基于改进灰狼优化的文本聚类多阶段特征选择算法
2023-04-07刘泓铄王诗瑶周灵鸽张建锋
刘泓铄 王诗瑶 周灵鸽 张建锋
(西北农林科技大学信息工程学院 陕西 杨凌 712100)
0 引 言
文本聚类是大数据分析的重要手段,广泛应用于主题划分、网络舆情分析、经济预测和情感分析等领域[1]。文本聚类的效果与文本特征选择结果密切相关。而通常预处理后的初始文本特征集合具有高维度和稀疏性特点,因此,如何对文本进行特征选择和特征提取,降低特征维度和移除冗余特征,得到最优特征子集成为直接关系文本聚类效果的关键问题[2]。
目前,文本特征选择主要有三类方法:过滤法、封装法和混合法。过滤法是一种统计分析方法,与具体分类算法无关,主要根据某一种数据特性对所选特征进行排序,判断特征优劣,筛选特征子集。常用过滤法包括:文档频率法DF[3]、卡方检测法CHI[4]、信息增益法IG[5]和互信息法MI[6]。过滤法简单易行,计算效率也较高,但经过文本聚类后其特征选择精度较差,特征冗余较多,直接影响了聚类效果。主要体现在:DF可能删除信息量较大但出现频率较低的词,CHI仅关注词条是否出现但忽略了词频,IG仅考虑词条在文本集中的影响,而忽略是否具有分类信息,MI则较多关注频词。总体而言,过滤法综合性能欠佳。比较过滤法,封装法将特征空间与分类算法密切关联,考虑了特征相互关联,能有效剔除冗余特征,提高聚类准确度。不足在于计算效率低于过滤法。该类方法通常借用智能群体算法提高特征选取时的搜索效率,如:遗传算法[7-8]、粒子群算法[9-10]、和声搜索算法[11-12]、差分进化算法[13]、蛙跳算法[14]、萤火虫算法[15]、蚁群算法[16]和猫群算法[17]等。文献[7]首先利用词频/逆文档频计算词条权重,然后利用传统遗传算法进行文本特征选择,不仅保证了文本分类准确度,还降低了特征维度。文献[8]根据词条权重性因子设计了基于遗传算法的特征选择算法GAFS,以计算时间最小、性能最大为目标优化特征子集选择,并用邮件文本测试了性能。文献[9]通过小生境改进了传统粒子群算法,以增强的粒子搜索性能对文本特征选择进行进化求解,获得的文本分类效率得到有效提升。文献[10]提出一种新的基于粒子群优化的特征选择算法PSO-TC。算法利用新的动态惯性权重策略对粒子进化操作进行改进,而最终的三类文本数据集的测试也证明在新的特征选择策略下生成的聚类在准确度和效率上均有一定改进。文献[11]通过改进和声搜索过程设计了一种自适应特征选择算法,算法利用三种动态策略,包括音调调整、限制特征域和内存合并率改善传统和声搜索过程。最后在多维度数据集的测试下验证算法在选择最优特征子集上的有效性。文献[12]利用传统过滤法对特征进行初选,然后输入至二进制和声搜索算法中对特征优选,证实分类准确率得到了提高。文献[13]首先联合平均中位值和词条方差建立相关特征子集,然后在该特征子集上利用改进差分进化算法对特征进行二次精选,增强了特征子集的扰动性和收敛速度。文献[14]通过信息增益和卡方检测对初始特征初选,然后引入改进蛙跳算法建立二次特征优选模型,有效排除了噪声特征干扰。文献[15]首先根据文本特征的信息增益值对所有特征降序排列,然后优选排序前列的特征作为萤火虫算法的初始种群,并利用萤火虫的捕食过程对特征做进一步选择,效果明显好于单纯信息增益法和萤火虫算法。文献[16]设计了基于蚁群算法的文本特征选择算法,有效实现了特征降维。文献[17]通过修正的猫群算法设计了文本分类下的特征选择算法。实验结果也证实利用猫群算法后的聚类明显优于仅使用词条频率下的聚类效果。显然,传统的特征选择更多依赖于特征对于后续分类的贡献度,贡献度越大,越有可能被选择为有用特征。然而,特征词之间的联系是相对复杂的,这样得到的特征词的聚类效果肯定存在很多偏差。而在过滤生成特征子集初始解后,再引入智能群体算法对特征子集做进一步评估和提取,将可以提高聚类效率和降低特征维度。灰狼优化算法GWO[18]是一种新型的智能群体算法,其模型更为简单、参数依赖较少且寻优性能好,研究表明它的寻优性能要明显优于以上遗传算法、粒子群算法、差分进化算法和蚁群算法等,近年来得到广泛研究认可。本文将设计一种多阶段的特征选择与特征提取算法,在融合不同相关性特征分值计算方式的基础上,先对文本特征进行初选;然后基于余弦相似度对特征进行冗余剔除;在此基础上,引入改进二进制灰狼优化算法对上一步的特征子集作特征精炼,得到最优特征子集。在多个文本数据集的测试下,验证了本文算法的性能优势。
1 文本特征模型
令集合D包含m个文档,表示为D={d1,d2,…,di,…,dm},di表示D中的第i个文档,m表示集合中的文档总量。将预处理后的文档i表示为向量di={wi,1,wi,2,…,wi,j,…,wi,n},n表示特征数量。利用词频逆文本频率指数TF-IDF计算文本特征权重,wi,j表示文档i中特征j的权重,且:
wi,j=TF(i,j)×IDF(i,j)
(1)
其中:
(2)
式中:TF(i,j)表示文档i中特征j的频率;z(i,j)表示特征j在文档i中出现的次数,分母表示文档i中所有特征的出现次数总和;IDF(i,j)为文档频率倒数;m表示文档集合中的文档总量;DF(j)表示出现特征j的文档数量,加1可确保分母不为0。
计算特征权重后,文本文档集合D中的每个文档di(i=1,2,…,m)可表示为其所有特征的向量di={wi,1,wi,2,…,wi,j,…,wi,n}。而含有n个特征的文本集合D则可表达以下的向量空间模型:
2 特征选择与特征融合
获取初始特征集合后,需要对特征过滤,得到相关度高的特征子集。引用两种方法计算特征相关性分值:平均绝对差MAD和平均中位数MM。MAD可以较准确地表征特征对文档的类别区分能力,所选择的特征具有更好的类别信息。MM则相对可以选择具有相关性的特征。结合两种特征选择方法计算特征相关性分值,可以实现特征选择的优势互补,更准确地得到相关特征子集。
MAD是词条方差TV的简化形式,通过计算样本与均值之差为特征分配相关性分值。特征j的平均绝对值定义为:
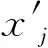
(6)
MM是倾斜率的简化形式,通过计算均值与中位数间的绝对差为特征分配相关性分值。特征j的平均绝对值定义为:
式中:median(xj)表示特征j的权重值的中位数。
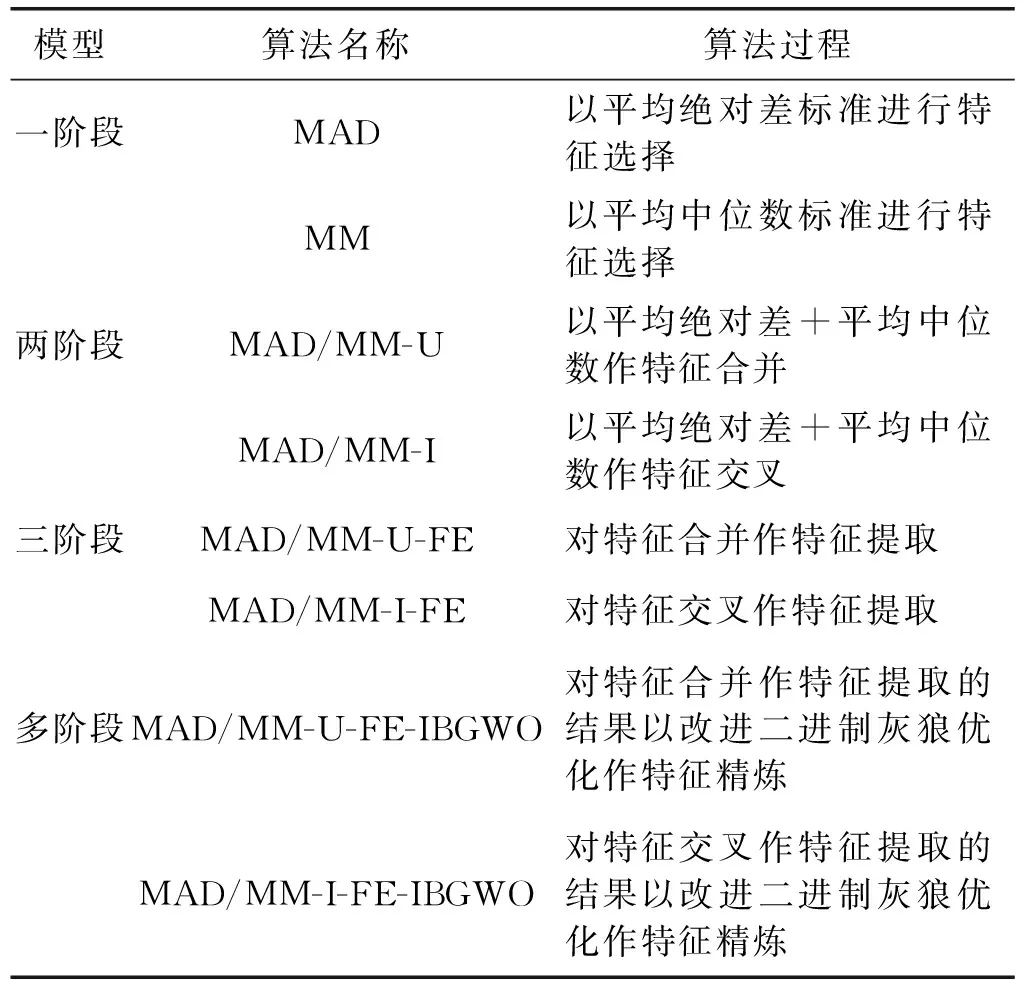
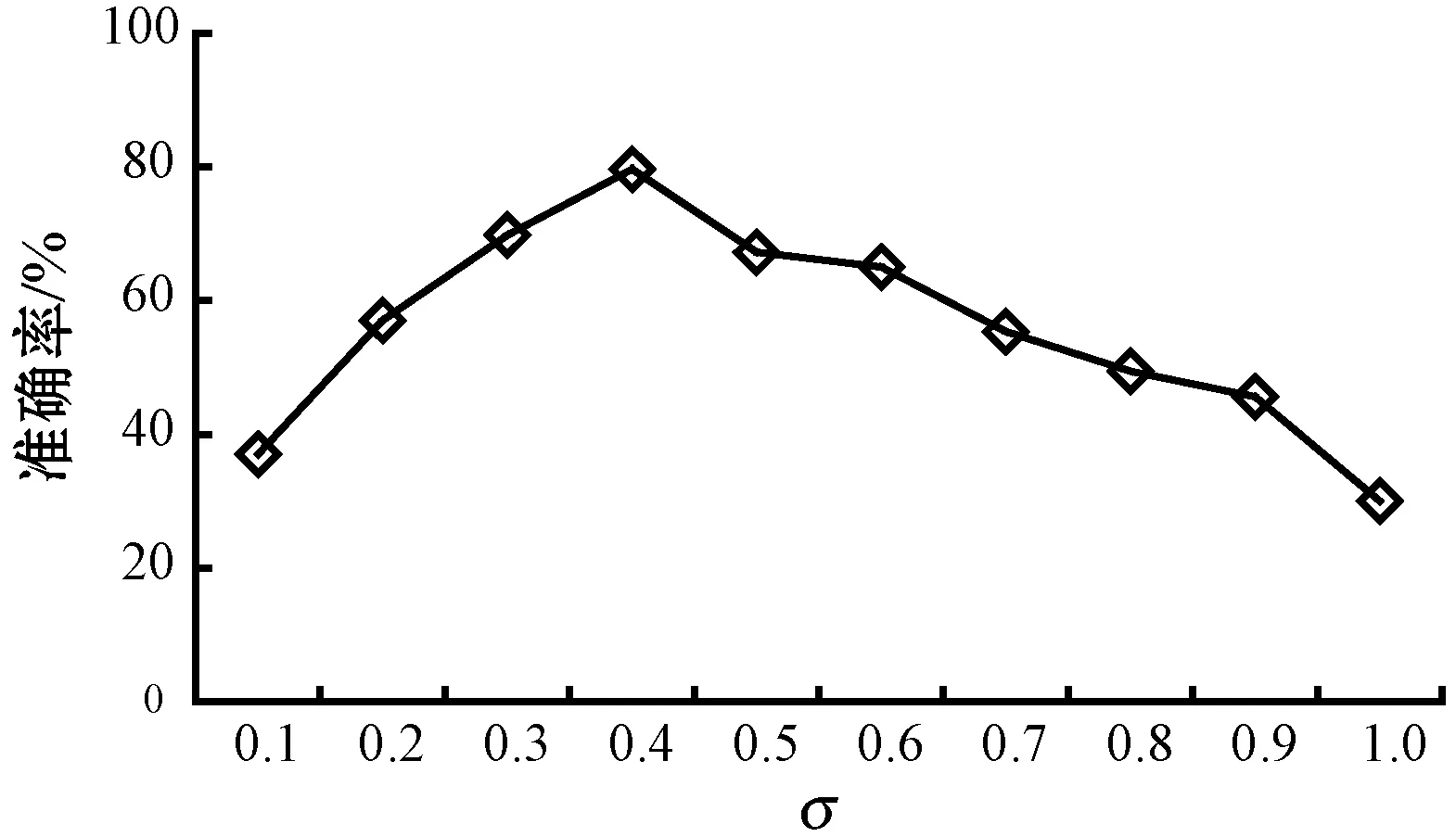
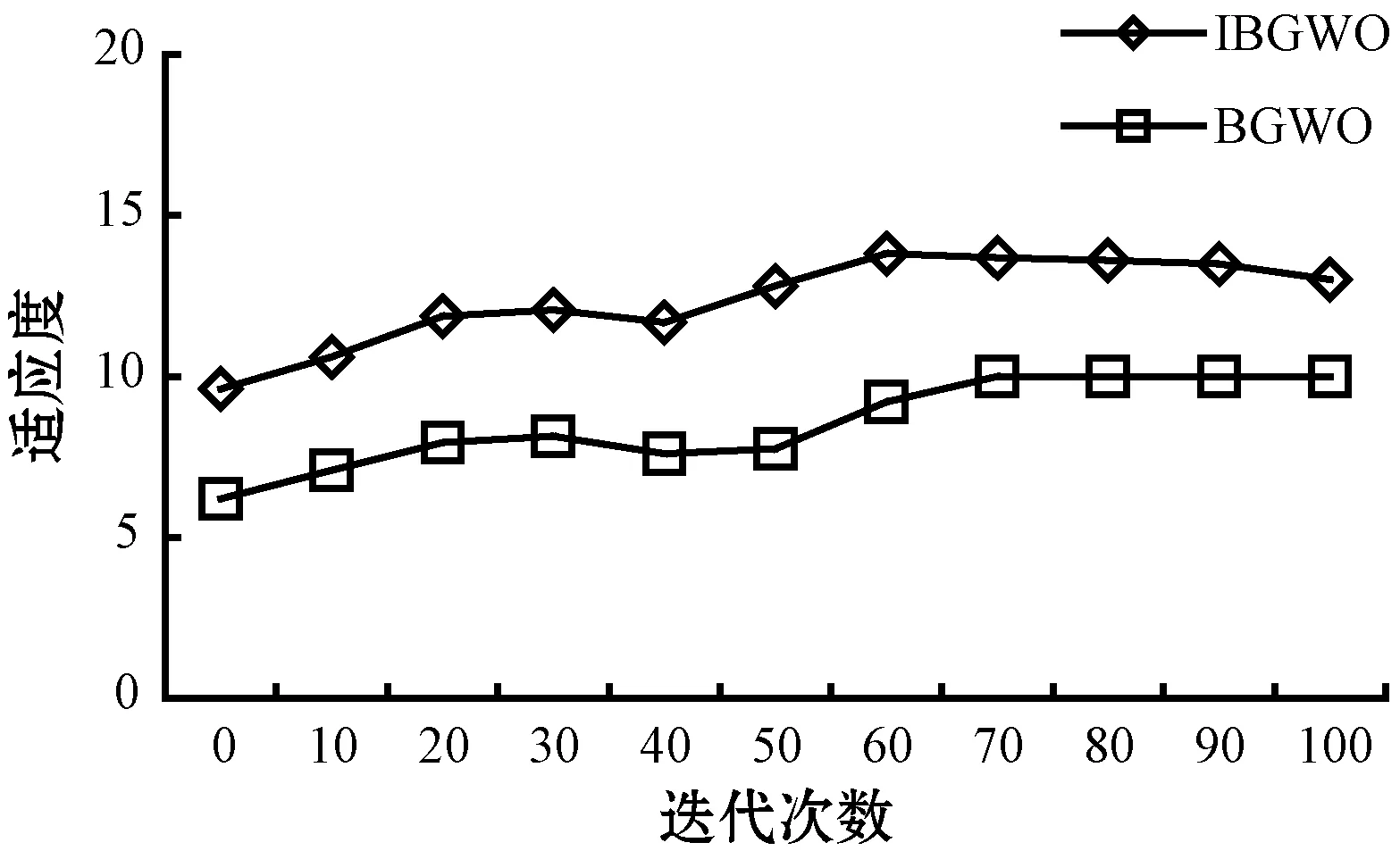
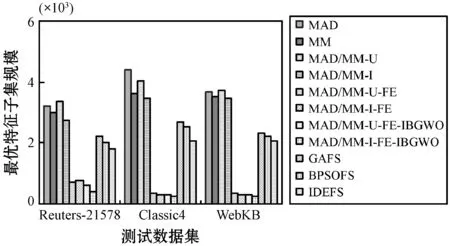
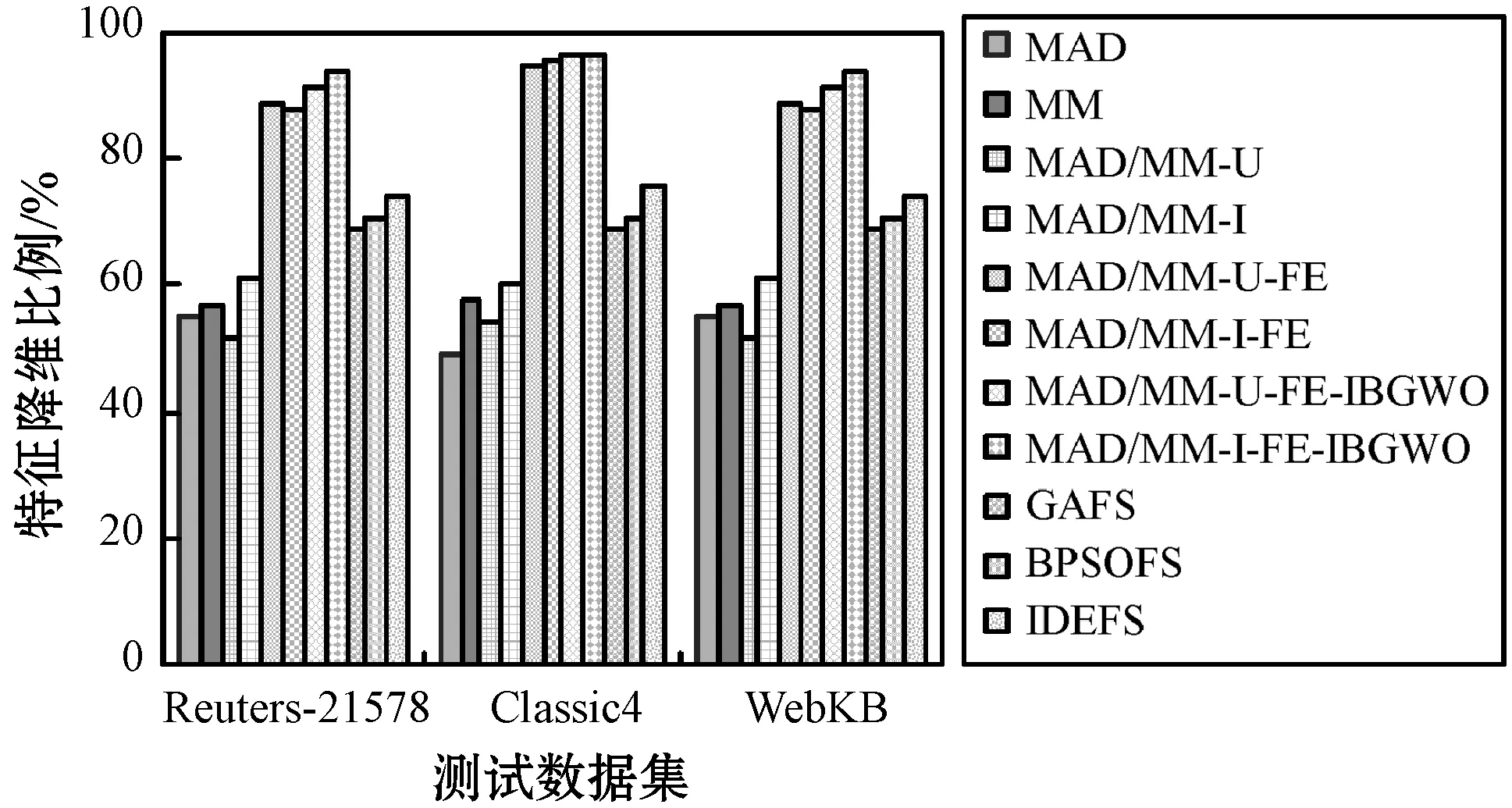
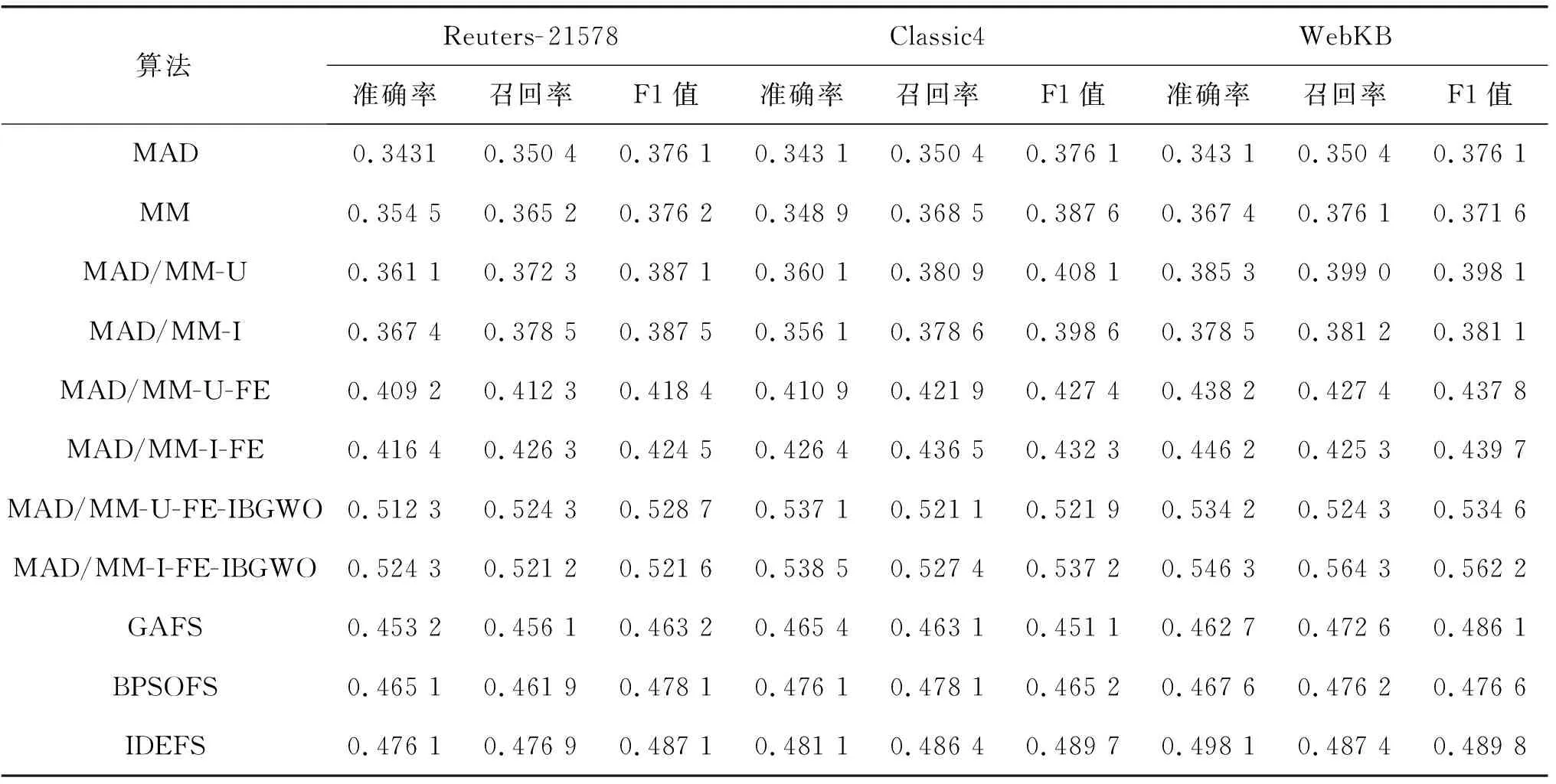
为了实现MAD和MM两种特征相关性分值计算方法的优势,提出将两种方法的特征选择子集进行融合。D为文本文档集合,经过预处理步骤后,得到特征集合T,令T={t1,t2,…,tn}代表预处理后的特征集合。利用MAD计算集合T中每个特征的相关性分值,并对特征按照相关性分值作降序排列,选择前q个为MAD生成的特征候选子集,表示为FSMAD={t11,t12,…,tq},显然,q< 利用特征合并U建立新特征子集FSU,即合并特征子集FSMAD和FSMM,表示为: FSU=FSMAD∪FSMM (8) 令特征子集FSU包含U个特征,则U≥q和p。 利用特征交叉I建立新的特征子集FSI,即交叉特征子集FSMAD和FSMM,表示为: FSI=FSMAD∩FSMM (9) 令特征子集FSI包含I个特征,则I≤q和p。 令n′表示特征选择后的特征子集长度。 算法1说明:步骤1首先根据MAD或MM(式(5)或式(7))计算每个特征的相关性分值,然后在步骤2根据相关性分值对特征作降序排列。步骤3将两个参数初始为0,CR用于记录特征相关性分值的累计值,sum用于记录所有特征的相关性分值之和。步骤4-步骤6计算当前所有特征的相关性分值之和。步骤7-步骤14则用于依次判断是否每个特征会被选入特征子集中,其中:步骤8计算更新CR,步骤9判断CR是否小于等于阈值,若满足,则在步骤10将该特征加入最后的所选特征子集中;否则,在步骤12退出。遍历完所有排序后的特征后,步骤15可以根据两种不同的特征相关性分值计算方法进行特征子集的合并和交叉。最终,步骤16返回维度为n′的不同方式生成的相关性特征子集。 算法1特征选择与特征融合 输入:文档数量m,初始特征数量n,阈值Threshold1。 输出:FSMAD,FSMM,FSU,FSI,特征子集(特征数为n′)。 1.计算每个特征的相关性分值Relj; 2.按相关分值对特征作降序排列; 3.CR=0,sum=0; 4.forj=1 tondo 6.endfor 7.forj=1 tondo 8.CR=CR+Relj/sum; 9.ifCR≤Threshold1then 10.FSMAD/MM=FSMAD/MM+FRElj; 11.else 12.break; 13.endif 14.endfor 15.FSU=FSMAD∪FSMM,FSI=FSMAD∩FSMM; 16.returnFSMAD,FSMM,FSU,FSI,特征量n′ 由于特征之间可能存在相似性,因此,特征选择阶段可能存在冗余特征。特征提取FE用于对特征选择阶段的特征子集进行冗余特征移除。通过两个特征向量间角度的余弦值度量特征间的相似性,定义为: 式中:wα和wβ表示两个特征向量,〈·〉表示点乘;‖·‖表示欧氏距离。该值度量了两个特征度量间的角度,取值范围为[0,1]。若余弦值为0,表明特征间是正交的;若余弦值为1,表明特征是共线的。 令n″表示特征提取后的特征子集长度。 算法2说明:算法的主要过程是按序依次遍历所有特征(步骤1-步骤9),根据式(10)计算相邻两个特征间的相似性(步骤2),并判断是否小于等于预定义的阈值,若满足,则将前一特征提取至最后的特征子集中(步骤3-步骤4);若当前特征是子集中的最后一个特征,则直接提取至最后的特征子集中(步骤6-步骤7)。最后,步骤10输出维度为n″的特征子集,作为下一阶段的特征精炼基础。 算法2基于余弦相似性的特征提取FE 输入:特征子集(特征数为n′),阈值Threshold2。 输出:特征子集(特征数为n″)。 1.forj=1 ton′do 2.s=cossim(Fj,Fj+1) ; 3.if(s≤Threshold2)then 4.FSFE=FSFE∪Fj; 5.endif 6.if((j+1)=n′)then 7.FSFE=FSFE∪Fj+1; 8.endif 9.endfor 10.return特征子集FSFE(特征数为n″) 经过特征选择和特征提取的特征过滤步骤后,可以生成初选的文本特征子集。为了进一步降低特征维度空间,本文引入IBGWO,在特征提取得到的特征子集基础上进行特征精炼,该步骤属于封装。GWO是一种新型的群体智能算法,模拟了自然界中灰狼的等级制度和捕食行为,通过灰狼群体搜索、包围及追捕攻击猎物等过程实现目标搜索。研究表明,GWO在求解问题精度和稳定性上优于传统的PSO、GA和DE,已在调度和规划优化问题上做了一系列应用。 利用GWO进行特征精炼,即一头灰狼在搜索空间中的位置信息可视为一种可行解。传统灰狼优化算法是连续灰狼算法,灰狼位置在搜索空间内可任意移动。由特征选择模型可知,特征精炼解将离散分布在二进制数0和1之间,所以,表达特征精炼可行解的灰狼优化算法需转换成二进制形式。将一头狼的位置编码为表1的二进制形式。编码中上层向量代表特征序号(维度),下层向量代表灰狼在各维度上的二进制位置,搜索空间维度n″对应特征提取后的文本特征数量,二进制向量Xh=(xh,1,xh,2,…,xh,n″),若xh,j=1,则表明灰狼h位置所代表的特征精炼候选解中,特征j选择为信息化特征;若xh,j=0,则表明灰狼h位置所代表的特征精炼候选解中,特征j不被选择定信息化特征,不包括在最优特征子集中。 表1 特征精炼解编码结构 传统灰狼优化算法随机进行种群初始化,然后通过优良个体保存策略逐步迭代,接近全局最优,改善种群个体,其搜索过程在满足预定义终止条件时结束。由于对全局最优没有任何先验知识,初始种群应尽可能均匀分布于搜索空间。算法的收敛速度与初始种群与最优解间的距离直接相关。若随机初始种群本身离全局最优距离较远,灰狼寻优可能无法完成。研究表明,接近一半的随机初始种群个体比较其反向解距离最优解更远。反向学习机制[19]可以通过同步考虑当前解及其反向解改善候选解的质量,并加快算法的收敛速度。因此,可将随机初始解及其反向解均考虑在初始种群中。以下对反向学习机制的概念作说明。 定义1反向数。令x为区间[l,u]内的实数,x∈[l,u],其对立数x′为: x′=u+l-x (11) 基于反向学习的灰狼种群初始化步骤如算法3所示。 算法3反向学习机制的种群初始化 输入:种群规模S。 输出:规模为S的灰狼种群X。 1.初始化规模为S的随机灰狼种群X 2.fori=1 toSdo 3.forj=1 toddo 4.endfor 5.endfor 6.X″=X∪X′ 7.计算灰狼适应度; 8.根据适应度对种群X″作降序排列; 9.X=top({X″}/2); 10.returnX 算法3说明:步骤1首先随机生成规模为S的灰狼个体位置,步骤2-步骤5在所有灰狼个体的所有位置维度上计算其反向点,然后在步骤6融合原始初始种群和由反向点组成的种群,形成规模为2S的灰狼种群结构X″。步骤7根据式(12)计算当前种群所有个体的适应度,然后在步骤8根据适应度对X″中的灰狼个体位置作降序排列,并在步骤9选取排序前S的灰狼种群X作为最终初始种群,最后在步骤10返回新生成的初始种群。 适应度函数用于评估灰狼位置代表的特征精炼解的质量。特征精炼应尽可能选取适应度更优的灰狼个体保留至下一种群世代中。对于文本特征而言,其重要程度不仅与其在文档中出现的次数相关,还与特征在文档中出现的频率相关。因此,将特征的累计词频与文档频率作加权计算特征精炼解的适应度[13],灰狼个体h的适应度计算为: 式中:σ和γ表示权重因子,分别用于表示特征的累计词频和文档频率对特征精炼解的偏好程度,σ、γ∈[0,1],且σ+γ=1;DFj表示特征j的文档频率;∑TF(i,j)表示特征j的累积词频。同时: DFj=DF(j)/m (14) 随着灰狼个体在搜索空间内的捕猎行为的进行,会导致灰狼位置发生变化,即代表相应的特征精炼解会更新。对于二进制灰狼优化算法而言,利用S型函数可将连续位置映射为二进制位置,具体转换函数为: 式中:x1,j、x2,j和x3,j分别代表灰狼个体h与当前的α狼、β狼和δ狼之间的距离;xh,j(t+1)表示迭代t+1时灰狼个体h的位置向量中第j维的二进制位置更新,代表灰狼个体h是否选择特征j为信息化特征;rand表示[0,1]内的随机生成数。函数sigmoid(x)定义为: x1,j、x2,j、x3,j计算方式如下: x1,j=|xα,j-A1·Dα| (17) x2,j=|xβ,j-A2·Dβ| (18) x3,j=|xδ,j-A3·Dδ| (19) 式中:xα,j、xβ,j和xδ,j分别表示当前灰狼种群中适应度最优的三头狼α狼、β狼和δ狼所代表的特征精炼解中,特征j是否选择为信息化特征。 系数A计算方式如下: A=2a·r1-a (20) 式中:r1表示[0,1]内的随机生成值;a表示收敛系数。a定义为: 式中:Tmax表示最大迭代次数。 Dα、Dβ和Dδ分别代表灰狼个体与α狼、β狼和δ狼之间的距离,计算方式为: Dα=|C1·Xα-X| (22) Dβ=|C2·Xβ-X| (23) Dδ=|C3·Xδ-X| (24) 式中:Xα、Xβ和Xδ分别代表α狼、β狼和δ狼的当前位置;X表示灰狼个体的当前位置。系数C的计算方式为: C=2r2 (25) 式中:r2表示[0,1]内的随机生成值。 由灰狼优化模型可知,灰狼对猎物的包围由收敛系数a决定,该系数决定灰狼的寻优能力,即局部开发与全局勘探能力。由收敛系数a的计算公式可知,a值变化呈线性递减趋势。对于灰狼优化算法而言,迭代初期,较大a值可以增大灰狼搜索步长,提高全局勘探能力,避免寻优过程过快收敛和早熟;迭代后期,较小a值可以减小灰狼搜索步长,提高局部开发能力,加快算法收敛。然而,两种搜索类型并不是完全线性切换的,收敛系数的线性递减并不能实际体现灰狼的复杂搜索过程,尤其出现多峰值情形时,易于陷入局部最优。本文将收敛系数a的变化改进为非线性递减形式,表示为: 式中:aini为收敛系数初值,通常为2;Tmax为最大迭代数,t为当前迭代数。式(26)表明,收敛系数a呈非线性衰减。迭代初期,衰减速率较慢,可以有效进行全局勘探;迭代末期衰减速率加快,可以更好进行局部开发。非线性衰减的收敛系数也因此更好地均衡了灰狼种群的全局勘探和局部开发能力。 由灰狼优化过程可知,搜索过程由当前灰狼种群中适应度最优的三头灰狼α狼、β狼和δ狼引领。在搜索过程末期,所有灰狼向决策层的三个头狼附近区域逼近,此时缺失群体多样性,收敛速度明显变慢或停滞,最终会陷入局部最优。算法继续引入反向学习机制,在α狼、β狼和δ狼的选取上同步引入其精英反向点,扩大灰狼的搜索范围,勘探新搜索区域。 利用MATLAB平台编写测试程序,硬件环境为Windows 10操作系统,Core i7处理器以及4 GB内存容量。所有文本特征选择算法以Java平台编写程序,最后的文本聚类测试则以K均值算法在MATLAB平台进行。 引入三种不同的经典基准数据集进行性能测试:Reuters- 21578[20]、Classic4[21]和WebKB[22]。三种数据集预定义划分为若干分类,分类信息在聚类过程中是未知的。Reuters- 21578数据集是路透社新闻专线发布的新闻集,包括21 578个文档,非均匀地分布于135个主题间。本文随机选取属于8个不同分类中的1 339个文档进行聚类分析。Classic4数据集包括7 095个文档,每个文档属于CACM、CRAM、CISI和MED四种分类中的一种。本文随机选取2 000个文档(一种分类500个文档)进行聚类分析。WebKB数据集即全球知识库,包括来自于四个学术领域内的8 282个Web页面,初始拥有7种分类,最后只有课程、学院、学生和项目四个分类被有效利用。本文从中随机选取2 803个文档进行聚类分析。从初始特征空间中随机抽取文档子集并不会转变数据集的属性,也不会影响算法的计算需求。三种数据集的详细统计如表2所示,可见,所有数据集拥有完全不同的文档数量、特征、偏斜度和稀疏性。 为了验证特征选择算法的性能,利用K均值算法根据特征选择算法求解的最优特征子集进行文本聚类,并以聚类性能分析特征选择性能。引入以下三个性能度量指标: 准确率P表明文本聚类结果的准确性,衡量查准率。P越大,聚类准确性越高,定义为: 式中:TP表示聚类解中被正确聚类的文档数量;FP表示错误聚类的文档数量。 召回率R表明文本聚类结果的完整性,即查全率。R越大,完整性越好,定义为: 式中:FN表示不该分开的文档被错误分开的文档数量。 F1度量:综合评定准确率和召回率。F1值越大,聚类性能越优,定义为: 本文设计的最优文本特征子集生成分成四个阶段:特征选择-特征合并/交叉-特征提取-特征精炼。令预处理后的文本特征规模为n。首先,特征选择阶段中,根据MAD或MM生成相关性特征子集,再对两类特征子集进行合并U或交叉I,得到规模为n′的特征子集,n′ 表3 测试算法 除表3的算法外,性能对比算法选择基于遗传算法的特征选择算法GAFS[8]、基于二进制粒子群算法的特征选择算法BPSOFS[10]和基于改进差分进化的特征选择算法IDEFS[13]进行对比分析。对于三种智能群体算法,种群规模设置为400,算法最大迭代次数设置为500,遗传交叉概率设为0.8,遗传变异概率设为0.2,粒子惯性权重最小值为0.4,最大值设为0.9,两个学习因子均设置为0.5。灰狼算法中的收敛系数初值设为2,系数A、C均随机生成,因此无须提前配置。 实验1确定IBGWO中适应度函数的权重因子σ和γ。由于σ+γ=1,可以仅以σ为参考,确定其参数取值。图1为改变σ取值时利用Reuters- 21578数据集进行聚类测试得到的准确率均值情况。σ调节步长为0.1,当增加σ取值时,则γ相应递减。从结果可知,聚类准确性整体是随着σ取值先上升后下降的,这说明适应度函数中的特征累计词频与文档频率两种要素会对聚类准确率产生影响,并且两个因素是相互制约的。在σ取值为0.4时,聚类准确率最佳。因此,后续实验测试中,将σ取值0.4、γ取值0.6进行实验分析。进一步需要说明的是,0.4/0.6的权重因子取值不一定是聚类准确率达到最高的取值组合,由于两个权重因子取值是可以在区间[0,1]内任意取值的,所以并不能确定其聚类准确率最大时的取值组合,但这并不会对后续实验分析产生不利影响。 图1 适应度函数权重因子的选取 实验2确定IBGWO在原始二进制灰狼优化算法BGWO基础上改进措施的有效性。图2为改进二进制灰狼优化算法与传统二进制灰狼优化算法在适应度方面的比较。可以看到,改进二进制灰狼优化算法可以有效提高灰狼个体所表征的特征精炼解的适应度值,这说明IBGWO中基于反向学习机制的初始种群生成方法可以优化初始种群结构,提升种群多样性。而非线性收敛系数衰减和精英反向学习机制,则可以有效提升灰狼算法的寻优性能,更加有助于灰狼个体的寻优收敛性,并最终得到最优文本特征子集。 图2 IBGWO的性能 实验3观察算法在特征降维方面的有效性。图3为所有算法在三种测试数据集中得到的最优特征子集维度,图4相应给出了算法在数据集原始特征规模下生成最优特征子集的降维比例情况。综合结果可以看到,传统过滤式特征选择方法MM和MAD对于特征空间维度的降低还是比较有限的,基本仅能降低全部初始特征空间的一半左右。融合特征合并和合并机制后,得到的特征规模并没有呈现大幅度增加或降低的趋势,这说明两种计算特征相关性分值的特征选择方法会产生很多交集,所选择的特征具有很大的相似性。而在引入余弦相似性的特征提取机制后,对相似性较高的冗余特征作了剔除,较大程度降低了特征规模。而引入改进二进制灰狼优化的多阶段特征精炼后,特征子集维度进一步有所减小,这说明本文所设计的特征选择-特征提取-特征精炼的多阶段降维机制是有效可行的,在降低相似性特征比例、提取信息化特征方面具有很好的优势。相比较GAFS、BPSOFS和IDEFS三种对比特征选择算法,本文的IBGWO同样具有进一步特征降维的优势,其中原因除了灰狼优化算法模型更为简单、参数依赖较少且寻优性能好之外,还在于本文灰狼优化中引入反向学习机制对灰狼种群的随机初始化作了改进,以及非线性收敛系数衰减模式和精英反向学习机制,最大限度地有效提升了灰狼算法的寻优性能,得到最优文本特征子集。 图3 最优特征子集规模 图4 特征降维比例 实验4进行系统的文本聚类性能分析。表4为11种算法在三个测试数据集上得到的聚类精确率、召回率和F1度量指标上的性能表现。综合结果可以看到,传统的过滤式特征选择方法MM和MAD对于特征空间维度降低比较有限,导致其冗余特征过多、噪声太大、信息化特征子集的提炼准确度过低,进而导致其聚类准确性较差。其他智能群体算法在进一步改进特征选择策略后,可以明显地提升聚类性能。相比较遗传GAFS、二进制粒子群BPSOFS、改进差分进化IDEFS三种对比特征选择算法,本文的改进二进制灰狼优化算法的多阶段特征选择机制在多数测试数据集均可以进一步改善聚类效果,说明引入的余弦相似性的冗余剔除机制可以有效分离出非信息化特征。而在二进制灰狼优化算法上进一步设计的反向学习机制对灰狼种群的随机初始化所作改进,以及非线性的收敛系数衰减模式和精英反向学习机制,最大程度地提升了灰狼算法的寻优性能,得到最优文本特征子集,不仅有效降低了特征维度,而且极大改善了文本聚类准确性。 表4 聚类性能对比 为了降低特征空间维度,提高文本聚类准确度,设计一种多阶段的特征选择与特征提取算法,在融合不同相关性特征分值计算方式的基础上,先对特征进行初选;然后基于余弦相似度对特征进行冗余剔除,在此基础上,引入改进二进制灰狼优化算法对上一步的特征子集作特征精炼,得到最优特征子集。在多个文本数据集的测试下,验证了本文算法的性能优势。进一步的研究可集中于尝试利用其他过滤式特征初选方式,并将其初选特征子集作为智能群体算法的初始种群结构,再进行特征提取和特征精炼,实现准确度更高的特征选择以及性能更优的文本聚类。3 特征提取
4 基于改进二进制灰狼优化的特征精炼
4.1 特征精炼解编码

4.2 基于反向学习机制的种群初始化
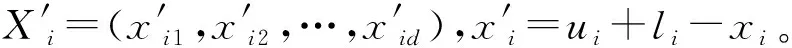
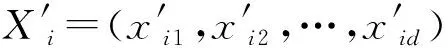
4.3 适应度函数
4.4 解的更新
4.5 非线性收敛系数更新机制
4.6 精英反向学习机制
5 实验与结果分析
5.1 测试数据集
5.2 性能指标
5.3 测试算法及参数
5.4 实验结果分析
6 结 语
