融合人体全身表观特征的行人头部跟踪模型
2023-05-24张广耀宋纯锋
张广耀,宋纯锋*
(1.中国科学院大学 人工智能学院,北京 100049;2.中国科学院自动化研究所 智能感知与计算研究中心,北京 100190)
0 引言
随着互联网视频内容的快速增长,基于视频的视觉内容分析成了计算机视觉中的一个热门研究话题。多目标跟踪是计算机视觉中的一个基础任务,它的目的是在一段连续的视频中关联特定类别的同一身份的检测框,从而形成多条轨迹。高度优化的多目标跟踪模型可以应用于视频监控、动作识别、自动驾驶等。
近些年来,随着深度神经网络的应用,多目标跟踪任务已经得到了长足的发展。其中,基于两步法的多目标跟踪[1]在大部分的通用场景下表现优异。然而,在极度拥挤的场景下,两步法多目标跟踪常常会失效。这是因为行人之间的互相遮挡会阻止行人的有效检出以及有判别力的行人表观特征提取[2]。
一些现有的工作试图通过学习一个对于漏检和有噪声的行人表观特征更加鲁棒的跟踪器[3]来减少漏检和帧间关联混淆,为了实现这一目标,这类工作一般会设计更加有效的跟踪片段管理方式[3],或对轨迹进行全局的优化[4];然而,此类模型需要利用未来帧的信息,因此无法满足实际场景中在线跟踪的要求。另一部分工作试图解决漏检问题以及对遮挡下的行人表观特征去噪声[2,5],本文的工作就属于这一类别。在严重拥挤的情况下,行人的全身目标框之间互相遮挡严重,但行人头部之间的遮挡相对较少,因此文献[2]中提出了一种行人头部跟踪的模型HeadHunter-T 和基准数据集Head Tracking 21(HT21)。这一范式引起了人们的广泛关注。然而,为了在被遮挡之后保有同样的身份,文献[2]中只考虑了行人头部的表观特征,并没有考虑其他的跟踪线索。直觉上来说,行人头部表观特征非常鲁棒,易于提取,是良好的行人头部跟踪的线索;但本文中的实验结果表明,行人头部的表观特征在拥挤场景下可能并不是最优的,特别是在远距离的情况下,行人头部会出现严重的模糊,因此无法提取有效的表观特征。实验结果显示,行人全身的表观特征相较于行人头部的表观特征更加具有判别力,能够更好地帮助行人头部的跟踪问题。为了能够利用全身的表观特征线索帮助行人头部跟踪,本文提出了一种融合全身表观特征的行人头部跟 踪模型 HT-FF(Head Tracking with Full-body Features)。该模型首先检测头框,然后利用头框动态生成全身框,最后利用全身框的表观特征帮助头框的跟踪。为了能够通过行人头部的目标框(头框)生成精准全身的目标框(全身框),受到R-CNN(Region-CNN)[6]的启发,本文利用一个回归分支对使用固定比例生成的锚框(Anchor)进行修正,能得到更加精确的全身框。此外,为了能够使全身的表观特征更好地辅助行人头部的跟踪,本文设计了一种使用人体姿态估计生成热力图来引导身体表观特征提取的模型。本文的HT-FF 模型在行人头部跟踪的基准数据集HT21 上取得了最好的结果;此外,通过对固定比例的全身框进行回归,该模型还可以得到行人全身目标框的结果,进而在全身跟踪的基准数据集上提交结果进行测试。
本文的主要工作包括:
1)设计了一种融合行人全身表观特征的行人头部跟踪模型HT-FF,可以同时利用具有更好判别力的全身表观特征线索和更少遮挡的行人头部框运动线索。
2)为了能够通过行人头部的目标框来提取全身表观特征,设计了一种从固定比例全身目标锚框进行回归的动态全身目标框生成模型和用人体姿态估计引导去噪声的表观特征提取模型。
3)本文模型HT-FF 可以同时完成行人头部跟踪和行人全身跟踪的任务,并在HT21 数据集上面取得了最好的性能。
1 相关工作
1.1 多目标跟踪的基准数据集和算法
多目标跟踪的目的是在一段视频序列中,检测特定类别的所有目标框,并关联同一身份的目标框,形成多条轨迹。为了评估多目标跟踪模型的性能,最常用的指标是CLEAR Metric[7],其中MOTA(Multiple Object Tracking Accuracy)是一个综合性的指标,这一指标综合考虑了IDs(ID switch)、FP(False Positive)和FN(False Negative);另一个常见指标是IDF1(ID F1 Score)[8],它刻画了成功匹配的轨迹在所有的轨迹真值的占比。在实践过程中,MOTA 更多地会倾向于给检测性能好的跟踪器高分,IDF1 会倾向于给检测和跟踪性能都比较好的跟踪器较高的分数。为了评估不同场景下不同类别多目标跟踪算法的性能,有许多的数据集陆续被提出来。其中MOT Challenge[8]提供了行人跟踪的一系列数据集。KITTI[9]和Waymo[10]提供了自动驾驶场景下的行人和车辆跟踪的基准数据集。
多目标跟踪问题的常见范式是两步法,即“先检测,后关联”,总共分为四个基本步骤[11]:目标检测、轨迹预测、亲和矩阵计算、关联结果生成。两步法的经典的工作有Deep Sort[1]、JDE(Joint Detector and Embedding)[16]、FairMOT(Fair detection and re-identification MOT)[17]和GM-Trakcker(Graph Matching Tracker)[18]等。Deep SORT[1]提供了一种非常简单但是有效的方式:通过卡尔曼滤波[12]和深度行人重识别网络分别进行运动预测和表观特征提取,然后通过匈牙利匹配对轨迹进行关联。后续的工作基本上是对于Deep SORT 的改进[13-18]:JDE 使用同一个骨干网络生成目标检测框和行人重识别的特征,使整个多目标跟踪的算法获得了接近实时的性能。FairMOT 分析了检测和行人重识别问题之间的冲突,并提出了针对性的解决方案:降低表观特征复杂度并使用基于Center Point 的目标检测模型。GM-Tracker 将多目标跟踪问题建模成一个图匹配的问题,并且提出了一种可微分的多目标跟踪算法。
1.2 密集场景下的行人跟踪
在密集场景中,普通的多目标跟踪模型常常会得到较差的跟踪结果,这是因为行人之间的遮挡会导致很多的漏检;此外,检测得到的全身框之间的重叠会导致提取到的行人重识别特征存在很多噪声。MOT20[19]是评估密集场景下的行人跟踪的基准数据集。一些模型试图在存在大量漏检和表观特征噪声的情况下通过全局优化[4]的方式优化跟踪结果;另一些模型试图解决漏检问题,以及对表观特征进行去噪声的处理[2,5]。在这之中,文献[2]中设计了一种新的行人头部跟踪的范式,通过跟踪密集场景中的遮挡较少的行人头部,自然地解决了漏检的问题。
文献[2]中提供了行人头部跟踪的基准数据集HT21,该数据集共有4 段训练集和5 段测试集,为了能够和全身跟踪的模型进行对比,HT21 中的部分训练集和测试集是从MOT20 的数据中重新标注得到的。此外,文献[2]中还提供了一种行人头部跟踪的模型HeadHunter-T,这是一种基于粒子滤波的速度模型和基于行人头部的色彩直方图的表观特征的行人头部跟踪模型。
2 融合全身表观特征的行人头部跟踪模型
多目标跟踪的目标是获取特定类别的物体的多条轨迹。在行人头部跟踪的任务中,类别指的是行人的头部。本文首先介绍通用行人头部跟踪的基本流程,然后介绍如何提取具有判别力的表观特征。
2.1 行人头部跟踪的通用流程
2.1.1 行人头部检测
多种目标检测器都可以用来检测行人的头部,比如Faster R-CNN[20]、RetinaNet[21]等。在这些 检测中,CenterNet[22]是一种一阶段的目标检测器,这一检测器可以利用DLA(Deep Layer Aggregation)[23]网络作为骨干网络。DLA网络比较小的下采样率以及CenterNet 一阶段的特性使CenterNet 特别适合用来进行实时的行人头部检测。本文将会使用CenterNet 作为默认的行人头部目标检测模型。
2.1.2 帧间行人头部关联
第t帧的检测框di∈Dt可以在第t帧使用CenterNet 检出。为了简化模型,本文使用了Deep SORT[1]中的通用流程,介绍如下。
为了建模同一物体在视频中的时间连续性,本文使用了卡尔曼滤波[12]来建模行人头部的运动。当新的一帧出现时,卡尔曼滤波可以预测过去的跟踪在当前帧的位置。利用位置信息和表观特征可以计算两个亲和矩阵m(1)和m(2),其中:
其中:dj是当前帧检出的目标框的位置;yi是已跟踪的目标的位置;是yi在各个方向上的标准差是 第k个行人在第t帧的表观特征;为第i个检测框的表观特征。卡尔曼滤波在每一帧可以分为两个步骤:预测和更新。预测时计算每一个Tracklet 在当前帧的位置;更新时先通过两个亲和矩阵进行匹配,然后将预测的位置和检测得到的位置进行加权得到最终的位置预测。
为了能够处理行人头部消失和新的行人头部出现,本文设置了两个阈值t1和t2。当m(1)(i,j) <t1或者m(2)(i,j) <t2时,认为新的目标出现。最终的亲和矩阵设置为这两个矩阵的加权求和m(i,j)=λm(1)(i,j) +m(2)(i,j),在计算得到最终的亲和矩阵之后,对亲和矩阵进行二分图匹配可以得到最终的分配结果。如果一个已跟踪的目标没有被分配新的检测框,则通过恒定的速度更新目标的位置。如果此目标在连续的Td帧都没有检测框分配,这一目标被认为是已经离开了监测区域并且将会被删除。在本文的模型中,表观特征和将使用全身的表观特征进行计算。
2.2 基于行人全身表观特征的行人头部跟踪模型HT-FF
尽管行人头部检测框表观特征稳定而且易于提取,但是实验结果表明行人头部框的表观特征不具备足够的判别力,这会损失行人头部跟踪的性能,特别是在远距离的情况下。为了能够得到更精确的跟踪结果,本文尝试了多种跟踪线索,最后发现全身的表观特征对行人头部跟踪来说是一个具有良好判别力的特征。
然而,利用全身的表观特征进行行人头部的跟踪具有两个难点:如何利用头框得到精准的全身框;如何从严重遮挡的行人全身框中提取去噪声的表观特征。针对这两个问题,本文接下来将详细介绍所提出的模型。
2.2.1 锚框引导的动态全身目标框生成
相较于头框的特征,全身框的特征更富有纹理而且对距离不敏感,这使它成为行人头部跟踪的合适的特征。然而,在拥挤场景下检测全身框十分困难,这是因为全身框彼此之间的相互遮挡带来了大量的漏检[2],而行人头部之间的遮挡较少,漏检也因此更少,这启发了本文利用头框来动态地生成全身框。
为了使生成的目标框更加精确,本文采用了两阶段法来得到全身框:第一阶段,利用固定的比例生成全身锚框(Anchor);第二阶段,利用R-CNN[6]的回归分支对全身锚框进行修正,进而得到一个更精确的全身框的预测。实验表明,相较于单纯的用固定的比例生成全身框,利用R-CNN 的回归分支可以精确地修正全身框。
给定第t帧的头框检测结果dj∈Dt,dj=(xj,yj,wj,hj),其中:xj,yj表示头框左上角的坐标,wj,hj表示头框的宽度和高度。本文用表示用固定比例生成的锚框,固定的比例设置为:
在得到这个锚框之后,本文从图像中裁剪出全身框,将它调整到128×224 大小之后输入神经网络预测回归值。为了提升速度,本文采用Resnet-18 作为锚框修正的骨干网络,在将裁剪出的图像界入Resnet-18 之后经过一个全连接层可以得到边框回归的值。与R-CNN[6]的做法相同,本文利用网络输出的回归值对固定比例生成的锚框进行修正,可以得到最终预测的精确的全身框。
2.2.2 去噪声的全身表观特征提取
表观特征是行人头部跟踪问题中十分重要的线索,精确的表观特征是行人头部被遮挡后保持身份的关键线索。然而,在拥挤情形下,行人的全身框之间会存在相互覆盖的问题,这导致提取的表观识别的特征存在大量噪声。为了解决这一问题,本文利用了人体姿态估计[24]的结果来对表观特征进行去噪声,人体姿态估计为找到行人未被遮挡的部分提供了天然的掩码。
本文使用了Alpha-pose[25]来预测人体姿态特征点。使用Alpha-pose 可以在每个行人的全身框中得到18 个姿态关键点的位置和置信度。本文认为低置信度的产生来源于遮挡,因此设置了一个阈值s来筛除掉置信度过低的关键点,对第t帧第m个行人目标框,最后只留下关键点pi∈Ptm。为了将姿态估计的结果映射到原图,本文以行人关键点的预测为中心,生成二维的高斯分布的热力图。生成的热力图记为Htm。每一个热力图可以通过下采样来保持与特征图大小一致。生成二维的高斯分布的热力图的方式如下:
其中,σ是超参数供后续调整。
生成的热力图表征了原图中的可见的未被遮挡的部分,通过下采样可以得到与特征图大小相同的热力图。本文采用了双线性插值的方式对热力图进行下采样,使热力图和特征图采样为同样大小。本文希望下采样之后的结果可以帮助引导生成去噪声的行人重识别特征。如图1 所示,首先图像通过Resnet-50[26]网络得到行人重识别的特征图Ftm,对特征图进行平均池化操作可以得到全局的行人重识别特征fg,本文将下采样之后的热力图Htm与Ftm相乘,然后进行平均池化可以得到姿态引导的行人重识别特征fp。实验结果表明,同时考虑这两个特征将带来最好的效果。连接这两个特征可以得到fcat,即本文所使用的姿态引导的行人重识别的全身特征。
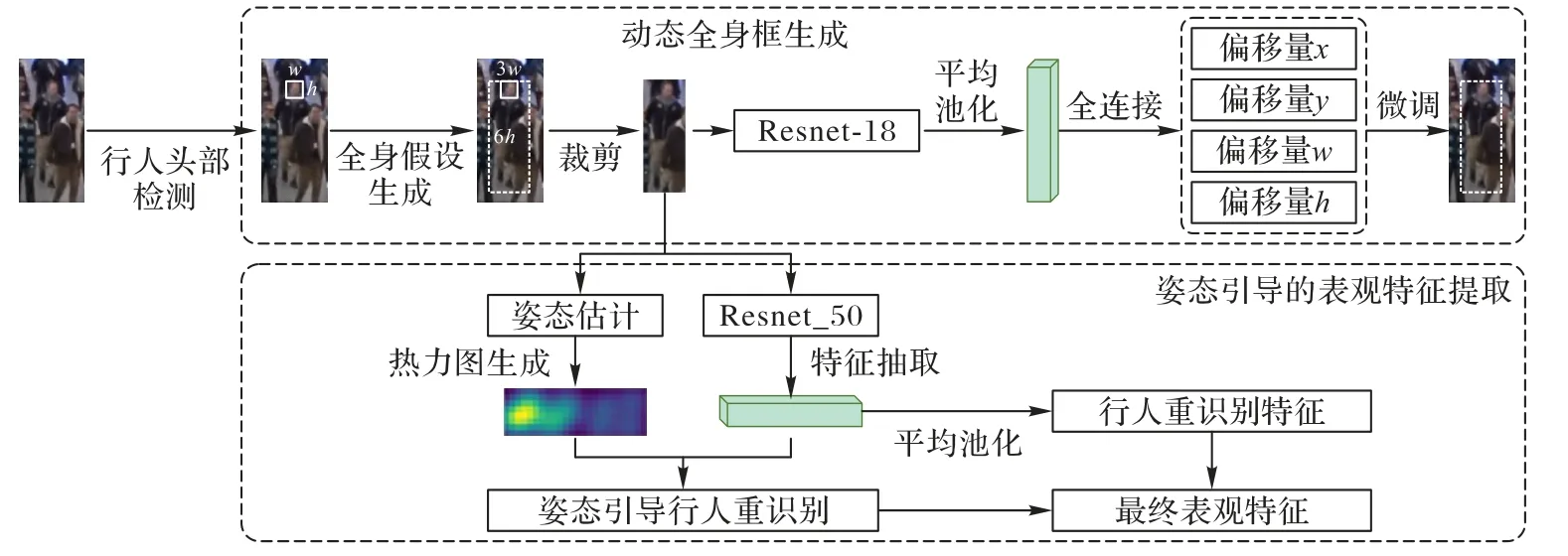
图1 本文模型的流程Fig.1 Flow of the proposed model
3 实验与结果分析
3.1 数据集和评价指标
Head Tracking 21(HT21)[2]是拥挤场景下行人头部跟踪的基准数据集。该数据集中,每一帧的平均头部数量达到了178,因此非常适合评估拥挤场景下的行人头部跟踪。与MOT Challenge[8]的其他数据集一样,该测试集的标注也不开放,因此只能在官方提供的服务器上提交测试。与HT21 相同,本文采用了误检数(False Positive,FP)和漏检数(False Negative,FN)来评估检测性能指标,并利用IDs(ID switch)数量来评估多目标跟踪器跟踪性能指标;此外,为了综合评估检测和跟踪性能,还使用了MOTA[7]和IDF1[8]对模型进行综合评估。为了评价动态全身框生成的性能,本文不仅采用了平均精度均值(mean Average Precision,mAP)指标,还计算了动态全身框生成的AP50 和AP75,这是因为AP50 和AP75只有在预测值与真实值IOU 大于0.5 和0.75 时才作为一次命中,因此能够更准确地刻画所生成检测框的紧致程度。
3.2 实验设置
本文使用了DLA-34[23]作为头部检测器的骨干网络,模型的参数首先在Crowdhuman 数据集[27]进行训练作为初始化,然后在Head Tracking 21 的训练集上面训练了30 个epoch进行微调,模型的批处理大小设置为12。对于姿态引导的行人重识别网络,采用Resnet-50 作为骨干网络,使用Alphapose[25]生成人体姿态估计结果。本文在CrowdHuman 数据集训练动态行人全身框生成网络,这是因为CrowdHuman 数据集有对同一个人的行人头部和全身框的标注。为了加快推理,本文使用Resnet-18 作为R-CNN 的骨干网络。使用Adam[28]训练器并且采用0.000 1 的学习率训练8 个epoch 之后收敛。在跟踪模型中,本文发现λ=0 可以得到最好的结果,这意味着在亲和矩阵的计算中,只使用表观特征就可以得到最好的结果。这是因为行人的头部位置波动较大,因此在采用较好的位置阈值之后就无需再使用位置作为关联的亲和矩阵的计算。本文设置Td=30 来得到最佳的关联的性能。
3.3 消融实验结果
为了验证全身特征相较于行人头部特征的优越性,本文设计了以下消融实验:使用行人头部的行人重识别特征来作为跟踪的线索。此外,使用全身特征引入了两个模块:动态的全身框的生成和姿态引导的行人重识别特征生成。本文分别对这两个模块进行了消融实验。
3.3.1 全身特征与行人头部特征
如表1 所示,与使用行人头部的行人重识别的特征相比,HT-FF 使用了全身的重识别特征,有更少的IDs,意味着本文的模型更不容易丢失同一身份的目标框。尽管行人头部的表观特征更加符合直觉,本文的实验结果表明全身的表观特征更加鲁棒,能够在困难的跟踪场景下保有身份信息。

表1 消融实验结果Tab.1 Ablation experimental results
3.3.2 姿态引导的表观特征
如表1 所示,不使用姿态作为引导,而是直接提取的表观特征的跟踪模型获得了更差的跟踪结果,这是因为在密集场景下,行人的全身框之间存在大量的相互覆盖,进而给行人重识别带来了更多噪声,使用姿态可以更好地消除这些噪声,使模型关注行人的可见区域。
3.3.3 动态生成全身框
如表1 所示,采用固定比例生成的全身框相较于动态的全身框生成的结果也会带来更多的IDs。在接下来的一节中,本文将会详细讲述固定比例生成全身框的模型,并且展示动态生成行人全身框相较于固定比例生成全身框在生成精度上面的优越性。
3.4 动态全身框生成结果
动态生成全身框的模块首先会通过一个固定的比例来生成一个锚框,然后通过R-CNN 的回归分支对锚框进行修正。本文报告了所提出的模型在CrowdHuman 验证集上的检测精度。为了验证本文使用的回归分支对于行人全身框的生成确实有帮助,本文也测试了通过固定比例生成的目标框在CrowdHuman 验证集上的精度。经过调优,本文发现如下的固定比例生成的全身框具有最好的检测精度:
如表2 所示,本文设计的动态生成全身框的模型可以输出更加精确的目标框,固定比例生成全身框的模型得到的MAP 值低于动态生成的MAP 值。此外,本文模型在AP75 上远高于固定比例模型,AP75 只有在预测与GT(Ground Truth)的交并比(Intersetion Over Union,IOU)大于0.75 时才算命中,这意味着本文模型可以生成紧致地包围身体边缘的全身框。

表2 固定比例生成全身框与动态生成全身框的精度对比 单位:%Tab.2 Precision comparison between fixed ratio full-body bounding box generation and adaptive full-body bounding box generation unit:%
3.5 Head Tracking 21测试集上的结果
与其他MOT challenge 上的数据集相同,HT 21 的测试集并不公开,因此只能提交到服务器进行测试。如表3 所示,本文模型在MOTA 和IDF1 上超过了对比模型,说明本文模型相较于前人模型更有效。
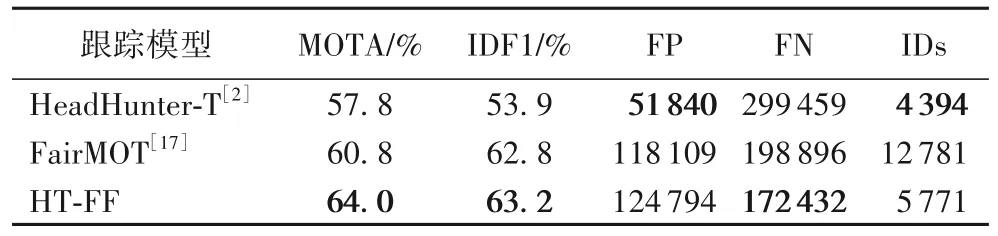
表3 不同模型在Head Tracking 21测试集上的结果对比Tab.3 Results comparison of different models on Head Tracking 21 test set
3.6 使用同样检测结果的跟踪结果
表3 为使用不同的行人头部检测模型的结果,这可能给MOTA 和IDF1 的指标带来不公平的对比。为了说明融合全身信息的行人头部跟踪模型的有效性,本文使用了同样的检测结果输入不同的跟踪器中。与文献[2]相同,本文在训练集上对这些结果进行对比。如表4 所示,在使用同样的检测结果的前提下,本文模型超过了SORT(Simple Online and Realtime Tracking)[29]和HeadHunter-T[2],验证了本文设计的跟踪模型的有效性。

表4 使用同样的行人头部检测结果的跟踪结果Tab.4 Tracking result based on same detection results
3.7 结果讨论
3.7.1 动态生成全身框
为了直观展示本文模型子模块的有效性,在图2 可视化了动态的全身框生成结果。可以看到,本文模型可以生成紧致地包围身体边缘的目标框。

图2 动态生成全身框结果Fig.2 Results of dynamic full-body bounding box generation
3.7.2 人体姿态估计热力图的可视化
本文可视化了人体姿态估计得到的热力图,如图3 所示,热力图很好地刻画了全身框在遮挡情况下的可见区域。

图3 姿态估计热力图的可视化结果Fig.3 Visualization results of pose estimation heatmaps
3.7.3 行人头部跟踪结果
此外,图4 将HeadHunter-T[2]模型与本文模型的结果进行了可视化。由于HeadHunter-T 只利用了头框的表观特征作为特征,可以看到,在距离较远的情况下,HeadHunter-T 更容易发生ID switch,因而跟踪结果较差。

图4 本文模型与HeadHunter-T对比(图中帧选自序列HT21-01)Fig.4 Comparison of the proposed model and HeadHunter-T(frames on image are selected from sequence HT21-01)
3.7.4 全身跟踪结果
图5 展示了本文设计的模型在MOT20 上提交的结果,MOT20 是密集场景下行人全身跟踪的基准数据集,利用头框动态生成全身框,可以得到全身跟踪的结果。

图5 本文模型在MOT20测试集上的结果Fig.5 Results of the proposed model on MOT20 test set
4 结语
本文提出了一种新型的融合全身表观特征的行人头部跟踪模型HT-FF,设计了动态的全身检测框生成网络和姿态引导的表观特征提取网络,实现了利用行人全身检测框内的全局表观特征为线索进行行人头部的跟踪。所设计的模型在行人头部跟踪的基准数据集上验证了有效性并达到了当前最好的效果。
本文提出的全身表观特征引导的行人头部跟踪HT-FF与传统模型的本质区别是使用了不同部件的位置与特征线索分别建模运动与表观特征,这是行人多目标跟踪中的一个新的范式。在未来,将会探究如何找到更全面的线索,以及设计如何自动发掘这些有用线索的机制。
