基于Transformer的U型医学图像分割网络综述
2023-05-24傅励瑶尹梦晓
傅励瑶,尹梦晓,2,杨 锋,2*
(1.广西大学 计算机与电子信息学院,南宁 530004;2.广西多媒体通信与网络技术重点实验室(广西大学),南宁 530004)
0 引言
相较于传统的学习方法需要手动优化特征表示,神经网络可以自动学习特征表示,并利用梯度下降迭代优化模型,从而得以迅速发展。在计算机视觉领域,近年来大热的卷积神经网络(Convolutional Neural Network,CNN)在各下游任务中表现出其自动学习表示的巨大潜能。随着CNN 所含层数的增加,促进了处理各种任务的深度神经网络的提出。如今,深度学习被应用到更多领域解决各类复杂问题,比如专家系统、自然语言处理(Natural Language Processing,NLP)、语音识别和智能医疗等。首个基于全卷积网络(Fully Convolutional Network,FCN)[1]的U 型网络(U-shaped Network,U-Net)由文献[2]提出,作为经典的CNN,文献[2]中利用跳跃连接(Skip-Connection)同时保留在下采样中丢失的细节信息和在低分辨率图像中获取到的全局特征,这种融合不同尺度特征的编码器-解码器结构设计大幅提升了分割模型的性能。所以,U 型网络是目前医学图像分割任务中应用最广泛的模型之一。自U 型网络被提出之后,各种改进版的U 型网络在许多医学图像分割任务中都有着出色的表现,这足以证明U 型网络中的残差多尺度特征融合网络结构有利于处理医学图像分割任务。尽管如此,卷积与生俱来的归纳偏置特点阻碍了分割网络性能的进一步提升,而利用自注意力机制获取全局特征的Transformer[3]模型利用它捕捉长距离依赖的优势能弥补CNN 的不足。在计算机视觉领域,ViT(Vision Transformer)[4]打开了Transformer 进入该领域的大门。Transformer 应用于图像分类任务中的优秀表现展现了它在图像处理领域的发展前景。在ViT 中,主要工作是把原始图像分割成16×16 的二维图像块,然后把图像块映射为一维的二维图像块序列以模仿NLP 任务的输入。这样的变换既能避免在每个像素之间计算注意力会大幅增加计算和存储负担,又能在不改变NLP 任务中的Transformer 模型主体结构的前提下将它应用到计算机视觉领域中。ViT 提出之后,在图像分割领域,文献[5]中提出了基于纯Transformer 编码器的图像分割模型——SETR(SEgmentation TRansformer);在目标检测任务中,文献[6]中引入了一个端到端Transformer 编码器-解码器网络——DETR(DEtection TRansformer)。
医学图像难标注、目标和背景比例极不平衡和对比度低以及边界模糊等问题加大了将Transformer 应用到医学图像分割任务中的难度;同时,医学图像大多是小数据集,难以预训练出专用于医学图像处理的Transformer 模型。所以,Transformer 在医学图像分割模型中的潜能还有待进一步挖掘。虽然U 型网络在医学图像任务中被广泛应用,但是下采样过程中细节特征的损失和卷积神经不擅长捕捉长距离依赖的缺点限制了U 型网络的发展。为了进一步挖掘Transformer 和U 型网络在医学图像分割任务中的潜能,本文从两者各自的优势出发,讨论基于Transformer 的U 型网络在医学图像分割任务中的研究进展,并对相关深度学习网络结构进行全面的研究和分析,有助于读者深入了解Transformer应用于U 型网络的优点。在本文最后讨论了两者结合在未来更有潜力的发展建议。
1 医学图像分割
医学图像分割是计算机视觉领域重要的研究方向,目标是在医学图像上进行像素级别的分类,进而准确地分割目标对象。分割数据集来自专业医学设备所采集到的单模态或者多模态图像,比如核磁共振成像(Magnetic Resonance Imaging,MRI)、计算机断层扫描技术(Computed Tomography,CT)、超声(UltraSound,US)等。传统的非深度学习医学图像分割技术主要依赖于基于阈值、区域生长、边界检测等方法。虽然传统的分割方法速度快且简单,对于硬件要求不高,但是需要人工参与才能得到好的特征表示;而基于深度学习的分割网络可以自动学习特征表示,几乎不需要人工参与,但需要高性能计算机花较长时间训练网络。随着图像处理单元(Graphic Processing Unit,GPU)和内存的发展,训练大多数基于深度学习的网络已不是难题,深度学习随之被应用到各领域完成自动学习目标任务的特征表示。如今,基于CNN的分割模型广泛用于许多分割任务当中,比如肿瘤分割、皮肤病变区域分割、左右心室分割以及眼底血管分割等。训练这些模型的方法中,除了很少一部分是基于无监督[7-9]和半监督[10-14]的方法,其余则是基于全监督[15-19]的方法,其中最经典的模型便是U 型网络。医学图像分割技术的发展对计算机辅助诊断、智能医疗和临床应用等领域的研究有着极其重要的作用。但CNN 由于感受野受限,只擅长获取局部特征,而缺乏捕捉长距离依赖的能力,而且卷积核的大小和形状固定,不能有效适应输入图像类型,限制了卷积的应用范围,也降低了分割模型的泛化性;同时,医学图像也存在边界模糊、对比度低、目标大小不一以及模态多样等问题。要有效解决上述问题,获取关键的全局上下文信息是必要的。因此,来自NLP 领域的利用自注意力机制获取全局特征的Transformer 被用于优化医学图像自动分割技术。在NLP 任务中使用的Transformer 大多经过在大规模的文本数据集上预训练得到。因为自注意力部分的计算量太大,预训练模型很大程度上能防止模型过拟合。但二维医学图像数据集通常规模较小,难以用于预训练原始的Transformer 模块;三维医学图像数据集不仅规模小,而且样本体素多,将它们直接放进Transformer 训练会大幅增加模型复杂度,增加过拟合的风险,反而可能降低模型性能。而ViT[4]中将图像切成多个图像块的做法,不仅可以降低单个样本的计算量和内存消耗,还可以增加数据的多样性,降低模型过拟合的概率,使模型的训练相对容易。借鉴ViT 的设计理念,Transformer 被应用到医学图像分割网络[20-22]。
2 U型网络
医学图像分割是计算机视觉领域重要的研究方向之一,而对准确的分割结果而言,细节信息和全局信息都很重要。如何在全局信息和局部信息之间找到完美的平衡,是提升分割模型性能的重要问题之一。此外,由于大多数医学图像数据集都很小,使训练出兼顾全局和局部特征的分割模型更具有挑战性。为了解决上述问题,U 型网络利用它特殊的对称结构在高分辨率图像中获取局部特征,在低分辨率图像中捕捉全局特征,实现端到端的分割。经典U 型网络结构如图1所示。
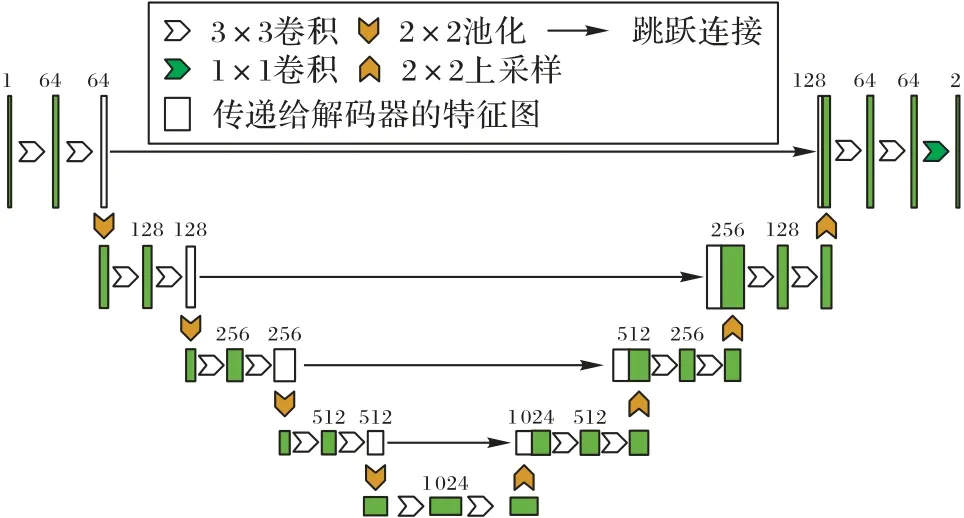
图1 经典U型网络总体结构Fig.1 Overall structure of classic U-Net
2.1 二维图像应用
U 型网络在编码器-解码器结构中,结合上下采样和跳跃连接,融合多尺度特征信息,为分割模型提供了粗细粒度特征图的同时还能加速模型收敛,对于处理医学图像分割任务极其有效。不仅如此,文献[2]提出的U 型网络结构不包含全连接层,而是使用参数量少的全卷积层代替。基于U 型网络的独特设计,U 型网络的分割精度几乎好于当时的所有优秀分割模型。U-Net++[23]为了能够减小编码器和解码器特征图之间的差异,进一步改进了U 型网络。U-Net++在跳跃连接上加上了若干卷积层,并在各卷积层之间使用密集连接(Dense Connection)[24],以减小两边网络特征表达的差异。此外,文献[23]中把编码器中产生的不同尺度的特征图通过上采样至原图大小,然后和标签计算损失,监督特征融合操作。受文献[2]的启发,ResUNet(Residual and U-Net)[25]把文献[2]所提出模型的骨干网络的卷积部分用残差网络(Residual Network,ResNet)[26]代 替,在此基础上,ResUNet++[27]在ResUNet 编码器中的每个残差块之后添加压缩提取模块(Squeeze and Extraction Block,SE Block)[28],不仅把编码器中不同尺度的特征图传递给解码器,还传递了通道注意力权重。模型利用权重信息过滤掉解码器特征图的多余信息,再将它输入到后面的网络中。实验表明,这种融合两边网络特征的方式比起一次性串联的融合方式更加有效。
2.2 三维图像应用
V-Net(Network for Volumetric medical image segmentation)[29]把三维卷积层应用到U 型分割网络中,用于分割三维医学图像。针对医学图像中常出现的前景和背景极不平衡的情况,文献[29]中提出了Dice 损失函数,进一步优化医学图像分割模型。三维U 型网络(3D U-Net)[30]将原U 型网络中的二维卷积用三维卷积替换,用于从粗标记中半自动或者全自动地进行三维医学图像分割。从以上网络可知,U 型网络变体大多侧重于修改U 型网络的网络结构,而Isensee 等[31]更加关注目标任务对U 型分割模型的影响,从而设计了自适应分割任务的网络——nnU-Net(no new U-Net)。nnU-Net 把重心放到数据的预处理和后处理,以及对模型训练超参数的设置,从而提升模型完成分割任务的效率。由于nnU-Net 在医学图像分割任务中的表现不错,所以该领域的研究者通常会考虑将nnU-NeT 的分割效果作为参考,同时,它也给非该领域使用者提供了快捷便利的分割工具。
如今,U 型网络不仅被频繁用于图像分割领域,还出现在道路提取、天气预测和图像分类等领域。各种U 型网络的变体在深度学习任务中有着不错的表现,特别是在医学图像分割领域,U 型网络更是胜过多数CNN。所以,即使自首个U 型网络被提出已过了七年之久,U 型网络处理医学图像分割的应用仍然随处可见,研究者们也依然在不断拓展U 型网络和其他高性能模块的结合应用,充分挖掘U型网络的潜力。
3 Transformer
Vaswani 等[3]首次提出Transformer,因其独特的设计赋予了Transformer 能处理不定长输入、捕捉长距离依赖和序列到序列(seq2seq)任务的特性。Transformer 主要包含解码器和编码器,每个编码器包括位置编码、多头注意力机制、层正则化(Layer Normalization,LN)[32]、前馈神经网络(Feed Forward Network,FFN)和跳跃连接,而解码器除在输入层增加了一个掩码多头注意力机制以外,其余部分与编码器相同。Transformer 结构如图2 所示。
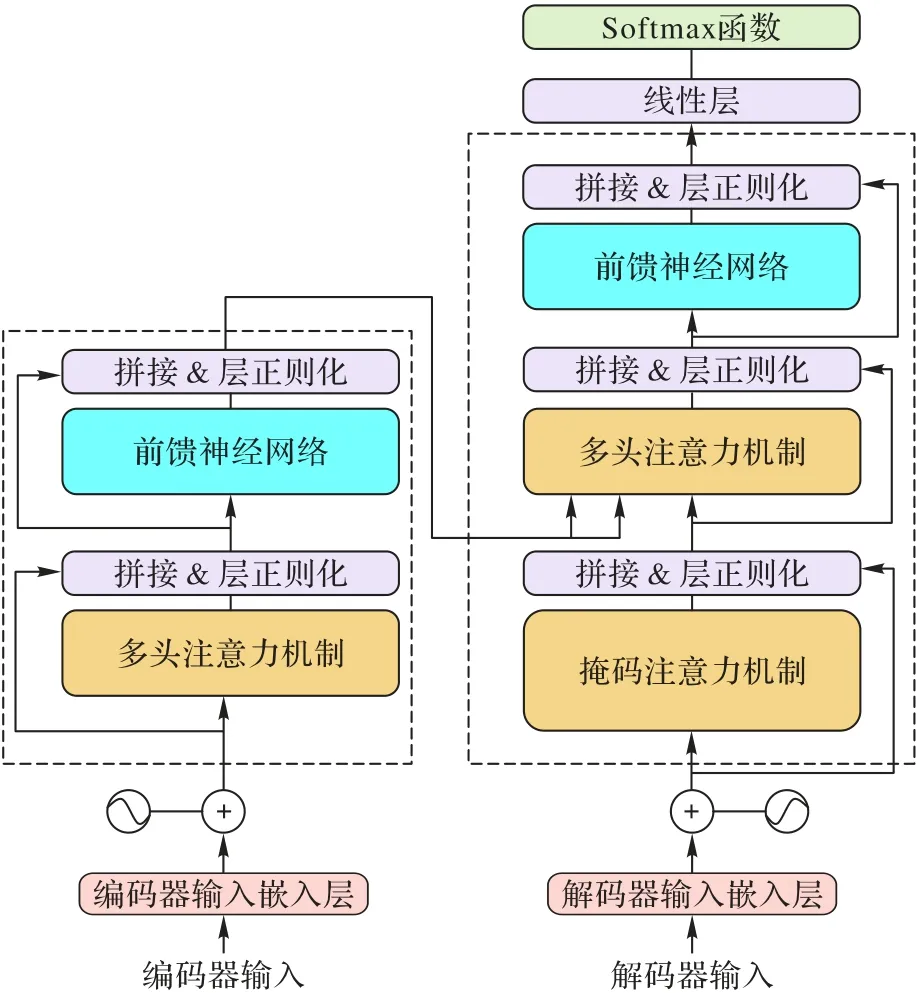
图2 Transformer总体结构Fig.2 Overall structure of Transformer
3.1 主要模块
3.1.1 注意力机制
1)自注意力机制:自注意力机制是Transformer 的关键组成部分,Transformer 能够获取长距离依赖主要归功于它。自注意力公式如下:
其中:q、k和v是输入X经线性层映射后的向量;dk是向量k的维度。
2)注意力机制:多头注意力机制中多个q、k和v向量分别组成矩阵Q、K和V,将每个组合并行计算后在通道维度进行拼接。在该注意力中,不同的头能够从不同位置的子空间中学习到不同种类的特征表示。下面是多头注意力的公式:
3)掩码多头注意力机制:为了避免解码器位置i依赖位置i后的数据,确保当前输出只依赖于i前的预测,后面的“未知”信息有必要被隐藏,即只用当前位置之前的信息推测结果。
3.1.2 位置编码
因为Transformer 不含循环神经网络(Recurrent Neural Network,RNN)和CNN,所以依赖于缺乏序列信息的注意力机制。但对于NLP 和图像处理任务,位置信息发挥着重要作用,所以,Transformer 需要自动学习位置信息。经典的Transformer 利用正弦和余弦函数学习位置信息,公式如下:
其中:pos是当前对象在当前维度的序列所处位置;dpos是位置pos所在维度;100 002dpos/dmodel表示频率。
3.1.3 层正则化
层正则化(LN)克服了批量正则化(Batch Normalization,BN)[33]难以处理变长输入的序列任务的缺点,把正则化的范围从样本外部转移到样本内部,这样的正则化就不会依赖于输入大小,非常适用于NLP 任务。详情见文献[32]。
3.1.4 前馈神经网络
前馈神经网络(FFN)由两个线性层加上ReLU 激活函数(max(0,input))组成,公式如下:
其中:X是输入图像矩阵;Wi是和X相同大小的矩阵;bi是长度等于X的通道数的一维向量。
3.2 Swin Transformer
相较于处理文字样本,用Transformer 训练处理图像或视觉的模型更具有挑战性。因为图像比文本更多样,且分辨率高。Swin Transformer(Shifted-window Transformer)[34]中提出的窗口多头自注意力(Window Multi-head Self Attention,W-MSA)模块和滑动窗口多头自注意力(Shifted Window Multi-head Self Attention,SW-MSA)模块缓解了Transformer在视觉领域中应用的困难。在W-MSA 中,图像被分成若干个由若干图像块组成的窗口,计算注意力权重只在窗口内部。在SW-MSA 中,利用滑动设计计算各窗口之间注意力分数,以此建立窗口之间的联系。相邻的W-MSA 和SW-MSA构成了Swin Transformer 模块。相邻Swin Transformer 块的计算方法如下:
其中:zi表示第i层的输出表示第i层的中间结果;LN()表示层正则化;W-MSA()表示窗口自注意力机制;SW-MSA()表示滑动窗口自注意力机制;MLP()表示多层感知机层。
Transformer 的提出对深度学习框架产生了极大的影响。因为CNN 的归纳偏好,导致CNN 获得长距离信息的成本过高,而Transformer 刚好可以弥补CNN 的不足。但Transformer获取全局信息的优势,不仅限于轮廓表示、形状描述和根据长距离依赖获取的目标类型先验,更重要的是局部和全局信息需要不同的感受野,跟CNN 相比,Transformer 中的注意力机制把握长距离相关信息则更加直接有效。可是,来自NLP领域的Transformer 并没有考虑计算机视觉任务分辨率高、目标形状和小大差异大等特点,限制了Transformer 在计算机视觉领域的应用。Swin Transformer 的出现无疑给Transformer处理图像或视频的应用开启了一扇新的大门。如今,计算机视觉领域中的Transformer 变体也不仅限于Swin Transformer,还有通过改进原始Transformer 子结构使其适用于视觉任务的其他模型,又或者是通过迁移学习和对抗学习方法引入Transformer 的模型。即使如此,已存在的基于Transformer 的模型会借助CNN 的归纳偏置更好地发挥作用。所以,探索Transformer 结合CNN 的模型有着很大的发展前景。
4 基于Transformer的U型分割网络
ViT[9]将Transformer 应用到图像分类任务中并取得成功之后,Chen 等[20]提出了TransUNet(Transformers and U-Net)。TransUNet 的提出开启了Transformer 在医学图像分割领域中的应用。由于Transformer 在大规模数据集上才能更好地发挥其优势,而大多数医学图像数据属于小规模数据集,因此,研究进一步改进Transformer 模块使其适用于医学图像处理便成了热门的研究方向之一。其中,最为有效的方法之一就是结合Transformer 与U 型网络,利用U 型网络尽可能减小计算量的同时也能有效捕捉重要信息的特点,充分挖掘Transformer 和U 型网络的潜力。接下来,本文从Transformer在U 型网络中所处的不同位置对相关研究工作进行分类讨论。
4.1 仅编码器
TransUNet 是首个将Transformer 应用到医学图像分割领域的U型网络,如图3所示。
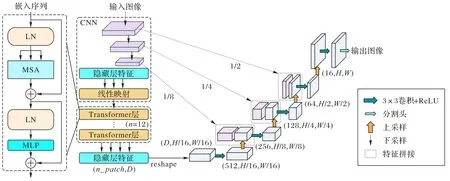
图3 TransUNet总体框架Fig.3 Overall framework of TransUNet
该模型直接将编码器中下采样之后的图像序列化,然后套用最原始的Transformer 模块进行训练,利用Transformer 在低分辨率图像中获取长距离依赖的优势和对称的编码器-解码器结构,提升了模型自动分割的性能。也因为TransUNet直接使用了NLP的Transformer模型,序列中的图像块大小固定,注意力计算量大,所以TransUNet的分割效率还有待进一步提升。文 献[22]结合文 献[35-36]提出了MedT(Medical Transformer),该网络在位置嵌入中加入门控机制,使模型在训练不同大小的数据集时能够自动调节门控参数,获得适合当前数据集的位置嵌入权重。实验结果表明基于MedT 的U型网络能适应不同大小的数据集。基于双编码器-解码器的X-Net(X-shaped Network)[37]把Transformer 作为主干分割网络的编码器,并通过跳跃连接建立基于卷积的辅助网络的编码器和解码器特征图的联系。X-Net 中的辅助网络的解码器把重建图像任务作为代理任务,在约束用于分割任务的编码器的同时,也能让编码器学习到表达能力更强的特征。相较于TransUNet 只有编码器和解码器分支的U 型对称结构,TransClaw(Claw U-Net with Transformers)[21]设计了编码器、上采样和解码器三分支的网络结构,利用跳跃连接将各部分的多尺度特征图相连。文献[21]中通过融合上采样的特征图、Transformer 在深层网络获取到的全局上下文信息以及卷积捕捉到的局部特征,使模型得到进一步优化。虽然实验结果显示模型在Dice 指标上没有明显提升,但在豪斯多夫距离(Hausdorff Distance,HD)指标上有着不错的表现。受GoogLeNet[38]和 Swin Transformer 的启发,TransConver(Transformer and Convolution parallel network)[39]用Transformer模块和卷积模块替换GoogLeNet 中的多分支结构,利用基于交叉注意力机制交互全局和局部特征(Cross-Attention Fusion with Global and Local features,CAFGL)模块替换GoogLeNet 的过滤器拼接层得到TC-Inception(Transformer Convolution Inception),再放到U 型网络的编码器中。CNN 和Swin Transformer 通过交叉注意力模块交换三维脑部图像的细节特征和全局背景信息,在提高肿瘤分割精度的同时,还降低了模型的计算负载,提升了模型训练效率。以上提到的大多数网络侧重于提升模型精度,在一定程度上忽略了模型的效率。为了同时权衡分割模型的速度和准确度,LeViT-UNet(Vision Transformer based U-Net)[15]嵌入了快速推理网络——LeViT(Vision Transformer)[40]。由于LeViT 既能提高模型推理速度又能有效地从特征图中提取全局上下文信息,将LeViT 置于U 型结构的编码器中,有利于模型从经卷积之后得到的具有空间先验的特征图中获取全局特征。LeViT-UNet 在Synapse数据集上的分割精度超过了大多数模型,特别值得注意的是,LeViT-UNet 在当时的快速分割网络中分割性能最好。为了降低模型复杂度,TransFuse(Fusing Transformer and CNNs)[41]使用在ImageNet 数据集 上预训 练之后 的DeiT(Dataefficient image Transformers)[42]减少模型参数,并且设计了并行的CNN 模块和Transformer 特征提取模块。为了充分利用两者优势,作者在并行的U 型网络中设计新的跳跃连接——BiFusion Block,该模块从Transformer 的特征图中提取通道特征,从CNN 的特征图中提取空间特征,然后有效地融合两者,以便引导后面的特征提取网络。Swin UNETR(Swin UNEt TRansformers)[43]是基于Swin Transformer 提出的一个自监督预训练分割模型。该模型在5 050 张非目标CT 图像中分别在对比学习、掩码体素块和随机数据增强三个代理任务上预训练Swin Transformer 模块。这三个代理任务能够帮助预训练模型学习到感兴趣区域(Region Of Interest,ROI)信息、邻近体素信息和结构先验知识。在目标任务中,微调之后的Swin Transformer 模块结合卷积层在三维医学图像分割任务中有着出色的表现。
4.2 仅解码器
Li 等[44]提出了基于压缩-扩展Transformer 的 解码器Segtran。其中,压缩注意力模块来自于专门处理无序集合特征的Set Transformer[45]中的ISAB(Induced Squeezed Attention Block)。ISAB 通过过渡特征图I(形为m×d的矩阵)浓缩X(形为n×d的矩阵)(n≫m)的关键信息,这样做可以大幅降低注意力模块的复杂度。对于扩展注意力模块,作者从混合高斯分布好于单一高斯分布的事实出发,提出了用多个单头Transformer 代替多头注意力机制的策略,以适应数据的多样性,获取更有区分度的样本特征。在位置编码部分,为了能够获得像素的局部性和语义的连续性,文献[44]基于原Transformer 中的正弦位置编码,提出了可学习的正弦位置编码。实验结果表明可学习的位置编码以及多个Transformer提取的特征都能给模型性能带来一定的提升。
4.3 编码器和解码器
前面所介绍的工作将Transformer 单独放在编码器或解码器中,接下来将讨论把Transformer 同时放在编码器和解码器中的分割模型。nnFormer(not another transFormer)[46]在网络中交替使用Transformer 和CNN,并提取每一尺度的特征信息进行多尺度监督学习,保证多尺度的特征表达尽可能准确;但引入多个Transformer 会大幅增加计算负载,于是文献[46]将Transformer 提前在ImageNet 中预训练之后,固定注意力模块和多层感知机(Multi-Layer Perceptron,MLP)层参数,其他部分根据目标任务进行新的学习。另外,受Swin Transformer 启发,文献[46]还用三维窗口替换原来的二维窗口,在窗口内进行自注意力计算,相较于原始的三维多头注意力机制,计算量减少了90%以上。为了避免三维窗口和三维图像不匹配而导致计算时填充冗余信息,三维窗口大小根据三维图像专门设定。不仅如此,作者提出用连续的、小的卷积层比ViT 中直接用单个的、大的卷积层学到的嵌入层有着更丰富的位置信息,还有助于降低模型复杂度。与模型nnFormer 用于处理三维医学图像一样,D-Former(Dilated transFormer)[47]借鉴空洞卷积提出了由局部处理模块(Local Scope Module,LSM)和全局处理模块(Global Scope Module,GSM)组成的空洞Transformer。其中,邻近的若干图像块组成的单元构成了LSM 的作用范围,GSM 的作用范围则是从整个特征图中选择间隔为g的图像块组成的单元。LSM 和GSM 模块的联合能够提取出区分度很强的局部和全局上下文联系。该模块在Synapse 数据集上的分割Dice 值高达88.93%,超过了许多高表现的分割模型。
Huang 等[16]设计了 高效的 分割模 型MISSFormer(Medical Image Segmentation tranSFormer)。在注意力模块,K和V被调整为(N/S,C×S),以减小序列长度,再用于计算注意力,然后用线性层将结果的通道恢复到C:
其 中:W(a,b) 代表输 出形式 为(a,b) 的二维 权重矩 阵;Reshape()代表重塑矩阵的函数;N=h×w(h和w分别输入图像长和宽);S是压缩率。这样自注意力模块的计算复杂度从O(N2)降低到O(N2/S),即使处理高分辨率的图像也容易了许多。作者还用卷积层、跳跃连接和层正则化的组合替换感知机层,进而再减少计算量。值得一提的是,作者所用的跳跃连接是一个全新的设计,作者称为增强上下文联系的Transformer 过渡连接(Enhanced Transformer Context Bridge)。该模块将编码器得到的多尺度特征图整合之后拉成一个大的序列放入Transformer 模块。文献[16]中提出的跳跃连接不仅能从低分辨图像中习得全局特征和从高分辨率图像中获得有辨别性的局部信息,还能有效获取两种表示之间的联系。实验表明MISSFormer[16]在多器官分割数据集上的表现好于Swin UNet[48]。针对自注意力机制只关注单个样本内部的联系,而忽略了样本之间的联系的问题,MT Net(Mixed Transformer U-Net)[49]将外部注意力(External Attention)[50]机制应用到改进后的Transformer 模块,并称为混合Transformer模块(Mixed Transformer Module,MTM)。该模块由三种不同的注意力模块连接而成,分别是局部、全局和外部注意机制。局部和全局注意力模块用于提取样本内的特征表达,外部注意力机制则用于建立样本之间的联系。整个U 型网络中包含4 个MTM 和4 个卷积块。实验结果表明建立样本之间的联系有助于提升模型分割精度。
类似于MTM 中的局部和全局注意力的设计理念,PCATUNet(Patches Convolution Attention based Transformer U-Net)[51]提出了图像块间的卷积自注意力(Cross Patches Convolutional self-Attention,CPCA)块和图像块内的卷积自注意力(Inner Patches Convolution self-Attention,IPCA)块分别用于提取图像块之间和内部像素之间的全局特征。但是与传统的Transformer 不同,PCAT 中的注意力机制基于CNN 构成。为了减小编码器和解码器特征表示之间的区别,PCAT通过特征分组注意力模块(Feature Grouping Attention Module,FGAM)中的平均池化层进行下采样,并将每次得到的特征图在通道维度均分成n份再放到m个卷积层中,以在不同的通道组合中提取详细且多样的特征。
Luo 等[52]提出了由U 型网络和Swin Transformer 共同作为主干网络的半监督模型。该模型通过CNN 和Transformer之间的相互学习(CNN 的伪标签监督Transformer 预测结果,Transformer 伪标签监督卷积神经网络预测结果)得到高质量伪标签。这种方法类似于“老师学生”网络,但与之不同的是,模型中的两个网络处于平等的地位,且骨干结构类型不同,这样的组合能够使模型学习到更丰富的特征表达。Swin Unet 是基于纯Transformer 的U 型分割网络,它完全抛弃了CNN,整个模型由Swin Transformer 和线性层组成,如图4所示。
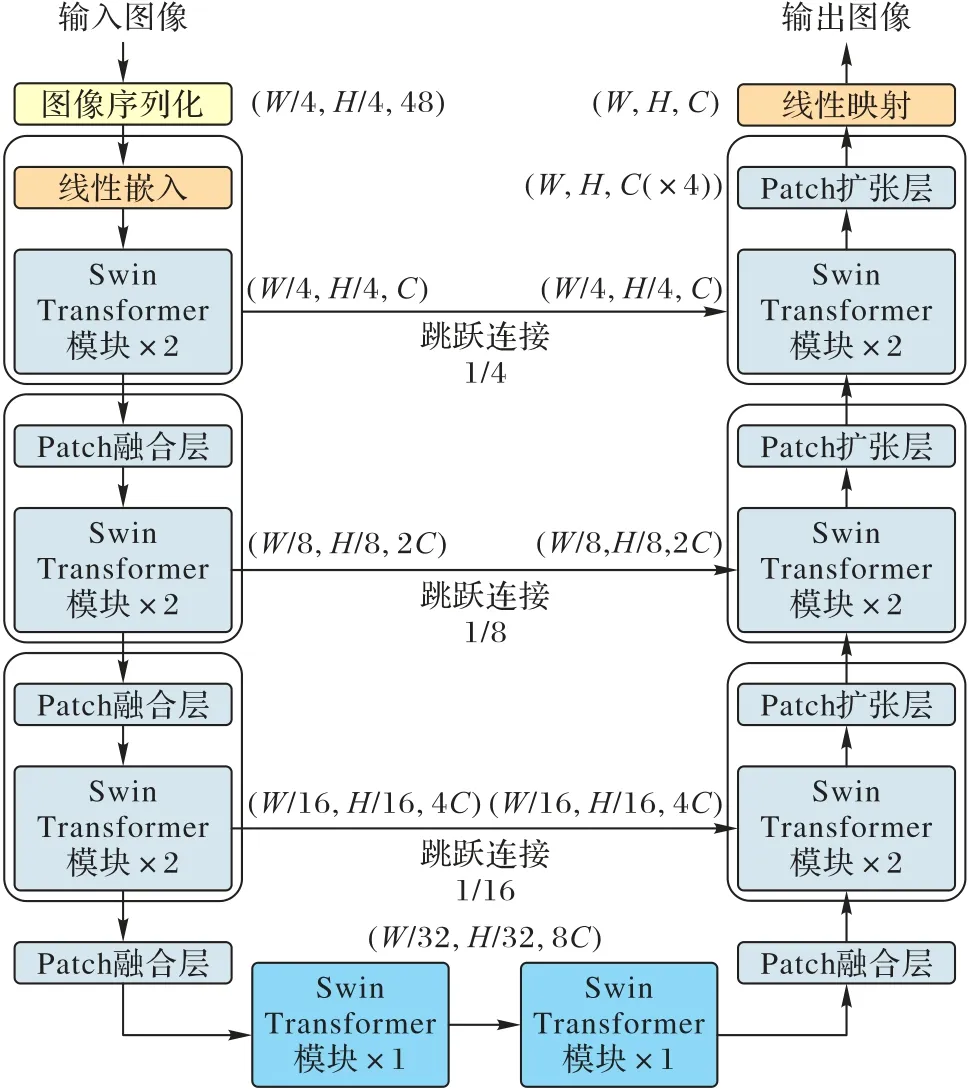
图4 Swin UNet总体框架Fig.4 Overall framework of Swin UNet
文献[52]用图像切片融合实现下采样,用图像切片扩展块实现上采样。实现结果显示,纯Transformer 模型分割结果好于文献中提到的FCN 或者Transformer 和卷积混合的神经网络。另一个基于Swin Transformer 的U 型网络是DSTransUNet(Dual Swin Transformer U-Net)[53],它在编码器中采用了双Swin Transformer 分支,为得到更多样的多尺度特征,每条分支的图像切片大小不同。又为了进一步丰富多尺度特征,基于Transformer 的交互融合模块(Transformer Interactive Fusion module,TIF)被用来融合两条分支产生的不同大小的特征图,同时充当跳跃连接的角色去连通编码器和解码器。以上模型展现了Swin Transformer 应用于医学图像数据集的潜能。比起在NLP 中需要大量数据预训练的Transformer 来说,Swin Transformer 更轻量,更适合医学图像分割任务。
4.4 过渡连接
为了处理各向异性的三维医学图像,Guo 等[54]利用单头Transformer 计算相邻切片之间的相似性,建立切片之间的信息编码,提出了新的分割模型。该模型只在切片内部进行卷积操作,在z轴不使用卷积,选择二维U 型网络作为主要结构,在降低计算复杂度的同时,也提升了分割精度。但利用简单的注意力机制去建立切片之间的联系,缺乏细节特征之间的联系。类似于文献[54],UCATR(TransUNet and Multihead Cross-Attention)[55]和 TransBTSv1(multimodal Brain Tumor Segmentation using Transformer)[56]在U 型网络底部直接套用ViT 的Transformer 模块从低分辨率图像中提取全局上下文。为了解决特征融合不足的问题,UCATR 在跳跃连接上插入了交叉注意力机制,其中Q和K来自解码器提取的特征表示,V来自编码器中的CNN。Q和K得到的注意力权重能够过滤掉后者的图像噪声和不相关信息,还能够将模型注意力集中到关键体素。而TransBTSv1 在三维CNN 中仅仅使用一次串联跳跃连接实现多尺度融合,如图5 所示。在底部使用了L层Transformer 建立三维多模态脑部医学图像体素之间的关系。虽然两者都使用Transformer 学习全局相关性,加上CNN 善于提取局部空间特征,比起纯CNN 模型分割精度确实有所提升,但是,由于两者使用的Transformer 和ViT相同,图像切块固定,注意力矩阵的计算量大,所以从头训练处理三维图像或者长序列任务仍然很吃力。为了减小三维医学图像在注意力模块中的计算和空间复杂度,MS(MultiScale)-TransUNet++[57]同样利用deep-wise 卷积层减小K和V的特征空间,减小计算注意力分数的成本,作者称其为高效Transformer,并在模型底部叠加了多个该模块。除此之外,在多尺度特征融合模块,引入网连接和密集连接加强编码器和解码器之间特征的联系,更好地恢复在下采样中损失的细节表示。与大多数医学图像分割模型使用Dice 加多分类交叉损失或二值交叉损失作为网络损失函数不同,MSTransUNet++使 用Focal[58]、MS-SSIM(MultiScale Structural SIMilarity)[59]和Jaccard[60]构成全局损失,监督分割结果。实验结果表明MS-TransUNet++的损失函数组合有助于提升该模型的分割精度。与MS-TransUNet++减小注意力模块特征空间的方法不同,TransBTSv2[61]把Transformer 从更深改到更宽,即扩大K和V特征空间,用更大的注意力范围代替堆叠多个Transformer 模块:
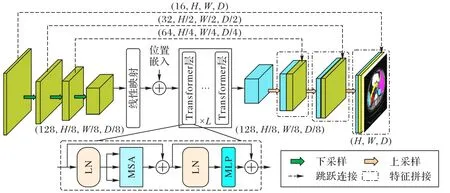
图5 TransBTSv1总体框架Fig.5 Overall framework of TransBTSv1
其中:dm=Edinput,E是膨胀率,dm是膨胀之后的维度;WQ、WK和WV分别是 形式为(dinput,dm)、(dinput,dm)和(dinput,dinput)的 矩阵,dinput是输入维度;Xinput是形式为(N,dinput)的矩阵;Q、K和V分别是形式为(N,dm)、(N,dm)和(N,dinput)的矩阵;Softmax()是激活函数。为了获取形状先验知识和清晰的边界特征,各尺度的跳跃连接中嵌入由三维CNN 构成的DBM(Deformable Bottle Module)。为了减小DBM 的计算复杂度,分别在该模块的前面和后面都加上了1×1×1 卷积分别用于压缩通道和恢复通道数。
文献[62]在跳跃连接中添加了门控注意力机制[63],用来过滤掉编码器中各层输出的冗余信息。为进一步优化分割网络,该模型不是改变损失函数组成成分,而是同时监督中间特征和最后结果,保证模型各部分之间的特征一致性。MBT-Net(Multi-Branch hybrid Transformer Network)[64]为了分割边界密集的角膜内皮细胞分割数据集,在细胞边界、细胞体和整个细胞分别设置了损失函数,以提升模型处理边界模糊以及密集分割的能力。其中,细胞边界标签通过坎尼算子(Canny Operator)从整个分割标签中提取而来,细胞体标签则先将分割标签翻转(0→1,1→0),再在边界上进行高斯模糊(Gaussian Blurring)操作。通过使用对位置敏感的轴注意力机制把握全局信息和监督细胞各部分的分割结果,模型的性能得到进一步提升。采用与轴注意力方法类似的AFTer-UNet(Axial Fusion Transformer UNet)[65]将轴注意力转移到z轴,即只在同一位置(i,j)(i=1,2,…,h,j=1,2,…,w)沿z轴计算像素之间的相似度,而不是在整个三维体素上计算。这样使三维注意力模块复杂度从O(hw×Ns)(h和w分别是输入的长和宽,Ns是邻近切片数)降低到O(hw+Ns)。虽然这样能够大幅减轻模型训练负载,但切片之间处于不同坐标的体素联系被忽略,在一定程度上会影响分割结果。CoTr(Convolutional neural network and a Transformer)[66]将 编码器中的多尺度特征图拉成一个大的图像序列,丢进基于三维可变形Transformer 的桥模块,然后传递给解码器。归功于可变形注意力机制[67]能够通过学习从整个K集合中挑选出关键键值形成目标K集合,然后用目标K集合和当前Q计算注意力权重,既能减少计算量也能避免噪声的干扰。同样用可变形Transformer 提升模型效率的MCTrans(Multi-Compound Transformer)[68]在过渡 模块上 嵌入了TSA(Transformer Self Attention)和 TCA(Transformer Cross Attention),用可变形注意力机制促进TSA 获取CNN 输出特征图;而对于整个TCA 模块,添加的可学习的辅助嵌入矩阵作为Q,将来自TSA 的特征表示映射为K和V。在TCA 模块最后,通过线性映射得到暂时的多分类结果,并用标签计算该辅助损失,引导TSA 学习不同类之间特征表示的区别和同类之间特征表达的联系,保证类内一致性和类间的区分度。上述分割模型绝大部分使用一次性跳跃连接,而在TransAttUnet(multi-level Attention guided U-Net with Transformer)[69]中,作者设计了三种不同的多级跳跃连接,并结合基于CNN 的全局空间注意力模块和基于多头注意力机制的Transformer 模块,筛选出关键特征传递给解码器,增强了模型的泛化性。实验中,模型在5 个分割数据集上都能产生优秀的分割结果。
4.5 其他位置
4.5.1 跳跃连接
Ma 等[70]把Transformer 放到U 型网络的跳跃连接上学习不同尺度的全局像素交互,提出了HTNet(Hierarchical context-attention Transformer Network)。每个跳跃连接有RAPP(Residual Atrous spatial Pyramid Pooling)、PAA(Positionsensitive Axial Attention)和 HCA(Hierarchical Context-Attention)三个模块。RAPP 是ASPP[71]和残差连接的组合,能够从不同大小的卷积核和高分辨率的原图像中捕捉到丰富的多尺度特征和细节特征;PAA 则是基于对位置敏感的轴注意力机制,该注意力机制在减少计算注意力矩阵的计算量的同时,也能获取全局上下文;HCA 通过模仿Transformer 结构计算特征之间的关联性。与常见的注意力机制最大的不同在于,HCA 中的Q、K和V来自U 型网络中不同尺度的特征图。由于特征图之间的大小不同,所以利用上下采样操作完成图像块之间相似性的计算,实现多尺度特征之间的联系。
4.5.2 输出块
RTNet(Relation Transformer Network)[72]用于分割糖尿病视网膜病变多病灶,该模型主要由基于卷积的全局Transformer 模块(Global Transformer Block,GTB)和关系Transformer 模块(Relation Transformer Block,RTB)组 成。GTB 利用血管分支分割出血管域,利用病变分支并行分割病变域,然后将各自得到的特征图传给关系Transformer。RTB中的自注意力模块所用的Q、K和V全部来自病变分支输出,目的是提取各病变域之间的联系;交叉注意力模块则用于获取病变域和血管域特征的异同,其中的Q来自病变分支,K和V来自血管分支。该模型的分割结果好于基准网络,但模型中的多个注意力模块增加了较多计算量和空间占用量。
4.6 讨论
从上述工作可以看出,选择将Transformer 置于编码器的分割模型明显多于将Transformer 置于解码器的分割模型。这一现象很大原因是处于解码器的模块的主要任务是融合来自编码器的特征,而编码器的主要任务是提取特征。只将Transformer 置于解码器不能充分发挥其从低表达能力的特征图中捕捉上下文联系的优势,从而降低其优化模型的能力。为了更好地将全局和局部信息有效融合,利用位于编码器中的Transformer 提取信息,利用位于解码器中的Transformer 融合信息,再结合卷积网络获取细节特征的优势,进一步增强模型对特征的表达能力。但是两边都插入Transformer 的模型会因注意力机制的计算复杂度而变得低效,所以探索高效的注意力模块有助于提升该类模型的效率。为了使Transformer 提取和融合全局特征的能力保持较好的平衡,将Transformer 放在过渡连接处是个不错的选择,既能从具有较低表达能力的特征中获取联系又能依靠全局特征引导后面的融合器。更值得一提的是,在过渡连接处特征图的分辨率是U 型网络所有特征图中最低的,即使使用多层叠加的Transformer 模块,也不会给模型带来很大的负载。但相较于将Transformer 置于编码器或解码器的方式,将Transformer 置于过渡连接处的方式在特征提取和融合方面的能力有限,需要花费更大的成本去权衡过渡连接处提取和融合的能力。
将Transformer 放到跳跃连接的位置是个不错的尝试工作。Transformer 在处理多模态信息的融合比CNN 更具有优势。在跳跃连接两边的特征虽然属于同一尺度,但由于所在网络的深度不同,会导致同尺度的特征图存在较大的差异。借助于Transformer,可以更好地拉近两者距离,降低因特征差异太大对后续融合部分的影响。但在U 型网络中处理高分辨率特征图时,Transformer 不一定能够提升模型效率。
总的来说,Transformer 处于不同位置有着不同的优缺点,读者应该从具体任务出发,选择合适的位置。比如,若任务更侧重于数据提取,可以考虑把Transformer 嵌入编码器中;当任务更侧重于数据融合,可以考虑把Transformer 插入编码器中。
4.7 分割数据集
上述分割模型所用数据集包括BCV(multi-atlas labeling Beyond the Cranial Vault)[73]、ACDC(Automated Cardiac Diagnosis Challenge)[74]、Brain US[75]、GLAS(GLAnd Segmentation in colon histology images)[76]、DSB18(2018 Data Science Bowl)[77]、TNBC(Triple Negative Breast Cancer)[78]、BraTS(Brain Tumor Segmentation)[79-80]、Kvasir[81]、ISIC(International Skin Imaging Collaboration)2017[82]、DRIVE(Digital Retinal Images for Vessel Extraction)[83]、STARE(STructured Analysis of the REtina)[84]、CHASE_DB1[85]、ISIC2018[86]、The Segmentation Decathlon[87]、PROMISE12[88]、LiTS(Liver Tumor Segmentation benchmark)[89]、Alizarine[90]、Thorax-85[91]、PanNuke(open Pan-cancer histology dataset for Nuclei instance segmentation and classification)[92]、KiTS19(Kidney and Kidney Tumor Segmentation)[93]、IDRiD(Indian Diabetic Retinopathy image Dataset)[94]、DDR(Dataset for Diabetic Retinopathy)[95]等,还有作者自己收集的数据集,如ABVS(Automated Breast Volume Scanner),详情见表1。
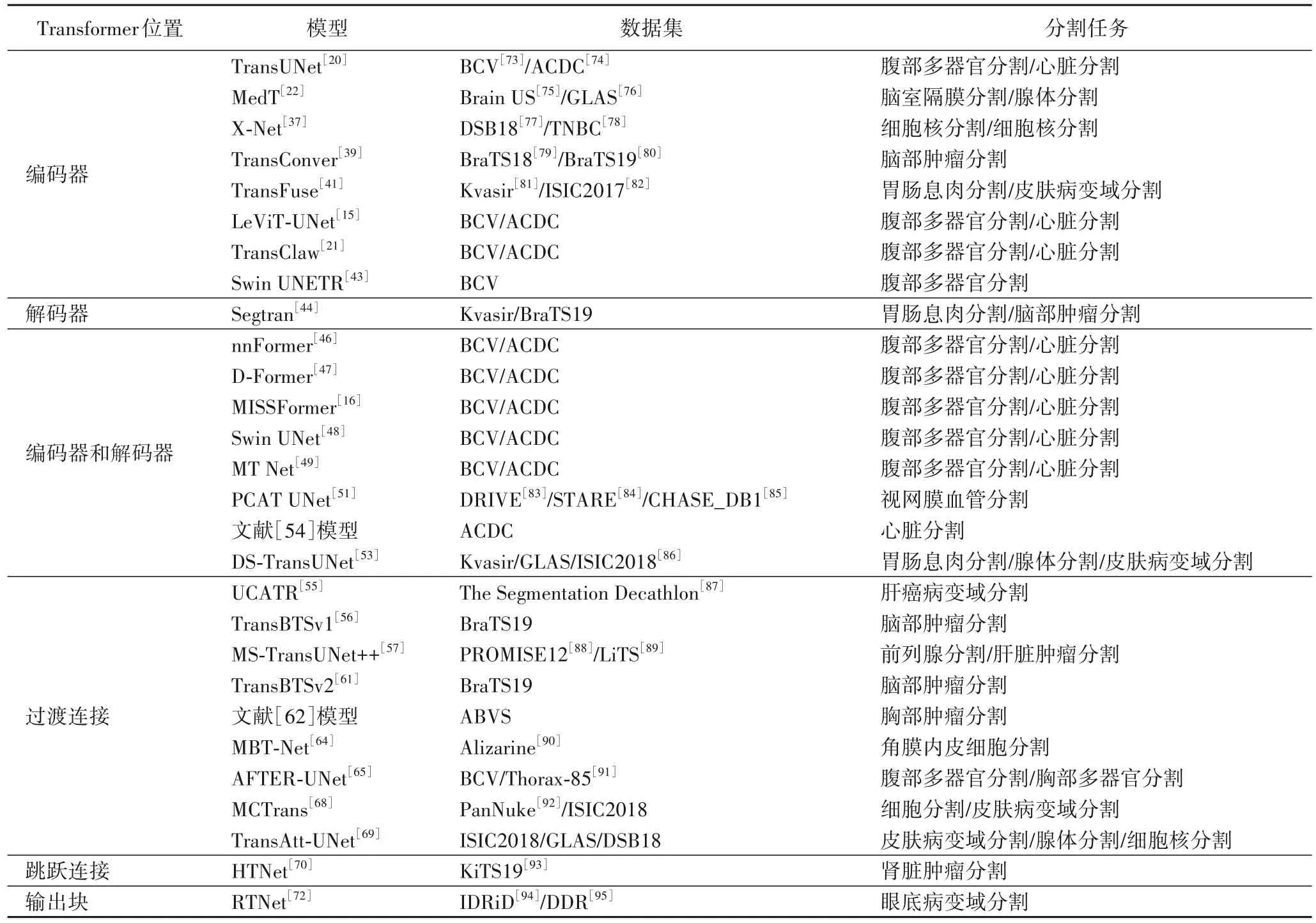
表1 基于Transformer的医学图像分割模型概览Tab.1 Overview of Transformer-based medical image segmentation models
5 挑战与展望
5.1 挑战
目前Transformer 已成为深度学习各领域研究的热点之一,尤其是在自然语言处理和计算机视觉领域,在各下游任务中都可见其身影。在医学图像分割任务中,U 型网络和Transformer 的混合模型展现出较好的分割效果。但即使如此,利用Transformer 处理医学图像仍然面临巨大挑战:
1)医学图像数据集偏小:标注医学图像需要具有专业适合和丰富经验的医生,且医学图像的分辨率普遍很高,以至于医学图像的标注费时费力,成本很高,所以较少有大的医学图像数据集。充分发挥Transformer 捕捉长距离依赖的优势需要一定的样本量,而大多数医学图像数据集都不能满足该需求。
2)医学图像分辨率高:Transformer 原用于处理自然语言中的序列任务,若用于处理图像任务需要将图像序列化。但医学图像分辨率高,像素点多,序列化之后会形成过长的序列。虽然ViT 提出了图像块序列,但切割高分辨率的医学图像之后的序列仍然会导致计算量较大。
3)Transformer 缺乏位置信息:在医学图像分割任务中,目标位置信息对于分割结果非常重要。由于Transformer 不含位置信息,只能通过学习嵌入位置信息。但对于不同的数据集位置信息不同,对位置信息的要求也不同,那么学习位置的方式也不同,严重影响了模型的泛化性。
4)自注意力机制只在图像块之间进行:为减少Transformer 处理图像的计算量,图像被序列化之后,注意力权重的计算只在图像块之间进行,而忽略了图像块内部像素之间的联系。当分割、识别或检测小目标以及边界模糊的任务时,像素之间的关键信息会影响模型精度。
5.2 展望
结合目前Transformer 和U 型网络的混合网络发展现状和所面临的挑战,对未来研究提出了以下几点建议和展望:
1)半监督或无监督学习:利用Transformer 能够从大数据集上提取出全局关键特征的优势,用它在大数据集上用辅助任务进行训练或学习已有标记图像特征进而自动生成高置信度的伪标签。两者可以缓解医学图像数据集规模普遍偏小的问题。
2)加入先验知识:先验知识能够帮助模型关注目标任务的关键特征,降低模型拟合冗余信息的概率。通常医学图像中的先验知识包括形状先验和位置先验等。
3)多模态图像融合:不同模态的医学图像提供不同的图像信息,融合多模态的图像特征能够帮助模型学习有利于分割的表示。比如T1 用于观察解剖结构,T2 用于确定病灶部位。
4)提出高效的采样操作:在U 型网络下采样和上采样操作不可避免地会导致细节特征的缺失和冗余数据的产生。提出高效采样方法既能降低模型复杂度,也能保留重要特征信息。
6 结语
Transformer 是近两年深度学习领域研究的热门框架之一。得益于其获取全局上下文的优势,在医学图像分割任务中能够缓解目标区域分散、形状差异大等问题。但对于规模不大的医学图像数据集,Transformer 难以充分发挥其优势。所以,借助于U 型网络结构能够充分利用样本信息提取多尺度局部空间特征,使模型的全局信息和局部信息达到较好的平衡,提高模型性能。本文从U 型网络中Transformer 所处位置的角度,归纳了结合两者的医学图像分割网络。从文中分割网络的表现可以看出,混合使用U 型网络和Transformer 模块有不错的发展前景和很大的研究意义。
