基于重构误差的无监督人脸伪造视频检测
2023-05-24王志宏单存宇孙亚茹
许 喆,王志宏,单存宇,孙亚茹,杨 莹
(公安部第三研究所 网络空间安全技术研发基地,上海 200031)
0 引言
随着深度生成技术的快速发展,机器自动内容生成水平不断提高,其中人脸伪造更是内容生成中的热门技术,在短视频、游戏直播、视频会议等领域得到了广泛应用。但具备极高欺骗性的深度伪造引发了诸多争议,如色情视频换脸、人体图像合成等,带来了潜在的社会信任和社会安全问题。因此如何自动高效地检测伪造视频成为迫切需要解决的问题,吸引了国内外研究人员的广泛关注。
目前人脸伪造视频检测主要被建模成有监督的分类任务,包括基于单帧的分类检测和基于多帧的分类检测。前者主要利用异常颜色、眼睛牙齿细节等特征在单帧内实现伪造视频检测[1-6];后者则对视频中的眨眼频率、表情变化等时序信息进行建模[7-13]。基于多帧的方法相较于单帧,性能都有不同程度的提高,证明了时序信息的引入对提升检测精度的重要性。然而当前工作仍存在两个主要问题:一是由于深度伪造方法不断地迭代更新、种类繁多,而现有的监督检测算法训练依赖的标注数据需要相应的伪造模型生成,这些伪造模型大多没有开源,复现难度大,训练成本高,极大地增加了检测模型的训练和更新成本;二是基于深度卷积网络提取特征的方法虽然性能良好但训练成本高,进一步提高了伪造检测模型的应用门槛。因此,需要一个平衡性能和成本的伪造检测方法。
为解决上述问题,在文献[10]研究的基础上,本文将伪造视频中不自然的表情和面部动态行为视为异常,引入时序异常检测任务中相关研究成果,设计了一种基于人脸特征点的无监督视频人脸伪造检测模型。主要思路是采用无监督方法重构正常视频的人脸特征点,然后通过比较重构误差的异常,判断视频的真伪。相较于目前有监督的检测模型,一方面,本文方法只需要正常视频作为训练数据,不需要任何伪造方法生成的带标注的伪造视频;另一方面,本文未使用深度卷积神经网络(Convolutional Neural Network,CNN)提取特征,仅采用主要人脸特征点,可以很好地保留视频人脸行为模式信息,同时减少训练时间,提高训练效率。
本文的主要工作包括:
1)将时序数据异常检测方法引入人脸伪造视频检测中,将人脸伪造视频检测任务转为无监督的异常检测任务。
2)提出一个全新的无监督的人脸伪造视频检测框架。本文方法无需任何标注数据,首先基于偏移特征、局部特征、时序特征等多粒度信息重构待检测视频中人脸特征点序列;然后通过计算原始序列与重构序列的重构误差对伪造视频进行自动检测。
3)在人脸伪造视频标准数据集上进行了大量的对比实验,结果表明本文方法可以有效检测多种类型的伪造视频,同时具有训练时间短、实现简单的特点,大幅减少了训练和使用成本。
1 相关工作
1.1 人脸伪造检测
目前人脸伪造视频检测主要被建模成有监督的分类任务,大多数工作都集中在基于单帧的伪造检测方法上。一部分工作通过人工选择关键特征后作进一步检测,如Matern等[1]通过颜色异常、脸部阴影和眼睛牙齿缺失的细节来判断真伪。更多的工作使用CNN 自动抽取特征,如:Afchar 等[2]认为微观的信息容易受到噪声的干扰,而宏观的信息不能很好地捕捉伪造细节,因此提出了基于介观的方法;Qian 等[3]提出的F3-Net(Frequency in Face Forgery Network)在CNN 提取的特征基础上进一步提取频域特征;Li 等[4]通过检测替换人脸时的融合边界存在的噪声和错误来判断真伪,达到了良好的性能;汤桂花等[5]针对现有检测方法在有角度及遮挡情况下存在的真实人脸误判问题,通过提高面部关键点定位准确度改善了由于定位误差引起的面部不协调,进而降低了真实人脸误判率;翁泽佳等[6]则引入领域对抗分支,所提模型能够抽取鲁棒性更强、泛化能力更高的特征。尽管目前基于单帧方法的效果良好,但是它们并没有充分利用视频的时序信息,所以最近越来越多的工作关注基于多帧的方法。其中一部分是基于人类自身的生理特征,如:李旭嵘等[7]通过基于EfficientNet 的双流网络检测模型在良好的准确率基础上提高了对抗压缩的能力;Li 等[8]通过检测眨眼频率的异常作判断;Yang 等[9]基于人脸特征点的中心区域和整体朝向不一致作区 分;Sun 等[10]提出的LRNet(Landmark Recurrent Network)则通过门控循环网络捕捉人脸特征点序列中不自然的表情和面部异常变化。相较于人工选择的特征,利用CNN 提取特征的应用更广泛,如Güera 等[11]和Sabir 等[12]都利用CNN 提取单帧特征,再用长短期记忆(Long Short-Term Memory,LSTM)网络提取时序特征;Gu 等[13]设计了两个非常复杂的模块分别捕捉空间不一致性和时序不一致性,达到了目前最优的性能。但是上述基于深度卷积网络特征的方法往往结构复杂、训练时间长。此外,现有的监督检测算法训练依赖的标注数据需要相应的深度伪造方法生成,由于伪造方法不断地迭代更新、种类繁多,而且大多没有开源,复现训练难度大、成本高,这极大地提高了检测模型的应用门槛。
1.2 时序异常检测
时序异常检测是从正常的时间序列中识别异常的事件或行为的任务。由于该任务获取标记数据成本高昂,因此文献[14-15]的有监督方法应用有限,所以目前大多数研究集中在无监督方法上。文献[16-17]中利用LSTM 网络构建时序特征来预测异常。Zong 等[18]提出自动编码器和高斯混合模型相结合的方法,通过自动编码器计算序列关键信息的编码表示,再用高斯混合模型对编码表示进行密度估计。文献[19-21]则结合LSTM 网络和变分自动编码器,通过重构误差预测异常。基于序列重构误差的方法是目前主要的方法之一,可以很好地检测出序列中的异常,达到良好的精度。
本文根据文献[10]的假设,伪造视频中存在不自然的表情和面部器官移动,这些描述面部动态行为的几何特征可以被人脸特征点序列很好地表达出来。本文将这些不自然的地方视为该序列的异常,借鉴时序异常检测任务的无监督研究成果,设计基于人脸特征点的无监督视频伪造检测模型。
2 无监督人脸伪造视频检测模型
本文模型由三个部分组成:数据预处理、人脸特征点序列重构和伪造得分计算。具体地说,对于待检测视频,先通过数据预处理抽取人脸特征点序列;然后利用卷积网络和循环网络编码多层次时序信息的变分自动编码器CNN-GRUVAE(CNN-Gated Recurrent Unit-Variational Auto-Encoder)重构特征点序列;最后计算重构序列和原序列的误差获得伪造分数,最终实现伪造视频的自动检测。
2.1 数据预处理
数据预处理的目的是抽取出待检测视频中人脸的特征点序列,包括人脸特征点抽取和特征点序列校准。
首先对待检测视频中的每一帧进行人脸检测,并裁剪出人脸图像,抽取出68 个人脸特征点[22],再将这些人脸特征点通过仿射变换对齐到预先设定的位置。
接着,需要对抽取出的人脸特征点序列进行校准。由于这些特征点是逐帧抽取的,即使在人脸几乎不移动的情况下,特征点也会有明显的抖动。因此参考文献[10]的工作,在校准过程中先通过Lucas-Kanade 光流算法[23]预测连续帧的下一帧,再利用卡尔曼滤波器[24]合并原帧和预测帧去除噪声,最终获得精度更高的人脸特征点序列。
2.2 人脸特征点序列重构
本文人脸特征点序列重构主要采用变分自动编码器实现,包括编码模块和解码模块,整体框架如图1 所示。其中编码模块主要编码视频中多层次的人脸特征点的时序信息,得到深层编码表示。针对原始人脸特征点序列,首先通过捕捉帧与帧之间的变化获得“邻近帧”的偏移特征;然后基于CNN 抽取连续数帧信息,获得“分块帧”的局部特征;最后采用双向门控循环神经单元(Bi-directional Gate Recurrent Unit,BiGRU)提取视频“连续帧”的序列特征。而解码模块通过深层编码表示,采用BiGRU 和全连接网络还原出人脸特征点的重构序列。
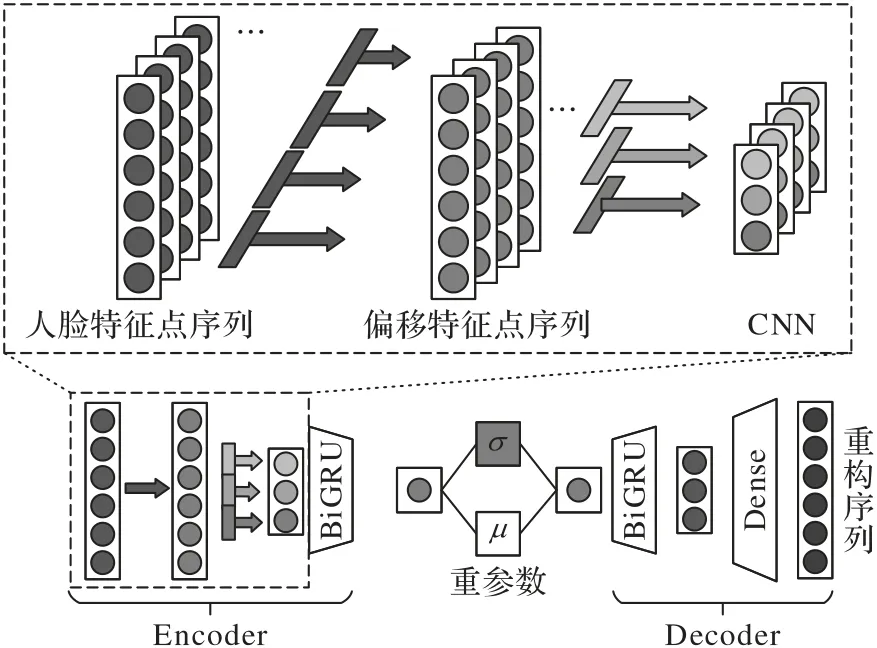
图1 人脸特征点序列重构的整体框架Fig.1 Overall framework of facial landmark sequence reconstruction
本文提出的人脸特征点序列重构方法具体描述如下:
文本分类相关工作[25]说明CNN 可以有效提取序列的局部特征,因此,本文在前述偏移特征的基础上,使用CNN 提取数帧之间的“分块帧”的局部特征。对于偏移特征序列fseq=[f1,f2,…,fN],首先将相邻特征连接为特征矩阵,即
其中:d表示卷积核大小;⊕表示连接操作。
为了获得不同角度的特征,需要随机初始化通道个数的滤波器wj(j∈[1,m],wj∈Rd×136),其中m为通道个数。所以偏移特征fi对应的第j个通道的局部特征为:
其中:*指的是卷积;h、b分别指激活函数和偏置。综上,局部特征序列为:
其中:ci表示m个通道组成的向量,表示第i帧对应的分块帧特征。
进一步地,考虑到视频中人脸表情变化的连续性和关联性,本文在视频伪造检测过程中采用BiGRU 建模人脸特征点序列的“连续帧”的序列特征。具体地,将局部特征ci通过BiGRU 后得到每帧对应的隐层表示:
将正、逆序隐层表示拼接,得到深层编码表示zi=其序列为zseq=[z1,z2,…,zN]。
此外,由于采样训练过程中不能传递梯度,所以本文采用重参数方式。即对于深层编码表示zi(i∈[1,N]),通过两个独立的全连接层分别得到期望和方差:μi=FCμ(zi)、σi=FCσ(zi)。重参数后的编码表示为=μi+ξiσi,ξi服从正态分布N(0,I)(I为单位矩阵)。
在解码过程中,同样需要考虑前后编码的时序信息,本文采用一个BiGRU 和一个全连接网络依次解码。
最终得到重构特征序列为f'seq=[f'1,f'2,…,f'N]。计算每一帧人脸特征点序列和重构特征序列的重构误差,即第i帧的重构误差为:
其中:ω是KL 散度的系数。
2.3 伪造分数计算
图2 为随机选取的一个正常视频(实线)和相应伪造视频(虚线),选择其中4 个有代表性的特征维度,绘制成的重构误差序列对比折线图。如同多变量时序异常检测任务一样,重构误差较大的地方说明在该点模型不能很好地还原,在图2 中表现为一个个波峰。其中图2(a)、(b)是区分明显的样例,可以看出虚线部分的波峰更多,也更频繁;而实线基本没有起伏,十分平缓。这是由于在训练阶段,模型只编码重构正常的特征序列,对于伪造特征序列则不能很好地还原,会产生更明显的波峰。
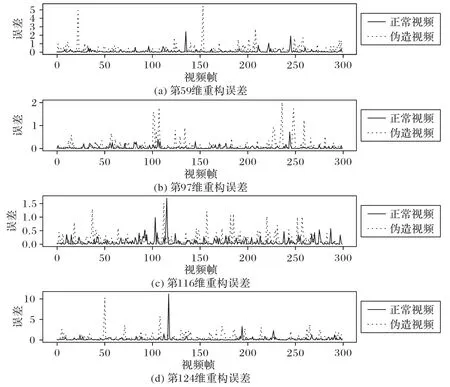
图2 不同维度特征点序列的重构误差Fig.2 Reconstruction errors of facial landmark sequences with different dimensions
时序异常检测任务通常通过对重构序列误差大小人工或自动地设置阈值来判断是否异常,但是本任务难以简单地通过一个阈值来区分。如图2(c)、(d)所示的样例,正常视频序列的误差在某些点非常高,甚至超过伪造视频序列,这种情况在实际数据中更常见。这是因为相较于时序异常检测任务中系统产生的序列,正常的人脸移动也会包含很多的个性化特征,这种个性化特征造成的较大重构误差并不能简单地和伪造产生的重构误差区分开,导致通过简单设定阈值的方法并不能取得好的区分效果。但是从序列整体来看,伪造特征序列重构误差的波峰会更频繁地出现。因为伪造视频中每一个表情都是伪造的,所以重构误差较大的地方较多,波峰也更多;而正常视频中每个人尽管都有自己独特的表情特点,但大多都服从普遍的模式,可以被很好地重构还原,所以波峰出现得较少。
根据上述分析,本文从重构误差波峰频率的角度出发,使用离散傅里叶变换将时域序列转换为频域信号,此时伪造视频的重构误差序列在高频部分会占有更大的比例。所以本文通过在频域上设定频率阈值θ,分别计算每一维特征点重构误差序列频率大于θ的比例作为特征点j的伪造得分scorej,最终整个视频的伪造得分为:scoreall=score1+score2+… +score136,得分越大说明是伪造的可能性越大。图3(a)、(b)分别表示测试集中伪造、正常视频的伪造分数频数图,即重构误差序列频域中高频和的频数图。容易看出,本文方法使正常和伪造的伪造分数集中于不同的区间,此时设置一个伪造分数相关的阈值,可以更简单地进行区分。
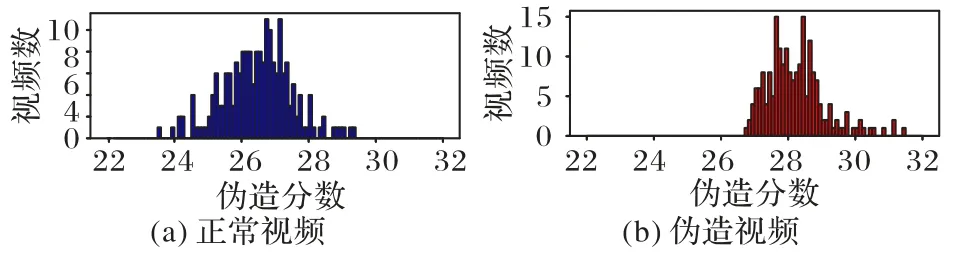
图3 伪造分数分布比较Fig.3 Comparison of forgery score distribution
3 实验与结果分析
3.1 实验设置
3.1.1 数据集
为验证本文方法的有效性,采用视频伪造检测任务中广泛使用的两个数据集FaceForensic++[26]和Celeb-DF[27]。其中FaceForensic++遴选了互联网上的1 000 个视频,用Deepfakes、Face2Face、FaceSwap、FaceShifter 和NeuralTextures等5 种伪造算法分别生成1 000 个伪造视频。根据压缩率不同,每一个视频有未压缩、轻微压缩和重度压缩三个版本,本文实验采用轻微压缩版本。Celeb-DF 包含了5 639 个伪造视频和540 个正常视频,采用改进的开源深度伪造算法,改善了颜色不一致等明显伪影。
3.1.2 参数设置
在预处理阶段,本文使用Dlib[22]标注人脸特征点。在重构流程前,将整个人脸特征点序列按2 s 即60 帧为一块切分,卷积网络的卷积核大小设置为5,填充设置为2,通道设置为32。编码的维度设置为16,解码器的输出的维度设置为32。
此外每批包含256 条数据,每次训练200 个轮次。采用Adam 优化器,学习率设置为0.001。KL 散度损失的权重设置为0.005。
3.1.3 衡量指标
为了应对数据集样本不均衡的情况,本文实验选择不容易受不均衡样本影响的接受者操作特征(Receiver Operating Characteristic,ROC)曲线的 曲线下 方面积(Area Under Curve,AUC)作为衡量指标。
其中:insi表示第i条样本代表第i条样本在得分从小到大排列时的序号;M、N分别表示正样本和负样本的个数;pos表示正例的集合。
3.2 实验及结果分析
本文设计了以下实验:1)通过对比在不同伪造方法上的检测效果,验证本文提出的无监督人脸伪造视频检测方法的有效性和可移植性;2)通过对比不同方法的训练时间,进一步说明本文方法的高效率和低成本;3)通过消融实验,说明本文方法各部分设计的合理性。
3.2.1 对比实验
对比实验主要用来说明本文无监督方法的有效性及可移植性。
1)模型有效性。首先对比FaceForensic++数据集上不同伪造方法的检测性能,验证本文无监督人脸伪造视频检测方法CNN-GRU-VAE 的有效性,实验结果如表1 所示。CNNGRU-VAE 训练集采用FaceForensic++数据集,随机选择800个正常视频作训练。测试分为两个部分,首先选择FaceForensic++剩下的200 个正常视频和不同方法下的200个伪造视频分别构造不同方法下的测试集。LRNet(DF)是模型LRNet[10]仅使用DeepFake 伪造的数据作为训练集负例得出的模型;LRNet(NT)是文献[10]仅使用NeuralTexture 伪造的数据作为训练集负例得出的模型。可以看出本文方法在DeepFake 上性能良好,不仅远好于LRNet(NT),与LRNet(DF)也很接近;在Face2Face 上与LRNet(DF)性能接近;在FaceShifter 和FaceSwap 上比LRNet(DF)和LRNet(NT)都好。这说明本文的无监督模型仅使用正常数据训练,面对未知伪造方法生成的视频仍然能够有效鉴伪,相较于使用单个伪造方法生成数据集上的训练模型,在未知方法生成的数据集上达到了不错的性能。CNN-GRU-VAE 对NerualTexture伪造方法的检测效果较差,主要是模型中的对多层次时序信息建模干扰了对几何信息的感知,具体解释将在3.2.3 节根据消融实验结果说明。

表1 不同模型在FaceForensic++数据集上的AUC得分Tab.1 AUC scores of different models on FaceForensic++dataset
2)模型移植性。使用Celeb-DF[27]的所有数据测试不同数据源对模型性能的影响,结果如表2 所示。其中,除LRNet和 CNN-GRU-VAE 之 外,Two-stream[28]、Meso4[2]、MesoInception4[27]、FWA(Face Warping Artifacts)[29]、DSPFWA(Deep Spatial Pyramid Face Warping Artifacts)[27]、Xception-c23[27]、Capsule[30]采用的是文献[27]中的实验数据。
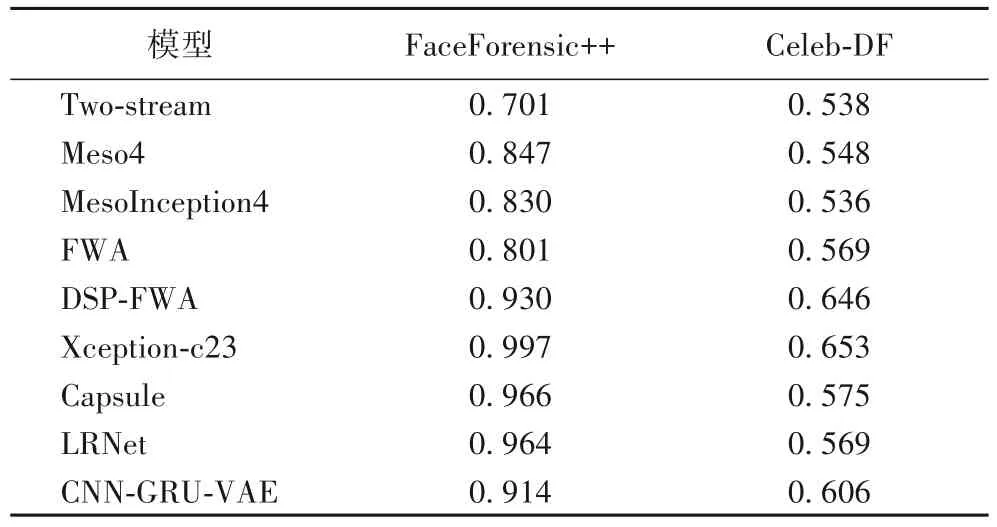
表2 通过AUC分数对不同模型的移植性能评估Tab.2 Transplantation performance evaluation of different models by AUC scores
FaceForensic++的实验设置和文献[27]相同,训练与测试集仅考虑DeepFake 伪造数据集上的结果。可以看出本文的无监督方法在FaceForensic++上超过部分方法,在Celeb-DF 上的性能好于多数方法。这说明本文模型在不同数据源上的可移植性优于多数有监督模型。
3.2.2 训练成本实验
为了验证本文模型在训练成本上的优势,从GPU 的显存占用、预处理后训练数据在硬盘占用和训练时长三个方面,将本文方法和其他伪造检测模型进行比较,结果如表3所示。其中,除CNN-GRU-VAE 之外,Xception[31]、X-Ray[4]、CNN+RNN(Convolutional Neural Network+Recurrent Neural Network)[32]、TSN(Temporal Segment Network)[33]、LRNet 采用的是文献[10]的实验数据。
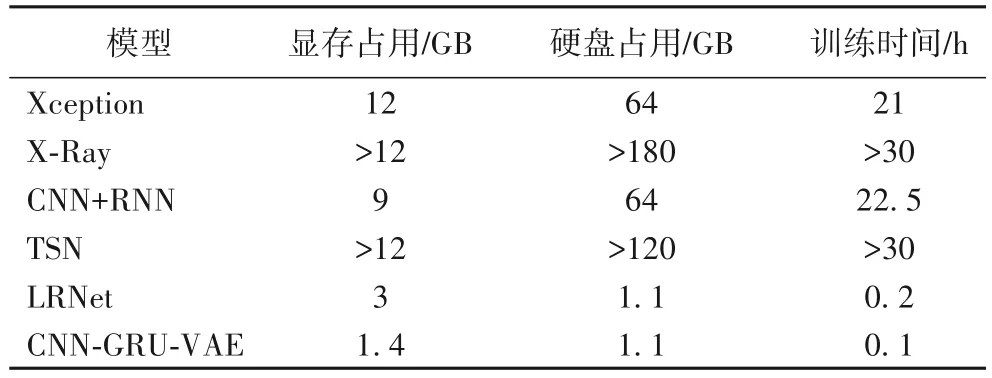
表3 训练成本对比Tab.3 Comparisons of training cost
从表3 可以看出,基于人脸特征点的模型在GPU 的显存占用、硬盘训练数据占用和训练时长都有明显减少,LRNet和CNN-GRU-VAE 显存和硬盘需求都远小于其他方法,训练时间都不到其他模型的1%。相较于同样基于人脸特征点的算法LRNet,尽管本文模型比它复杂,但训练时间更短,显存占用更少。显存占用少是因为LRNet 每次输入的批大小为1 024,而CNN-GRU-VAE 批大小为256。训练时间更短的主要原因有:LRNet 需要的训练数据比CNN-GRU-VAE 多1 倍;LRNet 有两个相似的网络需要分开训练;LRNet 收敛缓慢,通常需要400 轮以上才能达到比较好的性能,1 000 轮以上才能基本收敛,然而CNN-GRU-VAE 训练200 轮时就已经基本收敛;由于本文是无监督算法,所以面对不同的伪造方法只需要训练一次,而LRNet 此类的多数有监督算法想要达到比较理想的性能,需要在每一个伪造方法上训练一次。这充分说明了本文提出的无监督算法在训练成本上的优势。
3.2.3 消融实验
消融实验主要分析本文方法各部分设计的合理性和有效性,结果如表4 所示。其中:CNN-GRU-VAE 表示本文完整方法的AUC 得分;其他表示模型消除不同部分时的AUC 得分与完整模型AUC 得分的差值。“不使用偏移特征”是模型将人脸特征点序列直接输入解码器,不使用偏移特征;GRUVAE 是将编码器中去除CNN 后的模型;CNN-GRU-AE 是用自动编码器替换变分自编码器。从整体结果来看,本文各部分设计都有效地提升了视频中人脸伪造检测的性能。

表4 网络结构消融实验中不同组件对AUC分数的影响Tab.4 Influence of different components on AUC score in ablation study of network structure
使用偏移特征替换原始特征点后,Deepfake、FaceShifter和FaceSwap 在引入偏移特征后AUC 分数都有0.059 1 到0.061 8 的提升,而Celeb-DF 有0.045 0 的提升,说明了细粒度时序特征引入的有效性及必要性。但是在Face2Face 和NeuralTexture 上的检测性能反而降低了,其中Face2Face 变化不明显,但NeuralTexture 的AUC 分数下降了0.040 5。通过观察数据可以发现,相较于另外三个伪造算法,NeuralTexture 不自然的伪造痕迹更多体现在人脸器官的几何特点上,所以偏移特征虽然引入了细粒度时序特征,却弱化了模型对人脸特征点几何特征的提取,导致NeuralTexture的效果反而变差。
而通过GRU-VAE 模型的结果可知,引入CNN 后,Deepfake、FaceShifter 和Celeb-DF 的AUC 分数都有较大的提升,其他的也有少量提升。这说明CNN 引入的“分块帧”局部特征有助于加强模型的鉴伪能力。
变分自编码器的引入使多数方法的AUC 分数都有不同程度的提升,说明相较于自编码器,变分自编码器通过引入噪声使模型更加健壮,在深度伪造检测上表现为增强了模型对个性时序特征的容纳能力。但是NeuralTexture 上的性能降低了很多,这是因为区分NeuralTexture 需要的是几何特征,而不断增强的时序特征并没有给区分NeuralTexture 带来优势,反而阻扰了模型对几何信息的感知。
4 结语
本文创新性地将时序数据异常检测思想引入视频的人脸伪造检测中,提出了一种基于人脸特征点重构误差的无监督人脸伪造视频检测框架。首先对待检测视频逐帧抽取人脸特征点,并进行特征点序列校准;其次,基于偏移特征、局部特征、时序特征等多粒度信息对待检测视频中的人脸特征点序列进行重构;然后基于离散傅里叶变换计算原始序列与重构序列之间的重构误差;最后根据重构误差的波峰频率对伪造视频进行自动检测。实验结果表明,本文提出的无监督方法能够有效检测现有大部分伪造方法生成的人脸伪造视频,并在不同数据源间具有良好的移植性。未来的工作旨在更好地融合几何特征和时序特征,同时希望能够提升模型区分个性特征和伪造特征的能力,使其达到更好的精度。
