基于Hadoop与Spark的大数据处理平台的构建研究
2023-04-11朱毓
摘要:鉴于当前的数据治理管控方法缺乏统一标准约束,治理管控效果比较差,故此设计一种基于Hadoop与Spark大数据平台的数据治理管控方法。使用Apache Atlas元数据管理工具,配合Hadoop与Spark平台完成管理工具的伸缩和扩展,实现元数据管理,利用Hadoop与Spark大数据平台中自带的分布式文件系统GFS的结构,内置的大量块服务器与客户端功能使用的过程中进行交互,搭建并行计算框架,数据治理过程主要针对数据的一致性、完整性和实时性三个方面进行治理过程设计。方法性能测试结果表明:使用设计的数据治理管控方法,企业的运营数据一致性、完整性、实时性分别为97.5%、97.7%、95.4%,由此可以看出数据质量存在提升。
关键词:Hadoop;Spark;大数据处理;平台构建
引言
当前社会正处在大数据时代,各行各业在开发新的应用程序过程中,都是以大量的行业数据为研发基石的,而行业大数据分析也已变成了公司在企业信息化构建过程中的关键数据源泉[1]。大数据分析在提供给人们海量资讯的同时,也会随之而来产生一系列数据问题,使得应用程序无法有效而精准地解决现实行业需求,严重时甚至会影响整个企业数据管理平台的构建[2]。基于这种情况,对大数据进行治理以提升数据质量,是当前企业在数据时代的必行之策。为解决因缺乏统一的标准约束,在数据治理过程中难以展示数据的不同维度,导致治理管控效果有限的不足,本文设计一种基于Hadoop与Spark大数据平台的数据治理管控方法。该方法以Hadoop与Spark大数据平台为基础,对数据进行多方面的梳理与展示,为数据治理管控提供一定的便利条件。
1. 数据治理管控方法设计
1.1 设计元数据管理方案
大数据的背景下,元数据能够对数据的种类进行格式化的区分和描述,将非线性的大数据之间关系变得清晰,在实际应用中能够实现精准的数据生命周期管理[3]。元数据存在的意义是描述数据,对其进行管理能够将元数据的功能提供给所有的业务人员,促使业务人员能够快速理解数据,保证数据的利用率提升。在元数据管理方案中,一般使用管理工具来实现对元数据的管理。目前市面上对于元数据管理的重视程度较低,因此针对开源元数据的管理工具较少。
本文主要使用的是Apache Atlas元数据管理工具,该管理工具是元数据厂商出品的商业智能套件之一,在客户端所提供的版本是C/S版本。在实际的平台应用中,支持Hadoop与Spark大数据平台数据库的数据源,在数据通用标准模型中也能发挥自身的功能。该工具对于元数据模型具有良好的描述效果,对于数据的属性也在可编辑范围内[4]。在实际的使用过程中,可以结合工具的其他功能完成报表的设计以及OLAP分析。与此同时,在附件导入、Web界面访问等功能上都有良好的表现。与其他工具相比,功能更加丰富强大。除此之外,Atlas元数据管理工具在大数据处理体系中,能够配合Hadoop与Spark平台完成管理工具的伸缩和扩展,实现大数据的治理。在这样的组件使用方式下,能够形成大数据与工具组件信息之间的统一管理。
1.2 建立基于Hadoop与Spark大数据平台的并行计算框架
在Hadoop與Spark大数据平台中,所包含的HDFS分布式文件与大数据平台并行计算框架之间高度相关。作为大数据平台中的文件系统,其中的主要功能就是并行计算与存储组织计算机数据。Hadoop与Spark大数据平台上,在利用自带分布式文件系统GFS的结构中,存储的文件规模大,但是数量较少,与传统的大量文件之间是存在一定区别的。该文件系统在存储和读写数据的过程中,一般是直接在存储文件的代码末尾附加一个缩略数据,以达到减少开销的目的。与此同时,该缩略数据能区分数据流与控制流。GFS系统在运行过程中,内置的大量块服务器与客户端功能在使用的过程中进行交互,这样的直接交互方式能够提升计算过程繁忙时段的效率。Hadoop与Spark大数据平台中的HDFS分布式结构非常适合并行计算,在进行数据治理管控的过程中,能够提供良好的存储环境。数据在访问和存储过程中,这种分布式的集群环境都能够提升数据治理管控过程中平台的吞吐量。在不同功能节点划分的状态下,可以实现一对多。
本文所设计的数据治理管控方法就是在这样的环境下搭建MapReduce并行计算框架。通过合并之后转到下一个reduce过程进行处理。在搭建的并行计算框架中,根据框架中原有的编写作业,运行进程会生成一个对应的唯一作业,每次在执行程序的过程中,会生成一个对应的工作ID。每次只能实现一个作业的单一执行,这样会提升并行计算的效率,且请求的资源能够完全提交到HDFS上,能够避免因为运行期间等待提交超时而被误认为异常的情况发生。
1.3 数据多维度治理
数据治理主要是从数据的一致性、完整性和实时性三个方面进行治理。数据的一致性主要是指数据在采集到表达的一整套过程的各个阶段中,数据属性字段的命令一致。相同数据在一些属性的数据类型和精度方面是负荷实际需要的,在使用的过程中遵循数据的约束条件和实际的数据管理业务逻辑规则,才能够避免不一致的数据出现,从源头杜绝数据冗余。在一致性治理过程中,首先要对不规范数据进行统计,将数据进行分类,按照类别对不规范数据进行查询,利用SQL语句进行编程,查找不一致数据。在得到统计的数据之后,将不符合规定的数据导出[5],对不一致的数据字段利用不同的颜色进行标注,并按照不同的数据源进行采集之后,按照单位属性的不同进行分组,下发到数据收集的各个部门中。负责数据采集的部门将自身部门数据按照一致性的字段进行填写之后,汇总到数据项目组中,进行大数据平台的统一更新。将收集到的模板数据导入后台准备的临时数据表中,需要补充或修改的字段形式为代码形式,那么先将其存储之后,再导入平台的临时数据表中,利用字段进行代码翻译。在完成以上工作之后,进行数据更新,利用临时数据表中的对应字段与平台设备数据进行更新。数据的完整性和实时性治理过程与数据一致性的治理过程相似。在完成这三个方面的数据治理之后,数据质量会有一定程度的提升。至此完成基于Hadoop与Spark大数据平台的数据治理管控方法的设计。
1.4 大数据可视化技术分析
Hive是用于Hadoop平台的一种分布式数据分析框架,不仅能够实现Hadoop平台的数据存取和转换,还提供了丰富的SQL查询处理手段。为了衔接底层并行处理结构,Hive的查询语句被系统转换为Map和Reduce函数.利用这两个函数实现并行处理,可以极大地降低查询成本。同时,与HDFS类似,它也采用流模式进行数据输入和输出,不支持数据的随机存取。但是Map和Reduce函数的转换需要消耗一定的资源,因此对大规模查询,效率将会下降,其实时查询的效果也不佳。HBase是一种基于HDFS的数据库,且它是开源和基于列的,通常传统数据库均是基于行进行数据存取和查询的,而HBase则基于列进行相关操作,它的另外一個重要特征是可以用于存储非结构化数据(这正是大数据环境下亟待解决的问题)。传统数据库一般用于存储符合某一范式的结构化数据,但是大数据时代,非结构化数据将成为主流(如网络平台上发布的照片,其分辨率、格式、颜色模式等不可能完全统一)。
2.方法性能测试
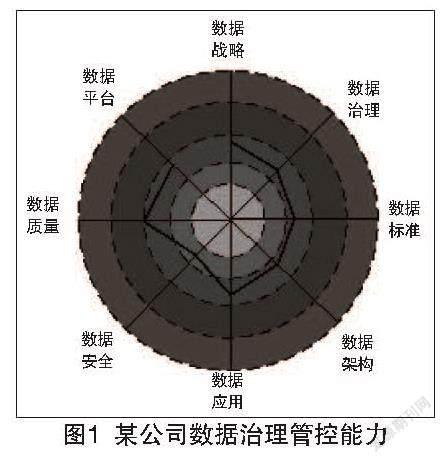
大数据的可视化呈现是基于平台中所有相关企业的业务数据构建的。由于原始数据采用的是多类型数据库系统,且业务数据一般分散存储在不同的服务器上,因此首先需要将数据集成,把分散的企业数据从分布式数据库集成到Hadoop集群中,从而完成初始数据收集。基于初始提供数据的结构以关系型数据库为主,需利用迁移工具Sqoop将数据从关系型数据库迁移至Hadoop的HDFS存储器上,进而再将其加载到便于检索、查询的Hive数据库。然后利用HQL语句对数据进行查询分析,并将查询结果存入HBase数据库。接下来将相应的查询结果与可视化的设计主题相结合,构造对应的可视化模型,并将模型以固定形式存入HBase,最后使用Echarts可视化插件对分析模型进行图形可视化呈现。为了验证本文所设计的基于Hadoop与Spark大数据平台的数据治理管控方法在实际应用中的性能,选择某公司的运营数据作为测试案例,将本文数据治理管控方法应用在该案例上,对该测试案例的数据质量管理能力情况如图1所示。
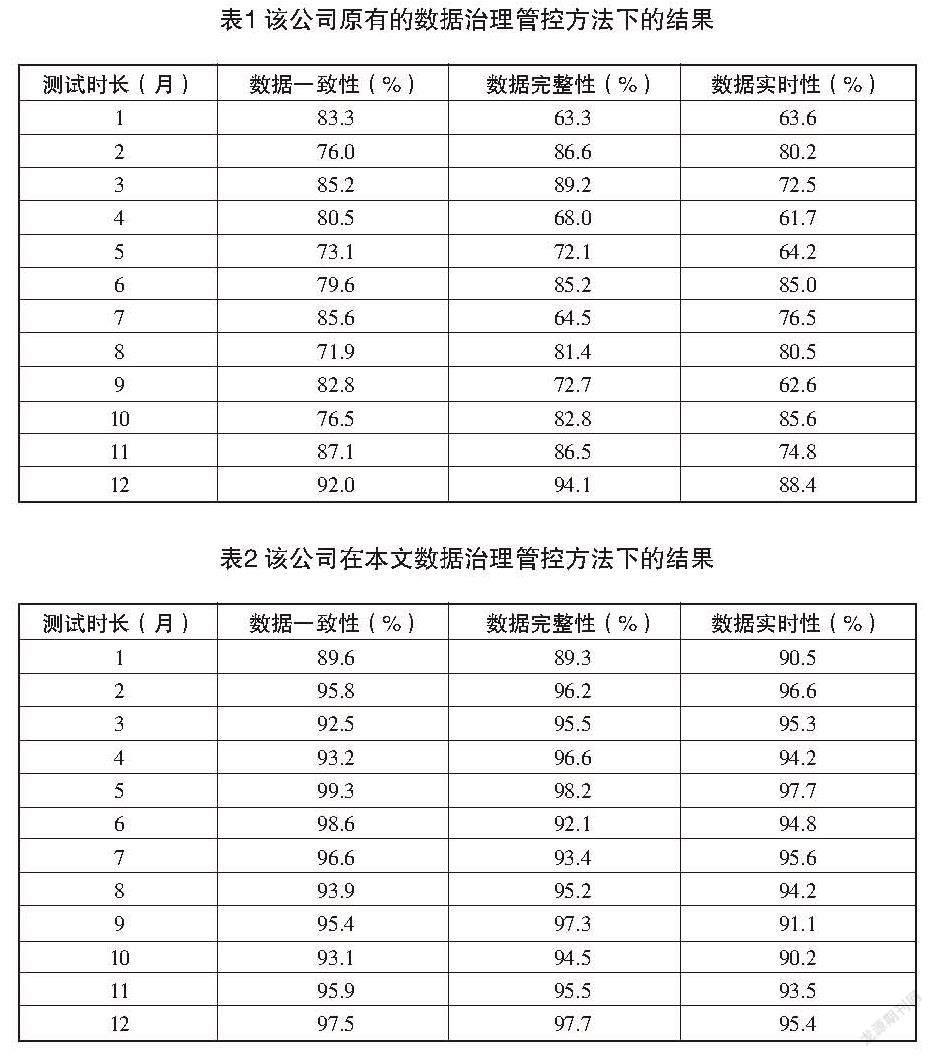
从图1可以看出,该公司对于运营数据的治理管控存在一定的问题,管理级别方面的评分较低,需要进一步在数据标准与数据质量方面进行优化、治理与管控。通过加强对公司主营范围内的业务数据以及指标数据的完善,在此基础上,使用本文设计的基于Hadoop与Spark大数据平台的数据治理管控方法和该公司原有的数据治理管控方式对数据进行治理。实验时间为12个月,对比在不同数据治理管控方法下,该公司的数据一致性、完整性和实时性。该公司原有的数据治理管控结果如表1所示。
在使用本文设计的基于Hadoop与Spark大数据平台的数据治理管控方法下,该公司的数据治理管控结果如表2所示。
分析表1和表2中的数据,可以看出,与该公司采用原有的数据治理管控方法的结果相比,在使用本文所设计的数据治理管控方法下,一年之内的数据质量均有不同程度的上升。在数据一致性中,本文方法比原有的方法提升了5.5%,数据完整性提升了3.6%,数据实时性提升了7%。由此可以看出,在使用本文设计的基于Hadoop与Spark大数据平台的数据治理管控方法下,该公司的运营数据质量有一定程度的提升。
结语
综上所述,本文针对目前数据治理管控方法存在的缺点,从实际的应用过程出发,考虑Hadoop与Spark大数据平台为数据治理能够提供的便利条件,来应对数据治理在当下的困难局面。本文从元数据管理、并行计算框架的设计以及数据多维度治理方面,对数据治理管控方法进行了设计和优化,并通过性能测试验证了本文方法的有效性。
参考文献:
[1]张黎平,段淑萍,俞占仓.基于Hadoop的大数据处理平台设计与实现[J].电子测试,2022,36(20):74-75,83.
[2]郭海波,宋达,高翔宇,等.基于EdgeX的舰艇大数据处理平台架构[J].舰船科学技术,2021,43(17):170-173.
[3]张海峰,魏可欣.一种基于Spark大数据处理平台的查询方法[J].南京邮电大学学报(自然科学版),2021,41(4):82-90.
[4]李涛.Spark平台下电力监测大数据并行处理与模型的跨平台迁移[D].华北电力大学,2021.
[5]李宁伟.大数据处理平台Hadoop攻击和检测技术研究[D].南京航空航天大学,2021.
作者简介:朱毓,在职硕士研究生,讲师,研究方向:计算机应用。
基金项目:安徽省高校自然科学研究重点项目——基于BPF面向容器网络模型研究与优化(编号:KJ2021A1467)。
