基于图注意力网络的全局图像描述生成方法
2023-05-24隋佳宏毛莺池于慧敏王子成
隋佳宏,毛莺池,2*,于慧敏,王子成,平 萍,2
(1.河海大学 计算机与信息学院,南京 210098;2.水利部水利大数据重点实验室(河海大学),南京 210098;3.中国电建集团昆明勘测设计研究院有限公司,昆明 650051)
0 引言
图像描述生成是一项涉及计算机视觉和自然语言处理的跨领域研究任务,目标是为输入图像自动生成自然语言描述,主要包括视觉理解和描述生成两部分。在深度学习广泛应用之后,图像描述生成的视觉特征表示经历了两个主要阶段:在第一阶段,提出了一系列卷积神经网络(Convolutional Neural Network,CNN)[1-4],从中提取固定大小的网格特征表示视觉信息,如图1(a)所示,这些网格特征在图像分类等视觉任务和图像描述生成等多模态任务中取得了优异的性能;在第二阶段,基于Faster R-CNN(Faster Region-Convolutional Neural Network)[5]提取的区域级特征显著提高了图像描述生成的性能,如图1(b)所示,此后区域特征被广泛研究[6-10],并成为大多数视觉-语言任务的标准方法。然而,区域提取非常耗时,目前大多数使用区域特征的方法都直接在缓存的视觉特征上进行训练和评估。此外,区域特征的固有缺点是忽视图像中非目标的区域(如背景信息)以及大目标的小细节。

图1 网格特征与区域特征Fig.1 Grid features and region features
然而,与目标检测器提取的区域特征相比,单个网格不能完全表示一个对象,它的语义层级较低,一旦忽略了图像的全局信息,就丢失了潜在的场景级语义上下文。例如,图2(a)的正确分类应是图2(b),而在仅存局部信息的情况下,图2(c)中将大部分图像误分类为鸟;在特征中添加整个图像的上下文信息(可能包含猫的强信号)后结果如图2(d)所示,可以捕捉全局背景,纠正错误,有效提高任务准确度。
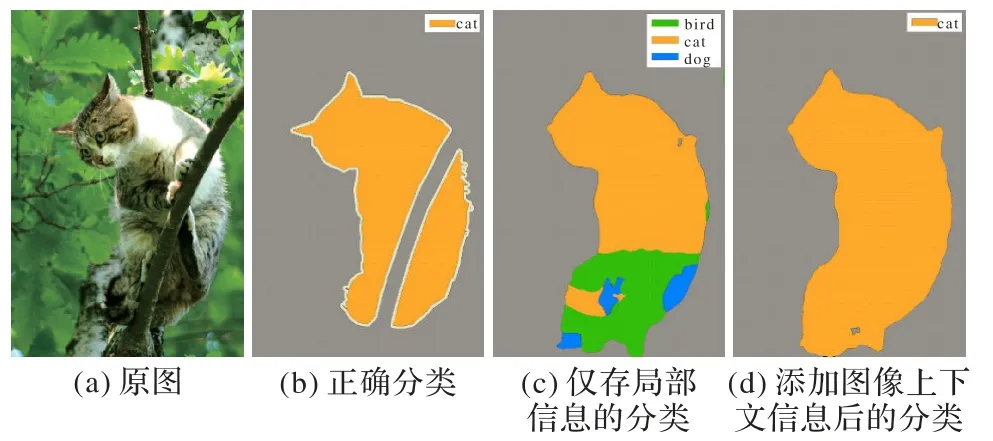
图2 图像分类结果比较Fig.2 Comparison of image classification results
现有的研究焦点是通过注意力机制(Attention)建模视觉和语言特征之间的相互作用,以获得更加丰富可靠的图像描述。虽然将Attention 引入基于长短期记忆(Long Short-Term Memory,LSTM)网络的解码器可以使LSTM 在描述生成过程中关注最相关的图像特征,但是没有充分利用图像特征之间的交互关系。图注意力网络(Graph ATtention network,GAT)常用于处理图结构数据,可以根据相邻节点的特征为图中的每个节点分配不同的权值,更新节点的表示,但仅处理局部网络。
本文利用网格特征作为图像描述生成方法的主要视觉表示,针对网格特征丢失空间和语义上下文信息,提出一种基于图注意力网络的全局图像描述生成方法,在提取图像特征时添加了全局上下文,将视觉特征提取转化为节点分类任务,以提高描述准确度。首先,为了充分利用网格之间的特征关系,构建网格特征交互图;其次,为了利用图像的全局特征,构建图注意力网络结合全局信息和局部信息;最后,将优
化后的视觉特征输入语言模型,用于图像描述生成。本文的主要工作包括:
1)构建网格特征交互图。在特征提取过程中对网格视觉特征进行融合编码,将特征提取任务作为图节点分类任务实现,能在不增加计算开销的同时提高性能。
2)利用图注意力网络更新网格特征交互图的节点信息,使模型可以捕捉整幅图像的全局视觉信息,并捕获网格特征的潜在交互,加深模型对图像内容的理解,从而生成优化的描述语句。
3)为探究本文方法的优势以及各模块的贡献,在Microsoft COCO 图像描述数据集上进行了实验与评估,通过详细的结果分析说明了本文方法的有效性。
1 相关工作
在视觉表示方面,基于区域的视觉特征[6]已成为图像描述生成、视觉问答等视觉-语言任务的主要方法。最近,Jiang 等[11]重新考察了视觉特征,发现区域特征效果更好的原因是使用了Visual Genome 数据集[12],大规模的对象和属性标注给图片提供了更好的先验知识,并证明了通过改造区域特征检测器[5]提取出来的网格特征,在后续任务中的推理速度和图像描述生成的准确度堪比甚至超过区域特征,而且避免了区域特征的固有缺点。为了更好地使用网格特征作为图像描述生成方法的主要视觉表示,Zhang 等[13]提出了网格增强(Grid-Augmented,GA)模块,该模块将相对位置之间的空间几何关系合并到网格中,解决将网格特征展平输入Transformer 模型时造成的空间信息丢失问题,以便更全面地使用网格特征。然而空间关系特征对图像或目标的旋转、反转、尺度变化等比较敏感,实际应用中,仅仅利用空间信息往往不够,不能准确有效地表达场景信息,还需要其他特征配合。Luo 等[14]进一步提出同时使用图像子区域和网格[11]两种视觉特征生成描述文本,旨在利用两种特征之间的互补性,并提出了局部约束注意力机制解决两种特征源之间的语义噪声问题;然而,两种特征互补的效果不如只使用区域特征的方法,也减弱了网格特征耗时短的优势。
为了进一步增强图像特征表示,一些研究通过在图像区域上构建图,将丰富的语义信息和空间信息连接到区域特征。Yao 等[15]首次尝试构建空间和语义图,随后Guo 等[16]提出利用图卷积网络(Graph Convolutional Network,GCN)[17]整合对象之间的语义和空间关系,语义关系图通过在Visual Genome 上预训练分类器来预测对象对之间的动作或交互,空间关系图通过对象对的边界框之间的几何度量来推断(如交并比、相对距离和角度),然而这些方法针对区域特征,并不适用于附加全局信息的网格特征。Yao 等[18]使用树来表示图像的层次结构,根节点表示图像整体,中间节点表示图像区域及其包含的子区域,叶节点表示区域中被分割的对象,然后将树送入TreeLSTM[19]中得到图像特征编码,但该方法没有考虑到子区域之间的交互关系。以上方法均无法充分利用网格特征的细节信息,同时忽略网格之间的交互以及全局特征会导致生成的描述受到错误的影响。对于交互特征的获取,现有方法直接将网格特征序列输入Transformer 的编码器,利用带残差连接的多头自注意力机制(multi-head attention mechanism)自动进行特征交互,通过自注意力的方式计算每个特征与其他特征的相似度,加权求和得到高阶的交互特征。本文采用构建网格特征交互图的方式,将特征作为图的节点,使用注意力网络聚合邻居节点的信息,以此将特征之间的复杂交互转化为特征图的节点之间的交互。对于一幅网格数为N×N的图像,Transformer 编码器的交互次数为N×N,网格特征交互图的交互次数为4 ×N,在实际操作中N=7,基于图的特征交互并没有增加计算开销,但是在性能方面有了显著提高。
综合以上分析讨论,网格特征作为图像描述生成的视觉表示具有一定的优势,引入全局特征指导优化更新网格特征可提高视觉表示的准确性。但传统的注意力机制不能满足网格特征复杂的交互关系,同时在整合全局图像信息方面也存在一些问题,因此,本文提出基于图注意力网络的全局图像描述生成方法借助全局图像特征增强视觉表示能力,利用图注意力网络将相邻的网格特征和全局特征相结合进行信息提取,以有效地捕获全局上下文信息和局部信息,然后解码相应描述。
2 本文方法的总体框架
图像描述生成的目标是能够识别并给出描述图像内容的自然语言语句。目前,提取图像的网格特征存在未充分利用空间关系特征和全局特征的情况,致使利用提取的图像特征生成的句子和人类描述存在明显差距,因此,增强网格特征的空间信息和语义信息对提高生成描述的质量具有重要的研究意义。本文提出了一种基于图注意力网络的全局上下文感知图像描述生成方法,由特征提取和特征交互两部分组成,用于增强网格特征。特征提取通过图中的全局节点机制充分利用全局上下文关系,整合图像中各个网格的局部视觉特征,以此优化生成的单词表示;特征交互依据网格特征交互图和图注意力网络,进一步建模图中邻域的空间上下文信息及其关系,更新节点特征,提高节点分类的准确性。
图3 展示了本文方法的总体框架。在视觉编码阶段,首先,特征提取模块利用多层CNN 分别提取给定图像的全局特征和网格特征;之后,构建网格特征交互图,将全局和局部视觉特征作为节点输入,图中的边表示视觉特征之间的交互,所有局部节点均与全局节点相连接;最后,利用图注意力网络更新优化网格特征交互图中的节点信息,得到新的全局图像特征和网格特征。描述生成阶段,基于Transformer 的解码模块利用更新后的视觉特征序列生成图像描述。本文方法侧重于增强网格特征来优化视觉表示,进而提高生成描述的质量。

图3 方法总体框架Fig.3 Overall framework of method
3 图像描述生成框架描述
3.1 视觉网格特征编码
相对于整张图像来说,图像的网格特征包含更细粒度的各类目标,对细粒度目标相关的图像内容进行编码无疑会优化图像编码,得到更具体、更精准的图像特征表示。然而网格特征的局部感受野较小,卷积神经网络只能学习到目标的局部特征,缺乏空间和全局信息。基于此,本文在融合各网格特征的基础上加入特征图的全局信息,提出一种具有全局特征的图像编码模块,该模块负责提取图像的全局特征和局部特征,如图3 中虚线框所示。
本文以与文献[11]中相同的方式提取图像的原始网格特征。具体来说,利用在Visual Genome 数据集上预训练的Faster R-CNN 模型[5],它使用步长(Stride)为1 的普通卷积层C5和带有两个全连接(Fully Connected,FC)层的1×1 兴趣区域池化(Region of Interest Pool,RoIPool)作为检测头,其中C5层的输出保留为描述生成模型的视觉网格特征。因此,本文方法给定一组固定大小的图像网格Grids=(p1,p2,…,pn)和整幅图像p0=full_image,提取的图像嵌入如式(1)所示:
其中:IE0:n=[IE0,IE1,…,IEn]∈Rn×dmodel表示输出的图像嵌入,dmodel表示模型的尺寸,IEi表示CNN 模型的第i个输出,n表示网格的个数;p0:n表示输入的图像部分,p0表示图像的全局信息,pi∈RH×W×3表示图像的第i个网格,H表示网格的高度,W表示网格宽度;ΘCNN表示CNN 模型的参数。每个图像和网格都是独立编码的,可以使用多个CNN 同步得到全局图像嵌入和局部图像嵌入,不需要额外的训练、推理时间,提高了计算效率,如式(2)、(3)所示:
3.2 网格特征交互图建立
在3.1 节得到的图像嵌入基础上增加全局图像特征,然后引入网格特征之间的依赖关系和全局图像特征,借助全局节点机制建立网格特征交互图,构建过程如图4 所示。
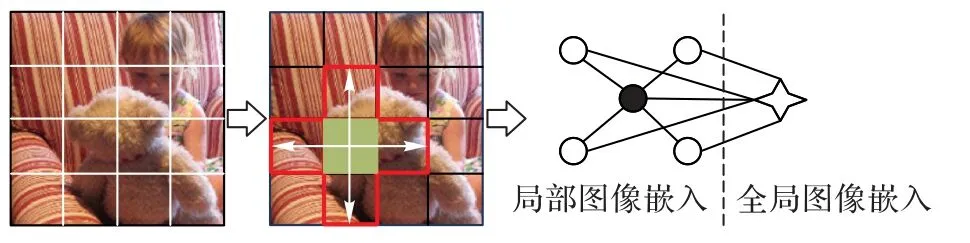
图4 网格特征交互图构建(与邻近4个网格进行交互)Fig.4 Construction of grid feature interaction graph(interact with 4 neighboring grids)
整个图像被转换成无向图G=(V,E),其中:V是节点集合,代表所有网格特征(圆形表示,深色圆形表示正在进行交互)和一个全局特征(四角星形表示);E是边集合,代表两个视觉特征之间的交互;邻接矩阵A∈RN×N是一个N×N的二元矩阵,表示图中节点和边的信息。给定图像的全局和网格特征,首先,根据网格的相对中心坐标为两个相邻的网格i和j建立连接,即将矩阵A中(i,j)的值赋为1,表示直接交互。此外,提出全局节点机制,用于捕获远程依赖关系和全局特征。
全局节点用作虚拟中心,与图中的所有节点连接,从局部节点中收集并分发通用信息。因此,每两个非相邻的局部节点间存在两跳路径的间接交互,与全局节点提供的通用信息相结合,可提供更丰富的交互特征。
3.3 基于网格特征交互图的图注意力网络
本文采用网格特征来生成图像描述,和区域特征相比,网格之间的依赖关系更加复杂紧密。图注意力网络已成功应用于图像描述生成任务中,Zheng 等[20]结合图网络和图像描述生成的自注意力机制计算区域级图像特征的权重,此外,还使用了多头注意力机制,保证注意力机制的稳定性,在一定程度上可以减少噪声,获得更好的效果。但是针对网格特征,图注意力网络对所有网格计算自注意力非常耗时,而且由于网格特征的语义层级较低,需要全局特征指导。
根据上述问题,结合网格特征交互图和图注意力网络,本文提出了基于网格特征交互图的图注意力网络(Grid-Graph ATtention network,G-GAT),如图5 所示,G-GAT 中图的节点与图像的网格相对应,节点的特征为局部图像嵌入,图的边对应网格特征交互图的边,并且利用多头自注意力机制对网格特征交互图中相邻节点的视觉信息进行融合更新,全局节点和局部节点采用相同的方式,从而得到具有全局上下文感知的网格特征表示,进一步增强视觉特征提取效果。
每个G-GAT 的输入是网格的特征表示h=(h1,h2,…,hn)(hi∈RF)及邻接矩阵A,其中:n表示网格个数,F为隐藏层输出的特征维度。然后应用图注意力网络进行视觉信息融合,将网格i和j的特征向量相连接,通过带泄露修正线性单元(LeakyReLU)的非线性层得到eij,对每个网格进行自注意力计算,如式(4)所示:
其中:eij表示网格j的特征对于网格i的重要程度;V和W均为可学习的参数矩阵;⊕表示连接。然后使用Softmax 函数对网格i的所有邻域网格特征进行归一化操作,得到注意力系数αij,使系数在不同节点之间易于比较,如式(5)所示:
其中:Ni表示网格i在网格特征交互图中所有的一阶邻域节点集合(包括i本身)。之后将网格i的所有相邻网格j的特征与对应的权重系数αij进行加权求和,通过非线性层σ得到每个对象节点的最终输出特征,如式(6)所示:
为了提高方法的性能,将上述方法扩展到多头自注意力机制[21]。
3.4 解码与损失函数
本文与已有图像描述生成方法[13-14]采用相同的训练方式,基准解码模块和优化解码模块的训练都分为两个阶段:-XE*阶段和-RL*阶段。其中:-XE*优化基于负对数似然估计的损失函数,等价于交叉熵损失函数XE(Cross Entropy);-RL*阶段基于强化学习(Reinforcement Learning,RL)的优化策略,将CIDEr(Consensus-based Image Description Evaluation)得分作为奖励函数。
其中:pθ表示解码模块的预测概率。
实际训练中,以批(Batch)为单位进行模型的权重更新,如式(8)所示:
其中:N是批的规模。
在-RL*阶段,基于负对数似然估计损失函数的训练之后,现有方法采用自批判序列训练(Self-critical Sequence Training,SCST)策略[22],以CIDEr 评分作为奖励对模型进行继续优化,如式(9)所示:
其中:r(·)为基于CIDEr 评分定义的原始奖励。本阶段的优化目标是最小化负期望奖励,使用文献[23]中的梯度表达式,即使用奖励的平均值而不是贪婪采样得到的奖励。奖励的梯度更新如式(10)~(11)所示:
其中:k为采样序列的个数为解码模块在推理算法下随机采样所得到的描述;b为采样序列获得的奖励的均值。
4 实验验证
4.1 实验准备
4.1.1 数据集和评价指标
Microsoft COCO 图像描述数据集(以下简称MSCOCO)[24]是当前最大的图像描述生成数据集,包含123 287 张图像,每张图像至少包含5 句英文标注。在实验中,采取通用的数据集划分方法[25],将训练集与验证集合并,由验证集中取出10 000 张图像,其中5 000 张用于模型验证,5 000 张用于模型测试,所有剩余113 287 张图像用于模型训练。数据预处理阶段,将所有描述文本中的词转换成小写形式,并用特殊字符“UNK”标记替换出现次数少于等于5 的词。
本文采用公开的COCO 评测工具包1 来计算指标评分,所涉及的评价指标为现有方法统一使用的指标组合,包括:BLEU(BiLingual Evaluation Understudy)[26]、METEOR(Metric for Evaluation of Translation with Explicit ORdering)[27]、CIDEr[28]、ROUGE-L(Recall-Oriented Understudy for Gisting Evaluation-Longest common subsequence)[29]和 SPICE(Semantic Propositional Image Caption Evaluation)[30]。
4.1.2 实验设置
本文方法采用与文献[11]中相同的特征提取方法,即改造预训练Faster R-CNN 模型的检测头来提取图像网格特征,网格尺度为7×7,每个图像特征维度为2 048。本文实验遵循Transformer 模型[23]的超参数设置,模型维度dmodel=512,多头注意力机制头的个数K=8。实验使用Dropout 算法防止模型过拟合,丢失率设置为0.1。实验基于PyTorch 框架并用Adam 梯度优化算法[31]进行梯度更新。模型训练分为两个阶段:在-XE*训练阶段,以初始学习率1 × 10-4训练18 轮,其中每3 个周期衰减一次,衰减率为0.8,优化对数似然估计损失函数,批规模设置为50;在基于强化学习策略的训练阶段-RL*,以固定学习率5 × 10-6训练25 轮,批规模设置为100。推理阶段,设置集束大小为5。注意,消融实验中的所有实验采用相同的超参数设置。
4.2 实验结果与分析
4.2.1 性能对比分析
为验证本文方法的有效性,与下列方法进行比较,其中:SCST[22]、Up-Down[6]和RFNet(Recurrent Fusion Network)[32]为基于注意力机制的方法;GCN-LSTM[15]和SGAE(Scene Graph Auto-Encoder)[33]在图像描述任务中引入场景图信息实现图像的丰富语义表示;ORT(Object Relation Transformer)[7]对区域特征之间的空间关系进行建模;AoA(Attention on Attention)[8]对自注意力模块进行扩展来设计描述生成模型;M2(Meshed-Memory transformer)[23]构造用于解码的网状连接网络结构;X-Transformer[34]在Transformer 的注意力模块中引入双线性池;GET(Global Enhanced Transformer)[9]采用上下文选通机制来调节全局图像表示对每个生成单词的影响;CPTR(CaPtion TransformeR)[35]为图像描述生成设计了第一个无卷积架构。
表1 展示了本文方法与对比方法在MSCOCO 分割数据集上的结果,其中:最佳指标以加粗标注;“—”表示未报告指标;B1 和B4 是BLEU-1 和BLEU-4 的简称。

表1 不同方法在MSCOCO分割数据集上的性能指标比较 单位:%Tab.1 Comparison of performance indicators of different methods on MSCOCO dataset unit:%
从表1 可知,相较于对比方法,本文方法在METEOR 和CIDEr 指标上均得到最佳评分,表现出性能优势,尤其在CIDEr 上达到了133.1%,优于次优的X-Transformer,提升了0.3 个百分点。CIDEr 指标是专门实际用于图像描述生成任务的语义一致性评测标准,评分越高说明生成的描述与标注文本相比语义一致性更高、生成的描述词更具特异性,本文方法在CIDEr 指标上表现突出,表明所提出方法可有效利用全局上下文信息提升描述文本的生成质量。在句子流畅性方面,BLEU 与ROUGR 分别仅考虑了准确率和召回率,而METEOR 同时关注一元组(Unigram)准确率和召回率,相对于BLEU 与ROUGR 评分来说有一定的优势。本文方法在METEOR 指标上取得最优表现,表示生成的描述在语义上是最匹配真实文本的。SPICE 是基于场景图而设计的用于图像描述生成任务评测的指标,虽然本文并未使用场景图,但在此指标上仍超过其他方法,仅低于X-Transformer。
综合以上分析,本文在METEOR 和CIDEr 指标上均有显著提升的原因主要是:在网格特征交互图中不仅结合全局特征捕获上下文重要信息,还通过图注意力网络聚合节点信息,捕获网格之间的依赖关系和潜在交互,能增强视觉特征,提高生成描述的准确性。
4.2.2 消融实验
为了验证全局节点的使用、网格特征交互的方式以及使用区域特征对模型表现的影响程度,设置如下3 组对照实验,以相同的实验设置对模型进行训练,并与原模型进行性能比较。
1)全局节点:在本文模型的基础上排除全局节点的使用。
2)交互方式:构建网格特征交互图时,采用邻域交互方式,如图6 所示。
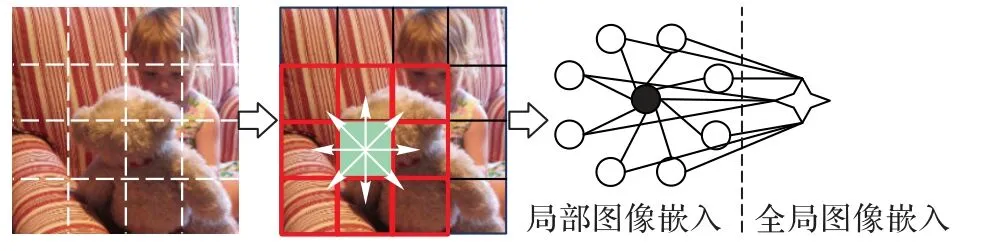
图6 邻域交互方式(与8个网格交互)Fig.6 Neighborhood interaction mode(interact with 8 grids)
3)区域特征:用Faster R-CNN 提取的区域特征表示节点,验证图注意力网络对区域特征的有效性。
消融实验结果如表2 所示,本文模型相较于对比模型性能达到了最佳,说明本文方法是有效的。具体来说,全局节点的影响最大,去掉全局节点后,模型的性能会下降,尤其是CIDEr 下降了3.9 个百分点,这表明全局节点在图注意力网络中有优化作用,可以增强网格的特征表示,从而促进高质量描述的生成。交互方式从相邻节点替换成邻域后,在CIDEr 和SPICE 上分别下降了2.6 和0.7 个百分点,说明上下文信息会提高识别精度,但是过多的上下文可能会增加噪声和问题维度,从而使学习变得更慢,性能更差。将网格特征替换成区域特征后,全局节点的提升作用有限,可能是因为提取的全局特征质量低于区域特征的质量,经过注意力机制后,区域特征受损,致使特征提取效果不明显。
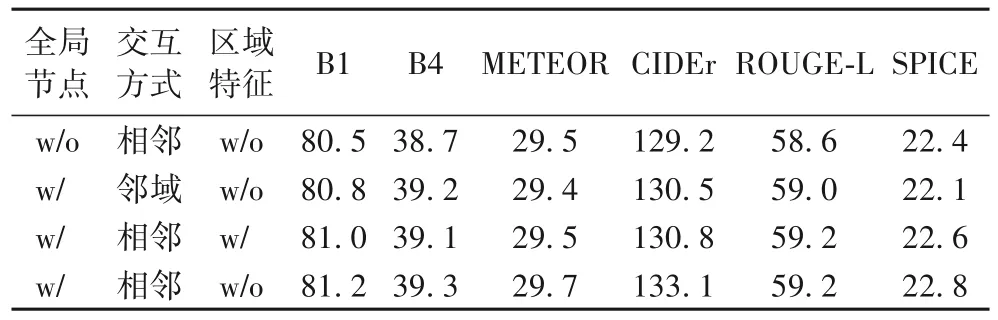
表2 消融实验结果 单位:%Tab.2 Ablation experimental results unit:%
4.2.3 可视化结果及分析
为了进一步评估与分析本文方法的描述生成效果,图7中4 个样例的描述结果对比如表3 所示。其中:带下划线标注基准Transformer 方法(Base)中的描述细节;加粗斜体标注本文方法相较于基准Transformer 描述有所改进的部分。每个样例均展示对应的人工标注文本(Ground Truth,GT)。

图7 典型样例图Fig.7 Typical samples
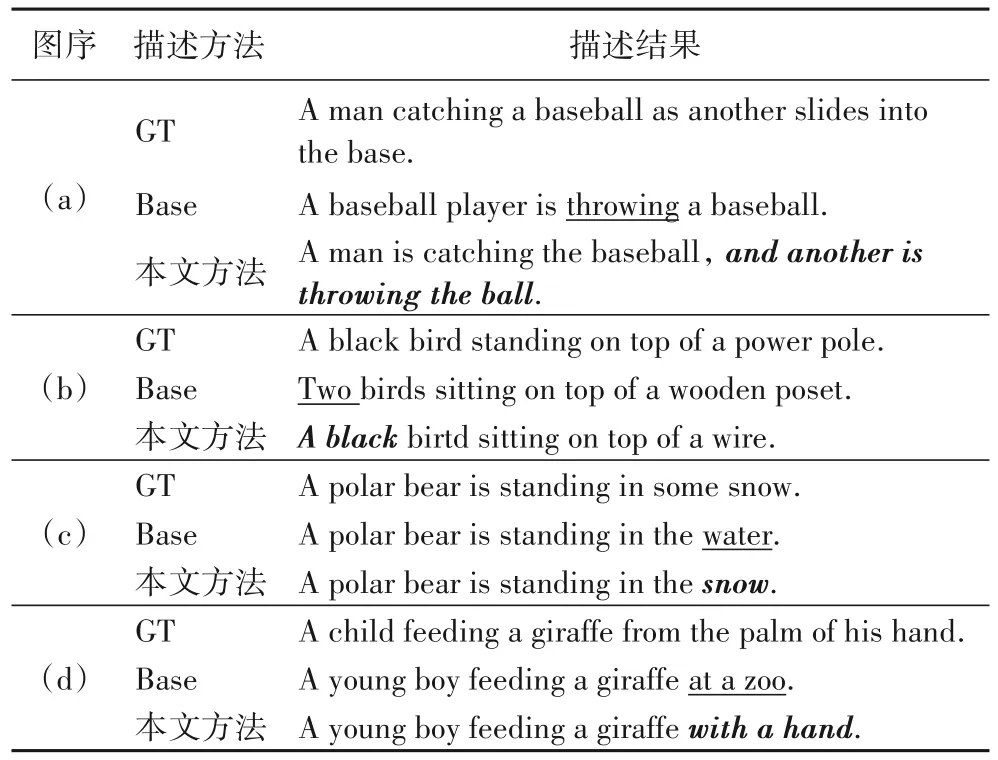
表3 图7样例图的描述结果Tab.3 Image captioning results of Fig.7
由图7 与表3 可以看到,在随机挑选的样例中,基准Transformer 无法基于检测到的区域特征信息生成高质量的描述。例如,在图7(a)中,Base 准确识别了图中的重要目标(穿蓝色衣服的人),却忽略了地上带红色帽子的人;本文方法在Base 预测结果的基础上,正确预测了“another is throwing the ball”。例如,在图7(d)中,Base 预测出“at a zoo”(在动物园),由图像内容并不能推断,因此是错误的预测;而本文方法在全局特征的基础上,并未受其中错误预测信息的影响,进而预测到“with a hand”(用手),最终生成更准确的描述:“A young boy feeding a giraffe with a hand”(一个年轻男孩用手喂一只长颈鹿)。相对来说,本文方法可以获取详细的全局上下文信息,具有更强的图像理解和文本表达能力。
以上分析说明:1)相较于基准方法,本文方法得益于全局图像特征,加深了对图像的理解,并基于全局语义进行合理推测;2)相较于利用区域特征的基准Transformer 方法,利用网格特征的方法可以生成更完整、详细的图像描述,在语义表达上更具优势。
5 结语
本文分析了现有图像描述生成研究中的特征提取方法,从全局图像特征的角度出发,提出了基于图注意力网络的全局图像描述生成方法,能够有效捕捉全局上下文信息和局部信息。实验结果表明,添加全局图像上下文信息能够提高局部网格的特征提取效果。未来计划整合文本上下文信息,利用语言特征弥补网格特征在语义表达能力上的不足,进一步增强网格特征的语义信息,提高图像描述生成性能。
