基于前缀树的业务流程增强预测方法
2023-05-30孙大志
孙大志

摘 要:预测性业务流程监控主要利用已经发生的流程执行的数据,目前的主流方法是通过建立深度学习模型预测在线流程的执行情况。现有的流程预测深度学习方法主要利用历史事件日志数据来学习模型进行预测,较少考虑日志间的行为关系,本文通过挖掘流程执行期间日志之间的行为关系,以帮助提高预测模型的质量。将挖掘出的日志间的行为关系使用前缀树进行表示,并使用现有的基于深度学习的业务流程预测模型,在结果预测阶段通过前缀树结构筛选符合行为关系的预测结果提供决策支持,以此提高预测结果的精确度,并在事件日志中与基线方法进行比对,在预测下一个活动以及预测后缀方面,预测精度均有所提高。
关键词:业务流程监控;深度学习;信息挖掘;前缀树;决策支持
中图分类号:TP391.9 文献标识码:A 文章编号:1673-260X(2023)02-0044-06
引言
对企业而言,找到一种能够预测业务流程的未来行为的技术非常重要,企业需要在流程实例运行之前识别出不符合标准的异常事件,以便能够根据相应的信息及时找到应对措施来避免损失,而预测性流程监控[1]主要从事件日志中训练模型,用来预测一个正在进行的案例在未来的执行情况,可以为企业提供所需预测技术,是目前业务流程管理领域的一个研究热点。
针对不同的预测任务,对预测性流程监控技术的分类有所不同,现有预测性流程监控技术论文主要分为三类:第一类侧重于时间方面的预测,Aalst等人通过从事件日志中构建带注释的变迁系统来预测流程的剩余时间[2]。Rogge-Solti等人使用了一种特定类型的随机Petri网,它可以捕获任意持续时间的分布,以此来预测一个案件的剩余时间[3]。Aburomman等人提出了一种新的基于向量和基于ATS的预测业务流程中的剩余时间方法,该方法考虑了与过程执行相关的结构特征或属性,如频率、重复、周期等[4]。Verenich等人将预测分解为更基本的向量,在活动的级别上预测性能指标,以一种透明的白盒方法预测正在进行的过程实例的剩余周期时间。第二类侧重于预测活动的结果。这类方法目标在于产生预测和建议的方法,以减少风险[5]。Conforti等人提出了一种技术,以支持过程参与者做出风险知情的决策,目的是降低过程风险。通过遍历从过去流程执行日志中生成的决策树来预测风险[6]。Pika等人通过识别和利用事件日志中可观察到的统计指标来预测与时间相关的过程风险,这些指标强调了超过最后期限的可能性[7]。Teinemaa等人将结构化数据和非结构化数据结合以尽早预测出违约客户无法在合理期限内支付任何款项的情况[8],Maggi等人提出了一个框架,根据给定情况下执行过的活动序列和案例中最后执行过的活动的数据属性值来预测案例(正常与异常)的结果[1]。第三类侧重于预测未来事件的延续。Lakshmanan等人提出了一个马尔可夫预测模型来建立一个特定于实例的概率模型,该模型可以预测给定一个运行过程实例的实例中特定事件的概率[9]。Polato等人提出了使用简单回归、上下文信息回归和数据感知转换系统来预测剩余时间和未来活动的序列[10]。Evermann等人提出了一个其中有两个通过反向传播训练的隐藏层的循环神经网络(Recurrent Neural Network,RNN)[11,12],而Tax等人利用长短期记忆(Long Short Term Memory,LSTM)和一個基于活动和时间戳的编码用来预测事件的延续[13]。Taymouri等人提出了一种对抗性训练框架通过同时训练两个神经网络,一个作为生成器,一个作为鉴别器,让他们相互对抗学习使得生成器能够更好地解决下一个事件预测的问题[14]。Lin L等人设计了一个组件调制器来定制事件及其属性表示的权重对于每个预测任务,使用不同的调制器同时进行下一事件及其属性的预测并最终预测事件序列后缀[15]。宫子优等人使用时间卷积网络将业务流程中的事件及其属性作为输入,在业务流程的执行场景中预测流程的下一个事件和剩余流程[16]。黄晓芙等人提出了一种基于频繁活动集的序列编码处理日志中的低频活动,并通过搜寻历史相似数据进行预测下一个活动[17]。
上述预测方法都是根据已发生事件日志中活动的执行顺序,时间戳以及已执行活动中的数据属性值训练预测模型后进行预测。事实上,现有绝大多数预测性业务流程监控方法只考虑利用活动以及活动属性值训练模型进行预测,并未考虑日志中隐藏的行为信息,本文通过挖掘算法挖掘流程执行期间日志之间的行为关系并用来提供决策支持增强业务流程预测质量。
本文使用文本挖掘算法将日志活动的行为关系用前缀树表示,提出了一种将深度学习模型与前缀树结合的预测方法。在训练好的预测模型中利用前缀树增强预测正在进行的案例的未来执行情况。本文以LSTM模型[13]作为所提出方法的基础,在四个事件日志中预测了正在执行的案例的下一个活动及后缀,并与基线LSTM方法进行比较。结果表明相比只使用预测模型进行预测的方法,使用前缀树提供决策支持进行增强业务流程预测的方法精度有所提升。
1 基本概念
定义1 迹 一个迹?滓=<-a1,a2,…,an>∈A*是一个有限的事件序列,由定义在活动集A上的一系列活动组成。
定义2 事件日志 一个事件日志是活动集A上的多组迹的集合。
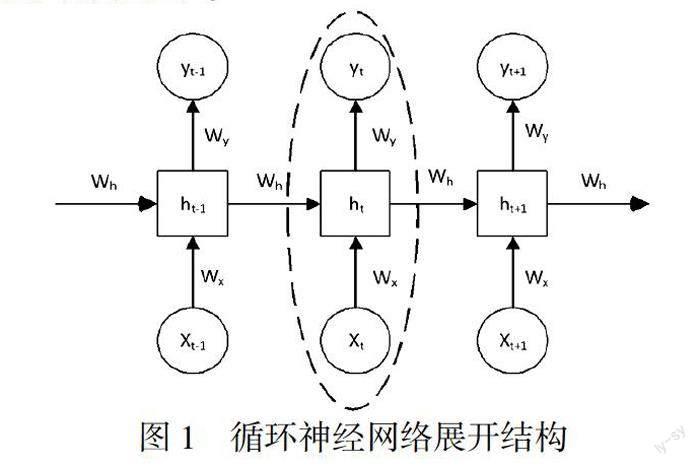
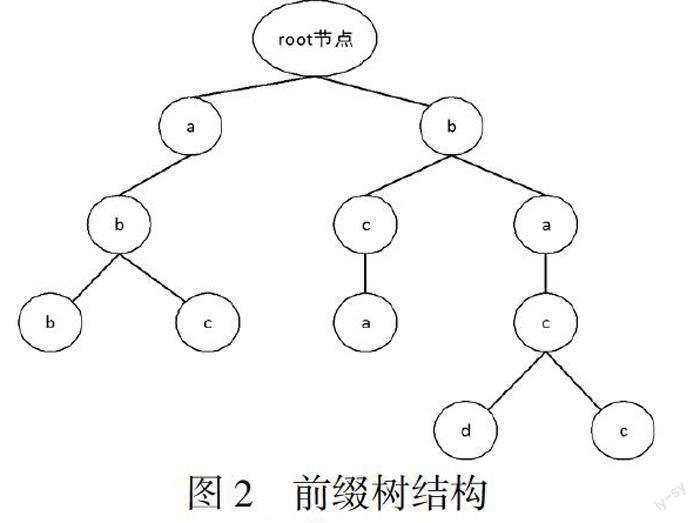
定义3 前缀迹 一个迹的前缀迹是它的从头开始的子序列,例如,给定一个迹?滓= 定义4 下一活动预测 给定一个前缀迹prefk(?滓)= 定义5 后缀迹 一个迹的后缀迹是其前缀迹的剩余部分的子序列,例如,给定一个迹?滓= 2 业务流程预测方法 2.1 循环神经网络与LSTM 人工神经网络是一种基于模仿大脑神经网络结构和功能而建立的一种信息处理系统(简称神经网络),在分类任务中作用非常显著[18]。人工神经网络主要架构是由神经元、层和网络三个部分组成。整个人工神经网络包含一系列基本的神经元、通过权重相互连接。神经元是人工神经网络最基本的单元。单元以层的方式组,每一层的每个神经元和前一层、后一层的神经元连接,共分为输入层、输出层和隐藏层,三层连接形成一个神经网络。输入层神经元经过权重加权之后得到的输出作为隐藏层神经元的输入,隐藏层神经元经过权重加权之后得到了输出层的输入。输出层经过激活函数的激活就可以进行分类任务的判别。其中每层神经元加权的权重通过基于梯度的优化进行反向传播从训练数据中学习得到。 RNN是神经网络的其中一个子类,它的展开之后的结构如下。 一个循环神经网络可以看作多个神经网络的连接,如虚线所示,对于任意的时间步长t,在这个时間步的执行就相当于一次神经网络的执行,Xt是输入层,ht是隐藏层,yt是输出层,此时ht包含所有时间步长到t时所提取的信息。在不同的时间步中输入不同的数据,通过当前时间步上的隐藏状态的激活以及输出层的激活,得到在此时间步在各个预测活动上的概率分布进行分类预测。在RNN中不同时间步的权重Wh,Wx,Wy是共享的。RNN已经被证明非常适用于序列化建模,(A.: Sequence Modeling: Recurrent and Recursive Nets.),例如,自然语言处理(Natural Language Processing, NLP)任务中,I like eating apple和The Apple is a great company。为apple打上标签,第一句中apple指代水果,而在第二句中apple指代一个公司,这种分类预测任务不仅与当前状态的输入有关,同时也取决于目前已经发生过的输入,正常的全连接网络单独的训练apple这个单词的标签,无法结合上下文去训练模型,循环神经网络可以通过不同时刻的参数共享,使得在时间步t可以获得前面t-1个时间步的状态信息来帮助进行预测。现实任务同样如此,下一个活动的发生不仅取决于当前的活动,同时取决于先前已发生的活动,因此,把预测任务看作是NLP任务,把迹中的每个活动看作是NLP任务中的单词,可以使用循环神经网络进行序列化建模。但对于基本的RNN来说,它只能够处理一定的短期依赖,并不能处理长期依赖关系,因此通过对RNN的隐藏层网络结构进行修改,产生了LSTM[19],它与基本的RNN相比引入了输入门、遗忘门、输出门三种门来保持和控制信息,能够长时间保存隐藏状态的信息,解决了RNN无法处理长期依赖关系的问题。 2.2 LSTM算法实现 目前已有许多预测过程监控方法使用带有LSTM单元的RNN。本文采用Tax等人提出的LSTM方法[13],它的执行方法依赖于活动序列编码,使用最为常用的one-hot编码,对于一个给定的活动集合A={a,b,c,d},需要创建一个索引函数,确定活动在集合中所处的位置,索引函数为index: A={a,b,c,d},有index(a)=1,即活动a在集合A中所处位置为第1个,活动b在集合A中所处位置为第2个。对活动序列进行编码时,为每个活动ai∈?滓创建一个长度为|A|的向量Ai,当前活动所处的索引值位置为1,其他位置均为0。迹的编码方式将迹中所有活动获得的向量组合成一个矩阵。训练阶段,使用编码好的迹训练LSTM模型,预测阶段,使用一个正在进行的活动序列(进行one-hot编码)进行预测监控。具体算法如下: 该算法输入一个已经训练好的LSTM模型,一个给定的最大迭代次数max,以及一个正在进行的活动序列prefk(?滓),通过迭代的预测下一个活动来预测后缀,当max=1的时候只迭代一次,即预测当前活动序列的下一个活动,max>1进行后缀预测。 3 使用前缀树增强预测方法 预测性业务过程监控使用存储在事件日志中的过去的迹来构建模型对未来进行预测,在某些场景非常有用,例如在医疗场景中,需已知患者执行了哪些活动从而对患者进行下一步的治疗方案进行决策,但现实中进行后续序列预测仍然存在很大的挑战,随着活动事件持续发生,预测后面序列越发困难,现有方法只考虑使用历史事件日志中的迹训练深度学习预测模型,并利用训练完成的模型预测未来活动的序列,忽略了历史事件日志中隐藏的行为关系。通过挖掘日志间的行为关系以流程图、前缀树、后缀树等形式进行表达,并结合深度学习预测模型可以帮助预测模型提高未知事件预测的质量。 3.1 从迹中学习 对历史事件日志的迹挖掘信息有多种方式,第一种为流程挖掘方法,通过流程挖掘方法获得活动的流程图,常见的几种流程图类型如下:(1)Petri nets(也叫petri网);(2)流程树(Process Tree,PT);(3)业务流程建模标记(Business Process Modeling Notation,BPMN);(4)直接跟随图(Directly Follow Graph,DFG)。上述方法能够展现活动之间的直接跟随关系。对于Petri nets,流程树以及BPMN模型,不仅可以确定活动间的直接跟随关系,同时可以展现活动之间的行为轮廓关系,例如两个活动之间相互排斥,两个活动相互严格顺序执行以及两个活动是并发执行,已知两个活动a和b是并发的,即a发生b一定发生,发生的顺序不定,预测时利用行为轮廓关系剔除不符合活动关系的迹,从而使得预测结果更贴近真实的结果,这些行为轮廓关系不止可以为深度学习模型预测提供决策支持,同时可考虑在训练模型阶段将行为轮廓关系编码作为输入属性进行预测模型的训练,这些工作在未来是我们尝试的方向。 第二种信息挖掘方式为数据挖掘,本文基础LSTM算法即是数据挖掘主要方法中的一类,属于预测模型方法,其余预测模型算法包括決策树、支持向量机等。 第三种信息挖掘方式为文本挖掘,文本挖掘是从非结构化的文本信息中抽取潜在的、用户感兴趣的重要模式或知识的过程,文本挖掘的主要研究内容包括关联分析、文本分类、文本聚类。转换一下思路,把事件日志看作文档,把迹看作文本中的字符串,可以使用文本数据挖掘相应的信息,本文的想法把迹看作字符串,使用字典树(也称前缀树)进行储存。字典树是一种字符串上的树型数据结构,在NLP中使用非常广泛,在NLP任务中,预测一句话的下一个单词需要此时所有已经发生过的单词即前缀,通过已知的前缀预测下一个可能的单词。前缀树支持有效的字符串匹配和查询,结构如下,下图展示使用abb,abc,bca,bacd,bacc字符串这几个字符串来构建的前缀树,该方法可以用作文本匹配,也可以清晰看出给定前缀的所有能够执行的后缀。 3.2 预测增强算法实现 本文使用文本挖掘算法将历史事件日志的行为关系用前缀树表示,结合深度学习预测模型,为预测模型提供决策支持,并在真实事件日志上进行了实验。算法2介绍了提出方法的伪代码,该算法在算法1的基础上得到,运用了前缀树为LSTM模型提供决策支持增强预测。算法如下,此时的输入为正在进行的迹、训练好的LSTM模型以及预测最大迭代次数,同时需要给定预测候选活动的最大个数k。 对于上述方法,在预测阶段同时预测前k个概率最大的活动,与迹进行拼接产生多个候选迹,按照概率大小对迹进行排序,将候选迹放入前缀树中重演,能够重演说明选取的迹在前缀树中真实存在,将该迹作为预测结果进行下一个预测,无法重演说明当前迹在历史日志中并未发生,舍弃当前预测结果,从候选迹中选取概率次之的迹进行判断,直到找到确定符合前缀树的迹,把当前迹作为预测输入进行下一次预测直到预测结束。 4 实验与结果评估 4.1 事件日志 本文采用四个真实的事件来评估提出的方法的可行性,其中BP12W和BP13是来自于BPIC(业务流程智能竞赛)12年和13年提供的事件日志,BP12W-no-repeat是对BP12-W事件日志处理后的事件日志,该事件日志是清洗掉循环后的日志,Helpdesk是某公司的帮助台的票务管理后台记录的日志。这些事件日志已经被过滤过。这些事件日志数据集的统计数据见下表: 4.2 实验设置与评估方法 本文实验环境在Windows10系统中使用Python3.7语言,并使用Keras深度学习库。对于LSTM的参数设置,使用了和Tax论文中一样的设置。同时对数据集进行划分,其中67%的迹作为训练集用于构建LSTM模型,剩余的33%作为测试集用来做测试。预测下一个活动时,需要对所有前缀进行预测,对于不同的数据集,本文仅选取了一些前缀长度进行展示,在Helpdesk数据集中,k∈{2,4,6},BPIC12W数据集中k∈{2,4,6,8,10,15, 20,25,30,35,40},BPIC12W(no duplicates)数据集中k∈{2,4,6,8}以及BPIC13数据集中k∈{2,4, 6,8,10,15,20,25,30}。在预测后缀任务中,只需要选取一个大于2的前缀长度进行测试即可,本文选取了四个前缀长度进行测试,k∈{2,3,4,5}。 为了评估预测下一个活动标签的准确性,使用准确率来作为衡量指标,它是指正确预测占预测总数的比例。 其中TP为正确预测的个数,FP为错误预测的个数。 为了衡量后缀生成的质量,使用基于Damerau-Levenstein距离(DL distance)的相似度来比较生成的后缀和真实迹后缀之间的相似度。Damerau–Levenshtein Distance用来测量两个字符序列之间的编辑距离的字符串度量标准。两个词的Damerau–Levenshtein Distance是从一个词转换为另一个词的最少操作数,与Levenshtein Distance不同的是,除了单个字符的插入、删除和变更之外,还包括两个相邻字符的转换。对于两个序列给定序列s1,s2,它们的相似度为 其中len(s)代表序列的长度,Sim越大说明两个序列越像,Sim=1说明两个序列完全相同,反之Sim=0说明两个序列没有相似的地方,是完全不同的。 4.3 结果与讨论 下一个活动预测:表2报告了使用前缀树增强预测的方法与基线方法在四个事件日志中的加权平均准确率,与基线进行对比,使用前缀树增强预测方法提高了总体的预测准确率,在循环次数较少的事件日志中,如Helpdesk以及BPIC12W(no duplicates),增强预测方法具有更高的提升。图3展示了基线方法与使用前缀树增强预测方法在预测的不同前缀上预测下一个活动的准确率,结果表明使用前缀树增强预测获得的准确率始终在基线算法之上,最差也与基线算法准确率相同。产生此结果的原因是在前缀树的决策支持中,将会使得不符合活动间行为关系的迹无法产生,确保了预测结果满足活动间的行为关系,从而增强了预测的准确率。 活动后缀预测:表3总结了每个日志的后缀预测结果,使用前缀树增强预测方法与基线方法相比相对在各个日志上都有所提高,在循环次数较高的日志上提升明显,如BPIC12W和BPIC13,这是因为在预测后缀时循环的存在可能会导致产生的后缀结果一直处在循环之中,使得后缀长度增长同时数据不断增长,基于前缀树增强预测方法避免迹的无限增长,当不断循环的迹不再符合活动间的行为关系时,及时的结束预测,从而提高了预测后缀结果的相似度,但是并没有真正解决循环问题,未来如何以一种较好的方式在合适的位置结束循环仍然是继续研究的方向。 5 結语 本文提出一种将使用深度学习模型与前缀树结合的预测方法,在对历史事件日志学习预测模型之外,对历史事件日志进行了信息挖掘,将日志中的行为关系通过前缀树表示,在结果预测阶段通过前缀树结构筛选符合行为关系的预测结果提供决策支持,以此提高预测的精确度。在四个事件日志上的结果表明,利用表示日志中行为关系的前缀树来增强预测的精确度是有效果的,因此在现实中进行预测监控时,可以通过挖掘日志中隐藏的行为关系来提高预测精度。未来的工作有以下几个方向:(1)继续结合预测模型与挖掘出的活动关系,尝试将活动之间的行为轮廓关系,如选择关系,并发关系作为额外信息在模型之外增强预测。(2)将活动之间的行为关系作为属性在训练预测模型时使用。(3)以一种合理的方式解决后缀中的循环。 —————————— 参考文献: 〔1〕Maggi F M, Francescomarino C D, Dumas M, et al. Predictive monitoring of business processes[C]//International conference on advanced information systems engineering. Cham, Switzerland:Springer, 2014: 457-472. 〔2〕Van der Aalst W M P, Schonenberg M H, Song M. Time prediction based on process mining[J]. Information systems, 2011, 36(02): 450-475. 〔3〕Rogge-Solti A, Weske M. Prediction of business process durations using non-Markovian stochastic Petri nets[J]. Information Systems, 2015, 54: 1-14. 〔4〕Aburomman A, Lama M, Bugarín-Diz A. Estimating Remaining Time of Business Processes with structural attributes of the traces[M]//Computational Intelligence and Mathematics for Tackling Complex Problems 2. Cham, Switzerland:Springer, 2022: 47-54. 〔5〕Verenich I, Dumas M, La Rosa M, et al. Predicting process performance: A white‐box approach based on process models[J]. Journal of Software: Evolution and Process, 2019, 31(06). 〔6〕Conforti R, Leoni M, Rosa M L, et al. Supporting risk-informed decisions during business process execution[C]//International Conference on Advanced Information Systems Engineering. Berlin, Heidelberg: Springer, 2013: 116-132. 〔7〕Pika A, van der Aalst W M P, Fidge C J, et al. Predicting deadline transgressions using event logs[C]//International Conference on Business Process Management. Berlin,Heidelberg: Springer, 2012: 211-216. 〔8〕Teinemaa I, Dumas M, Maggi F M, et al. Predictive business process monitoring with structured and unstructured data[C]//International Conference on Business Process Management. Cham, Switzerland:Springer, 2016: 401-417. 〔9〕Lakshmanan G T, Shamsi D, Doganata Y N, et al. A markov prediction model for data-driven semi-structured business processes[J]. Knowledge and Information Systems, 2015, 42(01): 97-126. 〔10〕Polato M, Sperduti A, Burattin A, et al. Time and activity sequence prediction of business process instances[J]. Computing, 2018, 100(09): 1005-1031. 〔11〕Evermann J, Rehse J R, Fettke P. A deep learning approach for predicting process behaviour at runtime[C]//International Conference on Business Process Management. Cham, Switzerland:Springer , 2016: 327-338. 〔12〕Evermann J, Rehse J R, Fettke P. Predicting process behaviour using deep learning[J]. Decision Support Systems, 2017, 100: 129-140. 〔13〕Tax N, Verenich I, Rosa M L, et al. Predictive business process monitoring with LSTM neural networks[C]//International Conference on Advanced Information Systems Engineering. Cham, Switzerland:Springer, 2017: 477-492. 〔14〕Taymouri F, Rosa M L, Erfani S, et al. Predictive business process monitoring via generative adversarial nets: the case of next event prediction[C]//International Conference on Business Process Management. Cham, Switzerland:Springer , 2020: 237-256. 〔15〕Lin L, Wen L, Wang J. Mm-pred: A deep predictive model for multi-attribute event sequence[C]//Proceedings of the 2019 SIAM international conference on data mining. Philadelphia:Society for Industrial and Applied Mathematics, 2019: 118-126. 〔16〕宮子优,方贤文.基于时间卷积网络的业务流程预测监控[J].安徽理工大学学报(自然科学版),2021,41(05):64-70. 〔17〕黄晓芙,曹健,谭煜东.基于频繁活动集序列编码业务过程预测性监控[J].北京邮电大学学报,2019,42(04):1-7. 〔18〕韩力群,施彦.人工神经网络理论及应用[M].北京:机械工业出版社,2017. 〔19〕Schmidhuber J, Hochreiter S. Long short-term memory[J]. Neural Comput, 1997, 9(08): 1735-1780. 收稿日期:2022-09-27 基金项目:国家自然科学基金(61402011)
