中小学课堂视频多模态分析模型的建构与应用研究
2023-05-23屈曼祺李宝敏杜龙辉
屈曼祺, 李宝敏, 杜龙辉
(1.华东师范大学 教师教育学院, 上海 200062; 2.华东师范大学 教师发展学院, 上海 200062)
一、问题提出
教育信息化的迅猛发展对教师的教育教学提出了更高的要求。2018年1月,中共中央、国务院《关于全面深化新时代教师队伍建设改革的意见》提出,教师要主动适应信息化、人工智能等新技术变革,积极有效开展教育教学。[1]同年4月,教育部印发《教育信息化2.0行动计划》,提出要发挥技术优势,变革传统模式,推进新技术与教育教学的深度融合。[2]在此背景下,中小学普遍引入智慧教室、智能录播系统等包含课堂实录功能的设备,为教师的专业发展提供硬件支持。但在当前较为充足的信息技术支持下,中小学教师在听评课过程中仍普遍存在仅凭经验而不能有效利用信息技术的现象。课堂视频本身囊括完整的课堂环境和教师-学生反应,保留了师生的行为与面部表情等反应数据,因此课堂视频理应通过非单一言语渠道进行剖析解释,[3]这为开展多模态分析提供了良好条件。因此,如何有机融合教师的经验和智能分析技术,促进他们合理、适度、准确地利用信息技术手段分析与处理课堂视频中的教学行为,更好地理解教学场景中的关键事件,提升他们教学行为有效性,是深化教研、助力教师专业成长的关键。基于此,笔者拟在梳理课堂视频多模态分析理论的基础上,界定其维度,从教师和学生视角构建课堂视频多模态分析模型,以引导中小学教师从依靠自身经验进行教学改进转变为基于课堂视频的循证教研。
需要说明的是,主流的多模态分析主要分为两支。一支基于系统功能语言学、社会符号学,最初主要服务于二语习得领域,在这个取向上的多模态分析指的是各种功能符号如话语、行为、声音、颜色等。这些功能符号在教学过程中被用来进行意义表征,从而完成教学目的。[4]另一支则依靠信息科学的支持,使用先进的传感器等信息技术与设备(如眼动仪、脑电仪等),通过处理过程性学习数据来研究课堂复杂情景中的学习问题。[5]而在课堂视频的情境下,穿戴式设备会对学生的自然学习状态造成干扰。所以尽管本研究试图融合符号系统取向的多模态以及技术数据取向的多模态,对关键事件进行质性的描述性分析,再通过智能技术的手段为分析提供证据支持,但其中不包含学生的直接生理数据。
二、研究依据
(一)价值取向
进行人机协同的课堂视频多模态分析的最终目的是通过分析教师课堂教学,实现教学改进和学生在课堂教学中的深度学习。崔允漷教授将深度学习界定为认知参与:在复杂的环境下,表现出高度投入、高度认知参与并获得意义的学习。[6]1956年,布卢姆在《教育目标分类学》中把认知领域分为知道、领会、应用、分析、综合、评价六个层次。[7]一般认为,知道、领会、应用三个方面属于低阶思维,即浅层学习;分析、综合、评价三个方面属于高阶思维,即深度学习。布卢姆提出目标分类之后,安德森进一步把认知过程分为记忆、理解、应用、分析、评价和创造六个层次。[8]一般认为,记忆和理解属于低阶思维,应用、分析、评价和创造则属于高层次的思维。在这一深度学习分类的指导下,教师课堂视频的分析以改变传统课堂中重复性的知识记忆、提升学生分析问题和解决的能力、锻炼学生的高阶思维为价值取向。
(二)理论基础与维度界定
对课堂视频进行多模态分析首先要对课堂要素进行维度分类。钟启泉教授提出,“课堂教学是一种以教材为媒介,教师的教授活动与学生的学习活动这三者之间的互动过程”[9],也就是说,课堂教学研究蕴含于具体的课堂互动研究中。蔡楠荣提出,按照课堂互动的媒介,课堂互动大致可以分为言语互动和非言语互动。[10]基于此,笔者从言语互动和非言语互动出发,在社会文化理论、具身认知理论与情感教育理论的基础上,选取了三个有价值的模态分析切面,即言语互动对应话语互动、非言语互动对应行为以及情感的互动表达。而话语通常伴随着行为表现与情感传递,行为亦包含着情感表达,所以三者并不是割裂的,而是各有侧重,三维度的关系如图1所示。
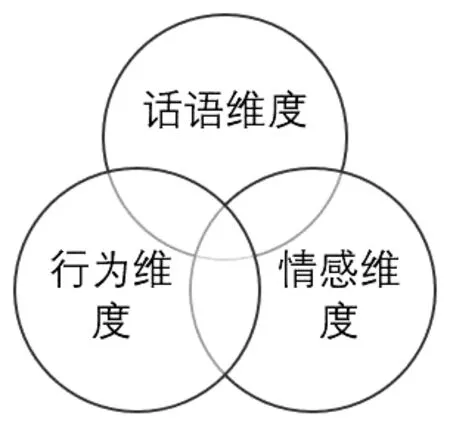
图1 课堂视频多模态分析的三维度关系
1.基于社会文化理论的话语维度
本研究对话语维度关注的理论基础来源于社会文化理论。中介说、内化说是社会文化理论的核心。[11]中介说认为,人们的知识学习需要通过物质或符号工具作为中介,并认为语言是高阶认知的符号;内化说认为人的认知是社会活动的结果。社会文化理论指导下的学习观认为学习是一个不断内化的过程,而这样的内化离不开互动的情境。兰托夫将内化过程分成两个阶段:第一个阶段是通过人际交流获得文化符号工具;第二个阶段是自我交流,通过个人努力将上一个阶段获得的文化符号工具转化为自我的心理活动工具。[11]也就是说,学习是先进行社会交际,再转化为个体内部心理活动的过程。课堂视频本身包含学生学习的完整情境,通过课堂视频分析可以看出学生的社会性发展。因此,本研究基于社会文化理论主张将人与社会、语言与文化融为一体的哲学立场,关注课堂视频中师生话语互动的社会意义建构。
2.基于具身认知理论的行为维度
本研究对行为维度关注的理论基础来源于具身认知理论。具身认知理论认为人的身体在认知过程中起到了非常重要的作用,认知是通过身体的体验及其行为活动方式而形成的。[12]维果茨基以及皮亚杰在关于儿童认知能力发展的论述中均有具身认知的思想。维果茨基主张“高级水平的思维活动是人类最初的身体活动(感知运动)的内化(internalization)”[13];皮亚杰认为认知过程是一个建构主义过程。通过连续不断的同化与适应,主体图式与客观对象间达到最终的认知,而这样的主体图式本质上就是一种“行为图式”(schemes of action),这样的行为图式最初存在于身体的感官运动中。[14]只不过两位学者并没有将身体的行为参与作为学生认知的主要途径。具身认知理论指导下的课堂视频分析更强调参与学生的真实体验,注重课堂中的身体语言和课堂气氛对学生的带动作用,以及从传统纯粹的脑部活动到身心投入的体验式学习。在这一理论指导下,本研究关注课堂视频分析中教师与学生真实行为的意义。
3.基于情感教育理论的情感维度
对课堂中师生情感的关注是对教育本质问题的关切,是育人价值的体现。朱小蔓教授对情感教育的定义为“在学校教育、教学中关注学生的情绪、情感状态,对那些关涉学生身体、智力、道德、审美、精神成长的情绪与情感品质予以正向的引导和培育。”[15]越来越多的实证研究表明,学生学习的积极性、学生发展与学习环境以及师生关系密切相关。而情感的难以言喻和转瞬即逝使其在课堂中难以被观察,但情感与学生认知密不可分。因此,本研究关注在课堂视频中通过师生情感的“现象”把握师生的情感体验,也就是说,在研究中要根据话语、身体等确实外显的要素来实现师生情感的“转喻”。转喻是在同一认知域内,用易感知、易理解的部分指代整体或整体其他部分。[16]所以情感维度在实际观察中并不独立于话语维度与行为维度,而是以其重要的价值取向和外在体验与两个维度分离开。
三、中小学课堂视频多模态分析模型的建构
基于上述理论分析与维度界定,笔者首先从教师、学生的互动视角构建课堂视频多模态分析模型基本框架,之后通过专家验证对该模型框架进行迭代与修正,并通过对现有智能分析系统的要素归纳,构建课堂视频多模态智能分析模型,服务于教师专业发展中教师课堂自我观察的科学化与精准化。“解因性是人的属性,释义性是人工智能的缺陷”,最后将两类模型的要素进行对齐并分工,实现模型的协同互补。
(一)课堂视频多模态分析模型:质性分析
课堂视频多模态分析模型框架是在社会文化理论、具身认知理论与情感教育理论主张的指导下,课堂环境中教师、学生两主体在教学以及学习过程中所涉及的多模态符号系统。
1.教师视角
在话语维度上,基于经典的“Initiative-Response-Evaluation”(I-R-E)话轮,将该维度的分析要素进一步修改为“表达”“提问”“回应”和“反馈”。“表达”即代表传统的教师开展正常课程讲授活动,其间并不需要学生互动参与,如教师进行课本知识的解读。“提问”则代表教师有意与学生进行互动,邀请学生参与课堂话轮,给予学生发言的机会,如教师针对某一知识点对学生记忆程度的询问。“回应”则为教师在得到学生的回答后,进一步为学生的回答做出的互动反应,不包括对学生回答结果的评价,如对学生零散回答的进一步凝练与归纳。“反馈”则是教师对学生回答的针对性评价,如对学生回答中关键性语句的重复或点评。
在行为维度上,结合过往文献以及实践经验,将该维度的分析要素确定为“声音”“眼神”和“动作姿态”。其中将“声音”进一步细分为“音调”“音量”和“语速”;将“动作姿态”进一步细分为“手势”“体态”与“动态”。在教学中,教师的声音作为话语的物理载体,影响着学生的情绪与课堂氛围。“音调”即同物理意义上的音调,表达声音频率的高低;“音量”同物理意义上的响度,代表着声音的大小;“语速”则为教育情境下特有的要素,代表教师在教学过程中说话的快慢。“眼神”属于课堂社会情境下的默会知识。作为重要的非言语行为之一,眼神有时可替代部分的话语功能,实现师生间的情意表达与人际控制。“动作姿态”为教师身体语言的集中表达,按影响大小可分为局部活动的“手势”、身体系统表达的“体态”与代表教师在教室中移动的“动态”。
在情感维度上,近似经典“I-R-E”话轮,本研究认为完整的情感反应轮同样具有“表达”“识别”与“回应”。情感“表达”以“喜悦”“中性”“急躁”“悲伤”“愤怒”五大基本情绪为主。而课堂并不是一个自由无序的场所,基于公共秩序以及师生不平等权力,情感往往并不是外显的,所以需要情感“识别”。教师情感“识别”的过程首先要“发现”学生的情绪,从而进一步对该情绪进行识读,达到“理解”。在教师捕捉到学生情感后,要做出反应,而这样的情感反应则归为两种:一种是教师对学生情感的选择性忽视,即“冷漠”;另一种是教师对学生情感的“共情”。优化后的教师视角下的课堂视频多模态分析模型如表1所示。
2.学生视角
在话语维度上,学生的话语主要有“回应”“提问”与“表达”。教师具有课堂的主导权,学生通常是被动地通过教师提问或者其他引导而参与话轮。学生课堂话语的起始为对教师的“回应”。在“回应”后学生可能会拥有主动发起话轮的机会,即“提问”。同时,在如翻转课堂、合作学习、探究学习等新型学习方式下,学生还可能拥有在课堂上表达自我的机会,所以在话语维度上也应有“表达”这一要素。
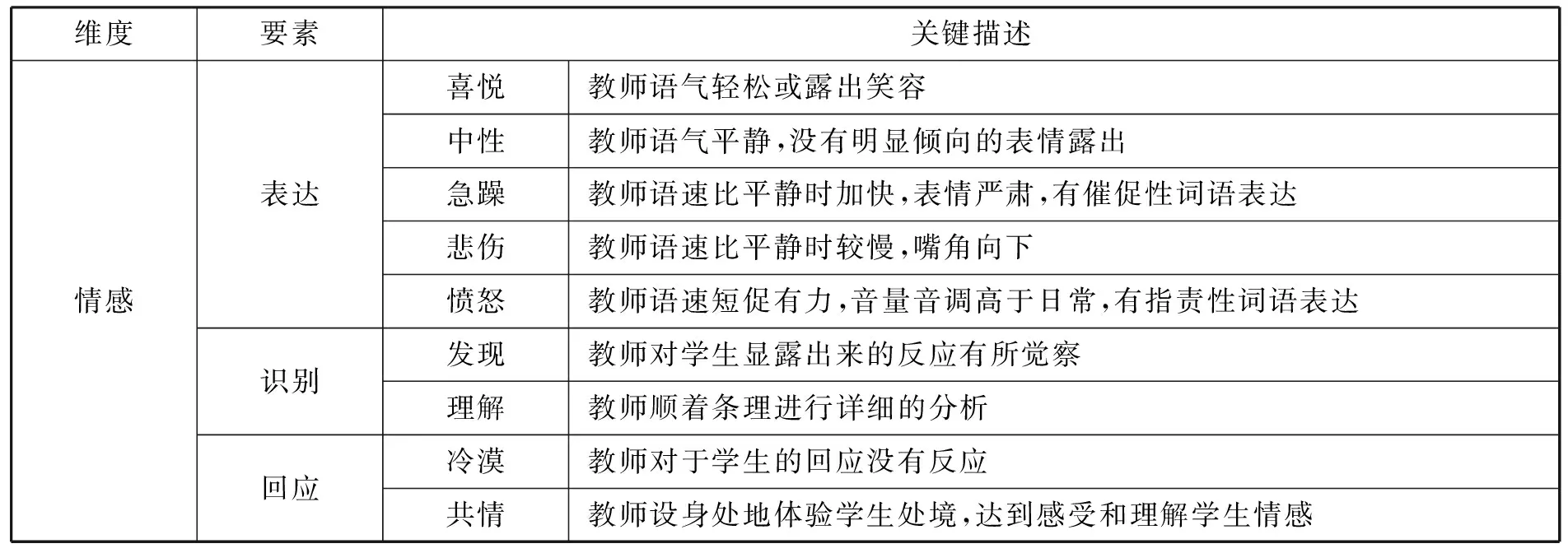
续表1
在行为维度上,由于学生基本坐在固定位置上,所以对其行为有所限制,主要体现为“眼神”以及“动作姿态”。眼睛是心灵的窗户,学生的“眼神”在一定程度上可以反映出学生的注意力与投入度。伴随着学生学习状态的还有身体语言的表达,被称为“动作姿态”。由于“动作姿态”的多样性,又可以进一步从自我动作以及社交行为两方面分为“注意”“观察”“倾听”“书写”“帮助”与“合作”。
在情感维度上,学生的情绪体现为与教师互动的状态。由于与教师权力的不平等,学生会对教师的情绪进行“识别”,具体分为“理解”与“领悟”。二者字面看起来颇为相似,但“理解”是学生对教师情绪或者话语的浅层把握,而“领悟”则可能延伸到学生对教师所授知识的晓悟。同时学生也同样不需要受地位等条件的约束,所以其情感的“表达”要素会更丰富,主要包括“迷惑”“无聊”“中性”“好奇”“喜悦”“焦虑”“沮丧”“愤怒”。优化后的学生视角下的课堂视频多模态分析模型如表2所示。
(二)课堂视频多模态分析模型:量化分析
教育领域一直以来都在为脱离主观性的偏见做出努力。技术天然带有价值中立的属性,所以教育中的很多复杂问题同样希望借助技术进行精准化、智能化的分析与决策。课堂视频作为携带大量信息的数据,同样可以通过以图像识别为代表的信息技术进行智能分析。因此,本研究运用归纳法从当前智能分析系统中提取相关的技术分析要素,构建与前述模型对应的、具有成熟可行性的课堂视频多模态智能分析模型。
与前述质性分析不同,技术取向下的分析则属于量化分析,这样的分析往往忽略课堂的意义情境,将课堂中的话语、行为等视为不同的数据模态。在操作步骤上往往将课堂从时间序列上进行切片划分,然后对单位时间内所涉及的特征模态进行加和计算或比例计算。如果说质性取向下的课堂视频处于微观层面,那么量化取向下的课堂视频则处于宏观层面,其并不关注课堂的动态发生,而是对所有可以识别到的数据特征点进行统计,从而反映课堂的整体状态。
当前较为成熟的智能分析普遍围绕话语维度和行为维度。话语维度的分析主要依靠语音识别技术,识别课堂上的教师话语和学生话语,然后将关键词作为识别的特征点,如以“为什么”为提问的开启词。行为维度的分析主要依靠图像识别技术,通过识别课堂上教师或学生的肢体动作特征,再为其赋予实际意义,如学生“举手—起立”的完成标志着该同学正在进行问题的回复。话语维度以及行为维度智能分析的准确度较高,而情感维度的识别则相对来说拥有较高的误读率,所以在量化模型中没有直接对课堂情感进行分析。
1.教师视角
归纳出教师视角下的多模态智能分析模型如表3所示。
教师视角下的多模态智能分析模型在话语维度上主要聚焦于教师的“提问”与“回应”两个话语要素。“提问”要素分为“是何”提问、“为何”提问、“如何”提问以及“若何”提问。

表2 中小学课堂视频多模态分析模型(学生视角)
“是何”类问题通常用来提问有事实结果的内容,主要反映学生对内容的记忆、理解,如“苹果树是什么种类的植物?” “为何”类问题通常用来询问学生的目的、原因、原理、定律或者逻辑的推理,如“为什么苹果熟了会落地?” “如何”类问题通常询问学生与方法、路径相关的问题,说明怎么样,用什么方法、手段、途径,处于怎样的状态或情况,如“怎样才能知道一个苹果的重量呢?”“如何”类问题培养的是学生的元认知能力,强调在做中学习,在体验中学习。“若何”类问题通常询问学生如果条件发生变化后可能产生的新结论,如“如果没有起重机,怎样才能知道一头象的重量呢?”“若何”类问题属于培养学生创新思维的问题,强调学生发散与创造性的学习。
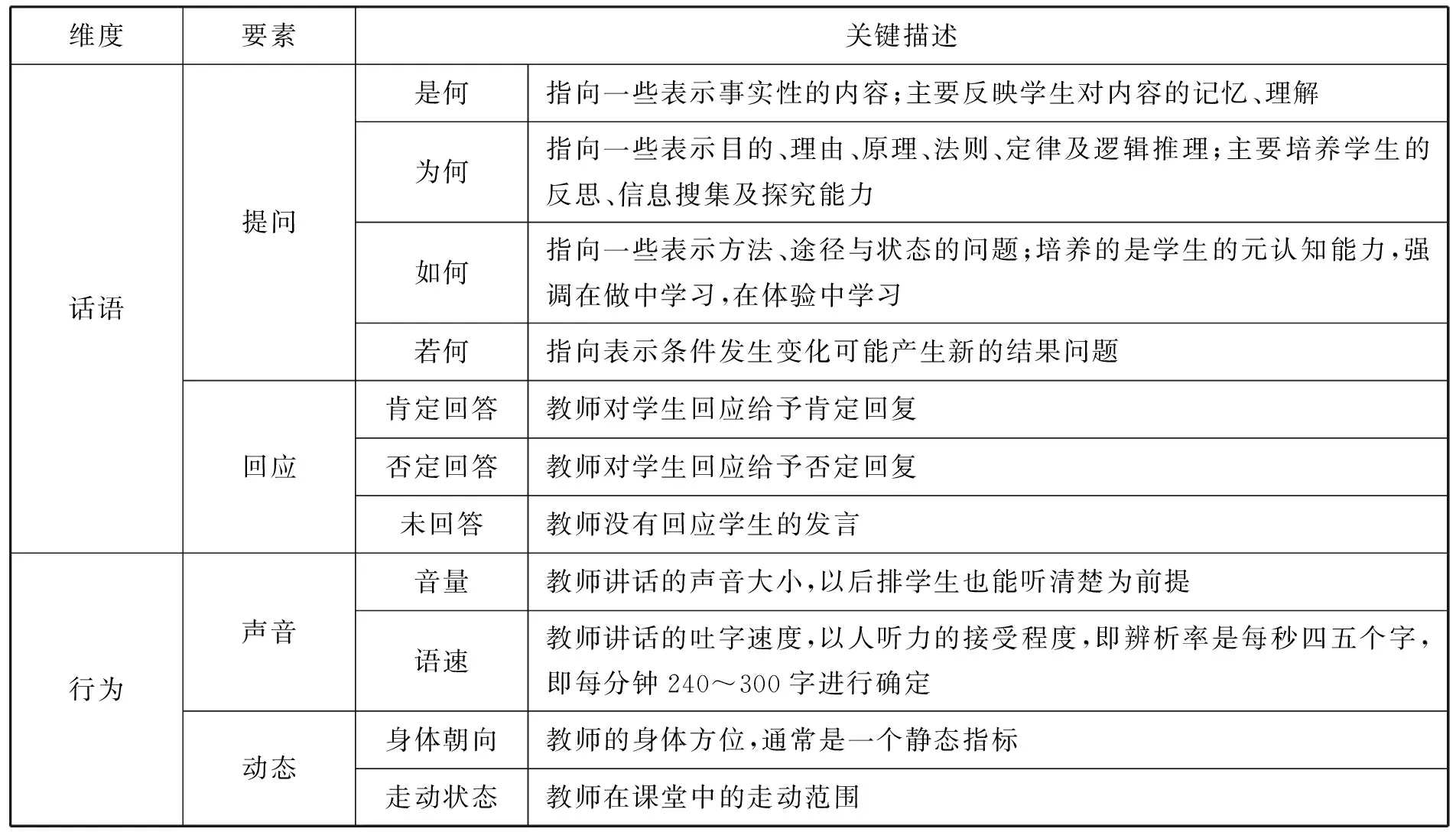
表3 中小学课堂视频多模态智能分析模型(教师视角)
教师的“回应”则又被分为“肯定回答”“否定回答”和“未回答”。课堂视频的智能分析通常以比例的形式体现,教师肯定回应占比较高,表明教师十分注重对学生的肯定和鼓励;若教师多次对学生的发言不进行回应,则反映出教师对学生的忽视与冷漠。
教师视角下的多模态智能分析模型在行为维度上主要聚焦于教师的“声音”与“动态”两个行为要素,行为要素的量化通常按照包含具体数值的常模标准来确定(常模为该区域同类课程的相同教师行为的数据,如该分析课程的此类教师行为占比大于该区域或全国同类课程的此类教师行为占比)。“声音”要素的识别又分为“音量”和“语速”。对于“音量”,依据所在场合的大小划定常模标准,以后排的学生也能听得非常清楚为前提。如果是 10 人之内的小班,建议用一般说话的声音即可,约30~40分贝;面对10~50人,声音大致上要提高到平时说话的1.2 倍,约50分贝;面对50人以上时,音量约为平时的1.5倍最佳,约60分贝左右。对于“语速”,根据一般情况确定常模标准,以人耳的接受程度,即辨析率是每秒4~5个字,即每分钟240~300字进行确定。“动态”行为要素包括“身体朝向”与“走动状态”。“身体朝向”为教师的身体方位,通常是一个静态指标;而“走动状态”则体现教师的走动范围,通常反映教师的行为动态。
2.学生视角
归纳出学生视角下的多模态智能分析模型如表4所示。

表4 中小学课堂视频多模态智能分析模型(学生视角)
学生视角下的多模态智能分析模型在话语维度上主要聚焦于学生的“回应”要素。“回应”要素又被细分为“机械性回答”“记忆性回答”“推理性回答”以及“创造性回答”。该分级依据深度学习理论,“机械性回答”指学生的回应并没有认知参与与信息加工,比如对教师话语的简单重复或对他人回答的模仿跟随;“记忆性回答”则是学生仅依靠对知识的记忆进行回应,比如对学科名词的回答;“推理性回答”已经到了高认知层面,代表学生有对所接收材料的分析过程,从而基于信息获得的因果或者相关性进行回答;“创造性回答”在布卢姆深度学习塔中位于最高认知阶段,代表学生可以对信息进行迁移运用,多体现在以写作为代表的课堂任务中。
学生视角下的多模态智能分析模型在行为维度上主要聚焦于学生的“动作姿态”要素,进一步细分为“举手”“站立”“坐姿不端”“打哈欠”“注意”“书写”与“合作”。这些行为都有较为明显的特征动作体现,识别准确度较高。其中“举手”“站立”“坐姿不端”“打哈欠”都与日常理解相符,所以不进行额外解释。而“注意”“书写”与“合作”则与课堂视频多模态分析模型中学生视角行为维度中的分析要素相同,故不进行重复解释。不论是话语维度的“回应”要素还是行为维度的“动作姿态”要素,在智能分析中都以百分比的形式呈现。
(三)课堂视频多模态分析双模型的要素
为了更好地实现从理论域到实践域的转化,需要在课堂视频多模态分析模型与课堂视频多模态智能分析模型的基础上,厘清分析要素,为方法的实操应用做准备。
1.教师视角
教师视角下的课堂视频分析要素如表5所示。
相比于可以人工分析的要素,由于识别技术的限制,教师视角下技术分析的要素仅有四项,即“提问”“回应”“声音”“动态”。技术分析的独特之处在于数理统计的意义,人工无法对数据进行实时采集与统计,因为需要耗费大量的时间。从表5可以看出,所有智能系统可以分析的要素,都可以进行质性分析,智能系统可以为分析提供数据佐证,而人工则可以进一步在教育情境下对有意义联结的教与学过程进行分析。除了可以被技术分析的四项要素,其他要素如“反馈”“眼神”则更为微观,暂时只能通过人工进行质性分析和解释。

表5 教师视角下的中小学课堂视频分析要素
2.学生视角
学生视角下的课堂视频分析要素如表6所示。
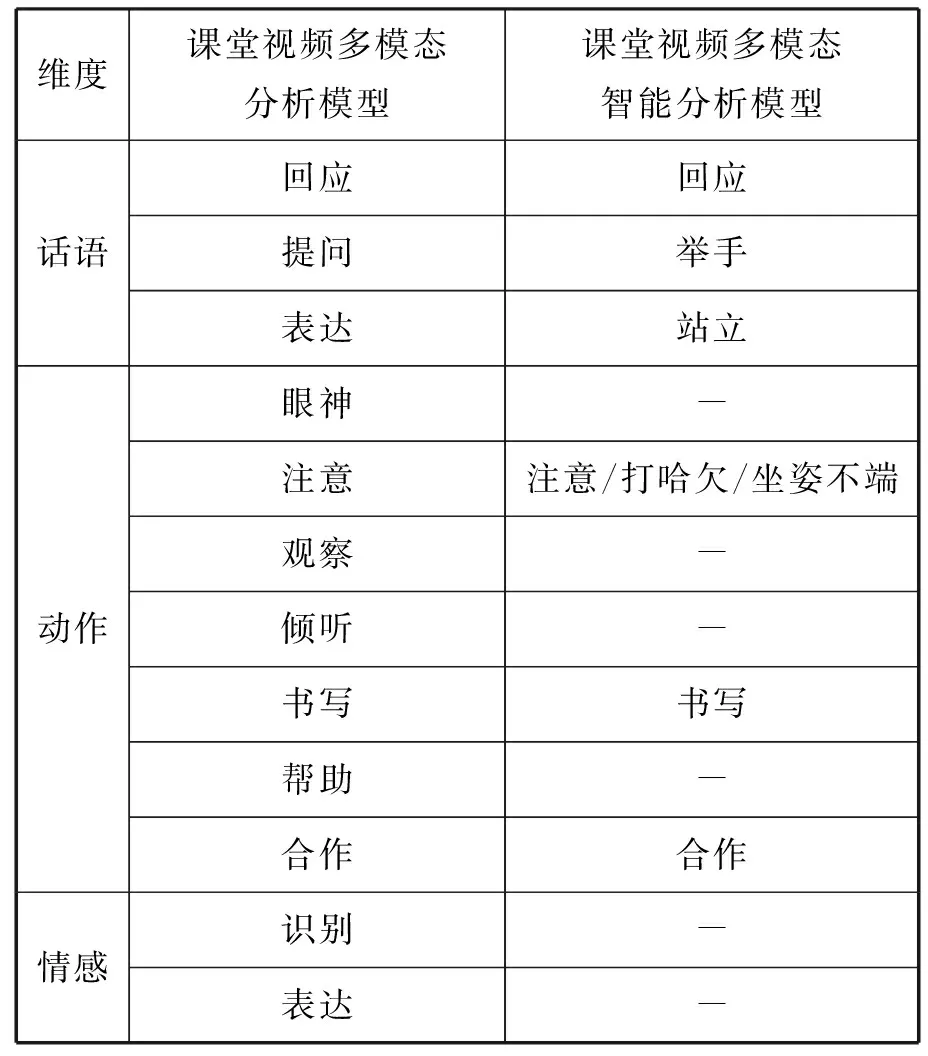
表6 学生视角下的中小学课堂视频分析要素
学生视角下课堂视频分析要素可以更明显地体现出智能分析系统释义性缺失的特点,从表6可以看出,智能分析系统非常依赖于客观具体动作的识别,如“提问”要具象为“举手”,“注意”则需要依赖于“打哈欠”“坐姿不端”这样的身体表现。同时,智能系统也无法准确地理解课堂中的情绪。所以当前的智能分析仍暂时只能作为课堂视频分析的部分依据,主要还是需要人工分析来赋予意义。
四、中小学课堂视频多模态分析模型的应用
展示课堂视频多模态分析模型如何应用,进而引导教师学会自我观察,从依靠自身经验进行教学改进转向基于课堂视频的循证教研,开展基于视频分析的专业研究,是本研究的意义所在。笔者以云南省某市的教育帮扶项目中一位教师讲授如何从加法算式转换为乘法算式并组织学生进行看图列式计算练习为教学关键事件进行应用研究。具体案例题目共有两道,要先写加法算式,后写乘法算式,教师要求学生们在草稿纸上完成练习。本案例聚焦课堂教学的即时评价问题。
(一)案例分析
通过案例分析发现,教师对学生学习情况的即时评价有误。在该案例中,教师在第一道练习题后判断学生掌握了列加法算式以及将加法算式转换为乘法算式这一知识,但实际上仅有少部分学生掌握。
在此教学关键事件中,教师多次提问“几个几?”的问题,试图引导学生从图像中抽象出数字关系。(1)在此案例描述中,T表示教师,S表示学生,Sn表示很多学生。用以下符号表示视频中学生或者教师的声音、表情等,(-):模糊音;…:犹豫;——:声音延长。讲解第一道练习题时:
T:老师想问一下,在这道题里,有几个几?
S1:三个五(-)
Sn:三个五——
S2:不是…
T:几个几?(教师惊讶反问,视频画面中呈现教师惊讶表情)
S3:五个三。
Sn:五个三——
在第一次练习中,出现了由一个同学的错误导致后面同学集体盲目跟随错误答案的现象,这种现象的出现至少可以说明大多数同学并不能分清楚类数与个数的不同。教师也意识到了这一点,进而有一个详细的描述性回应:
T:你看,这里有三个,这里有三个,这里有三个,这里有三个,这里有三个(教师手势画圈,表示“整体”集合,视频画面中呈现教师动作)。那我们把这三个看成一个整体,对不对?它是一个整体,两个整体,三个整体,四个整体,五个整体是不是这样的?所以有几个几?
Sn:(沉默)
T:几个几?
S4:五个三。
Sn:五个三。
T:五个三。
T:那我们写加法算式的时候很简单。它是三,它是三,它是三,它是三,它是三。把它们都加起来是不是这样的?把这几个都加起来,就是它的加法算式。
这样面向集体的询问尽管起到了一定的效果,但在沉默后的正确回答仍是由少部分同学(S4)引发的。而此时有许多同学其实眼神并没有看向黑板区域,注意力分散(视频画面中,可清晰看到多位学生的视线并未聚焦于黑板区域),这也是学生之前短暂沉默的原因之一。
第一题讲毕,教师询问学生:
T:有没有写对?
Sn:对了。
这一次教师并没有意识到仅有少部分学生掌握了这一内容,她对学生学习情况的判断仅通过问询学生是否写对,而这一评价实际上是学生的自我评价,具有很大的主观性。教师收到绝大多数同学的自我评价为“写对了”,并且也相信了这一单方面自我评价:
T:…下一个!这道题的话我们就不在草稿纸上写了,因为大部分同学基本上都会了对不对?同学们都会了…
但学生是否真的已经掌握了呢?这一问题可以从学生做第二道练习题的情况中得到答案:
T:这里有几个几?
Sn:(先沉默)五个四。
T:有五个四。这里四个,这里四个,这里四个,这里四个,这里四个,对不对?
S1:对!
T:那写加法的时候,几个几加起来啊?
S:呃…(视频画面中,可清晰看到学生躲避教师视线,面露犹豫)
T:不知道几个几加起来呀?
Sn:呃…
S2:四——
Sn:四——
T:这里的什么?
Sn:四——加——四——加——
T:是不是都是四?把四都加起来,就是这道题的答案。
在进一步的提问中,学生仍多次出现集体犹豫这一情况,这进一步证明学生对此知识点并未完全掌握。通过智能分析系统同样可以看出,在完整的课堂上,教师共提问103次,说明教师对学生即时反应的收集频率较高,但教师即时评价中的肯定回答占比62.2%,追问占比21.6%,而否定回答占比为0,也就是说,教师在整个课堂中都没有对学生的回应做出否定。这固然表达了教师对学生情感的维护,但也反映出教师对学生回应的分辨力不强,没有办法做到对学生回应的实时纠正。
(二)教学改进
1.即时评价的准度:通过非集体提问的方式,对回答学生的学习程度做出判断
在该教学关键事件中,教师采用向学生集体提问的方式考察学生对知识的掌握程度。这样的做法导致学习程度较弱的学生可能会因为一些程度较好学生的抢答而选择“随大流”,报出集体答案,从而使教师无法分辨学生对知识的掌握程度。所以教师可以通过更为个性化的方式进行提问,根据自己对学生的先前了解以及提问的结果,对学习程度较弱的学生采用较高水平的即时性评价。
2.即时评价的深度:教师应有评价分级意识,对重要的教学内容采取更为细致的即时评价
若想对课堂中动态生成的学生回应做出正确且及时的评价,教师应具有评价分级意识。有研究者以化学学科为例,列举了当前课堂即时评价的六种形式,分别为无应式即时性评价、简单式即时性评价、肯定式即时性评价、点评式即时性评价、提升式即时性评价与素养式即时性评价。其中后三种为高水平的即时评价方式,分别起到帮助学生点题、凝练认知思路以及发展高阶思维的作用。[17]而即时评价形式的选择则应与教学内容挂钩。[18]在上述教学关键事件中,教师的即时性评价属于盲目的肯定式评价,围绕列加法算式以及从加法算式到乘法算式的转换又是整堂课的重点内容,教师不应急于推进课程教学进度,而是应在学生回答错误时可以进行归因分析,从而实施对症评价。
结 语
课堂视频的分析需要方法融合、师生互动、模态多样。本研究首先在方法层面进行质性分析与量化分析的融合,质性分析对教学关键事件进行意义诠释,量化分析为其分析结论提供数据支持;其次,本研究并未将课堂中学生的“学”与教师的“教”进行割裂单独研究,而是在学生与教师互动成长视角下展开研究,创新视频分析的新范式;最后,从话语、行为、情感三维度下进行融合分析,在真实课堂情境下进行多模态的意义建构。中小学课堂视频多模态分析模型为深描课堂互动,助力教师开展自我专业发展的循证教研提供了有力支持,值得在未来的实践中深入研究。
