基于烛台图模式匹配的PM2.5扩散特征的提取
2023-05-24文益民沈世铭
许 睿,梁 爽,万 航,文益民,沈世铭,李 建
(1.桂林电子科技大学 计算机与信息安全学院,广西 桂林 541004;2.南方海洋科学与工程广东省实验室(广州),广州 511458;3.卫星导航定位与位置服务国家地方联合工程研究中心(桂林电子科技大学),广西 桂林 541004)
0 引言
实现经济和环境协同发展已经成为全球关注的热点,而大气环境污染是目前主要的环境问题之一。造成环境污染的细颗粒物种类众多,主要包括氮氧化物、硫氧化物、臭氧、一氧化碳等。大气污染物浓度监测是环境治理的一个重要手段,不仅可以识别大气中的污染物质,还能掌握其分布和扩散规律,监视大气污染源的排放和控制情况。大气污染物浓度预测方法特点对比如表1 所示。在众多的污染物浓度预测方法中,基于深度学习的方法以其学习能力强、适应性强、可移植性好以及准确率高等特点被广泛应用。本文考虑结合股票预测中广泛使用的K 线图技术分析方法,充分挖掘PM2.5(大气细颗粒物污染)浓度扩散数据,以有效提取大气污染物扩散过程特征。
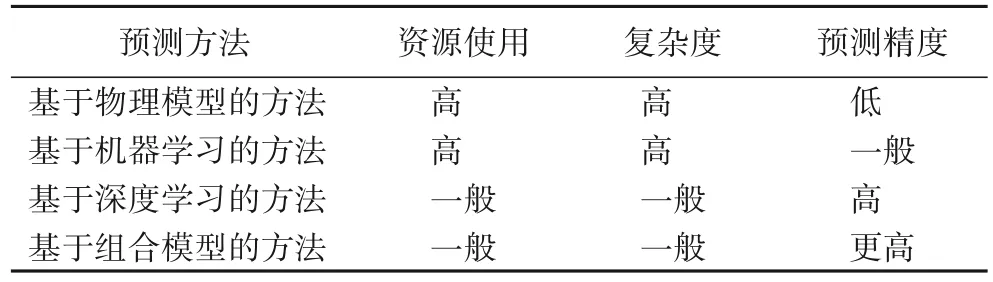
表1 大气污染物浓度预测方法特性对比Tab.1 Comparison of characteristics of air pollutant concentration prediction methods
本文提出了一种基于烛台图(Candlestick Chart,也称作K 线图)表示的卷积神经网络(Convolutional Neural Network,CNN)提取大气污染数值序列特征——基于烛台图模式匹配(Candlestick Pattern Matching,CPM)的PM2.5扩散特征提取方法,通过聚类分析网络中烛台图的特征判断将会发生的趋势反转情况。烛台图被广泛应用在股票市场用来记录和预测价格走势,烛台图分析技术的使用解决了非线性数据庞大无章的问题,同时保留了数据的语义关系。本文在引入烛台图的基础上,使用在深度学习领域广泛应用的VGG(Visual Geometry Group)网络提取污染物浓度变化特征,并对最终走势进行预测。实验结果表明:本文的预测方法可以有效提取PM2.5趋势特征,验证了基于CPM 的方法在预测未来污染物浓度周期变化时的有效性。
1 相关工作
随着当今世界经济的发展,人们对环境污染的问题也越来越重视,PM2.5已成为大气污染与扩散领域的重点研究对象。一个旨在预测空气质量变化的模型,不仅要充分考虑多种复杂因素的影响,如气候、交通、地形地貌、理化过程等,还需要充分保护数据的原始性,并考虑污染物浓度扩散的全局趋势以及局部变化特征。因此,将单纯时序数据与大气污染物扩散过程相对应,充分提取变化特征的研究具备实用性和学术价值。
目前针对污染物浓度数据的分析中,利用传统的物理模型以及人工神经网络等各类方法对空气质量指标未来走势进行分析是大气环境监测领域的一个重要方向。例如,Zhang 等[1]全面评估了具有在线耦合气象-化学的三维实时空气质量预测(3-D Real-Time Air Quality Forecasting,3-D RT-AQF)模型;李威凌等[2]分别采用高斯模型和空间插值法对空间扩散情况进行模拟;Sun 等[3]提出了一种混合深度空气质量 预测模 型(Mixing Depth Air Quality Prediction,HDAQP)来预测空气质量指标。现在基于人工神经网络的预测方法中,普遍集中在将初始处理的数据预处理成各种维度的数据向量后作为神经网络的输入样本。这些方法在对初始数据进行处理,或对输入数据的维度进行确定时,都对最原始的数据进行了改变和筛选,限定了原始数据呈现特征的形式,可能损失很多隐藏信息。
在众多的数据分析方法中,烛台图被认为是能够最好保存时序数据指标的一种形式,烛台图模式对应数据走势中的浓度变化。例如,Takeuchi 等[4]设计了改良的K 线;Li 等[5]将压力模式定义为一系列烛台图;魏连江等[6]从K 线图角度对瓦斯异常模式进行研究。但是,K 线图对各类纷繁复杂的分析规则的应用主要依赖分析者个人的经验,因此利用科学统计的方法真正抓住K 线图中预测涨跌的特征信号显得尤为重要。
随着深度学习研究的日益发展,CNN 在图片识别领域的应用取得了巨大成就。例如,Hu 等[7]将深度学习方法(卷积自动编码器)与K 线图分析技术相结合并应用在股票分析中;Chen 等[8]使 用CNN 和格拉 姆角场(Gramian Angular Field,GAF)图像捕获了8 种主要的烛台形式;Huang 等[9]通过阅读烛台图表而不是财务报告中的数值来预测价格走势;张智军等[10]则将含有需要识别的金融K 线形态图像和该形态对应的坐标作为神经网络的输入。通过深度学习算法在K 线形态图像识别的应用,不仅克服了现有时间序列数据量化程序难以表达分析师根据经验得到的K 线形态特征的问题,还能自主学习那些需要被识别的K 线形态后再用于包含K 线形态特征的实时图像识别中。
在将神经网络应用于大气质量预测时,现有研究多集中于采集监测站中各种维度和各种频率的数据,然后进行插值和剔除等预处理,之后再输入到深度神经网络进行学习训练[11],但少有方法能将原始数据不经破坏地保留下来。部分学者已经尝试在各个领域将图像分析方法和人工神经网络相结合,但还未单独考虑神经网络对于烛台图的识别分类问题[12-14],没有将此技术分析方法应用到大气环境领域。因此,本文将K 线分析技术与CNN 相结合,探讨由PM2.5生成的烛台图所包含的可以预测未来浓度变化的信息。
2 研究区概况
污染物浓度序列种类繁多,具有动态、非线性、混乱等特点,是大气环境技术分析与量化投资领域的重要研究内容。从海量的历史污染物时间序列数据中,表征并捕获某种特征的扩散过程,是构建神经网络模型的基础[15-17]。本次研究采用桂林市大气质量在线监测站的监测数据,如图1 所示。桂林地处中国华南,由于桂林特有的气象和地形条件,市区PM2.5扩散十分缓慢。烛台图的生成需要泄放时间较长的连续泄漏型数据,这使K 线图像分析技术在大气环境领域的应用变得合理。这种泄放时间较长的连续型数据恰好利于烛台图的生成以及变化特征的提取,为后续大气污染物浓度的预测提供数据基础。
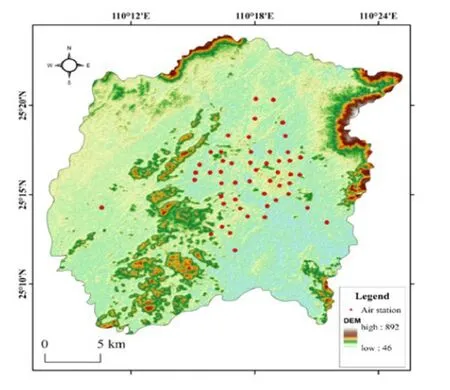
图1 桂林市大气质量在线监测站分布Fig.1 Distribution of air quality online monitoring stations in Guilin
本文结合在股票价格预测中广泛使用的分析方法与深度学习技术来预测PM2.5在桂林市的浓度水平变化。在传统的烛台图表分析中,总会根据一些特殊烛台图表或趋势反转信号的出现来判断趋势变化。然而,不同的站点会有不同的浓度变化机制,当带有趋势反转信号的烛台图出现时,当前污染物的浓度变化将会继续或是反转,这取决于站点对污染物浓度的扩散模式[18-20]。因此,需要找出污染物浓度的扩散模式,以帮助预测具体的浓度改变数值。
3 理论基础与模型构建
3.1 模型框架
在烛台图聚类分析和污染物浓度扩散机制相互联系的基础上,基于烛台图模式匹配(CPM)的大气质量预测框架如图2 所示,主要流程包括数据采集与预处理、特征提取与烛台图生成、模式匹配、趋势预测和结果分析。
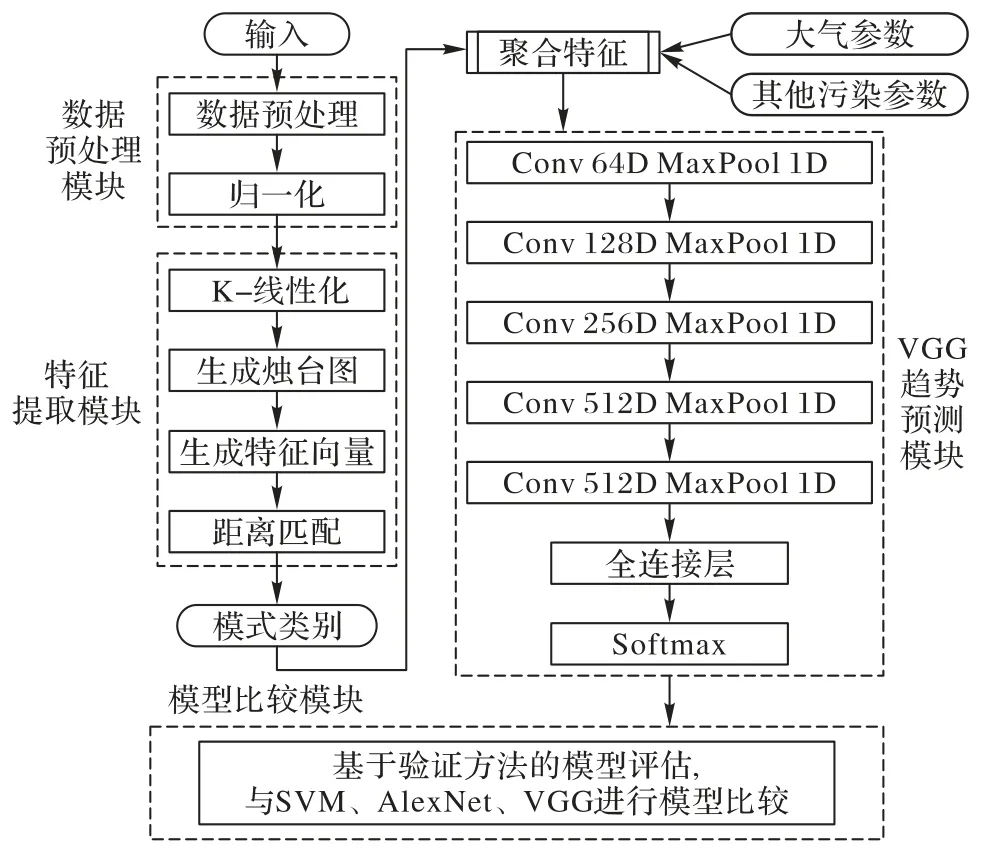
图2 基于CPM的大气质量预测框架Fig.2 Air quality prediction framework based on CPM
3.2 烛台图库的生成
PM2.5浓度K 线图中主要包括4 类数据,即起始值(First)、最高值(Highest)、最低值(Lowest)、结束值(Last)。PM2.5浓度扩散规律也是围绕这4 个数据进行研究。图3 中展示了污染物1 天内的变化信息,以及PM2.5浓度的烛台图对应过程。
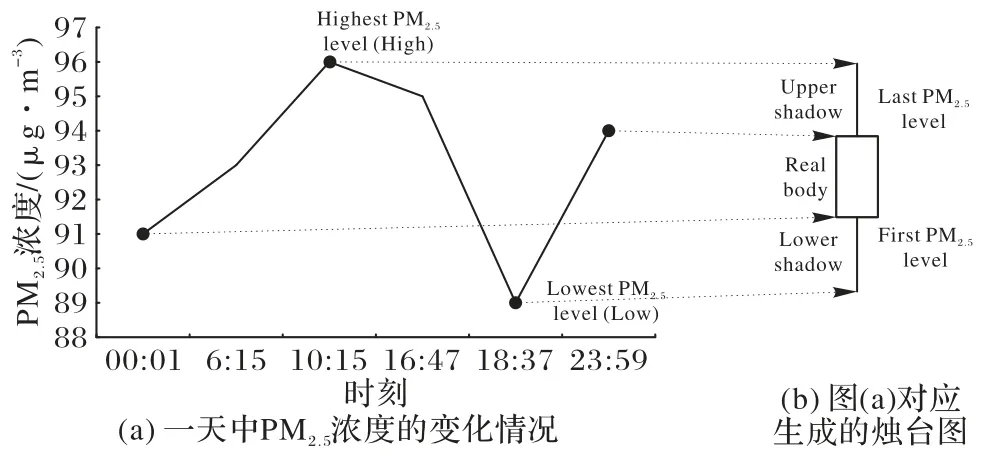
图3 1天中PM2.5浓度变化与对应的烛台图Fig.3 Candlestick chart corresponding to PM2.5 concentration change in one day
为了建立一个明确的参考模型用于对未来模式研究进行合理分类,Hu 等[21]提出了103 个已知烛台图案的综合形式规范。根据绘图规则,两种基本的烛台形状如图4 所示,所有可能存在烛台图的形状如图5。
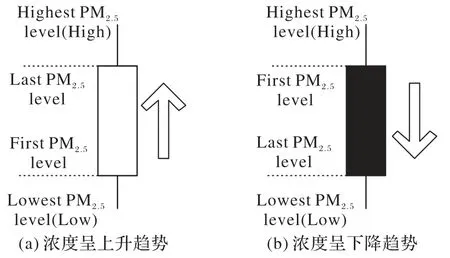
图4 两种基本的浓度烛台图形状Fig.4 Two basic concentration candlestick charts
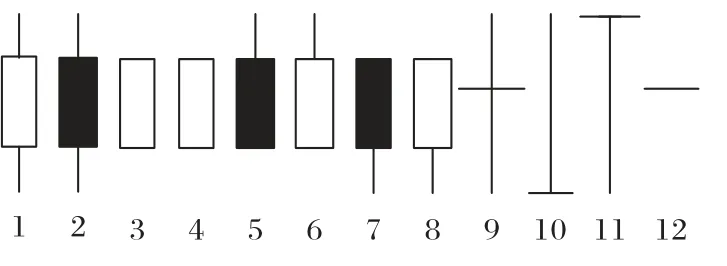
图5 12种类别烛台图Fig.5 Twelve types of candlestick charts
3.3 大气污染扩散过程特征提取
每一天内的浓度波动信息都通过5 个基本特征来描述,将污染物浓度扩散过程定义为一系列的烛台图表,然后进行浓度匹配,预测当前污染物趋势发生逆转还是保持不变。
3.3.1 浓度烛台图的特征描述
污染物浓度烛台图特征向量表示为:
通过从烛台图中提取5 个不同且有实际意义的特征fi1,fi2,…,fi5来反映1 天内整体的浓度情况,分别对应以下特征:
1)类别特征(Category Shape):通过区分浓度的升降、实体的有无、上下影线的有无,烛台图被定义为12 种不同的形状,类别特征表示为CShape∈{1,2,…,12}。
2)实体特征(Entity Features Length):在烛台图中,实体的长短表征着污染物浓度上升/下降的强度,较长实体的烛台表征明显的增加/减少的趋势。实体特征的计算方法为:
其中:Openi为第i天起始浓度值,Closei为第i天结束浓度值。
3)上影线特征(Upper Hatch Feature Length):具有较长上影线的浓度烛台图表示浓度趋势下降的幅度很明显,甚至在下一个时间间隔内,持续下降的可能性更大。上影线的计算方法为:
其中:Highi为第i天最高浓度值。
4)下影线特征(Undercut Feature Length):具有较长下影线的浓度烛台图表示浓度趋势上升的信号很强烈,这将导致下一个时间点浓度的增加。下影线的计算公式为:
其中:Lowi为第i天最低浓度值。
5)变化率特征(Rate Change):比较两个相邻位置的烛台图,计算出平均浓度变化趋势的信息,来锁定对当前时刻有用的污染物浓度模式。在一天当中,整体的浓度水平用平均浓度变化来表征,并以此作为浓度烛台的中心。此项特征将通过当天与前一天的浓度水平变化来描述,即:
通过提取带有浓度变化趋势的烛台图模式特征,捕捉出反转信号。如图6 展示了一些带有浓度反转信号的烛台图,表征趋势的转折点,当过去几天出现连续的浓度增加,而这种信号减少的烛台图出现时,预示未来浓度可能会降低。其中,浓度递减烛台图(1~4)和具有长上影线的烛台图(5、6)代表具有递减反转信号的烛台图。此外,那些不具备实体的特殊形状的烛台图(7~9)也可被看作是可能存在的转折点。同样,带有递增反转信号的烛台图特征也是如此。
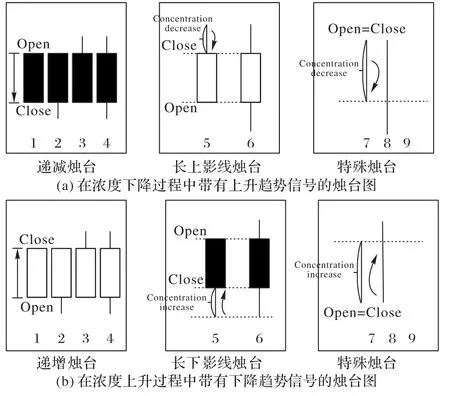
图6 浓度增加/减少过程中可能存在转折点的PM2.5烛台图Fig.6 PM2.5 candlestick charts with possible turning points in concentration increasing/decreasing process
3.3.2 污染物浓度模式匹配
1)浓度增加/减小周期:在连续的时间间隔t1,t2,…,tn,当i=2,3,…,n-1 时,如果满 足Ci,avg>max(Ci-1,avg,Ci+1,avg),则Ci,avg是浓度周期的峰值;当i=2,3,…,n-1 时,如果满 足Ci,avg<min(Ci-1,avg,Ci+1,avg),则Ci,avg是浓度周期的谷值。比如,Ci1,avg、Ci3,avg是两个最近相邻的浓度谷值,Ci2,avg是两者之间的浓度峰值,并且i1 <i2 <i3,则浓度谷值Ci1,avg和下一个浓度峰值Ci2,avg之间的连续时间间隔被视为浓度增加周期,浓度谷值Ci2,avg和下一个浓度峰值Ci3,avg之间的连续时间间隔被视为浓度减小周期。
2)浓度模式:浓度模式是由浓度烛台图特征向量PCFi组成的序列,即M=在每个浓度增加或减少的周期中,K是浓度周期的长度。鉴于最近的烛台图能够对未来预测提供更有用的信息,按照从后向前的顺序进行匹配。定义匹配率ρ,指K组特征中有ρ组参数能够完成匹配,并通过距离衡量两个烛台的特征向量的匹配率。如果匹配距离低于某一个阈值,则认为匹配成功。距离公式定义为:
其中:wi(i=1,2,…,5)是权重因子=1。本文方法的权重采用层次分析(Analytic Hierarchy Process,AHP)算法确定。距离当前天数最近的烛台图能够描述更加有用的信息,因此对应的权重w1将被赋予最高的数值。对于类别特征CShape,要求匹配的准确率最高。
针对实体、上影线、下影线、变化率四个特征,本文采用Z-score 标准化对原始监测数据进行归一化处理,以加快深度学习模型的收敛。
3.4 卷积神经网络模型的设计
3.4.1 网络模型的结构
在图像识别和分类领域,广泛使用CNN 处理实际问题。CNN 因具有极小的特征工程需求而被广泛应用,这为深度学习在大气质量领域的合理应用提供了技术支持。深度卷积神经网络VGG(Visual Geometry Group)是CNN 的经典模型,在特征提取和分类方面均表现优秀[22-24]。基于VGG 的浓度趋势预测框架如图7 所示。污染过程的局部特征由卷积层提取,对应大气污染物扩散过程。即第一天污染将对第二天和第三天污染造成的影响,此类模式的特征被卷积层捕获;池化层进一步加强统计特征层的信息,使网络强特征表现更明显,弱特征作用相对较小。污染过程的全局趋势信息由全连接层进行整合,能提高预测大气污染变化趋势的准确性。
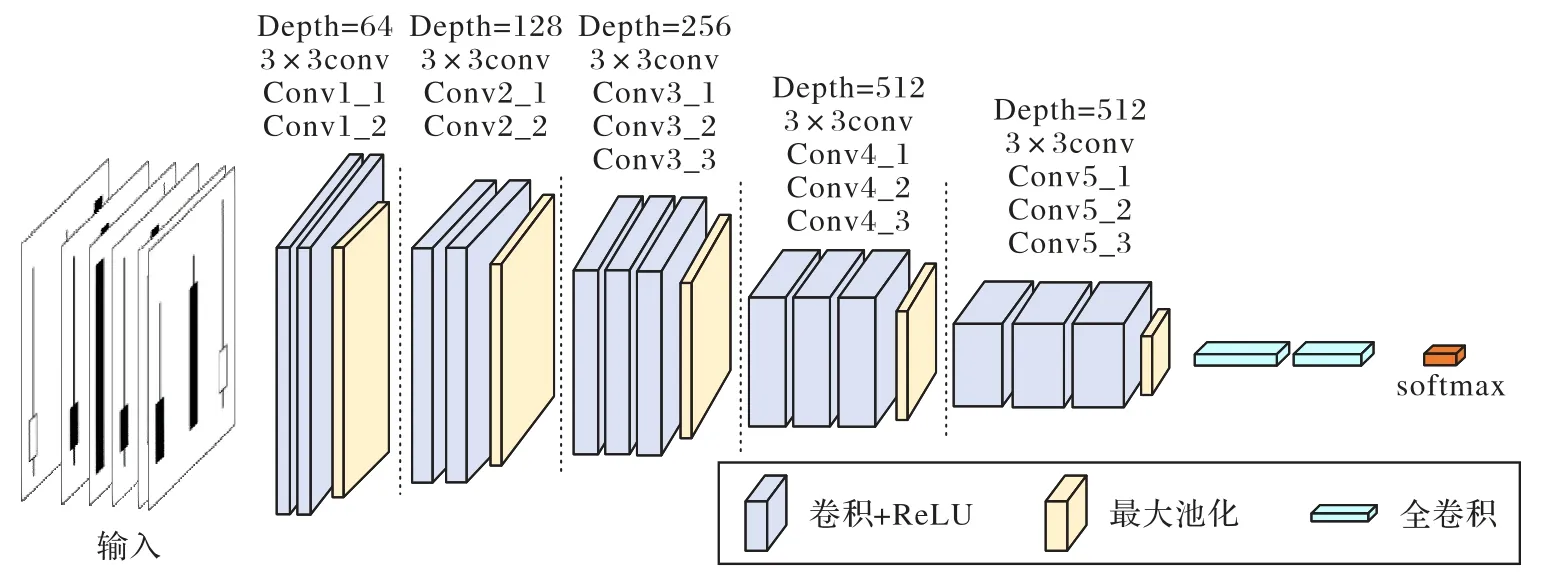
图7 基于VGG的PM2.5浓度趋势预测框架Fig.7 PM2.5 concentration trend prediction framework
如图7 所示,将连续3 天的PM2.5浓度数据通过K 线发生器生成污染物烛台图,然后通过模式匹配,输入VGG 网络结构中。
最后,综合评估了网络的效果和可用的计算机硬件条件,确定用以下CNN 结构进行研究:第一个卷积层设计32 个卷积核,第二个卷积层设计32 个卷积核,第三个卷积层设计16 个卷积核,卷积核大小为3×3。
在该网络模型中,激活函数都采用线性整流单元(Rectified Linear Unit,ReLU),ReLU 的使用不仅可以解决梯度消失的现象,还可以有效加速模型的训练。通过max()函数描述ReLU 的过程,并加入Dropout 层,以随机断开链接的方式防止模型过拟合。还在模型的最后一个卷积层加入Flatten 层,将多维数据压缩成一维。
3.4.2 网络模型的训练准备
本文设置批次大小batch_size=200,即每输入200 张图片训练后,网络进行权重校正并完成参数迭代。在前面设计的CNN 预训练期间,7~9 次的训练可以使神经网络达到最好收敛状态,因此在所有对比实验中设置epochs=10。
4 实验与结果分析
4.1 数据收集及预处理
4.1.1 数据收集
本次研究采用桂林市大气质量在线监测站的监测数据,桂林市总共配有61 个监测站负责监控大气环境质量,其中10 个是固定站,51 个为微型站。数据库中存储的数据通过服务设备每5 min 记录一次相应站点对应的污染物和气象数据。其中,气象数据有大气的气压、降雨量、风速、风向、湿度、温度等;污染物浓度数据包括NO2、SO2、CO、O3、PM2.5、PM10等。数据时间窗口选择自2019 年8 月8 日—2021 年8 月7 日,共计3 年的日污染物浓度数据。本次实验通过Hadoop引擎连接大数据系统,导出研究所用数据集。
4.1.2 数据预处理
数据的预处理分为两部分:首先是对数据集的基本面预处理,然后是对数据进行初始分类,包括极端值或缺失值处理、Z-score 标准化处理等。为避免因不同站点的污染物浓度数据差异较大对模型预测结果产生影响,本次实验采用Z-score 方法对历史PM2.5浓度数据进行标准化处理。Z-score将不同量级的数据统一转换成同一量级,并统一用计算出的Z-Score 值来衡量,以保证数据之间的可对比性。
4.2 评价指标
评估分类模型的评价指标中最常见的是混淆矩阵。在本次实验中,最终输出结果将会展示未来污染物浓度上升还是下降,考虑到污染物浓度上升会对环境产生的不良影响,故将浓度在分类型模型中表现上升设为positive,浓度在分类型模型中表现为下降设定为negative。
准确率指模型预测正确的样本数占样本总数的比重,可以直观衡量模型总体性能,如式(6)所示:
精确率指在模型预测是positive 的所有结果中,模型预测对的比重,如式(7)所示:
召回率指在预测出的分类样本中被正确预测的比重,如式(8)所示:
F1 分数是P与R的加权平均值,计算公式如式(10):
4.3 模型对比分析
为评价本文提出的基于CPM 的PM2.5扩散特征提取方法,对比了未考虑大气污染扩散过程的VGG 的方法,以及在相同实验条件下基于支持向量机(Support Vector Machine,SVM)、AlexNet 的预测方法。实验结果表明本文方法表现出了更好的性能。
通过对图5 中的12 种不同外观的烛台图进行统计后发现,浓度烛台形状3 和4 最为常见,占比分别为48.74%和31.31%。图8 是带有浓度烛台图序列的大气污染物时间序列片段。可以看出,当伴有反转信号的烛台图出现时,污染物浓度的变化趋势不会立刻反转,因此,通过浓度扩散模式进行判断。在获取污染物浓度模式的过程中,跳过了没有任何数据的时间间隔,只考虑完整的浓度循环周期。
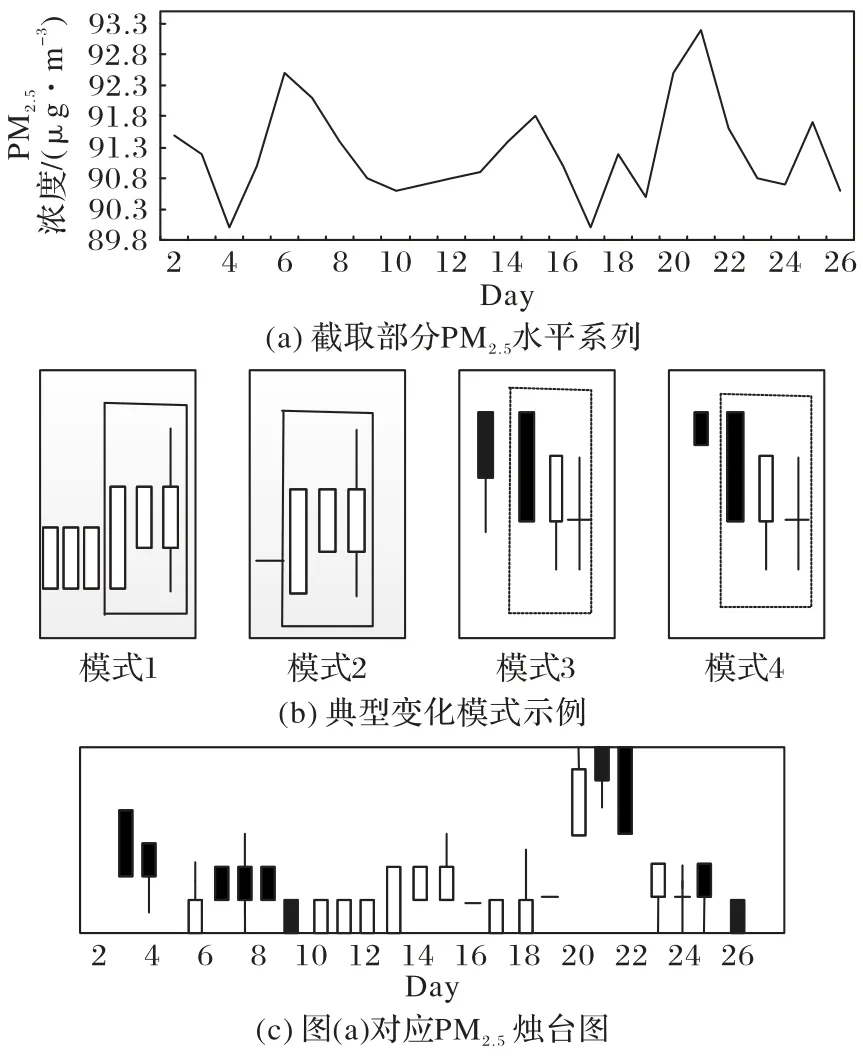
图8 PM2.5浓度模式匹配图Fig.8 PM2.5 concentration pattern matching diagram
匹配率ρ被用来调控匹配时间,从时间序列片段中提取两个浓度模式:模式1 和模式3,如图8 所示,即代表第10~15天的污染物浓度增加模式以及第21~24 天的污染物浓度减小模式。匹配过程中,调整匹配率ρ=1 时,会无法找到这两种模式对应的精确匹配;当设ρ=0.8 时,成功找到了历史模式中对应的模式2 和4 与之匹配。表2 显示了不同匹配率的预测结果,最终选择匹配率0.8 作为本文模型的参数。
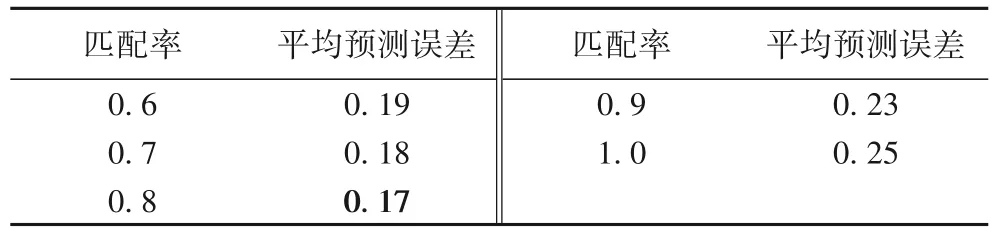
表2 匹配率变化时的预测误差Tab.2 Prediction error when matching rate changes
分别利用SVM、AlexNet、VGG 和本文方法的改进VGG 模型进行训练。此次实验选用的多源数据所包含的内容信息如4.1.1 节所示,划分其中70%的样本作为训练集,30%样本用来测试,并以准确率、精确率、召回率和F1 分数作为模型评价指标。为了控制变量,均采取50 个epoch 作为每个网络的训练批次。
不同预测方法的准确率比较结果如表3 所示,本文方法取得了最高的准确率,为95.1%,与基于普通VGG 的方法相比,准确率提高了1.9 个百分点,也优于传统的机器学习方法(SVM)和其他图像识别模型(AlexNet)。这是因为,单纯的VGG 没有充分融入一天内的污染物浓度扩散过程;而后两种方法在捕获转折点变化信号时,过分注重整体趋势,往往会忽略一些小的短期浓度波动,准确率更低。
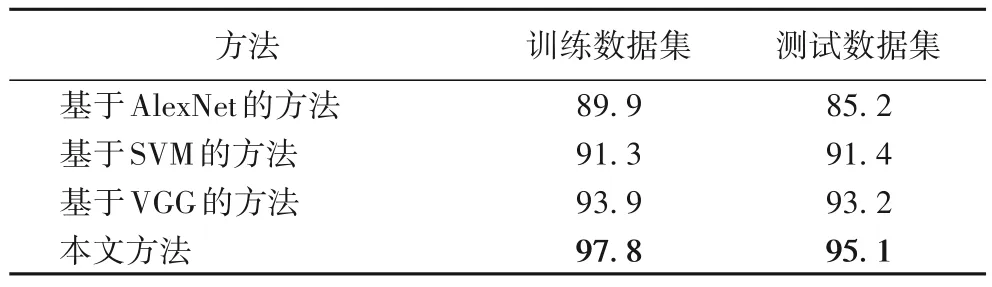
表3 不同预测方法的准确率比较 单位:%Tab.3 Accuracy comparison of different methods unit:%
污染物浓度随着长期的浓度循环变化,短期波动也会很大,基于CPM 的卷积神经网络预测方法可以捕捉更细粒度上的浓度变化信息。在精确率、召回率和F1 分数指标上,不同方法对PM2.5浓度上升、下降和不变情况的预测结果对比如表4 所示,本文方法同样取得了最好的结果。SVM 模型预测精确率高于AlexNet 模型,但召回率却较低,这是因为,SVM 在寻找重要的污染物浓度趋势转折点时更有效,但却没办法捕获一些小的趋势变化信号,存在一定的滞后现象。VGG 在捕获短期浓度变化信号时表现敏感,但会产生过拟合的现象。

表4 不同方法对PM2.5浓度变化情况的预测对比Tab.4 Comparison of different methods for predicting change of PM2.5 concentration
显然,基于CPM 设计的卷积神经网络模型表现出的性能明显优于基于普通时间序列的其他网络。因此,将股票分析中被广泛应用的K 线图应用到大气污染物分析领域,不仅能完整保存数据信息,还能够充分提取大气污染扩散过程中污染物浓度变化过程的局部变化信息,从而为大气污染物浓度趋势变化提供指导。
5 结语
提高大气污染物的预测精度是大气环境监测领域面临的重要任务。目前,众多的污染物浓度预测模型都未曾充分提取原始数据的变化特征,也无法融入大气扩散机制。因此,本文提出了一种基于烛台图时空聚类的深度学习预测方法。实验训练数据集由一组时间序列数据构建而成,其中包括历史PM2.5浓度数据、相关污染物数据以及气象关联参数。首先,利用烛台图形式化表示污染物扩散周期性变化;然后,通过浓度模式匹配融入大气物理扩散机制;最后,结合其余情景参数,通过卷积神经网络VGG 提取局部特征,并进行趋势预测。
通过实验对本文方法的整体性能进行了评估,并与基于传统的时间预测模型(AlexNet)、普通的机器学习模型(SVM)以及不结合烛台图的深度学习模型(VGG)的方法进行了比较。结果表明,本文方法的准确率、精确率、召回率和F1 分数均取得了最好的结果。烛台图简洁直观、立体感强,还能够全面透彻地观察到污染物浓度的真正变化,将K 线分析技术应用到大气污染领域,具有很高的实用性。
但本文方法仅预测了污染物未来的浓度水平变化,还无法预测下一个具体的浓度水平。因此,未来将进一步分析PM2.5的长期依赖特征提取,以捕捉大气污染物的浓度变化行为。
