密空聚类式交通事故多发路段智能鉴别研究
2023-05-18孙承臻范春生阮永娇陈娅鑫
孙承臻,陈 昕,范春生,张 丽,阮永娇,陈娅鑫
密空聚类式交通事故多发路段智能鉴别研究
孙承臻1,陈 昕1,范春生2,张 丽3,阮永娇1,陈娅鑫1
(1.辽宁工业大学 汽车与交通工程学院,辽宁 锦州 121001;2.辽宁省高速公路运营管理有限责任公司,辽宁 沈阳 110179;3.锦州市公共交通有限责任公司,辽宁 锦州 121000)
以高速公路交通事故记录数据为基础,将聚类算法与核密度估计联动,依据我国对事故黑点的鉴别标准,进行交通事故密度聚类分析,参考我国对事故数据进行分级处理的事故标准,基于聚类结果计算交通事故黑点权重,进行交通事故空间数据核密度估计,并采用GIS技术可视化,运用空间统计方法智能鉴别多发事故路段,对高速公路警示标志设置和路安部门监管重点提供参考依据。通过对辽宁省某区域内的三条高速路段进行交通事故多发路段鉴别,智能鉴别能够有效应对不同交通事故点分布特点,避免简易事故的影响,清晰准确找到事故多发路段的位置。
交通事故;密空聚类;多发路段;智能鉴别
围绕交通运输服务安全应急保障的新趋势新要求,对道路安全检测是智能安全保障的重要前提,通过大数据技术和智能算法对交通事故数据充分分析,鉴别事故多发路段可以及时准确的预防并处理交通事故。谢练等[1]针对现有事故多路段鉴别方法阈值选择的缺点和局限,提出自适应选取阈值的密度聚类方法。王海等[2]应用改进的“优化窗宽的和密度聚类”空间分析方法进行交通事故多发点鉴别。王颍志等[3]通过路网裁剪形成的时空子路段,提出交通事故场景的网络时空核密度估计值作为鉴别指标。Saffet等[4]用核密度分析法和泊松统计方法分析在研究区域内高速公路网络的空间分布。Tessa等[5]运用GIS技术和核密度估计算法研究交通事故的空间特点,并采用k均值聚类算法根据事故数据,寻找交通事故多发点。Thomas等[6]通过分位数回归确定事故多发路段,以及哥伦比亚奥卡尼亚市区内易发生事故路段的危险等级,建立事故频率与路段长度、道路宽度、车道数、交叉口数、平均日交通量和平均速度等特征模型。本文研究密空聚类式方法鉴别交通事故多发路段,将密度聚类算法与核密度估计联动,对两种方法进行整合,用密度聚类根据空间信息划分事故黑点,用核密度估计宽带范围模拟交通事故的影响范围,通过GIS空间技术可视化处理,更加直观表达交通事故多发路段和黑点的位置,对3条高速公路辽宁段交通事故多发路段进行鉴别。
1 交通事故数据空间点分布
2019年公安部交通管理局制定《公路交通事故多发点段及严重安全隐患排查工作规范(试行)》中定义,道路交通事故多发点、段是指3年内,发生多起交通事故或事故损害后果极其严重,有一定规律特点的道路点、段。
高速公路多发点范围为:道路上1 km(含)范围内或收费站、隧道口、匝道口(含加减速车道)、接入口、平面交叉口等点。高速公路交通事故多发段的范围为:道路上4 km范围内(单向)或桥梁、隧道、长大下(上)坡全程。
1.1 交通事故数据
交通事故数据来源于辽宁省高速公路某区域交通事故数据记录,包含事故创建信息、事故发生时间、事故发生地点、肇事车辆信息、伤亡人数、经济损失和事故发生环境情况信息。
本文对三条高速路段编号为高速路段Ⅰ、Ⅱ、Ⅲ,处理后数据包括高速路段Ⅰ交通事故数据1 450条,高速路段Ⅱ交通事故数据117条,高速路段Ⅲ交通事故数据36条,共计1 603条数据。
根据公安部交通管理局制定《全面排查交通事故多发点段工作方案》,交通事故直接损害后果有人身伤亡和财产损失,选取交通事故多发路段研究因素如表1所示。
表1 交通事故多发路段研究因素
类别事故要素 事故位置路线编码 起始桩号 位置坐标 人身伤亡死亡人数 受伤人数 车辆损失事故车辆数 道路损失路损金额
1.2 交通事故点空间分布
将交通事故数据运用python编程分布到对应的高速路段上,交通事故点在3条高速路段分布为:高速路段Ⅰ交通事故点密集分布在整条路段上;高速路段Ⅱ事故点呈稀疏状态均匀分布;高速路段Ⅲ事故点集中在分布在两个地区交的汇边界,不同分布特点是由不同高速的负荷运行状态和车流量差异造成的。
2 交通事故数据密空聚类
2.1 DBSCAN算法
DBSCAN(density-based spatial clustering of applications with noise)是带有噪声的基于密度的聚类方法。将交通事故黑点作为DBSACN算法聚类结果的簇,没有构成事故黑点的交通事故点作为噪点,利用经纬度位置信息对交通事故点进行聚类分析,得到事故黑点所在位置,以及事故黑点的事故严重程度。
2.2 算法参数确定
(1):最近邻距离度量参数。根据标准欧式二维距离计算,-邻域内事交通事故点1(1,1),2(2,2)之间的距离,欧氏距离二维空间公式如(1)所示。
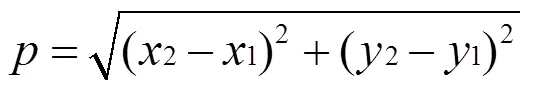
(2)eps:-邻域的距离阈值,代表交通事故黑点长度。依据我国对交通事故黑点鉴别标准为一年内长度为1 km的路段发生在3起以上的交通事故的路段,将交通事故黑点长度选定1 km。因为交通事故点在路网中的位置用经纬度(WGS84)确定,经纬度中1 km≈0.009°,所以把-邻域设置为0.004 5。
(3)MinPts:-邻域内的样本数阈值,代表交通事故黑点长度范围内交通事故次数。所以交通事故黑点判定阈值MinPts设置为3。
2.3 算法步骤
输入:交通事故点度量方式;交通事故数据集:={1,2…u},包含经纬度坐标和事故等级,邻域参数(eps, MinPts)。
Step1:初始化事故黑点核心交通事故点集合Ω=Ø,初始化事故黑点簇数=0,初始化未访问交通事故点集合=,初始化簇划分=Ø。
Step2:历遍所有交通事故点,找出所有核心交通事故:
①根据交通事故点度量方式,确定交通事故点u的-邻域∈(u);
②若u的-邻域内满足|∈(u)|≥MinPts,则将u加入核心交通事故点合集Ω=Ω∪{u}。
Step3:如果核心交通事故点集合Ω=Ø,算法结束,否则转入Step4。
Step4:在核心交通事故点集合Ω中,随机选取一个核心交通事故点o∈Ω,初始化当前簇核心交通事故点队列Ω=
Step5:如果当前簇核心交通事故点队列Ω=Ø,则当前事故黑点簇C生成完毕,更新簇划分。={1,2, …,C},更新核心事故点集合Ω=ΩC,转入Step3,否则更新核心事故点集合Ω=ΩC;。
Step6:在当前簇核心事故点队列Ω中取出一个核心事故点o’,通过邻域距离阈值找出所有-邻域事故点∈(o’),令Δ=∈(o’)∩,更新当前簇事故点集合C=C∪Δ,更新未访问事故点集合Δ,更新Ω=Ω∪(Δ∩Ω)o’,转入Step5。
输出:事故黑点集合={1,2, …,C},类事故黑点的数据平均值w。
2.4 交通事故数据集构建
以交通事故记录数据中“死亡人数”、“受伤人数”、“事故车辆数”、“路损金额等级”作为划分依据,进行交通事故事故等级划分,部分交通事故数据信息如表2所示,交通事故等级信息如表3所示。
表2 交通事故数据信息示例
高速路段编号起始桩号事故车辆数死亡人数受伤人数路损金额等级经度x纬度y Ⅰk498.91000121.5451441.174748 Ⅰk499.22000121.5793041.184195 Ⅰk495.41000121.5153841.165193 …………………… Ⅰk466.952000121.2186641.033480 Ⅰk498201960121.5406641.173713 Ⅰk5002000121.5705241.181387 Ⅰk478.72000121.3565541.09520
表3 交通事故等级信息
事故点等级事故车辆数死亡人数受伤人数路损金额数量 1级2辆以下万元001000元以下1108条 2级大于2辆,小于5辆00大于1000元小于3万元349条 3级小于5辆03人以下大于3万元,小于6万元106条 4级大于5辆大于1人大于3人大于6万元40条
该区域高速公路存在伤亡交通事故占9%,多车相撞的事故占22%,轻微事故占69%。对于该区域主要事故集中于车辆追尾或故障,虽然1级事故没有造成严重的经济损失和人员伤亡,但是数量多、频率高的特点,同样影响该区域高速公路正常通行,给车辆行驶带来极大的隐患。
2.5 交通事故黑点聚类结果
高速路段Ⅰ聚类结果如表4所示,将事故桩号分成23个存在交通事故黑点的路段。事故次数大于100次的路段有4个,并且路段范围均大于3 km。因为高速路段Ⅰ车流量大,交通事故分布在整条道路上,所以交通事故黑点分布广泛,并且事故较为严重,只存在2个噪点,事故黑点存在于整条道路。
表4 高速路段Ⅰ事故黑点
序号桩号范围交通事故等级均值wk事故次数路段范围/km 1K442.07~K4431.667130.93 2K443.15~K4461.511442.85 3K446~K4551.4851729 4K455~K4561.444361 5K456~K4571.500321 6K457~K4581.488351 7K458~K4661.4511978 8K466~K4671.264341 9K467~K4731.3622106 10K473~K474.11.446650.9 11K474.1~K4761.392681.9 12K476~K4771.417241
续表
高速路段Ⅱ聚类结果如表5所示,将事故桩号分成14个存在事故黑点的路段,大部分路段事故次数4次左右,只有1个路段大于10次,最大路段范围为6 km,事故黑点中交通事故次数较少,简易交通事故黑点占57%,4个路段交通事故等级均值高于1.5。高速路段Ⅱ交通事故稀疏在整条高速上,很多路段没有聚类为事故黑点,但是噪点占整体交通事故次数43%,交通事故影响依然严重。
表5 高速路段Ⅱ事故黑点
序号桩号范围交通事故等级均值wk事故次数路段范围/km 1K45.24~K45.891.66730.7 2K54.5~K55.951.462131.35 3K56.2~K57.81.50041.6 4K67.85~K68.31.00040.45 5K69~K70.71.00040.7 6K72~K76.91.00064.9 7K77.3~K77.61.00040.3 8K78.5~K79.51.00041 9K91.6~K921.66730.4 10K92.1~K93.951.50041.85 11K99.5~K100.81.33330.7 12K105~K1071.66732 13K112.2~K112.351.00080.15 14K118.5~K118.851.00030.35 噪点 1.47051
高速路段Ⅲ聚类结果如表6所示。
表6 高速路段Ⅲ事故黑点
序号桩号范围交通事故等级均值wk事故次数路段范围/km 1K323~K324.42.00041.4 2K303.95~K304.81.66730.85 3K319~K3201.00031 噪点 1.48025
将事故桩号分成3个存在事故黑点的路段,路段事故次数4次左右,最大路段范围为1.4 km,事故黑点中交通事故次数较少,1、2路段交通事故等级均值高于1.5。高速路段Ⅲ交通事故集中分布在K319~K324.4上,有很多路段没有划分为事故黑点,事故噪点占整体交通事故次数67%,交通事故影响依然严重。
3 基于事故黑点的交通事故多发路段智能鉴别
3.1 交通事故黑点核密度估计
因为密空聚类得到的交通事故黑点道路桩号覆盖范围大,并包含大量简易事故。所以采用核密度估计进行空间数据分析,减小简易事故对鉴别事故多发路段的影响。
3.1.1 核密度估计
核密度估计是一种以非参数方式估计随机变量的概率密度函数(PDF)的方法。常用核函数为高斯核函数(gaussian_kde),适用于单变量(uni-variate)和多变量(multi-variate)数据。
3.1.2 确定参数
参数有dataset(数据集)、bw_method(用于计算估计其宽带的方法或参数)、weights(权重)。
(1)dataset:将交通事故黑点位置信息数据经度和纬度数据进行叠加,生成二维矩阵数据集A作为核密度估计的数据集。
(2)bw_method(b):宽带参数控制函数的径向作用范围,事故多发路段为4 km,4 km≈0.036°,所以bw_method=0.018。
(3)weights:将聚类结果的交通事故等级均值w,按事故黑点类别赋给交通事故点,为交通事故点权重w。
3.1.3 核密度估计步骤
输入参数:数据集={1,2, …,a};核密度估计参数(b =0.018,weights=w);

Step2:单变量核函数K的核函数选用高斯核函数,如式(3)所示。

Step3:交通事故点核密度估计多维变量的核函数K,用单变量核函数K的累计乘积表示,如式(4)所示。

Step4:根据核密度估计结果绘制热力图,采集图像数据为RGB通道,根据公式(2)、(3)、(4),可知2维颜色通道的核函数乘积公式如式(5)所示。

3.2 交通事故多发路段鉴别
通过核密度估计进行空间数据分析,可以更加直观鉴别事故多发路段,核密度估计通过事故黑点的事故次数以及相关权重进行分析,其结果表示发生交通事故的概率。为了让核密度估计结果与底色区分,低数值结果设置为白颜色。累计交通事故发生概率,从浅色位置到黑色位置依次增高,黑色位置是最有可能发生交通事故和交通事故影响最大的区域。
高速路段Ⅰ实际方向为东西走向,所以核密度估计结果为横向分布;高速路段Ⅱ、Ⅲ实际方向为南北走向,所以核密度估计结果分布为竖向分布。
高速路段Ⅰ核密度估计结果如图1所示,交通事故影响范围与道路形状相似,有两段出现深色区域,为交通事故发生概率最高的区域,鉴别为交通事故多发路段。
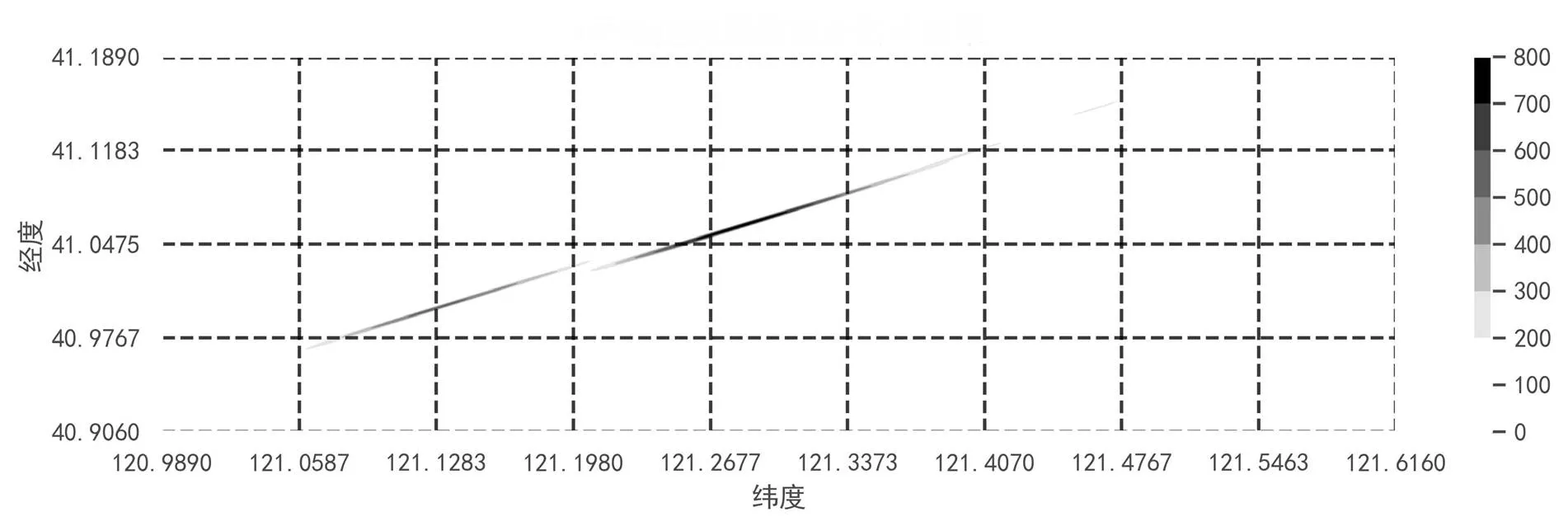
图1 高速路段Ⅰ核密度估计结果
高速路段Ⅱ核密度估计结果如图2所示,核密度估计结果特征不连续、分布范围较广,最上方区域颜色最深,表示该部分发生交通事故可能性最大,其余道路颜色较浅表明发生交通事故概率较小,该条高速没有多发事故路段,深色路段称为事故黑点。
高速路段Ⅲ核密度估计结果如图3所示,结果分布与道路形状相似,中间部分深色路段长度介于多发事故黑点与多发事故路段之间。因为发生交通事故次数少,路段上方与下方结果显示不明显,颜色较浅,所以累计发生概率较小,故排除事故多发路段。
综上所述,3条高速路段交通事故多发路段信息如表7所示。
表7 交通事故多发路段信息
高速路段编号桩号范围平均事故次数/(次·km-1)路段长度/km ⅠK451.5~K45826.1546.5 K469~K47342.0004 ⅡK54.5~K55.958.9651.45 ⅢK321.6~K324.72.5803.1
4 结论
本文将密度聚类算法与核密度估计空间分析方法联动,针对交通事故空间聚积分布的特点,首先将事故数据依据交通事故关键要素采用划分成同一等级事故,再将交通事故数据按空间位置数据进行聚类分析,得到同一性质的事故黑点,对交通事故黑点添加权重进行核密度估计空间数据分析。
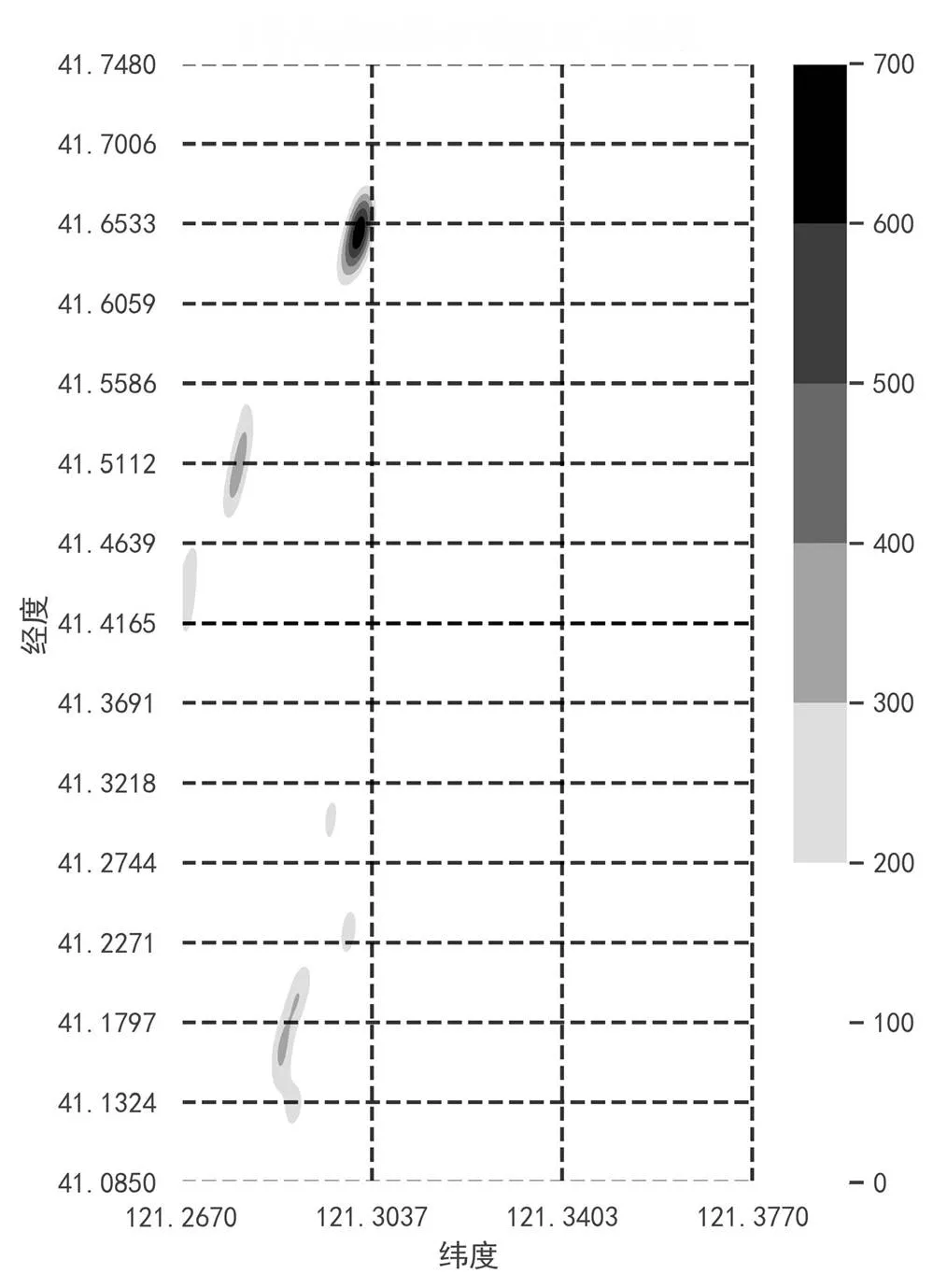
图2 高速路段Ⅱ核密度估计结果

图3 高速路段Ⅲ核密度估计结果
对辽宁省某区域内的3条高速路段,进行交通事故多发路段智能鉴别,结果表明能够有效应对不同交通事故点分布特点,有效避免简易事故对事故多发路段的鉴别的影响,清晰准确找到事故多发路段的位置,采用GIS技术可视化处理,更加直观清晰鉴别事故多发路段,达到智能识别交通事故多发路段目的。
[1] 谢练, 吴超仲, 吕能超, 等. 基于改进聚类算法的道路交通事故多发路段鉴别方法研究[J]. 武汉理工大学学报: 交通科学与工程版, 2014, 38(4): 904-908.
[2] 王海. 基于空间分析技术的交通事故多发点鉴别及成因分析[D]. 北京: 清华大学, 2014.
[3] 王颖志, 王立君. 基于网络时空核密度的交通事故多发点鉴别方法[J]. 地理科学, 2019, 39(8): 1238-1245.
[4] Erdogan S, Yilmaz I, Baybura T, et al. Geographical information systems aided traffic accident analysis system case study: City of Afyonkarahisar[J]. Accident Analysis and Prevention, 2007, 40(1): 174-181.
[5] Tessa K, Anderson. Kernel density estimation and K-means clustering to profile road accidenthotspots[J]. Accident Analysis and Prevention, 2009, 41(3): 359-364.
[6] Thomas Edison Guerrero-Barbosa, Shirley Yaritza Santiago-Palacio. Determination of accident-prone road sections using quantile regression[J]. Revista Facultad de Ingeniería Universidad de Antioquia, 2016, 79: 130-137.
Research on Intelligent Identification of Accident-prone Sections Based on Density Space Clustering
SUN Cheng-zhen1, CHEN Xin1, FAN Chun-sheng2, ZHANG Li3, RUAN Yong-jiao1, CHEN Ya-xin1
(1. School of Automobile and Traffic Engineering, Liaoning University of Technology, Jinzhou 121001, China; 2. Liaoning Highway Operation and Management Co. LTD, Shenyang 110179, China;3. Jinzhou Public Transport Co. LTD, Jinzhou 121000, China)
Based on the actual traffic accident data of highway, the clustering algorithm is linked with the kernel density estimation, and the traffic accident density clustering analysis is carried out according to the identification standard of the traffic accident black spot in China. With reference to the accident standard of China for grading the accident data, the weight of the traffic accident black spot is calculated based on the clustering results, and the kernel density of the traffic accident spatial data is estimated, and the GIS technology is used for visualization, and spatial statistical methods are used to intelligently identify accident-prone sections, which provides a reference for the setting of warning signs on highways and the supervision of road safety departments. Through the identification of three highway sections with frequent traffic accidents in a certain area of Liaoning Province, intelligent identification can effectively deal with the distribution characteristics of different accident-prone sections, avoid the impact of simple accidents, and clearly and accurately find the location of accident-prone sections.
traffic accident; density-based space clustering; accident-prone sections; intelligent identification
10.15916/j.issn1674-3261.2023.02.004
U491.31
A
1674-3261(2023)02-0087-06
2022-05-17
辽宁工业大学研究生教育改革创新项目(YJG2021003)
孙承臻(1998-),男,辽宁大连人,硕士生。
陈 昕(1972-),女,辽宁铁岭人,教授,博士。
责任编辑:陈 明
