基于CmabBERT-BILSTM-CRF的针灸古籍分词技术研究
2023-04-13钟昕妤李燕徐丽娜陈月月帅亚琦
钟昕妤 李燕 徐丽娜 陈月月 帅亚琦
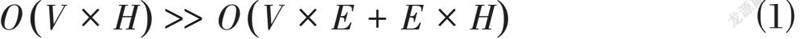
摘 要: 针灸古籍中含有大量通假字、歧义词和专业术语。基于深度学习的分词方法,因静态字向量固有表示和大规模且高质量语料缺乏等问题,限制了分词性能。为缓解上述问题,提出引入预训练策略,在ALBERT模型基础上,利用大量中医古籍再训练得到CmabBERT模型,并构建CmabBERT-BILSTM-CRF融合模型运用于针灸古籍分词任务。实验结果表明,在小样本语料基础下,对比Jieba分词器、BILSTM-CRF和ALBERT-BILSTM-CRF模型,该融合模型展现了更优越的分词性能。
关键词: 针灸古籍; 分词; 序列标注; 预训练
中图分类号:TP391.1 文献标识码:A 文章编号:1006-8228(2023)04-11-05
Abstract: Acupuncture ancient books contain a large number of false words, ambiguous words and professional terms. The word segmentation method based on deep learning is limited by the inherent representation of static word vectors and the lack of large-scale and high-quality corpus. In order to alleviate the above problems, a pre-training strategy is proposed. Based on the ALBERT model, a large number of ancient Chinese medicine books are retrained to obtain the CmabBERT model, and the CmabBERT-BILSTM-CRF fusion model is constructed and applied to the word segmentation task of acupuncture ancient books. The experimental results show that compared with the Jieba word segmentation, BILSTM-CRF and ALBERT-BILSTM-CRF models, this fusion model exhibits superior word separation performance on the basis of small sample corpus.
Key words: acupuncture ancient books; word segmentation; sequence tagging; pre-training
0 引言
計算机技术应用于中医领域,可利用知识发现方法总结已有知识体系,挖掘新的知识规律。针灸作为我国中医学的重要组成部分,因其特殊的治疗效用而被广泛使用,现已成为世界上应用最广泛的传统与替代医学[1]。古籍作为针灸传承发展的重要载体,蕴藏着丰富的针灸理论知识和实践经验,是中医学爱好者的一大宝库。随着古籍数字化工作的推进,越来越多针灸古籍被转化为非格式化文本数据,亟待学者们对其进行处理,挖掘其中的宝贵知识。
分词通过界定字间界限,划分出具有意义的词汇,这是实现计算机处理针灸古籍的基础任务,亦是实体识别、关系抽取等自然语言处理(Natural Language Processing,NLP)任务的基础。而当前针灸古籍分词存在以下三个问题。
⑴ 存有较多通假字、歧义字。最新方法[2]的字向量表示为静态,无法很好地区分多义字,限制了分词性能。
⑵ 知识面涉及较广。除针灸和中医知识外,还囊括古汉语、古哲学等内容,存在未登录词识别难题。
⑶ 大规模且高质量的标注语料尚为缺乏[3,4],其对标注人员要求较高,耗时较长。此外,由于还没有统一标注规范,现有语料还存在质量不齐问题。
为了缓解上述问题,本文将预训练策略引入到针灸古籍分词任务中,利用大量中医古籍,对ALBERT模型再训练以学习上下文特征,最终得到CmabBERT模型,该模型更为符合针灸古籍语境的动态字向量表示输出,联合该模型进一步构建CmabBERT-BILSTM-CRF融合模型应用于针灸古籍分词任务,实现性能提升。
1 相关研究
近年中医古籍分词研究已取得一定成果,其主要基于词典规则、概率统计和深度学习三大类方法。
在研究初期,主要是采用词典和概率的方法。2015年,张帆等[5]结合中医领域词典与CHMM实现中医医案文献分词,缓解未登录词和歧义问题。2019年,Xianjun Fu等[6]基于HMM模型开发了中医药古籍分词系统并构建了中医药术语词库。同期,Qi Jia等[4]提出一种基于分支熵法的无监督方法,利用中医领域词典计算优度阈值,构建分词器并在中医药文本上验证了有效性。后来学者们尝试将深度学习方法引入研究中。语料作为深度学习方法的基础需要预先构建。2018年,付璐等[3]通过人工标注构建了一个小型的清代医籍分词语料库,并据此探讨了中医古籍的分词规范。在此基础上,Si Li等[7]针对CNN的缺陷,将胶囊结构引入分词的序列标注任务,由此构建中医古籍分词器并达到了可接受的性能。2020年,王莉军等学者[2]通过构建BILSTM和BILSTM-CRF模型对中医古籍进行分词,并在各类别上验证了模型的分词性能和鲁棒性。深度学习方法在中医古籍分词中展现了优越性能,然而由于静态字向量固有表示和语料缺乏且质量不齐的问题,限制了其性能的进一步提升。此外,当前研究主要集中于中医医案与中医药古籍,对针灸古籍的分词研究较为缺乏。
据此,本文提出将预训练策略引入针灸古籍分词任务,通过利用大量中医古籍再训练模型,以自主学习中医古籍的上下文特征,从而输出更符合针灸古籍语境的动态字向量表示,以期在小样本语料训练下实现更优分词。经实验证明,对比其他已有方法,本文构建的CmabBERT-BILSTM-CRF融合模型,在各项分词指标上都获得了一定提升。
2 基本原理
目前中医领域中未有公开的预训练模型(Pre-Trained Model,PTM),且在中医古籍处理中亦未引入PTM进行分词实验。本文联合PTM再训练后更符合针灸古籍语境的动态字向量表示输出,构建CmabBERT-BILSTM-CRF融合模型,应用于针灸古籍分词任务,进一步克服针灸古籍分词难题。
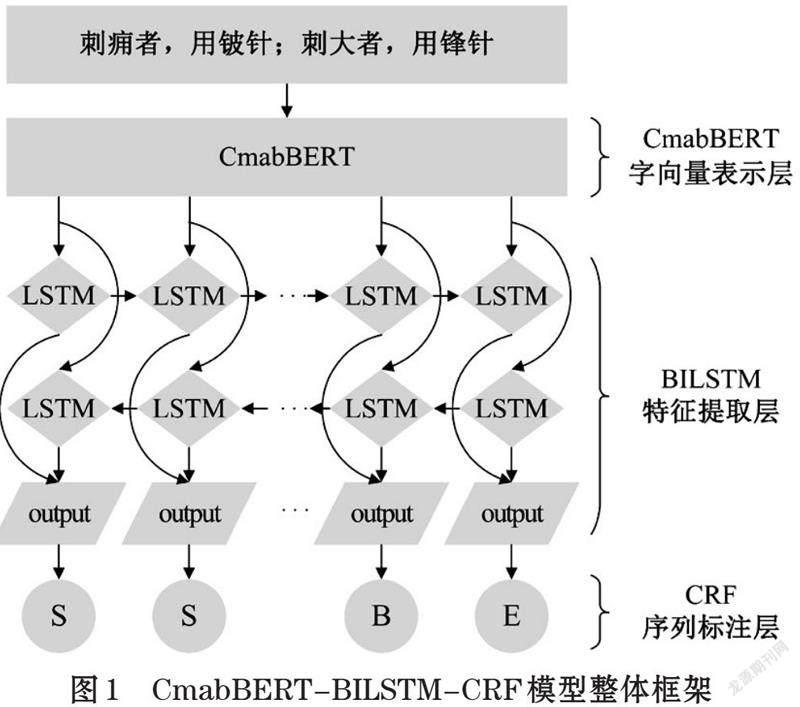
如图1所示,本文提出的模型框架整体分为三大模块:CmabBERT字向量表示层、BILSTM特征提取层和CRF序列标注层。其中,CmabBERT模型是由ALBERT模型经过中医古籍语料再训练得到。
2.1 ALBERT
2019年,Zhenzhong Lan等[8]提出更为轻量级的ALBERT模型,通过参数减少方法降低内存消耗并提高训练速度,缓解BERT、ROBERTA模型在扩大规模以提升性能的时候遇到的内存耗尽问题,并以更少量参数更优越性能拿下13项NLP任务。
在字向量表示中,ALBERT模型能动态地将文本中字符经双向Transformer层转换为对应的向量表示。同BERT、ROBERTA等模型一样,ALBERT模型基于Transformer[9]的Encoder层,通过大量运用多头注意力机制,获取范围内的长、短距离依赖关系,防止模型在编码当前位置时过度关注于自身,从而更好地获取文本的上下文特征。
在ALBERT模型的预训练任务中,主要通过掩碼语言模型(Masked Language Model,MLM)和句子连续预测(Next Sentence Predict,SOP)实现文本上下文特征的自监督学习。
⑴ MLM,为更好地训练模型获取字符双向深度表示的能力,Jacob Devlin等学者[10]在BERT模型预训练中采用MLM,通过预测输入字符串中一定比例的随机掩盖字符训练模型,并为减轻微调阶段没有掩码而与预训练不匹配的问题,将掩码时间划分为80%时间的正常掩盖,10%时间的随机字符替换和10%时间的不变字符。
⑵ SOP,在BERT模型预训练中,由于下一句预测使用的负样本选自不同文本,混肴了主题预测与连贯性预测,造成推理不可靠问题。为消除这一问题,Zhenzhong Lan等学者[8]提出将连续句子以顺序交换的方式作为负样本进行模型训练。
除SOP外,ALBERT通过嵌入参数分解的方式大幅减少模型参数,从而能进一步扩大模型深度和广度,提升模型性能。如式⑴所示,自然语言处理通常需要尺寸为V的词汇量。不同于其他预训练模型直接将热向量投射到隐藏层,使得嵌入层随隐藏层参数H扩增时存有大量闲置参数。ALBERT模型先将词嵌入映射到尺寸E的低维空间上,再由低维空间投射至隐藏层。由此,当H>>E时,参数降低效果极为显著。
2.2 BILSTM
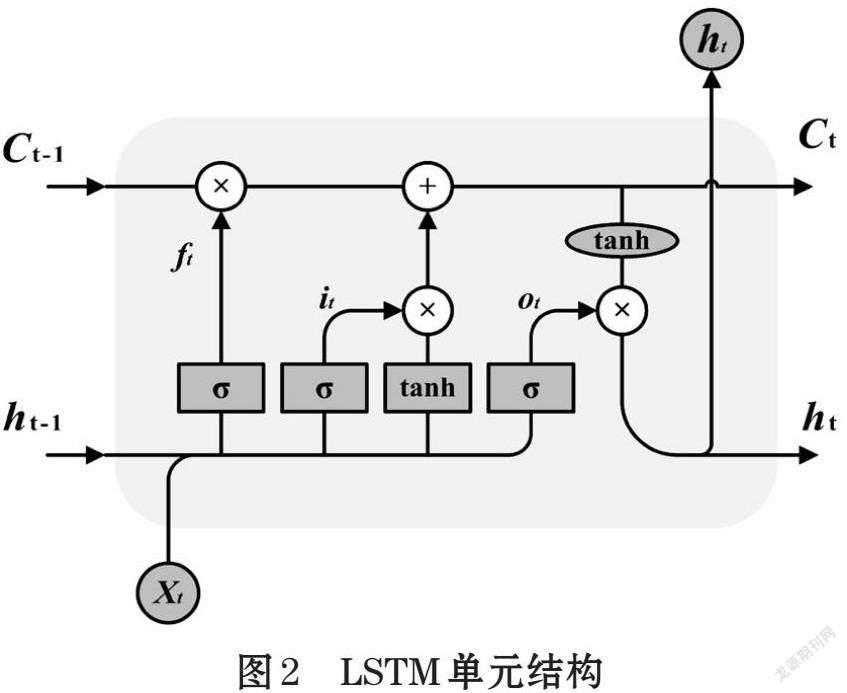
BILSTM由前向和后向LSTM组成。LSTM在RNN的基础上引入门机制,通过记忆门、遗忘门、输出门控制特征信息的传递,能有效防止信息特征在长距离计算中被覆盖,从而能更好地在数据中查找和利用远距离依赖[11]。
LSTM由一系列单元组成,以单元状态Ci的链式传递为核心。如图2所示,t时刻的单元状态[Ct]由两部分组成:①前一时刻向后传播的单元状态[Ct-1]联合遗忘门输出[ft];②t时刻的单元更新值[Ct]联合输入门输出[it]。其整体结构可由式⑵~式⑺表示:
其中,[σ]表示sigmoid激活函数,[tanh]表示tanh激活函数,[ot]表示记忆单元,而三门机制的输出皆经由前一时刻隐藏层[ht-1]和输入数据[xt]计算得出。
单个LSTM层只能传播单向信息,对文本而言,其理解需要结合上下文语境,单向语境会限制文本特征信息获取的准确性。BILSTM则通过前后双向的信息传递实现更优文本特征选择,一度成为NLP领域模型研究中应用最为广泛的基础结构。
2.3 CRF
CRF是一种基于马尔科夫性的概率无向图,在seq2seq类任务中具有良好表现,常被应用于NLP中,判断序列标注的最优结果。线性链CRF对于给定的线性随机观测序列[W={W1,W2,…,Wn}],任意[Wi]的对应状态[Li]满足[PLi|W,L1,L2,…,Ln=P(Li|W,Li-1,Li+1)],即状态[Li]不仅与前一时刻状态[Li-1]有关,还与整个观测序列[W]和后一时刻状态[Li+1]有关。CRF将整个[W]作为全局条件,对[P(L|W)]进行建模。
本文在分词任务中,采用BMES标注方法,词汇的开头、中间、结尾分别由“B”、“M”、“E”符号标记,单字和符号则由“S”标记。如图3所示,CRF最终输出的状态序列[L]取决于整个观测序列[W]的联合概率分布,是全局最优解。
3 实验与分析
3.1 实验设置
本文实验环境配置如下:操作系统Ubuntu 18.04,CUDA 10.0,cuDNN 7.6,tensorflow-gpu 1.13.1,Keras 2.2,使用NVIDIA GeForce RTX 2080 Ti。为保障PTM在各类针灸古籍语境中的鲁棒性,选用了《黄帝内经》《针灸甲乙经》《本草纲目》《伤寒杂病论》等810本中医古籍,共208MB作为原始语料,经掩码标注处理获得自监督训练语料约2.29GB。而由于服务器显存限制等问题,本文仅选用小规模的ALBERT模型作为再训练的基础模型。
此外,因目前未有统一的中医古籍分词规范,本文参考付璐等学者[3]对清代医籍的分词标准研究成果,选用《灵枢》针灸古籍,经Jieba分词器联合人工标注的方式获得较高质量的小样本精加工语料,作为各类模型的训练、评估和测试数据。
3.2 实验流程
本文构建CmabBERT-BILSTM-CRF模型应用于小样本语料的针灸古籍分词任务。关键流程如下:数据准备→PTM再训练→融合模型训练→获得分词结果→方法对比分析。
在数据准备阶段,除小样本语料标注外,本文以不同古籍的不同段为划分,区分不同内容,再以句号为划分,分割同内容的上下句,最后通过15%概率的随机MASK方式构建再训练语料。
在PTM再训练阶段,本文将训练批量设置为256,训练步数设置为125000,学习率设置为0.00176,并采用LAMB优化器进行优化迭代。训练时,模型将自主整合语料中的各项信息,实现掩码位置对应字符预测及上下句判断,并不断调整自身参数实现更优,从而学习到语料中丰富的上下文特征。
在融合模型训练阶段,本文将基于再训练得到的CmabBERT模型的动态字向量表示输出,联合BILSTM+CRF模型构建融合模型,其中BILSTM层包含前后向各256个神经元,批量大小为128,学习率为0.001,优化器为ADAM,并设置了0.5的丢弃概率指数,以防止模型过拟合。
在方法对比分析阶段,除本文研究的CmabBERT-BILSTM-CRF模型外,还选用了Jieba分词器、BILSTM-CRF模型、ALBERT-BILSTM-CRF模型作为对比。其中,BILSTM-CRF模型以Word2Vec静态词向量作为输入。
3.3 实验结果
3.3.1 模型预训练评估结果
模型预訓练评价将训练前后的ALBERT和CmabBERT模型分别在MLM任务和SOP任务上的准确率进行对比。其中,MLM准确率为模型正确预测掩码位置原字符数量与所有预测掩码数量的比值,SOP准确率为模型正确判断上下句数量与所有预测句子数量的比值。表1展示了预训练模型在经大量中医古籍的自监督训练前后,在预测掩码和判断上下句上的性能表现。从表1可以看出,经再训练后,CmabBERT在MLM任务和SOP任务准确率皆有较多提升,表明CmabBERT模型在再训练中较好地学习到了中医古籍的上下文特征,从而能更好地运用于针灸古籍中,输出更符合语境的动态字向量表示。
3.3.2 分词方法结果评价
基于评价指标——准确率P、召回率R和F1值,将模型分词序列标注结果与经人工标注校正的分词结果进行对比。其中,P值是模型标注正确量与模型总标注量的比值;R值是模型标注正确量和人工总标注量的比值;F1值为综合性评价指标,是两倍的P、R积和P、R合的比值,由P和R共同决定。
表2展示了各类分词方法在小样本数据集上的分词性能表现。分析表2可以得出以下结论:在无额外辅助信息下,①基于深度学习的三种分词方法明显优于通用领域的Jieba分词器;②基于动态字向量表示的两种分词方法在各项评估指标上皆高于基于静态字向量表示的分词方法;③经再训练的CmabBERT预训练模型输出的动态字向量表示比基础ALBERT模型更适合于针灸古籍分词任务。
如表3所示,为进一步对比各类方法的分词表现,本文选取部分分词结果进行对比分析,并为展示方便,将序列标注结果进行转化。其中,在“腹中常鸣”症状术语分词中,BILSTM-CRF和CmabBERT-BILSTM-CRF实现了准确标注;在“气上冲胸”分词中,ALBERT-BILSTM-CRF和CmabBERT-BILSTM-CRF实现了准确标注;在“巨虚上廉”穴位术语分词中,仅有CmabBERT-BILSTM-CRF实现了准确标注;而在“刺肓之原”分词中,几种分词方法皆未能成功标注“盲之原”穴位术语。上述结果表明,经再训练学习到中医古籍上下文特征的CmabBERT模型能更好地动态表示针灸古籍语境下的字向量,而在此基础上进一步构建的CmabBERT-BILSTM-CRF模型则能更好地适用于小样本语料的针灸古籍分词任务中,获得更为准确的分词结果,从一定程度上缓解静态字向量固有表示和语料缺乏造成的分词性能限制问题。
4 结束语
本文为缓解静态字向量固有表示和中医领域大规模且高质量语料缺乏的问题,引入预训练策略,基于大量中医古籍对ALBERT模型再训练,以学习古籍的上下文特征,最终得到CmabBERT模型,从而获得更符合针灸古籍语境的动态字向量表示输出。在此基础上,本文构建了CmabBERT-BILSTM-CRF模型,最终通过实验验证了该模型在小样本语料下的针灸古籍分词性能提升。在无其他辅助信息增强下,本文模型各项评估值均优于当前主流模型。分词性能的提升,能为后续针灸实体关系抽取、知识图谱构建等工作提供质量保障。
本研究仅在小规模ALBERT模型基础上再训练得到CmabBERT模型。而越大规模的PTM对于下游NLP任务的提升效果越为显著。在未来的工作中,将进一步通过剪枝等方法训练更少参数更大规模的中医领域预训练模型,以更好地服务于中医领域各项NLP任务,助力于中医智慧服务的发展。
参考文献(References):
[1] 张梦雪.中国针灸学会发布推进针灸高质量发展“十四五”规划纲要[J].中医药管理杂志,2022,30(4):89
[2] 王莉军,周越,桂婕,等.基于BiLSTM-CRF的中医文言文文献分词模型研究[J].计算机应用研究,2020,37(11):3359-3362,3367
[3] 付璐,李思,李明正,等.以清代医籍为例探讨中医古籍分词规范标准[J].中华中医药杂志,2018,33(10):4700-4705
[4] Jia Q, Xie Y, Xu C, et al. Unsupervised traditional Chinese medicine text segmentation combined with domain dictionary[A].International Conference on Artificial Intelligence and Security[C]. New York: Springer,Cham,2019:304-314
[5] 张帆,刘晓峰,孙燕.中医医案文献自动分词研究[J].中国中医药信息杂志,2015,22(2):38-41
[6] Fu X, Yuan T, Li X, et al. Research on the method and system of word segmentation and POS tagging for ancient Chinese medicine literature[A].2019 IEEE International Conference on Bioinformatics and Biomedicine (BIBM)[C]. San Diego:IEEE,2019:2493-2498
[7] Li S, Li M, Xu Y, et al. Capsules based Chinese word segmentation for ancient Chinese medical books[J].IEEE Access,2018,6:70874-70883
[8] Lan Z, Chen M, Goodman S, et al. Albert: A lite bert for self-supervised learning of language representations[J].arXiv preprint arXiv,1909.11942,2019
[9] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[A].Proceedings of the 31st International Conference on Neural Information Processing Systems[C].California:ACM,2017:6000-6010
[10] DEVLIN J, CHANG M W, Lee K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[A]. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies[C]. Minneapolis: ACL,2019: 4171-4186
[11] HUANG Z, XU W, YU K. Bidirectional LSTM-CRF models for sequence tagging[J].arXiv preprint arXiv: 1508.01991,2015
*基金项目:基于AI深度学习的中医知识图谱构建(2021LDA09002); 甘肃中医药大学研究生创新基金项目(2022CX137)
作者简介:钟昕妤(1996-),女,浙江人,硕士研究生,主要研究方向:古籍知识图谱、数据挖掘。
通訊作者:李燕(1976-),女,甘肃人,硕士,教授,硕士生导师,主要研究方向:中医药数据挖掘、医学信息学及信息技术在医学中的应用。
