轻量级词典协同记忆聚焦处理的Web攻击检测研究
2023-04-11刘拥民石婷婷欧阳金怡刘翰林谢铁强
刘拥民,黄 浩,石婷婷,欧阳金怡,刘翰林,谢铁强
(1.中南林业科技大学 计算机与信息工程学院, 长沙 410004;2.中南林业科技大学 智慧林业云研究中心, 长沙 410004)
Web技术已成为当前互联网最热门的应用架构之一,但却经常受到恶意攻击。严重的网络攻击会带来灾难性的数据泄露和丢失,因此为Web应用程序建立入侵检测机制十分重要。Web应用程序基于HTTP协议进行数据传输,攻击者常常构造恶意HTTP请求发起攻击,使Web应用程序承担各种安全风险[1],如SQL注入和跨站脚本攻击(cross-site scripting,CSS),因此针对HTTP文本进行Web攻击检测是非常有效的手段。
防火墙、入侵检测系统、Web应用防火墙等安全产品中广泛应用的检测方法是特征匹配。特征匹配[2-3]方法可精准地检测出已知特征的攻击,但却不能检测未知特征的攻击。当前日益复杂的网络环境及人工智能技术的发展使得研究重点转向了能检测未知攻击的算法。如支持向量机[4]、决策树[5]、随机森林[6]、K-means[7]等机器学习方法。这类方法虽具有泛化能力,能检测未知特征攻击,但需要人工选择特征,并且人工选取的特征类型对检测的准确率影响巨大。而使用深度学习方法可以避免人工选择特征,因此有研究者们使用深度学习方法[8-9]自动提取特征检测攻击。深度学习方法首先会使用词典将HTTP文本非结构化数据转为结构化数据,但由于HTTP文本具有单词可自定义特点,生成的词典过大,导致深度学习模型参数增多。故大多研究者为了减小词典单词量,只提取HTTP的部分数据如URL[10]作为输入,但这种方式会导致样本失真,丢失部分攻击载荷。此外,HTTP文本具有攻击载荷位置不定性以及载荷语义复杂性,从而致使漏报率高,因此采用聚焦处理技术来分析攻击载荷也就成为了当前的研究热点之一。
为解决深度学习模型参数过载和漏报攻击载荷的问题,提出将词典轻量化,基于轻量级词典预处理HTTP文本,减小深度学习模型的参数量;协同记忆聚焦处理模型定位攻击载荷,处理攻击载荷的复杂语义,以此提高Web攻击检测的准确率,减小漏报率。
1 相关研究
研究者们采用Web流量统计特征和HTTP请求文本作为输入数据检测Web攻击。如Kim等[11]使用Web流量的统计特征作为输入数据。Xie等[12]使用包层次统计特征和流层次统计特征两者作为输入数据。更多研究者们使用HTTP请求文本,对其采用了不同的预处理方式。如Sahingoz等[13]使用HTTP文本的URL作为输入数据,直接对URL进行关键词检测而直接生成特征,使用该特征输入至分类模型。Cheng等[14]提出的Web异常检测方法,也使用了URL作为输入数据,其方法中使用了一种改进的特征提取方法,利用了URL语义结构的优势,用来识别URL中每个部分的功能和漏洞。Tekerek[15]选择的输入数据是HTTP中的URL和payload,分割URL和payload的变量和值生成词典,使用词典将输入数据转化为矩阵,使用该矩阵训练模型。Liu等[16]选择HTTP的访问路径和访问参数作为输入数据,并进行参数特征检测和数据归一化。
目前检测Web攻击使用的深度学习模型有卷积神经网络(convolutional neural network,CNN)、循环神经网络(recurrent neural network,RNN)、混合神经网络等。Tekerek[15]使用CNN来检测Web攻击,他将输入数据预处理成一个数值矩阵,用CNN分析计算此矩阵得到检测结果。JEMAL等[17]探索和评估用于Web应用程序安全的深度学习技术,通过实验分析了影响CNN检测网络攻击的不同因素。Yang等[18]提出了一种基于关键字的卷积门控递归单元神经网络用于检测恶意URL,使用GRU代替原来的池化层对时间维进行特征获取,得到了高精度的多类别结果。除基于GRU的循环神经网络外,还有基于LSTM的循环神经网络方法,如Song等[19]提出了一种基于双向LSTM的模型用于XSS、CSRF等恶意攻击。Vartouni等[20]在他们的Web应用防火墙方法中提出了基于深度神经网络和并行特征融合的方法,采用堆叠自编码器和深度信念网络的混合模型进行特征提取,用支持向量机、随机森林等作为分类器来检测Web攻击。此外,Tekerek等[21]使用了基于特征的检测和基于异常的检测的混合模型来防止网络攻击,方法中基于异常的检测模型是使用人工神经网络来实现的。
上述方法多为避免词典过大导致模型参数过载,仅采用HTTP文本的部分数据作为输入,这会导致样本失真进而带来攻击载荷漏检。加上Web攻击载荷位置具有不确定性,部分攻击载荷被遗漏,漏报率升高。本文中使用完整HTTP文本作输入数据,避免遗漏攻击载荷,轻量化词典减小模型参数量。此外,由于Web攻击载荷语义复杂多变,模型仅分析文本整体语义不足以提高检测率。受到注意力机制应用在入侵检测[22]上的启发,构建基于多头注意力机制[23]的记忆聚焦处理模型,定位攻击载荷并聚焦分析复杂语义,提高准确率,减小漏报率。
2 Web攻击检测方法
Web攻击检测方法框架包含预处理器和分类器。预处理器由轻量级词典和基于轻量级词典的预处理方式实现,分类器由记忆聚焦处理模型实现。该方法的总体框架如图1所示。

图1 Web攻击检测方法框架
从时间序列上来看,Web攻击检测方法可以分成2个阶段:训练阶段和检测阶段。
训练阶段可在任意一台服务器上运行。首先初始化并持久化保存轻量级词典,同时初始化记忆聚焦处理模型参数。预处理器基于轻量级词典、预处理规则及预处理算法将HTTP文本转为结构化数据传入分类器。分类器调用记忆聚焦处理模型将数据转为词嵌入矩阵,分别作记忆分析与聚焦处理,再融合计算两模块的信息得出预测向量,并结合损失函数反向传播更新模型参数。训练结束后持久化保存模型参数。
检测阶段将预处理器和分类器部署在Web应用防火墙上用于在线检测。部署后预处理器载入轻量级词典,分类器载入记忆聚焦模型参数,进入Web攻击在线检测过程。Web中传输的HTTP未知样本可经由预处理器和分类器计算得预测向量,由argmax函数计算攻击类型,输出样本的攻击类型。
2.1 轻量级词典
轻量级词典由数据集数据和内置数据生成,主要组成部分为占位符、特殊字符、通用高频词典、专家词典以及数据集高频词典。其中占位符共有5个,分别为_PH_、_NL_、_DS_、_AS_、_MS_,代表占位、换行、纯数字串、纯字母串、混合串5种意义,并且在词典中的索引指定为0、1、2、3、4。特殊字符是Web中经常使用的标点符号,在词典中的索引紧跟占位符后。通用高频单词由Web中经常使用的非语法关键词构成。专家词典是由各编程语言、标记语言、结构化查询语言中经常被用来攻击的语法关键词构成。此外,为了轻量化词典,将数据集中的随机字符串、cookie值等无意义低频单词去除,生成数据集高频单词。轻量级词典如表1所示。

表1 轻量级词典
2.2 基于轻量级词典的预处理
在将HTTP文本输入检测模型前,要先对文本进行预处理,将非结构化数据转为结构化数据。基于轻量级词典配合预处理规则,可先将HTTP文本转为通用格式文本,再将通用格式文本中各单词替换为轻量级词典中相应的单词索引,可得到整数编码向量,用于输入检测模型。将HTTP文本转为通用格式文本的预处理规则如下:
规则1单词属于轻量级词典,并且单词在句子中的位置小于通用格式文本指定长度,保留单词。
规则2单词是换行符,并且单词在句子中的位置小于通用格式文本指定长度,替换为_NL_。
规则3单词完全由数字0~9组成,并且单词在句子中的位置小于通用格式文本指定长度,替换为_DS_。
规则4单词完全由字母a~z组成,并且单词在句子中的位置小于通用格式文本指定长度,替换为_AS_。
规则5单词由字母a~z、数字0~9和其他字符混合组成, 并且单词在句子中的位置小于通用格式文本指定长度,替换为_MS_。
规则6句子长度小于通用格式文本指定长度,添加_PH_。
规则7句子长度大于通用格式文本指定长度,丢弃多余单词。
预处理过程的伪代码描述如算法1所示。在执行预处理规则之前要先解码HTTP文本中的URL编码,并依照轻量级词典中的特殊字符对HTTP文本进行分词处理得到单词列表。然后初始化一条空的通用格式文本列表,对单词列表中的单词逐一处理后填入通用格式文本列表中。最后将通用格式文本列表中的单词替换为索引,返回整数编码向量。
算法1基于轻量级词典的预处理算法
Input: (R,n,V,S)
Output: (Q)
R← urldecode(R); //解码R中的URL编码
W[] ← split(R,S); //S作分隔符分割出单词列表
Q[] ← initialize_length(n); //初始化列表Q长度为n
fori=0 tondo //逐单词进行预处理
ifi>= length(W) do
Q[i] ← “_PH_”
continue;
end if
word← tolower(W[i]);
ifwordinVdo
Q[i]←V[word];
else ifwordis newline symbol do
Q[i]← “_NL_”;
else ifwordis number do
Q[i]← “_DS_”;
else ifwordis pure letter string do
Q[i]← “_AS_”;
elsewordis mixed string do
Q[i]← “_MS_”;
end if
end for
foritondo //通用格式文本转为整数编码向量
Q[i]←V[Q[i]];
end for
returnQ; //返回整数编码向量
其中:R为HTTP请求文本字符串;n为通用格式文本的长度;D为轻量化词典,键为单词,值为单词索引;S为分隔符列表,元素为轻量级词典中的特殊字符;Q为整数编码向量。
预处理一条样本的样例如下:
1) 含URL编码的SQL注入攻击样本
GET http://localhost:8080/tienda1/publico/vaciar.jsp?B2=Vaciar+carrito%27%3B+DROP+TABLE+usuarios%3B+SELECT+*+FROM+datos+WHERE+nombre+LIKE+%27%25 HTTP/1.1
User-Agent:Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.8 (like Gecko)
…
Cookie:JSESSIONID=BDF1F164FC252B1351
B09758629AEE54
Connection:close
2) 预处理后生成的通用格式文本
get http://localhost:_DS_ /tienda1 /publico /vaciar.jsp ? b2=vaciar+carrito′;+drop+table+usuarios ;+select+*+from+datos+where+nombre+like+′% http /_DS_._DS_ _NL_ user-agent:… cookie:jsessionid=_MS_ _NL_ connection:close
3) 预处理后生成结构化数据整数编码向量
[89,74,31,15,15,46,31,2,15,88,15,90,15,135,14,39,35,153,7,135,27,125,12,11,27,258,27,261,27,262,11,27,264,27,23,27,238,27,265,27,266,27,91,27,95,27,12,20,74,15,2,14,2,1,77,6,…,115,31,47,0,0,0,…,0,0,0,0,0,0]
2.3 记忆聚焦处理模型
如图1所示,分类器的具体实现为记忆聚焦处理模型,包含4个模块:嵌入矩阵、记忆分析模块、聚焦处理模块和融合计算模块。嵌入矩阵将整数编码向量转为嵌入向量矩阵,嵌入向量矩阵经过记忆分析模块与聚焦处理模块分别处理后由融合计算模块输出预测向量。
嵌入矩阵E的维度为D×N,其中D是词嵌入向量的维度,N是词典的单词量大小。假设一个整数编码向量所对应的one-hot词向量矩阵为Q,Q的维度为N×n,其中n为整数编码向量的长度。可由式(1)计算出其对应的词嵌入向量矩阵X,维度为D×n。
X=E·Q
(1)
记忆分析模块增强模型的信息记忆能力,加强模型对数据宏观上的分析能力。此模块由多个BiLSTM和一个全连接层串联而成。LSTM是递归神经网络的一种,LSTM由细胞状态和遗忘门、输入门和输出门组成,计算公式如式(2)—(7)所示,其中的WC、Wf、Wi、Wo分别为细胞状态、遗忘门、输入门和输出门的权重矩阵;bC、bf、bi、bo为细胞单元和各门控单元的偏置项;σ为sigmoid函数;tanh为双曲正切函数。遗忘门计算的公式为:
ft=σ(Wf·[ht-1,xt]+bf)
(2)
式中:ht-1为前一时刻的隐层状态;xt为当前输入词。输入门it计算公式为:
it=σ(Wi·[ht-1,xt]+bi)
(3)
(4)
当前时刻细胞状态Ct计算公式为:
(5)
输出门和当前时刻隐层状态计算公式为:
ot=σ(Wo·[ht-1,xt]+bo)
(6)
ht=ot*tanh(Ct)
(7)
通过计算最终能够得到与句子长度相同的隐层状态序列[h0,h1,…,hn-1]。
因HTTP文本中包含程序代码,为更精确地分析函数定义和调用行为信息,采用BiLSTM进行记忆和分析。BiLSTM拼接前向隐含状态h=[h0,h1,…,hn-1]和后向隐含状态h′=[h0′,h1′,…,hn-1′]整合得H。前方的BiLSTM模块使用下式进行隐含状态融合:
H={[h0,h0′],[h1,h1′],…,[hn-1,hn-1′]}
(8)
而最后的BiLSTM模块的隐含状态融合公式为:
H=[hn-1,h0′]
(9)
记忆分析模块全连接输出层的计算公式为:
OM=ReLU(WBi·H+bBi)
(10)
式中:OM为记忆分析模块的输出向量;WBi为记忆分析模块全连接输出层的权重;bBi为记忆分析模块全连接输出层的偏置项;ReLU为线性整流函数。
聚焦处理模块增强模型的聚焦处理能力,使模型注意力集中至攻击载荷,致力于分析复杂语义。聚焦处理模块参考Transformer的Encoder结构[16],由多个多头注意力层、1个卷积降维(convolution dimension reduction,CDR)层和1个全连接层组成。多头注意力层包含多头注意力子层和全连接前馈网络子层,每个子层周围都使用一个残差连接和Dropout层,再执行层归一化,每个子层的输出为LayerNorm(x+Dropout(Sublayer(x))。其中Sublayer(x)是子层实现的函数本身,每个子层产生的维度dmodel。其中多头注意力子层有3个输入Q(Query)、K(key)、V(value),这些输入经过线性层,并拆分成多头。将式(11)应用到每个头,其中dk为K向量的维度。最后连接各注意力头的输出,并放入线性层。
(11)
此外,词嵌入向量矩阵X经聚焦处理模块处理前须加上位置编码PE,添加词之间的位置信息。位置编码PE的计算公式为:
PE(pos,2i)=sin(pos/10 0002i/dmodel)
(12)
PE(pos,2i+1)=cos(pos/10 0002i/dmodel)
(13)
式中:pos是位置,i是维数。尾端多头注意力层连接卷积降维层,特别的是此层只有1个n×1的卷积核。此卷积降维层可将n×dmodel的矩阵转成维度为dmodel的向量。卷积降维层后接全连接层得到长度与OM长度一致的向量OF。
融合计算模块负责结果的输出,通过综合决策与计算输出最终的结果。使用如下公式将OM、OF融合为向量I:
I=[α·OΜ+β·OF,OΜ,OF]
(14)
式中:α和β分别是OM和OF的融合系数,具体取值由模型在训练过程中计算得到。经过2层全连接层,由下式计算得到预测向量ypre。
ypre=softmax (W2·ReLU(W1·I+b1)+b2)
(15)
式中:W1、W2分别为全连接层的权重矩阵;b1、b2为全连接层的偏置项。最后一层的神经元个数为数据集的类型数c。
在训练阶段,分类器使用多分类交叉熵损失函数为目标函数。首先计算损失向量L:
(16)
式中:yti为符号函数,如果样本的真实类别等于i,取1,否则取0,ypi为样本属于类别i的预测概率,即ypre向量的各元素值。由下式对每一批次向量求平均得损失值Lbatch,反向传播更新模型权值,其中N为每批数据量。
(17)
而在检测阶段,前向传播计算得到预测向量ypre,用argmax函数对ypre计算得到最终的结果。
3 实验和分析
3.1 数据集
实验使用了数据集HTTP DATASET CSIC 2010[24]和Simulation Dataset。HTTP DATASET CSIC 2010是由西班牙研究委员会信息安全研究所编制的公开数据集,包括正常和异常2种类型。而Simulation Dataset是本文使用Metasploiable2 Linux靶机和Kali Linux 2021.1攻击机模拟真实环境而制作的数据集,攻击载荷位置多样化。此数据集有Normal、Injection、XSS、Data Exposure、RCE共5种类型标签。数据集随机打乱6∶2∶2比例切分生成训练集、验证集、测试集。Simulation Dataset各数据量如表2所示。

表2 Simulation Dataset
3.2 实验细节
嵌入矩阵中词嵌入向量的维度D设置为64,通用格式文本长度n设置为512。记忆分析模块有2个BiLSTM模块和1个全连接层,神经元个数设置为16,其中全连接层使用ReLU激活函数。聚焦处理模块有2个多头注意力层模块,dmodel为64,8个注意力头,全连接前馈网络子层共两层,神经元个数分别为16和64,使用ReLU激活函数。融合计算模块两层全连接层,第一层16个神经元,ReLU激活函数,第二层c个神经元,使用softmax激活函数,其中c为拟分类的数量。优化方法为Adam,设置β1=0.9,β2=0.98,ε=1×10-9,并使用了一个自定义的学习速率,自定义学习速率lr如式(18)所示,其中warmup_steps=4 000,step_num为梯度下降的步数。
step_num*warmup_steps-1.5)
(18)
对比的分类模型为FCNN、CNN、LSTM、GRU、CNN-LSTM、CNN-GRU。对比的预处理方式为2种:URL_CHAR,将URL处理成字符级向量;URL_WORD,将URL处理成单词级向量。
3.3 评价指标
采用攻击检测和深度学习领域中常用的几个评价指标进行量化分析,分别是:准确率(accuracy)、误报率(false alarm rate,FAR)、漏报率(missing alarm rate,MAR)、ROC曲线、AUC值。公式如下所示:
(19)
(20)
(21)
选择某种攻击类型为阳性,其余类型为阴性,则TP为分类阳性样本正确的数量,TN为分类阴性样本正确的数量,FP为分类阳性样本错误的数量,FN为分类阴性样本错误的数量。其中,在深度学习的评价指标中,误报率也为假阳性率(false positive rate,FPR),漏报率为假阴性率(false negative rate,FNR)。
3.4 结果及分析
使用3种不同的预处理方式来预处理Simulation Dataset,在记忆聚焦处理模型上进行检测。统计各自预处理方式生成的词典单词量、模型嵌入矩阵参数量以及检测指标,实验结果如表3所示。

表3 3种预处理方式在Simulation Dataset上的 实验结果
从结果可知,数据集经本文提出的新方法预处理,词典单词量以及模型嵌入矩阵参数量介于URL_CHAR和URL_WORD之间。本文预处理方法相对URL_WORD有效地减小了词典的单词量和模型参数量。词典单词量和模型参数量虽然没有低于URL_CHAR,但是准确率却高于URL_CHAR,且同时高于URL_WORD。这是新方法采用完整HTTP作为输入数据,不会遗漏攻击载荷,并且轻量级词典处理后也不会丢失攻击载荷的关键信息,所以能提高检测准确率。
本文针对HTTP DATASET CSIC 2010,分别使用URL_CHAR和URL_WORD这2种预处理方式进行预处理,再分别搭配7种不同的分类模型进行检测,得到14种检测方法的准确率、误报率和漏报率,以探究本文模型的有效性。实验结果如表4所示。
可知使用URL_WORD比URL_CHAR的检测准确率高,其中URL_WORD搭配本文记忆聚焦处理模型的检测准确率最高。虽误报率略高于GRU和LSTM模型,但漏报率远低于其他模型。这是因为聚焦处理模型中的多头注意力机制自动定位并分析攻击载荷,有效地降低了复杂语义攻击载荷的漏报。且双向长短时记忆模块能够提升整体记忆能力,故拥有较高的整体准确率。
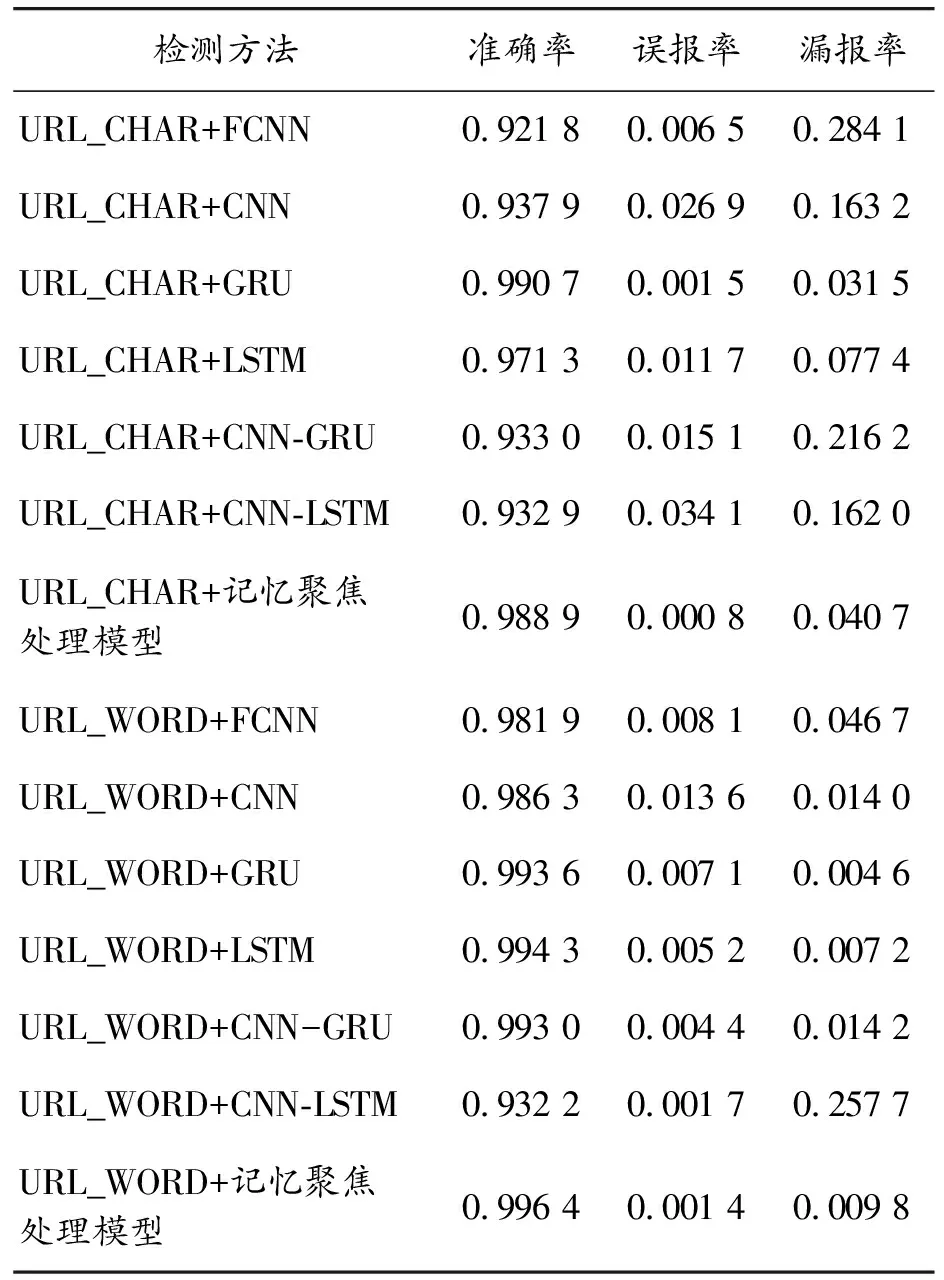
表4 14种检测方法在CSIC 2010上的实验结果
使用表4中的12种常见经典模型检测方法与本文的Web攻击检测方法在Simulation Dataset上进行检测。实验结果如表5所示。
显然在攻击载荷的位置更多样化的数据集上,本文Web攻击检测新方法的检测准确率最高,误报率和漏报率更低。对于攻击载荷不在URL上的攻击样本,采用URL作为输入数据的检测方法漏检率为100%。而本文方法输入完整HTTP文本,能够增强此类样本的检测率,但引入的大量单词可能导致模型参数过载,但经过词典轻量化后可有效减轻此问题。此外,在误报率和漏报率上,本文提出的新方法也处于领先地位。说明本文的记忆聚焦处理模型是降低漏报率的有效因素。
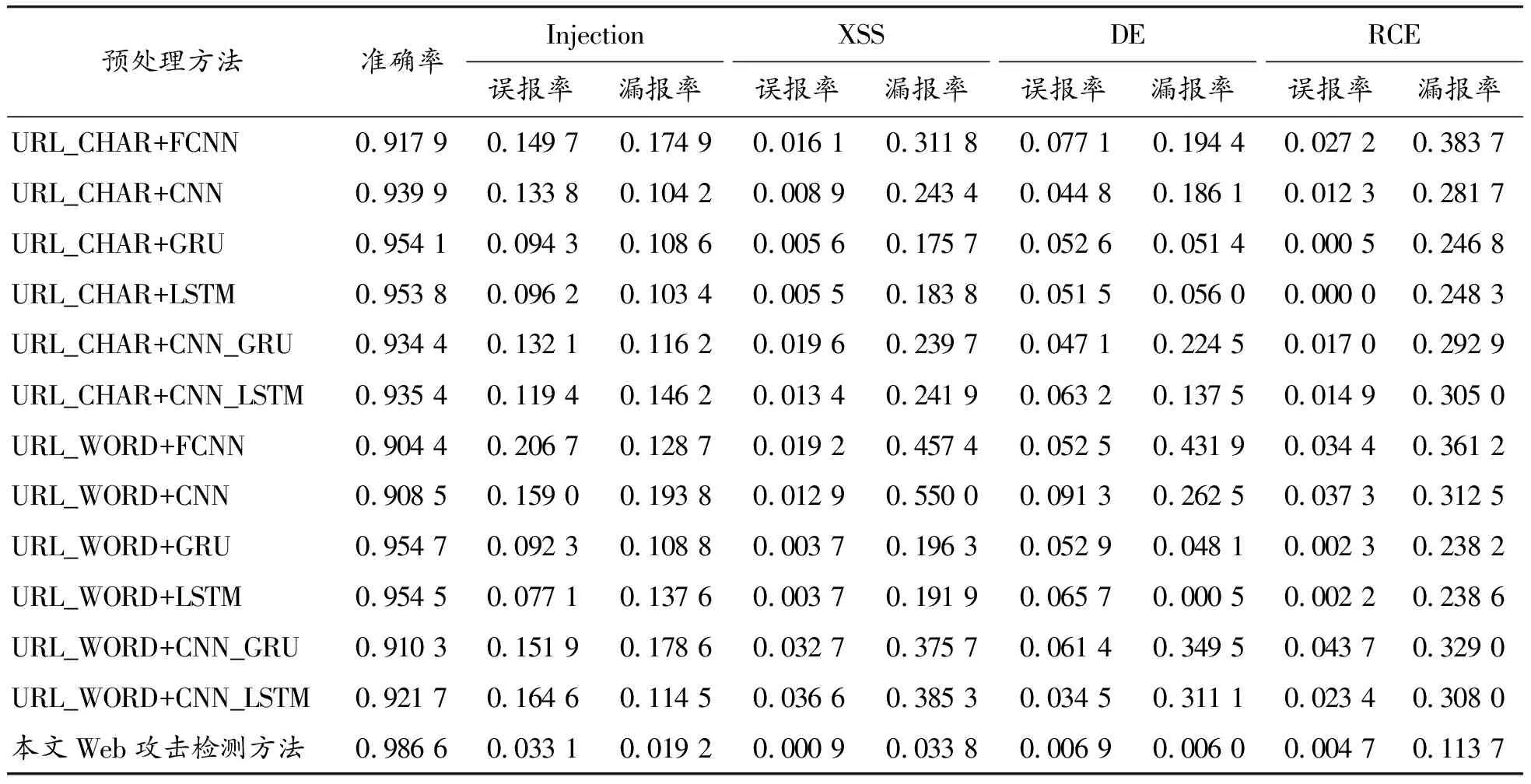
表5 本文方法与12种检测方法在Simulation Dataset上的实验结果
图2—5为实验结果的ROC曲线,分别为4种攻击类型的曲线。为了更好区分,选取绘图区间FPR∈[-0.01,0.5],TPR∈[0.5,1.01],放大整体曲线图的左上区域。

图2 Injection攻击类型ROC曲线

图4 DE攻击类型ROC曲线

图5 RCE攻击类型ROC曲线
可以看出,本文中提出的新方法ROC曲线表现最好,且AUC值相对最高,反映了新方法相比其他常见经典方法具备更好的综合性能。
为了直观查看记忆聚焦处理模型处理一条样本时的聚焦过程,使用如下所示的SQL注入样本输入至模型。
SQL注入样本:
GET/dvwa/vulnerabilities/sqli?query=query%22+UNION+ALL+select+NULL+--+ HTTP/1.1
User-Agent:Mozilla/5.0 (X11; Linux x86_64; rv:78.0) Gecko/20100101 Firefox/78.0
…
Upgrade-Insecure-Requests:1
Content-Length:0
Host:192.168.52.129
可知模型的各注意力头所聚焦的位置不尽相同,但总体上更多的注意力聚焦在了“"”“all”“null”“union”“-”等单词上。这些单词正是此条SQL注入样本的攻击载荷的组成部分,这说明记忆聚焦处理模型的多头注意力机制能够自动聚焦分析样本中的异常部分,能够更精准地分析复杂语义攻击载荷,这对减小漏报率起到了关键的作用。
使用本文Web攻击检测方法与其他12种Web攻击检测方法在2个不同的数据集上进行攻击检测实验,计算检测单条样本的时间开销。时间开销如表6所示。
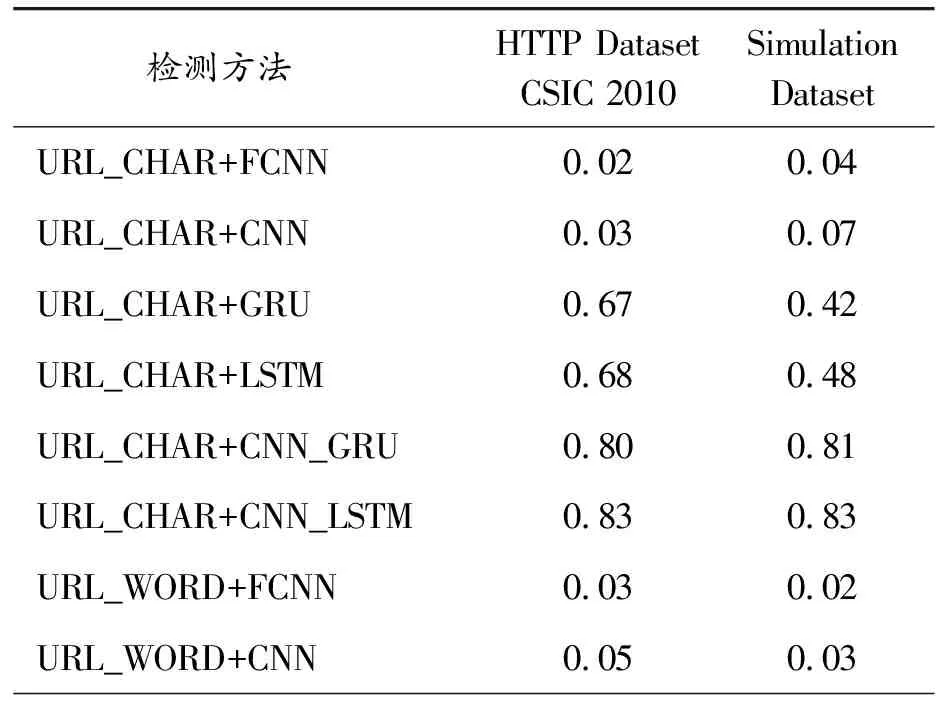
表6 检测单条样本的时间开销 ms

续表(表6)
由时间开销、检测准确率、漏报率等指标分析,可知:准确率较高的检测方法检测单条样本的时间开销也较大。故如何在保证高准确率和低漏报率的情况下降低时间开销即为下一步研究内容。
4 结论
选取完整HTTP文本作为输入数据,避免了遗漏攻击载荷;将词典进行轻量化并结合轻量级词典和预处理规则将HTTP文本处理成通用格式文本后,再转为整数编码向量,有效减轻了模型参数过载;同时为聚焦分析攻击载荷的复杂语义信息,进而构建基于双向长短时记忆和多头注意力机制相结合的记忆聚焦处理模型。利用模型记忆分析长序列文本和聚焦处理分析攻击载荷,降低了漏报率。实验结果表明,新提出的Web攻击检测方法能有效提升检测准确率和减小漏报率,且能大量缩小词典单词量,并减轻模型参数过载。未来将尝试采用轻量化模型以降低时间开销,确保漏报率尽可能低,进一步降低误报率。
