环境流行病学研究中广义可加模型在Python中的实现
2023-05-11李湘莹李培政罗晨曦张清煜
李湘莹,李培政,王 静,罗晨曦,张清煜,马 露
武汉大学公共卫生学院(武汉 430071)
环境流行病学领域研究工作中往往涉及大量时间序列数据,其影响因素的多样性和复杂性使得在研究时往往难以确定回归关系的基本形式,广义可加模型(generalized additive models,GAM)是解决这一问题的一种途径。GAM 是在广义线性模型(generalized linear mode,GLM)基础上发展而来的,它提供了更为灵活的建模框架,其反应变量可以为非正态的指数族分布,解释变量与反应变量间可存在复杂的非线性关系,由指定的协变量平滑函数加上线性项的常规参数分量之和得出。伴随环境流行病学领域研究资料的数字化高速发展,多源数据融合、智能化管理和分析已成为必然趋势。Python 作为一个拥有强大第三方库的开源软件,其规范且相对简洁的编程语言,在同应用程序整合、数据源连接与读取、调用其他语言,以及实现人工智能等方面展现出了显著优势[1]。然而,在环境流行病学领域中,使用Python 进行GAM 分析的研究尚较少。本文利用环境流行病学研究中的一组时间序列资料,分别进行Python、R 和SAS 的GAM 建模,比较它们在运算逻辑、参数、结果方面的差异,以拓宽Python 软件在环境流行病学领域的应用场景。
1 资料与方法
1.1 资料来源
因呼吸系统疾病入院人次数据主要来源于某地区卫生信息中心2017 年1 月1 日至2018 年12 月31 日记录的该地医院病案首页。每日大气中PM2.5浓度、日均温度、平均湿度等数据来源于当地环境监测部门官方网站。PM2.5浓度和研究对象日入院人次逐日变化图如图1 所示。

图1 2017—2018年某地PM2.5浓度和研究对象日入院人次逐日变化图Figure 1. Daily variation of PM2.5 concentration and the number of hospital admissions of research objects from 2017 to 2018
1.2 模型构建
为了评价大气污染物与因呼吸系统疾病入院人次的关系,需要对长期趋势和季节趋势、星期效应、平均温度、相对湿度等产生的影响进行控制。此处长期趋势指连续数年观察中入院人数呈现的某种总的变动趋势;季节趋势指入院人数在每年随季节产生的周期变化。这里,我们对数据库进行了调整,为了控制长期趋势和季节趋势,将事件发生的日期调整为这一事件发生的先后次序,引入时间序列变量(命名为time),记作1,2,3…。为了控制星期效应的影响引入星期变量(命名为dow),工作日(星期一至星期五)入院为dow=0、周末(周六至周日)入院为dow=1。平均温度的单位为℃,相对湿度的单位为%,PM2.5浓度单位为μg/m3,数据形式如表1(仅展示部分数据)。
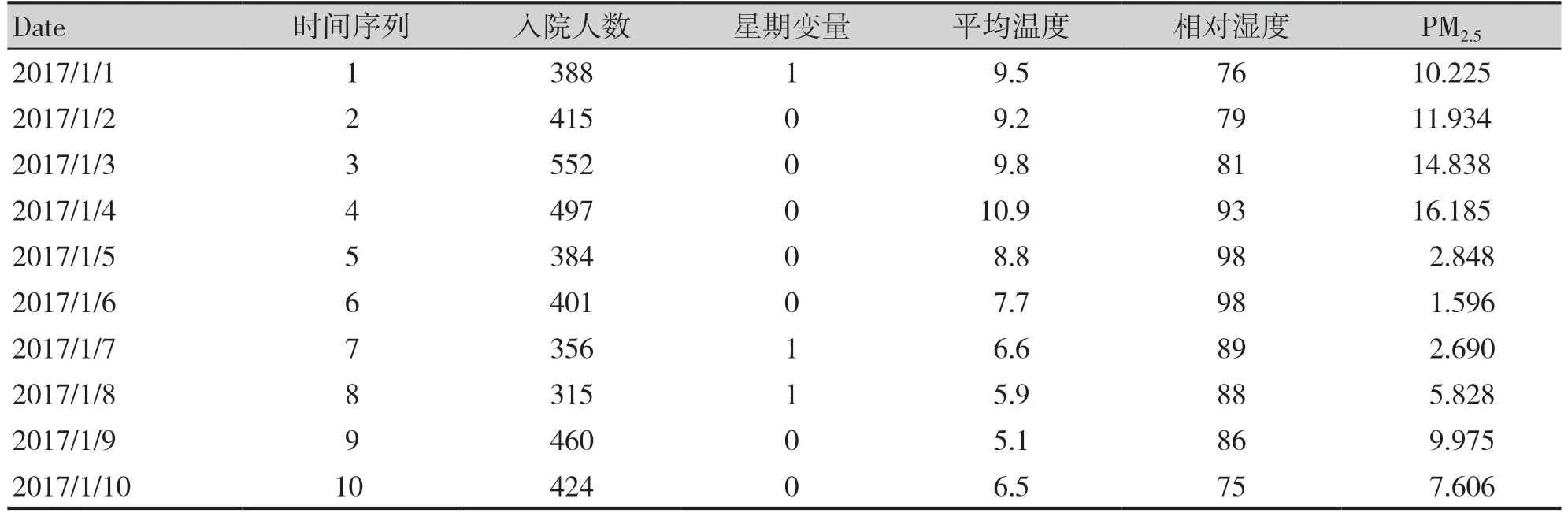
表1 颗粒物、气象及研究对象数据资料Table 1. Data of particulate matter, meteorology and research objects
本研究首先在入院前三天的单日和移动平均暴露的多个滞后结构下估计了空气污染物对全因住院的短期影响(lag0-3, lag01-03)。然后根据模型的广义交叉验证(generalized cross-validation,GCV)和R2,最终选择以PM2.5单污染物滞后0天的暴露模型作为先验滞后结构,利用Python 中的statsmodels 库构建GAM 模型,并与R 软件、SAS 软件的输出结果进行比较,验证Python 结果。
GAM 的基本形式为:
其中,g(μ)为连接函数,g(μ)的选择由反应变量的分布形式决定:①当反应变量服从正态分布时,等同于一般可加模型,g(μ)=μ。②当反应变量服从二项分布时,选用logit 连接。③当反应变量服从Gamma 分布时,选用Identity 连接[2]。④当反应变量服从Poisson分布时,选用Log连接[3]。Si(·)为非参数光滑样条函数,ε 为误差项。模型构建过程如下:
(1)调用相关参数并载入数据
加载statsmodles 库与pandas 库,从statmodels库中加载GLMGam 语句,CyclicCubicSplines 语句,以便于读取数据和拟合模型。使用pd.read 语句载入数据保存在base_data 中。命令如下:

(2)对解释变量进行样条变换
在Python statsmodles 库中,使用GLMGam 函数进行拟合。分类变量被视为线性项,对非线性解释变量通过样条函数进行拟合。GLMGam 函数中主要选择的平滑基函数有两类,分别是B 样条函数与循环立方样条函数。在本例中我们选用循环立方样条函数对长期趋势、温度、湿度这三个变量进行样条变换。命令如下:
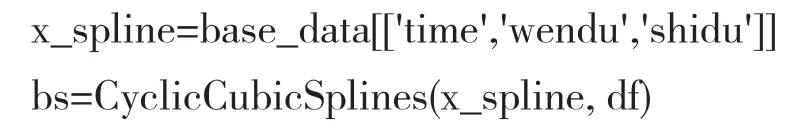
(3)确定模型自由度
自由度很大程度上会影响模型拟合和预测的准确性,目前主要有四种确定模型自由度的方法:①根据既往学者的经验设置固定的自由度;②根据最小化模型残差自相关绝对值最小来选择;③广义交叉验证(generalized crossvalidation,GCV)依据GCV 值最小选择;④赤池信息准则(Akaike information criterion,AIC),依据AIC 值最小选择[4]。在实际操作中对于最优自由度需要进行多次评估,本例依照既往学者的经验并结合AIC 值、GCV 值,设置固定自由度,其中长期趋势自由度设为15/年,平均温度自由度设为4,相对湿度自由度设为4。命令如下:
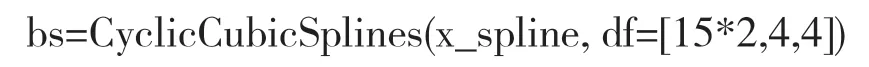
(4)构建基础模型
由于因呼吸疾病系统入院人次服从Poisson分布,故连接函数选择Log 连接,根据GAM 函数定义,构建如下模型:
其中β1、β2分别为PM2.5和短期波动(dow)的系数,s为非参数平滑函数,ε 为残差项。
使用GLMgam 函数构建模型,对三个非线性解释变量使用循环立方样条函数拟合,定义反应变量为泊松分布,使用fit 语句拟合函数,summary 语句查看结果。具体命令如下:

1.3 模型验证
采 用R 3.6.1 软 件 的mgcv 包 与SAS 9.2 中的proc gam 语句构建GAM 模型作为参照,由于Python 与SAS 软件中可选择样条函数的限制,为保证结果的可比较性,本文选用R、Python 软件中的循环立方样条(cyclic cubic splines)函数及SAS 软件中的三次平滑样条函数对非参数项进行拟合,并设置统一且固定的自由度,验证输出结果是否正确。R、SAS 相关代码见框1。

框1 R、SAS中的GAM代码Box 1. GAM codes in R and SAS
2 结果
2.1 GAM建模及参数估计结果
Python、R、SAS 三种软件输出结果与指数转换结果如表2。Python 与R 输出的结果主要包括:偏回归系数、标准误、Z值、P值等。SAS除上述结果外还会输出迭代汇总、平滑模型分析及图例。

表2 Python、R、SAS参数估计结果Table 2. Results of parameter estimation in Python, R and SAS
Python 输出的截距、PM2.5、星期变量参数估计结果分别为:ε=3.937,α=0.003,Z=1298.86,P<0.01;β1=0.087,α=0.009,Z=9.29,P<0.01;β2=-0.299,α=0.004,Z=-68.63,P<0.01。
指数转换后的结果说明,在控制了长期趋势和季节趋势、星期效应、平均温度、相对湿度的影响后,每日因呼吸系统疾病入院人次与PM2.5浓度变化有关联。三种软件输出的污染物及星期变量的估计值和标准误结果有所不同,但差异较小。Python 参数估计结果显示,PM2.5每升高100 μg/m3,入院人次增加9.1%[95%CI(7.2%,11.0%)]。R 输出结果为PM2.5每升高100 μg/m3,入院人次增加9.1%[95%CI(7.3%,11.1%)],SAS 输出结果为PM2.5每升高100 μg/m3,入院人次增加9.1%[95%CI(7.6%,10.6%)]。
在模型拟合结果中,R 软件输出R2=0.659,Python 输出Pseudo R2=1.000,但SAS 中仅针对各非参数项输出GCV 值,GCV 值越小表明拟合效果越好,本例中各非参数项GCV 值均较小。
3 讨论
本文结合环境流行病学研究实例,简要介绍了GAM 模型的基本形式,并比较Python、R 和SAS 在建模和分析结果上的异同。结果发现三种软件的输出结果基本一致,Python 输出结果可信。
在GAM 模型构建的参数设置上,三种软件存在差异。第一,三者内置函数拟合过程不同。Python 软件与R 软件是通过惩罚似然最大化来拟合平滑参数,通过对每个平滑参数添加惩罚项来避免拟合过度或拟合不良[5],而SAS 软件是通过双重迭代方法估计平滑参数[6]。第二,三者构建模型命令代码不同。Python 软件先统一对非线性参数项使用同一样条函数,再将非线性项与线性项通过GLMGam 函数构建模型进行拟合。R 软件与SAS 软件均通过相应函数直接将线性项与非线性项放在同一语句内构建模型。第三,三者可选用的样条函数不同。Python 软件目前已得到验证的样条函数仅有B样条函数与循环立方样条函数,SAS 软件中只可以使用三次平滑样条函数、局部回归与薄板样条函数[7],R 软件则能在这两种软件的基础上提供如三次自然样条函数等更多可供选择的平滑函数[8]。这些在参数设置和选择上的不同可能是其结果出现差异的主要原因。
尽管在本研究中,运用Python 进行GAM 建模无论是从程序语言上还是参数设置上,都没有展现出其在统计分析方面的优势,但Python 作为当前主流的计算机语言之一,其在网络爬虫、数据可视化、机器学习等方面拥有丰富的第三方库资源支持,能够高效实施多源数据连接与管理,并最终使实现数据收集与处理的环境统一成为可能。不断拓展Python 在环境流行病学领域的应用,必将为促进计算机与医学相关领域交叉融合发展提供借鉴和参考。
