基于不同敏感度的改进K-匿名隐私保护算法
2023-05-24陈学斌张国鹏裴浪涛
翟 冉,陈学斌*,张国鹏,裴浪涛,马 征
(1.华北理工大学 理学院,河北 唐山 063210;2.河北省数据科学与应用重点实验室(华北理工大学),河北 唐山 063210;3.华北理工大学 唐山市数据科学重点实验室,河北 唐山 063210)
0 引言
大数据及相关技术给社会和科技发展带来了重大的影响,数据的开放共享也给科学研究、社会治理等领域提供了支撑条件,但数据开放共享的同时,也不可避免地造成了数据隐私的泄漏。为解决这一问题,研究人员提出了许多隐私保护方法。目前,应用较广泛的隐私保护方法有数据加密技术、数据失真技术和数据匿名化技术[1]。数据加密技术指将信息使用加密函数转换为密文,如同态加密技术[2];数据失真技术指通过添加噪声的方式保护数据的安全,差分隐私技术[3]为常见的数据失真技术;数据匿名化技术指对数据进行泛化或隐匿。K-匿名[4]技术是目前应用较广泛的基于数据匿名化的隐私保护技术之一,原理为对数据进行泛化处理,使得对数据集中的每一个数据都有K-1 个数据与之相同。
传统的隐私保护方法主要考虑对数据进行保护,忽视了数据的可用性[5]。对拥有多个属性的数据集进行K-匿名处理时,由于属性的数量过多,为了使多个属性同时满足K-匿名特征,会产生过度隐匿现象,破坏数据的可用性。为了解决这个问题,本文提出一种基于随机森林(Random Forest,RF)的K-匿名隐私保护算法——RFK-匿名隐私保护。
本文首先用RF 算法[6]预测不同属性值的敏感程度,由于使用RF 算法对属性值的敏感程度进行预测会存在误差,因此利用k-means 聚类算法[7]将不同敏感程度的属性值分成不同集群,使每个集群中的属性敏感程度相近。最后根据不同属性集群对属性进行不同程度的隐匿,用户可以根据自己的需求选择隐匿数据表。该方法在保障数据隐私安全的基础上增加了数据的可用性。本文的主要工作如下:
1)与传统K-匿名技术中的无差别隐匿不同,本文根据属性敏感度的不同,对属性信息进行不同程度的隐匿,在保证数据的安全性的同时,减少了数据的损失。
2)使用真实数据集进行机器学习训练时有数据泄漏的风险,考虑到直接对真实数据集进行K-匿名处理会由于属性数量太多导致过度隐匿,而使用过度隐匿的数据进行机器学习训练时训练准确率会明显下降的情况,本文对真实数据集根据属性的敏感程度不同进行RFK-匿名处理,并使用处理后的数据进行机器学习预测。与K-匿名算法、(p,α,k)-匿名隐私保护算法相比,在阈值E较大时,本文方法的预测准确率有所提升。
1 相关工作
1.1 隐私保护
在数据隐私保护的基础上,保证数据的可用性至关重要。针对这一问题,研究人员提出了一系列研究方案。蒲东等[8]根据属性值不同的敏感等级,采用不同的匿名方法,例如分类型数据中,对于较低敏感程度的属性,泛化到所在树的上一层节点,对于较高敏感程度的属性,泛化到更高一层的节点;同时,根据阈值α确定属性值出现的频率,使泛化后等价类中各个敏感属性值出现的频率平均,在减少数据损失的同时降低了隐私泄漏的可能。张王策等[9]提出了一种将缺损数据与完整数据混合匿名的算法,能有效地提高数据的可用性。吴梦婷等[10]在K-匿名中考虑K 最近邻(K-Nearest Neighbor,KNN)聚类思想[11]的离群点问题,降低了数据的损失。苏林萍等[12]提出了一种个性化(α,l,k)匿名隐私保护模型。在最大程度保证个性化匿名需求的同时根据敏感属性值敏感等级的不同,对各个等价组中的敏感属性值分别采取不同的匿名方式,优先泛化高敏感度等级的属性值,使等价组中的每个敏感属性满足对出现频率α以及多样性l的约束条件,从而有效降低数据集中高敏感等级信息的泄露风险,并提高数据的可用性。王楠[13]提出的(p,aisg)-敏感性k-匿名差异化地限制了敏感组出现的总频率,实现了在敏感组维度的个性化保护,并根据敏感值的敏感度设置了有区别的多样性约束的(pi,aisg)-敏感性k-匿名,敏感值维度也达到了个性化匿名效果,减少了对低敏感信息保护过度造成的冗余信息损失。对于(p,aisg)-敏感性k-匿名模型和(pi,aisg)-敏感性k-匿名模型存在语义相似性攻击的威胁,对敏感值进行语义类别划分,王楠[13]提出了针对语义相似性攻击的具有对敏感组个性化保护特性的(psc,aisg)-敏感性k-匿名,在此基础上还添加了面向语义类别的个性化保护的(pisc,aisg)-敏感性k-匿名,以较少的数据可用性为代价在隐私性方面表现出了突出优势。张强等[14]提出了一种基于最优聚类的k-匿名隐私保护机制,通过建立数据距离与信息损失间的函数关系,将k-匿名机制的最优化问题转化为数据集的最优聚类问题;然后利用贪婪算法和二分机制,寻找满足k-匿名约束条件的最优聚类,从而实现k-匿名模型的可用性最优化,能最大限度减少聚类匿名的信息损失。杨柳等[15]设计了一种混合式K-匿名特征选择算法,使用分类性能作为评价准则选出分类性能最好的K-匿名特征子集,在分类性能上可以超过现有算法并且信息损失更小。樊佳锦等[16]提出了一种基于分类重要性与隐私约束的K-匿名特征选择(Importance Feature Privacy K-Anonymous by Clustering in Attribute,IFP_KACA)方法,根据特征分类重要性排序选择分类性能较好并且满足隐私约束的特征进行K-匿名处理,从而得到保护特征隐私后的优选特征子集。算法筛选的特征集能够平衡隐私保护度和分类挖掘性能,有效检测微博垃圾用户。然而上述研究仅在数据集的部分属性中使用了K-匿名技术,而真实数据集中的属性数量更多,数据集中的某些属性的敏感程度较低,将这些信息发布出来对用户的影响较小,但是对全部属性进行隐匿,由于多个属性难以同时达到K-匿名条件,满足K-匿名条件时属性要不断泛化,泛化程度越大,数据的精度越低,会严重影响数据的可用性。为了解决这一问题,本文提出了一种改进的K-匿名隐私保护算法,对数据集中的所有属性进行K-匿名处理,而且在对属性进行隐匿之前,首先使用RF 算法预测属性的敏感程度,将属性根据敏感程度不同划分成若干的集群,对于不同敏感度集群的属性采用不同的隐匿方法,达到在保护用户隐私的基础上提高数据可用性的目的。
1.2 K-匿名
K-匿名[17]是一种对数据进行处理的隐私保护方法,指的是对于某一用户的某一项信息,至少有K-1 个人与之相同,这样攻击者便无法分辨出真正的隐私信息。本文利用K-匿名技术将用RF 算法预测出的会产生隐私泄漏的数据进行隐匿,达到隐私保护的作用。用户的基本信息分为标识列和准标识列。标识列指用户的姓名、身份证号等信息,在隐私保护过程中,标识列的信息会被直接抹除;准标识列的信息是关于用户的其他信息,如用户的年龄、城市、学校等,如果不对准标识列的数据进行处理,会产生链接攻击[18]。链接攻击指攻击者通过将两个数据中的信息混合得到有关用户的隐私。本文利用K-匿名法对准标识列的信息进行处理,使得对于用户的某个数据,有K-1 条数据与之相同,可以有效防止因准标识列泄漏导致的链接攻击[19]。
2 基于随机森林的K-匿名隐私保护算法
本文提出的RFK-匿名隐私保护算法根据真实数据集属性的敏感程度不同,对数据进行不同程度的隐匿,在保护了隐私的前提下最大限度地保证了数据的可用性。本文的目的主要是解决使用真实数据集进行机器学习分类预测过程中数据可用性和安全性的平衡问题。
2.1 问题描述
大数据背景下,用户的个人信息被上传至多个服务器,同时,也带来了一系列隐私泄露的隐患。机器学习需要大量的真实数据集,在使用机器学习进行分类预测时,足够数量的真实数据集是准确预测结果的重要条件之一。然而,数据拥有者将数据发布即面临一定的风险,导致大多数数据拥有者不愿意发布自己的数据。机器学习的发展需要足够数量的兼顾可用性和安全性的数据。针对这一问题,本文提出了一种改进的K-匿名隐私保护技术,在数据拥有者发布数据之前,使用K-匿名技术对数据进行处理,由于真实数据集属性数量过多,为了避免多个属性同时能满足K-匿名特征会产生过度隐匿现象,破坏数据的可用性,因此根据属性的敏感程度不同,对属性进行不同程度的隐匿,根据用户的需求发放隐匿数据表,在保护数据安全性的前提下提升数据的可用性。
2.2 算法描述
本文方法的主要步骤如下:首先,使用RF 算法根据属性预测关键信息,对关键信息的预测影响越大的属性越敏感;然后,使用k-means 聚类算法根据属性的不同敏感程度对属性进行聚类,分成敏感程度不同的5 个集群,即k=5;最后,使用K-匿名算法根据属性的敏感程度采用不同的泛化程度隐匿用户的隐私信息,用户可以根据自己的需求选择使用不同匿名化程度的数据表。
2.2.1 随机森林算法预测
使用RF 算法根据属性值对标签值进行预测,然后每次减少一个属性,并用剩余的属性对标签值进行预测,减少属性后预测准确率降低越多说明该属性值越敏感。算法伪码如下:
算法1 随机森林(RF)预测算法。
2.2.2k-means聚类算法过程
使用k-means 聚类算法根据属性值对标签值的影响大小对属性进行聚类,设置k=5,即将属性分为5 个敏感程度不同的集群。算法的流程如下:
1)从属性值中随机选取5 个值作为初始中心点;
2)计算各个属性值的敏感程度值到各个中心点的距离,将属性根据敏感程度值划分到距离它最近的中心点集群;
3)计算集群的平均值作为新的中心点;
4)重复上述过程直至中心点不再发生变化。
算法2k-means 聚类算法。
2.2.3K-匿名处理
将属性聚类后的第1 集群进行K-匿名处理后的数据表阈值设置为1;将属性聚类后的第1、2 集群进行K-匿名处理后阈值设置为2;将属性聚类后的第1、2、3 集群进行K-匿名处理后阈值设置为3;将属性聚类后的第1、2、3、4 集群进行K-匿名处理后阈值设置为4;将全部属性进行K-匿名处理后阈值设置为5。用户可以根据自己的需求选择使用不同匿名化程度的数据表。算法的流程如下:
算法3K-匿名算法。
2.3 算法分析
2.3.1 算法复杂度
k-means 算法对属性值的敏感程度进行聚类的时间复杂度为O(nkt),其中n为数据的个数,k为初始中心点的个数,t为迭代次数;用RF 算法预测属性集群的敏感程度的时间复杂度为O(Mmnlog(n)),其中n为数据的个数,m为特征的个数,M为随机森林中树的个数;K-匿名算法对数据进行隐匿的时间复杂度为O(nK),其中n为数据的个数,K为对于每个数据相同的个数。即本文提出的基于随机森林的K-匿名隐私保护算法的时间复杂度为O(nkt+Mmnlog(n) +nK)。
2.3.2 算法安全性
本文算法中,数据的拥有者首先使用RF 预测数据集的属性敏感程度,这一过程由数据拥有者自己进行,所以不存在数据泄露的风险。其次根据预测准确率进行k-means 聚类,将属性根据敏感程度的不同划分到不同集群,这一过程只对属性的敏感程度值进行操作,不会出现原始数据的泄漏。最后使用K-匿名隐私保护方法对数据进行不同程度的隐匿,这一过程由于提前预测敏感属性,并对不同敏感程度的属性进行不同程度的保护,保证了原始数据的安全性。
数据集中有数值型数据和分类型数据,对于数值型数据,信息损失度ILi如下:
其中:MAXi为第i个属性概化后的最大值,MINi为第i个属性概化后的最小值;Ri为第i个属性数据的值域。
对于分类型数据,信息损失度ILi如下:
其中:Nodei为第i个属性的原始叶子节点数为第i个属性概化后的叶子节点数。相较于K-匿名算法,RFK-匿名算法有效减少了信息的损失度,而且安全性较高。
RFK-匿名算法满足K-匿名算法的基本条件,对于每一条数据,都有至少K-1 条数据与之相同,可以有效地防止链接攻击;而且用户可以根据自己的需求选择不同程度的隐匿数据表。与K-匿名算法相比,RFK-匿名算法在没有降低安全性的情况下提高了数据的可用性。
2.3.3 算法可用性
本文算法利用RF 算法根据一部分特征值预测某个特征值,而RF 算法随机将数据集分为训练组和测试组,训练组与测试组结果的比值为准确率,符合RF 算法预测的条件,预测准确率为一个数值。利用k-means 聚类算法可以对数值型数据进行聚类,将数据分为k(本文k=5)个集群,用k-means 聚类算法对数据根据数值进行聚类,满足聚类算法的条件。本文算法利用K-匿名算法对属性值进行隐匿,这样对每一个元组,都至少有K-1 个与之相同,满足用K-匿名算法进行隐匿的条件。在使用机器学习进行预测的过程中,数据集的可用性和安全性需要得到保障,在实验过程中,采用RF 算法对属性的准确率进行预测,然后依次删除一个属性,使用其他剩余属性对标签值进行预测,删除这个属性前后准确率变化越大表示这个属性越敏感。对全部属性进行K-匿名处理时,由于属性数量太多,达到K-匿名的条件时属性泛化程度较大,数据的可用性降低。使用k-means 聚类算法根据属性的不同敏感程度对属性进行聚类,分成敏感程度不同的集群,使用K-匿名算法根据属性的敏感程度采用不同的泛化程度隐匿用户的隐私信息,使用处理后的数据进行机器学习的预测,能保障数据的安全性和可用性。用户可以根据自己的需求选择使用不同匿名化程度的数据表。
3 实验与结果分析
3.1 数据集
本实验采用了UCI 的Adult 和Bank Marketing 数据集,数据来源:https://archive.ics.uci.edu/ml/datasets/Adult,https://archive.ics.uci.edu/ml/datasets/Bank+Marketing。
Adult 数据集抽取自美国1994 年人口普查数据库,因此也称作“人口普查收入”数据集,其中包括:年龄、工作类型、序号、受教育程度、受教育时间、婚姻状况、职业、关系、种族、性别、资本收益、资本损失、每周工作时间、原籍等14 个字段信息,共有48 842 条数据。该数据集是一个分类数据集,用来预测年收入是否超过5 万美元。年收入大于5 万美元的人口占比为23.93%,年收入小于5 万美元的人口占比76.07%。
Bank Marketing 数据集与葡萄牙银行机构的营销活动相关,这些营销活动以电话为基础,银行的客服人员需要至少联系客户1 次来确认客户是否认购该银行的产品(定期存款)。该数据集中包括年龄、职业、婚姻情况、受教育程度、账户余额、住房、贷款、日期-日、日期-月、存款期限、营销活动、存款情况等16 个字段信息,共有11 162 条数据。
3.2 实验环境
本实验采用macOS 操作系统,处理器为1.8 GHz 双核Intel Core i5,用Python 语言在jupyter 中编写实验代码。
3.3 实验过程
本文实验分为以下几个部分:1)先使用RF 算法预测出属性的敏感程度,对敏感属性根据敏感程度进行聚类,并验证即使预测结果具有随机性,聚类后同一集群的属性仍然不会发生变化;2)对不同聚类的属性分别进行RFK-匿名处理和K-匿名处理,对比预测准确率和信息损失度;3)用(p,α,k)-匿名隐私保护算法和RFK-匿名处理后的数据计算预测准确率和信息损失度。本文首先对数据集进行预处理,然后使用RF 算法根据所有属性值预测标签值。在预测过程中,对于每个属性,用其他剩余属性预测标签值。为了使RF 预测的结果更准确,采用20 次实验的平均值作为预测准确率,将每个属性删除前后的预测准确率之差看作属性对预测标签值的敏感程度,由于实验结果具有随机性,用k-means 算法对属性根据敏感程度进行聚类,使相近敏感程度的属性值都在一个集群里,这样即使输出结果的排序具有随机性,也不会影响集群中的数据,能更好地减小误差。k-means 聚类算法中的k=5,即将属性分为5 个敏感程度不同的集群,第一集群属性的敏感程度最高,第二集群的次之,以此类推。使用K-匿名算法分别对这5 个敏感程度不同的集群进行隐匿,即对所有属性隐匿的数据表阈值设置为5,对第一、二、三、四集群隐匿的数据表设置阈值为4 的数据表,以此类推,对第一集群隐匿的数据表设置阈值为1 的数据表。由于数据集中的属性数量太多,为了更好地保证数据的可用性,进行K-匿名处理时的K值大于2 即可。
3.4 实验结果
3.4.1 预测准确率
使用RF 算法根据全部属性预测标签值的准确率,每次删除一个属性,用剩余的其他属性预测准确率,准确率越高说明删除的属性对预测结果的影响度越低,该属性的敏感性越低;准确率越低说明删除的属性对预测结果的影响度越高,则该属性的敏感程度越高。对每一个属性分别利用其他剩余属性预测20 次的平均准确率和用所有属性预测20 次的平均准确率如表1、2 所示。

表2 RF在Bank Marketing数据集上的预测准确率Tab.2 Prediction accuracy of RF on Bank Marketing dataset
对于每个属性,删除该属性前后对预测准确率的影响如表3、4 所示。
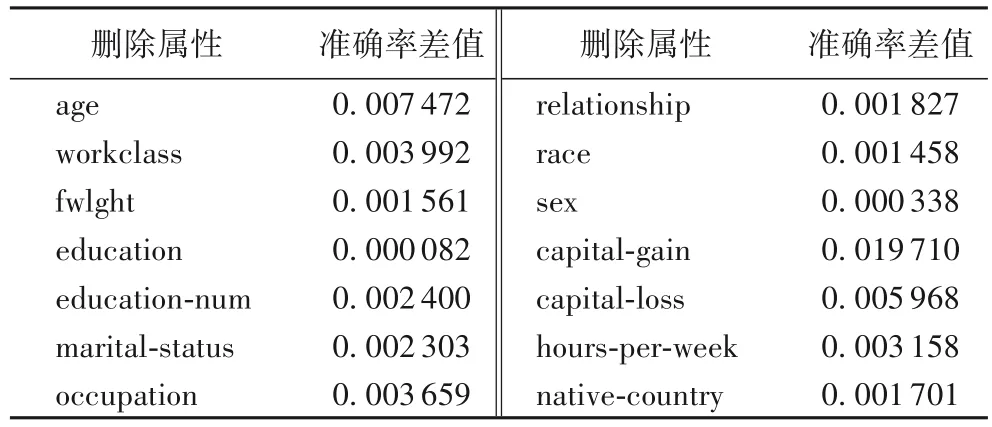
表3 Adult数据集中每个属性是否参与预测的准确率的差值Tab.3 Difference in prediction accuracy for eliminating each attribute or not in Adult dataset

表4 Bank Marketing数据集中每个属性是否参与预测的准确率的差值Tab.4 Difference in prediction accuracy for eliminating each attribute or not in Bank Marketing dataset
对于每个属性,根据属性对准确率的影响程度,使用k-means 聚类算法进行聚类,将属性分为5 个不同的集群,聚类后的结果如表5~8 所示。预测准确率采用的是预测20 次的平均准确率,并使用k-means 聚类算法根据属性对准确率的影响进行聚类,有效降低了由于预测误差导致的结果不确定性。
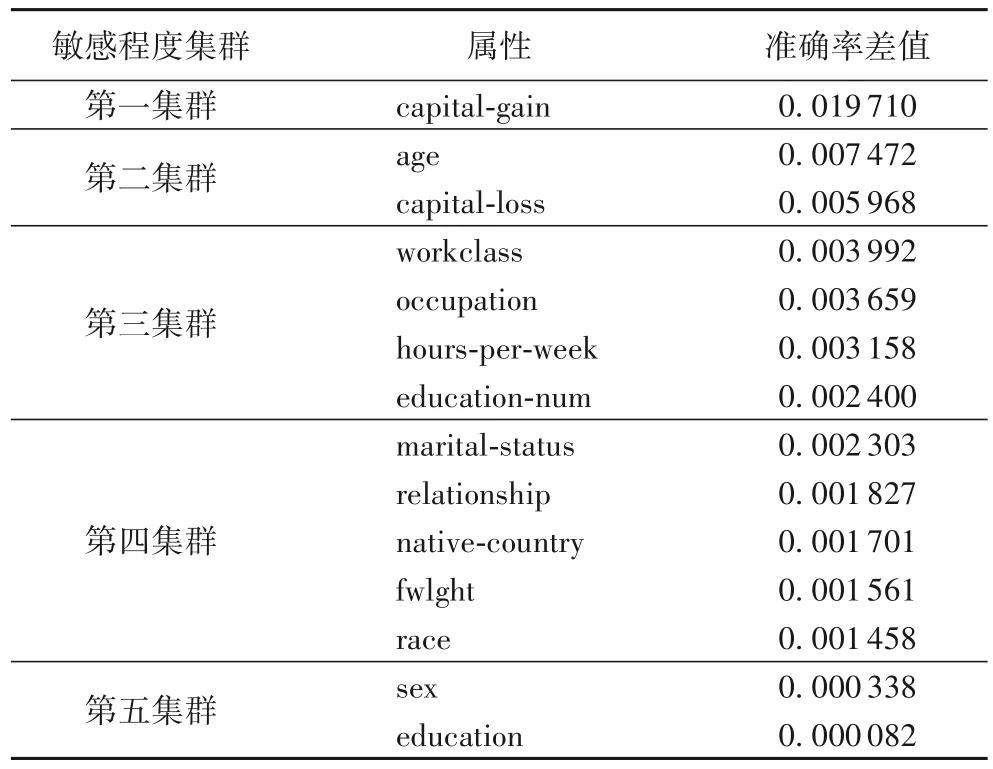
表5 Adult数据集上k-means聚类结果Tab.5 k-means clustering results on Adult dataset

表6 Bank Marketing数据集上k-means的聚类结果Tab.6 k-means clustering results on Bank Marketing dataset

表8 Bank Marketing数据集上k-means的聚类结果可靠性验证Tab.8 Reliability Verification of k-means clustering results on Bank Marketing dataset
图1 为RFK-匿名算法和K-匿名算法的准确率对比结果。其中E为可信度阈值,将第一集群的阈值设置为1,将第一、二集群的阈值设置为2,将第一、二、三集群的阈值设置为3,将第一、二、三、四集群的阈值设置为4,将第一、二、三、四、五集群的阈值设置为5。

图1 RFK-匿名算法与K-匿名算法的预测准确率比较Fig.1 Comparison of prediction accuracy between RFK-anonymity algorithm and K-anonymity algorithm
图1 中预测准确率的结果表明,当E为1、2 时,使用K-匿名算法处理后的数据进行预测的准确率高于使用RFK-匿名处理的数据进行预测的准确率;当E为3、4 时,使用RFK-匿名处理后的数据进行预测的准确率高于使用K-匿名算法处理后的数据进行预测的准确率,在Adult 数据集中分别提升了0.5 个百分点和1.6 个百分点,在Bank Marketing 数据集中分别提升了0.4 个百分点和0.9 个百分点;当E为5 时,使用RFK-匿名算法处理的数据和使用K-匿名算法处理的数据的预测准确率相等。出现这一现象的原因是当E为1、2 时,RFK-匿名中的属性数量太少,导致预测准确率低;当E为3、4 时,使用RFK-匿名算法进行处理的属性数量足够,同时没有过多属性导致的过度隐匿情况;当E为5 时,使用RFK-匿名处理的数据相当于直接对数据集进行K-匿名处理。同时,使用K-匿名算法直接对数据集进行处理时,由于属性数量过多,满足K-匿名条件的K值过大,属性泛化程度更大,影响了数据的可用性,泛化后的数据用来机器学习预测的准确率约等于只使用一半属性进行K-匿名处理后进行预测的准确率,严重影响了数据的可用性。
3.4.2 信息损失度
RFK-匿名与K-匿名算法的信息损失度如图2 所示,其中E为阈值,Information Loss 为所有数值型数据和分类型数据的信息损失度之和。
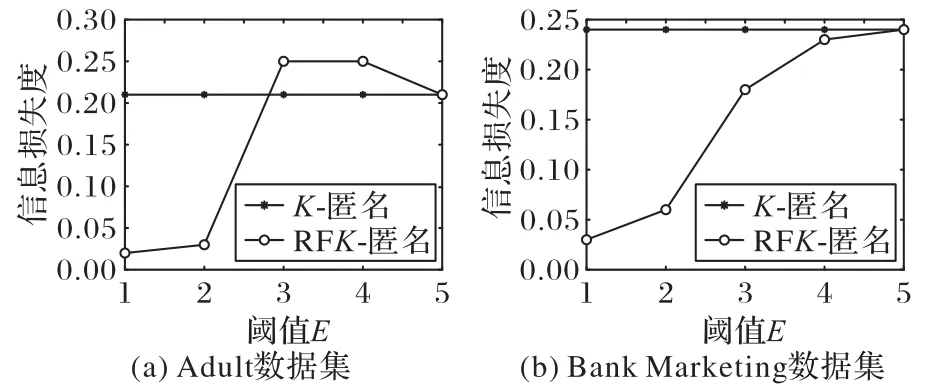
图2 RFK-匿名算法与K-匿名算法信息损失度的比较Fig.2 Comparison of information loss between RFK-anonymity algorithm and K-anonymity algorithm
从图2(a)中可以看出:当E为1、2 时,使用K-匿名算法处理后的数据的信息损失度高于使用RFK-匿名处理的数据;当E为3、4 时,使用RFK-匿名处理后的数据的信息损失度高于使用K-匿名算法处理后的数据;当E为5 时,使用RFK-匿名算法处理的数据和使用K-匿名算法处理的数据的信息损失度相等。出现这一现象的原因是当E为1、2 时,RFK-匿名中的属性数量少,K-匿名的条件容易达到;当E为3、4 时,属性数量明显增加,所以K-匿名的条件较难达到;当E为5 时,使用RFK-匿名处理的数据相当于直接对数据集进行K-匿名处理。
从图2(b)中可以看出,当阈值E不断增加时,RFK-匿名算法的信息损失度不断增加,但信息损失度一直低于K-匿名的信息损失度。这是因为随着E不断增加,属性的数量增加,满足K-匿名条件的K值变大。对数据集直接进行K-匿名处理时,由于属性数量过多,满足K-匿名条件的K值过大,属性泛化程度更大,影响了数据的可用性,数据的信息损失度高于使用RFK-匿名处理的信息损失度。
(p,α,k)-匿名隐私保护算法作为一种很好的隐私保护方法,在保护了隐私的前提下提升了数据的可用性,但更适合于直接发布数据,不适合应用于机器学习。
从图3(a)中可以看出,使用(p,α,k)-匿名隐私保护算法处理过的数据进行预测的准确率比较平稳,使用RFK-匿名算法处理过的数据进行预测的准确率在阈值较低的情况下低于使用(p,α,k)-匿名隐私保护算法处理过的数据进行预测的准确率;随着可信度阈值不断提升,使用RFK-匿名隐私保护算法处理过的数据进行预测的准确率高于使用(p,α,k)-匿名隐私保护算法处理过的数据进行预测的准确率。在Adult 数据集中,阈值E为4 时提高了0.4 个百分点,阈值E为5 时提高了1.9 个百分点。这是由于随着阈值E的不断增加,RFK-匿名中的数据集属性信息在不断完善,使用(p,α,k)-匿名隐私保护算法处理的数据集用来机器学习由于属性数量不够会影响预测准确率。

图3 RFK-匿名算法与(p,α,k)-匿名隐私保护算法的比较Fig.3 Comparison between RFK-anonymity algorithm and(p,α,k)-anonymity algorithm
从图3(b)中可以看出,使用RFK-匿名算法处理过的数据进行预测的信息损失度在阈值E为1,2 时低于使用(p,α,k)-匿名隐私保护算法处理过的数据;随着阈值不断提升,使用RFK-匿名隐私保护算法处理过的数据的信息损失度高于使用(p,α,k)-匿名隐私保护算法处理过的数据。用户可以根据自己的需求选择阈值。
3.4.3 实验小结
RFK-匿名隐私保护算法使用RF 算法根据Adult 和Bank Marketing 数据集中所有属性值预测标签值,并对每一个数据用其他剩余的属性预测标签值,删除这个属性前后的预测值之差为属性值对标签值的敏感程度,使用k-means 聚类算法根据标签值的敏感程度进行聚类,分成5 个集群,并对这5 个集群的数据分别进行K-匿名处理。实验结果表明:在Adult数据集中,第一敏感程度集群为capital-gain,第二敏感程度集群为age、capital-loss,第三敏感程度集群为workclass、occupation、hours-per-week、education-num,第四敏感程度集群为marital-status、relationship、native-country、fwlght、race,第五敏感程度集群为sex、education;在Bank Marketing 数据集中,第一敏感程度集群为poutcome,第二敏感程度集群为duration、day、contact,第三敏感程度集群为default、marital、age,第四敏 感程度 集群为balance、job、campaign、pdays、month、housing、previous、loan,第五敏 感程度 集群为education。通过图2 可知,使用(p,α,k)-匿名隐私保护算法处理过的数据进行预测的准确率比较平稳,使用RFK-匿名算法处理过的数据进行预测的准确率在阈值较低的情况下低于使用(p,α,k)-匿名隐私保护算法处理过的数据进行预测的准确率;而随着可信度阈值不断提升,使用RFK-匿名隐私保护算法处理过的数据进行预测的准确率高于使用(p,α,k)-匿名隐私保护算法处理过的数据进行预测的准确率。用户可以根据自己的需求选择阈值,这样可以在不影响数据的可用性的前提下保证数据隐私安全。
4 结语
本文首先利用随机森林算法对Adult 数据集和Bank Marketing 数据集中的属性进行敏感程度预测,其次将不同敏感程度的属性用k-means 算法进行聚类,然后使用K-匿名算法将不同敏感程度集群的属性进行隐匿,在保护数据隐私安全的基础上提高了数据的可用性。根据数据集中属性的敏感程度不同,给属性分成5 个聚类集群,将对不同集群的属性分批次进行K-匿名处理后,对数据集中的属性进行不同程度的隐匿可以在不影响数据的可用性的基础上提高数据的安全性,使数据集更适合用于分类预测。
