Dual Attribute Adversarial Camouflage toward camouflaged object detection
2023-05-06YngWngZhengFngYunfeiZhengZhenYngWenTongTieyongCo
Yng Wng ,Zheng Fng ,Yun-fei Zheng ,b ,Zhen Yng ,Wen Tong ,Tie-yong Co ,*
a Institute of Command and Control Engineering,Peoples Liberation Army Engineering University,Nanjing,210007,China
b The Army Artillery and Defense Academy of PLA,Nanjing,210007,China
c PLA University of Foreign Language,Luoyang,471000,China
Keywords:Adversarial camouflage Digital camouflage generation Visual concealment Object detection Adversarial patch
ABSTRACT The object detectors can precisely detect the camouflaged object beyond human perception.The investigations reveal that the CNNs-based (Convolution Neural Networks) detectors are vulnerable to adversarial attacks.Some works can fool detectors by crafting the adversarial camouflage attached to the object,leading to wrong prediction.It is hard for military operations to utilize the existing adversarial camouflage due to its conspicuous appearance.Motivated by this,this paper proposes the Dual Attribute Adversarial Camouflage (DAAC) for evading the detection by both detectors and humans.Generating DAAC includes two steps: (1) Extracting features from a specific type of scene to generate individual soldier digital camouflage;(2) Attaching the adversarial patch with scene features constraint to the individual soldier digital camouflage to generate the adversarial attribute of DAAC.The visual effects of the individual soldier digital camouflage and the adversarial patch will be improved after integrating with the scene features.Experiment results show that objects camouflaged by DAAC are well integrated with background and achieve visual concealment while remaining effective in fooling object detectors,thus evading the detections by both detectors and humans in the digital domain.This work can serve as the reference for crafting the adversarial camouflage in the physical world.
1.Introduction
Camouflage plays an important role in many aspects,such as the concealment of soldiers and equipment.It can confuse the human vision system by blurring the distinction between object and background.In this way,the survival probability of camouflaged objects will increase in the military operation.
In recent years,deep learning and convolution neural networks(CNNs) [1—4]have gained tremendous success in computer vision tasks.At the same time,they have propelled the development of camouflaged object detection in the modern military [5].Current CNNs-based camouflaged object detectors[6,7]can precisely detect camouflaged objects beyond human detection.The camouflaged object detectors even replace human beings in some specific military operations(e.g.,border patrol and satellite reconnaissance[8])due to their high accuracy and efficiency.
However,some studies show that CNNs are vulnerable to adversarial attacks [9—11].The precision of CNNs-based detectors will degrade significantly confronting with adversarial attack.Thus,some attackers launch the adversarial attack by crafting the adversarial patch and attaching it into the image [12—16].As demonstrated in Fig.1,the utilization of most existing adversarial patches and camouflages is challenging due to their conspicuous appearance,especially in military operations.
Duan et al.[14]propose a method that can improve the visual effects: Adversarial Camouflage.It transfers the natural style from the selected image to the adversarial camouflage.The Adversarial Camouflage has a good visual effect when the object is stationary,but it is not suitable for the moving object like soldier,because it is hard to select the suitable image style when matching the constantchanging backgrounds.In addition,Duan et al.cover the whole object with the adversarial camouflage,which is named the holistic patch (camouflage) in this paper.The same case also occurs in literature [15—17].However,if the adversarial camouflage is sheltered,its adversarial strength will degrade significantly.Therefore,the obstacles in practice would easily foil the protection of the holistic patch on soldiers.

Fig.1.Existing adversarial patches: (a) Literature [12];(b) Literature [14];(c) Camouflages literature [15].
We expect to design an individual camouflage with the adversarial attribute that is adaptive to the military operations in the future.The visual concealment requires that the camouflage looks inconspicuous and can be applied as ordinary physical camouflage.The previous works mainly focus on attack strength and few of them care about the visual effects.Hence,we aim to generate the camouflage’s adversarial attribute while guaranteeing its visual effects.
The usual digital camouflage generation methods utilize digital image processing techniques to extract scene features from the input image,including the dominant background color and texture structure [17—19],then craft the digital camouflage by arranging camouflage units filled with dominant colors according to the texture structure.However,there exist many differences between the generations of ordinary digital camouflage and individual soldier digital camouflage: (1)Extraction source.The ordinary camouflage utilizes the features extracted in the image,but the individual camouflage should use the features extracted from the scene to enhance the universality;(2)Noise in the image.The image contains many noises and interference areas,including natural noise(e.g.,illumination and shadow)and area irrelevant to camouflage (e.g.,sky).These noises and areas would degrade the accuracy of extraction.The differences above make the usual digital camouflage generation method unsuitable for individual camouflage.
To address these issues,we proposed the Dual Attribute Adversarial Camouflage(DAAC) toward camouflaged object detection.Generating DAAC includes two steps:(1)Extracting the scene features from one specific type of scene to craft the individual soldier digital camouflage;(2) Training the adversarial patch with scene features constraint and attaching it to the individual camouflage to generate the adversarial attribute.The essential factor in achieving our target is the scene features.We design a new method to eliminate the noise in the image,and extract the scene features from the scene image set.Both the camouflage and patch merge with the scene context due to the scene features,which achieves the visual concealment.By attaching the adversarial patch with scene feature constraint to the specific position of digital camouflage,the generated DAAC can evade detection from both detectors and humans.The pipeline of the DAAC generation is shown in Fig.2.
We test and verify the performance of DAAC in 6 scenes.The mean precisions of Faster R—CNN [4]and YOLOv4 [20]are decreased by over 70%,meanwhile,the human detection time significantly increases.
The innovations of this paper are summarized as follows:
(1) We introduce the DAAC,which can evade detections from both human and detectors.Since the appearance of DAAC is close to the ordinary digital camouflage,it can serve as the ordinary physical camouflage to confuse human vision.
(2) We design a new method to filter the noise in the image and extract scene features from the scene image set effectively.The scene features are utilized to craft the individual soldier digital camouflage and constrain the adversarial patch,making the DAAC merge with scene context and realize visual concealment.
2.Related work
2.1.Object detection
The CNN-based detectors can be divided into one-stage detectors[21—23]and two-stage detectors[4,24,25]according to the ways of generating region proposals that might contain the object.
Due to high accuracy and simplicity,Faster R—CNN [4]establishes the prominent position of two-stage detectors.Faster R—CNN generates proposals through Region Proposal Network(RPN)in the first stage.In the second stage,it refines the coordinates of proposals and outputs their category.The refined proposals are called bounding boxes.The researchers present plenty of works to improve the Faster R—CNN in different aspects,e.g.,the strategies of selecting training samples [26,27],multi-scale training [25,28,29],and architecture reform [24,30]In general,they have the same fundamental pipeline as Faster R—CNN.
The one-stage methods directly generate the proposals in the feature maps extracted through the backbone.In this way,the computing time of the one-stage method significantly decreases compared with the two-stage methods.The typical one-stage methods are the YOLO series [20,21,31,32].YOLO divides the input image into many grids.For each grid,it predicts confidence scores and bounding boxes,respectively.The confidence scores are utilized to reflect the probability of object existence.Through data augmentation,multi-scale training,and efficient backbone,the latest YOLO v4[20]achieves state-of-the-art performance across a large-scale range of methods,including two-stage methods.
2.2.Adversarial attacks
Szegedy et al.[9]demonstrates that CNNs are vulnerable to the adversarial example.Some researchers attach imperceptible perturbation into images to lead the detectors predict incorrectly[33,34].However,the complex environment (e.g.,lighting,distance) might impair the attack perturbation in practice [15].
The adversarial patch intends to implement the universal and robust attacks to any image or object.Brown et al.[12]firstly introduce the adversarial patch toward image classification.Liu et al.[13]craft the adversarial patch to jointly attack Faster R—CNN and YOLOv2.Huang et al.[35]refine the patch that keeps the essential pixels for the attack.Some works make efforts to attack the detectors in the physical world.Chen et al.[36]propose to fool YOLO v2 in the traffic scene.Xu et al.[37]print the adversarial patch on T-shirts to evade person detectors.Huang et al.[15]propose the Universal Physical Camouflage Attack for fooling the detectors in both virtual scenes and the real world.Wang et al.[16]craft the adversarial camouflage by suppressing both the CNNsbased model and human attention.However,the works above mainly focus on attack strength and few of them care about the visual effects,making the existing adversarial camouflage methods not applicable to military practice.Different from the above works,we put the visual effects first and propose the DAAC that prevents the object from being detected by detectors on the premise of visual concealable.
2.3.Digital camouflage
Literatures[17—19]extract dominant colors using the improved K-Means algorithm.The subsequent studies [38,39]combine KMeans with spectral clustering and histogram statistics to improve the extraction accuracy.Cai et al.[40]extracts the dominant colors by fuzzy C-Means and achieves expected results.Jia et al.[18]arranges camouflage unit through Markov Random Field to generate Digital Camouflage.Li et al.[41]get the texture structure by the watershed algorithm.Literature [42,43]fill units according to the proportion of colors in the background.In recent years,researchers have progressed in generating Digital Camouflage through CNN[44—46].We consider the scene feature extraction as a statistical issue,and extract scene features from scene image set based on the local clustering and global sampling.The scene features are adopted to constrain the appearance of the adversarial patch and generate digital camouflage that is suitable for individual soldiers.
3.Method
We introduce the individual soldier digital camouflage in subsection 3.1 and the adversarial patch with scene feature constraint in subsection 3.2.
3.1.Individual solider digital camouflage
There are two main differences between the generations of ordinary camouflage and the individual camouflage: the extraction source and the noise in the image,making the ordinary digital camouflage generation method unsuitable for the individual soldier digital camouflage.
The individual soldier digital camouflage is supposed to adapt to all kinds of situations,which requires the camouflage to merge with the scene features to enhances the universality.To meet the requirement,we design a new method to extract the scene features from the scene image set and use it to generate the individual soldier camouflage.This section presents the individual solider digital camouflage generation from two aspects:the filtration stage and the extraction stage.In the filtration stage,considering the noise in the scene image will lower the extraction accuracy,we introduce the HLS histogram filtering that can eliminate noise effectively in the image;In the extraction stage,we bring the method to extract the scene feature from the image set.In the end,we use the scene features to generate individual soldier digital camouflage and constrain the adversarial patch to improve their visual effects.
3.1.1.Thefiltration stage
We divide the scene image into noise pixels and normal pixels.Noise pixels include natural noise(e.g.,lighting,shadow,and other natural noise) and interfere with the extraction accuracy of the dominant color.The camouflaged object will not appear in the area irrelevant to camouflage,so the contained pixels are useless for extracting the scene feature.Our target is to filter these two kinds of noise pixels.In the RGB color space,it is difficult to filter the noise pixels because three primary colors represent the same information (color) in essence.
Thus,we convert the image into HLS color space.In HLS color space,it uses the indexes of hue,lightness,and saturation to represent the pixels.We analyze the distribution of pixels in the hue histogram and lightness histogram:(1)The hues of natural and normal pixels are distributed in the same interval but can easily be distinguished in lightness;(2) The pixels in the irrelevant area account for a small proportion in the image,leading to a tiny bin in the hue histogram;The normal pixels take over a large proportion and present a continuous interval.It is easy to filter the noise pixels in hue and lightness histogram.The input image is shown in Fig.3(a).The hue and lightness histogram are demonstrated in Fig.3(b) and (c).
Comparing subfigure (b) with (c),we find that the general shapes of the red,green,and blue curves are similar with each other while the curves of hue,lightness look totally different.The hue and lightness filtration results are shown in Fig.3(d)—(e),where their statistic has been normalized.To obtain the continuous interval mentioned above,the maximum in the interval should be higher than the peak threshold to ensure that the interval contains the local maximum in the histogram,and the continuous tiny bins are filtered out.After filtration,we obtain many qualified intervals and only retain the interval with the minimum average value due to human sensitivity to lightness.The trough and peak threshold of lightness and hueLightnessT,LightnessP,HueT,HueP,are set 0.05,0.2,0.5 and 0.9 by experiment.The result is shown in Fig.4.
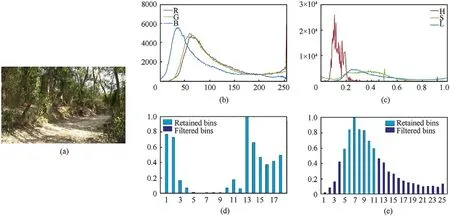
Fig.3.The filtration results:(a)Input image;(b)Histogram in RGB color;(c)Histogram in HLS color;(d)Result of lightness filtration;(e) Result of hue filtration.
As shown in Fig.4(a),the image contains illumination pixels(mainly on the ground) and some irrelevant pixels (mainly in the sky).Fig.4(b)tells that through hue filtration,we move the most of irrelevant pixels.As shown in Fig.4(c),the illumination pixels are removed by lightness filtering.We save the filtration result in the maskMaskf.InMaskf,the normal pixels remain unchanged,and noise pixels save to 0.After filtration,most noise pixels are deleted,as shown in Fig.4(d).
3.1.2.The extraction stage
We conduct the scene feature extraction from a statistical perspective.The overview of extraction is shown in Fig.5.Through local clustering,we obtain the clustering groups in each image.Local clustering can preserve more features in the image than global clustering and reduce the computational cost.For all the clustering groups in the image set,we sample a constant number of clustering centers over each image.The clustering centers in global sampling are labeled with red in Fig.5.Finally,the dominant colors are gained by clustering these red points through the K-Means++algorithm.The ratio of clustering samples in K-Means++clustering groups is seen as the proportion of the dominant color in the camouflage pattern.In this way,we address the issue that the features cannot be extracted from the whole scene images set effectively.The broader the sampling domain is,the higher the accuracy of feature extraction would be.
Considering computation complexity and efficiency,we apply Simple Linear Iterative Clustering (SLIC) to clustering the image locally.SLIC represents the pixel through 5 variables: lightnessl,colora,colorb,coordinatexandy.We setkclustering centers evenly distributed in the image containingNpixels.The area of interest is in a rectangle with border length ofThe spatial distancedsand the color distancedcbetween the pixel and clustering center are calculated by Eqs.(1)and(2),respectively.The clustering center is updated according todcanddsafterward.

Fig.4.The results of filtration:(a)Original image;(b)Result of hue filtration;(c)Result of lightness filtration;(d) Result of filtration.
We sampleMpoints from the image clustered and selectSclustering centers nearest to each sampling point as the clustering samples in the next stage of K-Means clustering.It requires that the values ofM*Spoints inMaskfare non-zero.Namely,they have not been eliminated in the filtration stage.If this requirement is not satisfied,then we resample the points.We utilize K-Means++to cluster all the sampled points and determine the number of cluster centers through Within Groups Sum of Squares.In the end,we select the four colors with the most clustering samples as the dominant colors to craft the camouflage pattern.In our experiment,MandSare set to 20 and 5,respectively.
It is hard to extract the universal texture structure for the whole scene.Motivated by literature[44],we generate camouflage texture with the preset pattern,where the probabilities of different patterns are set beforehand.The preset pattern is randomly sampled and forms the texture.We fill the texture according to the proportion of the dominant colors.The pipeline is shown in Fig.6.
The size of the preset pattern is 12 × 12 pixels.The individual soldier digital camouflage patterns generated in different scenes are shown below.Within each subfigure in Fig.7,the left three images correspond to the scene,and the rightmost one is the camouflage pattern of the scene.
3.2.Adversarial patch with the color constraint
The previous works directly attach the conspicuous adversarial patch to the image,as shown in Fig.1.To improve the visual effects,we propose to train the adversarial patch with the scene feature constraint.In this way,the adversarial patch can integrate into the digital camouflage more naturally.Then we embed the adversarial patch at the center of the object to fool the detectors.The center position has a significant influence on the regression and classification of the proposal.In this paper,we set two detectors as the targets,i.e.,Faster R—CNN and YOLO v4 in literature [16].The adversarial strength may degrade and even disappear if the detectors cannot photograph the adversarial patch embedded at the object's center,and we will discuss this issue in Section 6.
We give a unified definition of proposals generated by two different detectors: for imagex,its proposals present asP={pi:(di,ci);i=1,2,…,n}.didenotes the location ofpi,andcidenotes the confidence score ofpithat reflects whether thepicontains objects.Our target is to evade the detection from these two detectors by embedding the adversarial patch φ on the object.The adversarial losslossadvis described by Eq.(4):
yidenotes the label ofpi,which equals 1 ifpidoes not contain the object;otherwise,it equals 0.Sdenotes the scene.Meanwhile,φ is supposed to resemble the corresponding individual camouflage.We use the dominant color extracted to constrain φ.
φ is constrained in R,G and B channels.mdenotes the color with the most significant proportion extracted in scenes.We embed φ at the center of the object and formulate optimization objectives as:
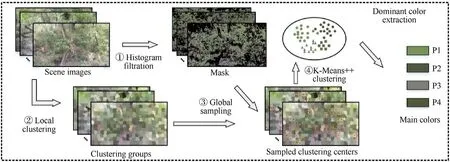
Fig.5.The overview of color extraction.

Fig.6.The individual solider digital camouflage.
The illustration of the adversarial patch training and embedding is shown in Fig.8.We find that it could hold the trade-off between adversarial strength and visual concealment when using the same coefficient to two kinds of losses,so we set their coefficients to 1.Due to the moving position,the size of the object in the image keeps changing.The size should adapt to the object during training and testing,and we utilize the following formula to gain the scaling factor and resize the patch:
The original border length of the patch is set to 12,Hdenotes the object height.
4.Experiment results and analysis
We evaluate the DAAC from 3 aspects:human visual inspection,precision degradation of detectors,and computation efficiency.The experimental settings are as follows:
Dataset:We experiment on an individual soldier dataset containing 6 different scenes,2484 images with a resolution of 854 *480.The object in the image is labeled with a bounding box and mask.The function of the mask is to attach the DAAC to the object.More details of the dataset are shown in Table 1.

Fig.7.The scene images and corresponding individual solider digital camouflage patterns:(a)Normal forest;(b) Autumn forest;(c)Broad-leaved forest;(d) Hardwood forest;(e)Summer forest;(e) Rain forest.
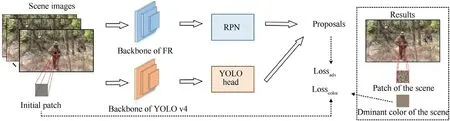
Fig.8.The illustration of the adversarial patch training and embedding.
The Adversarial Patch Training:Target models include Faster R—CNN[4]and YOLO v4[20].We adopt the official implementation of YOLO v4 and utilize the ResNet50 [1]as the backbone of Faster R—CNN with FPN[25].The precision of Faster R—CNN is higher than the results given in Ref.[4].
4.1.Visual inspection
There are two evaluation ways: (1) Utilize canny operator to extract the edge of the camouflaged object.(2) Invite people to conduct the subjective evaluation.The edge extracted by the canny operator is shown in Fig.9,and the objects are bounded by red rectangles.The upper threshold of canny operator is selected by OSTU [47],and the lower threshold is set to 1/3 of the upper threshold based on experience.
Compared with Fig.9(a) and (c),we can see that the object camouflaged with DAAC is highly similar with the background and able to achieve concealment,and it is not easy to find the object with human vision quickly.The results of edge extraction in Fig.9(b)and(d)show that the edge of the object camouflaged with DAAC is disguised,and the camouflaged object and background can merge well.
We compare the visual effects between the patch with color constraint and the one without it.The scenes need not to be distinguished when training the patch without constraint.It means that the patch without constraint can be applied to any scenes.Two types of adversarial patches are shown in Fig.10.
As shown in the middle and right column of Fig.10,there is little difference between two types of the patch when it is small;the patch without constraint is easier to be found when the object is large,e.g.,right column.The constrained one is closer to the digital camouflage pattern in appearance.
We invite 15 persons who have not seen the dataset before the test.The test set used for subjective evaluation includes 100 images randomly selected from the dataset,and half of them is camouflaged by the DAAC.We count the number of false detections and the average detection time of the image.All testers know that the image contains only one object,and we define the case where the Intersection over Union (IoU) between the box bounded by the tester and the ground truth is less than 0.5 as the false detection.The average detection time of the image refers to the average time that the tester bound the box on each test image.The results are shown in Fig.11.
Thex-axis coordinate is the number of the tester.As shown in Fig.11,the statistics of DAAC are significantly higher than that of the original image.The average time to detect DAAC increases by 81.7%compared to detecting the original image,as shown in Fig.11(a).Moreover,the number of false detections generally exceeds that of original images,as shown in Fig.11(b).We also conduct the subjective evaluation of the object camouflaged with the individual camouflage and the unconstrained patch,and its statistics are lower than the originals.Two experiment results have verified the performance of DAAC on human visual detection.

Fig.9.The result of edge extraction: (a)Original image;(b) Edge extracted;(c) DAAC;(d) Edge extracted.

Fig.10.Comparison between patch with and without constraint: (a) Without constraint;(b) With constraint.

Fig.11.The results of subjective evaluation:(a)Average detection time;(b)Number of false detections.
4.2.Precision degradation
We use the individual soldier dataset and the dataset camouflaged by the digital camouflage to train the target model.The Adversarial patch is trained with the SGD optimizer over Nvidia 2080Ti with a total of 8 images per minibatch (4 images per detectors)in a total of 20 epochs.The initial learning rate is set to 0.02 and decreased by 10% in the 10th epoch.When embedding the adversarial patch to the object,we resize the pattern referring to Eq.(7).We measure the precision in the following cases: the original object,the object camouflaged by the individual soldierdigital camouflage,the object embedded with the adversarial patch,and the object camouflaged by DAAC.The precisions in the different scenes are presented in Tables 2 and 3.

Table 1 Number of images in different scenes.
The detectors have a good performance on both the original dataset and the dataset with the digital camouflage.There is a narrow gap between them.After embedding the adversarial patch on the object,the mAP decreases by 73.2% and 71.2% on Faster R—CNN and YOLO v4,respectively.Furthermore,it decreases by 78.0%and 79.2%through the DAAC on Faster R—CNN and YOLO v4,respectively.With DAAC,the mAP goes down to 11.3% and 12.8%,respectively,which reflects its attack strength.
We also compare the precision between the patch with the constraint and the one without it,and the result in Table 4 tells that the mAP of these two kinds of patches are nearly the same.Namely,whether it has the constraint or not,the patch could attack the detectors with high strength.
From the results,it seems that DAAC has good performance in misleading the detectors.The detection results are shown in Fig.12.
4.3.Computation efficiency
We analyze the computation efficiency of individual soldier digital camouflage in DAAC.Because its computing time fluctuates wildly,the longest computing time is more than 20 times than the shortest one.
The step to generate the digital camouflage include histogram filtration,SLIC local-clustering,global sampling,K-Means++clustering,and dominant color filling.We can ignore the times of global sampling,K-Means++clustering,and dominant color filling because they would not change since sampling points are constant.
The time of SLIC local-clustering and histogram filtration is linear with the number of image pixels.Therefore,we mainly analyze the impact of different image resolutions.The normal forest scene dataset is used for test,which contains 270 pictures.(see Table 5)
With different resolutions,processing time increases from 16 min to 55 s(K=400,scale=1/4)to over 9 h(K=100,scale=1).The complexity of SLIC is independent ofK,but the choice ofKaffects the visual effects of individual camouflage.IfKis too small,clustering centers will be repeatedly sampled,and too many image details will be lost;IfKis too large,the proportion of sampling points in clustering centers is too small,leading to that the sampling operation cannot fully extract the image information.to hold the trade-off between computation speed and visual effects,we setK=300 and resolutionscale=1/4,which makes the individual soldier digital camouflage achieve an expected result(Table 5).

Table 2 The mAP on scenes with Faster R—CNN (%).

Table 3 The mAP on scenes with YOLO v4 (%).

Table 4 The mAP of the unconstrained patch and the constrained patch (%).
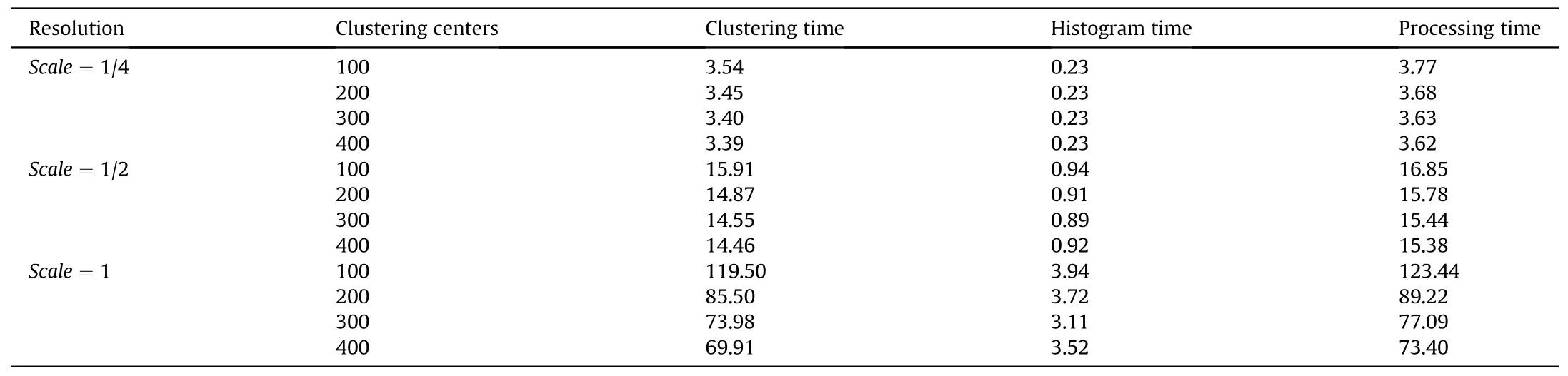
Table 5 Processing time of SLIC local-clustering and histogram filtering(s).
5.Prospect
Existing adversarial camouflage methods mainly focus on static image tasks like image classification and object detection[9,12,13,34,35].A few works validate their high-level adversarial performance in the physical world with some ideal assumptions[11,14,15,28].These works do not suit military practice due to the conspicuous appearance,as we mentioned previously.In addition,we still need to consider some practical factors in the physical application,which leaves a long way to apply the adversarial camouflage in reality.The following introduces the difficulties and some works we could refer to in implementing physical adversarial camouflage.
5.1.The adversarial examples for non-rigid object
Some researchers craft the adversarial example to a traffic sign and automobile [16,28],and these rigid objects do not involve the problem that adversarial example deforms due to the pose change.Subsequent adversarial example designed for non-rigid objects(adversarial camouflage)encounters the problem.It is particularly prominent in the adversarial camouflage crafted for the person.A subtle pose change would cause obvious deformation of the adversarial camouflage on people and the degradation of adversarial performance,making it challenging to apply the adversarial camouflage in the physical world.Some works simulate the physical world in a virtual environment [15,16].However,it cannot simulate well the non-rigid deformation of the adversarial camouflage,such as internal folding and distortion.
Previous works provide some references.Athalye et al.[11]present the Expectation over Transformation (EoT) framework for synthesizing adversarial examples over a chosen distribution of transformations toward image classification.The transformations include scaling,brightness,the addition of noise,random rotation,and translation that may occur in the physical world.They also validate its performance by using the 3D-printing in manufacturing the rigid model camouflaged with adversarial examples in practice.
Xu et al.[37]adopt the EoT on the non-rigid object through the Thin Plate Spline(TPS)to model the possible deformation.TPS has been widely used to model the non-rigid transformation in image alignment and shape matching.For pixelin the imagex,TPS provides a parametric model of pixel displacement to estimate the increment Δ(p(x);θ)when mappingto the deformation imagez.(see Fig.13)
Udenotes Radial Basis Function and θ=[c;a]are the TPS parameters.
The authors intelligently conduct the TPS transformation on the T-shirt distributed by anchor points between two frames in video(Fig.13).In this way,they work out the parameters of TPS and craft the adversarial T-shirt that could evade person detectors,which gives us the helpful hint.The modeling of the TPS is shown below.

Fig.12.The detection results:(a)The ground truth;(b)The detections of YOLO v4;(c)The detections of Faster R—CNN.

Fig.13.The modeling of the TPS.
5.2.The black-box attack
The adversarial attack methods can be divided into white-box attack and black-box attack.The attacker cannot gain any parameters or structure of the target model in black-box attack,which is opposite of white-box attack and close to the real scenario.
Depending on whether the attacker needs to query the model,black-box attacks are labeled as query-based or query-free attacks.The query-free attacks attack the model relying on the transferability that the adversarial example crafted under the known model parameters has adversarial strength to other unfamiliar models.It also can enhance the adversarial strength through the model-ensemble.Transferability and model-ensemble based methods are now in the common use of adversarial examples against detectors.On the other side,since the query-free method is less practical in military practice,we do not discuss them here.
In transferability-based attacks,the attacker usually crafts the adversarial example for the universal module of detectors,e.g.,RPN in two-stage detectors[15,28].The crafted adversarial example has adversarial strength to the detector with the same module.Some works try to attack the classification branch in one-stage detectors and RPN simultaneously [13,16,34,37],and the same with our method.To enhance the transferability,Wei et al.[34]manipulate the feature maps extracted by the backbone,which is usually universal between detectors.They also use the attention weight to measure the objects and attach the perturbation to feature maps through GAN.Their work provides a reference for us to enhance the physical transferability of DAAC.
5.3.Adversarial attacks toward visual object tracking
For the object detector,detecting the object in the video is equivalent to detecting the frame at a specific time.There is no temporal coherence between the current and historical frames in object detection,so the attacker does not need to consider the influence of historical detection on the adversarial attack.However,it is not the same with visual object tracking(VOT).

Fig.14.The Comparison of the original pipeline and the solution to the patch-holistic.
VOT is a fundamental task in computer vison.Given the initial state of a target in the first frame of a video sequence,the aim of VOT is to automatically obtain the states of the object in the subsequent video frames.While locating the object,the tracker would produce temporally coherent results,like bounding boxes,and make the potential area of current result close to that of last result.It is more challenging to craft adversarial examples to VOT due to the temporally coherent frames.
Compared with image classification and object detection tasks,there are fewer adversarial attack methods targeting on VOT,and most of them are white-box attacks.Jia et al.[48]consider the temporal consistency between subsequent frames and use the current adversarial perturbation to initialize the perturbation in the next frame.In addition,they attempt to attack the regression branch that refines the bounding box.Guo et al.[49]combine the temporal attack with spatial-aware gradient sign method and propose the spatial-temporal sparse incremental attack that can generate perturbations in real-time.Liang et al.[50]present the Fast Attack Network that combines drift loss and embedded feature loss to construct an adversarial attack.Chen et al.[51]design a oneshot adversarial attack method with dual attention by optimizing the batch confidence loss with confidence attention and the feature loss with channel attention.Jia et al.[52]propose the black-box IoU attack that sequentially generates perturbations based on the IoU scores from the current and historical frames.
It is hard to know the parameters of the tracker deployed in the background in the real world,so the black-box attacks are more practical than the white-box attacks.We will consider incorporating the temporal attack with DAAC and make it adversarial to object tracker.
6.Subsequent technology research
We will focus on two problems in the subsequent research to apply the DAAC in the physical world.The first problem is the deformation of the adversarial camouflage in the non-rigid object,which we have discussed in subsection 5.1.The second problem is the previously mentioned patch-holistic.
Currently,we attach the adversarial patch with scene feature constraint to the object’s center.If the patch is sheltered,the adversarial strength will deteriorate significantly,the same as the patch-holistic in literature [14].In order to address the issue of patch-holistic,we propose the solution as demonstrated in Fig.14(b).We transform the adversarial patch with scene feature constraint(Resize&Rotate)according to the distance and deviation angle between the detector and camouflaged object.Afterward,we attach the transformed patch evenly to the entire digital camouflage.The part of the detected camouflaged object might contain the adversarial patch.With this practice,the adversarial attack is more likely to maintain a high-level strength even if the object camouflaged with DAAC is sheltered.
However,since it is hard to measure the detection probability of the adversarial patch in the camouflage,we only discuss the situation of attaching the adversarial patch on the center of object in the digital domain.It is a better choice to test in the physical world instead of in the digital domain,and we would facilitate further research on it.
7.Conclusions
After detailing the existing adversarial patch and camouflage research,this paper proposes the Dual Attribute Adversarial Camouflage (DAAC) that can achieve visual concealment while remaining effective in fooling CNNs-based object detectors,thus evading the detections by both detectors and humans in the digital domain.
To the best of our knowledge,this is the first work that combines individual camouflage with the adversarial patch to craft the adversarial camouflage.We propose a new method to extract the scene features efficiently and intelligently utilize the feature to improve the visual effects of DAAC.In addition,we discuss the difficulties in the practical implementation of DAAC and the subsequent research and experiment as well.In the end,we hope our work can provide an informative reference to the generation of adversarial camouflage.
Declaration of competing interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Acknowledgements
The authors would like to acknowledge National Natural Science Foundation of China (grant number 61801512,grant number 62071484) and Natural Science Foundation of Jiangsu Province(grant number BK20180080) to provide fund for conducting experiments.
杂志排行

Defence Technology的其它文章
- Hardware-in-loop adaptive neural control for a tiltable V-tail morphing aircraft
- Resilient tightly coupled INS/UWB integration method for indoor UAV navigation under challenging scenarios
- Microfluidic assisted 90%loading CL-20 spherical particles:Enhancing self-sustaining combustion performance
- GO/HTPB composite liner for anti-migration of small molecules
- Benchmark calculations and error cancelations for bond dissociation enthalpies of X—NO2
- One-step green method to prepare progressive burning gun propellant through gradient denitration strategy