基于字体字符属性引导的文本图像编辑方法
2023-05-24陈靖超徐树公丁友东
陈靖超,徐树公,丁友东
(1.上海大学 通信与信息工程学院,上海 200444;2.上海大学 上海电影学院,上海 200072)
0 引言
文字在人类的历史发展中占据了十分重要的地位,作为个体沟通与文化传承的载体,文字的出现给人类的工作与生活带来了极大的影响。随着近几年计算机视觉与深度学习的飞速发展,文字图像被越来越多的研究人员关注,其中主要的方向包括文本检测[1-5]、文本识别[6-10]、字体生成[11-13]、文本编辑[14-17]等任务。本文的文本编辑任务的应用场景包括图像隐私化处理、海报复用和视觉场景翻译等。传统的文字图像编辑方案需要执行定位文字区域、擦除原文字、输入新文字、迁移原文字风格等步骤,耗时耗力,成本较高;而基于深度学习方法的自动化文字图像编辑方法能够大幅改善这一点,并提升编辑前后的风格连贯性。文本编辑的目标是无缝将新的文本内容替换掉原图中的旧文本,并保持风格样式不变。其他文本相关任务与文本编辑也都紧密相关,如:文本识别可以评估编辑生成的文字图像的可读性,字体识别可以评估编辑生成的文本图像的字体属性的迁移效果。
本文首先在Edit-100k 测试集的1 000 组文本图像上分析了基线模型SRNet(Style Retention Network)[14]生成的编辑结果,探究该方法的特点与不足。分析实验中先使用SRNet对测试集图像进行推理,然后将推理的编辑结果与标签的前景文本区域和背景纹理区域分别进行对比。前景文本区域与背景纹理区域使用掩码进行分割。从表1 可以看出,SRNet 对文本区域的峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)与结构相似度(Structural SIMilarity,SSIM)[18]低于背景区域,从而拉低了整体的编辑结果,两项指标仅为22.91 dB 与0.79。产生这一现象的原因主要是背景区域有原始可参考的输入,而前景区域则需要由网络自主进行编辑生成。根据此分析实验,本文选择文字区域生成作为主要优化方向,通过加入字体字符属性来引导优化被编辑图像中文字字形字体的生成。
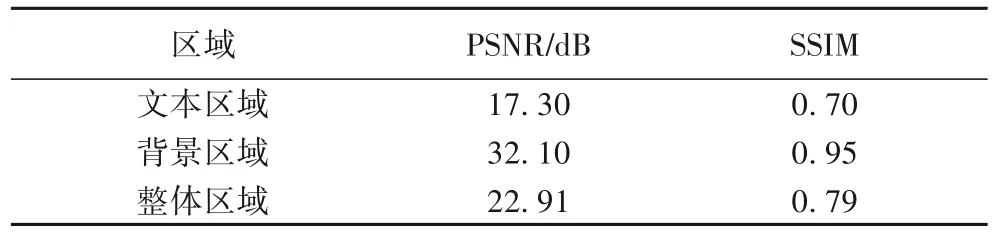
表1 编辑结果中各区域的PSNR和SSIM结果Tab.1 PSNR and SSIM of each area of edited results
本文提出的基于文字属性引导的文本编辑方法使用文字与背景分离处理的分阶段模型进行编辑生成,利用文本识别与字体识别的模型辅助文本编辑模型进行训练,对特征提取过程中的文字内容特征与字体属性特征进行相应的引导。实验中本文方法所编辑的图像结果在PSNR、SSIM 与均方误差(Mean Squared Error,MSE)指标上都明显优于SRNet,同时在可视化效果的对比上也修正了一些SRNet 编辑结果的伪影瑕疵。本文还提出了一个用于文本编辑训练的合成数据集Edit-100k,其中训练集包括10 万组成对的有监督文本图像数据,测试集包括1 000 组文本图像。
1 相关工作
在基于深度学习的文本编辑方法出现之前,相关研究的重点主要聚焦于更简单的文本图像移除与修复。Zhang等[19]提出的EnsNet(Ensconce Network)使用了一个加入跳跃连接的生成器和局部预测的判别器的结构,能够自动去除自然场景图像中的文本内容,并将文本区域替换为合理的背景图像。Liu 等[20]又提出了一个由粗到精的两阶段网络,同时利用一个额外的分割头预测文本区域辅助文本擦除的效果,使擦除区域与擦除效果更准确。
文本编辑任务相当于在文本擦除的基础上添加新文本替换的任务,集文本替换、文本擦除、背景修复于一体。端到端可训练的编辑模型SRNet[14]分别用两个编码器提取文字的风格与内容特征进行聚合,并与背景纹理融合得到最后的结果;但该方法对于复杂文本图像的编辑会存在伪影效果或字符误 差。Yang 等[15]提出的 文本替 换方法SwapText 在SRNet 的框架基础上添加了文本几何变换网络(Content Shape Transformation Network,CSTN)来分离前景文本替换中的几何变换部分,并添加了自注意力模块替代简单的通道拼接作为特征聚合方式,提升了弯曲文本的文本编辑效果;同时该方法还在背景修复网络中加入了扩张卷积增大修复时的感受野,使背景细节在纹理上有更多保留。Roy 等[16]提出了基于字体适应性神经网络的场景文本编辑器(Scene Text Editor using Font Adaptive Neural Network,STEFANN),分为字体适应性神经网络(Font Adaptive Neural Network,FANNet)和颜色网络(Color Network,ColorNet)两部分,分别对文字的字体几何特征和颜色纹理特征进行迁移;但该方法只针对前景文本使用深度学习模型进行生成,文本擦除、修复等模块依赖于其他算法效果。Shimoda 等[17]提出了一种将文本图像进行参数化,预测出文本位置、颜色、字体、字符、背景等渲染参数的方法。该方法在训练中通过渲染参数实现文本图像的重建,并通过修改渲染参数实现文本图像的编辑;该方法编辑自由度很高,但并不能完全保留原有图像的风格信息实现无缝编辑。
2 多属性引导的文本编辑
本文提出的基于字体字符属性引导的文本编辑方法首先利用分阶段的文本编辑模型框架将整个任务分解为前景变换、背景修复和前背景融合。其中,前景变换网络完成原图前景文本内容的位置定位、几何字体特征和颜色纹理特征的迁移。文本编辑网络的输入(Is,It)如图1 所示。

图1 网络的输入图像Fig.1 Input images of network
从图2 中可以看到,前景变换网络会通过两个编码器对Is和It分别进行风格特征和内容特征的提取,然后将两者在通道维度进行合并,并通过两个解码器分别输出骨架图Osk以及迁移原图文本风格的新文本图像Ofg。背景修复网络完成原图中文本内容的自动擦除以及背景修复的任务。背景修复网络的输入只有Is,通过一个带有跳跃连接的U-Net 生成器输出纯净背景Obg。而最后的前背景融合网络负责将前两个子网络输出的前背景图像通过融合网络结合为最后的结果。前背景融合网络还将背景修复网络中的各尺度解码器特征图加入融合网络中的解码器,使最终的编辑结果Ofus在细节纹理上更丰富。而最后的输出图像也会通过字体字符分类器与相应损失函数约束,利用字体字符属性来引导生成网络方向保证正确的编辑效果。

图2 文本编辑网络框架Fig.2 Text editing network architecture
2.1 前景变换网络
前景变换网络的主要目的是替换原始文本图像中的文本内容,同时保持原有的文字风格样式。网络的输入是原始待编辑图像Is和新的文本内容的图像It。It是标准范式文本图像,具有固定字体与背景。前景变换网络总体上使用了多输入多输出的编码器/解码器结构。为了提取出文本风格特征和内容特征,原始图像Is和文本内容图像It都被由三层下采样和残差卷积块构成的编码器进行编码。两个编码器共享相同的结构,但并不共享参数,分别用来提取图像中的文本风格与文本内容特征。经过编码后的文本风格特征与新文本内容特征会在通道层面进行合并,聚合风格与内容特征。聚合后的特征会通过一个由三层转置卷积作为上采样层的解码器进行解码。前景变换网络的计算过程如式(1)所示:
其中:Gfg表示前景变换网络;Ofg是前景变换网络输出的新文本图像。
由于文字骨架代表了文字的具体语义信息,因此另一个解码器输出单通道的骨架掩膜图Osk,使生成的新文本图像在文字可读性上有更好的效果。骨架损失函数Tsk使用集合相似度度量函数约束单通道骨架图的生成,如式(2)所示:
其中:Osk和Tsk分别表示网络解码的单通道骨架图和骨架图标签;N代表骨架图中的像素点个数。骨架图还被加入前景变换网络的输出模块中,辅助前景变换的新文本图像Ofg生成。前景变换网络的最终损失函数包括骨架引导损失以及像素点级的L1 损失,如式(3)所示:
其中:Ofg和Tfg分别代表网络输出的文本变换结果和标签图像;α是骨架损失的参数,训练中设置为1.0。
前景变换网络的输入输出可视化如图3 所示,该网络实现了对原图中的文字风格样式在新文本上的迁移。

图3 前景变换网络输出可视化Fig.3 Visualization of foreground transformation network
2.2 背景修复网络
背景修复网络的任务是完全擦除原图中的文本,并对擦除的空白区域填充合适的纹理颜色,最后输出纯净的背景图像。空白区域填充的可视化如图4 所示。

图4 擦除区域填充可视化Fig.4 Filling visualization of erased region
图4(a)的文本图像区域像素点被擦除后仍旧留有空白,需要合适的纹理进行填充。背景修复网络的输入是原始待编辑图像Is,输出纯净背景图像Obg。该网络采用了带有跳跃连接的U-Net[21]结构,有助于网络保留空间下采样过程中丢失的背景细节信息。输入图像由3 个下采样卷积层进行特征编码。由于背景修复的本质是借鉴其他区域颜色纹理填充空白区域,所以更大的感受野可以使网络获取更丰富的信息,生成效果更接近真实。因此编码器后接3 个扩张率分别为(2,4,8)的扩张卷积[22]用于扩大感受野,提升纹理信息的参考区域范围。然后,扩张卷积的输出特征通过三层上采样的转置卷积模块进行解码得到修复后的纯净背景输出Obg。如果用Gbg表示背景修复网络,生成过程如式(4)所示:
背景修复网络还通过一个判别器进行对抗训练,以得到外观上更加真实的结果。总体的损失函数是由判别器的对抗损失和像素点级的L1 损失组成,如式(5)所示:
其中:Obg和Tbg代表网络生成的纯净背景图像和标签图像;Dbg是背景修复判别器;β是像素点级损失权重,设置为10。
背景修复网络的输出可视化如图5 所示,从相邻的背景中学习到了合适的纹理颜色,并填充到文字擦除后的空白区域。

图5 背景修复网络输出可视化Fig.5 Output visualization of background inpainting network
2.3 前背景融合网络
前背景融合网络的任务是融合前景变换网络和背景修复网络的输出,生成最终的文本编辑结果。融合网络是一个编码器/解码器的结构。其他子网络输出的文本变换图像Ofg和纯净背景图像Obg被送进融合网络中,并输出为文本编辑结果Ofus。该子网络的编码器与解码器结构与其他子网络相同。不同的是,解码器每层都会结合背景修复网络中的各尺度解码特征。因此,融合网络可以补全编码器阶段丢失掉的背景细节信息,得到更好的生成效果。融合网络的生成过程如式(6)所示:
其中:Gfus表示前背景融合网络;featbg表示背景修复网络的各尺度解码特征。融合网络的损失函数如式(7)所示:
其中:Ofus和Tfus分别代表文本编辑结果和标签图像;Dfus是用于前背景融合网络对抗训练的判别器;γ是像素点级损失的超参数,设置为10。
前背景融合网络的输出可视化如图6 所示,该网络融合前一阶段子网络的前背景输出结果得到最终的编辑结果。

图6 前背景融合网络输出可视化Fig.6 Output visualization of foreground and background fusion network
2.4 字体属性损失
文字的字体类别属性代表了文字的风格样式。在文本编辑任务中,最重要的任务之一就是原图文字风格样式的迁移。本文提出了一个字体属性的引导分类器,通过字体属性引导生成网络的特征提取,提升编辑前后文字风格样式的一致性。
字体分类网络的特征提取是ResNet(Residual Network)[23]结构。本文首先利用字体分类数据集以交叉熵损失对字体分类器进行预训练,并冻结参数作为文本编辑网络的属性辅助引导。字体属性损失Lfont如式(8)所示,包括字体分类损失Lcls、字体感知损失Lper与字体纹理损失Ltex。
字体分类损失Lcls使用内容输入的文本字体标签与分类器预测结果构建,使用交叉熵损失进行约束,引导编辑模型结果的文字字体风格与原图风格接近。Lcls如式(9)所示:
其中:N代表训练批的大小;M为字体类别数量;yi,c指一个训练批中的第i张图对于M个字体类别中的第c个类别的标签;pi,c指一个训练批中的第i张图对于M个字体类别中的第c个类别的预测置信度概率。
本文使用字体分类器的各尺度特征构建字体感知损失Lper,衡量生成器迁移文本字体样式的能力。在Lper的计算中,将字体分类网络每个下采样阶段的输出激活图作为文本特征级差异的衡量。Lper如式(10)所示:
其中:φi代表字体分类器的第i阶段特征激活图。
本文使用gram 矩阵(偏心协方差矩阵)的L1 距离来衡量特征图的空间相关性差异,如式(11)所示:
其中:代表字体分类网络的各阶段特征图计算gram 矩阵的空间相关性的结果。
2.5 字符属性损失
文本编辑不仅需要维持编辑前后文字风格样式的一致性,还要确保新文本内容生成的可读性。字符类别属性代表文字的语义内容信息。本文使用预训练的字符识别模块引导最终文本图像的编辑过程。通过字符内容属性引导,输出图像可以减轻文本伪影,并修正编辑过程中的字符生成误差。
本文采用的字符分类网络基于TRBA(Tps-Resnet-Bilstm-Attention)[24],主要网络结构包括四个部分:文本矫正模块、特征提取模块、序列建模模块和字符预测模块。其中:文本矫正模块使用薄板样条(Thin Plate Spline,TPS)插值,可以将非水平的文本字符进行水平矫正,更适用于网络的识别;特征提取模块使用ResNet,能够提取出输入文本图像的视觉特征;序列建模模块则使用了双向长短期记忆(Bidirectional Long Short-Term Memory,BiLSTM)[25]网络结构,对文本图像前后字符进行上下文序列特征提取;字符预测模块使用注意力解码模块,对前面得到的视觉特征和序列特征进行解码,预测出对应位置的字符类别。字符分类损失可用式(12)表示:
其中:N代表图像中预设的字符最大长度;M代表字符类别的个数;yi,j和pi,j分别代表第i个字符对于第j个字符类别的标签与预测的类别置信度。
2.6 实现细节及训练策略
为了使图像在生成过程中更加逼真,本文使用了基于局部区域的生成对抗网络(Patch Generative Adversarial Network,Patch GAN)[26]判别器。判别器的网络结构由4 个下采样步长为2 的卷积块和一个步长为1 的卷积块组成。输入图像大小为64×256 时,最终的输出预测图大小为8×32。其中每一个预测值代表原图中一个16×16 的局部区域,用来衡量这个局部区域编辑效果真实程度。相较于一般判别器,使用基于局部区域的判别器能够在局部区域细节上生成更真实的效果。
本文模型是分阶段的文本编辑模型,分为三个子模型。因此本文方法在训练过程中先对前景文本变换网络和背景修复网络分别进行训练优化;然后用前两个网络参数固定训练前背景融合网络,并以字体字符分类器的属性引导进行编辑效果精炼优化;最后,整个文本编辑网络进行端到端训练微调后得到最优的结果。本文训练数据集Edit-100k 通过真实数据集的颜色纹理库和常用字体进行合成。训练中输入图像的大小为64×256,训练批大小为64,网络训练的初始权重都是以零均值的正态分布进行初始化。使用Adam 优化器[27],学习率设置为0.000 2,指数衰减率β1=0.9,β2=0.999。所有实验均在PyTorch 框架上实现。
3 实验与结果分析
3.1 数据集与评估指标
合成数据集Edit-100k:由于文本编辑网络在训练过程中需要成对的有监督训练数据,而现实中很难获取到相应的成对数据,所以本文的编辑模型在训练过程中使用Edit-100k作为训练数据。Edit-100k 合成数据集的合成流程:1)从语料库中随机获取一对文本内容作为原始图像的文本和编辑替换的目标文本;2)随机选择字体、颜色纹理、背景和几何变形参数等,合成出成对的训练数据。背景选择不仅包含纯色背景,还包含场景图像。为了使合成图像更接近真实域,本文还对训练图像进行数据增强,包括高斯模糊、动态模糊、重采样等,模拟现实的外部场景与特殊条件。
真实数据集:ICDAR 2013[28]是一个自然场景文本数据集,包括229 张训练图像和233 张测试图像。每个图像中的文本都有一个或多个文本框作为文本检测区域的标签以及相应框内文本内容的标签。本文在该数据集上进行可视化效果的对比实验。
在文本编辑任务中,本文沿用图像生成中常用的PSNR、SSIM 和MSE 指标作评估,计算公式分别为:
其中:x和y分是别标签图像和生成的图像;μx、μy分别是x、y的平均值;σx、σy分别是x、y的标准差,σxy是x和y的协方差;c1=(k1L)2和c2=(k2L)2是用来维持稳定的常数,L是像素值的动态范围,k1=0.01,k2=0.03。
更低的MSE 或者更高的PSNR 和SSIM 表示编辑模型性能更好。本文仅在Edit-100k 上评估各生成指标,因为真实文本数据集没有成对文本图像数据可供计算;而在真实数据集可以通过可视化对比来评估编辑图像的质量。
3.2 消融实验
消融实验主要集中在以下几个模块:字体分类器、字符分类器、端到端微调训练策略。图7 展示了消融实验的可视化结果,可以看到,相较于原始的基线模型SRNet,模型在增加了字体分类器的辅助引导之后对于文字的风格样式上与原图更加接近;而在加入了字符分类器的引导之后,原本字形生成不够精确的字符都被引导生成为更正确的字符形状,例如第一列中“C”、第二列中的“r”、第四列中的“m”;最终对整体网络端到端微调优化后也对编辑效果有一定提升,例如第三列中的“H”。

图7 消融实验的可视化结果Fig.7 Visualization results of ablation study
消融实验的量化评估结果如表2 所示,其中:√表示加入对应的模块,×则表示未加入;Δ 则表示每增加一个模块相对上一模块的结果之差。可以看到,本文方法的PSNR、SSIM和MSE 分别为25.48 dB、0.842 和0.004 3,相较于基线模型SRNet,PSNR、SSIM 分别提升了2.57 dB、0.055,MSE 降低了0.003 1,每一个模块的加入都提升了模型的效果。

表2 消融实验的量化评估结果Tab.2 Quantitative evaluation results of ablation study
3.3 对比实验
与现有方法进行对比的量化评估结果如表3 所示。与本文方法采用相同模型框架的SwapText 主要是在SRNet 的框架上加入了控制文本几何变形的CSTN 模块以及聚合内容与风格特征的自注意力机制。相较于SwapText,本文方法在三个指标上表现也更好,PSNR 和SSIM 分别提升了2.11 dB和0.046,MSE 下降了0.002 4。
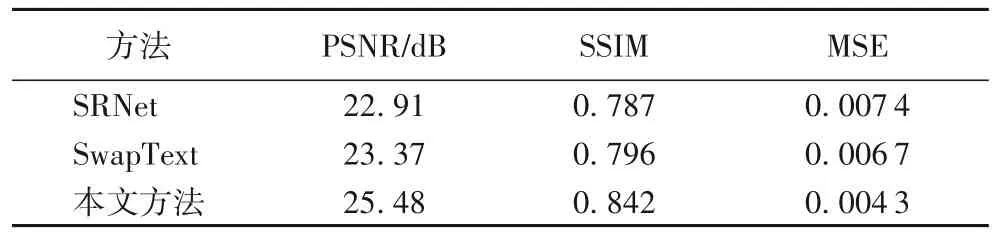
表3 对比实验量化评估结果Tab.3 Quantitative evaluation results of comparison experiments
3.4 场景文本图像编辑可视化
由于本文中的编辑模型主要针对单文本图像编辑,但真实场景图像大多包含多个文本实例,因此场景文本图像编辑需要先使用上游文本检测方法对各文本实例进行检测,然后再选择编辑的文本实例和新的文本内容,并将两者一同输入文本编辑模型中进行生成。本文使用的文本检测模型是微分二值化网络(Differentiable Binarization Network,DBNet)[5],主要是因为DBNet 不仅可以达到具有竞争力的检测性能,同时还能拥有较快的检测速度。
在图8 中可以看到,本文方法在ICDAR2013 数据集的真实场景文本图像上准确地完成了文本编辑操作,无缝将新的文本内容替换掉原图中的旧文本,并保持风格样式不变,甚至保留了各自场景的光照与模糊效果。

图8 自然场景文本图像的可视化结果Fig.8 Visualization results of text images in nature scenes
4 结语
本文提出了一种利用字体字符类别属性引导的分阶段文本编辑网络,将复杂有挑战性的文本编辑大任务分解为三个任务:前景文本变换、背景修复和前背景融合。同时,结合字体字符分类器引导,本文方法不仅维持了编辑前后文字风格样式的一致性,而且提升了新文本生成的可读性,解决了文本伪影与文字误差的问题。本文还针对分阶段的文本编辑网络设计了对应的训练策略,进一步提升了模型的编辑效果。实验中,本文方法的评估指标与可视化效果都优于SRNet 和SwapText。在未来的工作中,希望解决更加复杂极端的文本图像编辑任务,例如极端光照、模糊、立体效果的文字图像,完成对任意文本图像场景的编辑。此外,也将探索使用其他文本图像属性更全面地引导文本编辑任务。
