基于FPGA的卷积神经网络硬件加速器设计
2023-04-07黄沛昱李煜龙
黄沛昱 赵 强 李煜龙
(重庆邮电大学光电工程学院 重庆 400065)
0 引 言
近年来,随着人工智能的快速发展,其理论研究日益成熟。机器视觉是人工智能的一个重要研究方向,卷积神经网络(Convolutional Neural Network,CNN)已经被广泛应用于机器视觉完成特征提取[1-4]。
深度学习主要分为两个步骤:训练和推理。采用通用处理器实现卷积神经网络的推理,其运算效率非常低。因为通用处理器采用冯诺依曼结构是串行执行,难以满足卷积神经网络需要大量的并行计算。因此,针对卷积神经网络的结构出现了三种主流的硬件加速方式:专用集成电路(Application Specific Integrated Circuit,ASIC)、图形处理器(Graphics Processing Unit,GPU)、现场可编程门阵列(Field Programmable Gate Array,FPGA)。其中,基于ASIC的硬件实现研发周期长,无法适应复杂多变的CNN结构,并且专用集成电路研发成本高昂。基于GPU的硬件实现虽然可以获得很好的性能,但是较高的功耗也会降低其性能,同时,如果将其部署到移动设备会严重缩短续航时间。基于FPGA的硬件加速器能克服ASIC和GPU的缺点,同时,FPGA支持并行计算,具有动态可重构、低功耗、低延时、高性能的优势[5-7]。
因此,目前基于FPGA对卷积神经网络进行硬件加速设计已经被广泛研究。文献[8]采用8 bit位宽量化卷积神经网络,在损失一定准确度的情况下,减少网络的体积,并且节约了FPGA的存储资源,同时也提高了计算性能。文献[9]提出一种卷积循环二维展开的加速器设计,其核心思想是把每一层卷积计算的输入和输出特征图循环展开进行并行计算,从而提高计算的吞吐量。但是,由于该设计把权重和输入输出特征图缓存在FPGA片上,导致FPGA消耗过多的资源,不利于部署在中小规模FPGA上。
在进行FPGA硬件电路设计时,传统的方法采用Verilog或者VHDL语言进行设计,这种方式开发效率低。目前,随着高层次综合工具的日益成熟,Xilinx公司推出的HLS工具已经支持C/C++语言对FPGA完成算法开发,从而提高开发效率[10]。
为了提高卷积神经网络的推理速度,本文设计一种基于FPGA的硬件加速电路。首先,网络结构采用工业界广泛用于目标检测的YOLOv2网络。为了减少网络模型的体积,同时为了保证网络预测结果的准确率,本设计采用16位定点化权重参数,偏置项参数以及输入输出特征图的像素。然后设计卷积运算模块的硬件电路,为了提高计算的吞吐量,采用输入输出二维循环展开的方法,为了降低从内存中读取数据的延时,采用双缓存设计。最后,将本设计的YOLOv2网络加速器部署在Xilinx公司的Pynq-z1嵌入式开发板上性能超过i5- 4440处理器。同时,与已有的CNN模型的硬件加速器性能进行对比。
1 卷积神经网络加速器研究
1.1 卷积神经网络
2012年,Hinton教授带领学生在Imagenet数据集上,将AlexNet网络用于图像分类获得的准确率远高于传统算法。从此,卷积神经网络广泛用于图像分类、目标检测和跟踪等一系列的计算机视觉领域[11-12]。
卷积神经网络主要包括输入层、卷积层、池化层、全连接层、输出层等。VGG- 16网络如图1所示,其网络包含13个卷积层、5个池化层、3个全连接层。卷积神经网络中不同卷积层有不同数目的卷积核,卷积核的大小主要以3×3和1×1为主,卷积层通过卷积核提取图像特征。卷积的结果需要通过相应的激活函数计算后再进行池化,激活函数是为使网络的输入输出之间满足非线性的关系,增强神经网络的表达能力。常见的激活函数有ReLU、Leaky ReLU、Tanh和Sigmoid函数。池化层也被称为降采样,作用是减少特征图的尺寸。常用的池化方法有最大池化和平均池化,而池化的大小以2×2为主。网络中的全连接层一般位于网络最后几层,其作用是将提取的特征完成分类,由于全连接层的参数占整个网络的90%以上,参数的冗余降低模型的表达能力。因此,现在大量性能优异的网络采用全局平均池化代替全连接层,使用Softmax函数来完成分类任务,例如ResNet网络和GoogLeNet网络[13-15]。
1.2 YOLOv2网络模型分析
YOLOv2网络模型是目标检测领域的One-Stage典型算法,其速度要快过Two-Stage算法中的Fast-RCNN和Faster-RCNN网络模型。同时,YOLOv2网络模型可以速度和准确率之间进行权衡,适应不同场景的需求[16-17]。比如,在不需要速度的时候,适当地提高模型的准确率;而在一些场景对速度有严格的要求,可以适当地提高速度。因此,YOLOv2适合部署于中小规模设备。
YOLOv2网络结构中使用Darknet- 19网络作为基础分类网络,Darknet- 19网络如表1所示,Darknet- 19网络结合GoogLeNet网络和VGG- 19网络的优势,在Darknet- 19网络中使用1×1和3×3的卷积核进行卷积计算,同时,使用全局平均池化代替全连接层。Darknet- 19网络不仅能降低模型的参数量和计算的复杂度,而且能提高网络的泛化能力,避免模型的过拟合。
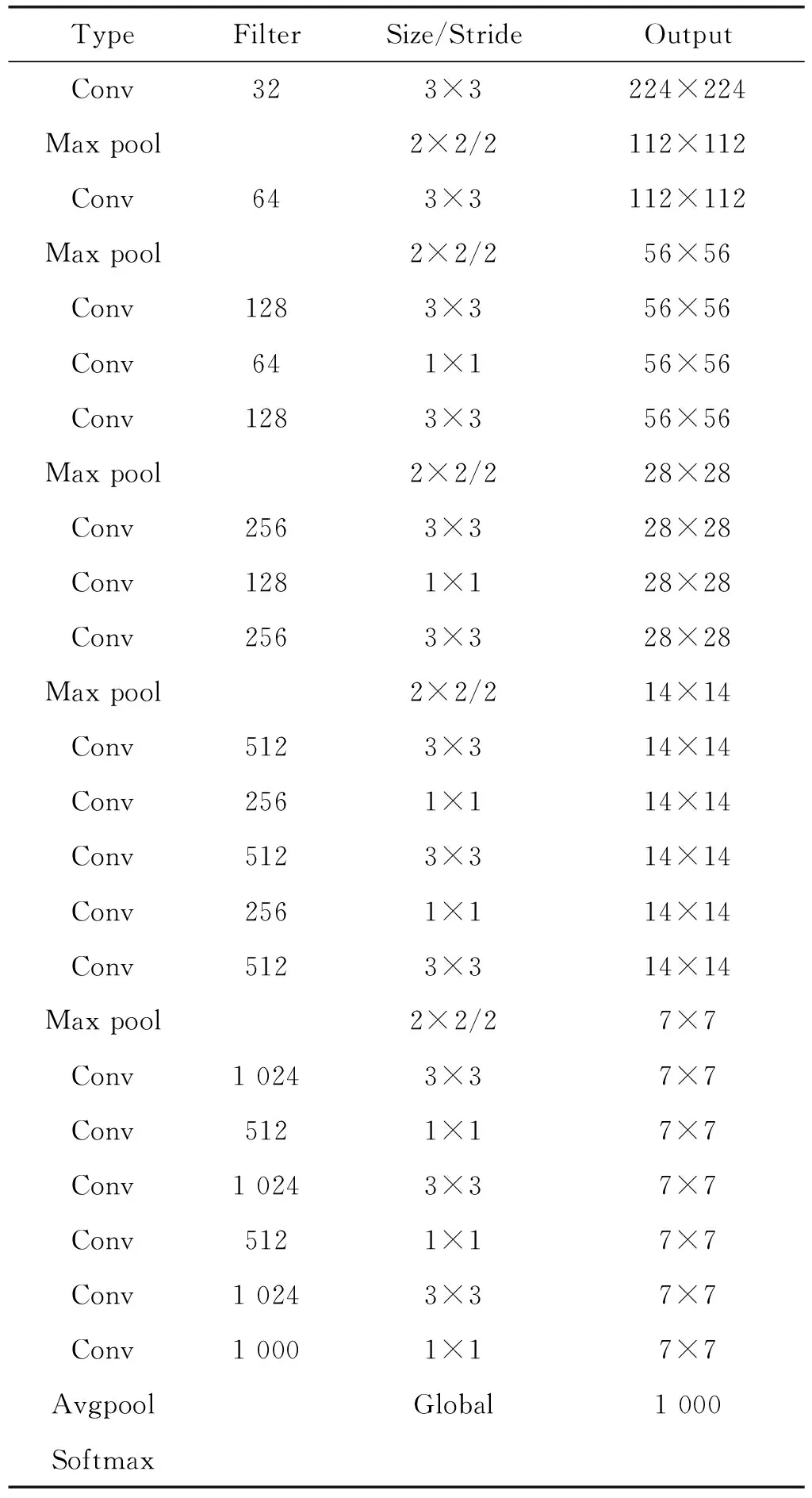
表1 Darknet- 19网络结构
1.3 CNN加速器策略
因为卷积层的计算量占据整个网络模型的90%以上[18],所以为了加速卷积神经网络的推理过程,本文采取循环展开和分块的策略,针对网络模型中的卷积层运算进行优化。
1.3.1循环展开
循环展开是针对卷积计算常用的硬件加速策略,主要是提高硬件乘法单元的并行度。循环展开可以分为两类:一类是输入特征图的循环展开,另外一类是输出特征图的循环展开。
输入特征图的循环展开通过每个时钟周期并行的读取Tn幅输入特征图的像素点,然后与对应的权重参数进行乘累加操作。如图2所示(Tn=4),每个时钟周期读取的特征图的个数Tn需要合理设置,特征图的个数Tn决定输入并行乘法器的个数。如果Tn值太大,虽然可以获得较高的性能,但是会消耗FPGA芯片内部大量的DSP资源,如果Tn值太小,则无法发挥FPGA并行计算的优势。
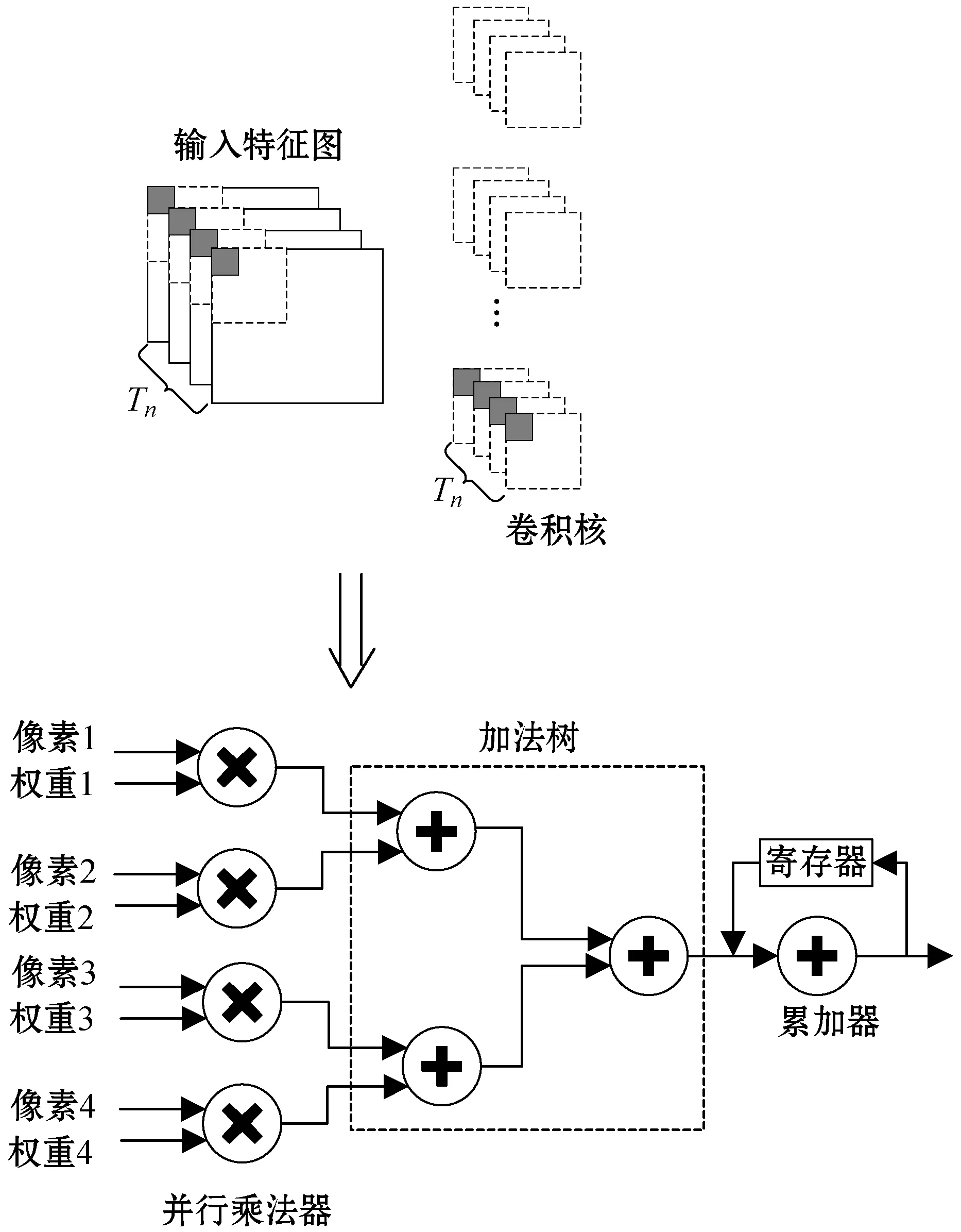
图2 输入特征图循环展开示意图
输出特征图的循环展开是通过每个时钟周期并行读取Tm个卷积核权重参数值与读取的一幅输入特征图的像素值进行乘累加操作,如图3所示(Tm=2)。
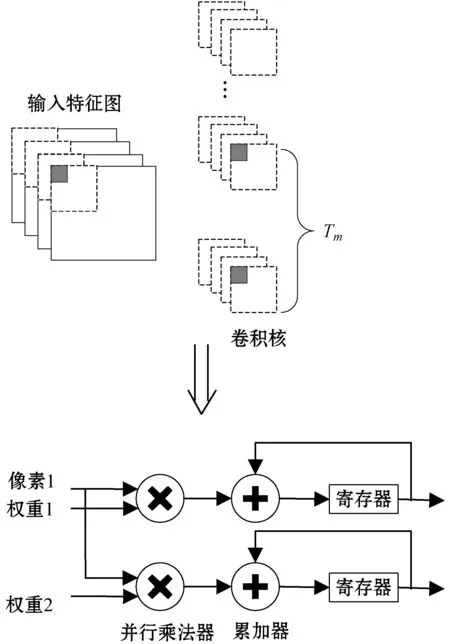
图3 输出特征图循环展开示意图
1.3.2循环分块
因为FPGA芯片内部存储资源有限,所以将CNN网络部署到FPGA上,需要将输入输出特征图和权重参数存储到片外存储器中。
本设计采用循环分块的思想,每个时钟周期从片外读取Tn个Tix×Tiy大小的像素块,并且读取Tm个卷积核,卷积核大小为Tn×Tkx×Tky,卷积核的大小是由网络结构所决定。同时,把中间计算结果缓存在片上存储中,当计算完成得到最终结果,再向片外存储器写入Tm个Tox×Toy大小的像素块,如图4所示。采用循环分块的思想可以有效地减少片外存储访问次数,降低访存时延,从而提高加速性能。
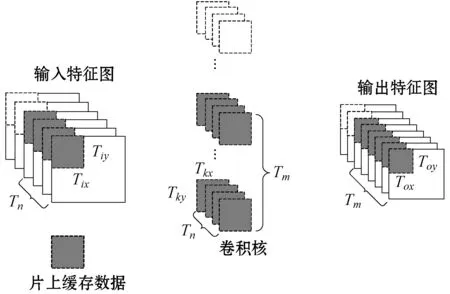
图4 循环分块示意图
2 YOLOv2网络硬件加速器设计
2.1 硬件加速器整体架构设计
在卷积神经网络的推理阶段,网络的层与层之间是串行结构,每一个网络层的输出作为下一个网络层的输入,而每一个网络层内存在大量的并行计算。本设计的硬件加速器充分利用卷积神经网络的层间流水,层内并行计算特点。为了减少读取或写入数据传输时延,本设计使用双缓存结构,如图5所示。
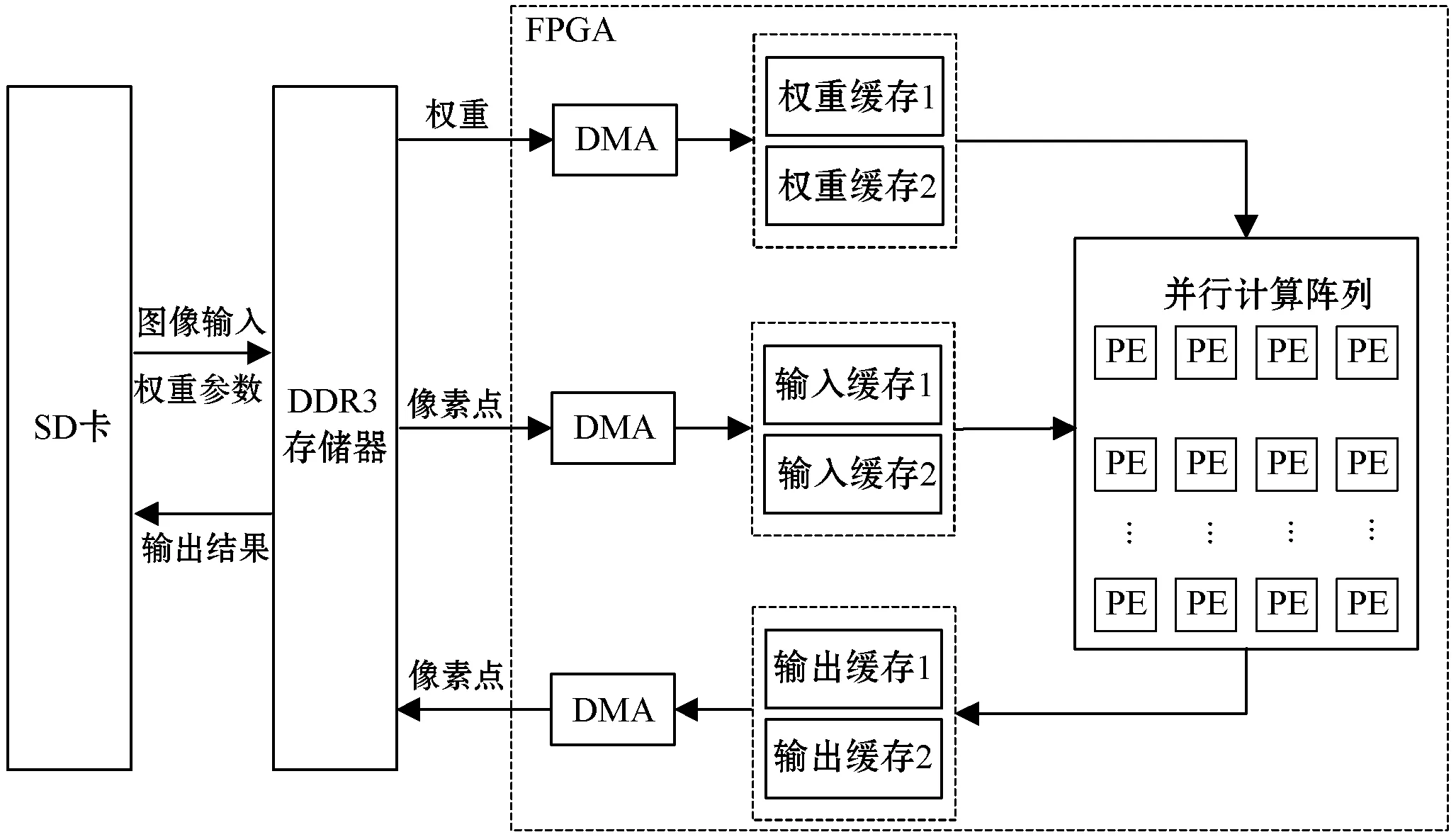
图5 硬件加速器架构
本设计在zynq- 7020芯片完成加速器的设计,首先把待测试的数据集、16位定点量化权重参数和偏置参数存放在SD卡中,然后从SD卡读入片外DDR3存储器中。在进行计算之前,需要对图片进行预处理,大小为416×416,同时,把RGB图片的像素值量化为0到1之间的小数。接着在DDR3存储器和片上缓存之间,通过4个AXI总线的HP端口,使用DMA(Direct Memory Access)把片外存储器的数据读取到片上缓存中。其中,AXI总线的HP端口通过双缓存的设计,使得读取数据、计算和写入数据三者同时进行,能够有效提高因为数据传输时延而影响加速器的性能。
在片上计算单元中,时钟频率为150 MHz,通过设计并行计算阵列加速YOLOv2网络中卷积和池化运算。其中,本设计的卷积并行计算阵列大小32行4列,每次从输入读取4幅特征图部分像素块,像素块大小为Tix×Tiy。
Tix=(Tox-1)×s+k
(1)
Tiy=(Toy-1)×s+k
(2)
式中:Tox和Toy为输出特征图的像素块的大小,Tox=Toy=13;s为卷积计算的步长;k为卷积核的大小。
整个硬件加速器依次从DDR3内存中读取数据,然后在片上完成计算,实现层间流水,层内并行的硬件加速器。最后将加速器的计算结果写回DDR3内存中,通过Softmax函数完成目标检测的分类,使用非极大值抑制算法得到目标的边框,以及在图片上完成标记。
2.2 卷积层硬件加速单元设计
在YOLOv2网络模型中,卷积层包括卷积计算,批归一化(Batch Normalization,BN)和激活函数(Leaky ReLU)三部分。批归一化是针对卷积运算的输出特征图的每个像素点进行线性运算,因此,在进行卷积计算之前,本设计将批归一化运算与权重参数和偏置参数进行融合,然后在FPGA片上进行卷积计算,有利于减少FPGA片上的计算量,从而提高加速器的性能。
因为卷积运算占据大多数CNN网络中90%以上运算量,所以目前针对CNN硬件加速器设计主要集中在卷积层的硬件设计。本设计针对卷积计算硬件加速单元的设计采用循环展开和循环分块的策略,对输入输出特征图进行二维展开,在合理考虑硬件资源和YOLOv2网络结构的情况下,本设计采用128个并行乘法器实现卷积层的硬件加速,如图6所示。每输入一张特征图与一组权重参数相乘为1个PE单元,因为本设计输出特征图采用32维展开,所以一幅Tix×Tiy大小的特征图需要与32组权重参数进行并行乘法计算,总共为32个PE单元。同时,输入特征图采用4维展开,在每个时钟周期同时读取4幅Tix×Tiy大小的特征图,再结合输出特征图展开维度为32,总共为128个PE单元,构成32行4列卷积并行计算单元。
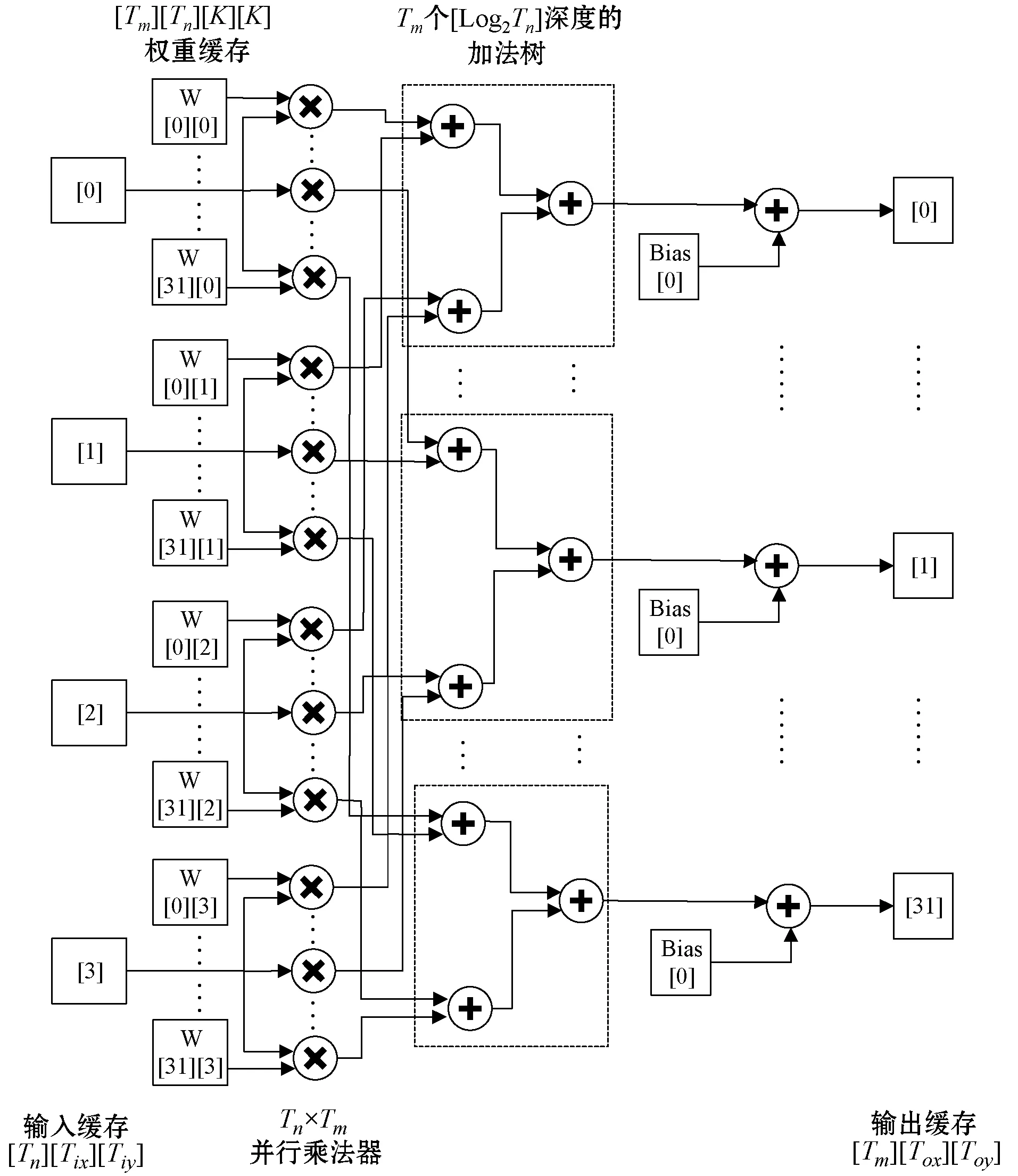
图6 卷积层硬件加速结构图
卷积计算单元输入输出端口包括特征图输入端口、权重参数输入端口和特征图输出端口三部分。因为卷积计算的偏置参数量较少,所以预先存储在FPGA芯片内部。在进行卷积计算时,输入输出端口均采用乒乓操作,在同一时钟下,使得读取和写入数据同时进行,能够有效降低读取和写入数据的传输时延,提高每个PE单元计算速度,从而提高整个硬件加速器的计算性能。
2.3 双缓存设计
在YOLOv2网络模型中,每一层的计算需要频繁地对片外DRAM读取和写入数据,将会导致因为数据传输延迟而带来的硬件加速器计算性能的下降。因此,双缓存设计是为了降低从片外DRAM内存中的数据读取到片上的传输时间和降低从片上的计算结果写回片外DRAM内存中的传输时间。
双缓存设计具体的结构如图7所示。首先,第一个时钟周期,将输入数据通过输入数据选择器存入缓存1中。然后,第二时钟周期,将输入数据通过输入数据选择器存入缓存2中,同时,将缓存1中的数据通过输出数据选择器输出到卷积运算单元中。第三个时钟周期,将输入数据存放在缓存1中,依次重复之前的操作,实现数据流水处理,降低从片外到片内数据传输的时间。双缓存设计通过FPGA的片上BRAM逻辑资源实现,输入缓存区N1和输出缓存区N2的大小通过式(3)和式(4)计算得到。
式中:Datawidth表示输入输出特征图中数据位宽大小;MBRAM表示一块BRAM能够存储数据的大小。
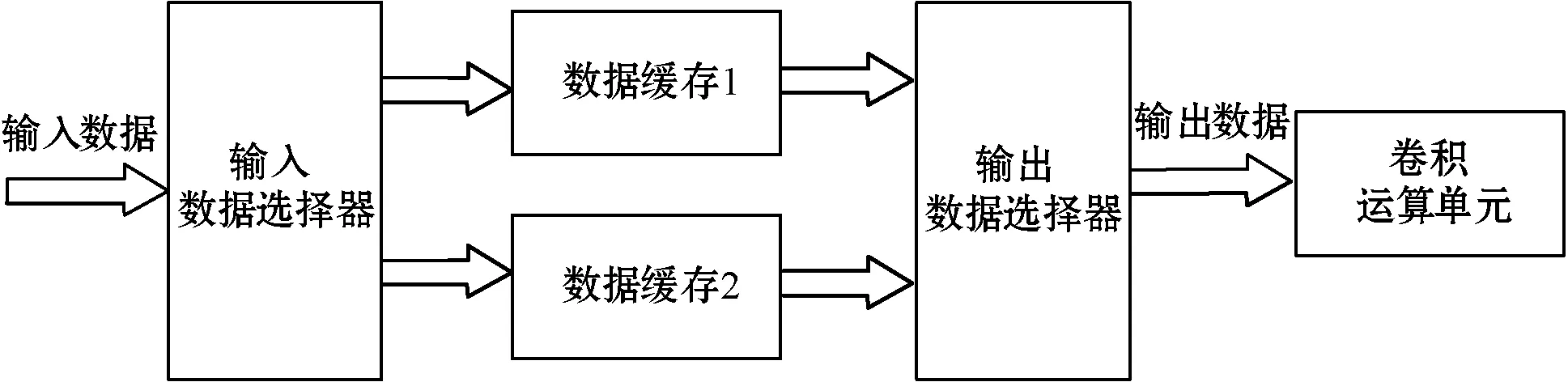
图7 双缓存设计结构图
当不采用双缓存设计时,完成一次卷积运算总延迟时间为:
T1=Tread+Tcompute+Twrite
(5)
式中:Tread表示从片外DRAM内存中读取数据到片上的时间;Tcompute表示片上卷积层计算的时间;Twrite表示片上的计算结果写回到片外DRAM内存中。
当采用双缓存设计后,完成一次卷积运算总延迟时间为:
T2=max(Tread,Tcompute,Twrite)
(6)
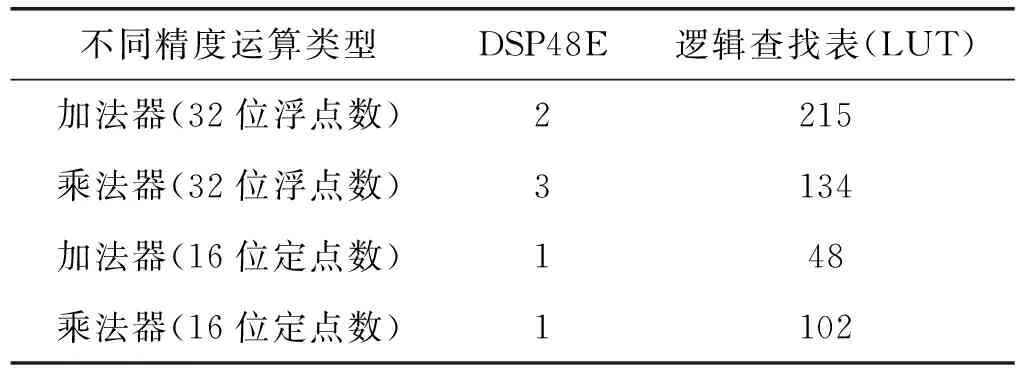
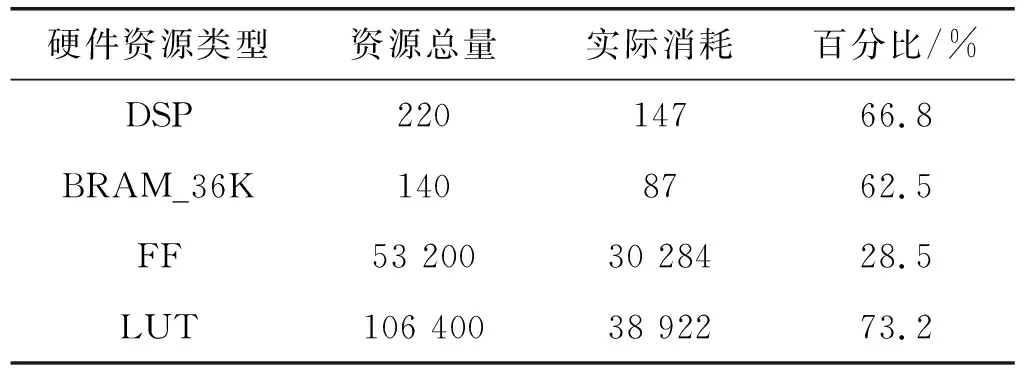
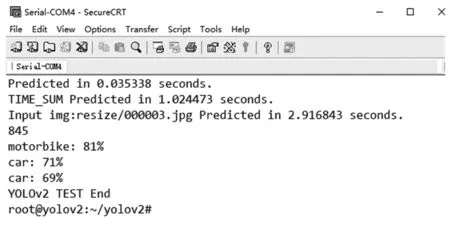
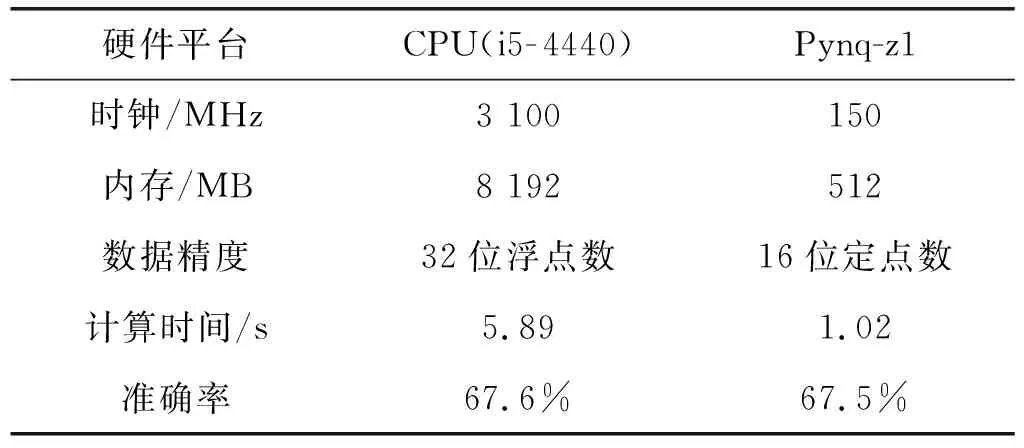
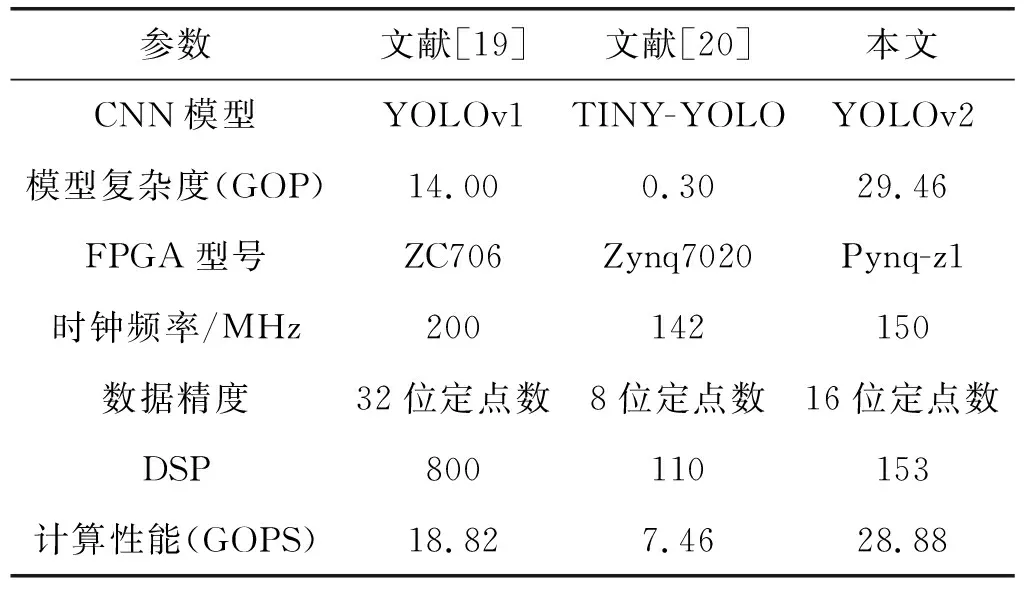
因此,一次卷积运算总延迟时间T2 在YOLOv2模型中每层网络的特征图像素值,权值参数和偏置参数均采用32位浮点数,为了降低YOLOv2网络模型的复杂度,提高模型的推理速度,同时节约FPGA内部的硬件资源,本设计采用16位定点数量化模型。由实际测试可知不同精度消耗FPGA内部乘法器和加法器的硬件资源如表2所示。 表2 不同精度资源消耗 由表可知,采用16位定点数相比32位浮点数将节省一半以上的硬件资源。同时,实际测试发现16位定点数量化YOLOv2网络模型准确率几乎不变。 本设计采用Xilinx公司的pynq-z1异构平台,主控芯片为zynq- 7020。该芯片采用双核ARM A9处理器和FPGA架构,其中,ARM处理器端时钟频率为667 MHz,DDR3内存大小为512 MB,FPGA端内部硬件资源DSP48E、BRAM_36K、LUT和FF分别为220、140、53 200、106 400。本设计采用HLS软件完成YOLOv2网络模型硬件加速器的设计,然后将加速器IP导入Vivado软件中完成综合和实现后,得到硬件资源消耗如表3所示。 表3 zynq- 7020硬件资源消耗 同时,本设计对比CPU平台的YOLOv2网络模型实现,CPU平台硬件参数为Intel 4核酷睿i5- 4440处理器,主频为3.1 GHz,DDR3内存大小为8 GB。 本设计在验证YOLOv2网络加速器的结果正确性时,从COCO数据集的测试集中选取100幅交通工具图片作为验证,交通工具图片主要包括人、自行车、汽车、摩托车、飞机、公共汽车、火车、货车以及红绿灯交通标志等类别。实验在Pynq-z1开发板上的测试结果如图8所示。 图8 SecureCRT串口终端测试结果 首先,通过Xilinx公司的Petalinux工具定制嵌入式Linux系统,包括镜像文件、uboot文件和根文件系统。将以上3个文件烧录SD卡中,通过UART串口将PC与Pynq-z1开发板连接,在PC上通过串口终端SecureCRT软件显示检测结果,并与PC端下测试结果进行对比。 通过测试结果表4发现,本文设计的硬件加速器在保证准确率几乎不变的情况下,分辨率为416×416的单幅图片计算时间缩短为1.02 s,极大提高网络推理速度。 表4 不同硬件测试结果对比 同时,本设计与之前已有工作的硬件加速器进行对比,如表5所示。本设计的硬件加速器使用Xilinx公司的HLS软件,采用C/C++语言进行编程,并使用优化指令对算法中的数组和For循环进行资源和性能的优化。本设计在输入输出接口部分充分使用双缓存设计,通过乒乓操作,使读取和写入数据与计算同时进行,有效节省传输时延。本文为了降低模型在硬件部署上的难度,提前将YOLOv2网络中的Bn层与权重和偏置参数进行融合。在FPGA硬件部署上针对卷积模块采用输入输出二维循环展开和分块的思想,合理设计并行乘法器的个数,提高硬件加速器的吞吐量。 表5 与已有的硬件加速器性能对比 本文设计的硬件加速器的计算性能通过GOPS(Giga Operation Per Second)指标来衡量。其中,使用GOP(十亿次操作)来衡量CNN模型的复杂度。本文采用CNN模型与文献[19]和文献[20]对比,模型复杂度最大,同时,本文设计的硬件加速器的计算性能高于文献[19]和文献[20]。 本文针对目标检测模型YOLOv2,设计一种基于FPGA的硬件加速器。该硬件加速器针对YOLOv2网络模型中的卷积层,采用输入输出二维循环展开和循环分块的方法。通过对卷积层硬件单元的设计,使用128个乘法单元并行计算,提高整个网络的计算性能。本文在硬件加速器的输入输出接口部分采用双缓存设计,通过乒乓操作使读取,写入和片上计算单元能够并行操作,降低传输时延带来的计算性能损失。同时,为了降低网络模型的准确率损失和减少硬件资源的消耗,本文采用16位定点数对权重参数,偏置项参数以及输入输出特征图的像素值进行量化。实验结果显示,本文设计的硬件加速器与通用CPU酷睿i5- 4440处理器相比,计算性能提高5.77倍,同时,在COCO数据集上保持准确率几乎不变。除此之外,本文设计的硬件加速器在时钟频率为150 MHz,计算性能达到28.88 GOPS。2.4 计算精度量化
3 结果分析与讨论
3.1 实验软硬件环境
3.2 结果验证和性能测试对比
4 结 语
