基于特征空间多分类对抗机制的红外与可见光图像融合
2023-03-27张浩马佳义樊凡黄珺马泳
张浩 马佳义 樊凡 黄珺 马泳
(武汉大学电子信息学院 武汉 430072)
图像融合旨在从不同传感器或不同拍摄设置捕获的图像中提取最有意义的信息,并将这些信息融合生成单幅信息更完备、对后续应用更有利的图像[1-3].红外与可见光图像融合是应用最为广泛的图像融合任务之一.具体来说,红外传感器对成像环境较鲁棒,所捕获的红外图像具有显著的对比度,能有效地将热目标与背景区分开.然而,红外图像往往缺乏纹理细节,不符合人类的视觉感知习惯.相反,可见光图像往往包含丰富的纹理细节,但容易受天气、光照等因素影响,且无法有效突出目标.红外与可见光图像融合致力于同时保留这2 种模态的优异特性,以生成既具有显著对比度又包含丰富纹理细节的图像.由于融合图像的优良特性,红外与可见光图像融合已被广泛应用于军事探测、目标监控以及车辆夜间辅助驾驶等领域[4-5].
现存的红外与可见光图像融合方法根据其原理可分为传统方法和基于深度学习的方法.传统方法通常利用相关的数学变换在空间域或变换域进行活动水平测量,并设计相应的融合规则来实现图像融合[6].代表性方法有:基于多尺度变换的方法[7-8]、基于稀疏表示的方法[9]、基于子空间的方法[10]、基于显著性的方法[11]以及混合方法[12].一般来说,这些传统方法手工设计的活动水平测量及融合规则具有较大的局限性:一方面,源图像的多样性势必会使这些手工设计越来越复杂;另一方面,这也限制了融合性能的进一步提升,因为不可能以手工设计的方式考虑所有因素.
近年来,深度学习的快速发展推动了图像融合领域的巨大进步.基于深度学习的融合方法凭借神经网络强大的特征提取和图像重建能力,不断提升融合性能[13].根据图像融合的实现过程,现存的基于深度学习的图像融合方法可以分为端到端融合方法和非端到端融合方法.端到端融合方法[14-17]通常在损失函数的引导下隐式地实现特征提取、特征融合及图像重建,其损失函数被定义为图像空间中融合图像与源图像绝对分布(如像素强度、梯度等原始图像属性)之间的距离,如图1 所示.在这一类方法中,图像融合网络的优化实际上是寻求红外与可见光图像绝对分布的中和比例,这势必会造成有益信息被削弱,如纹理结构和热目标被中和.

Fig.1 Schematic of the end-to-end fusion method图1 端到端融合方法示意图
非端到端融合方法一般基于自编码网络,其先用编码器实现特征提取,然后使用融合策略聚合提取到的特征,最后使用译码器对融合特征进行译码实现图像重建.然而,在现存非端到端图像融合方法中,所采用的中间特征融合策略仍然是传统的[18],如Mean 策略、Max 策略以及Addition 策略等,如图2 所示.这些融合策略是全局的,不能根据输入图像来自适应地调整,融合性能十分有限.比如,Mean 策略对输入特征直接取平均,会造成显著目标的亮度被中和;Addition 策略直接将输入特征相加,会造成部分区域亮度中和或饱和.

Fig.2 Schematic of the non-end-to-end fusion method图2 非端到端融合方法示意图
为了解决上述挑战,本文提出一个基于特征空间多类别对抗机制的红外与可见光图像融合网络,显著提升了融合性能.首先,该方法基于自编码网络,利用编码器网络和译码器网络显式地实现特征提取和图像重建.其中,编码器网络引入了空间注意力机制来关注更重要的区域,如显著目标区和丰富纹理区;译码器网络引入通道注意力机制来筛选对重建图像本身更有利的通道特征,如高频特征通道和包含了显著性目标的低频特征通道.此外,译码器网络还采用了多尺度卷积,其可以从不同尺度处理特征,从而在重建过程中更好地保留细微纹理.然后,采用生成式对抗网络(generative adversarial network,GAN)实现中间特征融合策略的可学习化.具体来说,本文设计了一个特征融合网络作为生成器来融合由训练好的编码器提取的特征,其致力于生成同时符合红外和可见光2 种模态概率分布的融合特征.提出一个多分类器鉴别器,其致力于区分红外特征、可见光特征以及融合特征.特征融合网络和多分类器鉴别器持续地进行多分类对抗学习,直到多分类器鉴别器认为融合特征既是可见光特征,又是红外特征.此时,特征融合网络便能保留红外图像和可见光图像中最显著的特性,从而生成高质量的融合特征.最终的融合图像由训练好的译码器网络对融合特征译码得到.值得注意的是,所提方法采用的多分类对抗机制区别于传统GAN[19]的二分类对抗,其更符合图像融合任务的多源信息拟合需求.与当前基于GAN 的图像域对抗融合方法[16]也不同,所提方法首次将生成对抗机制引入特征空间,对技术路线中的“特征融合”环节更具针对性.更重要的是所提方法摆脱了当前几乎所有的基于GAN 的融合方法都需要的距离(内容)损失,仅在GAN 分类决策所捕获的模态概率分布(如对比度、纹理等模态属性)之间构建损失,有效地避免了有益信息的削弱,从而实现显著热目标和丰富纹理结构的自适应保留.
所提方法有两大优势:1)相较于现存端到端的融合方法,本文方法没有使用融合图像与源图像绝对分布之间的距离作为损失函数,而是在分类决策捕获的模态概率分布之间建立对抗损失,从而避免有益信息被削弱.2)相较于现存非端到端的融合方法,所提方法将中间特征融合策略可学习化,能够根据输入图像自适应地调整融合规则,较好地保留了源图像中的显著对比度和丰富纹理细节.这种智能融合策略可以避免传统融合策略造成的亮度中和或饱和以及信息丢失等问题.为了直观展示所提方法的优势,选取了代表性的端到端融合方法U2Fusion[15]和非端到端融合方法DenseFuse[18]来对比显示,其中DenseFuse 按照原始论文建议选取了性能相对较好的Addition 策略,融合结果的差异如图3 所示.可以看出,U2Fusion 的融合结果中出现了典型的亮度中和现象,目标建筑物的亮度没有被保持,纹理结构也很不自然.DenseFuse 使用Addition 融合策略,虽然能较好地维持纹理结构的显著性,但目标建筑物的亮度依旧被削弱.相比之下,本文方法能显著地改善这些问题,融合结果不但准确地保持了目标建筑物的亮度,而且包含丰富的纹理细节.这得益于所提方法中特征融合网络的优异性能,其能自适应地保留红外与可见光的模态特性.
本文的主要贡献有3 个方面:1)提出了一个新的红外与可见光图像融合网络,其利用多分类对抗机制将传统融合策略扩展为可学习,具有更好的融合性能.2)所提模型将现存方法中融合图像与源图像绝对分布之间的距离损失扩展为模态概率分布之间的对抗损失,有效避免了现存融合方法中有益信息被削弱的问题.3)本文方法具有良好的泛化性,可以推广到任意红外与可见光图像融合数据集.

Fig.3 Comparison of fusion performance图3 融合性能对比
1 相关工作
本节回顾和所提方法最相关的技术和工作,包括基于深度学习的融合方法及GAN.
1.1 基于深度学习的图像融合方法
近几十年,基于深度学习的融合方法凭借神经网络强大的特征提取和图像重建能力,获得了远超传统方法的性能[20].现存的基于深度学习的图像融合方法可以分为端到端融合方法以及非端到端融合方法.
端到端融合方法通常直接使用一个整体网络将输入的红外和可见光图像进行融合.换句话说,融合的各个阶段如特征提取、特征融合以及图像重建都是隐式的.端到端融合方法可根据所采取的架构分为基于卷积神经网络的融合方法[21-22]和基于GAN 的融合方法[23-25].这些方法的共性在于依赖融合图像与源图像绝对分布之间的距离损失.例如,PMGI[14]在融合图像和2 幅源图像间建立强度和梯度距离损失,并通过调节损失项的权重系数来调整信息融合过程中的保留比例,从而控制融合结果绝对分布的倾向性.U2Fusion[15]则在融合图像和2 幅源图像间建立强度和结构相似度损失[26],并通过度量特征图的信息质量来自适应地调整损失项系数,从而引导融合图像保留有效信息.不幸的是,这种融合图像与2 幅源图像绝对分布之间的距离损失会建立一个博弈,导致最终融合图像是2 幅源图像原始属性(如像素强度、梯度)的折中,不可避免地造成有益信息被削弱.除此以外,武汉大学的Ma 等人[16]将GAN 架构引入到图像融合领域并提出了引起广泛关注的FusionGAN,其中网络的优化不仅依赖图像绝对分布之间的距离损失,还依赖模态概率分布之间的对抗损失.随后,文献[16]的作者引入双鉴别器来平衡红外与可见光信息以进一步提升融合性能[17],但是网络优化仍离不开图像绝对分布之间的内容损失,这意味有益信息的丢失问题仍然存在.
非端到端融合方法主要是基于自编码架构[27],其特征提取、特征融合以及图像重建3 个阶段都是非常明确的,由不同的网络或模块来实现.现存非端到端图像融合方法的融合质量一直受融合策略的性能制约.具体来说,现存的基于自编码结构的融合方法采用的融合规则都是手工制作的,且不可学习.例如,DenseFuse[18]采 用 Addition 策略和l1-norm 策 略;SEDRFuse[28]采用最大值策略.这些策略不能根据输入图像自适应地调整,可能会造成亮度中和或过饱和、信息丢失等问题,因此,研究可学习的融合规则非常有意义.
1.2 GAN
原始GAN 由Goodfellow 等人[19]于2014 年提出,其由一个生成器和一个鉴别器组成.生成器是目标网络,致力于生成符合目标分布的伪数据;鉴别器是一个分类器,其负责准确分辨出真实数据和生成器伪造的假数据.因此,生成器和鉴别器之间是敌对关系.也就是说,生成器希望生成鉴别器无法区分的伪数据,而鉴别器则希望能准确鉴别出伪数据.生成器和鉴别器不断迭代地优化,直到鉴别器无法区分是真实数据还是由生成器产生的伪数据.此时,生成器便具备生成符合目标分布数据的能力.下面,我们形式化上述对抗学习过程.
假设生成器被表示为G,鉴别器被表示为D,输入到生成器的随机数据为Z={z1,z2,…,zn}~Pz,目标数据为X={x1,x2,,…,xn}~PX.那么,生成器致力于估计目标数据X的分布PX,并尽可能生成符合该分布的数据G(Z),而鉴别器D需要对真实数据X和生成的伪数据G(Z)进行准确区分.总而言之,GAN 的目的就是在不断地对抗训练中使得伪数据的分布PG不断逼近目标数据分布PX.因此,GAN 的目标函数被定义为
随着研究的深入,研究者发现使用交叉熵损失的原始GAN 在训练过程中非常不稳定,且生成结果质量不高.最小二乘GAN[29]的提出改善了这一现象,其使用最小二乘损失作为损失函数,引入标签来引导生成器和鉴别器的优化.最小二乘GAN 的目标函数被定义为
其中r,s,t是对应的概率标签.具体来说,r是鉴别器判定目标数据集合X中数据xi对应的标签,设定r=1;s是鉴别器判定由生成器构造的伪数据G(zi)对应的标签,设定s=0;t是生成器希望鉴别器判定伪数据G(zi)对应的标签,设定t=1.
2 本文方法
本节详细描述提出的基于特征空间多分类对抗机制的红外与可见光图像融合网络.首先,我们给出问题建模,然后介绍网络详细结构,最后提供损失函数的具体设计.
2.1 问题建模
从定义上来说,图像融合是从源图像中提取最有意义的特征,将它们融合并重建包含更丰富信息的单幅图像.因此,图像融合的整个过程可以分为3个阶段:特征提取、特征融合以及图像重建.基于上述思想,本文提出一个基于特征空间多分类对抗机制的红外与可见光图像融合网络,其总体框架如图4所示.

Fig.4 Overall framework of the proposed method图4 本文方法的总体框架图
首先,鉴于自编码器网络的“低维—高维—低维”映射理念非常契合特征提取和图像重建这2 个环节,所提方法提出一个引入注意力机制的自编码器网络来实现特征提取和图像重建.其中,编码器网络EI中的空间注意力机制能使得低维向高维映射时更关注那些包含重要信息的区域,如包含丰富纹理或显著热目标的区域;而译码器网络DI中的通道注意力机制则使得高维向低维映射时更关注对重建图像更有利的通道特征,如高频特征通道和包含显著目标的低频特征通道.除此以外,译码器网络DI还引入了多尺度卷积来加强对细微空间纹理的保留.
其次,使用训练好的编码器网络EI从红外和可见光图像中提取特征,并设计一个特征融合网络F来融合这些特征,这种可学习的特征融合策略比现存方法所使用的传统融合策略具有更强的性能.具体来说,所提的特征融合网络F被当作生成器,然后结合使用1 个多分类鉴别器MD,二者构成特征空间上的生成式对抗网络.特征融合网络F致力于同时估计红外与可见光2 种模态特征概率分布,以生成同时符合这2 种模态概率分布的融合特征;而多分类鉴别器MD则致力于准确区分可见光特征、红外特征以及特征融合网络生成的融合特征.经过持续的对抗学习,直到多分类鉴别器认为融合特征既是红外特征又是可见光特征,此时该融合特征便具备了红外和可见光2 种模态中最显著的特性.值得注意的是,所提模型中生成式对抗网络的优化仅依赖于模态概率分布之间的对抗损失,不依赖绝对分布之间的距离损失,这极大地避免了现存方法中存在的有益信息被削弱问题.最终,将特征融合网络F生成的融合特征经训练好的译码器网络DI译码得到高质量的融合图像Ifused.整个融合过程可以被形式化为
其中Iir和Ivis分 别表示红外图像和可见光图像;EI(·)表示编码器网络对应的功能函数,F(·)表示特征融合网络对应的功能函数,DI(·)表示译码器网络对应的功能函数.
2.2 网络结构
本文所提红外与可见光图像融合网络包括2 部分:负责特征提取和图像重建的自编码器网络;负责融合规则学习的GAN.
2.2.1 自编码器网络
自编码器网络是一种经典的自监督网络,其以重建输入数据为导向,先利用编码器网络将图像映射到高维特征空间,再利用译码器网络将高维特征重新映射为图像.因为译码器网络重建图像的质量依赖于中间高维特征的质量,所以编码器网络必须能提取具有高表达能力的特征,而译码器网络必须具备从中间特征准确重建出源图像的能力.本文提出了一种新的自编码器网络来实现融合过程中的特征提取和图像重建,如图5(a)所示.
编码器网络EI使用10 个卷积层从源图像中提取特征,其中卷积核尺寸均为 3×3,激活函数均为lrelu(leaky relu).在第5 和第9 层后,使用空间注意力模块对所提特征沿空间位置加权,以增强特征中重要的空间区域(如显著目标、结构纹理).空间注意力模块[30]的网络结构如图5(b)所示,可以看到,空间注意力模块先使用最大池化和平均池化对固定空间位置不同通道的信息进行聚合,然后使用1 个卷积层处理串接的聚合特征,以生成与原始特征空间尺寸相同的注意力谱.该注意力谱本质上是一系列学习到的权重,对输入特征沿着空间维度进行选择性加权,从而实现感兴趣区域特征的增强.在编码器中使用空间注意力模块可以有效满足对感兴趣特征的提取偏好,提升编码特征的表达能力.此外,编码器还将密集连接[31]和残差连接[32]相结合,其一方面把浅层特征不断跳跃连接到深层网络以增强后续特征表达能力和增加特征利用率,另一方面残差连接也避免了特征提取过程出现的梯度消失和爆炸问题.

Fig.5 Structures of the autoencoder network for feature extraction and image reconstruction图5 用于特征提取和图像重建的自编码器网络结构图
在译码器网络DI中,先使用2 个结合通道注意力模块的多尺度卷积层处理由编码器网络EI提取的中间特征.在每个多尺度卷积层,3 个具有不同尺寸卷积核的卷积层并行处理输入特征,其卷积核尺寸分别为 7×7,5 ×5,3 ×3,激活函数均为lrelu.通道注意力模块[30]的网络结构如图5(c)所示,其先使用最大池化和平均池化对固定通道不同空间位置的特征进行聚合,然后在2 个分支中分别使用2 个卷积层对聚合特征进行处理,最后将2 个分支的处理结果求和得到最终的注意力谱.该注意力谱是一个长度与输入特征通道数相同的向量,表示将为输入特征每个通道分发的权重.在自监督重建的优化导向下,译码器将自适应地关注对重建更重要的特征通道,从而提升重建精度.最后,使用3 个卷积核尺寸为 3×3的卷积层来重建源图像.其中,除了最后一层,其他卷积层均使用lrelu作为激活函数,最后一层使用tanh 作为激活函数.在上述特定设计下,所提自编码网络具有强大的特征提取和图像重建能力.
2.2.2 GAN
本文设计了一种新颖的特征融合规则构建方式,其利用GAN 将融合策略可学习化,从而获得更好的融合性能,如图6 所示.
首先,特征融合网络F在对抗架构中扮演生成器的角色,其将训练好的编码器网络EI提取的红外特征Feair和可见光特征Feavis进行融合,生成融合特征Feafused.在特征融合网络F中,先使用3 个卷积核尺寸为3×3、激活函数为lrelu的卷积层来处理输入的红外特征与可见光特征.然后,采用3 个分支来分别预测融 合权重 ωir,ωvis以及偏差项 ε.每 个分支包含2个卷积层,其卷积尺寸均为3×3.在融合权重预测分支,2 个卷积层分别使用lrelu和sigmoid作为激活函数;在偏差预测分支,2 个卷积层的激活函数均为lrelu.融合特征可以被表示为
其次,使用1 个多分类鉴别器MD来区分红外特征Feair、可见光特征Feavis以及特征融合网络F合成的融合特征Feafused.在多分类鉴别器MD中,先使用4 个卷积层来处理输入特征,它们的卷积核尺寸均为3×3,激活函数均为lrelu.然后,处理后的特征被重塑为1 个1 维向量,并使用1 个线性层来输出1 个1×2 的预测向量,分别表示输入特征为红外特征的概率Pir,以及输入特征为可见光特征的概率Pvis.特征融合网络F和多分类鉴别器MD连续地对抗学习,直到多分类鉴别器MD认为生成器产生的融合特征既是红外特征又是可见光特征,此时特征融合网络F便学会合理的融合规则.
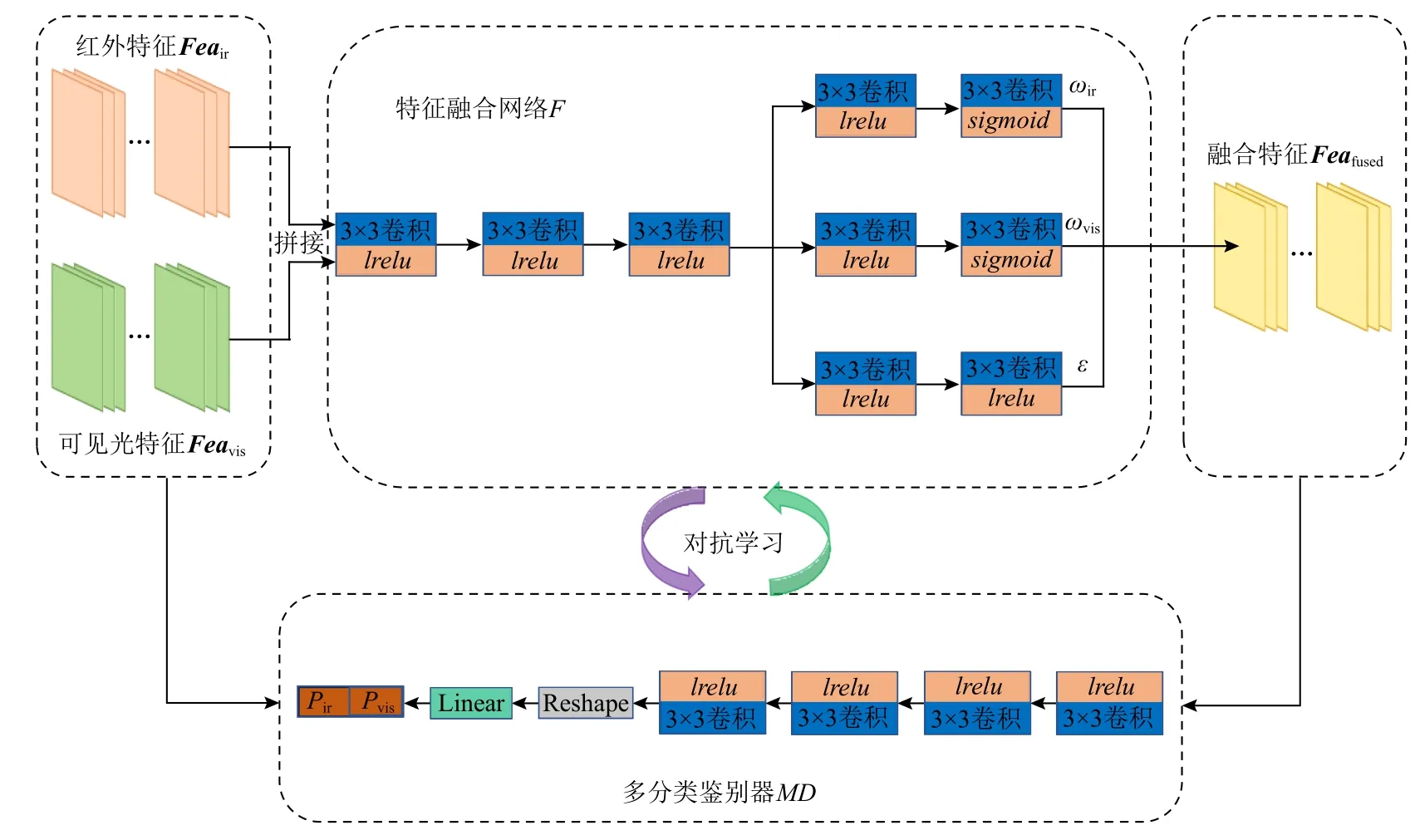
Fig.6 Structures of generative adversarial network for fusion rule learning图6 用于融合规则学习的生成式对抗网络结构图
2.3 损失函数
本文的损失函数包括2 部分:自编码器网络损失函数和生成式对抗网络损失函数.
2.3.1 自编码器网络损失函数
自编码器网络先利用编码器网络EI将低维图像映射为高维特征,再利用译码器网络DI重新将高维特征映射为低维图像.也就是说,自编码器网络致力于重建输入图像.所提方法在强度域和梯度域构建重建图像与输入图像的一致性损失:
其中 LAE是自编码器网络的总损失,Lint是强度损失,Lgrad是 梯度损失,β是平衡强度损失项和梯度损失项的参数.值得注意的是,自编码器网络的训练同时在红外图像与可见光图像上进行,即红外图像和可见光图像共享编码器网络EI和译码器网络DI的权重,因此对应的强度损失和梯度损失被定义为:
其中Iir和Ivis是输入源红外和可见光图像,是 自编码网络重建的红外和可见光图像,其可以表示为=DI(EI(I(·))).此 外,|·|是 ℓ1范 数,∇是Sobel 梯度算子,其从水平和竖直2 个方向来计算图像的梯度.在上述损失的约束下,编码器网络EI能较好地从源图像中提取特征,译码器网络DI则能从编码特征中准确地重建源图像.
2.3.2 GAN 损失函数
生成式对抗网络通过连续地对抗学习构建高性能融合规则,其网络优化仅依赖于模态概率分布之间的对抗损失,不依赖融合图像与源图像绝对分布之间的距离损失,极大地避免了有益信息被削弱.
对于特征融合网络F,其目的是产生可以骗过多分类鉴别器MD的融合特征Feafused,即让MD认为所生成的融合特征Feafused既是红外特征Feair又是可见光特征Feavis.因此,特征融合网络F的损失 LF为
其中MD(·)表示多分类鉴别器的函数,其输出是1个1×2 的概率向量.MD(Feafused)[1]指的是该向量的第1 项,表示多分类鉴别器判定输入特征是红外特征的概率Pir;MD(Feafused)[2]指的是该向量的第2 项,表示多分类鉴别器判定输入特征是可见光特征的概率Pvis.a是概率标签,设定a=0.5,即特征融合网络希望通过自身的优化使得多分类鉴别器无法区分融合特征是红外特征还是可见光特征.
与特征融合网络F成敌对关系,多分类鉴别器MD希望能准确判断输入特征是红外特征、可见光特征还是由特征融合网络F产生的融合特征.因此,多分类鉴别器损失 LMD包括3 部分:判定红外特征的损失 LMDir、判定可见光特征的损失 LMDvis以及判定融合特征的损失 LMDfused,即
其中,α1,α2,α3是平衡这些损失项的参数.当输入特征为红外特征Feair,多分类鉴别器判定的Pir应趋于1,Pvis应趋于0.对应的损失函数LMDir被定义为
其中b1和b2是 红外特征对应的概率标签,设定b1=1,b2=0,即多分类鉴别器应该准确识别出输入特征是红外特征而不是可见光特征.
类似地,当输入特征为可见光特征Feavis,对应的损失函数 LMDvis被定义为
其中c1和c2是可见光特征对应的概率标签,设定c1=0,c2=1,即多分类鉴别器应该准确识别出输入特征是可见光特征而不是红外特征.
当输入特征为融合特征Feafused,多分类鉴别器输出的Pir和Pvis都应趋于0.对应的损失函数LMDfused被定义为
其中d1和d2是 融合特征对应的概率标签,d1和d2都被设为0,即MD应能准确识别出输入特征既不是红外特征也不是可见光特征.
3 实 验
本节将在公开数据集上评估所提方法.5 个最先进的红外与可见光图像融合方法被挑选作为对比,包括GTF[12],MDLatLRR[33],DenseFuse[18],FusionGAN[16],U2Fusion[15].值得注意的是,在后续实验中,DenseFuse使用推荐的性能更好的Addition 策略.首先,提供实验配置,如实验数据、训练细节以及评估指标.其次,从定性和定量2 方面实施对比实验.本节还提供泛化性实验、效率对比及消融实验来验证所提方法的有效性.
3.1 实验设置
3.1.1 实验数据
本文选用TNO 数据集[34]和MFNet 数据集[35]作为对比实验的数据,TNO 数据集和MFNet 数据集用于测试的图像对数量分别为20 和200,用于训练的数据分别为裁剪得到的45 910 对和96 200 对80×80的图像块.此外,选用RoadScene[36]数据集作为泛化性实验的数据,用于测试的图像对数量为20.以上3个数据集中的图像对都已被严格配准[37].
3.1.2 训练细节
首先训练自编码器网络.在自编码器网络的训练过程中,批大小被设置为s1,训练1 期需要m1步,一共训练M1期.在实验中,设置为s1=48,M1=100,m1是训练图像块总数量和批大小s1的比率.自编码器网络训练好后冻结其参数,然后在训练好的编码器网络提取的特征空间中训练GAN.在GAN 的训练过程中,批大小被设置为s2,训练1 期需要m2步,一共训练M2期.在实验中,设置s2=48,M1=20,m2是训练图像块总数量和批大小s2的比率.无论是自编码器网络还是GAN,都采用Adam 优化器来更新参数.在整个训练结束后,将编码器网络、特征融合网络以及译码器网络级联组成完整的图像融合网络.值得注意的是,因为该图像融合网络是一个全卷积神经网络,输入可以是任意尺寸源图像对,即测试时不需要像训练那样对源图像进行裁剪.此外,根据经验,设定式(6)中的参数β=10,式(10)中的参数α1=0.25,α2=0.25,α3=0.5.所有的实验均在GPU NVIDIA RTX 2080Ti 及CPU Intel i7-8750H 上实施.
3.1.3 评估指标
本文从定性和定量2 个方面评估各方法的性能.定性评估是一种主观评估方式,其依赖于人的视觉感受,好的融合结果应同时包含红外图像的显著对比度和可见光图像的丰富纹理.定量评估则通过一些统计指标来客观评估融合性能,本文选用了7 个在图像融合领域被广泛使用的定量指标,如视觉信息保真度[38](visual information fidelity,VIF)、信息熵[39](entropy,EN)、差异相关和[40](the sum of the correlations of differences,SCD)、互信息[41](mutual information,MI)、质量指标[42](quality index,QAB/F)、标准差[43](standard deviation,SD)及空间频率[44](spatial frequency,SF).VIF测量融合图像保真度,大的VIF值表示融合图像保真度高;EN测量融合图像的信息量,EN值越大,融合图像包含的信息越多;SCD测量融合图像包含的信息与源图像的相关性,SCD越大意味着融合过程引入的伪信息越少;MI衡量融合图像中包含来自源图像的信息量,MI越大意味着融合图像包含来自源图像的信息越多;QAB/F衡量融合过程中边缘信息的保持情况,QAB/F越大,边缘被保持得越好;SD是对融合图像对比度的反映,大的SD值表示良好的对比度;SF测量融合图像整体细节丰富度,SF越大,融合图像包含的纹理越丰富.
3.2 TNO 数据集上的对比实验
3.2.1 定性对比
首先,在TNO 数据集上进行定性对比.5 组典型的结果被挑选来定性地展示各方法的性能,如图7所示.可以看出,本文所提方法有2 方面的优势:一方面,本文方法能非常精确地保留红外图像中的显著目标,它们的热辐射强度几乎没有损失,且边缘锐利;另一方面,所提方法也能很好地保留可见光图像中的纹理细节.
从融合结果的倾向性可以把对比方法分为2 类:第1 类是融合结果倾向于可见光图像的方法,如MDLatLRR,DenseFuse,U2Fusion.从图7 中可以看到,这一类方法的融合结果虽然包含丰富的纹理细节,但其对比度较差,热辐射目标被削弱.例如,在第1组结果中,MDLatLRR,DenseFuse,U2Fusion 对树木纹理保留得较好,但却削弱了目标建筑物的亮度.类似的还有第2 组中的水面、第3 组和第4 组中的人以及第4 组中的坦克.第2 类是融合结果倾向于红外图像的方法,如GTF 和FusionGAN.这一类方法能较好地保留热目标,但纹理细节不够丰富,它们的结果看起来很像是锐化的红外图像.如在图7 中的第1 组结果中,GTF 和FusionGAN 较好地保留了目标建筑物的显著性,但周边树木的纹理结构却不够丰富.类似地还有第2 组中的灌木、第3 组中的路灯以及第4 组中的树叶.本文所提方法综合了这2 类方法的优势.具体来说,所提方法既能像第1 类方法那样保持场景中的纹理细节,又能像第2 类方法那样准确保持热辐射目标.值得注意的是所提方法对热目标边缘保持得比第2 类方法更锐利.总的来说,本文方法在定性对比上优于这些最新方法.
3.2.2 定量对比
进一步,在20 幅测试图像上的定量对比结果如表1 所示.可以看出,本文所提方法在EN,SCD,MI,QAB/F,SD,SF这6 个指标上都取得最高平均值;在VIF上,本文方法排行第2,仅次于方法U2Fusion.这些结果说明:本文方法在融合过程中从源图像传输到融合图像的信息最多、引入的伪信息最少、能最好地保持边缘.生成的融合结果包含的信息量最大、有最好的对比度、具有最丰富的整体纹理结构.总的来说,本文方法相较于这些对比方法在定量指标上也是有优势的.
3.3 MFNet 数据集上的对比实验
3.3.1 定性对比

Fig.7 Qualitative results of the comparative experiment on TNO dataset图7 TNO 数据集上对比实验的定性结果
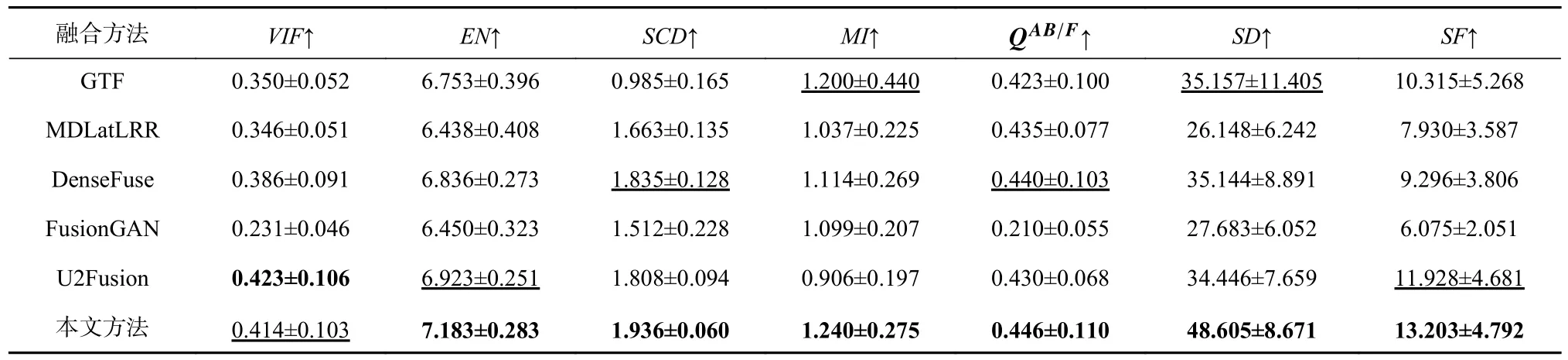
Table 1 Quantitative Results of the Comparative Experiment on TNO Dataset表1 TNO 数据集上对比实验的定量结果
在MFNet 数据集上实施定性对比实验,同样提 供5 组代表性的结果来展示各种方法的性能,如图8所示.可以看到,只有GTF,FusionGAN 以及本文方法能较好地维护红外图像中热辐射目标的显著度,但相较于这2 种方法,本文方法能更好地保持热目标边缘的锐利性,呈现良好的视觉效果.例如,在第3,4,5 组结果中,本文方法能较好地保持热目标行人的姿态,而GTF,FusionGAN 均由于边缘扩散导致轮廓模糊.相 反,MDLatLRR,DenseFuse,U2Fusion 太过于 偏重于保留结构纹理,而忽视了热辐射目标保留,这导致一些场景中目标削弱或丢失.例如,在第2 组结果中,汽车旁边的微小行人在这些方法的结果中被丢失.相较而言,本文方法能在热目标和结构纹理的保留上取得较好的平衡.例如,第1 组结果中,所提方法既维持了窗户的显著性,又保留了墙壁的纹理细节.总体而言,本文方法在MFNet 数据集的定性对比上比这些最新方法有优势.


Fig.8 Qualitative results of the comparative experiment on MFNet dataset图8 MFNet 数据集上对比实验的定性结果
3.3.2 定量对比
在MFNet 数据集中的200 幅测试图像上定量地对比这些最新方法以及本文所提方法,结果如表2所示.本文方法在EN,SCD,MI,SD这4 个指标上排行第1,在指标SF上排行第2,仅次于U2Fusion.这些客观结果表明本文方法所得结果包含的信息量最丰富、引入的伪信息最少,与源图像的相关性最大,以及具有最好的对比度,这些定量结果和图8 展示的视觉结果相符合.总的来说,本文方法在MFNet 数据集上的定量对比上比其他方法性能更好.
3.4 泛化性实验
本文所提方法能较好地迁移到其他数据集,也可以处理彩色可见光和红外图像融合.为了评估本文方法的泛化性,实施了泛化性实验.具体来说,使用RoadScene 数据集中的图像测试在TNO 数据集上训练得到的模型.由于RoadScene 数据集中的可见光图像是彩色图像,先将可见光图像从RGB 转换到YCbCr 色彩空间,然后融合Y 通道与红外图像.最后,将融合结果与Cb 和Cr 通道拼接在一起,并重新转换到RGB 色彩空间得到最终的融合结果.上述5 种对比方法在泛化性实验中仍然被采用,且评估仍然从定性和定量2 个方面来进行.

Table 2 Quantitative Results of the Comparative Experiment on MFNet Dataset表2 MFNet 数据集上对比实验的定量结果
3.4.1 定性对比
5 组代表性的定性结果被挑选来展示各方法的泛化能力,如图9 所示.可以看出,本文所提方法在RoadScene 数据集上仍具有良好性能,且相较于对比方法在纹理保持和显著目标保留2 个方面的优势仍十分明显.首先,在显著目标保持上,本文所提方法表现最好,如第1 组图像中的车辆、第2 组和第4 组中的骑行者,以及第3 组和第5 组中的行人.相反,在MDLatLRR,DenseFuse,U2Fusion 的融合结果中,这些显著目标被削弱.虽然GTF 和FusionGAN 相对这些方法能更好地保留显著目标,但其在目标边缘保护上却不如所提方法.其次,本文方法也能保证可见光图像中的纹理细节被很好地传输到融合图像中,如第1 组和第4 组结果中的云朵、第2 组和第3 组结果中的树木,以及第5 组结果中的广告牌,而GTF 和FusionGAN 做不到这些.因此,这些定性结果可以说明本文方法具有良好的泛化性,其能被迁移到RoadScene 数据集,并得到高质量的融合图像.
3.4.2 定量对比


Fig.9 Qualitative results of the generalization experiment图9 泛化实验的定性结果
定量实验被实施来进一步验证所提方法的泛化性能,结果如表3 所示.本文方法在EN,SCD,MI,SD这4 个指标上取得了最好的结果,在SF上取得了第2 好的结果.对于VIF和QAB/F,所提方法分别排行第4 和第3.总的来说,本文所提方法在RoadScene 数据集上的定量结果最好,这进一步说明了所提方法优良的泛化性.

Table 3 Quantitative Results of the Generalization Experiment表3 泛化实验的定量结果
3.5 效率对比
运行效率是评估方法性能的重要依据之一,为此,统计各方法在TNO,MFNet,RoadScene 数据集上的平均运行时间来比较运行效率,结果如表4 所示.本文所提方法在3 个数据集上都取得了最快的平均运行速度,比对比方法快5 倍以上.

Table 4 Mean of Running Time of Each Method on Three Datasets表4 各方法在3 个数据集上的平均运行时间 s
3.6 消融实验
在所提方法中,最终实现红外与可见光图像融合的框架包括编码器网络、特征融合网络以及译码器网络.为了验证它们的有效性,相应的消融实验被实施.
3.6.1 特征融合网络分析
特征融合网络的作用是将中间特征的融合策略可学习化,从而使得融合特征同时符合红外与可见光2 种模态特征的概率分布.相较于现存方法使用的传统特征融合策略,所提的特征融合网络具有更强的性能.为了验证这一点,将本文提出的用于特征提取和特征重建的编码器网络和译码器网络固定,中间特征融合规则分别用Mean 策略、Max 策略、Addition 策略、l1-norm 策略及所提特征融合网络,实验结果如图10 所示.

Fig.10 Ablation experiment results of feature fusion network图10 特征融合网络的消融实验结果
首先,由Mean 策略、Max 策略以及l1-norm 策略得到的结果的对比度都非常差,不仅显著目标被削弱,场景纹理结构也不够自然.Addition 策略虽然比这些策略的性能更好,但其无法自适应地选择性保留有益信息,以至于某些区域出现过度饱和或亮度中和的现象.比如,在第1 组结果中,由Addition 策略得到的结果没有充分保留水面的亮度;在第2 组结果中,建筑物的亮度又是过度饱和的.相反,采用本文所提的特征融合网络可以自适应地保留红外与可见光源图像中的显著特征,其不仅具有显著的对比度,而且包含丰富的纹理细节.这些结果可以说明所提特征融合网络的有效性.
3.6.2 自编码器网络分析
自编码器网络的作用是实现特征提取和图像重建,其性能对融合结果的质量影响很大.为了验证本文设计的自编码器网络的优势,将其与经典的DenseFuse[13]进行对比.具体地,我们控制融合规则保持相同(Addition 策略以及l1-norm 策略),使用本文提出的自编码器网络或DenseFuse 中的自编码器网络来提取特征和重建图像,实验结果如图11 所示.
对于Addition 策略,DenseFuse 结果中的显著目标被严重削弱,而本文方法却可以很好地保持它们.对于l1-norm 策略,DenseFuse 丢失了一些纹理结构,如云朵和椅子,而所提方法很好地保持了这些细节.总的来说,本文设计的自编码器网络的性能比DenseFuse 中的更强,其可以较好地实现特征提取和图像重建.
4 结论
综上所述,本文提出的基于特征空间多分类对抗机制的红外与可见光图像融合网络主要包括2 个部分:1)引入空间注意力机制,同时使用密集连接和残差连接来构建高性能编码器网络实现特征提取;引入通道注意力机制,同时使用多尺度卷积来构建高性能译码器网络实现图像重建.2)将融合策略网络化,引入多分类生成对抗机制使融合特征同时符合红外与可见光2 种模态的概率分布,从而构建高性能的深度融合策略.最终的红外与可见光图像融合网络由训练好的编码器、特征融合网络以及译码器级联而成,生成高质量的融合结果.相较于现存方法,所提方法可解释性好,能根据输入图像自适应生成更合理的融合策略,从而在源图像中同时保留丰富的纹理细节和显著的对比度,有效避免融合过程中有益信息的削弱问题.广泛的实验表明,所提方法与最新的融合方法GTF,MDLatLRR,DenseFuse,Fusion-GAN,U2Fusion 相比,融合性能更好.同时,本文方法的融合速度很快,较对比方法快5 倍以上.

Fig.11 Ablation experiment results of autoencoder图11 自编码器的消融实验结果
作者贡献声明:张浩提出方法思路,设计及实施实验,分析结果并撰写论文;马佳义构思和设计研究方向,对论文提出建设性的意见,并对手稿进行修改;樊凡协助实施实验,并分析实验结果;黄珺对论文提出建设性的意见,并对稿件进行了修改;马泳完善方法理论,并对稿件进行了修改.
