基于信息熵加权的多视图子空间聚类算法
2023-04-29李顺勇许晓丽
李顺勇 许晓丽

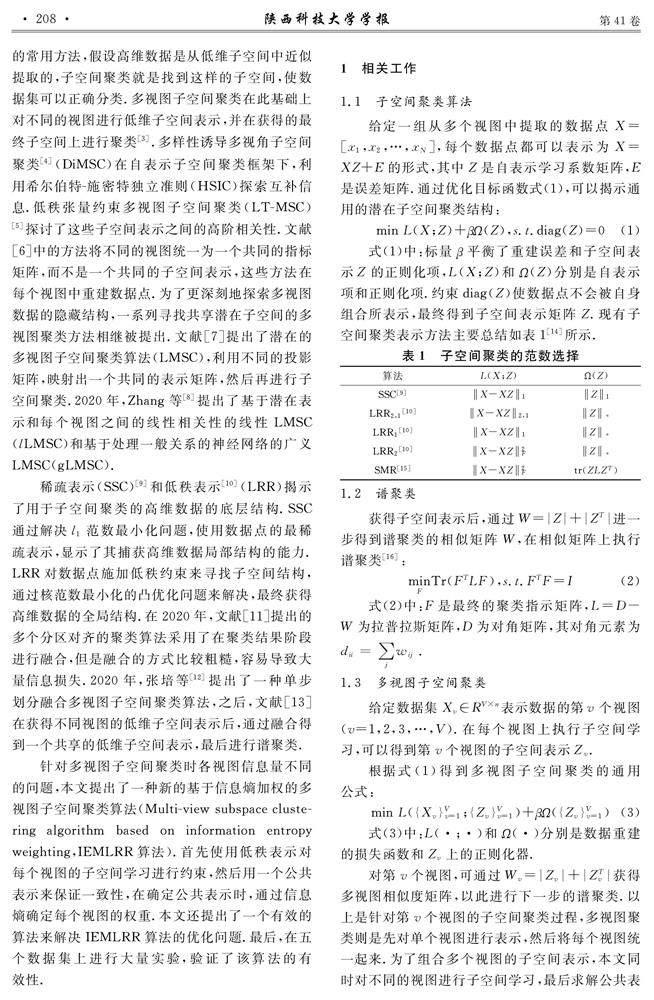

摘要:多视图数据集普遍分布在低维子空间上.为了解决多视图子空间聚类时各视图信息量不同的问题,提出了一种新的基于信息熵加权的多视图子空间聚类算法(IEMLRR).首先在低秩表示的约束下获得每个视图的子空间表示,在获取公共子空间表示时,使用信息熵加权来保证不同视图所携带的信息差异,最后用谱聚类算法进行聚类.采用增广拉格朗日乘子法对IEMLRR算法进行优化,并在五个数据集上验证了算法的有效性.
关键词:信息熵加权; 多视图学习; 低秩表示; 子空间聚类
中图分类号:TP391文献标志码: A
Multi-view subspace clustering algorithm based on
information entropy weighting
LI Shun-yong, XU Xiao-li(School of Mathematics Sciences, Shanxi University, Taiyuan 030006, China)
Abstract:Multi-view datasets are generally distributed across low-dimensional subspace.In order to solve the problem that the amount of information of each view is different when multi-view subspace is clustered,a new multi-view subspace clustering algorithm based on information entropy weighting (IEMLRR) is proposed.First,the subspace representation of each view is obtained under the constraints of the low-rank representation,and when the public subspace representation is obtained,the information entropy weight is used to ensure the information difference carried by different views,and finally the spectral clustering algorithm is used for clustering.The IEMLRR algorithm was optimized by augmented Lagrange multiplier method,and the effectiveness of the algorithm is verified on five datasets.
Key words:information entropy weighting; multi-view learning; low-rank representation; subspace clustering
0引言
在如今的大数据时代,数据信息的多样化使得单视图数据已经无法满足人们的需要.针对同一个事物,多视图数据[1]是通过提取不同角度的不同特征来获取的.子空间聚类[2]是恢复数据子空间结构的常用方法,假设高维数据是从低维子空间中近似提取的,子空间聚类就是找到这样的子空间,使数据集可以正确分类.多视图子空间聚类在此基础上对不同的视图进行低维子空间表示,并在获得的最终子空间上进行聚类[3].多样性诱导多视角子空间聚类[4](DiMSC)在自表示子空间聚类框架下,利用希尔伯特-施密特独立准则(HSIC)探索互补信息.低秩张量约束多视图子空间聚类(LT-MSC) [5]探讨了这些子空间表示之间的高阶相关性.文献[6]中的方法将不同的视图统一为一个共同的指标矩阵,而不是一个共同的子空间表示,这些方法在每个视图中重建数据点.为了更深刻地探索多視图数据的隐藏结构,一系列寻找共享潜在子空间的多视图聚类方法相继被提出.文献[7]提出了潜在的多视图子空间聚类算法(LMSC),利用不同的投影矩阵,映射出一个共同的表示矩阵,然后再进行子空间聚类.2020年,Zhang等[8]提出了基于潜在表示和每个视图之间的线性相关性的线性LMSC(lLMSC)和基于处理一般关系的神经网络的广义LMSC(gLMSC).
稀疏表示(SSC)[9]和低秩表示[10](LRR)揭示了用于子空间聚类的高维数据的底层结构.SSC通过解决l1范数最小化问题,使用数据点的最稀疏表示,显示了其捕获高维数据局部结构的能力.LRR对数据点施加低秩约束来寻找子空间结构,通过核范数最小化的凸优化问题来解决,最终获得高维数据的全局结构.在2020年,文献[11]提出的多个分区对齐的聚类算法采用了在聚类结果阶段进行融合,但是融合的方式比较粗糙,容易导致大量信息损失.2020年,张培等[12]提出了一种单步划分融合多视图子空间聚类算法,之后,文献[13]在获得不同视图的低维子空间表示后,通过融合得到一个共享的低维子空间表示,最后进行谱聚类.
针对多视图子空间聚类时各视图信息量不同的问题,本文提出了一种新的基于信息熵加权的多视图子空间聚类算法(Multi-view subspace clustering algorithm based on information entropy weighting,IEMLRR算法).首先使用低秩表示对每个视图的子空间学习进行约束,然后用一个公共表示来保证一致性,在确定公共表示时,通过信息熵确定每个视图的权重.本文还提出了一个有效的算法来解决IEMLRR算法的优化问题.最后,在五个数据集上进行大量实验,验证了该算法的有效性.
1相关工作
1.1子空间聚类算法
1.2谱聚类
1.3多视图子空间聚类
1.4信息熵(简称熵)
2本文模型
本节介绍提出的基于信息熵加权的多视图子空间聚类算法(IEMLRR算法),并对此算法进行优化.
2.1IEMLRR算法
2.2优化过程
2.2.1优化w(v)
2.2.2固定w(v),独立优化单个视图中的变量
3实验与分析
3.1数据集介绍
3.2评价指标
3.3对比方法介绍
为了验证本文提出算法的有效性,将IEMLRR算法分别与自身三个变体算法和DiMSC、LMSC、MLRRSC与FMR四个多视图聚类算法进行比较.
IEMLRR算法的三个变体算法分别为:
(1)LRRbest:单视图下的LRR[9]:在每个视图特征上运行LRR,来获得低秩子空间表示,在这些表示上运行谱聚类,选择最好结果;
(2)MLRR:在低秩表示约束下的多视图子空间聚类算法,在单个视图分别运行低秩子空间表示,然后将获得的子空间表示组合在一起;
(3)WMLRR:在MLRR基础上,获得一个公共的子空间表示,用自适应权重[23]对视角进行加权.
进行比对的四个多视图子空间聚类算法:
(1)DiMSC[4]:在获取子空间表示的过程中,加入希尔伯特-史密斯独立性准则下的多样性项,探索了多视图表示的互补性;
(2)LMSC[7]:在多个视图均来自同一个潜在的表示的假设下,通过合理的潜在表示和子空间重构进行约束,最后用潜在表示进行聚类,获得聚类结果;
(3)MLRRSC[20]:基于低秩和稀疏子空间的聚类算法,要求子空间表示矩阵同时为低秩和稀疏矩阵;
(4)FMR[21]:在希尔伯特-史密斯独立性准则理论支持下,构造互补信息的潜在表示项,再通过数据重建得到子空间表示.
3.4实验结果分析
3.4.1消融性实验结果分析
在实验过程中,首先对每组数据进行归一化处理,并针对不同算法进行参数调优,最终选取最优结果,每组实验进行30次,获得聚类结果的平均值和标准差,具体实验结果如表4所示.
分析表4可知,与未加权的MLRR算法和自适应加权算法WMLRR相比,在五个数据集上的各个评价指标值均有显著提升,表明本文提出的IEMLRR算法具有更优的聚类效果,也说明利用不同视角的信息来进行加权是可取的.
为了更加直观地体现基于信息熵加权下每个视图权重的差异,以MSRCV1数据集为例,对MSRCV1数据集在IEMLRR算法下最终获得的最优权重值与单视图条件下五个视图的ACC和NMI进行展示,具体如图1所示.由图1可以看出,MSRCV1数据集在视图2上聚类结果最好,且视图2的权重值最大,表明IEMLRR算法所求各权重与聚类结果一致.
图1MSRCV1数据集各视图的权重及聚类效果3.4.2与其他算法对比实验结果分析
对比IEMLRR算法与其余几种算法,结果如表5所示.表5显示了不同算法的聚类性能结果.与多视图子空间聚类算法DiMSC,基于潜在表示的算法LMSC、FMR,基于低秩稀疏聚类算法MLRSSC相比,IEMLRR算法在大部分数据集上都优于其他算法,比如在UCI-digit数据集上,本文算法比MLRSSC在ACC和NMI方面分别提高了2.63%和0.95%左右;对于每个数据集,IEMLRR算法在NMI和ARI上优势显著,具体而言,IEMLRR产生的NMI与数据集Caltech101-7、BBCsports、MSRCV1、UCI-digit上的其他算法相比,分别至少提高1.36%、3.60%、5.46%、0.95%.
3.5参数设置与收敛性分析
3.5.1参数设置
实验过程中,超参数λ从集合{1e-2,5e-2,0.1,1,5,10,1e2,5e2,1 000}中選择.参数θ在{0.001,0.01,0.1,1,10,100,1 000}中进行选择.惩罚参数μ从{101,102,103,104}中进行选择,ρ设置为1.1,maxμ为106,最大迭代次数设置为100.
3.5.2收敛性分析
为了实证IEMLRR算法的收敛性,画出本文所提算法在五个数据集上的收敛曲线如图2所示.在图2中,三条曲线分别表示三个收敛条件所计算出的误差.可以看出,在迭代次数大约到50次时,本文提出的IEMLRR算法在五个数据集上均收敛,这表明算法的目标值随着迭代次数的增加显著降低,同时也验证了该算法良好的收敛性.
4结论
本文提出了一种基于信息熵加权的多视图子空间聚类算法(IEMLRR算法),该算法的主要特点是在对子空间进行低秩约束的基础上,学习所有视图的子空间表示,再获取公共的子空间表示,在这过程中,引入信息熵来区分不同视图的信息,从而获得不同视图对公共子空间表示的贡献程度.在五个多视图数据集上的实验结果表明,该算法的性能优先于其他现有的多视图子空间聚类算法.
参考文献
[1] Zhao J,Xie X,Xu X,et al.Multi-view learning overview:Recent progress and new challenges[J].Information Fusion,2017,38(2):43-54.
[2] Zhan K,Zhang C,Guan J,et al.Graph learning for multi-view clustering[J]. IEEE Transactions on Cybernetics,2017,48(10): 2 887-2 895.
[3] 李顺勇,顾嘉成.一种增强的K-prototypes混合数据聚类算法[J].陕西科技大学学报,2021,39(2):183-188.
[4] Cao X C,Zhang C Q,Fu H Z,et al.Diversity-induced multi-view subspace clustering[C]//IEEE Conference on Computer Vision and Pattern Recognition.Boston:IEEE,2015:586-594.
[5] Zhang C,Fu H,Liu S,et al.Low-rank tensor constrained multi-view subspace clustering[C]//IEEE International Conference on Computer Vision.Santiago:IEEE,2015:1 582-1 590.
[6] Gao H,Nie F,Li X,et al.Multi-view subspace clustering[C]// International Conference on Computer Vision.Santiago:IEEE,2016:4 238-4 246.
[7] Zhang C Q,Hu Q H,Fu H Z,et al.Latent multi-view subspace clustering[C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition.Honolulu:IEEE,2017:4 279-4 287.
[8] Zhang C Q,Fu H Z,Hu Q H,et al.Generalized latent multi-view subspace clustering[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2020,42(1):86-99.
[9] Ehsan E,Rene V.Sparse subspace clustering:Algorithm,theory,and applications[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(11):2 765-2 781.
[10] Liu G,Lin Z,Yan S,et al.Robust recovery of subspace structures by low-rank representation[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(1):171-184.
[11] Zhao K,Guo Z P,Huang S D,et al.Multiple partitions aligned clustering[C]//Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence.Macao:IJCAI,2019:2 701 -2 707.
[12] 張培,祝恩,蔡志平.单步划分融合多视图子空间聚类算法[J].计算机科学与探索,2021,15(12):2 413-2 420.
[13] 黄宗超,王思为,祝恩,等.基于子空间融合的多视图聚类算法[J].郑州大学学报(理学版),2021,53(1):68-73.
[14] Li R H,Zhang C Q,Fu H Z,et al.Reciprocal multi-layer subspace learning for multi-view clustering[C]//International Conference on Computer Vision.Seoul:IEEE,2019:8 171-8 179.
[15] Hu H,Lin Z C,Feng J,et al.Smooth representation clustering[C]//IEEE Conference on Computer Vision and Pattern Recognition.Columbus:IEEE,2014:3 834-3 841.
[16] 陈迪,刘惊雷.基于乘法更新规则的k-means与谱聚类的联合学习[J].南京大学学报(自然科学版),2021,57(2):177-188.
[17] 代劲,胡艳.混合粒度多视图新闻数据聚类方法[J].小型微型计算机系统,2021,42(4):719-724.
[18] 曹容玮,祝继华,郝问裕,等.双加权多视角子空间聚类算法[J].软件学报,2022,33(2):585-597.
[19] 刘金花,王洋,钱宇华.基于谱结构融合的多视图聚类[J].计算机研究与发展,2022,59(4):922-935.
[20] Brbic M,Kopriva I.Multi-view low-rank sparse subspace clustering[J].Pattern Recognition the Journal of the Pattern Recognition Society,2018,73(8):247-258.
[21] Li R,Zhang C,Hu Q,et al.Flexible multi-view representation learning for subspace clustering[C]//Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence.Macao:IJCAI,2019:2 916-2 922.
【责任编辑:陈佳】
