一种基于权值缩减克服IR-Drop 的忆阻器阵列神经网络训练方法
2023-04-19缪伟伟
缪伟伟
(合肥工业大学 计算机与信息学院, 合肥 230601)
0 引 言
深度神经网络(DNN)中存在大量的矩阵乘法运算。 然而随着神经网络层数的不断增加,利用传统处理器实现矩阵乘法会造成计算时间过长和能耗过大。 新型器件忆阻器(memristor)为实现矩阵乘法提供了一种更高效的方式[1],能够以O(1) 的时间复杂度实现矩阵乘法。 并且与传统的CMOS ASIC 和GPU 解决方案相比,忆阻器阵列可以将能效提高100 倍以上[2-3]。 忆阻器阵列实现矩阵乘法的结构如图1 所示。
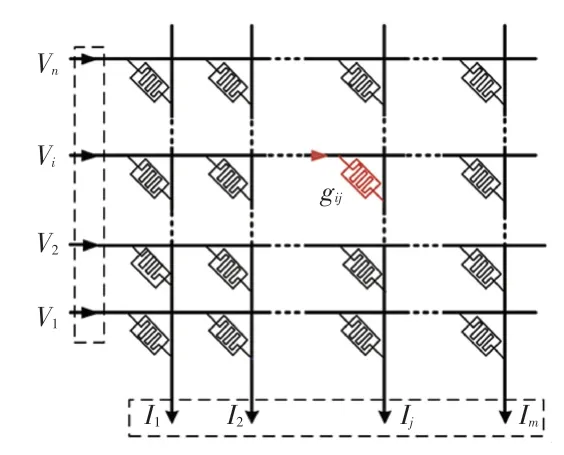
图1 利用忆阻器阵列实现矩阵乘法Fig. 1 The implementation of matrix multiplication using memristor-based crossbar
图1 中,忆阻器的电导值gij表示神经网络的权值,为忆阻器电阻值的倒数。 对忆阻器阵列的第i行施加一个电压矢量Vi,流经第i行第j列忆阻器的电流为gij·Vi,第j列的输出电流,即为输入向量与权值矩阵第j列的乘积结果。
尽管忆阻器具有很好的应用前景,但是由于IR-Drop 问题,会导致忆阻器阵列计算精度下降。IR-Drop 会造成输入端电压与实际到达忆阻器的计算电压之间存在偏差,导致忆阻器的实际输出偏移理想输出,忆阻器阵列计算精度降低。 在本文中,将输入端电压称为理想计算电压,实际到达忆阻器的计算电压称为实际计算电压。 忆阻器离输入端和输出端越远,IR-Drop 造成的理想计算电压和实际计算电压的偏差越大,忆阻器的理想输出电流和实际输出电流的偏差也越大[4-5]。 并且随着忆阻器阵列规模的增大,IR-Drop 对忆阻器阵列计算精度的影响也越明显。 例如,当忆阻器阵列规模从16×16 增大到128×128 时,计算精度降低了35%[5]。
为减轻忆阻器阵列中IR-Drop 的影响,文献[5]、文献[6]分别提出主成分分析(Principal Component Analysis, PCA) 和 奇 异 值 分 解(Singular Value Decomposition, SVD)的方法将大矩阵分解为2 个小矩阵的乘积。 通过减小忆阻器阵列规模,降低IRDrop 对忆阻器阵列计算精度的影响。 文献[7]、文献[8]分别在忆阻器阵列每列的输出端添加对应的平均电流偏移量以及调整每列跨阻放大器(TIA)的阻值,以此直接减小列输出的偏差。 文献[4]、文献[9]在网络训练中加入忆阻器阵列的IR-Drop 模型,使训练出的权值对IR-Drop 具有更好的鲁棒性。
IR-Drop 会降低忆阻器的实际计算电压,进而影响忆阻器的输出结果。 但忆阻器的输出结果等于忆阻器的实际计算电压与权值的乘积。 忆阻器的权值越小,IR-Drop 造成的输出结果偏差也越小。 假设理想计算电压为1 V,忆阻器的实际计算电压为0.8 V。当忆阻器权值为5 时,忆阻器的输出结果偏差则为|1-0.8 |×5 =1。 而当忆阻器权值为1 时,忆阻器的理想输出结果与实际输出结果的偏差为|1-0.8 |×1 =0.2。 同时映射到忆阻器的权值越小,忆阻器阻值越大,IR-Drop 对忆阻器实际计算电压的影响也就越小,造成忆阻器输出结果偏差也越小[8]。因此,小权值会使忆阻器输出结果对IR-Drop 有更好的鲁棒性。
为减小IR-Drop 对忆阻器阵列计算精度的影响,本文提出了一种基于权值缩减的神经网络训练方法(A Network Training Weight Reduction),为叙述方便在后续部分中简称为NTWR。 首先,在网络训练中添加L2 正则化,以此使训练出的权值尽可能小,从而提高忆阻器阵列计算精度对IR-Drop 的鲁棒性。 然后,本文通过基于行列约束的映射算法将大权值映射到离输入端和输出端较近的位置,避免大权值映射到IR-Drop 影响较大的忆阻器上,产生较大的输出结果偏差。 在确定权值与忆阻器的映射关系后,可能仍存在部分大权值映射到离输入端和输出端较远处的忆阻单元上,导致忆阻器阵列计算精度降低。 最后,减小映射到离输入端和输出端较远处的大权值,再利用重训练调整附近权值以恢复由于减小权值带来的计算精度损失。 不断迭代减小权值和重训练,直到忆阻器阵列的计算精度无法提升为止。
1 基于权值缩减的神经网络训练方法
1.1 NTWR 方法的整体流程
NTWR 方法的整体流程如图2 所示。 由图2 可看到,第一步是在神经网络训练中添加L2 正则化,使训练出的权值分布在较小值的范围,从而减小IR-Drop对忆阻器阵列计算精度的影响。 第二步是在得到训练好的网络权值后,执行行列映射算法将大权值映射到离输入端和输出端较近的位置,避免大权值映射到IR-Drop 影响较大的位置,造成较大的计算精度损失。 第三步是在执行映射算法后,减小映射在IR-Drop 影响较大处的权值,以此降低IR-Drop 造成的输出结果偏差。 再执行重训练恢复由于权值减小造成的计算精度损失,直到忆阻器阵列计算精度无法提升为止。
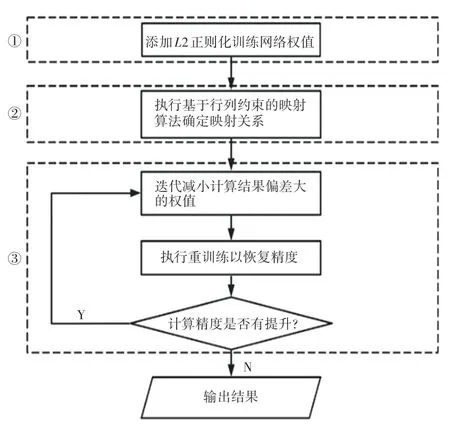
图2 NTWR 的总体流程Fig. 2 The overall process of NTWR
1.2 L2 正则化
在本节中,将详细探讨L2 正则化在神经网络权值训练中的作用。 研究时在训练中增加L2 正则化,是因为L2 正则化在训练过程中对大权重具有更大的偏向性, 可以将权重分布缩小到较小的值范围[10],进而提高忆阻器阵列的计算精度对IR-Drop的鲁棒性。因此本文提出在损失函数中增加L2 正则化的惩罚项,利用L2 正则化使训练出的权值尽可能小,从而降低IR-Drop 的影响。 这里需用到的数学公式为:
其中,W是神经网络的权值矩阵;λ是正则化参数,用来控制L2 正则化对损失函数的重要性;是L2 正则化的惩罚项。
目前,比较流行的为L1 正则化方法和L2 正则化方法,可分别由如下公式进行描述:
如果在网络训练中添加L1 正则化,则会使网络权值为零,导致训练出的神经网络稀疏化。 尽管稀疏化使大部分权值为零,不会对神经网络的计算精度造成较大的精度损失[11],但会使神经网络的计算精度对训练出的非零权值更加敏感。 在IR-Drop 影响下,会造成非零权值的输出结果出现偏差,对忆阻器阵列计算精度产生更大的影响。 而由文献[12]分析可知,L2 正则化可以降低神经网络的敏感性,从而提高神经网络的鲁棒性。 执行神经网络训练后,可以得到L2 正则化后的权值矩阵。 下面将对权值矩阵的映射算法进行研究阐述。
1.3 基于行列约束的映射算法
在本节中,将详细介绍基于行列约束的映射算法(Mapping algorithm with the Constraint of Row and Column, MCRC)的具体步骤。 MCRC 算法的主要思想是将权值矩阵中未确定映射关系的最大值在行列约束下映射到离输入端和输出端最近的忆阻器上,以此最小化IR-Drop 对忆阻器阵列计算精度的影响。 其中,行列约束指的是权值矩阵同一行和同一列的权值在映射到忆阻器阵列后仍在同一行和同一列。 之所以需要令确定的映射关系满足行约束,是因为施加在忆阻器阵列一行的理想计算电压是同一个,而不同行的理想计算电压是不同的。 例如,若将权值矩阵整个第1 行的权值映射到忆阻器阵列第2行,则只需要在忆阻器阵列第2 行施加权值矩阵第1 行的理想计算电压V1,权值矩阵第1 行第j列的输出结果仍为V1× w1j,如图3(a)所示。 但是若权值矩阵第1 行的w11和w12分别映射到忆阻器阵列第2行和第3 行,则权值矩阵第1 行第2 列的输出结果不再是V1×w12、而是V3×w12,如图3(b)所示。 同理,每一列的输出结果等于该列所有忆阻器的输出结果之和,如果权值矩阵一列的权值被映射到忆阻器阵列的不同列上,同样会导致输出结果出现误差。 故权值矩阵与忆阻器阵列的映射关系也需要满足列约束。
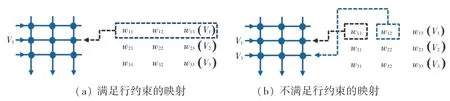
图3 基于行约束映射的举例Fig. 3 The example of mapping with the constraint of row
忆阻器阵列实现多层神经网络时,每层忆阻器阵列的输出都会连接下一层忆阻器阵列的输入,如图4 所示。如果调整第n层权值矩阵与忆阻器阵列的映射关系,例如将权值矩阵第i行映射到忆阻器阵列第j行,则原连接到第n层第i行的第n -1 层的输出也需要重新连接到第n层的第j行。 同理,如果要将第n层权值矩阵第i列映射到忆阻器阵列第j列,则原连接第n层第i列和第j列的第n +1 层的输入也需要交换连接。 因此,如果想要独立映射每层权值矩阵的M行或M列,而不改变与相邻层的连接,则需要使用M × M的路由模块来连接相邻层的忆阻器阵列,会带来较大的硬件开销[13]。 而MCRC算法是一种对忆阻器阵列通用的映射算法,无需得知忆阻器阵列的相关信息。 因此可以在确定每层权值矩阵与忆阻器阵列的映射关系后再制造忆阻器阵列,在多层神经网络中无需考虑映射带来的硬件开销,只需确定的映射关系满足行列约束。 故本文提出的MCRC 算法可以同时执行行映射和列映射。
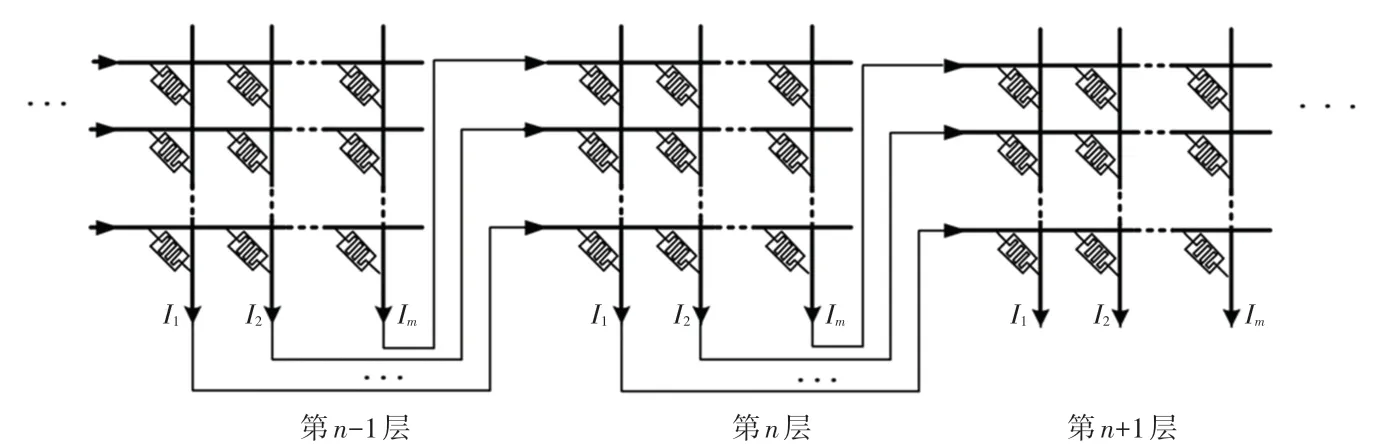
图4 忆阻器阵列实现多层神经网络Fig. 4 The implementation of multi-layer neural network using memristor-based crossbar
MCRC 算法的伪代码具体见算法1。
算法1 MCRC 算法
输入权值矩阵Wn ×m, 距离矩阵Dn ×m
输出输出映射结果
1.Tn ×m =| Wn ×m |,mapped_row[n] 和mapped_col[m] 全部置为-1,occupied[n][m] 全部置为false;
2.While (存在未确定映射关系的权值)
3. 在当前Tn ×m中找到最大值,将其行序号和列序号分别赋给row,col
4.visited[n][m]=occupied[n][m]
/ /将occupied数组中的信息复制到visited数组中
5.While(true)
6. 在当前Dn ×m找到visited[i][j]=false的最小值,将其行序号和列序号分别赋给i,j
7.If( (mapped_row[i]=-1or mapped_row[i]=row)and(mapped_col[i]= -1or mapped_col[j]=col))
/
/判断是否满足行列约束
8.mapped_row[i]=row,mapped_col[j]=col;
/
/将确定的映射关系存储到数组中
9.occupied[i][j]= true,T[row][col]=-1;
/ /更新状态
10.break;/ /跳出当前while循环
11.End
12.visited[i][j]=true;
/
/标记当前位置被访问
13. End
14.End
15.输出映射结果
在算法中,输入为权值矩阵Wn ×m和距离矩阵Dn ×m。 距离矩阵第i行第j列的元素Dij表示忆阻器阵列第i行第j列的忆阻器离输入端和输出端的距离。 以离输入端和输出端最近的忆阻器为原点,字线为横坐标,位线为纵坐标,建立坐标轴,如图5 所示。 以横坐标和纵坐标之和表示忆阻器离输入端和输出端的距离,如Dij =i +j。
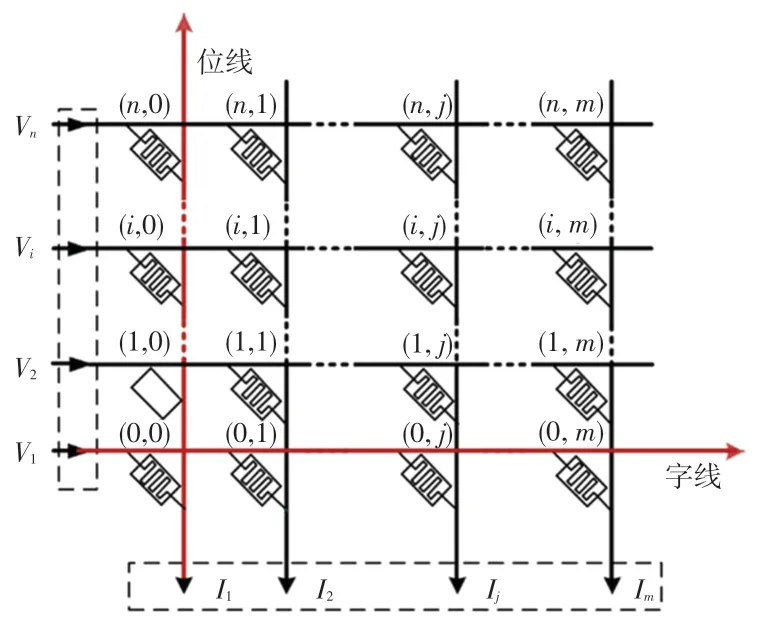
图5 在忆阻器阵列上建立坐标轴Fig. 5 The coordinate system based on memristor-based crossbar
算法1 中,伪代码的第1 行,对矩阵Tn ×m、数组mapped_row、mapped_col和occupied进行初始化。Tn ×m为Wn ×m的绝对值矩阵,其中Tij =|Wij |。 数组mapped_row和mapped_col分别用于存储确定的行映射关系和列映射关系。 数组occupied用于标记忆阻器阵列中忆阻器是否已确定映射关系,occupied[i][j]=true表示忆阻器阵列第i行第j列的忆阻器已确定映射关系。
下面通过具体的例子来阐释基于MCRC 算法的具体执行过程。假设矩阵Tn ×m、距离矩阵Dn ×m和数组occupied分别为、D3×3和。 研究推得的各矩阵值具体如下:
算法1 伪代码第3 ~4 行, 按照Tn ×m中值大小降序确定权值的映射关系,令row和col分别为Tn ×m中最大值的行序号和列序号。 利用数组visited标记忆阻器是否被访问过或已确定重映射关系。 例如在中,最大值为T22=1,row=2,col=2。
算法1 伪代码第6 行,按照离输入端和输出端的距离升序选择能在行列约束下与权值确定映射关系的忆阻器,令i和j分别为Dn ×m中visited[i][j]=false的最小值的行序号和列序号。 例如在当前D3×3中visited[i][j]=false的最小值为D00,i和j均为0。
算法1 伪代码第7~11 行,判断权值矩阵第row行第col列权值映射到忆阻器阵列第i行第j列忆阻器是否满足行列约束。 如果满足行列约束,则保存确定的映射关系,更新相应状态。 例如在当前中,mapped_row[0] 和mapped_col[0] 均为-1,即忆阻器阵列第0 行和第0 列都未确定映射关系。 因此,权值矩阵第2 行第2 列的权值与忆阻器阵列第0行第0 列确定映射关系。mapped_row[0]= 2,mapped_col[0]=2,和分别更新为和, 跳出当前while 循环。 研究推得的各矩阵值具体如下:
算法1 伪代码第2 ~14 行,若还存在未确定映射关系的权值,则继续执行算法。 如中仍存在未确定映射关系的权值,因此继续执行算法。 在中,最大值为T21=0.9,row=2,col=1。 将的信息复制到数组visited中。 在当前D3×3中visited[i][j]=false的最小值为D10,i=1,j=0。 因mapped_col[0]=2 且mapped_col[0] ≠1,即忆阻器阵列第0 列已经确定映射关系,且并不是权值矩阵第1 列确定的映射关系,因此不满足行列约束。 将visited[1][0] 置为true,继续寻找当前D3×3中visited[i][j]=false的最小值。 此时满足条件的最小值为D01,i=0,j=1。mapped_row[0]≠1但mapped_row[0]=2,并且mapped_col[1]=-1,满足行列约束。 因此,权值矩阵第2 行第1 列的权值与忆阻器阵列第0 行第1 列确定映射关系。mapped_row[0]=2,mapped_col[1]=1,和分别更新为和,跳出当前while循环。 由于在中仍有未确定映射关系的权值,因此继续根据上述步骤执行算法,直到所有权值确定映射关系。 研究推得的各矩阵值具体如下:
算法1 伪代码第15 行,当Tn ×m中所有值确定映射关系后,输出映射结果。 如对继续执行算法,可以得到映射后的T3×3为。 推得的矩阵值具体如下:
1.4 重训练算法
尽管利用MCRC 算法可以尽可能避免大权值映射到离输入端和输出端较远的忆阻器上,但大权值若聚集于一行或一列,则无法避免地会有部分较大权值被映射到离输入端和输出端较远的忆阻器上,导致忆阻器阵列计算精度的下降。 因此,本文提出一种重训练算法,通过减小映射到离输入端和输出端较远处的权值,降低IR-Drop 对输出结果的影响。 再通过重训练,恢复权值减小造成的计算精度损失。 重训练算法的伪代码具体见算法2。
算法2 重训练算法
输入映射后的权值矩阵, 距离矩阵Dn ×m, 偏差矩阵, IR - Drop 影响矩阵Sn×m
输出输出新的权值矩阵
1.While (忆阻器阵列计算精度仍可提升)
2. 初始化Modified[n][m],全部置为false
/
/用于标记修改过的权值
3. 在当前Sn ×m中找到最大值,将对应的权值赋给Wij
4.Wij =Wij /2/ /减小权值
5.Modified[i][j]=true
/
/将权值进行标记,重训练中不更新该权值
7. 测试重训练后忆阻器阵列的计算精度
8. 重新计算Sn×m
9. End
算法2 伪代码第2 ~4 行是迭代将IR-Drop 影响最大的权值减小为原来的1/2,再通过标记该权值,使其在后续重训练中不更新。 由于减小权值会造成计算精度的降低,因此通过重训练来恢复计算精度,参见伪代码第6 行。 在重训练时,为避免权值出现较大变化,造成映射到离输入端和输出端较远处的小权值突然更新为大权值的情况,可以以较小的学习率训练神经网络。 较小的学习率可以使权值以小细粒度进行调整,避免权值出现较大的变化[14]。 伪代码第7 行测试重训练后忆阻器阵列的计算精度,更新矩阵Sn×m。 如果相较于重训练前,忆阻器阵列计算精度有所提升,则继续执行算法。如果忆阻器阵列的计算精度无法继续提升,则结束算法,输出映射后的权值矩阵。
2 实验结果和分析
2.1 实验设置
为了验证NTWR 算法的有效性,在2 个数据集上进行了实验。 首先,在Pytorch 上构建了一个4 层卷积神经网络,采用MINST 数据集对其进行测试,输入图像的大小为28×28,由3 个卷积层和1 个全连接层组成。 然后,在Pytorch 上构建了LeNet,采用CIFAR-10 数据集进行测试,即由2 个卷积层、3 个全连接层组成。 忆阻器的电阻范围为10 kΩ ~1 MΩ,忆阻器阵列中忆阻单元之间的导线电阻为2.5 Ω,参数配置见表1。
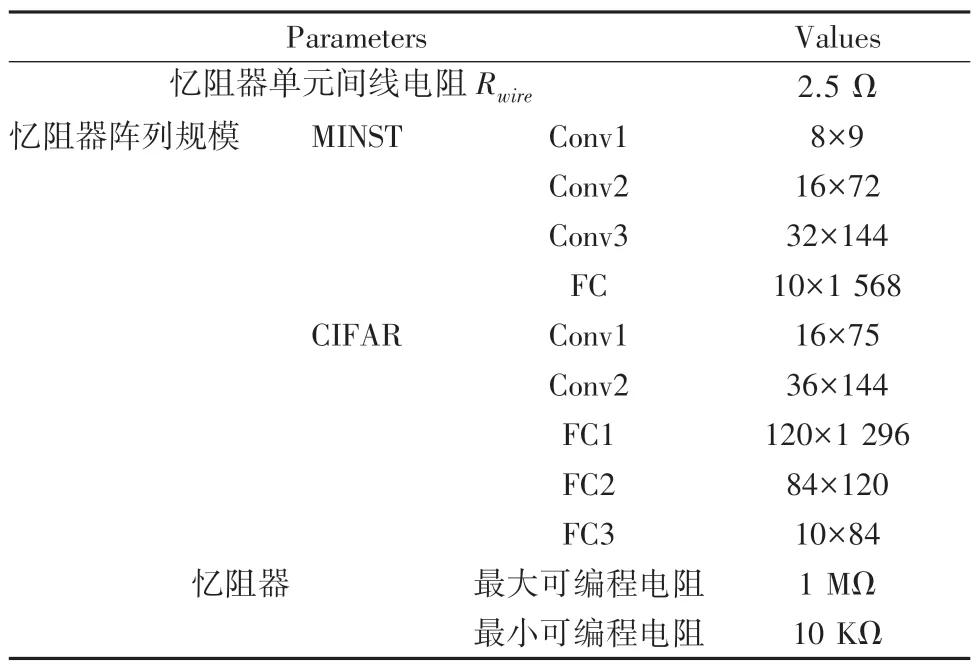
表1 实验参数设置Tab. 1 Experimental parameters setup
2.2 实验结果及分析
图6 为MINST 数据集上的4 层卷积神经网络未添加L2 正则化和添加L2 正则化的权值分布图。从图6 中可以明显看出,与不添加L2 正则化相比,添加L2 正则化可以将权值分布约束在一个较小值的范围内。 图7 为只考虑未添加L2 正则化和添加L2 正则化的忆阻器阵列计算精度对比图。 从图7 中可以看出, 添加L2 正则化后, MINST 数据集和CIFAR-10 下忆阻器阵列的计算精度可以分别提升15.30%和11.40%。可以得出相较于未添加L2 正则化,添加L2 正则化虽然会有部分计算精度损失,但是训练出的权值对IR-Drop 的鲁棒性有显著提高。
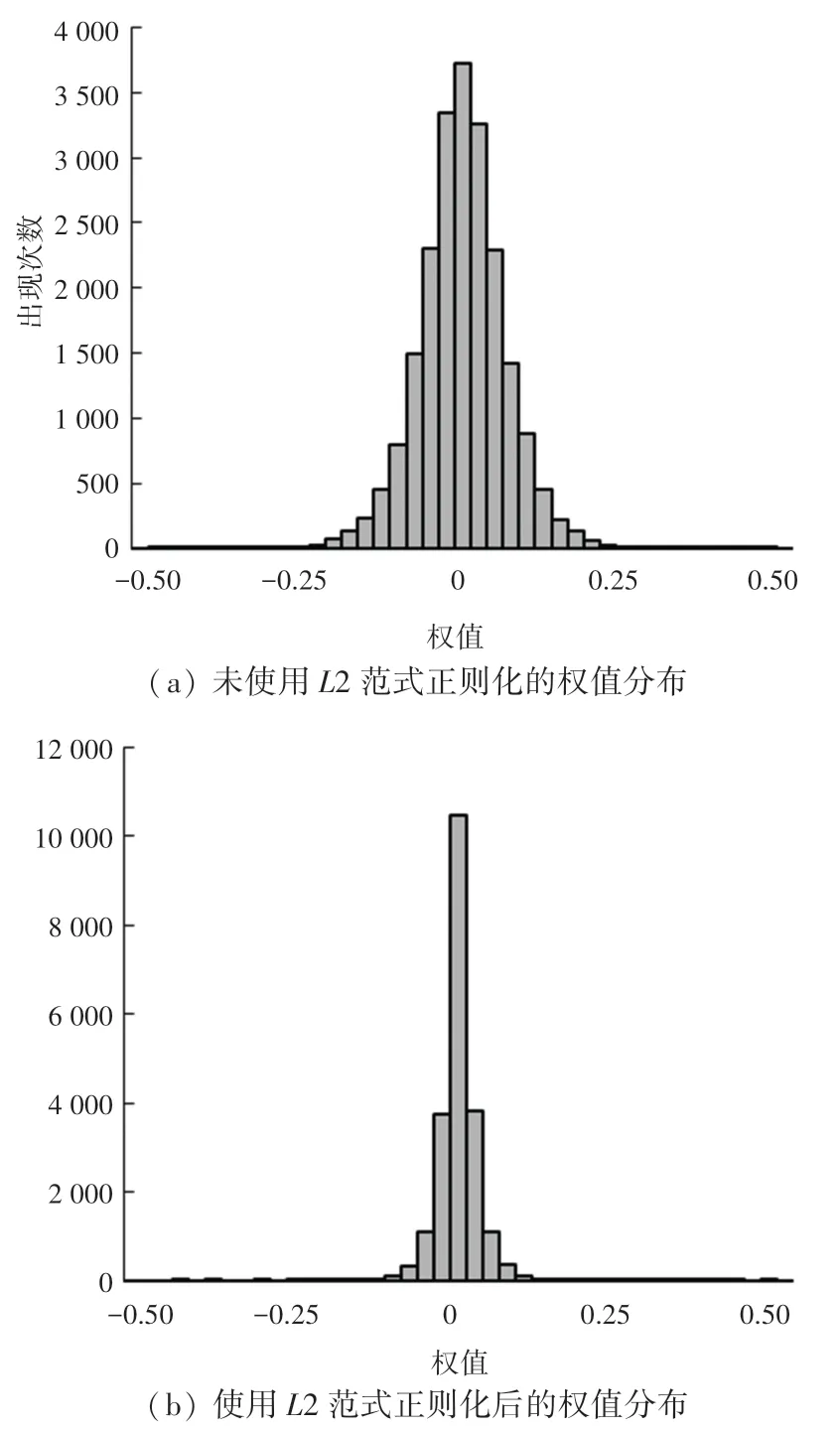
图6 MINST 数据集上未添加L2 正则化和添加L2 正则化的权值分布图Fig. 6 The weight distribution with and without L2 regularization on MINST
图8 为在MINST 和CIFAR 数据集下执行NTWR方法前后的计算精度对比图。 从图8 中可以看出执行MCRC 算法和重训练后,可以明显提高忆阻器阵列的计算精度。 在MINST 和CIFAR 数据集下,执行NTWR 方法可以分别使忆阻器阵列的计算精度接近理想水平,计算精度损失分别小于1%和3%。
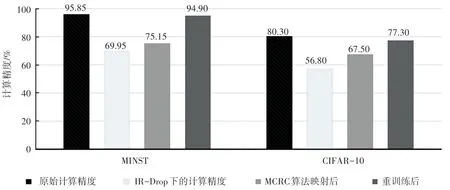
图8 执行NTWR 方法的计算精度对比图Fig. 8 The accuracy comparison of memristor-based crossbar with NTWR
3 结束语
本文提出了一种基于权值缩减的神经网络训练方法,以此减小IR-Drop 造成的计算精度损失。 首先,通过L2 正则化,将权值尽可能训练为较小值,以此减轻IR-Drop 对忆阻器输出结果的影响。 然后,执行基于行列约束的映射算法,将大权值尽可能映射到离输入端和输出端较近的忆阻器上,避免IRDrop 产生较大的输出结果偏差。 最后,减小映射到离输入端和输出端较远处的大权值,再利用重训练恢复权值减小造成的计算精度损失。 实验结果显示,本文所提方法最多可以将忆阻器阵列计算精度恢复到接近理想状态,计算精度损失小于1%。
