大规模结构网格数据的相关性统计建模轻量化方法
2023-03-27汪云海
杨 阳 武 昱 汪云海 曹 轶,3
1(北京应用物理与计算数学研究所 北京 100094)
2(山东大学计算机科学与技术学院 山东青岛 266237)
3(中物院高性能数值模拟软件中心 北京 100088)
大规模数值模拟是科学发现与工程设计不可或缺的关键手段,高置信度的数据可视分析对大规模数值模拟至关重要[1].随着高性能计算机的峰值性能的快速提升,为了精细模拟所研究问题的复杂特征,以尽可能高的计算效率将计算能力集中在问题的最关键部分,科学家常采用如图1 所示的非均匀分解的自适应网格,导致大规模多块数据的生成.然而,硬件存储瓶颈导致可视分析应用获取原始高分辨率数据越来越困难[2],大规模数值模拟应用先保存原始计算结果再进行事后可视分析的可行性不断降低.因此,数据约减势在必行.
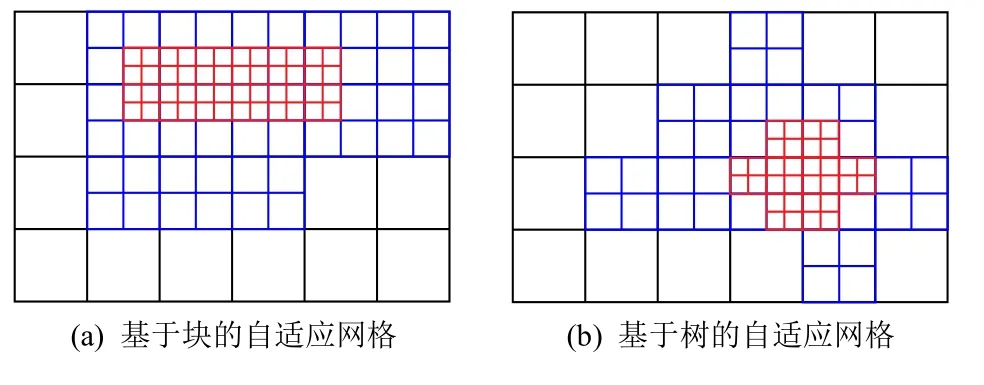
Fig.1 Adaptive mesh refinement图1 自适应网格
基于统计建模的数据轻量化方法[3-8]是一种主流的数据约减方法,它采用紧凑型的分布数据表达,替代传统的3 维网格数据表达,可以实现数值模拟数据规模的大幅约减,便于高效的事后可视分析[9-14].常用的分布数据表达有直方图(histogram)和高斯混合模型(Gaussian mixture model,GMM)[15-17].
然而,基于统计建模的数据轻量化方法的重建精度低,可视化不确定性高.主要原因是此类方法与数值并行区域分解策略产生的多块拼接网格数据的不适配性.因此,此类方法通常需要首先对原有的多块拼接网格数据进行合并;然后根据可视化的同质性需求,采用更适合可视分析方法的区域分解策略对合并数据进行重分,保证单块网格数据具有较小的数值梯度;最后,采用统计分布模型对每个数据块进行特征建模和可视分析.在大规模数值模拟场景下,这种建模方法会引起性能瓶颈和建模不确定2方面的问题[18].首先,数据合并与数据重分,将引起全局数据通信和高性能计算机节点间的大量数据迁移,导致显著的性能瓶颈问题.其次,不恰当的区域分解策略或统计分布模型,均会导致数据统计特征的丢失,进而增加可视分析的不确定性.能够适配数值并行区域分解策略的高精度统计建模与可视分析方法,仍有待开展研究.
为此,本文提出了一种大规模结构网格数据的相关性统计建模轻量化方法,其创新点有2 个方面:
1)提出了一种数据块间的相关性统计建模方法.在计算各单块网格数据的数值分布和空间分布后,利用信息熵与互信息表征数据块间的相关性,指导邻接数据块的统计建模.该方法通过耦合数据块的数值分布信息、空间分布信息和相关性信息,能够显著提升重建精度,降低可视化的不确定性.
2)本文方法保持初始数据分块不变,不需要对原始数据进行全局合并与重分,从而显著减少不同并行计算节点间的通信开销,降低计算成本.
实验结果表明,与现有方法相比,本文方法节省了数据合并与重分的计算成本,在获得更高重建精度的同时,将数据存储成本降低了约1 个数量级.
1 相关工作
1.1 网格数据压缩编码方法
压缩编码是传统常用的网格数据约减方法,分为无损和有损2 种压缩策略,但它很难适用于具有浮点数特征的数值模拟数据.例如,采用行程编码[19-20]、bZIP[21]等无损压缩算法,很难将数据压缩比提升到一个数量级.有损压缩则是相对有效的科学数据压缩途径.例如,几何驱动的静态有损压缩方法,它涉及网格顶点位置量化、预测、熵编码3 个主要处理阶段[22].面向不断增大的数据规模,渐近网格压缩方法逐渐成为研究热点,衍生出基于八叉树的渐近编码[23]、小波编码[24]、几何图像编码[25]等相关研究.但是,有损压缩算法无法在较大数据压缩比的前提下,同时高精度地保留原始高分辨数据的物理特征.
1.2 特征提取方法
特征提取方法使用特征数据替代原始数据场,从而实现数据轻量化.物理特征的定义形式包括等值面、流线、条纹线、矢量场拓扑、涡管、裂缝、断层线等.针对3 维数据场,目前通常采用“基于iso-value指定的等值数据范围”和“基于体绘制传递函数指定的不透明度到数值范围的映射”等方法进行空间特征提取.Tzeng 等人[26]使用标量值、梯度值和空间位置坐标训练传递函数,用于数据特征识别.Kindlmann等人[27]利用曲面曲率对数据样本进行特征分类.Tenginakai 等人[28]通过邻域统计信息定义数据等值面特征.Hladuvka 等人[29-30]借助等值面实现数据特征分离.但是,上述特征提取方法均依赖个性化特征定义,其普适性弱.
1.3 基于统计建模的数据轻量化方法
基于统计建模的数据轻量化方法,是目前有望解决大规模数据存储瓶颈的一种最新数据约减途径.它采用紧凑的分布数据表达,可以极大降低高分辨数据存储量,同时还能较好地保持数据蕴含的物理特征.Thompson 等人[15]使用直方图近似表示网格数据等值面.Wei 等人[13]提出了一种基于直方图的有效算法来搜索数据局部区域的相似分布.Liu 等人[16]和Dutta 等人[17]则使用GMM 对数据信息进行紧凑表达.然而这类方法的一个关键缺点是,其忽略了数据的空间分布信息,并最终导致基于统计建模方法的重建数据精度低,不确定性高.针对这一问题,Wang等人[31]提出了一种基于空间分布的数据轻量化方法,它使用直方图建模数值信息,GMM 建模空间分布信息,利用贝叶斯准则结合这2 类分布模型,最终显著提升重建数据精度.然而,受限于大规模数值模拟复杂的并行特征,文献[13,15-17,31]所述的轻量化方法无法直接适配多块拼接网格数据.因此,在大规模数值模拟场景下,这些方法势必会引起性能和建模不确定2 方面的问题.
1.4 相关性建模方法
现有的统计可视分析方法难以适应多块拼接数值模拟数据,无法在数据块的邻域边界保持重建精度.为此,近几年出现了相关性建模方法,它引入数据相关性来提升统计分布建模的精度.Dutta 等人[18]提出了一种基于数据固有空间相关性对数据进行聚类划分的方法,但该方法并不适用于数值并行计算阶段产生的多块拼接网格数据.Wang 等人[32]通过创建先验知识,捕捉低分辨率与高分辨率数据之间的相关性来提高重建精度,但先验知识的计算是十分耗时的.Hazarika 等人[33-34]从统计分析的角度出发,对多变量数据的相关性进行统计建模,从而降低重建数据的不确定性.目前,适用于数值并行应用区域分解策略的统计可视分析方法仍未开展研究.
2 基本概念
2.1 信息熵与互信息
在信息论中,信息熵(information entropy)是关于离散随机事件的出现概率.对于任意的概率分布,均可以定义信息熵以度量单个随机变量的不确定性.针对科学模拟数据,信息熵还可以作为一个数据复杂程度的度量[35].如果一个数据场越复杂,蕴含异质的物理特征越多,它的信息熵会越大;反之,数据场越简单,蕴含异质的物理特征越少,则它的信息熵将越小.联合熵(joint entropy)可用于度量一个联合分布随机系统的不确定性,它可以推广到互信息(mutual information),互信息可用于度量2 个随机变量之间的依赖关系.
将信息熵应用于数据轻量化问题的关键在于如何正确指定随机变量X,并定义其概率密度函数p(x)=Pr(X=x).在大多数情况下,可以启发式地定义这些概念函数以满足应用需求.本文将科学模拟数据集建模为离散随机变量,其区域内的每个数据点都对应物理场的一个数据值.因此,我们可以使用直方图对随机变量X的概率密度函数p(x)进行估计,即使用每个直方图Bin 区间的归一化频率作为相应的概率p(x).
本文使用信息熵、联合熵、互信息概念对数据相关性进行了建模.为便于理解,图2 为多块拼接结构网格数据中3 个相邻数据块X,Y,Z的信息熵与互信息示意图,其中,数据点的不同图案填充代表不同的物理 场变量 值.H(X),H(Y),H(Z)为数据 块直方 图的信息 熵;H(X,Y),H(X,Z),H(Y,Z)为直方 图之间 的联合熵;I(X,Y),I(X,Z),I(Y,Z)为直方 图之间 的互信息.由于联合熵与互信息具有对称性,为简化示意图,图2 在右上方加粗黑色框内展示联合熵与信息熵之间的关系,左下方加粗黑色框内展示互信息与信息熵之间的关系.
2.2 空间高斯混合模型
为了提升大规模数值模拟数据的重建精度,本文在数据建模过程还同时考虑空间位置信息,这构成了空间高斯混合模型(spatial GMM,SGMM)[31,36].SGMM可用于捕获相似数据值的空间分布特征.与将数值映射到概率的块高斯混合模型(block GMM)[14,16]不同,SGMM 将空间位置映射到概率.给定一个3 维空间位置p,则SGMM 定义为其中K是高斯函数分量的个数,ωk,µk,Σk分 别为第k个高斯函数分量的混合权重、均值向量和协方差矩阵.SGMM 的求解相当于一个包含缺失数据的参数估计问题,采用最大期望算法(expectation maximization algorithm)[36]可实现对其求解.
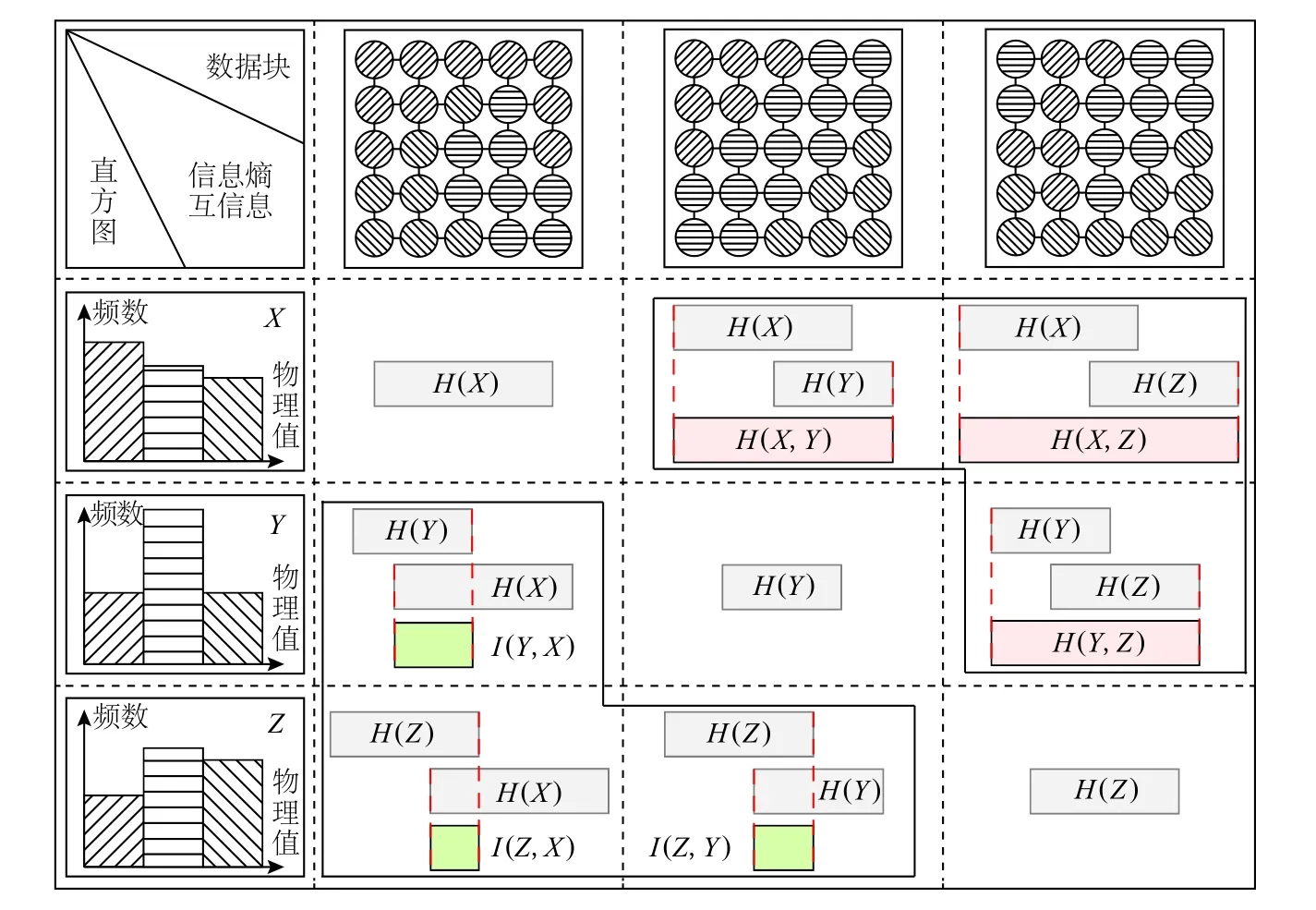
Fig.2 Information entropy and mutual information图2 信息熵与互信息
为了提高SGMM 的重建精度,目前的解决方案是根据可视化的需求对原始数据进行合并和重新分块.大规模多块数据的合并与重分会涉及并行计算节点之间的全局数据通信,导致显著的性能瓶颈问题.因此,随着并行通信模拟规模的逐渐扩大,减少全局通信对提高并行性能至关重要.本文方法利用相关性统计建模极大地降低了全局数据通信量.
3 相关性统计建模轻量化方法
为了适配数值并行应用区域分解策略,提升针对多块拼接结构网格数据的重建精度,实现大规模数值模拟数据的高效、高置信度可视分析,本文提出了一个大规模结构网格数据的相关性统计建模轻量化方法,它包括数据块内的统计分布建模、面向多块拼接网格数据的相关性统计建模、基于统计模型的数据重建与可视分析3 个阶段过程.特别地,本文的统计分布建模均采用了耦合了3 维空间位置信息的SGMM,SGMM 方法的总流程如图3 所示.
3.1 总体流程
给定一个多块均匀拼接网格数据,首先基于SGMM 进行逐块数据建模.每个数据块的统计模型,包含数值分布和空间分布2 类信息.本文针对数值分布,使用直方图进行数据表征;而针对落在直方图中同一个Bin 区间内的数据点,如它们具有相同或相似的数值,则要同时耦合该数值区间所对应网格数据点的空间分布,采用SGMM 进行数据表征.
其次,是逐块计算块内统计分布模型的信息熵.其中,一个数据块的统计模型对应的信息熵越大,则代表该块数据分布的不确定性越高,块内包含的信息量越大,并且将越逼近于均匀分布.针对均匀多块拼接的网格数据,每个数据块的1-邻域构成关系,可以分为图4 所示的4 种情况,深色立方体部分标记为中心数据块.针对中心数据块,计算其与1-邻域上每个数据块的统计分布模型的联合熵.特别地,联合熵越大,表明该邻接块的分布对中心块的分布所带来的影响越小.基于联合熵,可以获得中心数据块与其1-邻域数据块的统计分布模型的互信息.其中,互信息越大,表明2 个数据块之间的相关性越强.
然后,基于数据块之间的相关性感知采样,进行块间的统计分布相关性统计建模.其中,基于信息熵和互信息的理论,本文的相关性感知采样包含了3 项基本建模准则:1)信息熵越大的数据分布,越需要根据该块的邻接块的分布信息,对其进行相关性修正;2)与中心数据块分布具有较大互信息的邻接数据块,则其相关性系数越大;3)与中心数据块分布具有较大联合熵的邻接数据块,则其所需的相关性感知采样系数较小.如图3 所示,具有加粗黑色边框的子块区域代表一个中心数据块,其他8 个子块区域代表中心数据块的1-邻域数据块.图3 中数据点的不同图案填充,代表不同的物理场变量值.通过针对中心数据块及其邻域数据块的数值分布直方图进行相关性统计建模,本文方法可以提升中心数据块在边界附近的统计分布重建精度.随后,结合空间分布模型,即可得到关于中心数据块的相关性统计模型.
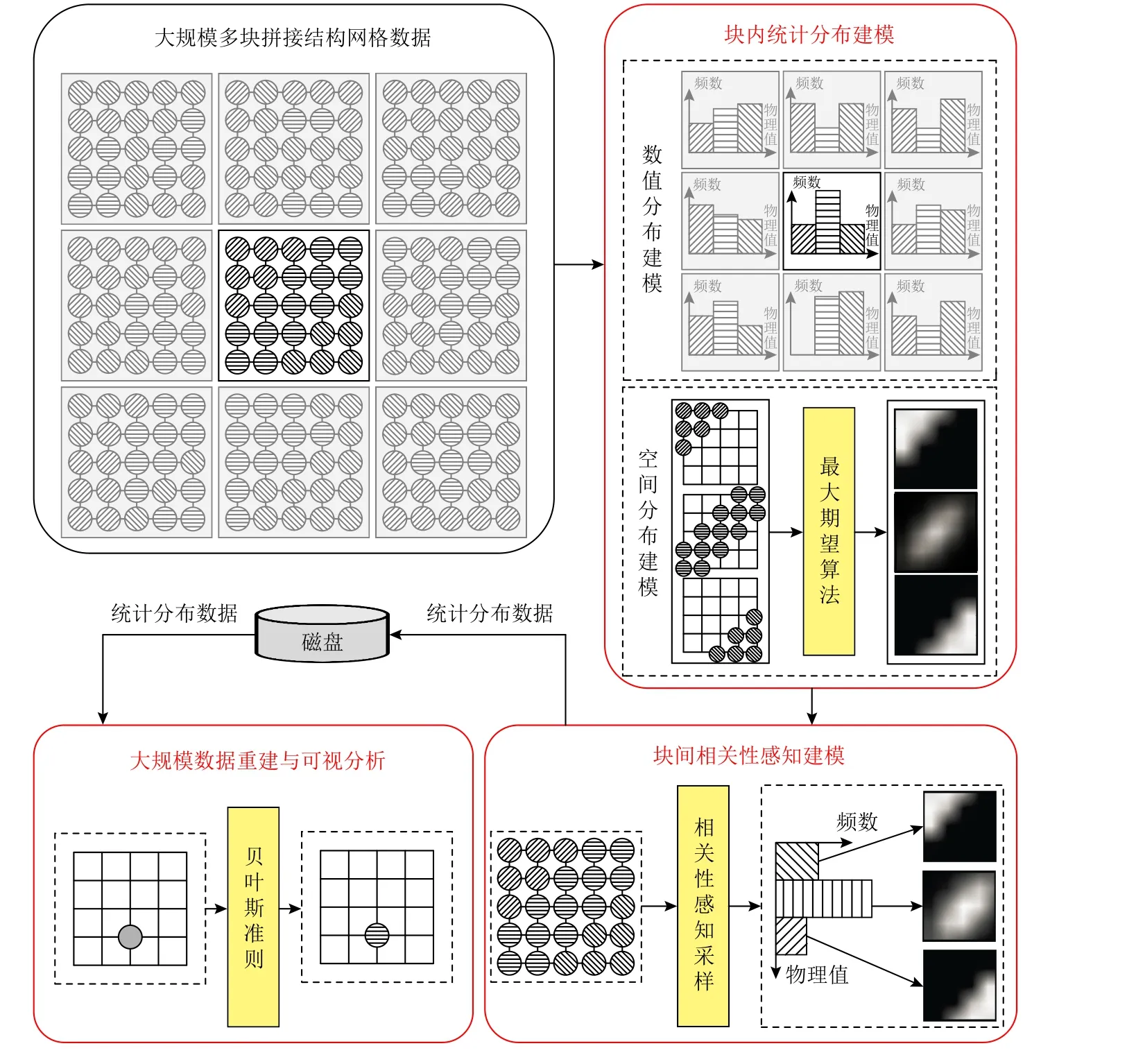
Fig.3 Method workflow of SGMM图3 SGMM 方法流程图
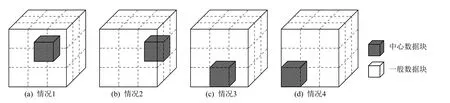
Fig.4 Four cases for 1-ring composition of a data block图4 数据块1-邻域的4 种分布情况
本文的统计建模过程,可以通过原位可视分析的紧耦合模式,直接对接大规模数值模拟应用,作用于数值模拟的计算结果输出过程,产生用于事后分析的统计分布数据.本文统计模型的数据表征方法,可以大幅降低大规模数值模拟应用的数据存储量,同时还能够高质量保持数据蕴含的物理特征,因此可以支撑事后的高效、高置信度可视分析.
最后,还需要统计分布模型的数据重建与可视分析.现有的可视分析算法均面向网格数据表征进行设计.因此,可视分析应用在读入统计分布模型表征的紧凑型数据后,还必须进行数据重建.数据重建包括网格拓扑构建和网格顶点上的变量数据重建2部分.对于结构网格应用,网格拓扑的构建无需依赖统计分布模型信息,重点在于网格顶点的变量数据重建.变量重建的过程,可以描述为:对于任意给定的一个空间位置坐标,在确定其所在数据块后,利用贝叶斯准则将数值分布、空间分布和相关性分布进行耦合,估计该空间位置坐标所对应的物理场数值,得到数据重建结果.
3.2 数据块内的统计分布建模算法
数据块内的统计分布建模算法,实现了每个结构网格数据块的高精度统计建模,是实现多块拼接结构网格数据高精度统计建模的基础.该算法包含了数值分布建模和空间分布建模2 部分.
首先,计算数据块内的数值分布模型.针对数据块尺寸为b的均匀拼接结构网格数据,分别计算其每个数据块的物理场变量的数值直方图.其中数值直方图Bin 区间的个数为M.以第i个 数据块Blocki为 例,其物理场变量记为Xi.使用直方图Histi对Xi的概率密度函数进行估计,Histi的每个Bin 区间对应一个数值区间.以第j个统计区间Binj为例,其相应的数值区间记为 [Lj,Uj],物理场数值属于该区间的网格采样点数目记为C,数据块Blocki内的网格采样点总数目记为Nb,则统计区间Binj的频率记为C/Nb.
其次,计算数据块内的空间分布模型.针对第i个数据 块Blocki的数值直方图Histi的 第j个统计区间Binj,使用2.2 节中介绍的方法,计算物理场变量值能够落在统计区间Binj内的网格采样点,然后根据这些网格采样点的空间位置坐标求解分布模型SGj.
需要注意的是,由于SGMM 为定义在无限空间内的近似分布,而非针对单一数据块,这势必会给数据块内物理场变量的概率密度函数带来一定的偏差,因此需要对其进行归一化处理:
其 中 Ωi为数据 块Blocki的空间 域,为SGj在Ωi上的累积概率.
3.3 面向多块拼接数据的相关性统计建模算法
面向多块拼接数据的相关性统计建模算法,考虑相邻数据块之间的统计分布特征,实现数据块边界的高精度统计建模,是多块拼接结构网格数据高精度统计建模的关键部分.基于3.2 节的块内统计建模结果,本节算法采用信息熵与互信息来表征数据块之间的相关性,指导邻接数据块的统计分布相关性感知采样,实现面向多块拼接结构网格数据的高精度统计建模.
首先,计算每个块内统计分布的信息熵和1-邻域内数据块间的联合熵与互信息.以第i个数据块Blocki为例,以Blocki为中心数据块,其1-邻域内数据块集合记为BSi,分别计 算信息熵H(Hi),联合熵H(Hi,),和互信息I(Hi,),其中为归一化处理后的数值分布直方图,且∈BSi.
其次,利用信息熵与互信息进行相关性感知采样计算.采样过程中需要用户预先设定信息熵阈值ε和互信息阈值δ .以Blocki为例,若H(Hi)>ε,则以Blocki为中心数据块,对其进行相关性感知采样.遍历其1-邻域内数据块集合BSi,若I(Hi,)>δ,则对中的网格点进行随机采样,采样比例Radd计算为
其中Hmax为联合熵的最大值.根据Radd对的空间域进行随机采样后得到的空间子域记为 Ωadd,Ωi更新为 Ωi∪Ωadd.利用更新后的 Ωi,将Hi更 新为.
特别地,相关性统计建模算法所涉及的信息熵阈值 ε和互信息阈值 δ,对模型重建精度和模型并行计算时间均具有显著影响.不同阈值参数的评估见本文实验部分(4.1 节).
3.4 基于统计模型的数据重建算法
采用统计模型表征,可以大幅降低大规模数值模拟在磁盘上的数据存储量.但是,为了适应现有可视分析方法,将分布数据表达恢复成可视分析可以处理的网格数据表达,还需要进行基于统计分布模型的网格数据内存重建.本节算法在块内统计建模算法和块间相关性统计建模算法的基础上,根据贝叶斯准则进行高质量的数据重建.本文算法中,重建数据采用了与原始数据一致的网格分辨率.
给定的3 维网格上的一个空间位置坐标p,首先要定位其所在的数据块Blocki,并且遍历的每个Bin 区间.其次,根据贝叶斯法则,计算位置p的物理场 数值落在第j个统计 区间Binj的概率:
4 实验结果与分析

Table 1 Test Data表1 测试数据
实验分别从重建精度和建模计算效能2 个方面进行测试与评估.首先,针对不同数据块尺寸参数b、信息熵阈值ε、互信息阈值 δ和多种统计分布模型,以及时变和大规模模拟数据应用,来评估本文方法的重建精度.其次,本文分别从模型并行计算时间和数据压缩比这2 个角度,评估本文方法对数值模拟实际应用的适用性和高效性.此外,本文在量化评估中使用归一化均方根误差(normalized root mean squared error,RMSE)和归一化最大误差(normalized maximum error,NME)来评估数据重建质量,它们的计算方法为:
其中X为原始数据,Y为重建数据,Xr为原始数据物理场变量的值域.此外,我们使用结构相似性(structural similarity,SSIM)[37]来度量2 组数据之间的相似性.
4.1 重建精度评估
4.1.1 不同数据块尺寸b的影响
数据块的尺寸代表了大规模数值模拟应用的区域分解特征.针对不同数据块尺寸的对比测试,用以评估本文方法对该类数值应用特征的典型适用性.
图5 展示了针对具有不同数据块尺寸的气候模拟飓风数据,给出基于SGMM 和本文提出的相关性统计模型的数据重建结果对比.其中,重建数据的可视分析采用了等值面绘制方法.分析结果显示,当数据块的尺寸相同时,SGMM 的重建结果显示出邻接数据块之间存在明显的数值不连续性,而本文方法却可以提升邻接块边界区域的数据重建精度,因此重建数据的数值不连续性得到了显著改善.这主要是由于SGMM 仅对单块网格数据进行独立统计建模,缺少了邻接数据块的统计分布信息.另一方面,通常建模采用的数据块尺寸越大,建模形成的统计分布数据的内存占用量越小,数据压缩比越大,并行计算时间越短,但是重建精度却越低.而本文方法通过相关性统计建模降低了数据块尺寸对重建精度的影响.因此,基于本文方法可以采用大尺寸数据块,获得与必须采用小尺寸数据块的SGMM 才能获得的同等甚至更高的重建精度.因此,本文方法实现了对大规模数值模拟应用并行特征更好的适应性,如图5(d)(e)所示.
4.1.2 不同信息熵阈值 ε的影响
本节主要讨论相关性统计建模中的关键参数之一,即信息熵阈值 ε选取对建模质量的影响与评估.
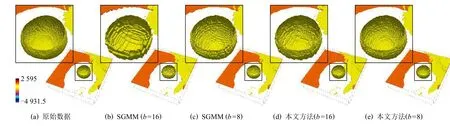
Fig.5 Reconstruction results of HD with different block sizes图5 气候模拟飓风数据在不同数据块尺寸的重建结果
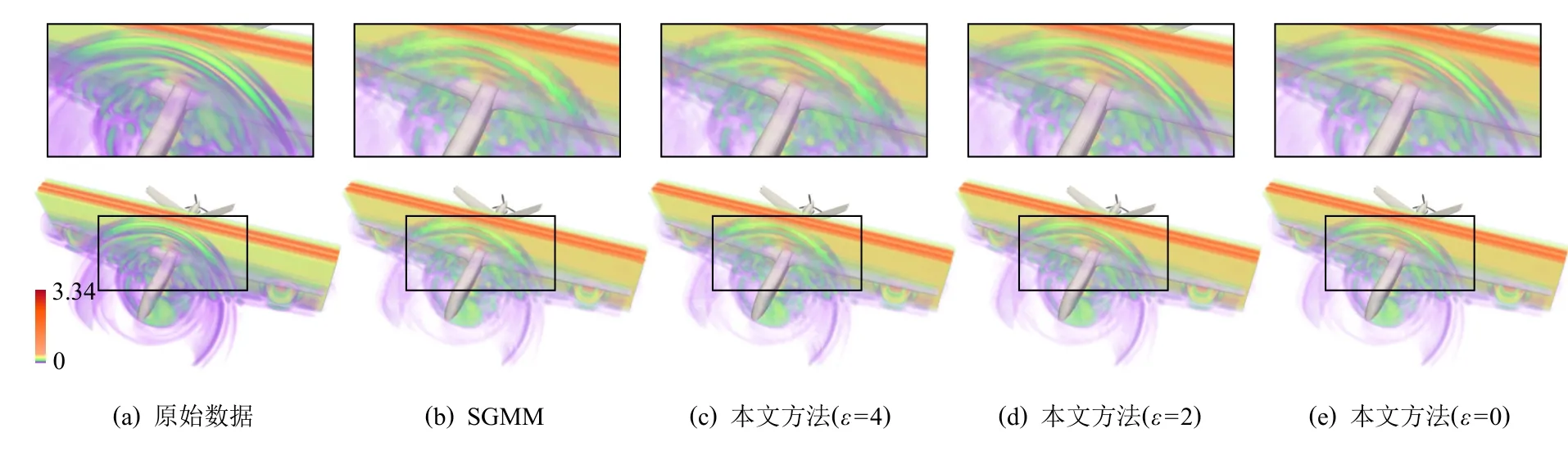
Fig.6 Reconstruction results of AED with different ε图6 飞行器电磁模拟数据在不同ε 的重建结果
图6 展示了不同信息熵阈值 ε参数设置下,使用SGMM 和本文所介绍的相关性统计模型对飞行器电磁模拟数据进行统计重建的体绘制结果.通过权衡数据压缩比、计算时间与重建精度三者,本实验设置数据块尺寸b=8 进行建模.由于该模拟数据的物理特征尺度小,在数据块尺寸b=8 时,数据重建会带来一定程度的局部精度损失,导致体绘制光线在数据空间上针对紫色属性数据的采样数量降低,故这些像素区域的体绘制累积不透明度低,导致颜色更淡、面积更小的现象.但是,相比图6(b),当设置 ε=2 和 ε=0时(图6(d)(e)),本文方法获得的重建数据及其体绘制结果具有更高的物质界面连续性.当原始数据场的网格分辨率进一步增大时,采用相同的数据块尺寸将可以获得重建精度更高的结果.图7 展示了信息熵阈值 ε的不同设置下,计算时间T、数据压缩比Rpre和重建精度RMSE,NME,SSIM的变化情况.结果表明,ε越小,进行相关性统计建模时需要耦合的数据块越多,重建结果的精度越高、不确定性越低;但数据压缩比越小,并行计算时间越长.通过权衡数据压缩比、计算时间与重建精度三者,本文默认设置ε=2(由于直方图Bin 区间个数的默认值为M=256,故 ε的最大值为8).如果用户对数据重建精度有更高的要求,并且可以处理更大的数据内存占用和更长的并行计算时间,则可以使用更小的信息熵阈值.图6(e)展示了ε=0 时相关性统计模型的重建结果,即在面向多块拼接数据的相关性统计建模算法中对所有数据块均进行了相关性统计建模.
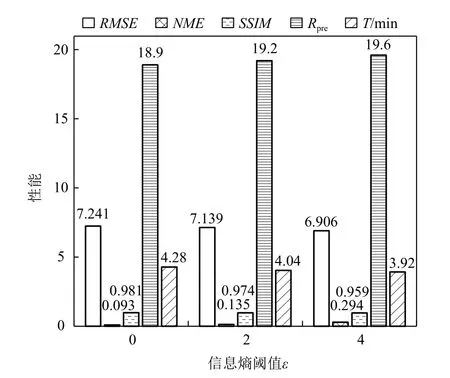
Fig.7 Quantitative analysis of AED with different ε图7 飞行器电磁模拟数据在不同ε 的定量分析
4.1.3 不同互信息阈值 δ的影响
一年365天,吴躜辉有一半时间都奔波在路上,家人的支持和理解给他全身心投入到工作中提供了巨大的支持。谈到接下来的规划,吴躜辉希望从眼前的事情做起,一步一步把服务做实做细,让农户有个好收成。
本节主要讨论相关性统计建模中的另一个关键参数,即互信息阈值 δ对建模质量的影响与评估.
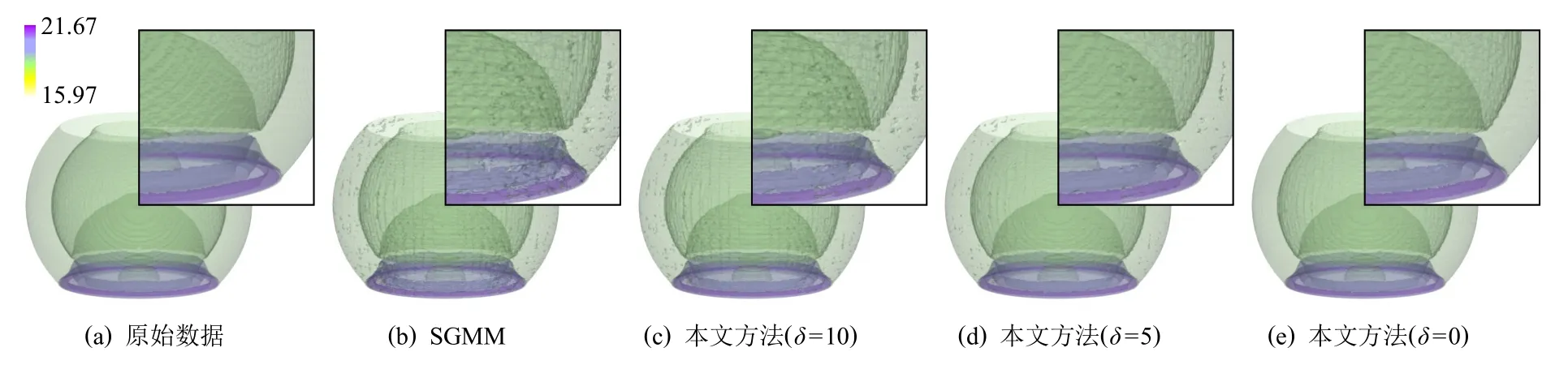
Fig.8 Reconstruction results of SWD with different δ图8 冲击波效应模拟数据在不同δ 的重建结果
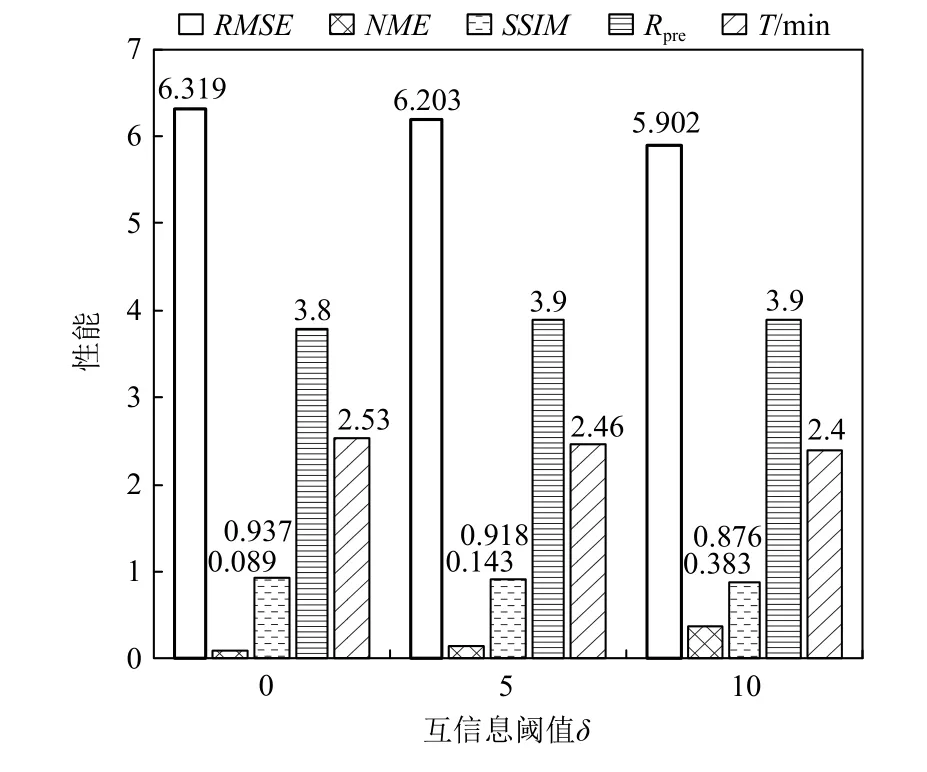
Fig.9 Quantitative analysis of SWD with different δ图9 冲击波效应模拟数据不同δ 的定量分析
图8 展示了不同互信息阈值 δ参数设置下,使用SGMM 和本文所介绍的相关性统计模型对冲击波效应模拟数据进行统计重建的结果,选取了冲击波效应模拟数据的4 个等值面进行渲染.图9 展示了互信息阈值 δ的不同设置下,计算时间、数据压缩比和重建精度的变化情况.结果表明,δ越小,执行随机采样的相邻数据块的数目越多,重建结果的精度越高、不确定性越低;但数据压缩比越小,并行计算时间越长.通过权衡数据压缩比、计算时间与重建精度三者,本文默认设置δ=5(由于直方图Bin 区间个数的默认值为M=256,故 δ的最大值为64).如果用户对数据重建精度有更高的要求,并且可以处理更大的数据内存占用和更长的并行计算时间,则可以使用更小的互信息阈值.图8(e)展示了δ=0 时相关性统计模型的重建结果.在多块拼接数据的相关性统计建模算法中,针对每个中心数据块的1-邻域范围,需要逐数据块进行相关性感知的分布数据采样计算.
4.1.4 不同统计分布模型的比较
不同的统计分布模型,可以描述不同的数据统计特征,其针对大规模多块数值模拟数据的特征表征效果存在差异.对比不同统计分布模型的重建结果,可以评估本文提出方法对于大规模多块数值模拟数据的适用性.
图10 显示了对惯性约束聚变激光成丝数据进行统计重建的结果,实验采用了直方图分布模型、SGMM和本文提出的相关性统计模型.在数据可视分析环节,本文选取了惯性约束聚变激光成丝数据的一个等值面进行可视分析结果评估.针对直方图模型,其主要缺陷是在统计建模过程中仅处理原始数据的数值分布信息,而丢失其空间分布信息;SGMM 则添加了对数据空间分布信息的统计建模,但仍然无法达到高质量的数据建模要求,尤其在数据块边界.由于以上这2 种统计分析方法仅针对每个数据块进行独立统计建模,缺省了邻域数据信息,因此其重建结果中数据块间的数值不连续性相对明显.相比之下,本文方法通过对数据块间的统计相关性进行建模,显著改善了块间不连续性,与直方图模型和SGMM 相比,它可以产生更为平滑的重建结果.定性定量分析的结果显示,上述3 种统计模型的重建结果与原始数据间的归一化最大误差,分别为0.011,0.894,0.992.3 种统计模型的数据压缩比均为43.5∶1,数据轻量化的效果显著,但其中本文方法的模型重建精度最高.
4.1.5 超大规模数值模拟数据集
为了验证本文方法处理超大规模数值模拟数据集的有效性,实验使用了模拟小行星撞击海底的2组大规模数值模拟数据集,采用体绘制方法进行可视分析.图11 与图12 分别给出采用SGMM 和本文相关性统计模型的统计可视分析结果.对比可知,本文方法可以显著提升分块数据边界区域的重建数据的数值连续性,从而获得与真实数据非常相似的重建结果.另外,本文方法还能够实现针对原始大规模数据的高效数据压缩.例如,模拟小行星撞击海底数据的Tev 变量数据场和V02 变量数据场的数据压缩比,可以分别达到22.2∶1 和11.4∶1,实现2 个数量级的大规模数据轻量化.
4.1.6 时变数据集
为了验证本文方法处理时变数据集的有效性,实验使用了包含48 个时间步的气候模拟飓风数据集,根据不同的数据块尺寸和不同的统计建模方法,组合为4 组实验:1)b=16,使 用SGMM;2)b=8,使 用SGMM;3)b=16,使用本文的相关性统计建模方法;4)b=8,使用本文的相关性统计建模方法.图13 与图14分别展示了上述4 组实验的时间步数据重建结果的归一化最大误差以及数据压缩比的堆积柱形图.分析可见,采用相同数据块尺寸(实验1 与实验3),实验2 与实验4),本文方法具有更小的归一化最大误差,即重建结果精度更高;采用不同数据块尺寸(实验2 与实验3),本文方法同时具有更小的归一化最大误差和更大的数据压缩比.
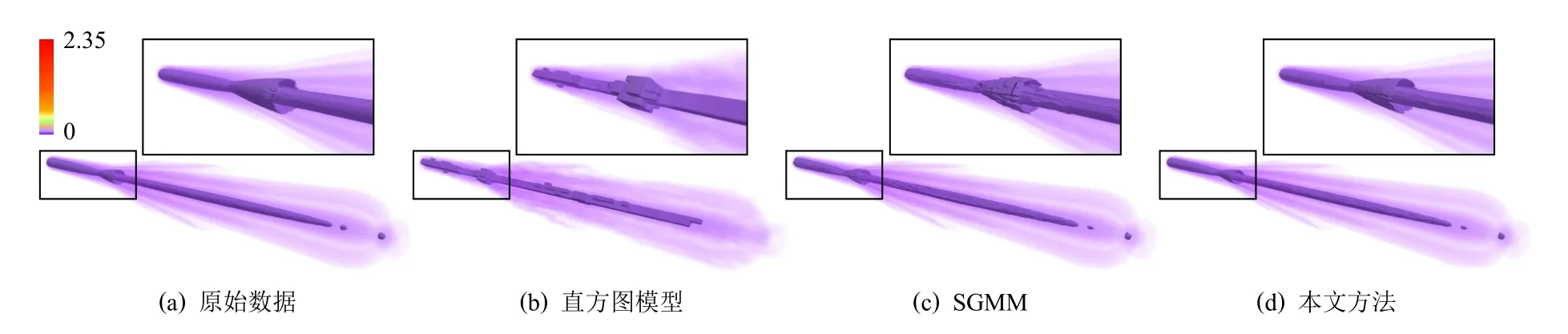
Fig.10 Reconstruction results of LD of different statistical distribution models图10 惯性约束聚变激光成丝数据在不同统计分布模型的重建结果
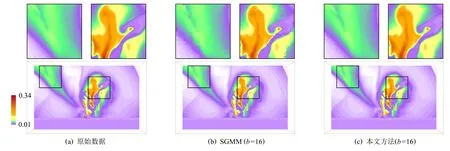
Fig.11 Reconstruction results of Tev field of AID图11 小行星撞击海底数据Tev 数据场的重建结果
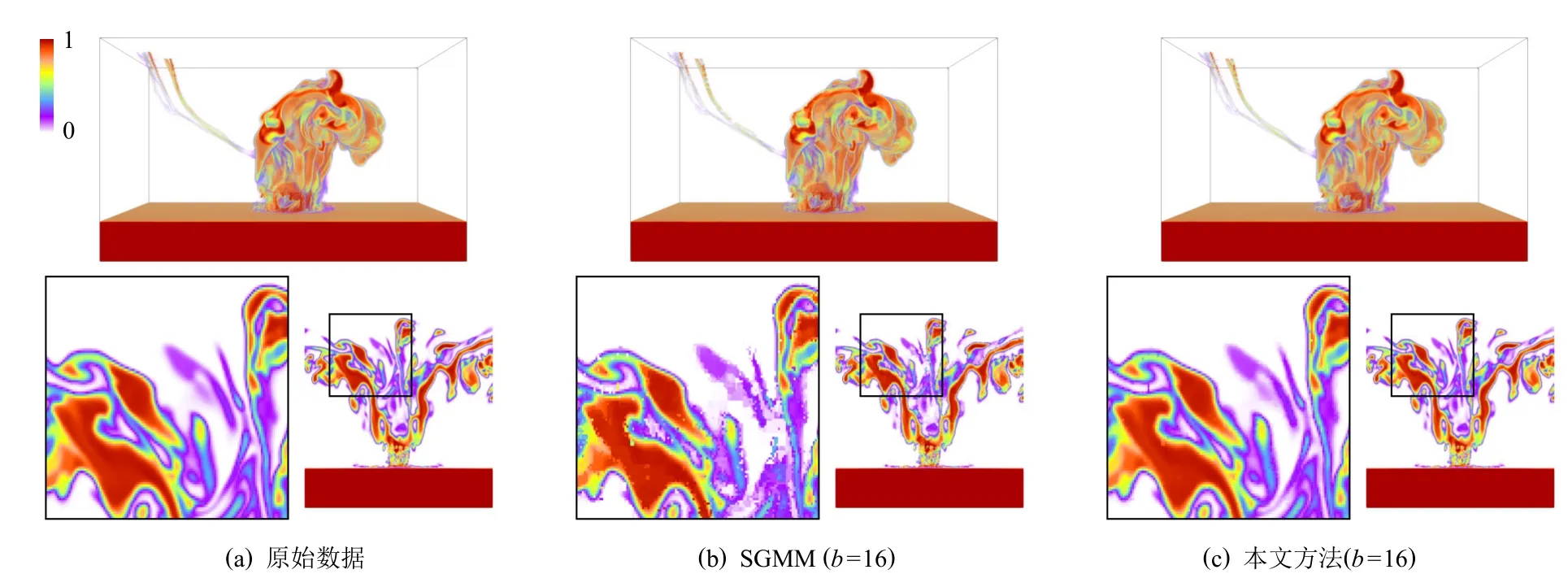
Fig.12 Reconstruction results of V02 field of AID图12 小行星撞击海底数据V02 数据场的重建结果
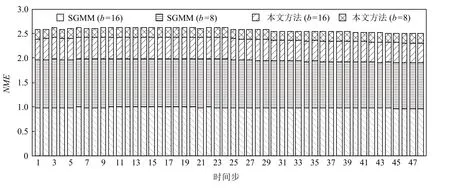
Fig.13 NME of HD varying with time step图13 气候模拟飓风数据在不同时间步的归一化最大误差
4.2 建模计算效能评估
4.2.1 并行计算时间
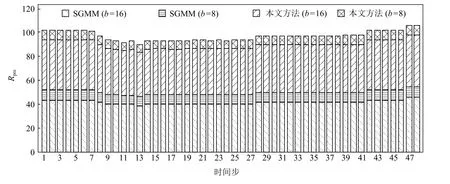
Fig.14 Rpre of HD varying with time step图14 气候模拟飓风数据在不同时间步的数据压缩比
本节通过模型并行计算时间评估本文方法针对大规模模拟数据的处理效能.针对小行星撞击海底数据(图11),浪潮服务器节点的每个核分配的数据块个数为9 300,采用24 核,块内统计分布模型和相关性统计模型的并行计算时间分别为199.52 s 和29.88 s,数据重建的并行计算时间为79.06 s,数据压缩比达到了22.2∶1.针对飞行器电磁模拟数据(图6),浪潮服务器节点的每个核分配的数据块个数为10 752,块内统计分布模型和相关性统计模型的并行计算时间分别为155.25 s 和32.93 s,数据重建的并行计算时间为53.07 s,数据压缩比达到19.2∶1.由于建模计算相对于数据可视分析是一个预处理过程,不强调处理的实时性,因此上述模型并行计算时间仍属于用户可接受范围,并可通过并行核数的增加继续缩短并行计算时间.而2 个数量级的压缩比,则确实可以显著解决应用数据的存储瓶颈.此外,由于本文方法不需要对多块数据进行合并与重分,可以显著减少多核间的数据通信.本文方法对小行星撞击海底数据(图11)和飞行器电磁模拟数据(图6)的通信时间分别为2.13 s 和1.09 s.
一般统计分布模型的精度,是与数据分块的大小成反比趋势变化的.而本文的统计分布模型则能够采用尺寸更大的数据块,获得与SGMM 相似甚至更高的重建精度,因而建模速度更快.如图5(c)和图5(d)所示,SGMM 需要使用数据块尺寸为b=8 时,才能获得相对高质量重建结果,其模型并行计算时间为39.49 s.而采用本文模型,仅需采用数据块尺寸b=16,即可获得与b=8 时SGMM 的重建质量,并且模型并行计算时间相比更短,下降为仅需32.48 s(块内统计分布模型和相关性统计模型的并行计算时间分别为31.22 s 和1.26 s).需要注意的是,原始数据的统计特征分布情况对本文算法的并行计算时间长短具有决定性影响,数据统计特征分布越集中,并行计算时间越短,反之亦然.
4.2.2 不同统计建模的效能比较
本文通过记录通信时间Tc、模型并行计算时间Tm、重建并行计算时间Tr和 总时间Tt来说明本文方法在计算效能方面的优势.由于本文方法可以直接处理原始的多块数据,无需进行合并和重分,因此多核间的数据通信时间相对较短.直方图分布模型和SGMM 则需要对合并后的数据进行重新分块,需要更长的通信时间.图15 和图16 分别为适用直方图分布模型、SGMM 和本文方法对飞行器电磁模拟数据和小行星撞击海底数据进行计算的Tc,Tm,Tr,Tt.可以发现,对于直方图分布模型和SGMM,数据通信占据了主要的时间,本文方法则使用最短的总计算时间获得了最精确的重建结果.
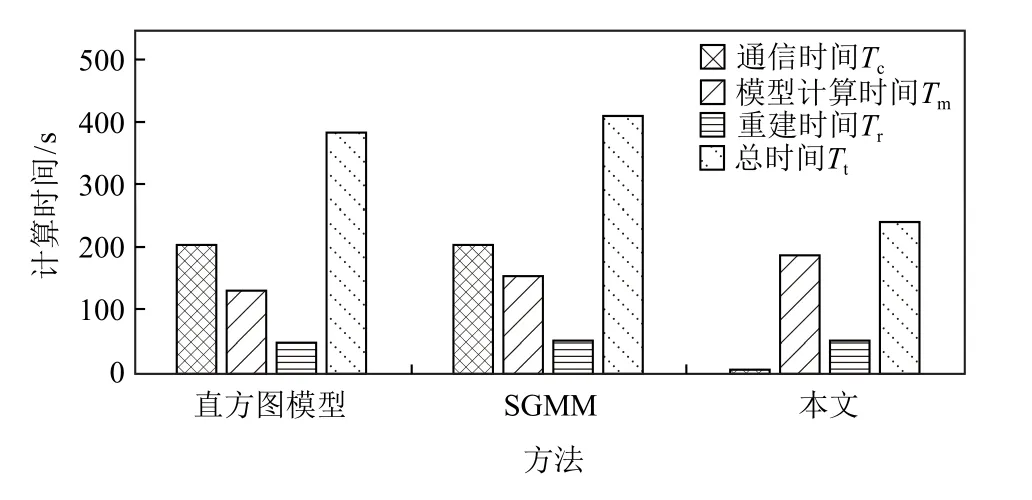
Fig.15 Efficiency comparison of different statistical modeling of AED图15 飞行器电磁模拟数据在不同统计建模的效能比较
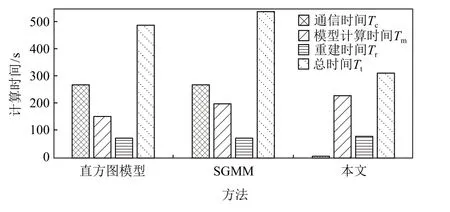
Fig.16 Efficiency comparison of different statistical modeling of Tev field of AID图16 小行星撞击海底数据在不同统计建模的效能比较
4.3 对比分析
实验使用的小行星撞击海底模拟、飓风气候模拟、飞行器电磁模拟、冲击波效应模拟和聚变激光成丝模拟数据,分别属于流体力学、气候变化、电磁环境、爆炸冲击、惯性约束聚变等5 个不同应用领域,代表了当前结构网格科学模拟的典型应用.这些典型应用的高分辨率模拟结果均呈现复杂的空间分布特征,并且在单块网格数据内表现出高度的数值异质性,如图5,6,8,10~12 所示.现有统计建模方法忽视了上述单块数据内的数值异质性,导致重建结果在数据块边界具有强数值不连续性,无法保持高精度.而本文方法则考虑了邻域数据的统计分布特征,从而可以获得数值连续性更优的重建结果,如表2第6~8 列所示.
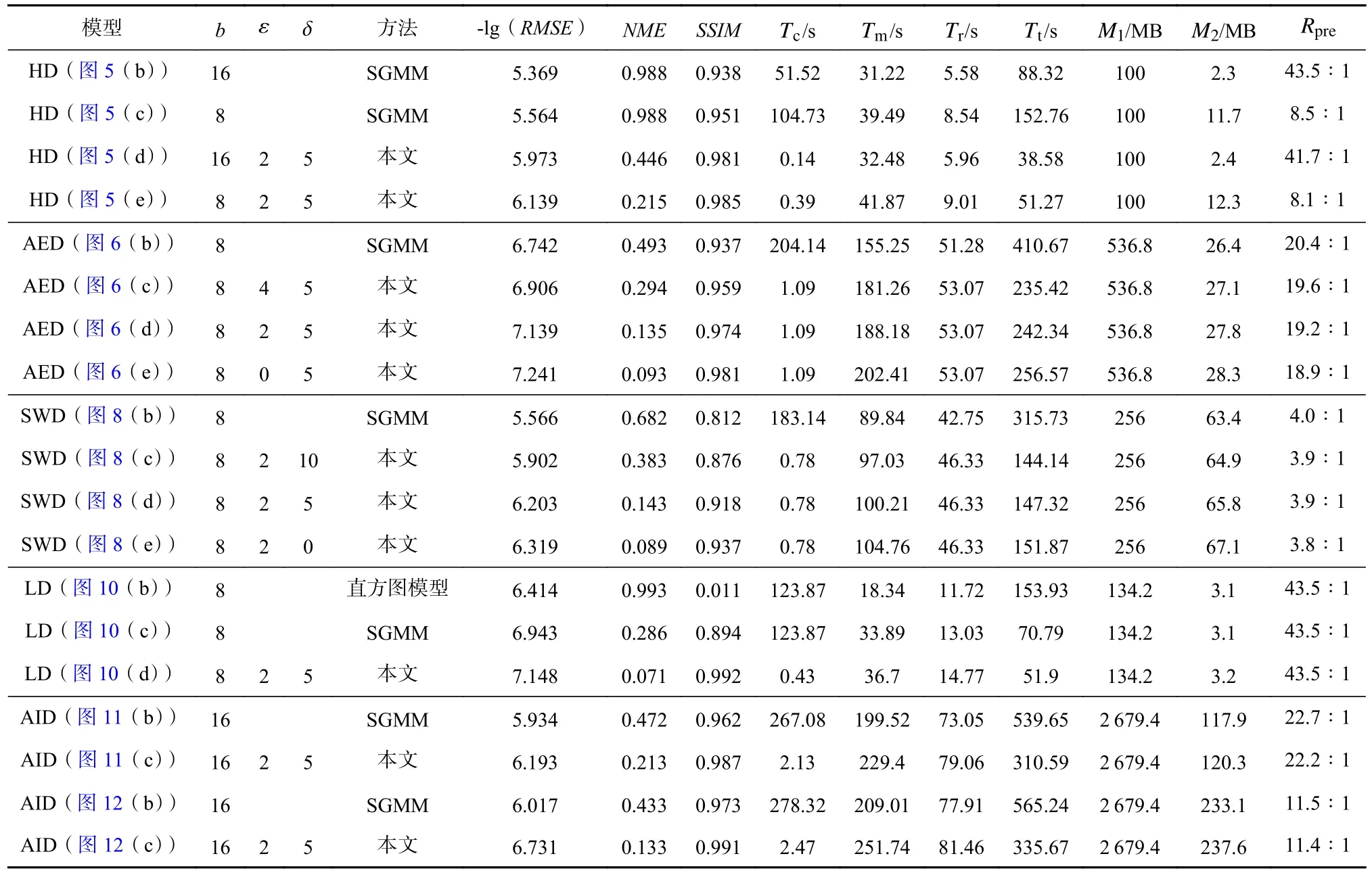
Table 2 Statistical Analysis and Computational Time of Test Data表2 测试数据的统计分析结果和计算时间
此外,本文方法不需要对原始多块数据进行合并与重分,避免了随并行计算规模显著增长的数据通信开销,因此,在实现跨量级的数据轻量化的同时,还能使得大规模数据的建模计算更加高效,如表2第10,11 列所示,其中M1为 原始数据所占内存,M2为统计模型所占内存,Rpre为数据压缩比.综上所述,本文方法能够在显著降低计算成本的同时,得到具有更高重建精度的数据轻量化结果,对于结构网格模拟应用具有较好的方法普适性.
5 结束语
本文提出了一种大规模结构网格数据的相关性统计建模轻量化方法,它通过使用数据块间的相关性统计表征,指导邻接数据块的统计建模,从而有效地保留数据统计特征.通过耦合数据块的数值分布信息、空间分布信息和相关性信息,可以更精确地重建原始数据,降低可视化的不确定性.且本文方法不需要在统计建模前对不同并行计算节点中的数据块进行合并与重分,从而显著减少数据通信开销.通过采用最大包含10 亿网格点的5 组科学数据进行实验比较,定量分析结果显示,本文方法相比现有方法可将数据存储成本降低约1 个数量级,同时具有更高的重建精度.然而,虽然本文方法对结构网格数据具有普适性,但由于非结构网格数据和集成数据没有规则的拓扑结构,使得本文方法难以适用.在未来的工作中,我们将考虑对网格的拓扑结构进行轻量化处理,实现本文方法的推广.
作者贡献声明:杨阳进行了该论文相关实验设计、编码及测试、论文撰写等工作;武昱进行了实验设计和结果分析;汪云海进行了论文结构讨论和修改;曹轶进行了实验设计和论文修改.
