,会有Pi=[Pi,…,pk],同时每次交叉验证都需要对原测试集进行预测,即同时获得一个模型在原测试集上的预测集ti,那么对于模型Mi来说,就会得到Ti=的数据维度将会是原测试集的K倍,为达到与原测试集相同的维度,需对Ti求取平均值。
其算法第二层框架为元学习器,其输入特征由原数据的真实标签Y与基学习器训练后的P=(Pi)共同构成。由于变量特征过少,若元学习器过于复杂可能会导致过拟合,因此通常选用简单逻辑回归模型(L)。经过元学习器模型训练后,对第一层训练的测试集结果进行预测,并得到最终的预测结果。具体算法框架如图1所示。
2.2改进Stacking算法理论
2.2.1第一层训练框架的加权优化
在传统Stacking模型中,每次迭代模型都需要在原测试集上再预测一次,故K折交叉验证会使每个基学习器都在原测试集上预测K次,进而使预测集维度扩大K倍,因此需要对预测集取平均,但没有考虑到基学习器拟合效果的影响[10]。而元学习器的训练却依赖于基学习器的预测集,所以基学习器的拟合效果不容忽视。故本文所改进的Stacking模型在测试集取平均日寸加入了精度衍生出的权重因子,为高精度预测集赋予较小权重,即T'i =wixTi,其中:
2.2.2第二层训练框架的特征改进
在传统Stacking模型元学习器训练时,只采用基学习器预测集,若选择2个模型进行Stacking融合,则特征变量X只包含2个模型的预测标签。这就导致特征变量少,可能丢失特征信息[11]。但若将特征全部投入,又产生变量冗余,且元学习器的训练集中已经包含原有变量的预测结果,再加入全部变量容易造成模型的过拟合。因此,本文提出在元学习器训练前加入特征选择的步骤,将筛选后的特征变量与基学习器预测集相结合,以构成元学习器的新训练集。
常见的特征选择方法有递归特征消除法(RFE)、LightGBM特征重要性法等。由于RFE是基于后向迭代的算法,容易陷入局部最优,且如果选择的模型稳定性不高,则它也不稳定。而LightGBM在特征选取上更灵活,且在训练过程中已记录其特征重要性,不用额外进行特征选择,故本文选用LightGBM来进行改进算法中的特征选择。
3数据处理
3.1数据来源
ESG数据主要是由企业的财务报告、企业社会责任报告与企业ESG报告等披露。本文主要收集和讯网企业社会责任板块中2010~2021年所有可获取的指标、CSMAR数据库中的部分环境表现指标,并结合其他数据库进行查缺补漏。若上述数据源有缺失的,再辅以搜索上市企业的ESG报告等公开报告,通过Python中的pdfplumber库进行采集补充。最终共收集到39 468条样本数据,获取42个基础指标,其中14个是/否二分类指标、27个数值指标、1个5分类指标(ESG评级),涵盖企业财务、环境表现、社会表现与公司治理4方面。具体情况如表1所列。
3.2数据预处理
3.2.1缺失值处理
ESG的概念在我国还处在新兴上升期,属于非强制性披露指标,企业对其相关的披露很少:又因为它目前没有统一衡量标准,进而导致企业所披露的指标充斥着差异性与随意性。所收集到的数据极可能面临数据缺失的问题。同时,在采用Python进行PDF处理时,会利用OCR识别技术提取表格数据,而目前识别准确率只能达到90%左右,并不能保证100%正确,且会跳过无法识别的表格。综合以上各因素的影响,最终所收集到的数据集有一定的缺失值,直接使用会导致模型预测效果大打折扣,需对其进行缺失值处理。
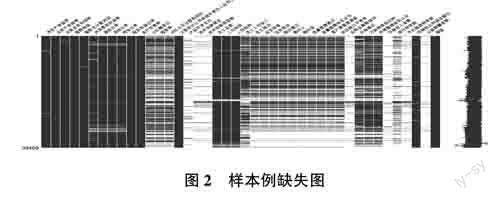
如图2所示,空白比例越大则样本缺失越严重,可以明显看出产品开发支出、技术创新理念、技术创新项目数、反商业贿赂培训、环保投入金额、节约能源种类数及公益捐赠金额7个特征的缺失率大,而数据较完整的大多为财务报表中所涵纳的指标。这是由于企业对财务报告的披露十分严格,而对于其他类型指标的披露具有自主性,故鲜少披露。针对上述7个高度缺失的指标,即使采用数据挖掘手段进行填充,对模型也无较大意义,因此直接剔除。而针对缺失值数量非极端的情况,本文选择随机森林填充法替换,即利用随机森林算法进行拟合填充。随机森林是非常有效的集成学习算法,对于缺失值的拟合填充效果较好,不论连续型、分类变量均适用。
3.2.2数据不平衡性处理
当分类模型的标签类别不均衡时,占比越大的类会成为影响准确率最主要的因素。在此情况下,通常会减少或忽略少数类,以多数类进行训练的模型,在少数类上的表现自然不尽如人意,导致模型的实际应用价值较低。因此,样本类别不均衡是数据预处理日寸需要重点关注的问题。
为解决该问题,通常选择简单易实现的过采样方法。其中,2个优良算法即为合成少数过采样算法(SMOTE)与自适应综合过采样算法(ADASYN)。前者根据少数类,利用最近邻算法人工合成新样本;而ADASYN则是在少数类的低密度特征空间区域中生成更多的合成样本,在高密度区域中生成较少的样本,其最大的特点是能够自动决定每个少数类样本需要产生的合成样本数量,而不是像SMOTE那样对每个少数类样本均合成相同数量。故本文选择ADASYN方法平衡样本数据。优化后结果如表2所列。
由表2可知,原数据集中ESG评级为D的企业最多,评为A的企业寥寥无几,B,C,E级的企业数量相差不大,但远少于D级,足以体现其严重的不平衡性。经过ADASYN算法优化后,大量填充了少数类样本,样本例数量趋于平衡,样本量也由之前的3.9万扩充为了17.2万,增长了约3倍。
4实例分析与结果
数据集预处理后,采用Python进行模型实验。分别将2种模型用Blending与Stacking算法进行融合。2种算法的主要区别在于在基学习器的训练中是否采用交叉验证。Blending算法的基学习器直接对K个模型分别进行训练与预测,未进行交叉验证,故它也不需要对原测试集预测集取平均。
实验中,本文均选择表现较好的LightGBM与KNN模型作为基学习器,并对Stacking模型做5折交叉验证,元学习器均选择LR模型。针对传统Stacking算法存在的问题,本文提出了改进方案,详见本文2.2节。对于改进后的Stacking模型,基学习器与元学习器的选择不变。设置训练集与测试集的比例为8:2;交叉验证为5折;其他模型参数设为默认值。
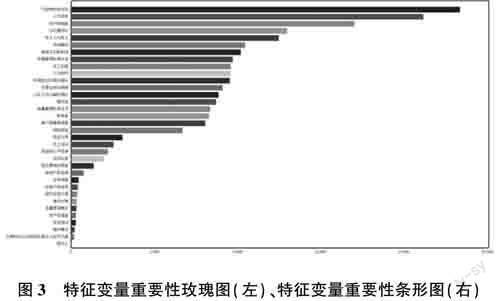
在输入特征的改进上,为不丢失重要变量,设定max_ num—features参数的阈值为剔除缺失后的总特征数34,并选择增益galn作为判断依据。
如图3所示,在增益值为2000时出现了急剧变化,故将阈值设定为2000。最终剩余18个特征,特征变量剔除比为47.06%。则新特征集一共包含20个特征变量,仍由LR模型训练。最终各模型实验结果如表3所列。
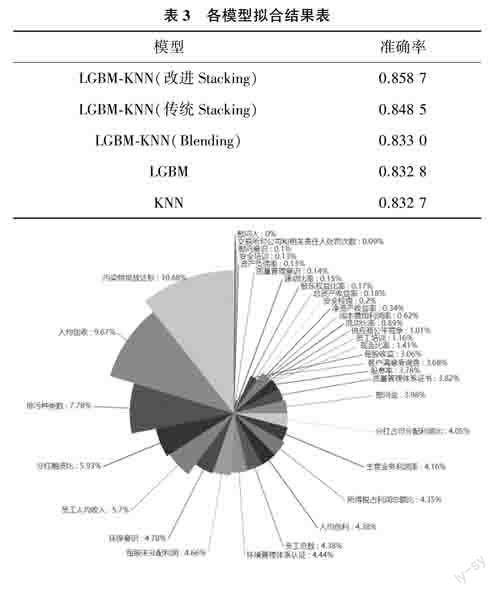
从表3可以看出,相较于单- LGBM与KNN模型.Stacking算法拟合效果更好;同时,它的训练效果也比Blending模型更佳,则可以认为加入交叉验证后获取新训练集进行预测的效果会比采用直接预测后获取的新训练集的效果更佳,侧面验证了交叉验证的优异性。而本文提出的加权与特征选取改进后的Stacking模型融合算法是几種模型中表现最佳的方法,准确率达到85.87%,说明该方法在ESG评级预测上是有效的。
5结束语
本文利用Stacking算法将集成学习器再度融合,并拓展到ESG评级领域,为ESG的评级系统提供了可选择的思路。从某一层面来说,其验证了利用机器学习进行ESG评级的有效性,为机器学习在ESG领域进一步的应用提供了理论基础。但本研究还存在诸多不足,其一在于数据指标的缺失上,不过随着未来ESG领域监管的加强,信息披露的增加,该问题将得到极大地改善;其二在于模型选取上,在后续研究中,可以通过网格搜索算法选取基学习器。
