基于多尺度核自适应滤波的股票收益预测
2023-05-24汤兴恒徐天慧张彩明
汤兴恒,郭 强*,徐天慧,张彩明
(1.山东财经大学 计算机科学与技术学院,济南 250014;2.山东省数字媒体技术重点实验室(山东财经大学),济南 250014;3.山东大学 软件学院,济南 250101;4.山东省未来智能金融工程实验室(山东工商学院),山东 烟台 264005)
0 引言
股票时序预测是指利用股票市场历史数据建立预测模型来捕捉潜在的交易模式,从而为投资者理性投资提供指导。精确稳定的股票时序预测模型能够为投资者制定合理投资策略、规避潜在投资风险提供帮助。然而,股票市场是一个受多种因素影响的复杂非线性动态系统[1],这使得根据获取的历史信息对股票时序数据进行预测成为一项非常具有挑战性的任务。
目前,众多技术被应用于股票时序数据预测领域,如:差分整合移动平均自回归[2]、卡尔曼滤波[3]、长短期记忆(Long Short-Term Memory,LSTM)神经网络[4]。这些方法虽然在平均绝对误差(Mean Absolute Error,MAE)和均方误差(Mean Square Error,MSE)等指标方面表现出较好的性能,但投资者在交易活动中往往更加看重投资行为能否获得较高的回报率。针对这一问题,文献[5]中使用核自适应滤波(Kernel Adaptive Filtering,KAF)捕捉股票时序数据中潜在的交易模式,用以预测股票未来收益。实验结果表明,该方法可以比较准确地捕捉潜在的交易模式,取得较高的回报率。然而,股票市场具有高波动性和非平稳性的特点,这为准确捕捉潜在的交易模式增加了难度[6]。股票时间序列具有多尺度特征,对股票时间序列进行多尺度分解能够将非平稳的时间序列分解成若干个平稳的子序列,且每个子序列具备不同的尺度波动特征[7],这便于进一步捕捉股票市场中潜在的多尺度交易模式,能有效增强股票收益预测模型的性能[8]。受此启发,本文提出了一种基于多尺度核自适应滤波(Multi-Scale Kernel Adaptive Filtering,MSKAF)的股票收益预测方法。为准确刻画股票时间序列的多尺度特征,该方法对股票时序数据利用平稳小波分解得到具有不同尺度特征的子序列,并对各子序列分别使用核自适应滤波方法进行序列学习,以得到不同尺度的波动规律,捕捉潜在的多尺度交易模式。此外,在处理多元时序数据时,为利用股票间的相互依赖关系[9],该方法对每只股票的预测不仅依赖于该只股票的交易模式,还会参考其所依赖股票的交易模式,从而进一步增强模型的预测能力。在公开数据集上的实验结果充分说明了本文方法在股票时序未来收益预测问题上的有效性。
1 相关工作
统计预测模型主要基于统计理论对股票时序数据进行预测。针对金融时序预测问题,Sims 提出了向量自回归(Vector Autoregression,VAR)模型[10-11]。该模型通过将系统中每一个变量作为所有变量的滞后值函数建模得到,从而将单变量自回归模型推广到由多元变量组成的向量自回归模型。然而,VAR 模型仅能对平稳的时序数据作出比较准确的预测,对于受多种因素影响的非平稳数据,VAR 模型的预测性能有所下降,这使它的应用范围受到限制。为此,Engle等[12]在VAR 的基础上引入误差修正项,提出了向量误差修正模型(Vector Error Correction Model,VECM)。该模型常被用于具有协整关系的非平稳时间序列建模。上述基于统计模型的预测方法一般采用线性形式建立相应的数学模型对时序数据进行拟合,但股票时序数据受多种因素的影响一般呈非线性形式,这导致该类预测方法难以得到理想的预测结果。此外,统计预测模型在建模过程中依赖于数据满足正态分布和平稳性假设,这对于具有非线性、非平稳、非正态等特征的股票时序数据来说,假设条件难以满足。故统计模型对非线性时序数据的拟合效果较差,这限制了该类方法在股票时序预测领域中的应用。
伴随着非线性时序预测问题研究的深入,以支持向量机(Support Vector Machine,SVM)和核自适应滤波为代表的核函数方法在时序预测领域得到广泛使用[5,13-14]。SVM 以结构风险最小化为原则,具有良好的泛化能力,但它的关键参数很难确定,这在很大程度上限制了它的应用范围。核自适应滤波是一种记忆学习和纠错相结合的方法,本质是通过一个线性的自适应滤波算法实现非线性函数映射。该类方法结合了神经网络的普适逼近特性和线性自适应滤波方法的凸优化特性[5],能够很好地拟合非线性函数关系,被广泛地应用于时间序列预测领域。核最小均方(Kernel Least Mean Square,KLMS)算法[15]是一种典型的基于核自适应滤波的时序预测方法,但它在进行时序预测时,计算复杂度会随着样本量的增加而增长。为此,Chen 等[16]提出了量化核最小均方(Quantized Kernel Least Mean Square,QKLMS)算法。该方法通过矢量量化技术压缩输入或特征空间,以抑制高斯核结构的增长,降低模型计算复杂度。此外,文献[17]将矢量量化技术与最近实例质心估计方法相结合,提出了最近实例质心估计核最小均方(Nearest Instance Centroid Estimation Kernel Least Mean Square,NICE-KLMS)算法,在一定程度上解决了核自适应滤波方法随样本数量增加导致的计算复杂度增长的问题,并表现出良好的性能。
近年来,基于神经网络的方法因具备优秀的非线性映射能力,在时序预测领域得到了研究人员的广泛关注[18-20]。基于前馈神经网络的预测方法通过动态调整网络神经元的互连权值来拟合时间序列数据内在的映射关系[21],最终能够获得比统计模型更准确的预测结果。但基于前馈神经网络的预测方法并不能反映股票的时序依赖性。为解决这一问题,文献[22]中提出了基于循环神经网络(Recurrent Neural Network,RNN)的股票时序预测方法。RNN 可以通过保存并传递上一时刻的状态信息来捕捉时序数据的依赖性。但该模型在训练时会随着隐藏层数量的增加而产生梯度消失或梯度爆炸问题,严重影响预测结果。为此,Hochreiter 等[23]在RNN 模型中引入细胞状态和门结构提出了LSTM,较好地缓解了长序列训练过程中的梯度消失和梯度爆炸问题,并在捕捉长期时序依赖方面表现出良好的性能。
尽管基于神经网络的预测方法在非线性数据处理方面表现出色,但在训练时通常需要较强的硬件资源和大量的训练数据,并且存在易陷入局部最优解和可解释性较差等缺点,这在一定程度上限制了此类方法在股票时序预测领域的应用。不同于神经网络,核自适应滤波不仅具有较低的计算复杂度和简单的递归更新形式,而且具有较好的可解释性,故本文专注于基于KAF 的股票时序预测方法。此外,由于股票时序数据具有多尺度特征,因此对它们进行多尺度分解有助于刻画时序数据在不同尺度上的波动规律,捕捉潜在的多尺度交易模式,这对于提升股票预测模型的性能具有重要意义[8]。鉴于此,本文提出了一种基于多尺度核自适应滤波(MSKAF)的股票收益预测方法。实验结果表明,相较于其他对比方法,本文方法能够获得更高的回报率。
2 本文方法
股票是具有多尺度特征的时间序列。本文方法首先使用平稳小波变换(Stationary Wavelet Transform,SWT)对股票数据进行多尺度分解,以获得具有不同尺度特征的子序列;在此基础上,对各子序列使用KAF 方法进行序列学习,刻画股票时序数据在不同尺度上的波动规律,捕捉潜在的多尺度交易模式;最后,模型借助捕捉到的多尺度交易模式对股票未来收益作出预测,MSKAF 模型如图1 所示。此外,为应对KAF 方法的计算复杂度会随样本量的增加而增长的问题,本文采用分段学习策略和矢量量化技术抑制高斯核结构的增长,实现降低模型计算复杂度的目的。

图1 MSKAF模型示意图Fig.1 Schematic diagram of MSKAF model
2.1 多尺度分解
传统的小波变换是进行多尺度分解常用的工具,但因其分解过程中存在下采样操作,会使获得的子序列长度缩减为原始序列长度的一半,导致子序列在时间维度上无法与原始序列相对应,不利于模型对时序数据的进一步分析。与传统的小波变换不同,SWT 在对股票时间序列进行多尺度分解时,由于滤波器的延展,可使多尺度分解后的子序列与原始序列长度相同,保留原始序列中的时间维度信息。因此,本文采用SWT 对股票时间序列进行多尺度分解。
SWT 的多尺度分解过程如图2 所示。给定原始股票时序数据D={yt:t∈[1,2,…,n]},t为时间变量,yt∈R 为第t时刻的收益。SWT 分别通过高通滤波器H0和低通滤波器L0对D进行卷积运算得到子序列D0和D1'。在此基础上,将滤波器H0和L0进 行插值补零得 到H1和L1,并利用H1和L1对D1'进行分解得到D1和D2'。依此类推,经过k阶分解后,可得到最终的高频子序列Dk-1和低频子序列Dk。

图2 多层级平稳小波分解Fig.2 Multi-level stationary wavelet decomposition
2.2 异常点检测
在时序预测过程中,核自适应滤波方法会为每一个新样本创建内核单元,导致计算复杂度会随样本量的增加而增长[14]。针对上述问题,本文采用文献[24]提出的异常点检测算法对股票时序数据进行异常点检测,并依据异常点对股票时间序列进行分段,通过分段学习策略实现降低模型计算复杂度的目的。如图3 所示,对于时序数据D={yt:t∈[1,2,…,n]},图中实线条代表D的数据波动情况,首先根据序列段{y1,y2,…,yt-1}(图3 中阴影窗口)的概率密度pt-1计算yt的异常得分,然后依据异常得分判断yt是否为异常点。异常得分通过式(1)计算:

图3 异常点检测过程示意图Fig.3 Schematic diagram of outlier detection process

图4 股票时间序列采样过程Fig.4 Sampling process of stock time series
式(1)被称为对数损失分数,表示yt相较于概率密度函数pt-1的预测损失[25]。当分数Score(yt) ≥δ时,表示yt为一个异常点,其中δ为异常点阈值;反之,yt为正常点。
2.3 多尺度核自适应滤波
1)Score(yt) ≥δ:这表明时间序列在yt处出现突变,将增加一套新的字典。此外,为了避免序列学习过程中出现较大的不连续[17],会将最邻近字典中的所有中心和系数复制到新增加的字典中。具体过程描述如下:
2)Score(yt) <δ:这表明时间序列在yt处未出现突变,不需要创建新的字典。
此外,本文采用矢量量化策略用以抑制核函数结构的增长:
不同于文献[16]中的矢量量化策略,本文采用数据分布特征代替输入空间中距离度量作为更新函数结构的标准,提高了最邻近中心的利用效率,使算法计算复杂度有所下降。算法1 给出了基于多尺度核自适应滤波的序列学习过程。
算法1 基于多尺度核自适应滤波的序列学习算法。
该方法需对n个样本分别进行处理,时间复杂度为O(N);对于每一个样本,在计算滤波输出时均需要寻找其最邻近的字典,该子过程的时间复杂度为O(N);在后续字典存储过程中,还需寻找样本的最邻近内核中心,此子过程的时间复杂度同为O(N)。因此,本文算法的时间复杂度为O(N3)。
2.4 多元时序数据依赖模型
为捕捉不同股票之间的相互依赖关系,提高模型的预测性能,本文将算法1 中的模型扩展为多元数据依赖模型。该模型在处理多元时序数据时,设Dstock={Dr:r∈[1,2,…,q]}为q只股票时序数据,其中Dr={yt,r:t∈[1,2,…,n]}为第r只股票时序数据。如图5 所示,对于每只股票分别使用算法1 进行多尺度序列学习,最终每只股票序列都会由子序列D1和D2分别得到高频字典和低频字典,即:

图5 多元时序数据依赖模型Fig.5 Multivariate time series data dependence model
本文提出的多元时序数据依赖模型如算法2 所示。在进行股票收益预测任务时,多元时序数据依赖模型的任务是根据输入向量x'∈RM去预测其标签值∈R。如2.3 节中,首先需要寻找最邻近的高频字典i*h和低频字典i*l,使用如下表达式:
由上述公式可以看出,有多只股票会被同时考虑用于选择最邻近的高频字典和低频字典。在预测阶段时,这些字典会被用于预测,如式(8):
其中w1的设置如下:
w1为预测阶段低频字典所占权重;var为训练样本收益日变化率的方差;υ和γ为超参数。
由式(6)~(8)可知,当对第r只股票中样本x'进行预测时,不仅依赖在该股票时序数据上捕捉的交易模式,还会参考从其他股票中捕捉到的交易模式,为将股票市场间的相互依赖关系融入模型提供了一种有效的方法,能进一步增强模型的预测性能。
算法2 多元时序数据依赖模型。
3 实验与结果分析
在公开数据集上进行实验以验证本文所提出的MSKAF方法在股票市场未来收益预测上的有效性。
3.1 实验数据
本文实验数据来源于公开数据集,该数据集中共包含来自德国(DE)、英国(UK)和美国(US)三个经济体的24 只股票(见表1)。本文使用调整后的收盘价计算每日收益[27],采用m=10 的滑动窗口对2006 年1 月17 日 至2016 年11 月30 日的股票时序数据进行采样,并将获得的10 880 组实验数据作为训练集;对2017 年1 月3 日至2018 年2 月28 日的股票收益数据以同种方式进行采样,并将获得的6 720 组实验数据作为测试集。此外,该数据集中的股票收益数据是标准化的,所有收益数据的均值估计为0,标准差为1。

表1 实验过程中使用的股票信息Tab.1 Stock information used in experimental process
3.2 对比方法及参数设置
为评估MSKAF 的预测性能,将它与以下6 种常用的时序预测方法进行对比:
1)基于神经网络的预测方法[4]。LSTM 是一种特殊的RNN 模型,可以有效地捕捉时序数据的依赖性并缓解训练过程的梯度消失和梯度爆炸问题,是一种常用的神经网络时序预测方法。
2)基于向量自回归模型的预测方法[10-11]。VAR 是一种经典的多元变量向量自回归模型,可用于多元时序数据预测问题建模。
3)基于向量误差修正模型的预测方法[12]。VECM 在VAR 的基础上增加了误差修正项,常被用于具有协整关系的非平稳时间序列建模。
4)基于量化核最小均方算法的预测方法[16]。QKLMS 通过量化操作压缩输入数据,有效地抑制了高斯核结构的增长。
5)基于最近实例质心估计核最小均方算法的预测方法[17]。NICE-KLMS 采用矢量量化技术与最近实例质心估计相结合的策略,有效降低了模型的计算复杂度。
6)基于核自适应滤波算法的预测方法TSKAF(Two-Stage KAF)[5]。该方法采用一种新的矢量量化策略,并将多元时序数据相互依赖关系有效地融入模型,表现出了较好的时序预测性能。
如表2 所示,以上6 种对比方法均采用作者公开的源代码以及默认的参数设置。此外,对基于LSTM 的预测方法,本文采用20 个神经元的单隐层结构进行训练,使用Sigmoid函数作为激活函数,并采用Adam 算法对模型进行优化。对基于自回归模型的预测方法的参数设置主要参考之前的研究[28-29],以保证它们可在测试数据集上获得较好的性能。
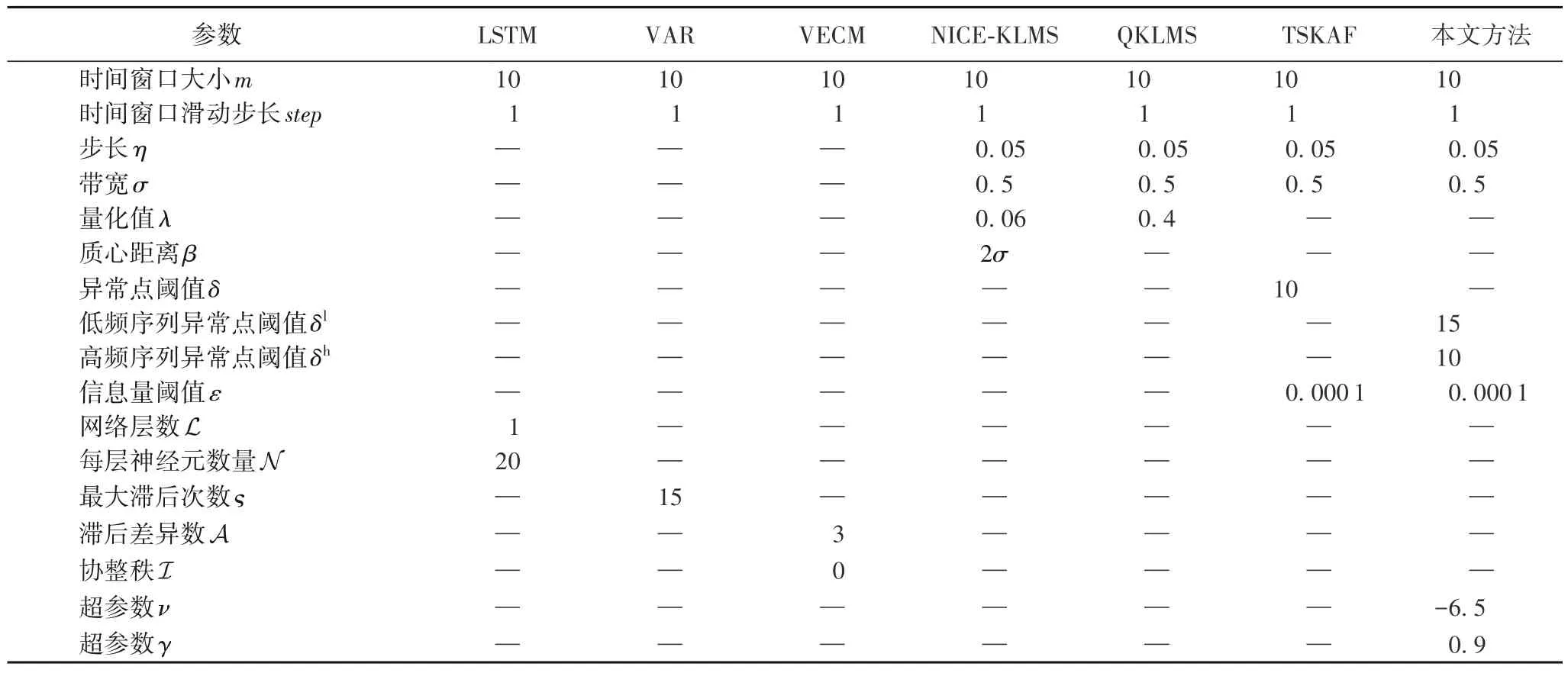
表2 比较方法的参数设置Tab.2 Parameter setting of comparison methods
3.3 评价指标
本文使用在时序预测领域中最为广泛采用的平均绝对误差(MAE)[30]、均方误差(MSE)[31]以及夏普比率(Sharpe Ratio,SR)[32]作为模型预测性能评价标准。MAE 是样本预测值与真实值的绝对平均误差,值越小代表预测结果越接近于真实值,即预测方法的性能越好;MSE 是样本预测值与真实值误差平方的均值,用来衡量二者之间的差异程度,值越接近于0 代表预测方法的性能越好;SR 是风险调整后的收益率指标,用来衡量承担单位风险所获得的超额收益,值越高代表预测方法的性能越好。
3.4 实验结果与分析
表3~5 分别给出了各预测方法实验结果的MAE、MSE 以及SR,每个表格的最后两行都给出了各预测方法的平均性能,且在该指标下用粗体标记最优值。

表3 测试阶段各模型的MAE值Tab.3 MAE values of different models in test phase
从表3 可以观察到,基于LSTM 的预测方法实验结果的平均MAE 值为0.012,这表明它的预测性能在MAE 指标上优于其他方法。虽然该方法表现出了最好的性能,但其他对比方法的实验结果也均取得了相对较低的MAE 值。此外,本文方法实验结果平均MAE 值为0.018,略高于基于LSTM的预测方法。虽然MAE 可从预测精准度的角度衡量预测方法的性能,但投资者在交易活动中往往更看重投资行为能否获得较高的回报率[5]。
由表4 可以看出,对比方法都获得了相同的平均MSE值,这表明在该指标下所有的预测方法都表现出了较好的预测性能。然而,基于LSTM 的预测方法在训练时需要较强的硬件资源和大量的训练数据[33],并且该类方法的可解释性较差。不同于基于LSTM 和自回归模型的预测方法,核自适应滤波是一种基于记忆学习和纠错相结合的方法,故该类预测方法可在未获得完整训练集的情况下即开始模型训练。此外,本文模型在对多元股票时序数据进行预测时,不仅使用在该股票中捕捉的多尺度交易模式,而且会参考其所依赖股票的交易模式来进行预测,从而进一步提升模型的预测能力,为将股票间的相互依赖关系融入预测模型提供了一种有效的方法。

表4 测试阶段各模型的MSE值Tab.4 MSE values of different models in test phase
尽管MAE 与MSE 可以从预测精准度的角度衡量模型的性能,但对于投资者而言,回报率是一项更为重要的衡量模型预测性能的评价标准。由表5 可看出,本文方法取得了最高的SR 值,优于其他对比方法,这表明本文提出的MSKAF模型会为投资者提供回报率较高的投资策略。

表5 测试阶段各模型的SR值Tab.5 SR values of different models in test phase
由表3 及表5 可知,本文提出的基于MSKAF 的预测方法相较于基于TSKAF 的预测方法在MAE 指标上降低了10%;在SR 指标上提升了8.79%。由此可知,对股票时序数据进行多尺度分解后,MSKAF 模型可以分离出具有不同尺度波动规律的子序列,进而更准确地捕捉不同尺度的交易模式,大幅提升了模型的预测性能。但是,如果内核带宽参数选择不当,会对KAF 的收敛速度产生不利影响[5],对此可以使用Silverman 经验法则来选择合适的参数值[34]。此外,本文方法利用再生和希尔伯特空间中的线性自适应结构来得到输入空间中的非线性映射关系,在保持线性自适应滤波结构简单特性的同时增强了模型的预测性能。
为分析多尺度分解层数k对模型预测性能的影响,将时间窗口大小m固定为10,时间窗口滑动步长step固定为1,并选取分解层数k=1、2 与3 进行实验,结果如表6 所示。

表6 多尺度分解层数对实验结果的影响Tab.6 Influence of multi-scale decomposition layers on experimental results
由表6 可以看出,当分解层数k由1 上升至2 时,在SR 指标上,基于MSKAF 的预测方法取得了较大的性能提升,这表明随着多尺度分解层数的增加,MSKAF 可以更为准确地捕捉隐藏在不同尺度子序列中的多尺度交易模式,使模型的预测性能得到了明显提升。由于MSKAF 仅适用于处理两个尺度的子序列,故当分解层数k由2 上升至3 时,本文仅使用子序列D2与D3进行字典学习。由表6 可看出,当分解层数k由2 上升至3 时,在SR 指标上,基于MSKAF 的预测方法性能大幅下降,这表明:一方面,由于只使用了子序列D2与D3进行字典学习,这会造成隐藏在多尺度子序列中信息的丢失,因此导致了MSKAF 性能的下降;另一方面,随着多尺度分解层数k的增大,会产生k+1 个子序列,虽然MSKAF 可以更准确地捕捉多尺度交易模式,但不同子序列间字典权重的设置将会变得尤其复杂与困难。
TSKAF 模型还包含两个重要参数,分别是时间窗口大小m和窗口滑动步长step。为分析m对该模型预测性能的影响,固定step为1,分别将窗口大小设置为m=8、9、10、11、12和13 在数据集上进行股票收益预测。图6(a)给出了选取不同窗口大小时TSKAF 的预测性能(为展示方便,图6 中的MAE 值均放大100 倍)。从中可以看出,尽管m=10 时,未取得最低的MAE 值,但拥有最高的SR 值3.909。这表明时间窗口大小为10 时,TSKAF 模型虽然没有取得最优的预测精确度,但可以取得最高的收益率,具有较高的综合性能。因此,本文采用长度为10 的窗口对时序数据进行采样。此外,由图6(a)中MAE 的变化趋势可以得知,随着时间窗口的增大,TSKAF 模型的预测精确度将得到提升;但是,随着时间窗口的进一步增大(m=13 时),窗口内样本点间的非线性映射关系将变得更加复杂,导致TSKAF 模型的预测性能下降。

图6 m与step对实验结果的影响Fig.6 Influence of m and step on experimental results
为分析step对该模型预测性能的影响,固定m为10,分别将窗口滑动步长设置为step=1、2、3、4 和5 进行实验,结果如图6(b)所示。可以观察到,随着步长step的逐渐增大,模型的预测性能逐渐下降。这是由于步长step的增大,将会使训练集数据规模减小(如step=2 时,训练集数据规模将变为原始训练集的1/2),从而导致模型的预测性能下降。
4 结语
本文针对股票时序数据的未来收益预测进行研究,首先介绍了未来收益预测问题的研究背景,然后回顾了基于统计模型的时间序列预测方法、基于核函数的时间序列预测方法和基于神经网络的时间序列预测方法,并对当前股票时序数据未来收益预测研究进行了简要介绍。针对股票时间序列具有多尺度波动规律的特点,本文提出了一种多尺度核自适应滤波(MSKAF)模型。该模型可以实现对股票时序数据多尺度交易模式的捕捉;而且模型采用分段学习策略和矢量量化技术,能降低模型复杂度;模型在处理多元时序数据时,较好地利用了股票间的相互依赖关系,能有效提升模型的预测性能。实验结果表明,本文提出的基于MSKAF 的股票收益预测方法取得了较好的预测性能,验证了模型在股票未来收益预测问题上的有效性。
