基于种群聚类和互信息的入侵检测方法
2023-05-13杨晓晖豆晓菲
杨晓晖,豆晓菲
(河北大学 网络空间安全与计算机学院,河北 保定 071002)
0 引言
互联网技术飞速发展伴随着网络安全问题的层出不穷,网络攻击形式也随网络环境不断发生改变,人们对网络安全的需求与对网络空间使用的需求同等紧迫[1]。如何在众多网络流量中检测出已知或潜在的威胁,从而对网络提供便于实施且行之有效的安全保护,已成为当前网络安全研究领域的热点问题。
应用于入侵检测领域的异常检测方法主要分为三类:基于统计的、基于知识的和基于机器学习的。机器学习技术被广泛应用于入侵检测。训练数据中的冗余和无关特征在网络流量分类中引起了长期的问题,这些特性不仅会减慢分类过程,还会妨碍分类器做出准确的决策。因此,选择一个好的特征子集是提高入侵检测性能的关键。
根据特征子集评估的不同,特征选择方法可以分为过滤法、包装法和嵌入法。本文将特征选择定义为一个优化问题,为克服收敛早熟问题,获得高质量的特征,提高入侵检测的准确率和检测率,提出了一种基于种群聚类的二进制粒子群优化算法和互信息的入侵检测方法,通过混合包装和过滤方法来选择特征。主要贡献如下:
1)提出一种种群聚类的方法,基于粒子与聚类中心的汉明距离和分类精度差定义相似度函数,基于粒子的位置和分类精度定义优度值,从而实现粒子群算法初始种群的均匀分布;
2)实现外层和内层相结合的双层优化,将基于互信息的过滤方法集成到基于种群聚类的二进制粒子群优化算法的包装器模型中,减少特征冗余,增加更有价值的特征子集,提高入侵检测精度;
3)定义基于检测率和误报率度量的双目标函数的适应度函数用于入侵检测,通过对照实验结果验证所提出模型的有效性。
1 相关工作
入侵检测领域的理论体系日渐完善,为后者进一步研究提供了有力的理论支撑。Kasongo 等人[2]提出基于包装式特征提取的前馈式深度神经网路侦测系统,并采用树算法生成简化的最优特征向量,提高了效率和检测精度。Lv 等人[3]提出基于混合核函数的极限学习机的检测系统,将引力搜索算法和差分进化算法相结合,提高了全局和局部优化能力。任家东等人[4]采用K近邻算法进行离群点检测并删除,并提出一种类别检测划分方法对抗检测干扰,提高了准确率和检测率。Fang 等人[5]充分利用了Elman 神经网络的优势和支持向量机去噪的优点构建模型,获得了更高的精度和更好的自适应性。高兵等人[6]提出基于麻雀搜索和改进粒子群优化算法的网络入侵检测算法,对轻量级梯度提升机进行参数寻优建立网络入侵检测算法,达到了更高的检测精度。
目前许多入侵检测方法只能检测到已知攻击,无法应对随环境变化的新型攻击。针对入侵检测中误分类的问题,Kumar 等人[7]提出了将多目标遗传算法与神经网络相结合的方法,建立了一套有效检测网络入侵的集成方案。Liu 等人[8]提出了一种将特征分析和SVM 优化相结合的Web 入侵检测系统,增强了检测性能。刘敬等人[9]提出一种半监督式的异常检测方法,采用主动学习策略,并采用单分类SVM 建立模型,从而获得较好的检测性能。曹峰[10]将加速粒子群优化算法和径向基神经网络相结合,从而对入侵检测系统进行了优化,实验结果表明,检测的性能有显著改善。
引入机器学习可以提高检测效率,特征选择在模型建立中起着至关重要的作用。Alazzam 等人[11]提出一种新的连续鸽群优化算法的二值化方法,在精度和F-score 等方面结果较优。Wei 等人[12]提出一种新的变异增强BPSO-SVM 算法,通过调整局部和全局最优,增加粒子变异概率,克服早熟问题。武小年等人[13]提出基于SVM 的两级特征选择方法,从而提高特征子集的分类性能,并在一定程度上减少了时间成本。Feng 等人[14]提出一种动态特征重要度度量方法,并提出了相应的特征选择算法。Prasad 等人[15]利用粗糙集理论和贝叶斯定理的混合方法,设计了一种特征选择智能系统,计算核心特征并对其进行排序,从而降低了计算复杂度,提高了检测率。Taradeh 等人[16]将引力搜索算法与进化交叉和变异算子相结合,获得了更快的收敛速度。唐成华等人[17]提出一种基于层次聚类和遗传算法的改进FCM 算法,并采用信息论的方法和约登指数进行特征选择,从而构建模型,提高了检测率,降低了误报率。
2 基于CPBPSO-MI 的入侵检测
面对网络数据样本量的持续增大和数据维度的迅速增加,本文从特征选择的角度入手,提出一种基于种群聚类的二进制粒子群优化算法(Clustering based Population in Binary Particle Swarm Optimization,CPBPSO)和互信息(Mutual Information,MI)的特征选择方法,简称CPBPSOMI,并在此基础上构建入侵检测模型。
2.1 模型框架
该模型分为3 个部分:第一部分对选取的NSL_KDD 数据集进行预处理;第二部分使用基于种群聚类的特征选择方法作为外部优化层进行全局搜索;第三部分基于CPBPSO 的启发式搜索,结合互信息进行局部搜索。图1 描述了提出的框架流程。
2.2 模型构建
2.2.1 特征的相似度度量
在众多特征选择算法中,粒子群优化算法是一种广泛应用于各个领域的算法,其有很强的全局搜索能力,简单和易于实现,然而,粒子群优化算法存在早熟收敛问题,影响勘探,导致性能下降。针对粒子群算法在搜索过程中的过早收敛问题,本文首先提出了一种基于种群聚类的粒子群优化算法。
为了避免特征选择过程中的候选解过早地收敛,首先随机产生p个初始粒子,集群的数量n如式(1)所示:
其中,α的取值范围为(0,1)。
定义每个粒子与聚类中心的相似度,如式(2)所示:
其中,Hd表示粒子与聚类中心间的汉明距离,Da表示粒子和聚类中心的精度差异,η和γ分别为加号前后两项式子的权值,η=1-γ。
式(2)右侧第一项表示粒子靠近聚类中心的容易程度,第二项表示当前粒子和聚类中心分类性能之间的相似性。
2.2.2 特征的优度度量
为了对集群粒子中的特征进行直观评价,本文从粒子的位置和分类精度两个方面,定义优度值:
最佳特征是优度值大于聚类中所有粒子优度值的平均值的特征。
2.2.3 适应度评估函数
每个代理特征子集都要通过适应度函数进行评估,由此可以确定最佳特征子集的位置。这里定义一个基于最大检测率(Detection rate,DR)和最小误报率(False positive rate,FPR)的双目标函数为适应度函数。
假设DR 和FPR 具有相同的重要性,在ROC曲线中,该函数的值取决于坐标为(FPRi,DRi)的每个代理点和坐标为(0%,100%)的完美分类点之间的最小化欧氏距离。
图2 为ROC 曲线中代理点和完美分类点之间的欧氏距离的简单示例。

图2 ROC 曲线Fig.2 ROC curve
适应度函数定义如下:
其中,1≤i≤n,ai是第i个代理点,p为假设的完美分类点。
2.2.4 互信息评估函数
为了让群体快速跳出局部最优,在粒子群优化算法中引入互信息方法。这里采用Amiri 提出的评估函数[18]:
其中,fi是希望选择的特征,C是目标类,S是候选的特征子集,β是根据经验确定的参数,在0 和1之间变化。第一项给出新的输入特征和输出特征之间的特征相关性,第二项类似于第一项的惩罚,并测量新特征和所选特征之间的相关性。该方法目的在于最大化输入特征和目标类之间的相关性,并且最小化所选特征之间的冗余。
3 实验结果与分析
3.1 实验环境
本文具体实验环境如表1所示。

表1 实验环境Tab.1 Experimental environment
3.2 实验数据
本文实验数据选自NSL-KDD 数据集。其为KDD 99 的修订版本,去除了KDD 99 的重复记录,使正确数据和攻击数据量达到平衡,其包含特征和KDD 99 相同。
数据集由41 个特性属性(其中7 个符号特征,34 个数字特征)和一个标志属性(除了Normal表示正常事件之外,其余标志都表示为异常)组成。攻击类型分为四类:拒绝服务攻击(DOS)、未授权使用本地超级权限访问攻击(U2R)、远程用户未授权访问攻击(R2L)、扫描攻击(Probe)。
在本文中,分别从KDDTrain+和KDDTest+数据集中选择了10 000 和5 000 个实例作为训练集和测试集。这些数据集的详细信息如表2所示。

表2 实验数据集信息统计Tab.2 Experimental data set information statistics
为了避免数据不平衡,必须对每个特征的值进行预处理。
首先用离散化方法离散NSL-KDD 中的连续特征,将所有的符号化数据转换为数值信息,然后进行归一化处理,公式如下[19]:
其中,1≤i≤N,N是数据集中实例的数量,vi是给定特征数据集中第i个实例的值,μ和σ分别是平均值和标准差。
3.3 评价指标
本文所采用评价指标如下:
准确度Acc 是评估分类模型性能的最常用指标,可表示为
检测率DR 表示正确识别的攻击样本的百分比,可表示为
误报率FPR 表示被归类为攻击的正常样本的比例,可表示为
其中,nTP表示攻击样本被分类正确的数目,nFP表示正常样本被判断为攻击的样本数目,nFN表示攻击样本被判断为正常的样本数目,nTN表示正常样本被分类正确的数目。
3.4 实验结果与分析
在本文实验中,将提出的CPBPSO-MI 模型与重力搜索算法BGSA 和二进制粒子群BPSO 两种特征选择方法进行了实验对比。表3~表5 分别为3 种特征选择方法的参数设置。

表3 BPSO 的参数设置Tab.3 Parameter setting of BPSO

表4 BGSA 的参数设置Tab.4 Parameter setting of BGSA

表5 CPBPSO-MI 的参数设置Tab.5 Parameter setting of CPBPSO-MI
按照上述参数设置,用支持向量机作为分类器,从准确率、检测率和误报率3 个方面将本文方法的性能与BGSA 和BPSO 进行了比较。三种方法在NSL-KDD 数据集100 次迭代实验中,在Acc、DR 和FPR 三个方面的运行结果分别如图3~图5所示。

图3 各算法在100 次迭代情况下的Acc 值Fig.3 Acc values of each algorithm in 100 iterations
如图3 和图4所示,本文方法在确定适应度函数时,从准确率和检测率两个方面对其进行定义的,因此在准确率和检测率方面表现较好。如图5所示,本文方法在误报率方面与另外两种方法的差别也并不大。

图4 各算法在100 次迭代情况下的DR 值Fig.4 DR values of each algorithm in 100 iterations

图5 各算法在100 次迭代情况下的FPR 值Fig.5 FPR values of each algorithm in 100 iterations
为了分析实验结果,将本文提出的CPBPSOMI 方法与BPSO 和BGSA 三种方法在准确率、检测率、误报率、运行时间、特征选择数量5 个方面的运行结果进行了对比分析,如表6所示。
由表6 可知,与其他两种方法相比,本文提出的CPBPSO-MI 方法结果的准确率和检测率较高。与标准BGSA 相比,其准确率和检测率分别提高了2.762%和5.135%,与BPSO 方法相比,分别提高了2.502%和4.890%。
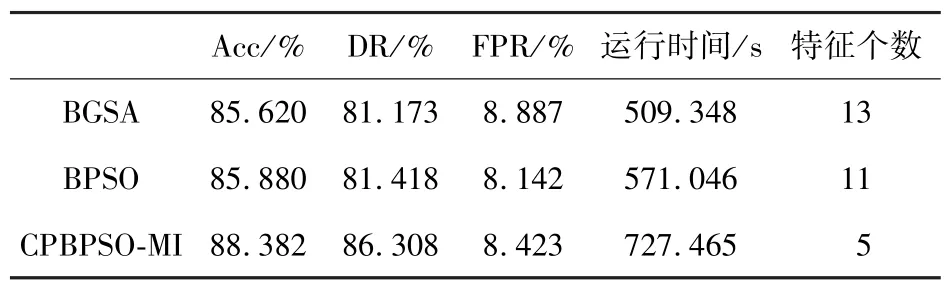
表6 BGSA、BPSO 和CPBPSO-MI 的运行结果Tab.6 Operational results of BGSA,BPSO and CPBPSO-MI
在特征选择方面,CPBPSO-MI 方法所选择的特征数量也相对较少,只选择了一小部分原始特征(在41 个特征中只选择了5 个特征,而BGSA 和BPSO 方法分别选择了13 个和11 个特征),说明相对于BPSO 和GSA 算法,本文提出的CPBPSOMI 方法在特征缩减方面的优势也比较明显,可以大幅度缩减特征空间,从而提高分类性能。
以上结果表明,在特征选择方法中利用信息论,同时考虑特征与特征和特征与类之间的互信息,增加输入特征与目标类之间的相关性,可以减少所选特征之间的冗余,从而提高入侵检测的性能指标。
在误报率方面,CPBPSO-MI 方法仍然优于BGSA 方法的性能,比其提高了0.464%,但该方法却比BPSO 方法的误报率略高。如图7所示,BPSO 方法在本次实验中的误报率最为理想,分别比CPBPSO-MI 方法和BGSA 方法的FPR 提高了0.281%和0.745%。另外,与另外两种方法相比,本文所提出的方法的运行时间更长。而在入侵检测问题中,能够在获取较高的准确率和检测率,并减小误报率更为重要。
4 结论
为了提高网络入侵检测的准确性,针对检测中特征获取的问题,本文提出了一种混合包装和过滤两层优化框架的特征子集选择算法,外层优化层基于粒子群优化算法,并使用聚类的方法,使初始种群分布在整个特征空间,进行全局搜索,有效解决了过早收敛问题。内部优化层采用基于互信息的方法,以实现特征子集的修剪,完成局部搜索,从而得到最优特征子集。最后采用支持向量机作为分类器,并以最大检测率和最小误报率为目标函数从而对网络流量进行入侵检测。基于NSL-KDD 数据集进行测试的结果表明,该方法较其他方法在准确率方面提高了2%以上,在检测率方面提高了4%以上,较好地提高了分类性能和入侵检测的准确率和检测率。
