基于问题分解的多跳阅读理解方法
2023-04-12樊睿白宇蔡东风







摘要: 多跳阅读理解是自然语言处理研究领域的热点和难点,其研究在文本理解、自动问答、对话系统等方面具有重要意义和广泛应用。针对当前面向中文的多跳阅读理解(Multi-Hop Reading Comprehension,MHRC)研究不足的现状,构建了一个面向复杂问题的中文多跳阅读理解(Complex Chinese Machine Reading Comprehension,Complex CMRC)数据集,提出了一种基于问题分解的中文MHRC方法。该方法分为问题分解和问题求解两个阶段:首先提出了一种融合JointBERT模型和规则的复杂问题分解方法,通过JointBERT模型对问题类型识别和问题片段识别联合建模,获得准确的问题类型和问题片段信息,再利用专门设计的问题分解规则将复杂问题分解为多个简单子问题;然后采用BERT预训练模型对所有子问题进行迭代求解,最终获得复杂问题的答案。分别在Complex CMRC数据集上进行问题分解和问题求解实验,取得了良好的实验结果,验证了提出方法的有效性。
关键词: 多跳阅读理解;复杂问题分解;预训练模型;数据集构建;问题求解
中图分类号: TP399" " " " 文献标志码: A
doi:10.3969/j.issn.2095-1248.2023.02.008
Multi-Hop Reading Comprehension based on question decomposition
FAN Rui-wen , BAI Yu , CAI Dong-feng
(Human-Computer Intelligence Research Center, Shenyang Aerospace University,Shenyang 110136, China)
Abstract: Multi-Hop Reading Comprehension (MHRC) is a hot and difficult task in the field of natural language processing,and its research is importantly and widely used in text understanding,automatic question answering,and dialogue systems.To address the current lack of research on Chinese-oriented MHRC,a Chinese MHRC dataset for complex question was constructed and a Chinese MHRC method based on question decomposition was proposed.The method was divided into two stages:Firstly,a complex question decomposition method integrating JointBERT model and its rules was proposed to jointly model the question type identification and the question fragment identification by JointBERT model to obtain accurate question type and question fragment information,and then the specially designed question decomposition rules were used to decompose the complex question into multiple simple sub-questions.Secondly,the BERT pre-training model was utilized to iteratively solve all the sub-questions and finally obtain the answer of the complex question.The question decomposition and question solving experiments were conducted on the Complex CMRC dataset respectively which verify the effectiveness of the proposed method.
Key words: Multi-Hop Reading Comprehension;complex question decomposition;pre-trained models;dataset construction;question solving
多跳阅读理解(MHRC)任务是指机器通过从给定的文本中获得信息,通过多步推理对给定的问题作出回答。与单跳阅读理解任务相比,多跳阅读理解任务通常是在文章和问题结构更加复杂的情况下,需要更多的推理步骤才能得到答案。因此多跳阅读理解更加贴近于真实生活,更接近人类的推理认知,具有更广泛的研究和应用价值,同时更具有挑战性。
MHRC主要分为基于问题分解和基于图神经网络两种方法。其中基于问题分解的方法是指将复杂问题分解成多个相对简单的子问题,然后按序求解这些子问题来回答原问题,可显著降低问题的求解难度,这与人类解决复杂问题时化繁为简、分而治之的推理方式十分相似,具有很好的可理解性和可解释性。子问题可直接利用现有的单跳阅读理解方法求解,是当前MHRC的主流研究方向之一。本文将针对中文MHRC来探讨这种基于问题分解方法的有效性。
Yang等[1]所提出的英文多跳阅读理解任务数据集HotPotQA中的大部分问题属于复杂问题,需要机器通过多步推理得到答案,该数据集的出现使得复杂问题分解(Complex Question Decomposition)的方法受到广泛关注。
近年来,基于复杂问题分解出现了很多有价值的工作,比如Min等[2]提出基于有监督方式的DecompRC模型,该模型针对不同类型的问句设计不同的分解规则,将复杂问题转化成若干个简单的、可以直接用现有的改进单跳阅读理解模型[3]回答的问题;此外还设计了一种新的全局打分方法,显著提高了在HotpotQA数据集上的整体性能;Perez等[4]提出了基于无监督方式的ONUS模型,该模型利用了无监督方式实现复杂问题的分解,先在没有监督的情况下使用伪分解学习分解,再使用现有的单跳阅读理解模型解决子问题,最后使用子问题及其答案作为附加输入更准确地回答复杂问题,该HotpotQA数据集上的工作效果显著提高;Hasson等[5]将复杂问题转化成依存图,依存图的节点为问句中的实体,依存图的边表示实体的逻辑关系,不同逻辑关系代表不同的问题分解操作,最后利用从序列到序列的结构学习分解过程,在性能相近的情况下,推理速度大幅提高。Zhang等[6]提出了分层语义解析(Hierarchical Semantic Parsing,HSP)方法,通过端到端模型进行训练,显著提升了实验效果;Gao等[7]构建了DeSSE数据集,该数据集用于训练并评估句子分解的效果,并提出了基于英文的ABCD模型,将复杂句子转化成图网络表示,并利用基于自注意力机制的序列到序列模型进行训练,得到很好的分解效果;Qi等[8]根据问题和文章生成自然语言搜索查询,利用现成的信息检索系统查询缺失的实体或证据来回答原问题,有效地扩展开放领域的多跳推理。
以上有关基于问题分解的MHRC工作都是在英文数据集上完成的,而面向中文复杂问题的MHRC研究较少,主要原因是难以找到中文的MHRC数据集。一些中文阅读理解评测中使用的数据集多是简单问题数据集,因此需要专门开发面向复杂问题的多跳阅读理解数据集。参考Min等[2]提出的DecompRC模型工作,提出了一种基于问题分解的中文多跳阅读理解方法。
1 Complex CMRC数据集设计
1.1 数据集来源及构建
Complex CMRC数据集的原始数据选用已公开的高质量中文阅读理解抽取式数据集CMRC2018[9],从中随机挑选了368篇文章,并通过手动标注的方式将原数据集的简单问题改编为复杂问题,共标注1 000条复杂问题。其中每条问题的数据包括:文章、问题,问题类型、分解后的子问题集合、答案和支持事实等。实例说明如下。
文章:0“杜文辉,中国足球运动员,司职前锋。”
1 “1998年,他正式进入北京国安三队。”
2 “1999年,杜文辉和邵佳一、崔威、王硕等人去法兰克福培训半年。”
3 “2002年,杜文辉进入北京国安一线队,杜文辉在热身赛中因骨折养伤3个月。”
标题:“杜文辉”
问题:“杜文辉正式进入北京国安三队的那年距离他进入北京国安一线队的那年间隔多少年?”
问题类型:“Bridge_Arithmetic_3”
子问题集合:[“杜文辉正式进入北京国安三队是什么时间?”,“杜文辉进入北京国安一线队是什么时间?”,“[ANS1]距离[ANS2]间隔多少年?”]
答案:“4年”
支持事实:[[“杜文辉”,1],[“杜文辉”,3]]
实例中的支持事实指可以推理出问题答案的句子序列,每个事实由文章标题和句子的标号组成。
本文后面的所有实验部分都以Complex CMRC作为测试集进行评测,包括问题类型和问题片段识别实验、问题分解实验和问题求解实验。
1.2 问题类型定义
回答复杂问题一般需涉及文章中的多个句子,句子间是通过共享的实体或问题片段建立起联系。一个复杂问题一般可以分解为相互关联的多个简单问题或子问题,这里某一简单问题的答案会作为另一个简单问题的组成成分出现(例如主语等),这个答案就相当于链接前后两个子问句的桥梁(Bridge),称为Bridge实体。因此,这类问题统称为Bridge型问题。在一般Bridge型问题的基础上,从问题分解的角度出发,依据子问题间的关系类型和答案类型,参考Min等[2]和Wolfson等[10]英文问题分类的有关工作,最终将复杂问题分为6种类型。
(1) 桥接型(Bridge):问题可分解成两个子问题,且子问题1的答案用于子问题2中,答案为文章的一段文本,可以是实体名、日期以及数值等;
(2) 布尔型(Boolean):与Bridge型问题相似,答案为Yes或No;
(3) 比较型(Comparison):比较Bridge实体属性的属性值,答案类型Yes或No;
(4) 联合型(Union):在Bridge型基础上,要回答两个并行的关于Bridge的子问题;
(5) 计算型1(Arithmetic1):计算两个实体的相同属性的属性值的和或差;
(6) 计算型2(Arithmetic2):在Bridge型基础上,计算两个实体的同类属性值的和或差。
其中布尔型和比较型都是判别类的问题,答案为Yes或No。与Min等[2]不同,本文增加了比较判断型问题,可以回答有关实体属性值是否满足给定条件的判断问题(例如:某人的年龄是否已经超过70岁了?)。另外,为了增加问题的复杂度,本文有意在每类问题(除计算型1外)中都引入了Bridge实体。
每个问题类型对应的分解图、具体问题及问题分解后的结果如表1所示。其中问题类型和问题分解图中,节点表示子问题,箭头表示子问题间依赖关系,后面子问题的求解要用到前面子问题的答案。问题分解结果及答案中,括号里是相应子问题的答案,一般最后一个子问题的答案就是原复杂问题的答案。
1.3 数据分布统计
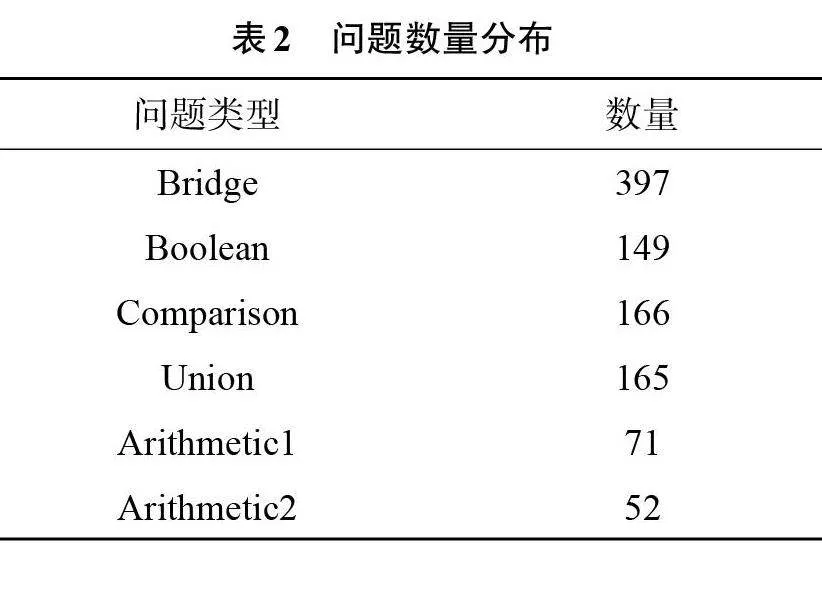
Complex CMRC数据集共包括1 000个复杂问题,每类问题的数量分布如表2所示。
2 融合JointBERT模型与规则的问题分解方法
2.1 问题分解方法概述
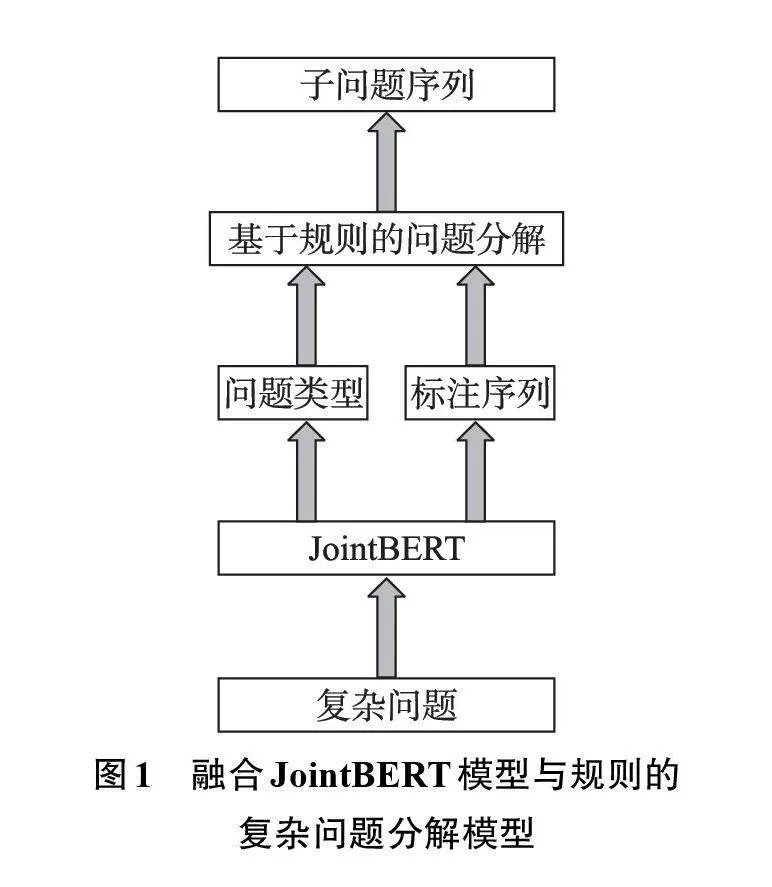
由于不同类型的问题具有不同的结构和分解要求,问题类型对于问题分解和问题求解都具有重要的指导意义。因此,本文问题分解方法分为两步:第一步,采用JointBERT联合模型,识别出复杂问题的问题类型和需要标注的问题片段;第二步,根据不同的问题类型,按照不同规则对问题进行分解,生成相应的子问题集。具体模型结构如图1所示。
2.2 复杂问题的标签设计
为了将问题分解为子问题,需要识别出问题中的重要片段,称为问题片段。本文采用BIOE序列标注方法,针对不同的问题片段引入不同的字标签。问题片段一般是复杂问题中的名词或短语,根据子问题答案的类型分为实体片段(OBJ)、时间片段(TIME)和数值片段(NUM);同时根据联合桥类型问题中所存在的两个并列成分和比较桥类型问题中存在实体属性比较成分,又分为并列片段(COO)、数值比较片段(COM_NUM)、时间比较片段(COM_TIME),总共6类问题片段。每类问题片段都要有开始(B)、中间(I),结束(E)的标签,另外不是问题片段的部分用标签“O”标注,共19种不同的标签。下面将用例子说明问题片段的标注。
桥接型问题:曾担任台北市立交响乐团团长及音乐总监的人在哪所学校学习的小提琴?
比较型问题:属于雀形目鸟类的动物 的 身长 超过10 cm了吗?
对于实体片段的标注标签是开始字B_OBJ、中间字I_OBJ、结束字E_OBJ,数值片段的标注标签的开始字B_NUM、中间字为I_NUM、结束字为E_NUM,其他问题片段的标注以此类推。
2.3 基于JointBERT的问题类型和问题片段的联合识别方法
JointBERT[11]模型在口语语言理解(Spoken Language Understanding)任务中被提出,针对意图识别和槽填充的联合任务,采用基于预训练模型BERT的联合建模方法,取得非常好的效果。考虑问题类型和问题片段的识别任务具有很强的相关性,适合于联合建模,因此,本文采用了基于JointBERT的联合识别方法。
2.3.1 识别方法
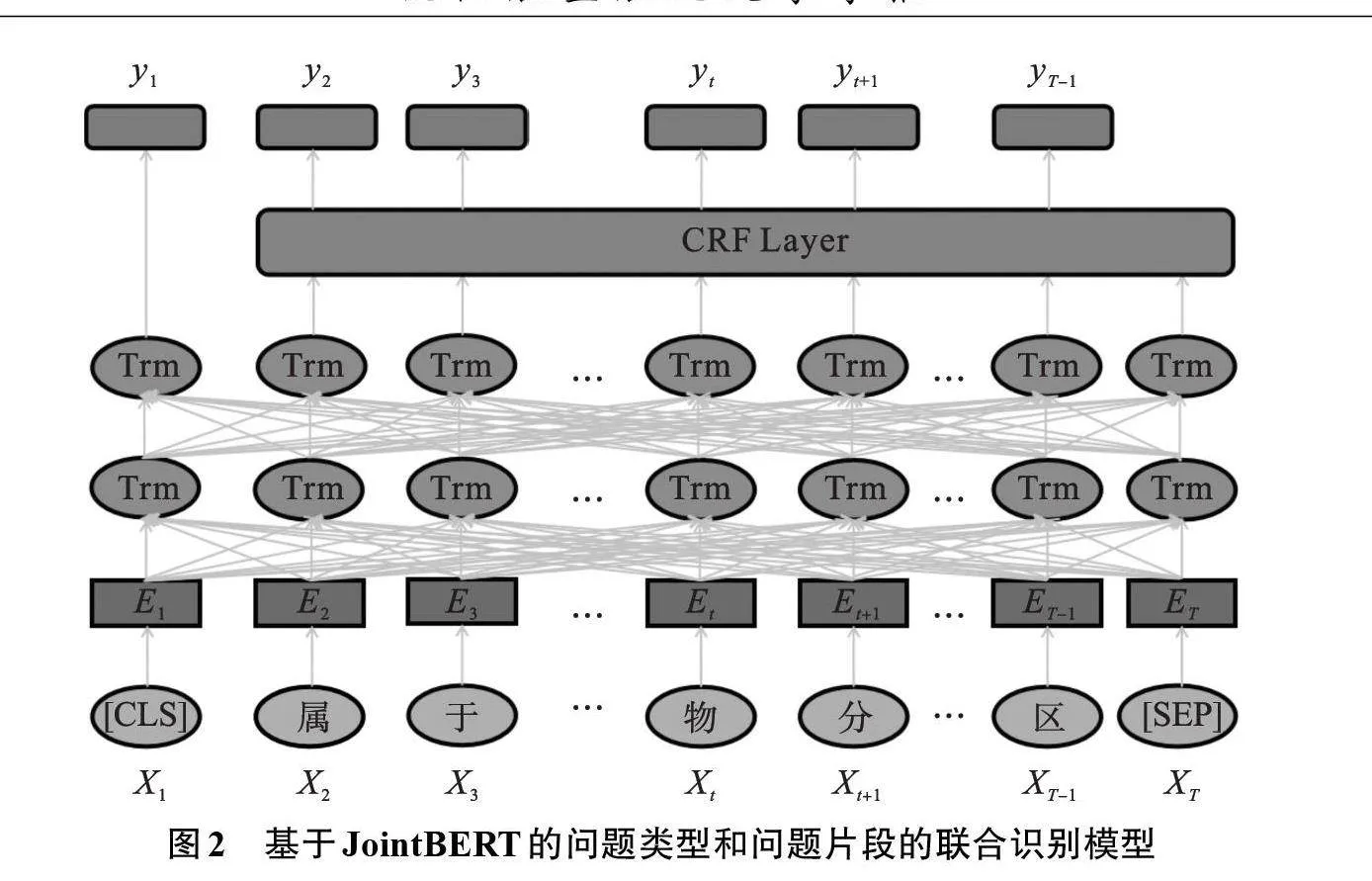
本文采用改进的基于JointBERT的问题类型和问题片段的联合识别模型结构,如图2所示。JointBERT模型结构上就是BERT模型,但在训练方式上采用了联合建模。BERT的模型架构是基于原始Transformer模型(Tm)的多层双向Transformer编码器。为了进一步优化输出序列,本文又在最后输出端加入了条件随机场[12]CRF(Conditional Random Field)层。图中以Bridge类型问句“属于细小的雀形目鸟类的动物分布在哪些地区?”为例。
图中[CLS]位是模型输入的首位置,[SEP]位是输入的最后一位,整个输入序列记为X=(X_1,X_2,…,X_T),输出序列为Y=(y_1,y_2,…,y_(T-1)),E_i是x_i对应的编码表示。
对于问题类型识别任务,JointBERT使用第一位[CLS]用来预测,使用[CLS]位的隐藏状态h_1,其预测过程如式(1)所示
y_1=softmax(W^1 h_1+b^1) (1)
对于问题片段识别任务,利用X_2,…,X_T的隐藏状态进行预测,其预测过程如公式(2)所示
y_n^'=softmax(W^2 h_n+b^2),n∈2,…,T (2)
式中:h_n是字符x_n的对应的BERT的隐藏状态。
利用CRF捕捉标签间的依赖关系全局优化标注序列,公式如式(3)所示
y_n=CRF(y_n^'),n∈2,…,T (3)
最后为了联合上述两项任务,最大化条件概率p(Y|X),如公式(4)所示
p(Y|X)=p(y_1 |x_1)∏_(n=2)^T▒〖p(y_n |x_n)〗 (4)
2.3.2 识别实验
本实验采用JointBERT模型解决Complex_CMRC数据集中复杂问题的类型识别和问题片段识别的联合任务,将整体数据集中的1 000条问题数据按照6∶2∶2的比例划分为训练集、验证集、测试集。
(1) 实验参数设置
采用Python3.6和Pytorch1.6框架,Batch size设置为32,学习率Learning rate设置为5e-5,Dropout rate设置为0.1,序列最大长度Max sequence length设置为100,Epoch设置为20。
(2) 实验评价指标
问题分类和问题片段序列标注的评价指标分别是正确率ACC和F1值。
(3) 实验结果
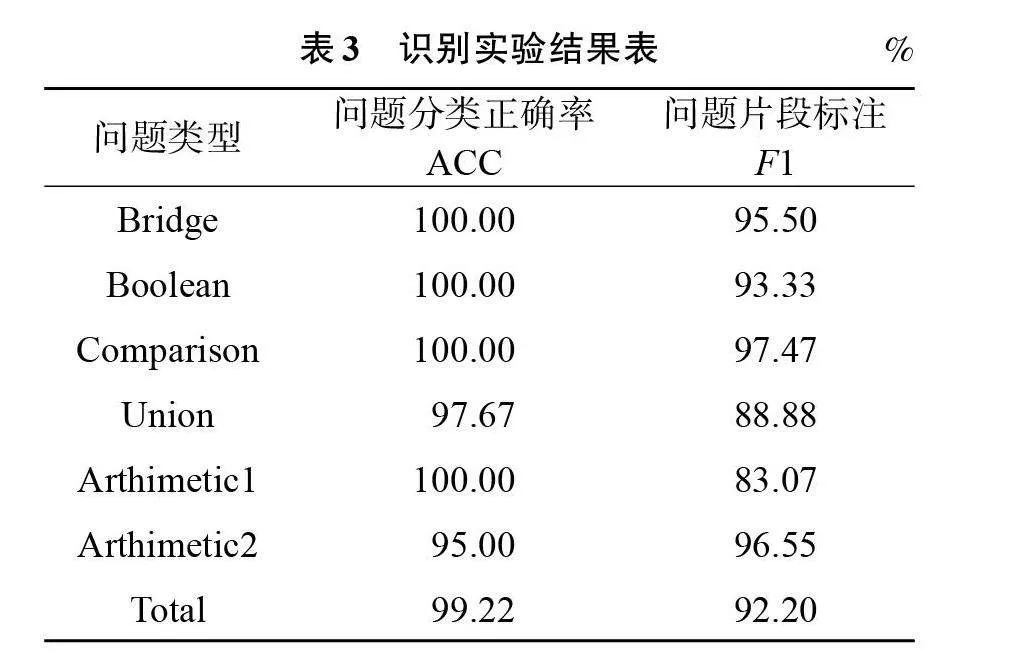
在测试集上的分类结果和问题片段识别结果如表3所示。
从表3可见,利用JointBERT模型进行上述联合识别任务效果良好,问题类型分类正确率高达99.22%,问题片段标注的F1值也达到了92.20%的效果。这说明JiontBERT模型的有效性和问题分解的可行性,为下一步问题分解奠定了良好的基础。
2.4 基于规则的问题分解
2.4.1 问题分解规则设计
问题分解规则是在充分分析和总结复杂问题的结构特点的基础上,基于问题类型信息和对各类问题片段的序列标注结果,由人工建立的。由于篇幅所限,下面仅以最简单的Bridge型问题和Boolean型问题的分解规则为例进行说明。
Bridge型问题和Boolean型问题的分解规则如下:
(1) 得到以“B-OBJ”标签开始,以“E-OBJ”标签结束的标签序列对应的问题片段,在后面添加疑问词“叫什么名字?”,构成子问题1。
(2) 将子问题1的答案标记成[ANS1],与E-OBJ后的问题剩余部分拼接得到子问题2。
关键是正确标注出句中的实体片段,这样就可以利用上面规则把问题分解为子问题。其他问题类型的分解规则要更复杂一些,要用到一些不同的问题片段,如时间片段,数字片段等。
2.4.2 实验结果与分析
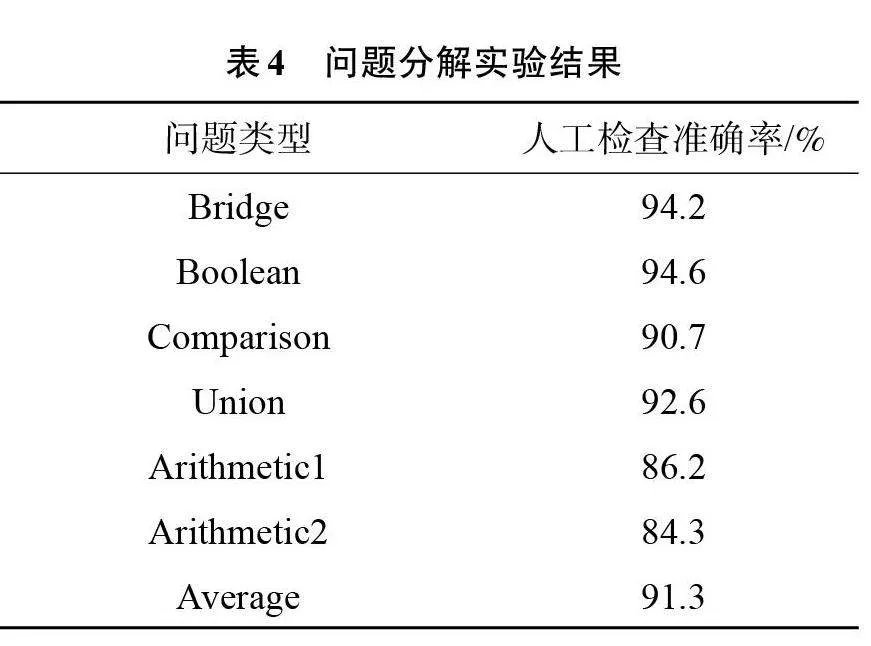
实验结果使用问题分解的子问题正确率为评价指标。对于同一问题,问题分解结果可以不唯一,只要合理就可以,但这样会造成实验结果的自动评价比较困难。因此,对规则分解结果是采用人工检查的方式进行对错判断和正确率计算,实验结果如表4所示。
通过表4实验结果可以看到,问题的平均分解正确率达到91.3%,取得了较好的结果,验证了分解规则的有效性。另外,子问题数量也对问题分解的正确率产生影响,分解子问题少的Bridge型和Boolean型问题,正确率最高达到94%以上;但分解子问题相对越多的问题,分解正确率就越低;最低的是要分解4个子问题的Arithmetic2型问题,正确率是84.3%。
3 基于预训练模型的问题求解
3.1 模型描述
在问题分解的基础上,按问题类型不同利用BERT预训练模型来组织和回答多个简单子问题,最终获得复杂问题的答案,也就是最后一个子问题的答案。不同问题类型,基于预训练模型BERT进行问题求解的过程如下:
(1) Bridge型问题
ANS1=BERT(q1,T) ANS2=BERT(q2(ANS1),T)
(2) Boolean型问题
ANS1=BERT(q1,T) ANS2=BERT(q2(ANS1),T)
(3) Comparison型问题
ANS1=BERT(q1,T) ANS2=BERT(q2(ANS1),T) ANS3=BERT(q3(ANS2))
(4) Union型问题
ANS1=BERT(q1,T) ANS2=BERT(q2,T) ANS3=BERT(q3(ANS1,ANS2),T)
(5) Arithmetic1型问题
ANS1=BERT(q1,T) ANS2=BERT(q2,T) ANS3=BERT(q3(ANS1,ANS2))
(6) Arithmetic2型问题
ANS1=BERT(q1,T) ANS2=BERT(q2(ANS1),T)
ANS3=BERT(q3(ANS1),T) ANS4=BERT(q4(ANS2,ANS3))
式中:T表示文章;qi表示第i个子问题;ANSi表示第i个子问题的答案;BERT表示预训练模型。对于给定的qi和T,通过BERT预训练模型得到答案ANSi。
3.2 问题求解实验
3.2.1 实验语料与模型
实验将使用中文阅读理解数据集CMRC2018和中文司法评测数据集CAIL2020进行微调,使用与问题分解实验中同样的Complex CMRC数据集的测试集作为测试语料。
作为子问题求解的预训练模型,本实验采用了哈尔滨工业大学开源的6个BERT系列的中文预训练模型:BERT、BERT-wwm[13]、BERT-wwm-ext[13]、MacBERT[14]、Roberta[15]和RoBERTa-wwm-ext[13]。
BERT是基准模型,本实验中选择BERT-Base-Chinese为基准测试模型,预训练任务为掩码语言模型(Masked Language Model,MLM)和下一句子预测(Next Sentence Prediction,NSP)。其他模型都是在此基础上得到,例如:wwm表示采用了全词掩盖代替字掩盖;ext表示扩展了训练语料库中文维基百科的语料,加入了其他百科、新闻、问答等语料数据;MacBERT和Roberta都对模型的训练进行了一些改变。
3.2.2 实验设置
实验采用Python3.6,Pytorch1.6.0框架,微调训练参数设置如下:
CAIL2020数据集上Batch size=32,Learning rate=1e-5,Dropout rate=0.1,Max sequence length=512,Epoch number=10;CMRC2018数据集上Batch size=32,Learning rate =3e-5,Dropout rate=0.1,Max sequence length=512,Epoch number=2。
3.2.3 实验评价指标
实验评价指标分为3部分,分别是问题答案评价指标、支持事实评价指标、联合评价指标。
问题答案评价指标包括答案精确匹配ANS EM、答案F1值ANS F1。ANS EM将模型预测的问题答案直接以字符串形式与标准答案进行比较,完全相同为1,否则为0。ANS F1是问题答案准确率ANS Precision和问题答案召回率ANS Recall的调和平均数。具体定义公式如式(5)、(6)和(7)所示
ANS Precision=
正确答案与预测答案重合的字符数量/预测答案的字符数量×100% (5)
ANS Recall=
正确答案与预测答案重合的字符数量/正确答案的字符数量×100% (6)
ANS F1=
(2×ANS Precision×ANS Recall)/(ANS Precision+ANS Recall)×100% (7)
支持事实评价指标包括支持事实精确匹配Sup EM、支持事实F1值Sup F1;计算公式与问答答案评价指标计算公式相似,只是将字符数量更改成支持事实集合的长度。
由于分解问题模型将复杂问题分解为多个子问题,回答每一个子问题都会得到该子问题Sup EM和Sup F1,因此为了得到通过分解模型回答复杂问题的支持事实评价指标,将复杂问题分解出的每一个子问题的Sup EM和Sup F1分别加权计算。将第i个子问题的支持事实精确匹配记为Sup EM_i;将第i个子问题的支持事实准确率记为Sup Precision_i;将第i个子问题的支持事实召回率记为Sup Recall_i,复杂问题可以分解为n个子问题。计算公式如式(8)、(9)、(10)和(11)所示
Sup EM=(∑_(i=1)^n▒〖Sup EM_i 〗)/n×100% (8)
Sup Precision= (∑_(i=1)^n▒〖Sup Precision_i 〗)/n×100% (9)
Sup Recall= (∑_(i=1)^n▒〖Sup Recall_i 〗)/n×100% (10)
Sup F1= (2×Sup Precision·Sup Recall)/(Sup Precision+Sup Recall)×100% (11)
联合评价指标包括联合精确匹配Joint" EM和联合F1值Joint F1。Joint" EM是将答案精确匹配值ANS EM与支持事实精确匹配值Sup EM相乘得到;将第i个子问题的答案精确匹配记为ANS EM_i;将第i个子问题的支持事实精确匹配记为Sup EM_i;将第i个子问题的联合精确匹配记为Joint EM_i,具体公式如式(12)所示
Joint" EM_i=ANS EM_i·Sup EM_i (12)
将每一个子问题的联合精确匹配值相加得到最终的联合精确匹配值 Joint EM,具体公式如(13)所示
Joint EM=∑_(i=1)^n▒〖Joint EM_i 〗 (13)
第i个子问题的联合F1值Joint F_i是该子问题的联合准确率Joint Precision_i和联合召回率Joint Recall_i的调和平均数。将第i个子问题的答案准确率、答案召回率、支持事实准确率、支持事实召回率分别记为ANS Precisioni、ANS Recalli、Sup Precisioni、Sup Recalli,具体公式如式(14)、(15)和(16)所示
Joint Precisioni=ANS Precisioni·Sup Precisioni
(14)
Joint Recalli=ANS Recalli·Sup Recalli (15)
Joint F1i=(2×Joint Precision_i" · Joint Recall_i)/(Joint Precision_i+Joint Recall_i )×100% (16)
将每一个子问题的联合F1值相加得到最终的联合精确匹配值Joint F1,具体公式如(17)所示
Joint F1=∑_(i=1)^n▒〖Joint F1_i 〗 (17)
3.2.4 实验结果与分析
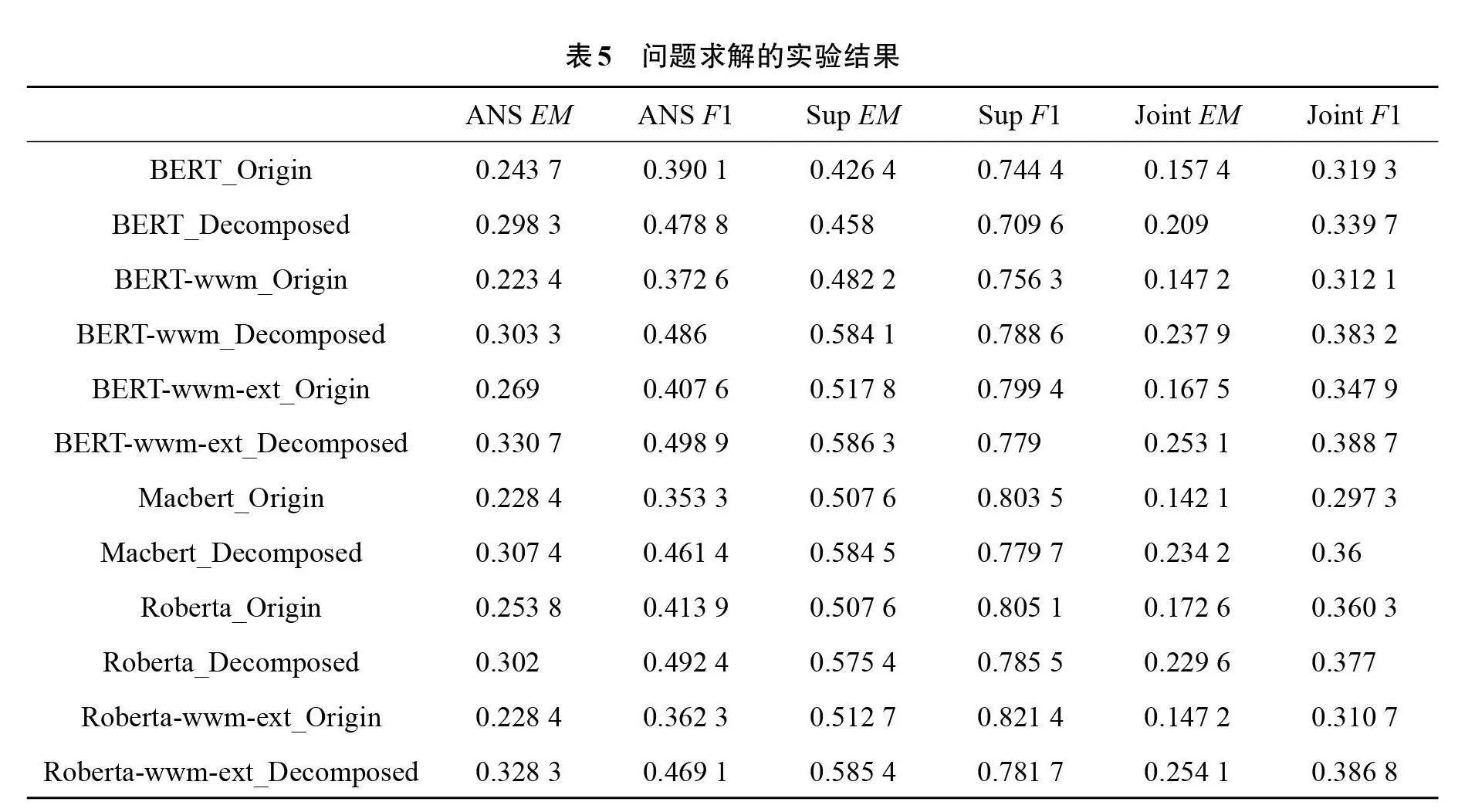
表5是问题求解的实验结果。其中给出了6个BERT系列中文预训模型,分别是使用和不使用问题分解方法的实验结果,Origin表示没有使用问题分解,Decomposed表示使用了问题分解的模型。
通过实验结果可以看出,使用问题分解模型对回答复杂问题的效果更好,准确率更高,6个模型的联合评价指标都得到了显著提升,平均联合精确匹配指标Joint EM提高8%,联合F1值Joint F1指标提高4.79%,验证了基于问题分解方法的有效性。
基于问题分解的BERT-wwm-ext_Decomposed和Roberta-wwm-ext-Decomposed模型表现突出,前者获Joint_F1最高值0.388 7,Joint EM第二高0.253 1;后者获Joint EM最高值0.254 1,Joint F1第二高0.386 8。二者模型在使用BERT和Roberta的基础上使用了全词掩盖代替字掩盖的方式,并利用了其他百科、新闻、问答等语料数据进行训练,能相对准确地定位问题答案和找到答案的支持事实句子。
4 结论
本文针对当前面向中文的MHRC研究不足的现状,开发了一个面向复杂问题的中文MPRC数据集Complex CMRC,包括368篇文章、1 000个问题。同时在对已有问题分类工作的归纳基础上,设计了6种复杂问题类型。提出了一种基于问题分解的中文MHRC方法。该方法分为问题分解和问题求解两个阶段:首先提出了一种融合JointBERT模型和规则的复杂问题分解方法,通过JointBERT模型对问题类型识别和问题片段识别进行联合建模,获得准确的问题类型(正确率为99.22%)和问题片段信息(F1值为92.2%),再利用问题分解规则将复杂问题分解为多个简单子问题(正确率为91.3%);然后在多个预训练模型上对所有子问题进行迭代求解,最终获得复杂问题的答案。实验表明,6个模型的联合评价指标都得到了显著提升,平均Joint EM提高8%,Joint F1提高4.79%,验证了提出方法的有效性。
本文是对中文MHRC的一次探索,还有许多可改进和优化的地方。下一步工作将扩展Complex CMRC数据集规模,进一步完善问题分解规则,采用更有效的子问题求解模型和方法。
参考文献(References):
[1] Yang Z,Qi P,Zhang S Z,et al.HotpotQA:a dataset for diverse,explainable multi⁃hop question answering[C]//Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing.Stroudsburg,USA:Association for Computational Linguistics,2018:2369-2380.
[2] Min S,Zhong V,Zettlemoyer L,et al.Multi-hop reading comprehension through question decomposition and rescoring[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics.Stroudsburg,USA:Association for Computational Linguistics,2019:6097-6109.
[3] Min S,Wallace E,Singh S,et al.Compositional questions do not necessitate multi⁃hop reasoning[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics.Stroudsburg,USA:Association for Computational Linguistics,2019:4249-4257.
[4] Perez E,Lewis P,Yih W T,et al.Unsupervised question decomposition for question answering[C]//Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP).Stroudsburg,USA:Association for Computational Linguistics,2020:8864-8880.
[5] Hasson M,Berant J.Question decomposition with dependency graphs[EB/OL].(2021-04-17)[2021-10-23].https://arxiv.org/abs/2104.08647.
[6] Zhang H Y,Cai J J,Xu J J,et al.Complex question decomposition for semantic parsing[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics.Stroudsburg,USA:Association for Computational Linguistics,2019:4477-4486.
[7] Gao Y J,Huang T H,Passonneau R J.ABCD:a graph framework to convert complex sentences to a covering set of simple sentences[C]//Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing.Stroudsburg,USA:Association for Computational Linguistics,2021:3919-3931.
[8] Qi P,Lin X W,Mehr L,et al.Answering complex open-domain questions through iterative query generation[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP).Stroudsburg,USA:Association for Computational Linguistics,2019:2590-2602.
[9] Cui Y M,Liu T,Che W X,et al.A span⁃extraction dataset for Chinese machine reading comprehension[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP).Stroudsburg,USA:Association for Computational Linguistics,2019:5882-5888.
[10] Wolfson T,Geva M,Gupta A,et al.Break it down:a question understanding benchmark[J].Transactions of the Association for Computational Linguistics,2020,8:183-198.
[11] Chen Q,Zhuo Z,Wang W.BERT for joint intent classification and slot filling[EB/OL].(2019-02-28)[2021-05-28].https://arxiv.org/abs/1902.10909v1.
[12] McCallum A.Efficiently inducing features of conditional random fields[C]//Proceedings of the Nineteenth conference on Uncertainty in Artificial Intelligence.New York,USA:ACM,2002:403-410.
[13] Cui Y M,Che W X,Liu T,et al.Pre-training with whole word masking for Chinese BERT[J].Institute of Electrical and Electronics Engineers,2021(29):3504-3514.
[14] Cui Y M,Che W X,Liu T,et al.Revisiting pre-trained models for Chinese natural language processing[EB/OL].(2020-04-29)[2021-10-20].https://arxiv.org/abs/2004.13922.
[15] Liu Y H,Ott M,Goyal N,et al.RoBERTa:a robustly optimized BERT pretraining approach[EB/OL].(2019-07-26)[2021-08-16].https://arxiv.org/abs/1907.11692.
(责任编辑:刘划" 英文审校:杜文友)
