基于上下文语义增强的实体关系联合抽取
2023-05-24雷景生剌凯俊杨胜英
雷景生,剌凯俊,杨胜英*,吴 怡
(1.浙江科技学院 信息与电子工程学院,杭州 310023;2.浙江省肿瘤医院,杭州 310022)
0 引言
实体与关系抽取(Relation Extraction,RE)是自然语言处理(Natural Language Processing,NLP)领域的核心任务,用于从非结构化文本中自动提取实体及其关系。该任务的结果在知识图谱的构建、问答系统和机器翻译等各种高级自然语言处理应用中发挥着至关重要的作用。
有监督的实体和关系抽取传统上采用流水线或联合学习方法[1]。流水线方法将抽取任务看作两个串行子任务:命名实体识别(Named Entity Recognition,NER)和关系分类。关系分类子任务对识别出的实体进行配对并分类。由于相关实体数量较少,流水线模型在配对阶段通常会生成大量的不相关实体对。此外,该方法还存在错误传播,同时对两个子任务的关联性关注不足等问题。为了解决这些问题,研究者们对联合学习进行了大量研究,取得了较好的效果。
联合学习是指通过一个联合模型提取实体并对关系进行分类,能够有效缓解级联错误,提高信息的利用率。联合提取任务通常通过基于序列标注的方法解决[2]。最近,基于span 的方法由于其良好的性能而受到了广泛的研究[3]。该方法首先将文本分割成文本span 作为候选实体,然后形成span 对作为候选关系元组,最后,对实体span 和span 对进行联合分类。例如,在图1 中,“Boston University”“Boston”等是文本span;〈“Boston University”,“Boston”〉和〈“Michael D.Papagiannis”,“Boston University”〉是span 对;同时“Boston University”被分类为Org(Organization 的缩写);〈“Michael D.Papagiannis”,“Boston University”〉被分类为Work_For。
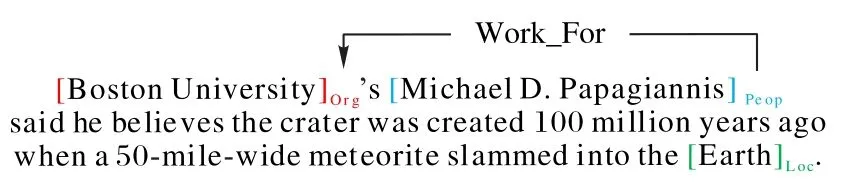
图1 span示例Fig.1 Examples of span
现有的联合实体和关系抽取方法的研究主要集中于两个子任务之间的交互,但存在对上下文的关注度不足的问题,且过度依赖ELMo(Embeddings from Language Models)[4]、BERT(Bidirectional Encoder Representation from Transformers)[5]等预训练语言模型的编码能力,导致其文本广度语义不足。如Eberts 等[3]直接使用BERT 中[CLS]的信息以及采用简单的最大池化将文本信息融入实体和关系表示中。这样无法很好地关注到上下文中的潜在信息,而这些信息对分类的准确性有着重要影响。
为了解决这一问题,本文提出了一个基于上下文语义增强的实体关系联合抽取(Joint Entity and Relation extraction based on Contextual semantic Enhancement,JERCE)模型,通过增强上下文的语义表示提高两个子任务的准确性。本文将同样的句子和上下文重复传递给预训练的编码器,通过应用标准随机掩码丢弃,可以得到语义相近且表示不同的嵌入,将它们作为正样本对;将同一训练批次的其他句子和实体间上下文作为负样本对。然后将上述样本输入对比学习模块,以获取增强后的文本语义表示。这种方法的优点是不需要通过复杂的操作就可以更好地捕获上下文中的关键信息,从而得到实体间关系的更准确的嵌入表示。在此基础上,还引入了一种加权损失函数来平衡训练过程中两个任务的损失,以此来获取整体性能更好的模型。在3 个基准数据集上的大量实验表明,本文模型相较于现有模型有着更好的表现。
1 相关工作
1.1 联合实体和关系抽取
联合实体和关系抽取的目的是同时从非结构化文本中检测实体以及实体之间的语义关系。它已被证明是有效的,因为它可以缓解错误传播,并有效利用命名实体识别(NER)和关系抽取(RE)之间的相互关系[6]。许多研究通过级联方法解决联合问题,它们先执行NER,然后执行RE。Gupta等[7]将联合实体和关系抽取作为一个表格填充问题,其中表格的每个单元对应句子的一个词对,同时使用双向循环神经网络来标记每个词对。Zhao 等[8]提出了一种特定于实体相对位置表示的模型,充分利用实体和上下文标记之间的距离信息,解决了实体特征模糊和局部信息不完整的问题。Sui等[9]将联合实体和关系抽取作为一个直接集预测问题,可以一次性预测所有三元组。Eberts 等[3]通过强负采样、跨度过滤和局部上下文表示,搜索输入句子中的所有跨度。Shen等[10]提出一个触发器感知记忆流框架(Trigger-sense Memory Flow framework,TriMF),通过多级记忆流注意模块,增强NER 和RE 任务之间的双向交互。
1.2 对比学习
对比学习的目的是在将不同样本的嵌入推开的同时,将相同样本的增强版本嵌入到彼此之间。该方法最早由Mikolov 等[11]引入自然语言处理,他们提出了一种基于对比学习的框架,使用共现词作为语义相似点,并通过负采样来学习单词嵌入。负采样算法利用逻辑回归将单词与噪声分布区分开,有助于简化训练方法。该框架以一种计算效率较高的方式明显地提高了单词和短语的表示质量。Saunshi等[12]提出了对比学习的理论框架,在使用学习到的表示进行分类任务时表现良好。该框架从未标记数据中学习有用的特征表示,并引入潜在类来形式化语义相似度的概念。
近年来,对比学习在一些自然语言处理任务中表现优异。Fang 等[13]提出了一种使用句子级对比学习的预训练语言表示模型 CERT(Contrastive self-supervised Encoder Representations from Transformers),以促进语言理解任务。CONPONO(CONtrastive Position and Ordering with Negatives Objective)模型[14]研究了篇章连贯性和文本中细粒度的句子排序,尽管与BERT-base 模型的参数数量相同,但性能更优。
2 本文模型JERCE
本文模型JERCE 使用BERT[5]进行编码,如图2 所示:将句子重复输入BERT,利用BERT 随机地丢弃掩码,获得正样本对,以便进行对比学习。在此基础上,计算得到增强的span 表示,并进行分类、过滤。然后用得到的实体集合组成关系空间,预测关系元组,计算关系表示并进行分类、过滤。
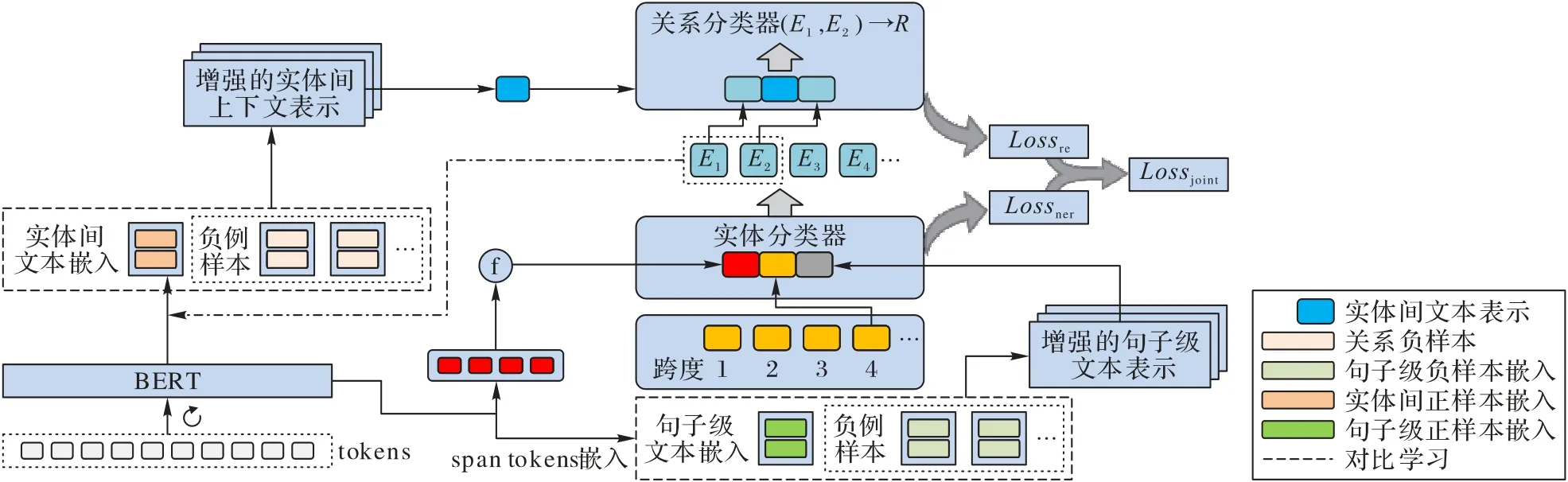
图2 JERCE的模型架构Fig.2 Model architecture of JERCE
2.1 BERT预训练语言模型
BERT 模型基于Transformer 编码器结构,能够学习到上下文的相关信息,解决了Word2Vec 和GloVe 等分布式词向量表示无法有效获取高维度特征的缺点。
BERT 的网络结构如图3 所示,它的模型架构是一个多层双向的Transformer 编码器。BERT 利用大规模无标注语料进行训练,获得文本包含丰富语义信息的表示,并在下游任务对预训练模型进行微调。它包含两个核心任务,即掩码语言模型(Masked Language Model,MLM)任务和下一句预测(Next Sentence Prediction,NSP)任务。MLM 使模型能够捕捉到辨别性的上下文特征,NSP 任务使理解句子对之间的关系成为可能。

图3 BERT模型Fig.3 BERT model
本文采用BERT 作为文本编码器,得到的输出表示为:
其中:S={s1,s2,…,sn}表示文本输入;H={h1,h2,…,hn},H∈Rd表示每个token 被BERT 编码后得到的token 嵌入,n为token 个数,d为BERT 隐藏状态的维度。
2.2 基于对比学习的文本语义增强表示
本文的目标是通过潜在空间的对比损失,使正样本对输入的一致性最大化,即正样本对语义向量的空间距离更近,负样本对语义向量的空间距离更远,从而学习到更准确的文本表示。
JERCE 使用预训练的语言模型BERT 对输入句子进行编码,然后使用对比学习目标对所有参数进行调整。
该任务的关键之一是在不破坏关键语义的前提下获取句子的正样本对,本文将同样的句子和上下文重复传递给预训练的编码器以实现这一目的。这是因为在BERT 的标准训练中,在全连接层和注意力层上有丢弃掩码。即
其中:z是随机的丢弃掩码表示输入xi的隐藏层输出;θ为函数f的参数。本文将相同的token 序列重复输入到编码器,得到具有不同丢弃掩码的嵌入,对于一个最小批次的N个句子或实体间上下文,同批次其余句子的对应内容作为负样本,本模块的训练目标便成为:
其中:z是Transformers 中的标准丢弃掩码;T是温度超参数,它会将模型的重点聚焦到距离正例较近的负例,并作出相应的惩罚。
这可以视为一种最低程度的数据增强,正样本对采用了完全相同的句子,它们的嵌入只是在进行随机掩码丢弃的过程中有所不同。
图4 展示了本文的对比学习模块的框架。给定一个句子w={w1,w2,…,wn},利用两次随机掩码丢弃获得两个语义相近的嵌入视图和接着加入了一个特征映射g(·)进一步提取特征,g(·)是一个2 层的多层感知机(Multi-Layer Perceptron,MLP)。从第一个嵌入视图得到了一个映射→h',同时从 第二个 嵌入视 图得到了 另一个映射→h″。

图4 对比学习模块的框架Fig.4 Framework of contrastive learning module
对比学习方法通过比较训练数据中的不同样本来学习表示。在训练过程中,通过使正对具有相似表征,使负对具有不同表征来学习文本语义。
2.3 span分类
由于span 的文本内容相对较少,可用信息有限,为此本文将工作的重心放在它的上下文表示部分。
如图2 所示,用于分类的span 表示由三部分组成:span文本信息、基于span 宽度的嵌入表示以及句子级上下文表示。本文用ti表示文本经过编码后得到的token 嵌入,将句子的嵌入序列表示为t0,t1,…,tN。span 嵌入序列定义如下:
span 自身的文本信息根据函数f融合得到,此处f采用最大池化处理,表示为:
对于特定长度的span,模型学习一个专用的矩阵以查找特定跨度的嵌入,它包含不同跨度[1;2;3;4;5-7;8-15;…]的span 的嵌入表示。这些嵌入通过反向传播学习。对于长度为k的span,其跨度嵌入为lk。
通过2.2 节的方法得到增强的句子级上下文表示,记为sc,并将它融入span 的表示中,以此来增强对上下文的信息捕获能力。所得到的分类实体span 的最终表示如下:
Zs最后被送入Softmax 分类器,该分类器在每个实体类别上产生一个后验:
其中:Ws为权重参数;bs为偏移量。
通过查看得分最高的类,span 分类器估计每个span 属于哪个类,得到构成实体的span 的集合,记为ε。然后对{ε×ε}衍生的关系元组进行关系分类。
2.4 关系分类
关系集合用ℜ 表示。关系分类器处理从{ε×ε}提取得到候选实体对即:并估计它是否存在ℜ 中存在的关系。
如图2 所示,用于分类的关系表示由两部分组成,包括被识别的实体对和增强的实体间上下文表示。
对于候选实体对s1和s2,位于它们之间的上下文在很大程度上蕴含了彼此之间的关系,为此利用对比学习对这部分文本进行语义提取。Ec表示s1和s2之间的增强局部上下文嵌入表示,s1和s2对应的实体表示为κs1和κs2,则最后的关系分类表示为:
将Zr送入Softmax 分类器,得到:
2.5 加权损失
本文模型包括多个子任务。在过去的工作中,为了将不同任务的损失进行联合优化,需要手动调节子任务的权重。在这个过程中,通常采取的损失函数是简单地将每个单独任务的损失进行加权线性求和,如下:
然而,模型最后的学习效果对于权重非常敏感,同时手动调节这些权重也是非常费时费力的工作。为此,需要找到一种更为方便的方法来学习最优权值。Cipolla 等[15]使用同方差不确定性来平衡单任务损失,同方差不确定性对相同任务的不同输入示例保持恒定的量。
模型的优化过程是为了使高斯似然目标最大化,以解释同方差不确定性,特别是要对模型权值w和噪声参数σs、σr进行优化。σs、σr为模型的观测噪声参数,即所谓的同方差不确定性项,它们可以捕获在输出中有多少噪声。为此引入以下联合损失函数:
通过最小化噪声参数σs和σr的损失,可以较好地平衡训练过程中单个任务的损失。可以发现增大噪声参数σs和σr会降低对应任务的权值,因此当任务的同方差不确定性较高时,该任务对网络权值更新的影响较小。通过这种方法,可以避免手工调优权重过程中耗时且繁琐的步骤。
3 实验与结果分析
3.1 实验数据
本文实验采用了以下3 个数据集:ACE05(Automatic Content Extraction,2005)[16]、CoNLL04(Conference on Natural Language Learning,2004)[17]和ADE(Adverse Drug Effect)[18]。
ACE05 由语言数据联盟(Linguistic Data Consortium,LDC)开发,包括新闻专线、广播新闻、广播谈话、网络日志、论坛讨论和电话谈话。预定义了7 个粗粒度实体类型和6 个粗粒度关系类型。本文遵循Li 等[19]的数据分割、预处理和任务设置。
CoNLL04 由来自华尔街日报和美联社等媒体的新闻文章的句子组成,数据集定义了4 种实体类型(person、organization、location 和other)和5 种关系类型(kill、work for、organization based in、live in 和located in)。为了与之前的工作进行比较,本文的实验遵循Gupta[7]和Eberts 等[3]的设置和数据分割。
ADE 是一个生物医学领域的数据集,旨在从医学文本中提取药物相关的不良反应。数据集提供了10 折训练和测试分割。它包括两种预定义的实体类型(Adverse-Effect 和Drug)和单一的关系类型(Adverse-Effect)。
3.2 评价指标
本文的模型性能评价指标包括精度P(Precision)、召回率R(Recall)和F1 值F1。具体公式表示如下:
其中:TP是真正例数;FP是假正例数;FN是假反例数;F1 值用来对精度和召回率进行整体评价。
3.3 实验参数设置
实验使用BERTbase(cased)作为句子的编码器;训练模型的batch size 为16,采用正态分布随机数(μ=0,σ=0.02)初始化分类器的权重;使用Adam 优化器,线性预热和学习率衰减,衰减指数为0.98,峰值学习率为5 × 10-5,丢弃率为0.2,宽度嵌入维数为25,epoch 数为30,关系滤波阈值α=0.4。
3.4 基线模型
将JERCE 同以下模型进行对比,这些模型在对应的数据集上有着不错的表现。
Relation-Metric[20]:该模型是多任务学习方案中基于序列标记的模型,它利用表结构、基于重复应用的2D 卷积和指标特征来池化局部依赖,在ADE 和CoNLL04 上有很好的性能。
MTQA(Multi-Turn Question Answering)[21]:该模型使用多回合问题回答机制,将实体和关系的提取转化为从情境中识别答案跨度的任务。该模型通过问题查询对需要识别的实体和关系的重要信息进行编码,并通过多步推理构建实体依赖关系,得到了数据集RESUME。
SpERT(Span-based Entity and Relation Transformer)[3]:该模型引入预训练的BERT 模型作为联合实体识别和关系提取的核心。
ERIGAT(Entity-Relations via Improved Graph Attention networks)[22]:该模型 将图注 意力网 络(Graph Attention Networks,GAT)引入实体关系联合提取域,有效地提取了多跳节点信息;同时采用对抗性训练,通过添加微小扰动来生成对抗性样本进行训练,增强了模型的鲁棒性。
eRPR MHS(entity-specific Relative Position Representation based Multi-Head Selection)[8]:该模型提出了一个特定于实体的相对位置表示,允许模型充分利用实体和上下文标记之间的距离信息;同时引入了一种全局关系分类增强对局部上下文特征的学习。
MRC4ERE++(Machine Reading Comprehension based framework for joint Entity-Relation Extraction)[23]:该模型引入了一种基于MTQA 的多样性问答机制,两种答案选择策略旨在整合不同的答案。此外,MRC4ERE++建议预测潜在关系的子集以过滤掉不相关的关系,从而有效地生成问题。
TriMF[10]:该模型构建了一个记忆模块来记忆实体识别和关系提取任务中学习到的类别表征,并在此基础上设计了多级记忆流注意机制,增强了实体识别和关系提取之间的双向互动。该模型在没有任何人工注释的情况下,可以通过触发传感器模块增强句子中的关系触发信息,从而提高模型的性能,使模型预测具有更好的解释性。
3.5 实验结果分析
3.5.1 模型对比实验分析
表1 中展示了本文的模型JERCE 在CoNLL04、ADE 和ACE05 数据集的主要结果。相较于基线模型,JERCE 在三个数据集上均有更好的表现。

表1 不同的模型在CoNLL04、ADE和ACE05上的实验结果 单位:%Tab.1 Experimental results of different models on CoNLL04,ADE and ACE05 unit:%
在CoNLL04 上,相较于最新的模型,JERCE 的实体识别F1值分别提升了1.81(MRC4ERE++)和1.04(TriMF)个百分点,关系抽取F1值则分别提升了1.19(TriMF)和1.13(ERIGAT)个百分点。
在ADE 上,相较于SpERT 和TriMF,JERCE 在实体识别性能上的提升有限,对比TriMF 提升了0.13 个百分点,但在关系抽取任务中有着较好的表现,F1值分别提升了1.26(SpERT)和1.14(TriMF)个百分点。同ERIGAT 相比,JERCE的实体识别任务更有优势,F1值提升了1.01 个百分点,但关系抽取提升有限。其中ERIGAT 采用了GAT,虽然可以有效提取多跳节点关系信息,但也使模型更复杂。整体而言,本文的模型要优于ERIGAT。
在ACE05 上,相较于在该数据集上有着优异表现的TriMF 和MRC4ERE++,关系抽取的提升有限,较TriMF 提升了0.44 个百分点,但JERCE 的实体识别性能提升显著,F1值分别提升了2.12(TriMF)和2.69(MRC4ERE++)个百分点。主要原因是TriMF 的触发器传感器机制更侧重于关系抽取任务,MRC4ERE++则采用问答机制的策略,对关系的预测的贡献更大;相比较而言,JERCE 通过上下文信息的增强,进一步放大了关键信息对实体识别的作用,同时改善了关系抽取任务,综合性能更好。
结合数据集的类型及模型的性能,相较于医学领域的数据集(ADE),本文的模型更适用于开放领域数据集(CoNLL04、ACE05)的联合实体和关系抽取任务。这是由于上下文的信息增强对于药物实体和副作用等专有名词的识别和分类作用有限。与上述模型相比,JERCE 通过对比学习,可以在较少语义信息的情况下实现更高的性能,表明JERCE 对实体和关系信息的提取能力较强。总之,相对比较模型,JERCE 能更有效地处理实体和关系信息。
3.5.2 消融实验分析
本文在ACE05 测试集上进行消融实验以分析不同模块的性能。
表2 展示了语义增强对实体识别和关系抽取联合任务的影响,其中:-ContextEnhanced 表示通过最大池化获取实体间上下文的表示;-SentenceEnhanced 表示直接采用BERT 模型中的[CLS]作为句子文本的语义表示;both 是通过执行以上两种消融而得到的模型。通过表2 的结果可以观察到,通过对比学习对实体间上下文以及句子的语义进行增强有助于提升实体关系联合抽取的效果;同时可以发现实体间上下文对关系抽取的影响较大,这是因为关系的大部分信息都体现在两个实体之间的内容中。
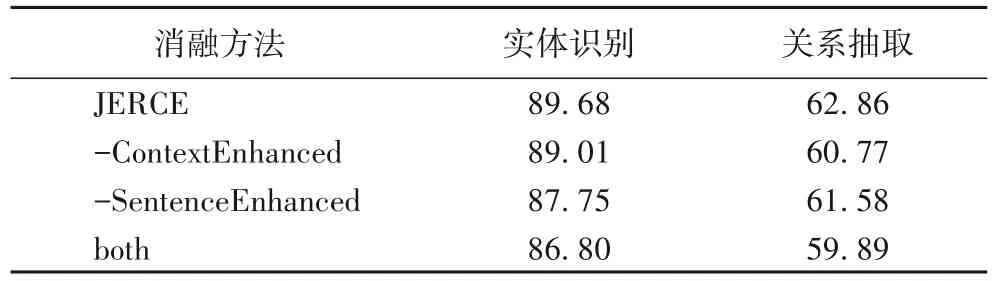
表2 语义增强消融实验的F1值 单位:%Tab.2 F1 values in semantic enhancement ablation experiments unit:%
表3 展示了通过计算加权损失进行优化的影响。本文模型结合同方差不确定性,引入了联合损失函数Ljoint来加权平衡实体识别和关系抽取两个任务的损失,-Ljoint表示在计算联合损失函数时不进行加权,而将两个任务的损失进行线性相加,即L=Ls+Lr。结果表明,通过动态加权两个子任务的损失,可以在一定程度上提升模型的性能。

表3 加权损失对模型F1值的影响 单位:%Tab.3 Influence of weighted loss on model F1 value unit:%
对比学习中的样本来自同一批次的其他句子,批量大小的值直接影响对比学习的样本数。如图5 所示,当批量小于16 时,对比学习中的负样本的数量对于模型的训练结果有着重要的作用;但该值大于16 时,效果并不明显。这是由于随着批量的增大,正负样本更为均衡,但同时过大的批量值也会在一定程度上损失模型精度。因此,本文模型将批量值设置为16,以保证模型性能的最优。

图5 批量大小对实体和关系抽取性能的影响Fig.5 Influence of batch size on entity and relation extraction performance
3.6 误差分析
本文模型JERCE 在实体识别和关系抽取方面获得了良好的结果,但通过对预测结果进行分析,发现了一些本文模型在实体识别和关系抽取中尚无法解决的错误,在此对这些错误进行总结分析,以便为后续的研究提供思路。表4 包含了在测试数据集中发现的3 种常见错误情况的示例。

表4 常见错误示例Tab.4 Common error examples
1)边界模糊:在实体识别过程中,存在无法准确获取实体边界的问题。例如表4 中“Harry Potter”为正确实体,但由于“Mr.”同人物实体的联系较为紧密,特征相似度较高,容易被一起识别。
2)逻辑错误:在关系预测中,同种类型的不同实体容易混淆。例如表4 中“David”和“Jack”均为人物实体,“David”和“Black Sea Fleet”之间的关系被预测为“Work_For”。但实际上并非“David”,而是“Jack”。这个问题在形式上是正确的,但在句中的逻辑是错误的。
3)逻辑缺失:在关系预测中,有些关系并未在句中明确表示,但可以根据上下文的逻辑推断得到。例如表4 中,Linda 代表公司发言,可以推断得出“Linda”是“Becton”公司的产品处理经理;但这在文中并未提及,因此该关系没有被预测。
4 结语
本文提出了一种对比训练的方法来增强上下文表示的联合实体和关系抽取模型JERCE。通过利用BERT 中随机掩码丢弃的特性,获得了对模型的训练更有益的正样本对,在增强文本语义的过程中取得了良好的效果。同时,本文引入同方差不确定性来对两个子任务的损失进行动态加权,提升了整体模型的表现。实验结果表明,相较于现有的模型,JERCE 在CoNLL04、ADE 和ACE05 数据集上均取得了更好的结果。但本文的模型也存在一些局限性,正如误差分析中所指出的,对实体边界的清晰度不够,同时在语义逻辑方面还有所欠缺,未来可能的工作是尝试优化边界标注策略,同时结合外部知识库增强语义理解来提升模型性能。
