融合词语信息的细粒度命名实体识别
2023-04-07曹晖徐杨,2*
曹 晖 徐 杨,2*
1(贵州大学大数据与信息工程学院 贵州 贵阳 550025) 2(贵阳铝镁设计研究院有限公司 贵州 贵阳 550081)
0 引 言
命名实体(Named Entity,NE)概述为包含人名、地名、组织机构名、特定领域专有名词等的短语[1]。命名实体识别(Named Entity Recognition,NER)是自然语言处理核心基础任务之一,它的目标是准确划分实体边界并将其正确分类。NER采用的传统机器学习研究方法包括隐马尔可夫模型、最大熵模型和条件随机场等,但这些方法通常都需要领域专业知识和进行大量人工特征标注工作[2-3]。
近年,基于深度神经网络的方法显著提升了自然语言处理任务的效果。词向量工具的出现实现了字转化为稠密向量的功能,词向量比人工选择的特征蕴含更丰富的语义信息,有助于提升下游任务的性能。word2vec[4]、GloVe[5]和BERT[6]在NER任务中被广泛应用,明显地提升了整体模型的训练效率。长短期记忆网络[7](Long Short Term Memory,LSTM)在处理长序列标注任务上有更好的表现,它解决了循环神经网络[8](Recurrent Neural Networks,RNN)在训练过程中易发生梯度消失和梯度爆炸的问题。基于LSTM+CRF[9]构建的端到端的模型在英文命名实体识别任务中取得了较好的成绩。
细粒度命名实体识别任务旨在更精细地识别出非结构化文本中的实体类型,这对实体边界划分以及如何充分利用文本潜在词语的信息提出更高要求[10]。最近,将字符信息嵌入到词向量表示中的英文NER模型获得很大的效果提升。与英文不同,中文文本没有明确的词语划分边界,一种直观的做法是先进行分词,再进行序列标注工作。可是一旦分词有误,这种错误会传播到NER中,影响模型的识别性能[11]。
针对以上问题,本文提出一种融合词语信息的中文细粒度命名实体识别模型。通过将句子与外部词典进行匹配,映射获取到句中潜在的词语信息,再将这部分信息嵌入到字级别的表示中形成网格结构。与单纯基于字的方法相比,这种结构不仅包含更多语义信息而且避免了分词错误传递的问题;通过Self-Attention计算权重的机制可捕获句中任意元素间的关系信息。在细粒度实体语料CLUENER2020上验证了本文模型的有效性。
1 相关研究
1.1 Lattice LSTM
Zhang等[12]首次提出Lattice LSTM模型用以解决命名实体识别问题,其结构如图1所示。
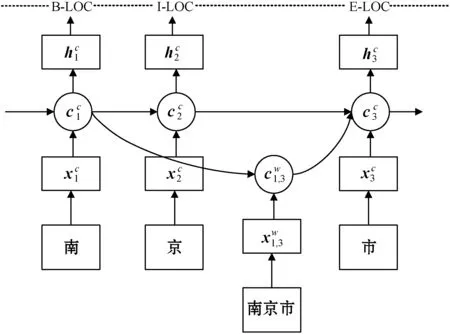
图1 Lattice LSTM结构
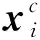
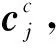
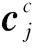
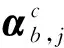
1.2 Transformer
Transformer是Encoder-Decoder网络结构。Encoder包括Self-attention和Fully connected feed-forward两个子层。Decoder比Encoder多一层Encoder-Decoder Attention。每一子层都附加了残差连接和正则化。Encoder结构如图2所示。
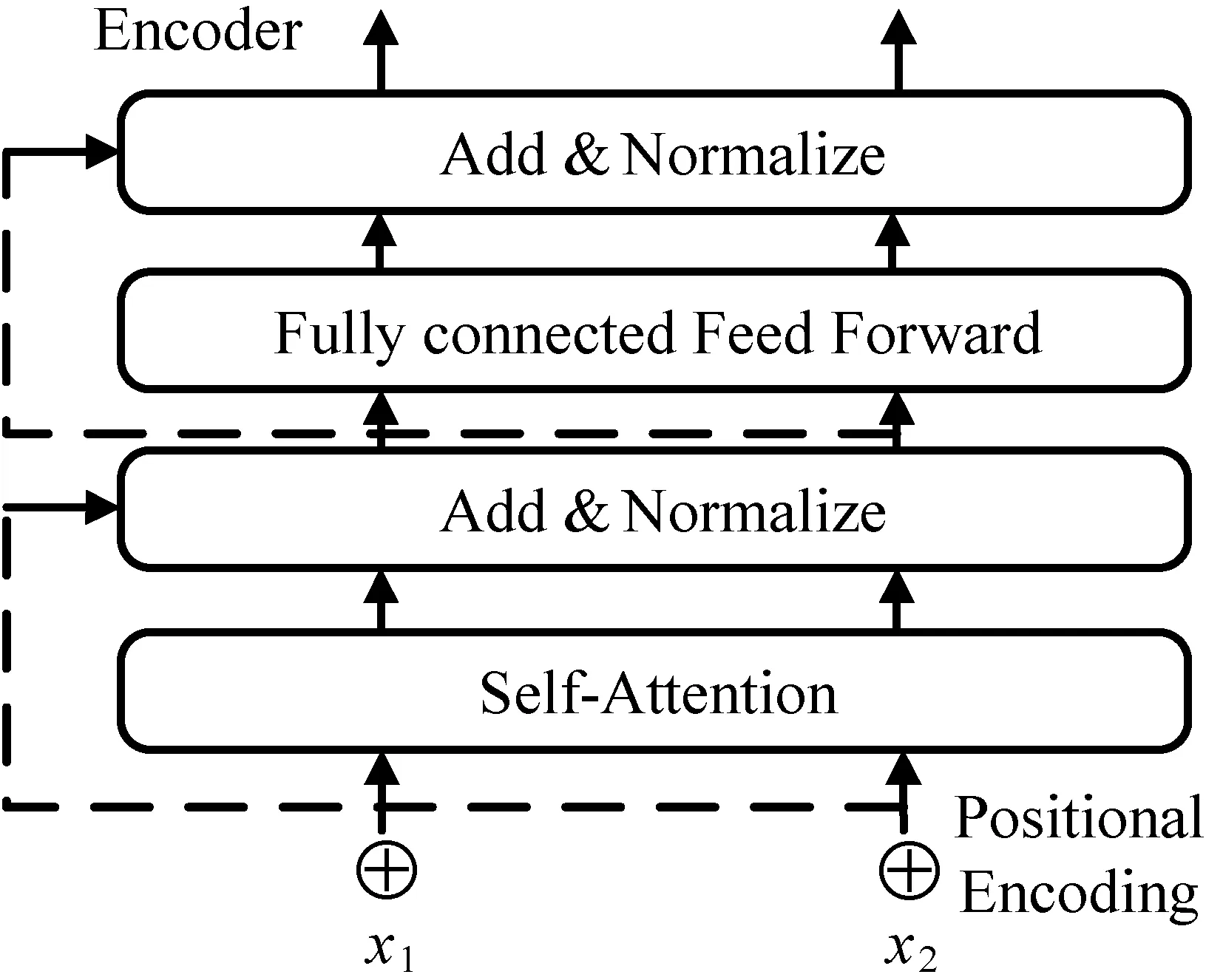
图2 Encoder结构
Self-Attention[13]是Encoder结构以及Transformer的核心组件,如式(5)所示。其思想是要从特征向量中学习到每一个元素对其余元素的影响程度,通过这种机制得到每个元素考虑了全局信息之后的新表达。
式中:当给定输入向量X,Q=XWQ、K=XWK、V=XWV,WQ、WK、WV是可训练参数,X∈Rn×d,WQ、WK∈Rn×dk,WV∈Rn×dV,dk是K的维度。
Transformer中使用了多头注意力机制处理输入向量,然后将每头注意力的计算结果拼接和线性变换。这样做不仅扩展了模型关注不同位置的能力,而且给注意力层带来更多“表示子空间”。
为了使Transformer可以捕捉输入序列的字顺序信息,在输入向量中加入了位置编码(Positional Encoding)用来对序列中的元素位置以及任意两个元素之间的距离建模。第j个元素位置编码p可表示为:
p(j,2i)=sin(j/10 0002i/d)
p(j,2i+1)=cos(j/10 0002i/d)
(6)
式中:i表示字或词的维度;d表示模型的维度。
2 命名实体识别模型
本文提出的模型结构如图3所示,可分为三个部分,输入部分为词向量与基于BERT-wwm构建的增强型字向量拼接而成的数据,经过扁平化的Lattice Transformer对输入及相关位置信息进行编码,最后通过CRF层计算出最大概率标签。
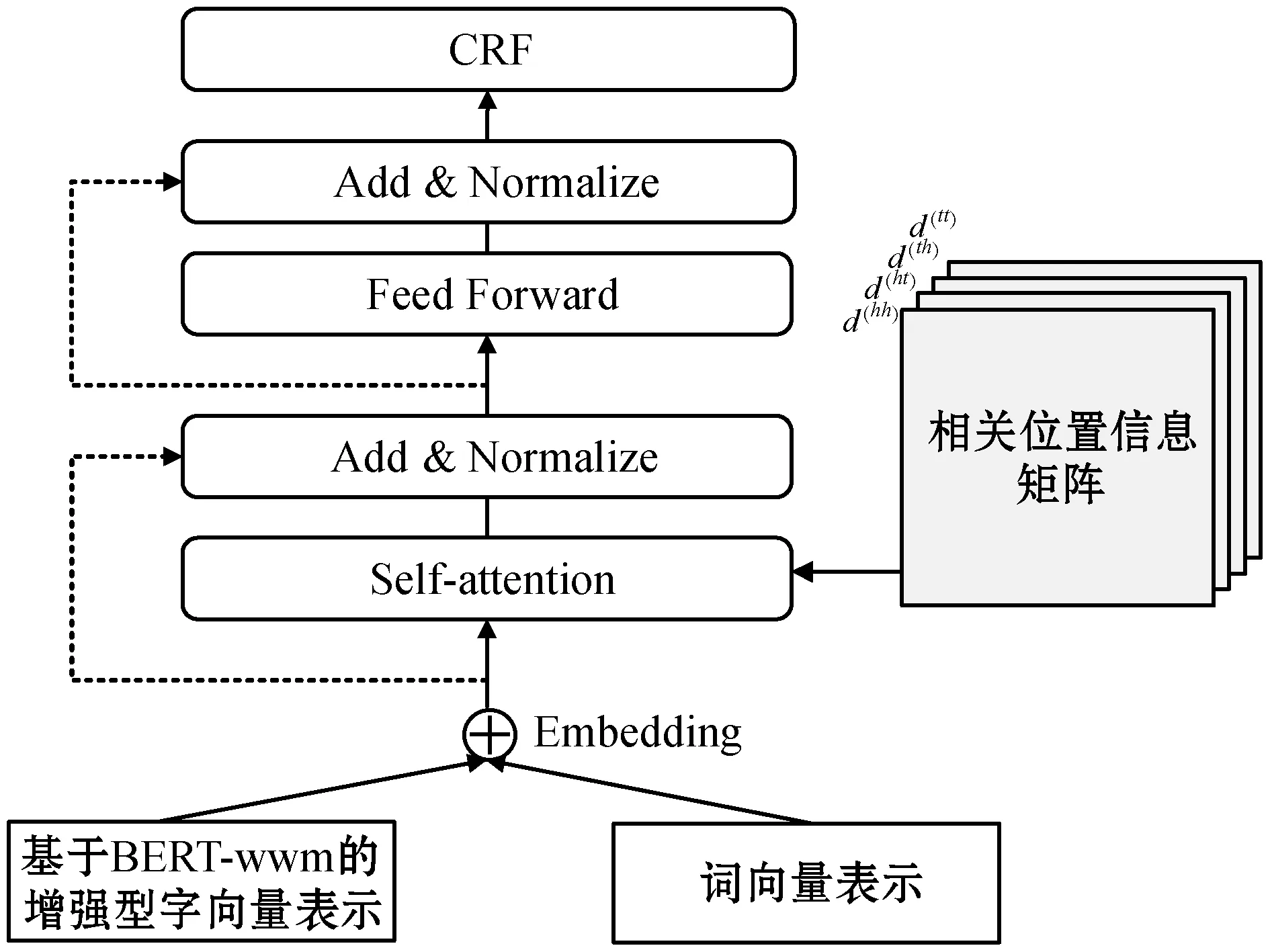
图3 模型结构
2.1 融合词语信息的特征表示
模型的输入向量包含词向量表示和字向量表示。词向量通过词典匹配的方式获取,即将输入的语句与中文词典进行匹配获取到句中潜在的词语集合,再通过查找预训练的向量矩阵,映射得到每个匹配词语的向量表示。
BERT具有强大的语义表征能力,其内部的双向Transformer网络结构可结合字左右两侧的上下文,动态地获取字的深层语义。但BERT是以字为单位对中文语料进行训练的,没有考虑到中文分词。BERT-wwm使用哈工大LTP分词,在训练时对组成一个词语的全部字都Mask,因此该模型更适合处理中文任务。基于BERT-wwm,本文构建一种增强型字向量表示方法,用以将句中潜在的分词信息加入到字向量中。
如图4所示,将词语集合{“南京”,“长江”,“长江大桥”,“大桥”}按照{B,I,E,S}的格式归类到每个字,其中:B集合包含以当前字作为开头的词语;I集合包含当前字在词内部的词语;E集合包含以当前字作为结尾的词语;S集合包含当前字,如果集合中没有匹配的词语则用None表示。通过式(7)计算得到每个字对应的分词集合的向量表示es(B,I,E,S):
es(B,I,E,S)=[vs(B)⊕vs(I)⊕vs(E)⊕vs(S)]
(7)
式中:vs(S)代表S集合中所有词语的加权向量;ew代表词向量映射表;z(w)代表词语w在数据集中出现的次数。最后,将es(B,I,E,S)与对应的由BERT-wwm产生的字向量拼接组成增强型字向量表示。
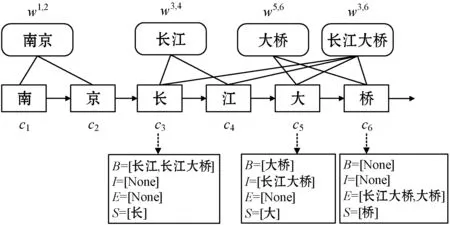
图4 增强型字向量表示
2.2 扁平化的Lattice Transformer
针对Lattice LSTM无法充分利用远距离时序依赖关系和计算速度慢的问题,本文引入了一种扁平化的Lattice Transformer(下文使用FLT简写)[14]结构。首先,通过为所有元素(字或词语)构建头指针head和尾指针tail的方式将原网格结构平面化,其中:head表示元素首字的索引,tail表示元素尾字的索引,单个字的head和tail相同,结构如图5所示。
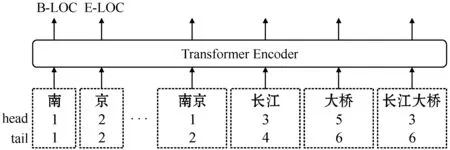
图5 Lattice Transformer结构
其次,任意两元素间可能存在的位置关系有三种:相交、包含和相离,为了使Transformer可编码任意元素的相对位置关系信息,设计一个稠密的向量来对元素关系进行建模。式(7)-式(10)的四种相对距离可以表示任意两元素间的关系:
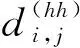
Pd由式(14)获得。
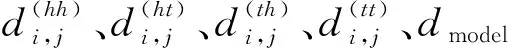
最终,考虑了相对位置信息的Self-Attention计算式为:
μTExjWK,E+νTRijWK,R
(15)
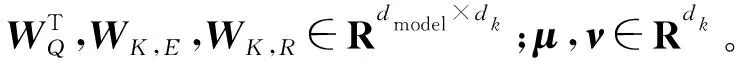
2.3 CRF
在模型的顶部,加入条件随机场(CRF)用以对输入序列进行标签顺序推理。假设记W为转换分数矩阵,Wyi,yi+1表示从yi标签转移到yi+1标签的得分;记pi,yi为序列中的第i个元素在yi标签处的得分。那么,对于给定长度为n的输入序列X=[x1,x2,…,xn],标签序列y=[y1,y2,…,yn],则计算该标签的得分公式为:
然后进行归一化处理,得到y的概率分布,其中YX代表所有可能的标签序列:
解码时,概率最高的序列y*即为最优输出标签序列:
本文采用维特比算法求解最优序列。
3 实验与结果分析
3.1 实验数据
本文实验采用细粒度命名实体识别数据集CLUENER2020,包含人名、地址、组织机构、书名、公司、游戏、政府、电影、职位和景点10个类别。训练集包含10 748个句子,测试集包含1 343个句子。表1给出了详细的实体数目统计。Lample等[15]在实验中采用的BIOES标注策略表明显示的边界标记有助于提升模型性能,本文采用相同的标注方法,其中:B表示实体开始;I表示实体内部;O表示不是实体部分;E表示实体结束;S表示单个字的实体。
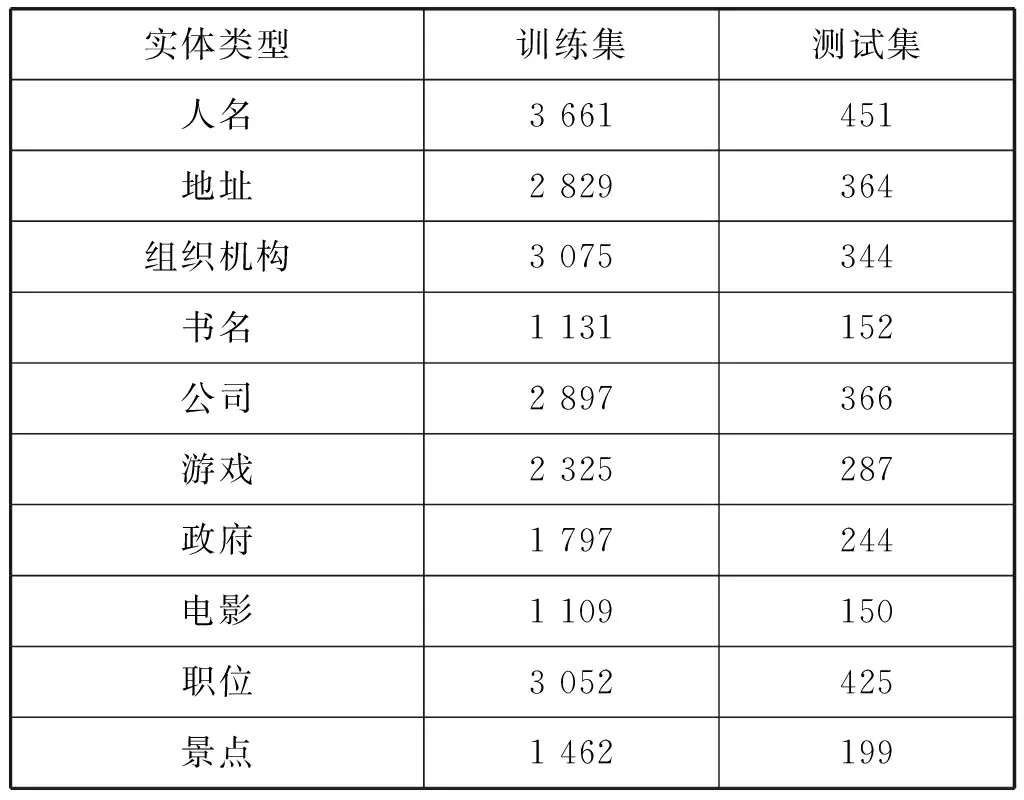
表1 实体数目统计
在实验结果评估上,采用精确率(Precision,P)、召回率(Recall,R)、F1值作为评价模型性能的指标。
3.2 实验设置
实验的环境配置如表2所示。
表2 实验环境
为了验证本文FLT-CRF模型的效果,设置了以下模型的对比实验:
(1) BiLSTM-CRF。该模型是经典的序列标注模型。输入使用Skip-gram模型预训练的字向量,LSTM隐藏单元数为128,层数为2,dropout为0.5。
(2) Lattice-LSTM-CRF。该模型的输入字向量来自于预训练的词典gigaword_chn.all.a2b.uni.ite50.vec,它是基于大规模标准分词后的中文语料库Gigaword使用word2vec工具训练得到的,共包括704 400个字符和词。词向量来自ctb.50d.vec,它是基于CTB6.0(Chinese Treebank 6.0)语料训练得到的。LSTM隐藏单元数为200,层数为2,向量维度为50,dropout为0.5,学习率为0.015,优化器使用SGD。
(3) FLT-CRF。该实验输入的字向量和词向量及使用的词典与Lattice-LSTM-CRF保持一致。参数设置Transformer为1层,学习率为0.001,Attention头数为8,维度为20,优化器使用Adam。
3.3 实验结果分析
表3列出了不同模型的实验结果。
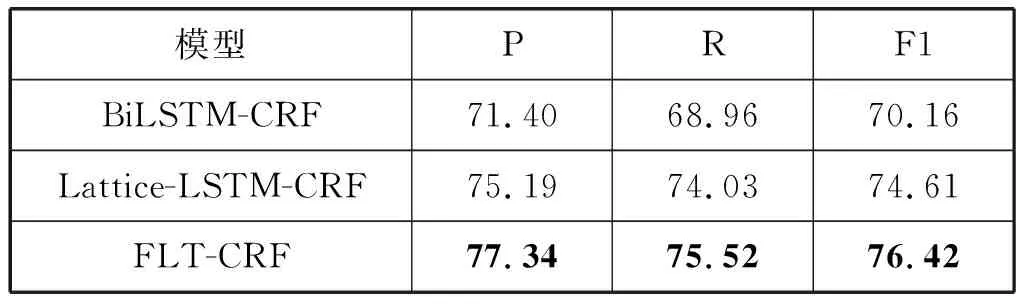
表3 不同模型实验结果(%)
实验结果表明,本文模型FLT-CRF在细粒度命名实体数据集上的效果要优于目前主流的中文命名实体识别模型。从表3可以看出,与基于字的BiLSTM-CRF模型相比,Lattice-LSTM-CRF模型精确率提高了3.79百分点、召回率提高了5.07百分点、F1值提高了4.45百分点,这是因为Lattice-LSTM模型引入了外部词典,将潜在的词语信息融入了字特征表示中,表明了词信息在命名实体识别任务中的重要性。与Lattice-LSTM-CRF模型相比,FLT-CRF模型的精确率提高2.15百分点、召回率提高1.49百分点、F1值提高1.81百分点,这是因为Self-Attention比LSTM对远距离依赖关系具有更强的抽取能力,并且能够利用任意元素间的相对位置信息,因此在识别精确度上有较大提升。
为了发现FLT-CRF在运行效率方面的表现,表4给出了在本文实验环境配置下Lattice LSTM-CRF和FLT-CRF每次epoch运行所需的平均训练时间。将Lattice LSTM-CRF的batch_size设为1,FLT-CRF的batch_size设为16。
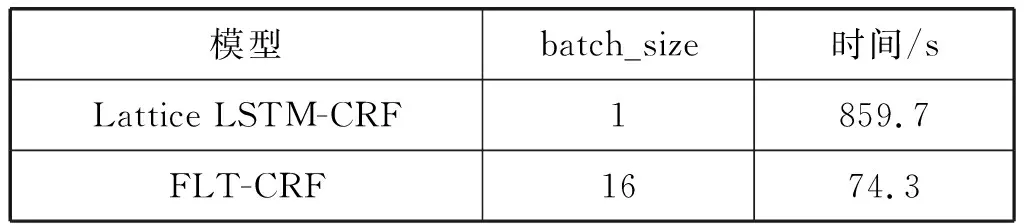
表4 运行时间对比
可以看出,FLT-CRF训练运行效率比Lattice LSTM-CRF高出10.57倍。这是因为Lattice LSTM是有向无环图结构模型,无法进行批处理,导致模型运行速度较慢。而FLT-CRF用Self-Attention代替了循环神经网络,将网格结构展开成一种平面的形式,可以充分利用GPU的并行计算资源,因此计算效率得到很大的提升。
为了验证本文构建的增强型字向量表示有助于提升FLT-CRF模型效果,设计了以下三组对比实验:
方案1将BERT-wwm-CRF模型作为基线模型。
方案2将BERT-wwm与FLT-CRF模型结合,输入的字向量表示仅由BERT-wwm产生。
方案3将本文2.1节构建的增强型字向量作为FLT-CRF模型的字向量输入。
方案2和方案3的词向量都通过词典映射获取,使用的词典和参数保持一致,实验结果如表5所示。
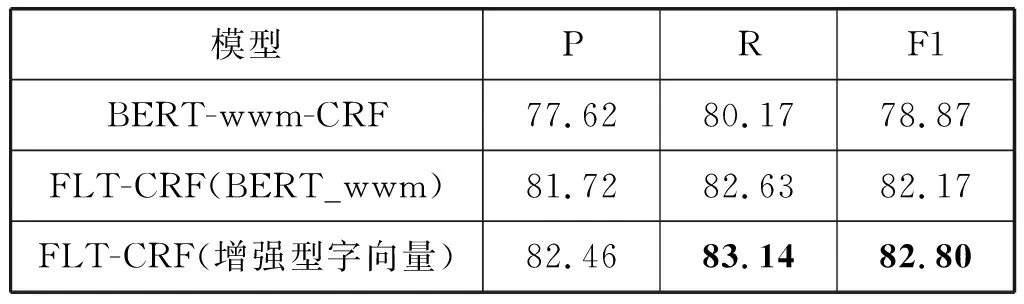
表5 不同输入字向量实验结果(%)
实验结果表明,将BERT-wwm运用到FLT-CRF模型中,与基于词典映射的方法相比,F1值由76.42%提升到了82.17%,这一方面是由于BERT-wwm的强大特征表示能力,对输入可以进行深层次的语义表达,另一方面是因为FLT-CRF可以更充分地建模这些语义信息,使得结果得到提升。方案2使用增强型字向量将模型效果提升到了82.80%,表明了将可能存在的分词信息嵌入到字向量中可以增强字向量表示有助于提升FLT-CRF的识别效果,例如在测试句子“住房和城乡建设部部长”中,“住房和城乡建设部”整体是政府部门实体,在没有引入增强型字向量时因未能正确划分实体边界,将“城乡建设部”标记为一个实体,忽略了“住房和”三个字,但引入增强型字向量后,由于嵌入了潜在分词“住房和城乡建设”“住房和城乡建设部”的信息,从而使得该实体被正确地识别出来。
4 结 语
针对现有基于字的模型无法充分利用句子词语信息的问题,本文提出一种基于扁平化Lattice Transformer且融合词语信息的细粒度命名实体识别模型FLT-CRF,在识别性能和计算效率上比已有方法得到较大提升。结合BERT-wwm可取得更好的实验结果。下一步考虑将Lattice Transformer结构结合到复杂的实体识别任务中,比如嵌套实体识别和跨域实体识别,并探索该模型在其他领域的识别性能。
