基于检测的高效自动驾驶实例分割方法 *
2023-05-04陈妍妍蔡英凤李祎承
陈妍妍,王 海,蔡英凤,陈 龙,李祎承
(1.江苏大学汽车与交通工程学院,镇江 212013;2.江苏大学汽车工程研究院,镇江 212013)
前言
近年来,基于图形数据的并行计算技术和传感器的快速迭代直接推动了基于深度学习的实例分割算法的发展,并在智能医疗、机器人控制、地理信息系统(GIS)和自动驾驶等领域取得了巨大的进步。实例分割本质上是一项更具细粒度的视觉感知任务,其结合了两项经典的计算机视觉环境理解子任务:目标检测[1]和语义分割[2-3]。目标检测需要以边界框的形式正确回归图像中目标位置和所属类别,而语义分割需要对每个像素分类。因此实例分割不仅需要区分像素类别,还需要准确分割属于同一语义类别下不同实例对象,从而为下游决策规划等任务提供丰富的感知信息[4]。
基于深度学习的实例分割算法主要可以分为4种主流的技术路线[5-6]:基于语义分割的自底向上方法、基于检测的方法、直接的实例分割方法和基于查询的方法。基于语义分割的方法[7-9]首先通过逐像素分类生成具有固定语义类别的分割掩码,然后通过聚类、度量学习等手段将像素分组到单个实例中。该类方法可以更好地保留浅层的细粒度特征和几何形状信息,但其后处理操作较为繁琐,且在对象规模较大且类别较多的复杂工况中准确率较低,因此不太适用于自动驾驶场景。为了不依赖于边界框或像素嵌入等手段,直接的实例分割法[10-11]通过直接预测实例掩码和语义类别。基于实例对象的中心位置和尺寸不同这一基本直觉,SOLO 系列[12-13]按照图像位置分割掩码。具体来说,将输入图像划分成若干个网格,实例中心所在网格单元负责为该实例的每个像素分配类别。但是当多个物体中心落在同一个网格时,预测的掩码和类别会出现混淆,进而影响智能汽车的行驶安全性。基于检测的方法首先通过强大的检测器[14-17]定位先验实例,然后在所得的感兴趣区域内进行分割[18-23]。得益于目标检测的发展,该类方法通常精确度更高,因此本文工作仍然遵循基于检测的实例分割范式。而基于查询的方法[11]利用自然语言处理中的Transformer 机制,并通过查询表示感兴趣对象。ISTR[24]是首个使用低维掩码嵌入进行端对端的实例分割。而Queryinst[25]以级联结构为基础,通过并行的动态掩码头构建检测和分割的多任务框架。该类方法的核心部件是多头注意力,其可显著提升模型性能,但计算资源昂贵。
根据目标定位和掩码生成所需的阶数,目前基于检测的实例分割方法可以分为单阶段方法和二阶段方法两种[26]。基于区域候选网络[27]的二阶段算法精度较高,但是模型的小批量训练会消耗大量显存资源并占据较长推理时间,如Mask-RCNN[19]和Cascade Mask R-CNN[28]。而YoLACT[22]、Blend Mask[29]和CondInst[18]等同时进行定位和分割的单阶段算法速度较快,远远满足自动驾驶所需的实时性需求,但是精度有所欠缺。Orienmask[30]是一种典型的基于锚框的单阶段实时性实例分割算法,其能够以较快速度运行,但准确率远低于常见的二阶段算法。这种以牺牲精度追求高速度的分割方法对于智能汽车的安全行驶是不可接受的。鉴于此,本文以该网络为基准进行算法的改进优化工作,使之能够适用于复杂的交通情况。
实例分割算法的准确率也会受到应用场景的限制。在港口和高速公路这样的单一封闭场景,分割算法通常具有较好的精确度,而在人类活动密集的城市场景,模型性能会显著下降,尤其针对嵌入式部署所设计的轻量级分割模型。为了应对现实交通场景的高精度需求,本文使用Cspdarknet53[16]取代原始骨干网络,通过跨阶段的连接方式扩大感受野并进行特征融合生成更密集的特征图,从而提高网络的特征提取能力。此外,为了产生更具判别性的特征 表 达,本 文 在 特 征 金 字 塔[31](feature pyramid network,FPN)的基础上,通过引入自校正卷积[32](self-calibrated convolutions,Sconv),并 优 化 基 于PANet 网络[33]的多条语义信息传播路径和池化模块,提出了一个全新的双路自校正金字塔池化模块。其中Sconv 可以为每个像素位置建立空间和通道维度的上下文关系,并通过多尺度信息编码实现长距离依赖建模。同时添加的语义信息传播路径可以自底向上地传播浅层的细节信息,恢复实例分割所需的边缘信息。
事实上,真实的城市交通场景还存在大量具有不同尺寸且像素分布差异较大的实例对象。大尺寸物体由于其像素占比大且特征丰富,通常较容易识别。而类似行人、骑行者等小目标,由于其特征的稀疏性,分割任务通常较为困难。此外,由于实例对象距离相机的深度不同,同一类别的不同对象之间也会存在尺寸的显著差异[34]。针对上述交通场景中明显的多尺度目标实例分割问题,本文提出了一种用于街景解析的多头掩码构建模块。根据目标的尺寸范围,该模块被细分成4 个尺度下的边界框检测和方向图生成,这极大地优化了大小目标的分割边缘细粒度。为了进一步减少参数量,本文只在第4 层预测全部尺度下的方向图,每一层下基于锚框的方向图和边界框一一配对进而生成最后的掩码。本文在开源的交通场景数据集BDD100k[35]上进行大量实验来验证所提模型的有效性,并在镇江的交通道路中开展实车验证工作。
1 实例分割方法设计
1.1 框架概览
基于锚框的单阶段实例分割网络通常由骨干网络、特征融合模块和最后的预测模块组成。基于Orienmask 网络,本文对该算法的3 种模块分别进行了优化。具体来说,所提框架采用Cspdarknet53 替代原始的骨干网络(backbone),并提出一种双路自校正金字塔池化模块进行特征融合并充分挖掘相邻像素间关系。此外,考虑到自动驾驶交通场景目标的多样性和复杂性,本文提出一种多头掩码构建模块以充分提高对大小交通对象的检测和分割性能,所提框架如图1所示。图中CBM 和CBL分别代表使用不同激活函数的卷积块,Neck表示瓶颈模块。
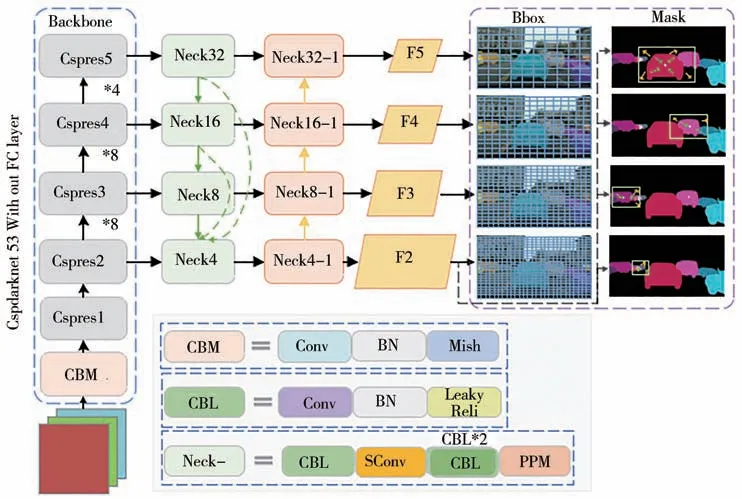
图1 本文所提算法的整体架构图
1.2 骨干网络
以Darknet53为骨干网络的Orienmask 算法在通用的MS-COCO 数据集可以同时实现目标定位和掩码生成,并在速度和精度之间取得较好的平衡。为了应对复杂的城市道路场景并增强网络的特征提取能力,本文使用Cspdarknet53 代替原始的骨干网络。该网络最早在Yolov4[16]中提出,通过引入跨阶段部分模块(cross stage paritial module,CSP),利用其大残差边扩大感受野并整合局部上下文信息,从而在减少计算量的同时获得丰富的梯度组合信息。由于良好的表征学习能力,该网络可以满足大部分分割场景的特征提取任务需求,改进前后的阶段模块对比如图2所示。优化后的骨干网络全部采取Mish激活函数,即使用CBM 卷积块代替原始的CBL 卷积块,从而得到4 倍、8 倍、16 倍和32 倍下采样后的高层强语义特征。
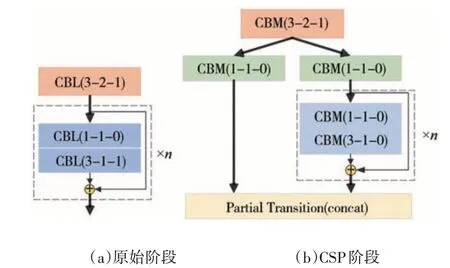
图2 骨干网络对比结果(数字按顺序依次代表卷积核大小、步幅以及相应的填充数)
1.3 特征融合模块
卷积神经网络(convolutional neural networks,CNNs)通过叠加多个卷积核扩宽网络深度以此获得丰富的语义信息。然而,随着网络层数的增加,浅层特征图上的纹理特征愈发稀少,如对象边界和位置信息,甚至小目标的细节信息会在多层映射后完全消失。事实上,在实际交通场景中,由于摄像头距离和广角范围的限制,不可避免地会出现各种数量巨大的小目标,这进一步影响着图像的整体分割性能。而应用于目标检测中的FPN则利用横向连接提取图像的多层次特征,从而较好地提高小目标的检测性能。该模块首先通过融合浅层的定位细节和高层的强语义,然后利用一个3×3 卷积核对相加后的特征进行再次融合以消除上采样所带来的重叠效应。Orienmask[30]仍遵循FPN 范式,但仅使用拼接替代简单的相加操作。
为进一步改善多尺度问题且获得更具判别性的特征表达,本文提出了一种双路自校正金字塔池化模块来重新构建特征融合,如图3 所示。与只定位边框的目标检测不同,实例分割不仅需要网络深处的高层语义信息,还需要图像的浅层定位信息,来分别匹配实例级的检测和像素级的分割任务,这仅仅依赖于自顶向下传播较强语义特征的单路FPN是远远不够的。因此本文使用双路金字塔[33]优化信息传播路径。具体来说,通过在自顶向下的路径基础上增加自底向上的融合模块,将浅层的纹理、结构等细节信息进一步传播到高层的强语义特征图上。此外,为了获得多样性的局部特征,本文还使用Sconv[32]替换基本的卷积特征变换操作,从而在每个像素位置建立远程空间和通道间的依赖关系。图4显示了该模块的详细结构,即通过4 次卷积运算,从原始尺寸和下采样之后的潜在空间映射角度进行多尺度信息编码,从而在扩大局部感受野的同时获得更准确的差异性区域。其中潜在空间映射主要通过下采样后的低维嵌入校准另一部分卷积核的卷积变换。同时为了减少参数量,本文仅在第2 层进行替换。为了聚合同层之间不同尺度的特征,进一步使用 金 字 塔 池 化 模 块[36](pyramid pooling module,PPM)保证该层特征的完整性和多样性。

图3 特征融合模块的整体架构图
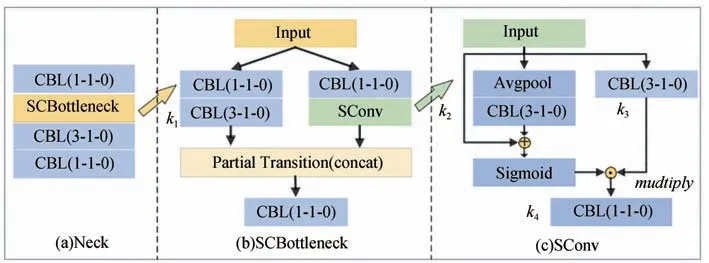
图4 自校正卷积结构图
1.4 多头掩码构建模块
Orienmask 通过添加一个并行的掩码分支预测像素方向图,并结合边界框分支预测的回归参数构建实例掩码。本文算法中仍然保留掩码部分来预测边界框中前景和背景像素的空间偏移。为了同时对不同尺寸目标构建更为细粒度的掩码,该模块被重新设计成4 个尺度下的边界框和方向图预测。每个尺度下生成的边界框都将与该层预设定的锚框相匹配,而每个锚框大小又与方向图相关联。这样就建立了边界框和方向图的对应关系,进而生成多尺度实例掩码。由于卷积在获得高层强语义特征的同时会伴随着细节信息的丢失,这对于像素级方向图是不可接受的,因此该算法只使用最浅层的高分辨率特征预测所有尺度的方向图,然后利用双线性插值恢复到其余3 个尺度下的分辨率大小,如图1 所示。其中浅层掩码构建的详细结构如图5所示。
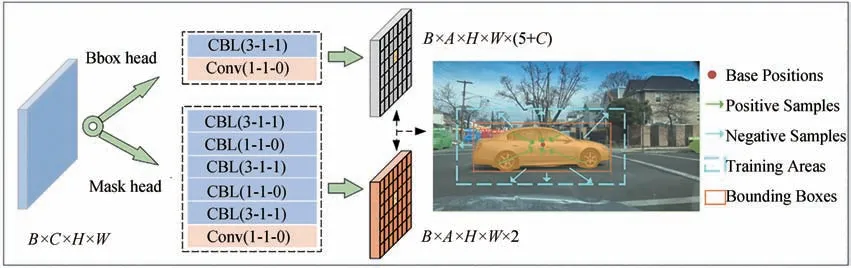
图5 多头掩码构建模块结构图
本文算法的边界框分支仅使用两个大小分别为3×3 和1×1 的卷积核,而掩码分支的设计也非常简洁,由6 个3×3 卷积核和1×1 卷积核交替组成,用于最终的方向图预测。此外,本文将带注释的边界框内前景像素方向偏移定义为指向基准位置的向量。实际上,边界框质心就是可选取的最佳基准位置。而背景像素的方向偏移,即不被实例掩码所覆盖的负样本,则定义为指向边界框的相反位置。因此,前景和背景像素的方向偏移在数学上表示为
式中:b代表基准位置;pf和pb分别代表前景像素和背景像素;αb代表背景像素方向偏移同边界框4 个顶点位置远离基准的方向偏移量比值的最大值的倒数,数学上可以表示为
由于实例掩码标签的固定性,正样本数量因而也是确定的。为了训练时高效的平衡正负样本,本文使用成比例扩大边界框真值的策略以形成有效的训练区域。因此最终形成的掩码可表示为
式中:Pxy为每个像素的坐标;sxy和τ分别表示边界框的尺寸和区域的缩放因子。
1.5 损失函数
为了让网络能够有效分割,本文使用一系列损失函数,主要包括检测损失和方向偏移损失。
1.5.1 检测损失
检测损失是针对目标检测所提出的,主要包括目标置信度损失Lobj、分类损失Lcls和边界框回归损失Lbox。Orienmask 使用Yolov3[15]中带有MSE Ioss 的回归损失,但是该损失函数会割裂边界框中心坐标和宽高之间的联系。因此本文使用CIoU Ioss[16],该公式被定义如下:
式中:IoU为预测框和真实框的交并比;ρ2、c2和ν分别为两个矩形框中心点距离的平方、外接最小矩形对角线距离的平方和两个矩形框宽高比相似度;α为ν的影响因子,α=ν/(ν-IoU+eps),其中eps为一常量,防止分母为0;同时Lcls和Lobj则保持不变。
最后,结合所有的3 种损失函数,本文的检测损失函数定义为
式中:Lcls和Lbox针对所有的正样本;Lobj针对所有的正负样本。
1.5.2 方向偏移损失
方向偏移损失是针对实例掩码所提出的,即分别计算训练区域中前景和背景像素的偏移损失并根据实例数量Nins占比进行加权处理,数学上表示为

因此,总的损失函数定义为
式中λ设置为0.15。
2 实验验证
2.1 公开数据集介绍和相应的锚框设计
本文实验所使用的公开数据集为最新公开的自动驾驶道路场景BDD100k 数据集[35],其以大规模和多样性而闻名,包括100k不同的视频片段、6个不同的场景类型和天气状况以及3 个不同的时间段。该数据集共采集了10k 图片并应用到像素级的实例分割任务中,其中训练集总共8k 张,分辨率大小均为720×1280。此外,该数据集包含驾驶场景中常见的8 个类别,即行人、骑行者、汽车、货车、公共汽车、火车、摩托车和自行车。与基于多边形注释的其他开源分割数据集不同,其标签以位掩码格式存储,并且分割掩码中不允许存在重叠,即每个像素仅分配一个类别标签。
遵循Yolov3,Orienmask 采用K-means[37]聚类算法对通用分割数据集MS-COCO 的标签信息进行聚类并生成9 个锚框。由于不同场景间的差异性,针对通用场景所设计的锚框是不能够通用的。由于道路交通场景通常包含大量具有不同对象尺寸的目标,因此针对BDD100k数据集设计了12种具有不同高宽比的锚框,如表1所示。图6为该数据集上不同对象的边界框像素分布结果,不同的颜色代表聚类所生成的不同簇,[×]表示某一簇的聚类中心。观察发现大部分物体集中在图像的左下角,即具有长尾分布现象。
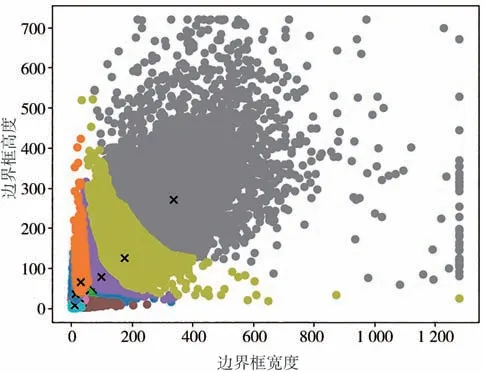
图6 BDD100k数据集的像素分布图
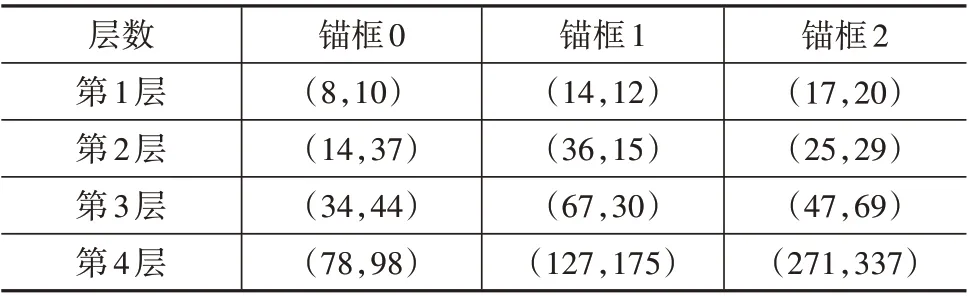
表1 锚框尺寸信息
2.2 实施细节
深度学习模型在训练过程中需要使用大量复杂的矩阵运算和浮点运算,并通过不断的迭代从数千个变量中寻找最优解,本文所提出的实例分割模型在Ubuntu18.04 操作系统和2 张Nvidia RTX 1080Ti显卡上使用Pytorch 深度学习框架进行分布式并行训练和同步批处理归一化,并使用SGD 作为优化器,其动量和权重衰减率分别设置为0.9 和5×10-4。为了提高分割性能,训练过程中还使用了在ImageNet[38]预先训练的模型和数据增强策略,包括颜色抖动、随机水平翻转以及随机裁剪。
学习率、批处理大小和损失函数的选择都会影响模型的训练速度和最终的分割精度。较大的学习率在提高训练速度的同时会造成损失的急剧增大,因此更加适用于训练的初始阶段。然而神经网络训练初期严重的不稳定性又需要极低的学习率。学习率若是设置过小则模型的收敛速度变慢,更易找到模型的最优解但可能产生过拟合问题,因此更加适用于训练的后期。鉴于以上特性,本文使用多阶段学习策略,首先使用warm-up 策略,使学习率随着迭代次数增加不断变大并达到初始训练值,随后使用Poly自适应学习率,使之平稳的下降,公式如下:
式中:In_lr为初始学习率,设置为0.001;it和max_it分别为当前迭代次数和训练最大迭代次数;r为影响因子,设置为0.1;power为衰减指数,设置为1。同样,批处理若是设置过大则模型会越稳定,训练速度会明显加快,但可能需要消耗更多显存以及影响泛化性能;批处理设置过小,训练速度会变慢。受限于实验室的硬件配置,批处理大小设置为4。
2.3 实验结果
本节中,对所提模型在开源实例分割数据集BDD100k 上的结果同一些先进方法对比,主要包括Mask R-CNN[19]、Cascade Mask R-CNN[28]、GCNet[39]、YoLACT[22]和Solov2-Lite[13]。本文选择 Orienmask[30]作为基线模型(baseline)。前3种方法均为基于两阶段框架的实例分割方法,其位置掩码的生成质量高度依赖于目标定位网络,且获得的精度均来自该数据集公开的官方基准。此外,与基于检测的单阶段方法不同,Solov2 依据每个对象中心不同的特性直接恢复实例掩码,因而没有边界框结果。上述所有算法的推理速度均遵循默认配置并在单张1080Ti显卡得出,对比结果如表2所示。
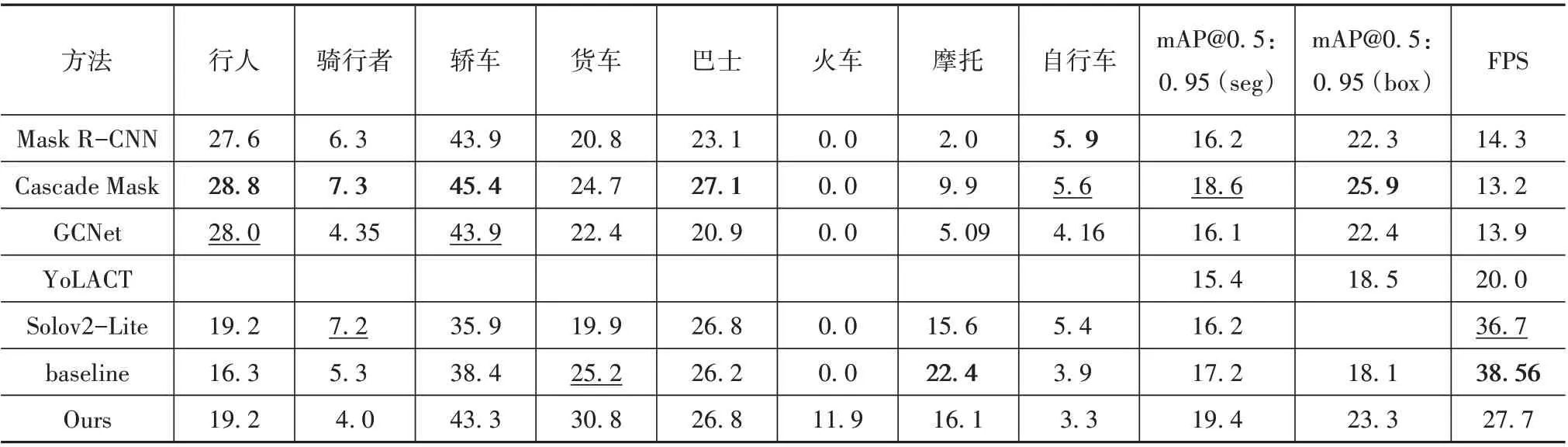
表2 在BDD100k验证集与主流方案的对比结果
观察发现二阶段算法的检测和分割效果整体上比单阶段方法更好,但也伴随着速度较慢等缺陷。与原始baseline相比,所提方法在边界框和分割掩码上分别获得了5.2%和2.2%的mAP@0.5:0.95 改进,但速度有所降低。具体来说,行人、轿车、货车、巴士和火车类别的性能均有所提升,其中交通场景中最为常见的两个重点类别,行人和轿车分别获得了2.9%和4.9%的改进。但是骑行者、自行车的精度略微下降,摩托的精度下降较为明显。对于这些复杂的弱势交通参与者性能不佳,猜测这是由于人-车一体的形状复杂性,即实例间的重叠遮挡问题,造成了网络的混淆。与最好的二阶段架构[28]相比,所提算法获得了0.8%的略微提升,但是速度上有着更大的优势。为了进一步证明所提方法的有效性,选择了验证集上的5张图片进行可视化,结果如图7所示。从上至下依次为原始结果,改进后结果以及相应的真值。定性结果表明所提方法显著改善了大尺寸物体的性能,且一定程度上缓解了远景区域小目标的漏检率,小尺寸物体的边缘也变得更加清晰平滑,尤其是在行人的姿态分割中。

图7 BDDI00k验证集上可视化结果对比图
2.4 消融实验
为了验证所提方法各组成部分的有效性,本文测试了在BDD100k 验证集上所获得的各种模型变体,性能结果如表3 所示。以Darknet53 为骨干网络的原始模型作为baseline。通过添加的双路自校正金字塔池化模块,边界框和实例掩码的准确度分别提高了2.6%和1.2%的 mAP@0.5:0.95。为了更清晰地阐述该模块,本文还对该模块进行了组件拆分,主要包括FPN(Sconv)和PANet(Sconv)。可以观察到后者的改进效果最明显,这进一步证明了本文的猜测即仅依赖单路自顶向下传播较强语义特征对实例分割是远远不够的。此外,设计的多头掩码构建模块通过产生更细致的尺度空间区分微小物体进一步改善了性能,在掩码上获得了1%的提升,在边界框上更是获得了2.5%的提升。最后,结合所有的部件,本文所得模型在该数据集的边界框上和掩码最终获得了41.0%和36.0%,分别获得了5.7 %和4.1 %的mAP@0.5改进。

表3 在BDD100k验证集上的消融实验
图8 显示了双路自校正金字塔池化模块在包含和不包含自校正卷积中所学到的特征可视化对比示例。第1 列是原图,第2 列和第3 列分别表示不加自校正和加入自校正卷积后的 FPN 模块最底层的输出特征。可以观察到,自校正卷积可以学习像素所在目标区域的上下文信息,通过引入小尺度低维空间信息扩大高维空间的局部感受野并产生更具判别性的特征,从而更准确地定位目标对象。图8 中的最后一行远景图像的热力图展示了对多尺度信息的编码能够使网络更加关注小尺寸物体的学习。

图8 特征的可视化结果图
2.5 实际场景结果
针对复杂的道路交通场景BDD100k 数据集,本文主要针对Orienmask算法从锚框设计,网络架构设计和监督学习损失函数这3 部分进行了相应的优化改进工作。为了进一步验证所提出模型的适用性,本文使用Arrizo-5E 自动驾驶实验车在中国城市镇江的3 个不同真实测试场景中进行了实车实验,主要包括城区、高架和校园,实验车辆如图9 所示。此外,本文进行实车实验环境配置时还考虑了不同的天气条件,主要包括3 种工况:白天、夜间和雨天。本文实车实验全部使用魔客仕摄像头来采集分辨率为480×640的图像。

图9 本文实车实验所采用的Arriz0-5E实验车
所提算法在现实场景上的定量结果如图10 所示,从上至下依次为晴天、夜间和雨天工况下的检测和分割结果。其中前两列为城区场景的分割性能,中间一列和最后两列分别为高架和校园的实验结果。整体上,所得模型对于大尺寸物体具有较好的性能,这可能是由于其特征密集的天然优势。相对来说,小目标的性能有所欠缺,但在场景的有效距离范围内,该算法仍然可以实现对小目标的精准定位和分类。与校园工况相比,高架和城区的预测结果相对更好,这可能是校园场景的狭小封闭和人-车交通无序所导致的。此外,随着天气工况的愈发恶劣,目标对象的边界框和分割边缘愈发粗糙。

图10 实车实验结果图
3 结论
本文以Orienmask算法为基础,并针对复杂的交通场景,提出了一种基于单阶段检测算法的多头实例分割框架,其主要包括骨干网络、特征融合模块和多头掩码构建模块。为了获取判别性特征,本文通过引入残差网络、自校正卷积和改善信息传播路径等方式优化网络的特征提取能力。同时针对交通场景下道路目标尺寸的多样性和复杂性,所提的多头掩码构建模块被设计成4 个尺度下的边界框和方向预测分支,以适应不同尺度物体并生成更具细粒度的实例掩码。此外,本文还优化了损失函数。
在开源数据集BDD100k 上的结果表明所提算法要显著优于原始方法,在边界框定位和掩码生成上分别获得了5.7%和4.1% mAP@0.5 改进,同时满足实时性要求。最后真实场景的实车实验也证明了所提算法具有更好的精度和鲁棒性,且对不同的场景也有较好的适应能力。但是也观察到部分弱势交通参与者的性能有所下降,未来将着重从实例间的遮挡角度优化模型算法,并进一步提高推理速度。
