融合单语翻译记忆的神经机器翻译方法
2023-04-12王兵叶娜蔡东风







摘要: 与以往使用双语语料库作为翻译记忆(Translation Memory,TM)并采用源端相似度搜索进行记忆检索,进而将检索到的相似句对与神经机器翻译(Neural Machine Translation,NMT)模型融合的这种分阶段进行的方法不同,提出一种新的融合框架,即基于跨语言注意力记忆网络的神经机器翻译模型,该模型使用单语翻译记忆即目标语言句子作为TM,并以跨语言的方式执行可学习的检索。该框架具有一定的优势:第一,跨语言注意力记忆网络允许单语句子作为TM,适合于双语语料缺乏的低资源场景;第二,跨语言注意力记忆网络和NMT模型可以为最终的翻译目标进行联合优化,实现一体化训练。实验表明,所提出的方法在4个翻译任务上取得了较好的效果,在双语资源稀缺的专业领域中也表现出其在低资源场景下的有效性。
关键词: 神经机器翻译;单语翻译记忆;跨语言注意力记忆网络;低资源领域;Transformer模型
中图分类号: TP391" " " " 文献标志码: A
doi:10.3969/j.issn.2095-1248.2023.02.009
Neural machine translation method integrating monolingual translation memory
WANG Bing, YE Na, CAI Dong-feng
(Human-Computer Intelligence Research Center, Shenyang Aerospace University, Shenyang 110136, China)
Abstract: Different from previous researches that used bilingual corpus as TM and source-end similarity search for memory retrieval, a new NMT framework was proposed, which used monolingual translation memory and performed learnable retrieval in a cross-language way. Monolingual translation memory was the use of target language sentences as TM. This framework had certain advantages: firstly, the cross-language memory network allowed monolingual data to be used as TM; secondly, the cross-language memory network and NMT model was jointly optimized for the ultimate translation goal, thus realizing integrated training. Experiments show that the proposed method achieved good results in four translation tasks, and the model also shows its effectiveness in low-resource scenarios.
Key words: neural machine translation;monolingual translation memory;cross-language attention memory network;low-resource scenarios;transformer" model
机器翻译是指利用计算机将一种自然语言(源语言)转换为另一种自然语言(目标语言)的过程[1]。近年来,端到端的神经机器翻译(Neural Machine Translation, NMT)取得了巨大进步[2-4]。特别是自Transformer模型[4]提出以来,机器翻译的翻译质量得到了显著的提升。Transformer逐渐成为机器翻译领域中的主流模型。翻译记忆是一种辅助翻译人员完成翻译任务的工具,其中存储着之前已经翻译好的句对、段落或文本句段[5-7]。译员遇到待翻译的源语句时,先从翻译记忆库中检索与当前句子最相似的翻译记忆句对,检索完毕后,译员可以重用匹配的部分来避免冗余翻译,以保证翻译的质量。
翻译记忆能够为机器翻译提供有效的外部知识,从而提高翻译的质量。随着神经机器翻译的不断发展,神经机器翻译和翻译记忆相结合的研究也在不断推进。二者的结合通常被分为两个阶段:首先是检索阶段,在检索过程中大都采用基于相似度的搜索方式,例如Gu等[8]以词为单位进行检索,Zhang等[9]和Bapha等[10]则以短语等相似片段为单位进行检索,检索得到结果后直接利用其中匹配部分的翻译与神经机器翻译结合;Cao等[11]、Bulte等[12]、Xu等[13]的研究则是以句子为检索单位,通过检索到相似语句来加强神经机器翻译。最后是生成阶段,生成是指如何利用翻译记忆来指导神经机器翻译模型输出结果的过程。曹骞等[14]提出基于数据扩充的方式将目标端翻译记忆直接拼接在源语句后面作为训练语料,并为翻译记忆与源语句分别加上标签以作区分;提出采用成对编码器分别对翻译记忆和源语句进行编码,并在解码过程中通过门控机制融合两者信息,让目标端翻译记忆指导模型的翻译。
通过对现有方法的研究和对比发现,将神经机器翻译与翻译记忆相结合的方法存在两个问题:(1)所使用的翻译记忆均来自对齐的源-目标句对组成的双语语料库。而对于某些小语种翻译,大多存在双语语料库不够丰富的问题,继而通过检索匹配得到的翻译记忆质量低,最终影响神经机器翻译的质量;(2)在训练过程中,翻译记忆的获取均采用离线检索的方式,翻译记忆检索匹配与神经机器翻译的训练过程无法一体化。
针对以上不足,本文提出了一种基于跨语言翻译记忆的跨语言注意力(Cross-Language Attention)记忆网络模型。以单语句子集合作为翻译记忆库,利用记忆网络进行跨语言翻译记忆知识的提取。通过记忆网络和Transformer的编码器在潜在向量空间中对源句子和单语翻译记忆进行对齐,对齐过程的参数与模型训练时的参数通过可学习的方式进行端到端优化,从而指导解码器生成更好的翻译。
1 跨语言注意力记忆网络翻译模型
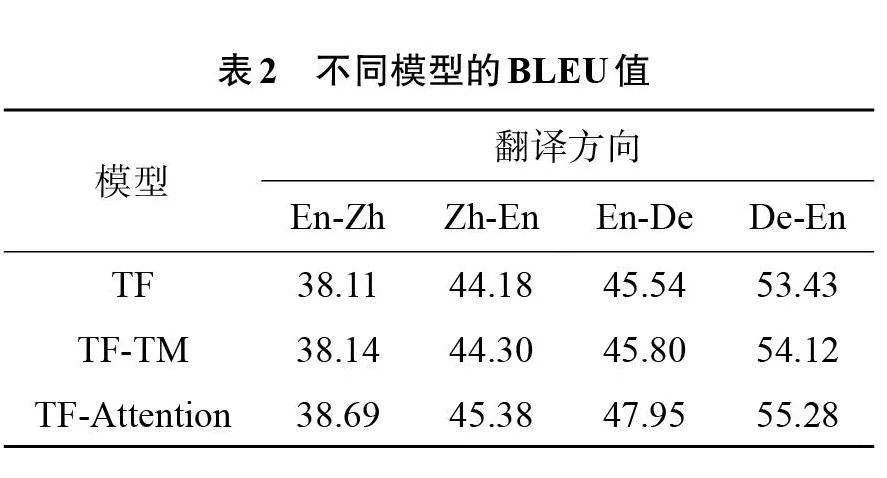
本文提出的基于跨语言注意力记忆网络的神经机器翻译模型的优点在于:(1)可以直接使用单语的句子集合作为翻译记忆,实现源语言端句子与目标端句子的跨语言检索;(2)加入了一个注意力记忆网络来获取翻译记忆的加权向量表征,并加入神经机器翻译模型训练指导模型输出。提出的模型结构整体分为两部分,如图1所示。图1左边是跨语言注意力记忆网络,D指的是翻译记忆库,在这里存放的句子均为目标端的单语句子。右边用一个Transformer作为编码和解码的主干模型。在本文的工作中,采用跨语言记忆网络的方法来提取翻译记忆中的潜在信息,并与Transformer进行交互。
给定输入的源语言中句子X=x1x2…xi…xn,通过Transformer的Embedding层得到词向量,将词向量进行算术平均求和得到各自的句向量e后,注意力记忆网络首先根据相关函数M(e,D)从单语翻译记忆中获取有帮助的信息,然后将其融入到Transformer的解码中,从而指导解码的生成。句向量e的生成过程在下节中详细介绍。形式上,整个翻译记忆指导机器翻译的过程如式(1)所示
Y=G(x,M(e,D)) (1)
式中:Y为目标语言;G为整个的翻译过程;D为单语翻译记忆库;X=x1x2…xi…xn为输入的单条源语言句子;M为跨语言的注意力记忆网络,其细节及如何与Transformer整合将在后面小节中描述。
1.1 跨语言注意力记忆网络
给定的单语翻译记忆库D中存放的句子为翻译记忆目标端句子,在此基础上模型实现了跨语言的翻译记忆匹配。但给定的翻译记忆库通常与训练语料类似,这样翻译记忆为模型训练提供了很好的参考,而且为每条输入的源句子确定什么是描述它的最佳翻译记忆。例如,给定一条源语言句子“the German defendant bought frozen pork from a Belgian company”可能在翻译记忆库中无法找到完全一致的翻译,但只要在翻译记忆中出现,就可以为解码的生成提供明确的信息。
将单语的翻译记忆定义为集合D={d1,d2,…,dk,…,dl}。首先训练一个Sentence-BERT模型,利用神经网络对翻译记忆中的每一条句子进行编码,得到固定长度的句向量,即键向量u={u1,u2,…,uk,…,ul}和值向量v={v1,v2,…,vk,…,vl}这两个向量集表示它们。在这里uk和vk是一致的,都为768维的句子向量。其中句向量的训练生成过程如下,以一条句子d为例:
(1)CLS:训练中使用[CLS]字符最后一层的输出向量,此时为生成的字向量d=w_1 w_2…w_n;
(2)采用最大值池化策略,将得到的所有的字向量求最大值操作得到整条句子的句向量w=max (w_1^1 u_1^2,…,w_1^n,w_2^1 w_2^2,…,w_2^n,w_3^1 w_3^2,…,w_3^n),将这个最大值向量作为一个句子的句向量。
然后,对于输入的每一个源句子X,首先通过Transformer的Embedding层得到它的词嵌入表示。Embedding的过程需要把两个方面的信息结合在一起,即每个时刻的字向量e_i^word=(e_1" ,e_2" ,…,e_n)和每个时刻所选取的字的位置信息e_i^pos=(e_1,e_2,…,e_n),最终的Embedding结果是上述两方面之和,即e_i=e_i^word+e_i^pos。
为了与得到的翻译记忆的句向量uk和vk维度保持一致,将编码器与解码器的嵌入维数设置为768,即n为768,然后对每一个源句子X的词向量进行求和再平均,最终得到一个1×768的句向量,记作e,如式(2)所示
e=1/n ∑_(i=1)^n▒e_i (2)
在进行翻译记忆检索时,将e作为“query”向量。在向量空间内,记忆网络通过取内积和Softmax来计算uk与输入的每一条源语言句子e的相似度,而vk作为潜在的句子向量生成最终的输出o。具体而言,注意力记忆网络首先将编码器端的句子向量e和单语翻译记忆库中每一条句子向量uk取内积,在这里使用一个Softmax函数,将uk与句向量e二者的内积得分标准化成一个隐含状态序列上的概率pk。计算过程如式(3)所示
p_k=(exp (e^T⋅u_k))/(∑_(k=1)^l▒〖exp (e^T⋅u_k)〗) (3)
概率pk作为权重被用来对翻译记忆库中的所有的句向量进行加权,相似度比较高的句子的权重值相对较高,而相似度值较低的直接赋值0,这样更容易突出相似度较高的句子,得到整个翻译记忆的特征表示。对于整个单语翻译记忆库D={d1,d2,…,dk,…,dl},每次通过加权编码获取来自相关单语翻译记忆的向量表示,最终得到跨语言注意力记忆网络的输出向量O,如式(4)所示
O=∑_(k=1)^l▒〖 p_k v_k 〗 (4)
1.2" 将注意力记忆网络与Transformer结合
本文将Transformer作为主编码器-解码器框架。在许多翻译与生成任务中已经表明,Transformer模型具有更有效的性能。在Vaswani等[4]的描述中,编码器由6个完全相同的层堆叠而成。每一层都有两个子层,第一个子层是一个多头注意力机制,第二个子层是一个简单的、位置完全连接的前馈网络。对每个子层再采用一个残差连接,接着进行层标准化。也就是说,每个子层的输出是LayerNorm(x+Sublayer(x)),其中Sublayer(x)是由子层本身实现的函数。为了方便这些残差连接,模型中的所有子层以及嵌入层产生的输出维度都为dmodel=512。解码器同样由6个完全相同的层堆叠而成。除了每个编码器层中的两个子层之外,解码器还插入第3个子层,该层对编码器堆叠的输出执行多头注意力机制。与编码器类似,在每个子层采用残差连接进行层标准化。
为了与记忆网络的输出向量O的维度保持一致,将模型中的所有子层以及嵌入层产生的输出维度均设置为768。当跨语言注意力记忆网络获得潜在句子嵌入O时,将通过以下的步骤将其与Transformer的编码器-解码器结合起来。
首先,输入的源句子通过Transformer的编码器,它为每个输入句子的词向量ei产生一个隐藏状态hi。然后通过逐元素加法h ̃=h_i+O将hi和O结合,并将其通过每个多头注意层发送到解码过程,在每个解码步骤t计算注意力向量a^t=α_1^t α_2^t…α_i^t…α_n^t。计算过程如式(5)、式(6)所示
α_i^t=(exp (e_it))/(∑_(j=1)^(|i|)▒〖exp (e_jt)〗) (5)
e_it=match(h_i⋅s_(t-1)) (6)
式中:s_(t-1)是解码器的隐层状态;match(hi,s_(t-1))是比较编码器状态hi和解码器状态s_(t-1)的一个匹配函数。a^t用于产生句子的上下文向量c^t,于是编码器端隐藏状态通过加权求和得到,如公式(7)所示
c^t=∑_(i=1)^n▒〖α_i^t (h_i ) ̃ 〗 (7)
解码器最后根据编码器端的上下文表示映射为自然语言序列。在t时刻,首先将t-1时刻输出的翻译通过嵌入层得到y_(t-1),以t时刻的嵌入向量y_(t-1)与t-1时刻的输出向量s_(t-1)为输入,通过全连接层得到输出向量s_t,再经过Softmax函数预测输出,得到每个时刻的概率分布,输出概率最大的翻译y_t。解码器端的解码过程如式(8)所示
y_t=G(s_(t-1 ),y_(t-1)" ,c^t) (8)
2" 实验设置
2.1" 实验数据
本文实验数据分为两类,一类选自与Cao等[14]相同的中英联合国语料库,另一类选自WMT英德数据集。本次实验数据的详细信息见表1所示,其中M表示百万条。
本文选择用Moses[16]工具包提供的脚本对训练语料和单语的翻译记忆进行预处理,使用Moses工具包将训练数据的最大句长控制为50,源端与目标端的词典大小都设置为3万,其中英文端不区分大小写。本文对源端与目标端都采用了字节对编码(Byte Pair Encoding,BPE)[17],在做BPE处理时,设置合并操作的次数为3万。本文使用BLEU值[18]作为评价指标。
2.2" 实验设置
在训练开始前,对跨语言注意力网络的关键向量uk和vk进行随机初始化,在训练过程中,两个向量会不断地更新。编码器-解码器嵌入维数均设置为768。词向量和编码器、解码器输入的最大长度为768。前馈神经网络的维度设置为2 048,模型参数均使用Glorot Initialisation方法初始化,跨语言注意力记忆网络和编码器词嵌入层共享参数。采用Adam[19]作为优化器,其中Adam优化器的参数β1为0.9,β2为0.98,ε为10-9。在训练过程中,固定了随机种子seed为3 435,以token为单位的批处理大小设置为4 096,warm-up step设置为16 000,learning rate为0.5,dropout[20]为0.1,label smoothing为0.1,并使用相对熵作为损失函数。在测试过程中,使用集束搜索beam search进行解码,并设置beam size为4,长度惩罚因子α为0.6。在本文中将此模型叫作TF-Attention。
将Transformer模型作为Baseline,其中词向量的维度以及源端和目标端的隐层大小都设置为512,相关参数与Vaswani等[4]保持一致(在本文中将此模型叫作TF)。最后实现了Cao等[14]的方法,其中翻译记忆库选用双语的翻译句对,为了与本文方法进行比较,将翻译记忆库大小设置为40万,句长最大为50,在本文中将此模型叫TF-TM。
本文实验在NVIDIA TITAN RTX 24 G显卡上训练。训练20次后对模型停止训练,将BLEU作为评价指标,在20个模型中,选择在各个翻译方向上测试集BLEU值最高的模型。
3 实验结果与分析
3.1 实验结果
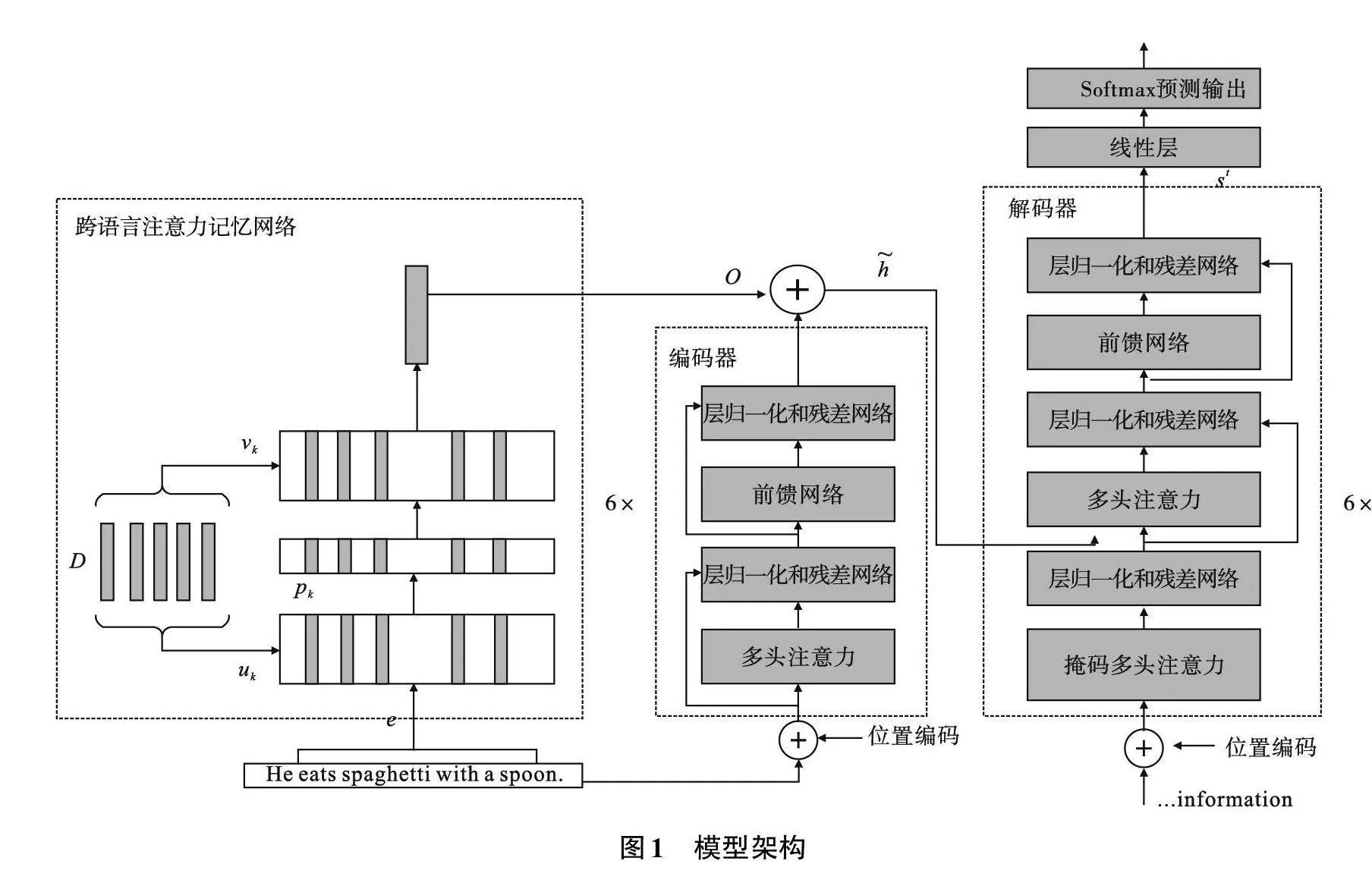
在本文中,对不同模型的结果进行比较。表2展示了在En-Zh、Zh-En、En-De、De-En 4个翻译方向上的实验结果。
在表2中可以发现,与Baseline(TF)相比,使用跨语言注意力模型的方法在全部测试集上都获得了提升。其中在En-Zh方向BLEU值提高了0.58;Zh-En方向上BLEU值提高了1.12。En-De方向上BLEU值提高了2.41;De-En方向上提高了1.85。
本模型的翻译结果与TF-TM模型相比,也均获得了提升。实验表明使用单语的翻译记忆并不比双语的翻译记忆效果差,反而得到更好的翻译质量,且使用少量的单语翻译记忆可以直接在两种语言之间挖掘有用信息,从而提高了模型的翻译质量,验证了本方法的有效性。
3.2 实验分析
3.2.1 翻译记忆库规模的大小对翻译的影响
在En-Zh、Zh-En两个翻译方向上依次进行实验。分别将40万单语语料库划分为4个大小相等的子集。将第一个子集作为翻译记忆,并通过在第一个子集中依次加入第二个子集,再加入单语数据来逐步扩大TM进行模型的训练,实验结果如表3所示。由实验结果可以发现,不同规模大小的翻译记忆库影响了模型的翻译效果,翻译记忆库规模越大,可利用的信息就越多,模型的翻译性能越好。
3.2.2 不同相似程度下的翻译记忆对模型的影响
由于实验资源有限,在实验中所使用的单语翻译记忆库的大小最大为40万。根据相似度算法为训练集检索到相应翻译记忆,并将其参与训练。表4中给出了不同相似度区间内的翻译记忆数据占实际翻译记忆库大小的比例。
由表4的实验结果可以看出,两个翻译方向均在相似度较高的[0.7,0.8)子集范围内获得了改进,在En-Zh翻译方向上BLEU值提高了0.72。而在[0.8,0.9)、[0.9,1.0)两个子集内,并没有因为相似度的增高而获得更高的BLEU值,原因可能是在这两个区间内的单语翻译记忆句子所占比例较小。总之,为训练集提前检索到相似度在[0.7,0.8)范围内的单语翻译记忆用作本模型的TM,可以明显提高模型的翻译质量;而且根据占比大小可知,TM越大,对翻译质量的提升越明显。
3.2.3 将训练语料作为翻译记忆
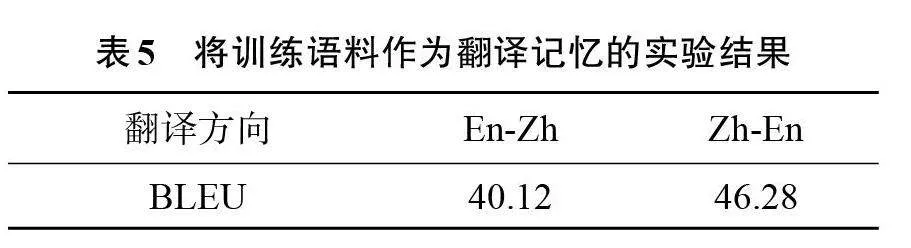
在训练语料中随机选出40万目标端句子作为翻译记忆库,并将其参与训练。得到的实验结果如表5所示。
从表5中可以看出,直接将目标端句子作为翻译记忆取得了显著的提升,在En-Zh翻译方向上比Baseline提高了2.01;与表2中随机挑选40万翻译记忆的结果相比,BLEU值也提高了1.43。这表明如果为模型提供完美的TM,可以产生非常好的翻译结果。
3.2.4 实例分析
表6为En-Zh方向上的翻译示例展示,对比了TF、TF-TM、TF-Attention 3个模型下的翻译结果。可以看到,TF(Baseline)模型在翻译时将“Regulations”翻译成了“条例”,TF-TM模型受到翻译记忆的影响将“Regulations”翻译正确,但没有将“《》”翻译出来,TF与TF-TM模型在翻译“实际运作情况进行审查”时都将“情况”翻译成“方式”,而TF-Attention模型的翻译几乎完全正确,这表明借助跨语言注意力记忆网络可以在翻译记忆中学到更深层的有用信息,进而帮助模型更好地翻译。
3.2.5 低资源场景下的结果
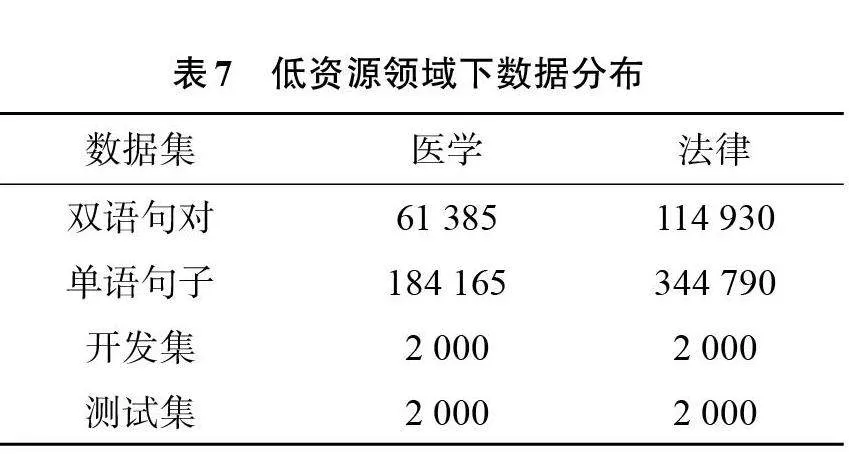
为了验证在低资源场景下本方法的有效性,收集了有关于医学和法律两个领域下的英德数据集。分别抽取2 000条句子作为开发集和测试集,然后用一部分双语句对进行训练,最后将剩余数据的目标端用来构建单语的翻译记忆,表7为数据的详细分布信息。
实验结果如表8所示。将加入通用领域的单语翻译记忆模型叫作TF-ordinary,将加入特定领域即与训练语料相关的单语翻译记忆模型叫作TF-specific。
从表8可以看出,当使用通用领域的单语数据作为TM来增强模型时,与基线模型相比,在医学领域BLEU值提高了1.85,在法律领域BLEU值提高了2.51。但在加入特定领域单语数据作为TM时,本模型与基线模型相比提高的更多,在医学领域BLEU值提高了2.32,在法律领域BLEU值提高了3.08。实验表明,在指导翻译上,加入特定领域的单语翻译记忆要比通用领域的数据更具有效果,从而也证明了本方法的有效性。
4 结论
本文探索了一种新的将翻译记忆融合到神经网络机器翻译的方法,即基于跨语言注意力记忆网络的神经机器翻译方法。与之前的方法不同,本文使用单语的句子集合作为翻译记忆,同时使用一个跨语言记忆网络,将单语翻译记忆与源句子在向量空间中进行对齐,获得翻译记忆的向量表示,最终将翻译记忆的信息融合到神经机器翻译模型中,这种方法进一步提高了模型的翻译质量。与之前的研究相比,本文使用的方法能够将翻译记忆的检索匹配过程与模型训练中的参数共同优化,进行一体化训练,不管是在通用领域还是特定领域都取得了不错的提升效果。
翻译记忆和机器翻译相结合,是一项非常具有应用价值和未来远景的研究工作。将来会进一步探索如何将大量的单语翻译记忆结合到机器翻译模型中,以及怎样利用不同句法知识来提高神经机器翻译。
参考文献(References):
[1] 冯洋,邵晨泽.神经机器翻译前沿综述[J].中文信息学报,2020,34(7):1-18.
[2] Sutskever I,Vinyals O,Le Q.Sequence to sequence learning with neural networks[C]//Advances in Neural Information Processing Systems 27:Annual Conference on Neural Information Processing Systems.Montreal, Canada,2014:3104-3112.
[3] Bahdanau D,Cho K,Bengio Y.Neural machine translation by jointly leaning to align and translate[C]//Proceedings of International Conference on Learning Representations. San Diego,USA:International Conference on Learning Representations,2015.
[4] Vaswani A,Shazeer N,Parmar N, et al.Attention is all you need[C]//Proceeding of Advance in Neural Information Processing Systems.Long Beach,USA,2017:5998-6008.
[5] 肖梦琳.翻译记忆库在CAT中的建设[J].智库时代,2020(9):239-240.
[6] 阮方圆.三大主流计算机辅助翻译软件[J].信息与电脑(理论版),2019(15):89-90,93.
[7] 汪昆,宗成庆,苏克毅.统计机器翻译和翻译记忆的动态融合方法研究[J].中文信息学报,2015,29(2):87-94,102.
[8] Gu J,Wang Y,Cho K,et al.Search engine guided non-parametric neural machine translation[C]//Proceedings of the AAAI Conference on Artificial Intelligence.New Orleans, USA,2018:5133-5140.
[9] Zhang J,Utiyama M,Sumita E,et al.Guiding neural machine translation with retrieved translation pieces[C]//Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies.New Orleans,USA,2018:1325-1335.
[10] Bapha A,Firat O.Non-parametric adaptation for neural machine translation[C]//Proceeding of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics:Hunan Language Technologies, Minneapolis, USA,2019:1921-1931.
[11] Cao Q,Xiong D.Encoding gated translation memory into neural machine translation[C]//Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing.Brussels, Belgien,2018:3041-3047.
[12] Bulte B,Tezcan A.Neural fuzzy repair:integrating fuzzy matches into neural machine translation[C]//Proceedings of the 57th Annual Meeting of the Association" for Computational Linguistics.Florence, Italy,2019: 1800-1809.
[13] XU J T,Crego J M,Senellart J.Boosting neural machine translation with similar translations[C]//Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics.Online,2020:1580-1590.
[14] 曹骞,熊德意.基于数据扩充的翻译记忆库与神经机器翻译融合方法[J].中文信息学报,2020,34(5):36-43.
[15] Reimers N,Gurevych I.Sentence-BERT:sentence embeddings using siamese BERT-networks[C]//Proceedings of the 2019 Conference on Emprirical Methods in Natural Language Processing.Hong Kong, China,2019:3982-3992.
[16] Koehn P,Hoang H,Birch A,et al.Moses:open source toolkit for statistical machine translation[C]//Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics.Prague, Czech Republic,2007.
[17] Sennrich R,Haddow B,Birch A.Neural machine translation of rare words with subword units[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics,Berlin, Germany,2016.
[18] Papineni K,Roukos S,Ward T,et al.BLEU:A method for Automatic Evaluation of Machine Translation[C]//Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. Philadelphia,USA,2002:311-318.
[19] Kingma D,Ba J.Adam:A Method for Stochastic Optimiza-tion[C]//International Conference on Learning Representa-tions.San Diego,USA,2015.
[20] Srivastava N,Hinton G,Krizhevsky A,et al.Dropout:a simple way prevent neural networks from overfitting[J].Journal of Machine Learning Research,2014,15(1):1929-1958.
(责任编辑:吴萍" 英文审校:杜文友)
