基于改进YOLOv3 的电容表面缺陷检测方法
2023-04-19李俊杰唐纲浩
李俊杰, 周 骅, 唐纲浩
(贵州大学 大数据与信息工程学院, 贵阳 550025)
0 引 言
钽电容是一种体积小、电容量大、使用寿命长、耐受性强的优异电容器,在军事通讯、航天、工业控制等领域中都有着不可替代的重要作用[1]。 在钽电容的生产过程中,会出现表面具有污点、划痕、凹痕、擦痕等缺陷的残次品,一般通过人工检测筛选出合格产品。 但人工检测代价较高,且容易发生误检,因此研发一种高效钽电容表面缺陷检测方法是十分必要的。
近年来,深度学习技术已成为研究热点,并在工业自动检测方面取得了可观进展。 在目标检测领域,学者们提出了多种多样深度学习目标检测算法,其效果普遍优于传统的需要对图像特征进行手工提取的目标检测方法[2]。 深度学习目标检测算法按照不同的设计思想主要可分为两大类,即:Twostage 系列算法和One-stage 系列算法。 其中,Twostage 系列算法在生成候选区域后,再将生成的一系列候选区域送入卷积神经网络进行预测与识别,代表 性 的 算 法 有 R - CNN ( Regions with CNN features)[3-5]系列算法等,这一系列算法的准确率和定位精度相对较高,但检测速度较慢,无法实现实时检测。 One-stage 系列算法能够端到端地通过输入图像推理得出图中所包含目标的位置与类别信息,主要有YOLO(you only look once)[6-9]系列算法、SSD(single shot multibox detector)[10]、RetinaNet[11]等。 One-stage 系列算法在性能精度上和Two-stage系列算法相比要略为逊色一些,但检测速度更快,可以满足实时检测的要求。
基于深度学习的表面缺陷检测方法有助于提高工业产品缺陷检测的准确性,现已广泛应用于表面缺陷检测[12]。 戚银城等学者[13]在Faster R-CNN 网络上嵌入双注意力机制,实现航拍输电线路螺栓的缺陷检测。 王宸等学者[14]将YOLOv3 应用于轮毂焊缝缺陷的智能化检测,通过优化激活函数等方法改进网络,检测精度高于传统机器视觉检测方法。 李鑫等学者[15]对YOLOv5 网络中的卷积模块进行优化,提高了钢材表面缺陷检测的检测精度与速度。 刘群坡等学者[16]从多尺度特征融合的角度改良单次多框检测器(SSD)算法,对微精密玻璃封装电连接器的缺陷进行检测。
为了满足实际生产环境中钽电容表面缺陷检测的要求,本文在YOLOv3 算法的基础上,对模型进行改进,增强YOLOv3 的检测能力,从而实现了对钽电容表面缺陷的有效检测。
1 YOLOv3 网络结构及原理
1.1 YOLOv3 网络结构
YOLOv3 主要包含2 部分,分别为:特征提取网络DarkNet-53 与多尺度预测网络(Feature Pyramid Network,FPN)。 研究可知,特征提取网络DarkNet-53 实际为去除最后一层全连接层的其余部分(详见图1(a)),由大量卷积结构与残差块堆叠而成。 卷积结构由普通卷积层、BN(Batch Normalization)层、LeakyReLU 层 级 联 而 成(详 见 图 1 (c) 中 的Convolutional),用来解决网络的梯度爆炸与梯度消失问题,并能够加速网络收敛。 残差块包含1×1 和3×3 的2 个卷积结构,通过先降维再升维的方式轻化模型,残差块的首尾两端通过残差结构的跳跃连接方式进行连接(详见图1(d)中的Residual),改善随着网络层数不断加深带来的梯度弥散问题。 普通卷积层穿插于卷积块之间,实现特征图尺寸的变化,相比于使用池化层,减少了特征信息的丢失。 多尺度预测网络FPN 部分,选取经过8 倍、16 倍下采样后的特征图,分别与对应的由上采样后所得相同大小的特征图进行特征融合,再经过一系列卷积层的计算完成对20×20、40×40、80×80 三个不同尺度的特征层上大、中、小目标的检测。 YOLOv3 网络结构所涉及的部分网络结构参见图1。

图1 YOLOv3 网络的部分结构Fig. 1 Partial structure of YOLOv3 network
1.2 SPP 结构及原理
改 进 YOLOv3 中 的 SPP ( Spatial Pyramid Pooling)模块借鉴于SPPnet[17]中的SPP 结构,有4条分支,见图1(b)。 第一个分支直接由输入接到输出,第2、3、4 个分支分别为池化核为5×5、9×9、13×13 的最大池化结构,步距均为1,意味着池化前进行padding 填充,在池化后得到的特征图尺寸大小和深度不变。 在DarkNet-53 的输出与第一个预测特征层前加入SPP 结构,通过上一级输入与5、9、13 三个最大池化下采样,实现了不同尺度的特征融合,显著增加了感受野,并且几乎不会降低网络运行速度。
2 改进的目标检测算法设计
2.1 引入新的定位损失函数
YOLOv3-SPP 网络中的损失函数L 由置信度损失Lconf、分类损失Lcla、定位损失Lloc三部分构成,损失函数可用如下公式来描述:
其中,λ1、λ2、λ3为平衡系 数。 置信度损 失Lconf、 分类损失lcla均由二值交叉熵损失(Binary Cross Entropy)计算得出,以及Lloc、Confidence、LIoU的系列计算公式具体如下:
其中,oi∈[0,1],为预测框与真实框的IoU值;为预测的置信度;N为正负样本总个数;Npos为正样本个数;Oij∈{0,1},表示第i个预测框中是否存在第j类目标;C^ij为预测目标概率。
交并比(Intersection-over-Union,IoU) 是衡量预测框与真实框重合度的评价指标,其值为目标框与真实框交集与并集的比值,如图2 所示。IoU值可由如下公式来求得:

图2 IoU 计算Fig. 2 IoU calculation
在置信度误差计算中,见前文式(5),IoU的大小直接决定了预测框与真实框的相似度情况,对损失函数的计算有着重要影响。 置信度损失与定位损失的计算均依赖于IoU,但是使用IoU时对于预测框和真实框不相交、2 个边框的真实重叠情况等问题,无法有效做出判断,直接用IoU计算损失有一定问题:
(1)当预测框和真实框交集为空时,IoU值简单地等于0,无法反映出两者的偏差大小。
(2) 对于面积不变的一组真实框与预测框,改变预测框的尺寸与位置,当真实框与预测框的交集大小相同时,其IoU值恒定,即无论预测框与真实框的位置关系如何、尺寸比例如何,损失都不变,无法对预测框与真实框的重合中心点位置、尺寸差异做出有效反馈。 如图3 所示。

图3 IoU 的计算缺陷Fig. 3 Calculation flaws of IoU
为了解决这一问题,随之衍生出多种基于IoU的 损 失 计 算 方 式, 如 文 献[18] 中 的GIoU(Generalized-IoU)、DIoU(Distance-IoU)以及CIoU(Complete-IoU)。 其中,GIoU通过预测框与真实框的最小外接矩形面积来反映预测框与真实框的远近。DIoU采用真实框和预测框的中心点距离与两者最小外接矩形对角线长度作为衡量标准,兼顾了预测框与真实框的远近与重合中心点位置两种因素。 与DIoU相比,CIoU进一步考虑了预测框与真实框的长宽比因素对损失计算的影响,加入了长宽比惩罚因子,CIoU的计算公式如式(3):
其中,b、bgt分别表示预测框、真实框的中心点坐标;ρ2表示两点间的欧氏距离;av表示预测框与真实框的长宽比因子。 相比于GIoU、DIoU,CIoU对于预测框与真实框的差异问题解决得更全面、效果更好,所以本文使用CIoU。
在不同的数据集上,GIoU、DIoU、CIoU的预测结果可能因数据集的不同而有所差异,因此,对GIoU、DIoU,CIoU在本文使用的电容数据集上的运行效果进行验证,验证结果表明使用CIoU在训练的收敛速度及最终结果两方面效果更佳。
2.2 Mosaic 数据增强
Mosaic 数据增强方法是在一个与图片大小相同的矩形中,随机选取一点作为拼接点,形成4 个不同的小区域,4 个区域内分别填充随机4 张图片上对应区域的图像信息,形成一张融合后的图像,接着通过随机缩放、随机裁减等方式进行数据增强。Mosaic 数据增强方法通过4 张图像的部分融合,丰富了小目标和检测物体的背景,增加了数据的多样性,并且在进行计算时,一次会计算4 张图像的数据,相当于变相增加了batch_size。 Mosaic 数据增强实现过程如图4 所示。

图4 Mosaic 数据增强Fig. 4 Mosaic data enhancement
2.3 先验框尺寸优化
YOLOv3 存在预设的3 组先验框,分别决定了在3 个预测特征层上预测框的大小,直接影响着预测结果的好坏。 贴合实际情况的先验框,在训练中能够使模型更快地收敛,定位也更加精确。 研究时,根据ImageNet 数据集设计得到了YOLOv3 中的先验框,但和本文所使用的电容数据集却并不通用。因此,为了得出更加适用的先验框,使用K-means聚类算法重新计算电容数据集的先验框。
K-means 算法通过距离来反映数据间的相似性,两者距离越近则越相似,以此划分出不同的类。先验框与数据集中真实框的相似程度与两者的IoU息息相关,但两者越相似,IoU值越大,为了达到距离越近、数据间的相似度越高的效果,使用1 -IoU作为“距离”,得到的先验框大小见表1。

表1 先验框尺寸Tab. 1 Prior box size
2.4 特征融合层
在特征提取网络中,输入的图像信息经过多层卷积计算,形成了多种不同分辨率的特征图,这也导致了不同深度出现了语义差异。 高层特征图中具有强大的语义信息,可以提高识别能力,但特征图的分辨率降低。
层与层之间信息的传播在深度学习网络中至关重要,语义信息丰富的高层特征图分辨率较低,识别能力必然受限。 YOLOv3 使用特征金字塔网络[19](Feature Pyramid Network, FPN)来融合不同层次的特征信息,将低分辨率、强语义特征与高分辨率、弱语义特征通过从上至下的路径以及横向连接进行融合,使得各个尺度上的语义信息都得到了增强。 如图5 所示。
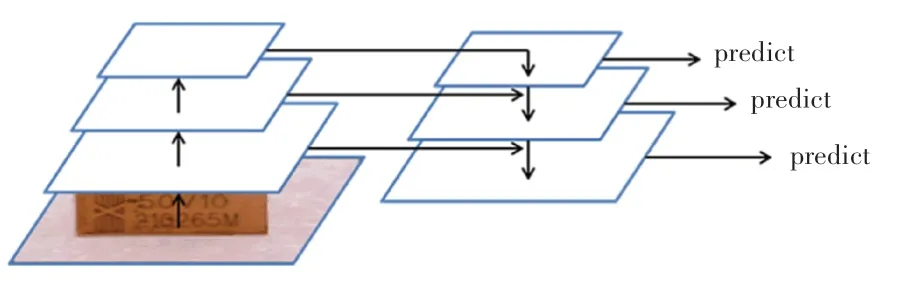
图5 特征金字塔网络Fig. 5 Feature Pyramid Network
特征金字塔网络采用自上而下的路径进行特征融合,实现了对各个层级语义学习的丰富,但是在这一过程中定位信息并未得到增强。 针对这一点,使用PANet(Path Aggregation Network)[20]结构对检测器及不同主干通过自下而上的路径进行特征融合,增强定位信息。 采用自上而下与自下而上的路径增强方式,在FPN 结构后添加PANet 结构,通过融合低层特征中包含的丰富定位信息,实现特征增强。具体来说,通过自下而上的路径以及横向连接,缩短较低层特征和最顶层特征之间的路径,实现定位信息的传递,使整个网络的层次结构更加合理。 通过这2 种连接方式,FPN 层由上至下传达语义特征,PANet 结构由下至上传达定位特征,完成了不同检测层的特征融合,大大增强了模型的目标检测能力。改进的特征融合网络结构如图6 所示。 改进后整体网络结构如图7 所示。
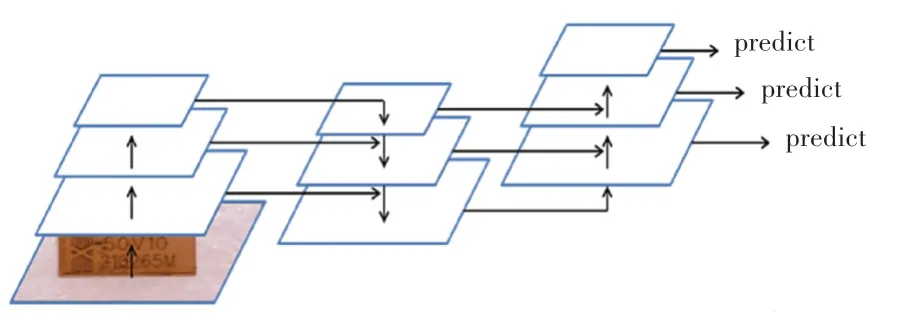
图6 改进的特征融合网络Fig. 6 Improved feature fusion network
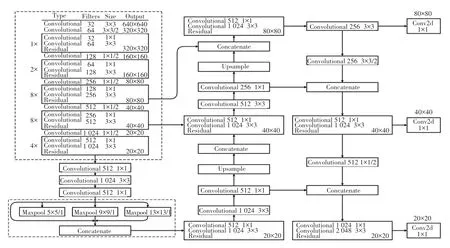
图7 改进算法的网络结构Fig. 7 Improved algorithm network structure
3 实验结果与分析
本文算法在Ubuntu16.04 操作系统上使用pytorch 深度学习框架实现,实验使用的硬件设备为:Intel®Xeon(R) CPU E5-2650v2@ 2.60 GHz 32 G CPU,NVIDIA GeForce GTX TITAN X GPU 12 G显存。 初始学习率为0.01,采用warmup 策略对学习率进行动态调整,batch_size为8, 训练300 个Epoch。
3.1 数据集
在钽电容的生产过程中,会出现表面具有污点、划痕、凹痕、擦痕等缺陷的残次品,这些缺陷出现在钽电容的各个表面,因此,若想完成钽电容的表面缺陷检测,必须了解其6 个表面的状况。 本文实验中使用的钽电容由某钽电容生产商提供,通过电子照相机对钽电容6 个表面进行拍摄,得到1 164 张钽电容照片,并用标记软件LabelImg 对图像中钽电容的污点、划痕、凹痕、表皮脱落四种缺陷进行标记,再按10 ∶1 的比例划分为训练集与测试集,形成本文使用的钽电容数据集。 几种缺陷类型如图8 所示。

图8 数据缺陷类型Fig. 8 Data defects type
3.2 实验结果与分析
本文采用(mean Average Precision,mAP) 平均准确率均值以及(Frames Per Second,FPS) 每秒检测帧数来评估本文算法的性能。 图9 为改进算法与未改进算法训练过程中的Loss值。 由图9 可以看出,改进算法不仅损失值更低,而且收敛速度也相对较快。 为了评估本文改进算法的性能,将目前主流的目标检测网络与本文算法在同一数据集的运行性能进行比较,对比结果见表2。

图9 改进前后loss 曲线Fig. 9 The loss curve before and after the improvement
通过表2 可以看出,本文算法的mAP值达到了89.70%,在各类算法中有着最高的平均准确率均值,相比于改进前的YOLOv3-SPP 算法,mAP值提高了4.79%,并且检测单张图片所消耗的时间也只多出0.008 s。 与Faster_RCNN 算法相比,本文算法的mAP值有3.82 个百分点的提升,单张图片的检测时间快出近2.4 倍。 与RetinaNet 算法相比,mAP值提升了约7%,FPS高出19.55。 在平均准确率均值与检测速度两方面,本文算法均优于上述2 种算法。 SSD 算法检测速度快,单张图片的检测时间仅为本文算法的二分之一,但其mAP值仅为80.67%,为本次实验各类算法中的最低值,低于本文算法9.03%。YOLOv5 算法是目前YOLO 系列算法的代表性成果,而本文算法的mAP值要比其高出3.54 个百分点,单张图片的检测时间则要低9 ms。 综合前文论述可知,相比于其他几类算法,本文算法平均准确率均值最高,检测速度虽然有待改进,但仍可满足实时检测的要求,具有一定的优越性。
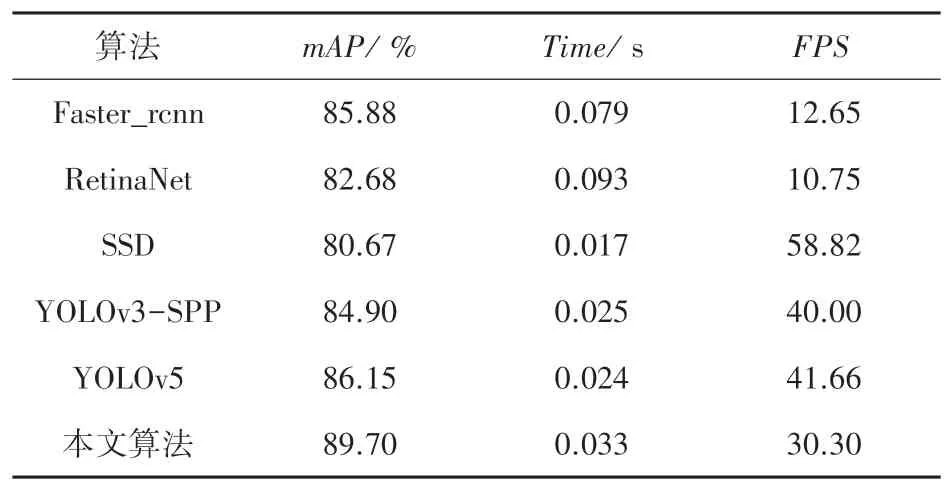
表2 算法性能对比Tab. 2 Performance comparison of algorithms
4 结束语
为了满足实际生产环境中钽电容表面缺陷检测的要求,基于YOLOv3 网络模型做出了一些改进,以提升模型在钽电容表面缺陷检测任务中的检测能力,使用K-means 聚类算法优化先验框。 使用CIoU进行损失函数的计算,加速收敛、提高定位精度;使用Mosaic 数据增强方法强化数据集,提升了模型的检测能力。 采用了FPN+PANet 结构的特征融合层,增强了模型的语义信息与定位信息,加强了模型的检测效果。 实验结果表明,改进的YOLOv3 算法的mAP值达到了89.70%,比原YOLOv3-SPP 算法提升了4.79 个百分点。 相比于其他主流算法,该算法在电容表面缺陷检测中有更高的平均准确率均值,且能满足实时检测的要求。 本文算法也存在一些不足,在网络模型Head 部分增加模块的设计虽然提升了mAP值,但也导致了检测速度的下降,如何能够做到两者兼顾,是后续亟待深入研究的主要课题。
