基于边缘智能计算的城市交通感知数据自适应恢复
2023-03-27向朝参程文辉焦贤龙屈毓锛戴海鹏
向朝参 程文辉 张 昭 焦贤龙 屈毓锛 陈 超 戴海鹏
1(重庆大学计算机学院 重庆 400044)
2(信息物理社会可信服务计算教育部重点实验室(重庆大学)重庆 400044)
3(南京航空航天大学电子信息工程学院 南京 210016)
4(南京大学计算机科学与技术系 南京 210023)
随着城市的不断快速发展,城市交通问题日益严峻,如交通拥堵等[1].为了解决这些问题,大量智能交通系统(intelligent transportation systems,ITSs)被广泛地部署,用于城市交通感知和监控[2].例如,澳大利亚新南威尔士州构建交通流量监控系统(taffic volume viewer system,TVVS)[3],部署超过600 个交通感知站点.然而,由于设备故障、数据传输和系统供电等问题,感知数据缺失问题在ITSs 中普遍存在[4].例如,文献[5]统计分析发现,澳大利亚TVVS 系统中约25%的站点感知数据缺失率超过60%,严重影响该系统的正常使用.因此,准确实时地恢复大规模ITSs 缺失感知数据对实现智慧城市的智能交通至关重要.
本文提出基于边缘智能计算的大规模交通缺失感知数据恢复系统,既利用大量不同交通站点感知数据之间的相关性,又利用部署在感知站点附近的边缘节点强大的计算处理能力,从而实现大规模交通感知数据的精确自适应恢复.但是,要实现该系统,需要解决2 方面的挑战:
1)高计算复杂性的边缘节点部署.边缘节点部署,既需要考虑部署在不同交通感知站点的成本与收益各不相同,还与交通感知数据分配策略紧密相关,从而使边缘节点最优部署问题更加复杂,在2.2节被证明是NP-hard 问题.所以,如何解决这个高计算复杂性问题以实现最优部署非常具有挑战性.
2)高时空动态的感知数据相关性.交通感知数据的时空相关性具有动态性、时变性和复杂性,经常受道路拓扑、感知站点位置、天气以及社会事件等多方面因素的影响[6].因此,如何基于该动态的、时变的、难建模的时空相关性实现感知数据的精确恢复非常具有挑战性.进一步地,数据之间的相关性影响各个交通感知站点的数据分配策略,如当感知数据之间的相关性较差时,需要增加边缘节点的分配数据量,以保证数据恢复的鲁棒性.但是感知数据之间的高时空动态相关性使保证感知数据恢复精度的鲁棒性非常困难.
为了解决上述2 个挑战,本文提出基于边缘智能计算的城市交通感知数据自适应恢复系统,主要包括2 部分:
1)具有理论下界的边缘节点次优部署分配.针对挑战1,首先,通过问题等价转化,解耦边缘节点部署和感知数据分配之间的复杂关系.然后,通过理论证明该问题具有非负的、单调的和子模的目标函数,以及p-独立系统的约束条件.最后,基于该问题的性质分析,提出基于子模理论的边缘节点次优部署算法,能够在多项式时间复杂度内获得具有理论下界的近似最优解.
2)基于低秩理论的感知数据自适应精确恢复.针对挑战2,首先,基于实际交通感知数据集,对感知数据进行时空维度的低秩分析;然后,基于该分析结果,提出基于低秩理论的时空维度联合数据恢复算法;最后,针对感知数据相关性的高时空动态变化,提出基于奇异值分解的感知数据非缺失下限估计.基于该下限估计反馈,自适应地调整各交通感知站点的感知数据分配比例,以保证感知数据的精确恢复,从而提高系统数据恢复性能的鲁棒性.
综上所述,本文主要具有3 方面的创新和贡献:
1)提出基于边缘智能计算的城市交通感知数据自适应恢复系统,既利用基于子模优化理论的边缘计算,又利用基于低秩理论的智能计算,还基于非缺失下限估计反馈,自适应地调整交通站点感知数据分配比例,从而实现交通感知数据的“闭环”处理,提高系统的鲁棒性.
2)针对边缘节点部署NP-hard 问题,基于子模优化理论,通过问题解耦转化和性质分析,提出近似比为的边缘节点次优部署分配算法,其中cjs表示任意一个边缘节点es部署在任意一个感知站点 λj处的成本.同时,提出缺失交通感知数据的自适应恢复算法,利用基于低秩理论的感知数据恢复,以及基于奇异值分解的非缺失下限估计反馈调整,实现缺失感知数据的自适应精确恢复.
3)基于澳大利亚600 个交通感知站点1 年的实际感知数据构建原型系统,并基于该系统进行全面且深入的实验评估.结果表明,所提算法的边缘节点部署性能达到最优性能的90%以上,缺失数据恢复精度比3 种方法至少提高43.8%.同时,自适应数据恢复精度平均提高40.3%.
1 相关工作
为保障智能交通系统的正常运行,促进智慧城市的进一步发展,大量工作开始致力于研究城市交通感知数据的精确恢复.因此本文提出了基于边缘智能计算的城市交通感知数据自适应恢复系统,所以下面将主要介绍交通感知数据恢复和边缘节点部署方面的研究工作.
1)ITSs 交通感知数据恢复.智能交通系统在城市化进程不断深入的当下起着越来越重要的作用,然而交通感知数据的普遍缺失却极大地影响了ITSs的效用,为此越来越多的研究工作开始致力于交通感知数据的精确恢复.例如,文献[7]利用真实数据和仿真数据,同时结合生成式对抗网络对交通感知数据进行恢复.文献[8]中以高速公路交通数据为例,提出了一种数据融合方法,通过挖掘感知数据内在特性以重构缺失数据.文献[9]中通过将交通感知数据恢复问题建模为一个高维张量补全问题,并采用奇异值分解来进一步了解感知数据的内在联系,以达到缺失数据补全的目的.文献[4]将城市交通感知区域建模成一个具有时空相关性的张量,同时结合交通感知数据的城市特性完成对缺失数据的填补.文献[10]中提出一种联合空间多核学习和非负矩阵分解的策略机制,去补全缺失感知数据.该机制充分考虑了多感知区域间多层面的相关性,使得其能获得一个较好的数据恢复精度.有别于文献[4,7-10]的工作,本文提出基于边缘智能计算的城市交通感知数据自适应恢复系统,实现了交通感知数据的自适应动态精确恢复.
2)边缘计算中的节点部署.由于感知数据恢复存在规模庞大和计算密集等问题,本文提出通过边缘计算来解决这一难题,充分利用边缘服务器强大的计算能力来完成对感知数据及时精准的恢复.目前,也有很多其他关于边缘计算应用的研究.例如,文献[11-12]中提出利用云端服务器和边缘节点协同处理任务;文献[13]中研究多个边缘节点协作优化任务卸载和服务缓存,以达到降低整体任务时延的目的;文献[14]中提出利用边缘计算来存储整理车辆的道路感知信息,以此为无人驾驶汽车提供及时准确的道路信息,确保驾驶的安全;文献[15]中研究了云服务和端服务之间通过事件机制进行的服务适配,并结合图论和排队论方法实现了服务的平均响应时间最小.此外,关于边缘节点的相关研究也有很多,例如文献[16-17]中研究了关于节点部署成本最小的问题,文献[18-20]中也研究了在站点容量约束和带宽约束下最小化边缘节点部署成本的问题.本文提出的部署方案主要为处理缺失感知数据而提出,对每个边缘节点都有一定的数据上传量下限要求.因此,前人的研究成果并不适用于本文的研究.虽然文献[5]中提出了一种边缘节点部署和数据恢复算法,但是没有考虑数据恢复结果对于边缘节点处的反馈.与该工作不同,本文提出一种基于边缘智能计算的缺失感知数据自适应恢复系统,基于恢复结果的反馈,自适应调整恢复过程,从而保证数据恢复精度,提高系统恢复的鲁棒性.
2 系统模型和问题建模
2.1 系统模型
为解决大规模ITSs 系统的感知数据缺失问题,本文提出基于边缘智能计算的大规模交通缺失感知数据动态自适应恢复系统模型架构,主要包括交通感知站点、边缘节点和云服务器.
1)交通感知站点.在智能交通系统中,交通感知站点被部署在城市的各条道路或其交叉路口上,感知和监测道路实时的交通信息,如车流量、车速等[21].假设有N个站点,用λi表 示第i个站点,其 中i∈{1,2,…,N}.此外,用wi表示λi的感知数据规模大 小.表1给出本文主要数学符号说明.
2)边缘节点.所有交通感知数据被传送至边缘节点进行缺失数据恢复处理.考虑到部署的便捷性及部署成本问题,边缘节点将被部署在交通感知站点处.假设共有S个边缘节点,用es表 示第s个边缘节点,其中s∈{1,2,…,S}.用xjs=1或 0 表示边缘节点es是否被部署到交通站点λj处,xjs=1表示被部署,否则xjs=0 .每个节点的部署需耗费一定成本,用cjs表示边缘节点es部 署到交通站点 λj的成本.不同的边缘节点有不同的计算存储容量,用ds表示es的计算存储容量.此外,用yij表示交通站点 λi传 输到部署在 λj处 边缘节点的数据比例,即yij∈[0,1].为方便处理,在进行缺失数据恢复时,边缘节点首先将各个站点上传的感知数据整合成一个含缺失数据的矩阵,即缺失矩阵,用Mjs表示 λj处边缘节点es整合的缺失矩阵.同时,为保证恢复精度,缺失矩阵的元素缺失程度不能太大,即传送到边缘节点的非缺失感知数据量需满足一定下限,用mj表示 λj处边缘节点整合矩阵的非缺失下限.特别地,矩阵非缺失下限值与矩阵的秩大小密切相关,具体见3.2.2 节.此外,由于外界因素,如环境、天气、节假日等的影响,感知数据矩阵的秩也将随之变化,进一步地将影响到数据最后的恢复精度.为保证在变动的外界因素下,缺失数据的恢复精度依然能满足一定要求,边缘节点将依据恢复结果计算相应非缺失下限值,并基于非缺失下限值调整各交通站点的感知数据分配比例,以保证感知数据的自适应精确恢复.此外,为提高恢复效率,边缘节点应能同时处理尽可能多的感知数据.

Table 1 Main Mathmatics Notations Description表1 主要数学符号的说明
3)云服务器.云服务器在整个系统中主要有2个功能:①管理和控制边缘节点.连接所有边缘节点,并灵活高效地控制和管理各个交通感知站点和边缘节点之间的数据传输和调度[22].具体地,首先,所有边缘节点根据恢复结果,计算非缺失下限值,并将该值发送至云服务器;然后,云服务器根据各个边缘节点上传的非缺失下限值重新计算感知数据分配方案,并反馈回各个边缘节点;最后,边缘节点通知各个交通感知站点新的感知数据分配比例.②复杂的大规模数据处理[23-25].当边缘节点恢复缺失感知数据之后,利用完整的交通感知数据进一步地进行复杂的大规模数据分析和挖掘,如基于深度学习的交通感知大数据态势分析和挖掘等[26-27].
2.2 问题建模
基于2.1 节所述的系统模型,本文研究的问题主要包括:1)如何在部署成本约束下设计边缘节点部署方案,提高部署性能使其能更好地服务感知数据恢复,即能同时处理尽可能多的感知数据.2)如何基于边缘节点部署实现感知数据的动态自适应恢复.
1)子问题P1——边缘节点的次优部署.已知边缘节点的计算存储容量 {ds|s∈{1,2,…,S}}和交通感知站点的感知数据规模 {wi|i∈{1,2,…,N}},如何设计S个边缘节点部署到N个交通感知站点的部署策略x=(xjs|∀j∈{1,2,…,N},∀s∈{1,2,…,S}),和N个交通感知站点传输到已部署边缘节点的感知数据量分配方案y=(yij|∀i,j∈{1,2,…,N}),以在总部署成本预算C0约束下,最大化所有部署边缘节点处理总数据量,即交通感知站点总上传数据量.
2)子问题P2——感知数据的自适应恢复.如何基于边缘节点整合的缺失矩阵,通过矩阵中完整元素恢复缺失元素.同时基于恢复结果,估计当前感知数据相关性程度,通过该相关性程度大小计算保证精确恢复所需的非缺失感知数据下限值,从而基于下限值调节感知站点上传至各边缘节点感知数据比例,达到动态自适应精确恢复的目的.用T表示矩阵Mjs的元素个数,用vt和分别表示该矩阵第t个元素的实际值和估计值,t∈{1,2,…,T}.因此,感知数据恢复问题可描述为:如何设计矩阵恢复函数 Φt(·),使得所有缺失感知数据的估计值与真实值之间的误差最小,形式化表示为:
其中:式(8)表示感知数据的估计误差,即平均绝对值误差[30];式(9)表示感知数据的估计恢复,Φt(Mjs)表示利用矩阵恢复函数,基于Mjs中所有非缺失数据估计其第t个元素的值.同时,为达到动态自适应精确恢复的目的,还需依据P2 恢复结果,更新非缺失下限值,以保证感知数据的恢复精度.
定理1.边缘节点的最优部署分配问题 P1是NPhard 问题.
证明.当每个交通站点的感知数据量规模 {wi}足够大,远大于所有边缘节点的存储容量上限 {ds}时,式(2)(5)可被松弛.原问题简化为
将S个边缘节点与N个交通站点的所有配对看成S×N个物品 {(j,s)|∀s∈{1,2,…,S},∀j∈{1,2,…,N}},并将每个节点的配对集合分为一组,共S组.因此,原问题可规约为一个经典的0-1 背包问题:已知每个物品 (j,s) 的价值和成本分别为ds和cjs,如何从每组物品中至多选择1 个物品,使在总成本C0约束下最大化物品价值.因为该0-1 背包问题是NP-hard 问题[31],所以,问题 P1也是NP-hard 问题,证毕.
3 算法系统设计
为了解决2.2 节所述的子问题P1 和P2,本文提出基于边缘智能计算的城市交通感知数据动态自适应恢复系统.如图1 所示,该系统基于交通感知站点中存在缺失的交通感知数据和交通感知站点的交通拓扑网络图,利用边缘智能计算进行感知数据的动态自适应恢复,从而得到精确完整的交通感知数据.具体地,该系统主要包括2 个模块:
1)具有理论下界的边缘节点次优部署(3.1 节).首先,通过问题等价转化,在3.1.1 节分析 P1问题的目标函数和约束条件性质;然后,基于理论分析结果,在3.1.2 节提出基于子模理论的边缘节点次优部署算法,在多项式时间内能获得该NP-hard 问题的具有理论下界的近似最优解.
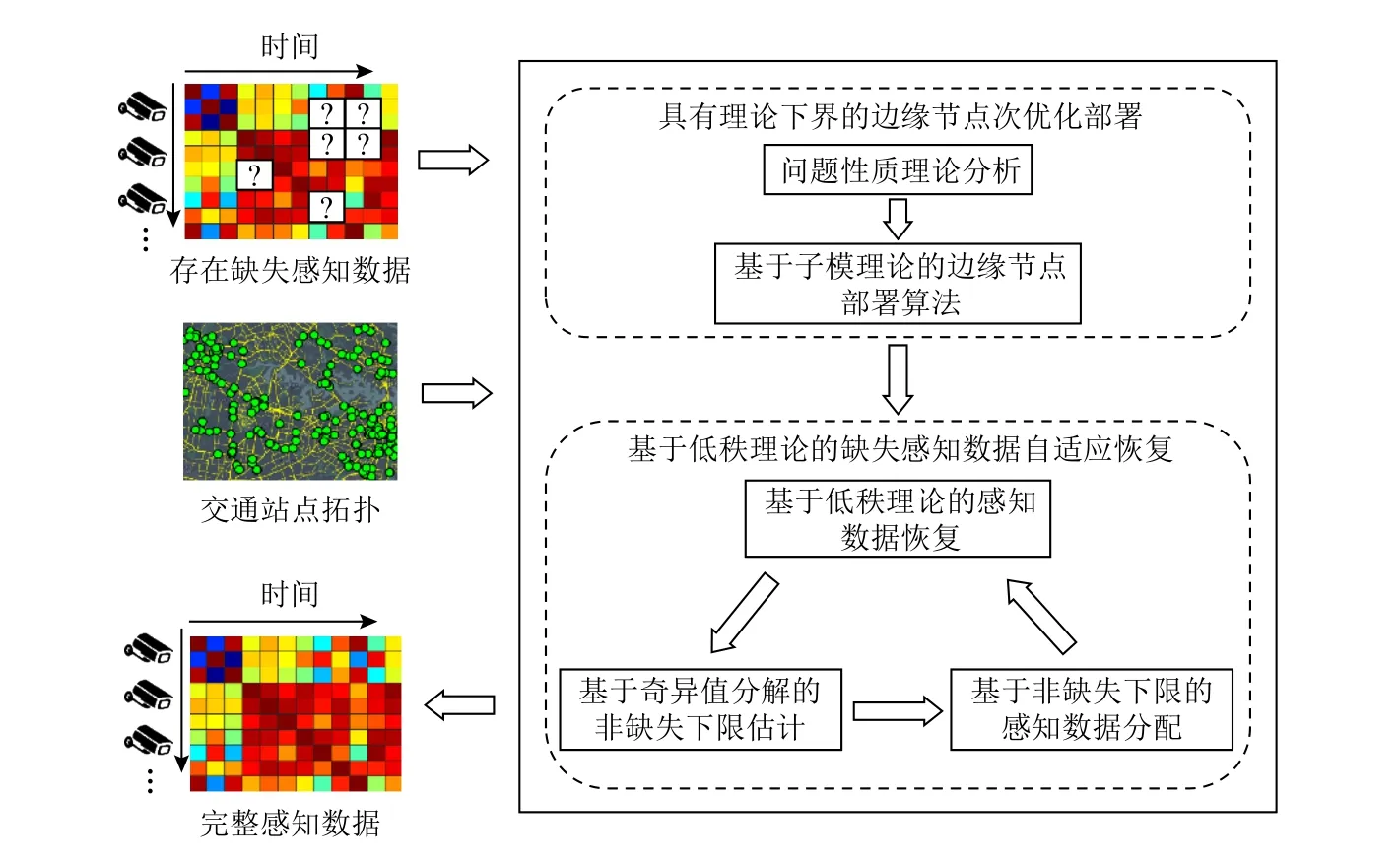
Fig.1 Intelligent edge computing-empowered adaptive urban traffic sensing data recovery system图1 基于边缘智能计算的城市交通感知数据自适应恢复系统
2)基于低秩理论的感知数据自适应恢复(3.2节).首先,分析交通感知数据的时空维度近似低秩特性,在3.2.1 节提出基于低秩理论的交通感知数据恢复算法;然后,基于恢复结果,在3.2.2 节利用奇异值分解和矩阵自由度理论估计交通感知数据的非缺失下限,依据此下限值更新感知数据分配比例,保证感知数据的精确恢复.
3.1 具有理论下界的边缘节点次优部署
3.1.1 问题性质理论分析
1)问题等价转化.问题P1 包含2 类决策变量,即边缘节点部署决策变量x和 感知数据分配变量y.用y*(x) 表示给定边缘节点部署规划x的最优感知数据分配方案.通过理论分析,可得引理1.
引理1.对于问题P1,如果给定边缘节点部署方案,能够在多项式时间内获得最优的感知数据分配方案y.
证明.给定任意的边缘节点部署策略x0=(),问题P1 转化为只关于y的感知数据分配问题 P1′:
P1′是一个简单的线性规划问题,可利用多种经典的线性规划方法[32]在多项式时间内求得最优解,
证毕.
用H(x,y)表示问题P1 的目标函数.因此,根据引理1,可以将H(x,y) 转化为只关于决策变量x的目标函数H(x,y*(x)) .进一步地,定义集合函数G:={(j,s)|∀j∈{1,2,…,N},s∈{1,2,…,S}},A:={(j,s)|xjs=1,∀j∈{1,2,…,N},s∈{1,2,…,S}},F(A):=H(x,y*(x)).因此,可将问题P1 等价转化为集合函数优化问题 P1′′:
其中 1l(·)表示指示函数.
2)问题性质分析.下面基于定义1 和定义2 分别分析问题 P1′′的目标函数性质(如引理2)和约束条件性质(如引理3).
定义1.非负性、单调性和子模性[33].对于一个集合函数F(·):2R→R(R 是一个 有限集),如果F(∅)=0并且F(A)≥0 (∀A ⊂R),则集合函数F(·)是非负的;如果∀A1⊆A2⊆R,F(A1)≤F(A2),则F(·)是单调 的;当且仅当 ∀A1⊆A2⊆R,∀e∈RA2,F(A1∪{e})-F(A1)≥F(A2∪{e})-F(A2),F(·) 是子模的.
引理2.P1′′的目标函数F(A)(A ⊆G)是非负 的、单调的和子模的.
证明.首先,由于F(A)的物理含义是感知数据量,所以易证其是非负的和单调的.
其次,证明F(A)是子模的.根据定义1,要证其是子模的,需证明 ∀A1⊆A2⊆G,∀(j1,s1)∈GA2,下列不等式恒成立:
然后利用反证法可证明
具体证明:假设该结论不成立,即
因此,该不等式表明加入节点 (j1,s1)后,A1中边缘节点的感知数据量减少.然而,根据目标函数的单调非减性可知,A1∪{(j1,s1)}中节点的感知数据量不会减少.因此,节点 (j1,s1)的感知数据量增加,所以可调整节 点 (j1,s1)的感知 数据到 A1中的边 缘节点.所 以A1∪{(j1,s1)}对应的感知数据分配解不是所有最优解中 (j1,s1)数据量最小的解.与结论的前提条件矛盾,即是 所有最优解中 (j1,s1)数据量最小的解.所以假设不成立,原结论成立,即
进一步地,因为
所以,
同理可证
综上,结论1)成立.
2)证明
具体证明:假设该结论不成立,即
因此,该不等式表明 A1∪{(j1,s1)} 加入 A2A1后,节点(j1,s1)的 感知数据量增加.由于 A1∪{(j1,s1)}中边缘节点的感知数据量在 A2A1加入前后保持不变,所以可调节 (j1,s1)上 的感知数据到 A1方案中的边缘节点.所以,A2∪{(j1,s1)}对应的感知数据分配解不是所有最优解中 (j1,s1)数据量最小的解.所以假设不成立,原结论成立,即
结论2)成立.
基于上述2 个结论,可得不等式(17)成立.因此,F(A)是子模的.证毕.
定义2.p-独立系统[34].给定一个任意有限集合 G,用 I 表示 G 的子集构成的集合族,即 I ⊆2G.则集合对(G,I)被称为独立系统,当且仅当满足2 个条件:①∅∈I ;②如果 A ⊆B ∈I,则 A ∈I.
说明:I中的元素被称为独立集.同时,∀A ⊆G,如果 A中的某个独立集不是 A中的任何一个独立集的子集,那么该独立集被称为 A 的基.用r(A) 和l(A)分别表示 A的最大基和最小基元素的个数.对于一个任意 独立系 统 (G,I)和任意集合 A ⊆G,如果max(r(A)/l(A))≤p,则独立系统 (G,I)被 称为p-独立系统.
引理3.式(15)(16)构成p-独立系统,且p=1+,其中cjs表示任意一个边缘节点es部署在任意一个交通站点 λj的 成本,∀j∈{1,2,…,N},∀s∈{1,2,…,S}.
证明.由定义2 可知原证明等价于证明 (G,Ip)构成p-独立系统,其中 G表示边缘节点和交通站点所有可能的配对集合,Ip表示所有可行部署方案的集合.首先,显然有 ∅∈Ip.此外,对于任意2 个部署方案X,Y,若其满足 X ⊆Y ∈Ip,则由于满足问题约束条件的可行解的子集也必定满足约束条件,所以任意可行解的子集也必为可行解.所以必有 X ∈Ip.所以,根据定义2,(G,Ip)是一个独立系统.
考虑任意集合 A ⊆G,因为 Ip是可行解集合.所以 A中独立集都是可行解.用 A1和 A2分别表示 A中任意2 个最大可行解(即满足全部约束已无法再加入元素),现如果向 A2中增加元素 (j,s)∈A1A2,就需要在 A2中拿出一些元素来满足约束.为满足式(15),需取出至多1 个元素.为了满足式(16),需取出至多个元素.如此循 环直到 A2=A1.当最差情况发生时,换入 |A1|个 元素需至多换出p|A1|个元素,即 A2中元素个数至多为 A1中 元素个数的p倍,所以,根据定义2 可得式(15)(16)构成p-独立系统.
证毕.
3.1.2 基于子模理论的边缘节点次优部署算法
根据引理2 和引理3 可得,子问题P1 具有非负的、单调的、子模的目标函数,以及p-独立系统的约束条件.因此,基于文献[35]的启发,为求解子问题P1,本文提出基于子模理论的边缘节点次优部署算法.如算法1 所示.
算法1.具有理论下界的边缘节点次优部署算法.
算法1 的核心思想是在每次迭代中,贪心地选择当前满足约束的、边际效益值最大的边缘节点部署方案.具体主要包含2 步:
1)添加新元素(行④⑤).计算 GB 中所有元素边际效益值,将其中边际效益值最大的元素加入解集 A 中.其中,B 表示当前加入 A中不满足约束的元素集合.
2)剔除冲突元素(行⑥~⑩).在每次向解集 A中添加新元素后,遍历 GB,将当前无法再被添加至A中的元素全添加至 B 中.当 B=G时,表明当前已无可添加至解集 A的元素.此时得到的 A即为最终解,而后基于 A,进一步计算边缘部署方案x和感知数据分配方案y.
分析算法1 的时间复杂度及解最优性,可得定理2.
定理2.算法1 能够在多项式时间内获得近似比为的近似最优解.
证明.基于引理2 和3,子问题 P1是具有非负、单调和子模的目标函数及p-独立系统约束的优化问题.由文献[35]可得,基于算法1,可求得近似比为1/(1+p) 的近似 最优解.根据引 理3 得,因此,算法1 可获得近似比为的 近似最优解.此外,算法1 最多迭代S次,每次迭 代的时 间复杂度为O(NSΓ),其 中,N和S分 别表示交通感知站点和边缘节点的数量,Γ表示求解线性规划问题 P1′的多项式时间耗费[32].因此,算法1 具有多项式时间复杂度,即O(NS2Γ),证毕.
3.2 基于低秩理论的感知数据自适应恢复
3.2.1 基于低秩理论的感知数据恢复
1)基于低秩分析的问题转化.利用实际智能交通感知数据集(详见4.1 节),分别基于时间维度和空间维度,分析不同时间和不同站点交通感知数据的低秩性.首先,分析在时间维度上的低秩特性.从数据集中随机选取4 个交通站点52h 的感知数据组成矩阵,并对该矩阵进行奇异值分解.如图2(a)所示,矩阵前10 个最大奇异值占全部奇异值之和的85%以上,即奇异值累积贡献率为85%.类似地,分析交通感知数据在空间维度的低秩特性.对25 个交通站点感知数据构成的矩阵进行奇异值分解,如图2(b)所示,前5 个最大奇异值占全部奇异值之和的90%以上.根据低秩理论[36]:如果矩阵中存在少量奇异值之和占所有奇异值总和的比值较大,则该矩阵可以近似认为低秩矩阵.因此分析可得,交通感知数据矩阵在时间维度和空间维度上都是近似低秩的.
基于上述结论可得,Mjs在时空维度是近似低秩的.由文献[37]可知,如果矩阵是近似低秩的,则通过采样其元素可以找到另一个低秩矩阵X来近似表示该矩阵.因此子问题 P2可等价转化为:
其 中 rank(·)表示矩 阵的秩函数,PΩ(·)表示投影采样算子.因为该秩函数是非连续和非凸的,求解非常困难,且最小化矩阵秩即最小化矩阵非零奇异值个数,可近似看作最小化矩阵奇异值总和(即核范数最小)[37].因此,为便于求解,可用核范数 ‖X‖*函数近似代替目标秩函数 rank(X).

Fig.2 Low-rank analysis of traffic sensing data matrix based SVD in terms of temporal and spatial dimensions图2 在时空维度下基于奇异值分解的交通感知数据低秩分析
2)感知数据精确恢复.受文献[38]启发,本文提出基于奇异值阈值截断(singular value thresholding,SVT)的缺失数据迭代恢复算法.该算法的核心思想是在每次迭代中对矩阵进行奇异值分解,然后将较小奇异值置为0,构造新矩阵进行下一轮奇异值分解.如算法2 所示.
算法2.基于低秩理论的感知数据自适应恢复算法.
以上2 步相互迭代,直至满足以下任意一个迭代停止条件:①迭代达到最大次数kmax(即行③);②恢复得到的矩阵Xk与原矩阵Mjs误差不大于ε(即行⑥).
3.2.2 基于奇异值分解的非缺失下限估计
当Mjs中缺失元素过多,即边缘节点es处感知数据量较少,而感知数据间的相关性程度又较小时,很难精确地进行缺失数据恢复.因此,为保证数据恢复精度,每个边缘节点分配到的感知数据量需满足一定下限,即非缺失下限.根据矩阵自由度理论[39],精确恢复一个含有缺失元素的矩阵需要的最少采样元素个数为
其中r表示该矩阵的秩即元素间相关性程度,n1和n2分别表示该矩阵的行列数.由式(23)可知,矩阵元素间相关性程度越小,精确恢复缺失数据所需的最少采样元素个数越多.
根据式(23),当计算基于算法2 恢复得到的完整矩 阵Xopt的非缺 失下限mj时,n1和n2很容易基于其行列数得到.而矩阵的秩rjs需进行估计,下面基于奇异值分解估计矩阵Xopt的秩rjs:
首先对矩阵Xopt进行奇异值分解为
其中 σ1≥σ2≥···≥σn≥0.
由于矩阵的低秩性,因此,可用占全部奇异值总和比例为 η(η ∈[0,1])的最少奇异值个数作为矩阵秩的估计值:
其中B为矩阵非零奇异值总个数.
最后,根据矩阵秩的估计值rjs,基于式(23)计算非缺失下限,并将该结果反馈至云服务器重新调整感知数据分配方案(子问题 P1′),以保证缺失感知数据的精确恢复.
4 基于大规模交通感知数据集的实验评估
4.1 数据集和实验方法介绍
1)大规模智能交通感知数据集介绍.本文利用澳大利亚新南威尔士州的交通流量监控系统TVVS的感知数据集进行实验评估.该感知数据集由部署在道路旁的大约600 个交通感知站点的交通监控感知系统产生,基本覆盖整个新南威尔士州.本文主要采用每个交通站点的交通流量感知数据,采样间隔为1h,采样时间长度为12 个月,即2018-01-01—2018-12-31.
2)实验方法介绍.为评估边缘节点部署性能,本文参照实际场景,设定交通站点数据量规模和边缘节点容量等其他参数,同时通过变化交通站点数据量规模、边缘节点容量及部署成本预算,分别评估3种因素对边缘节点部署性能,即所有节点能同时处理的总感知数据量的影响.在实验评估中,同时考虑了2 种不同规模的网络,即大规模网络(N=100,S=20) 和小规 模网络 (N=10,S=5).
为了充分地评估交通感知数据恢复的性能,随机地选择24 个交通感知站点,将它们中无缺失的感知数据组成实验数据矩阵.进一步地,在评估过程中,首先变化缺失数据长度(即矩阵缺失元素个数);然后固定缺失数据长度,变化交通感知站点的数量,以评估站点数量对缺失感知数据恢复性能的影响.
与当前多数边缘节点部署工作[19,28,40]类似,为了全面地评估边缘节点的部署性能,本文采用3 种性能不同的典型对比算法,即最优的、近似最优的、一般的对比算法.1)OPT.即最优的边缘节点部署方案,基于暴力搜索对所有可能的部署方案进行穷举以获得最优解.由于本文的边缘节点部署问题是NP-hard问题,因此,OPT 具有指数级计算复杂度,只能适用于小规模网络.2)HEU[41].即基于遗传算法的近似最优启发式算法,将部署方案类比成生物种群,初始化若干方案,并通过模拟自然界种群进化的过程(即遗传、交叉和变异),不断迭代更新以得到近似最优解.3)RAN.即随机部署算法,将边缘节点随机地部署在任意交通站点处.
为了充分评估缺失感知数据恢复性能,采用3 种常用的数据恢复算法作为对比算法:1)MR.即基于回归拟合的缺失数据恢复算法,利用非缺失数据拟合多项式,从而基于该多项式补全缺失数据.2)KNN[42].基于K近邻的缺失数据恢复算法,利用感知数据的时空相关性,通过距离缺失元素最近的k个数据的平均值来估计该缺失值.3)RF[43].基于随机森林回归的缺失感知数据恢复算法,即基于无缺失数据训练随机森林模型,用该模型预测缺失数据.
在实验评估中,本文采用3 种评估指标:1)边缘节点处理总数据量,即所有部署边缘节点接收到的总感知数据量,如式(1);2)平均绝对误差(mean absolute error,MAE),即补全数据矩阵元素的估计值与真值之间误差的绝对平均值,如式(27);3)平均绝对百分比误差(mean absolute percentage error,MAPE),即补全数据矩阵元素的估计误差与真值的百分比平均值,如式(28).
4.2 实验结果
1)边缘节点部署性能评估

Fig.3 Impact of different sensing data scales of traffic stations on the performance of edge node deployment图3 不同交通站点感知数据规模对边缘节点部署性能的影响
①评估不同交通感知站点的感知数据规模对边缘节点部署性能的影响.如图3 所示,变化交通站点数据规模为实际规模的1.0~2.0 倍.实验结果表明,在小规模网络场景下本文算法比RAN 算法性能平均提升25%.同时,本文算法与HEU 算法都能达到OPT算法的95%以上.主要原因是小规模网络场景中,满足约束的可行部署方案较少,使得HEU 算法有较大概率获得性能较优的解,从而性能与本文算法以及OPT 算法接近.但是,在大规模网络场景中,本文算法比HEU 算法平均提升性能8.8%,比RAN 算法平均提升性能31.6%.
②评估不同边缘节点容量对边缘节点部署性能的影响.如图4 所示,本文算法比RAN 算法,在小规模和大规模网络场景中性能分别平均提升25.9%和28.1%.虽然本文算法和HEU 算法在小规模网络场景中较为接近,都达到了OPT 性能的95%以上,但是在大规模场景下本文算法比HEU 性能平均提升10.3%.
③评估不同部署成本预算对边缘节点部署性能的影响.如图5 所示,本文算法比RAN 算法,在小规模和大规模网络场景中性能分别平均提升45.2%和32.5%.同时,在小规模场景中,本文算法和HEU 算法都能达到OPT 性能的92%.但是,在大规模网络场景下,本文算法的性能比HEU 算法平均提高11.9%.
2)交通感知数据恢复精度评估
为了评估本文所提缺失感知数据恢复算法的性能,分别与3 种常见缺失数据恢复算法在变化缺失长度和交通站点数量情况下进行比较.
①评估不同感知数据缺失长度对缺失数据恢复精度的影响.如图6 所示,实验结果表明,随着感知数据缺失长度的增大,缺失数据恢复的精度也不断降低.该结果符合常理,即缺失的感知数据量越大,则数据所包含信息量就越小,因此,数据恢复的精度也就越差.同时,与RF 算法、MR 算法和KNN 算法比较,本文算法的MAE指标分别平均降低48.0%,65.1%,74.8%,MAPE指标分 别平均降低47.8%,62.4%,78.9%.
此外,当缺失数据长度较大时,MR 和KNN 算法恢复的结果不够理想,这是因为基于均值恢复和多项式拟合恢复数据的算法对数据的非缺失程度要求较高,所以当数据缺失程度较大时,选择SVT 算法能够保证较好的补全精度.
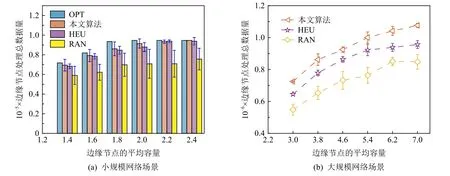
Fig.4 Impact of different edge node capacities on the performance of edge node deployment图4 不同边缘节点容量对边缘节点部署性能的影响

Fig.5 Impact of different total consumption budgets on the performance of edge node deployment图5 不同总耗费预算对边缘节点部署性能的影响
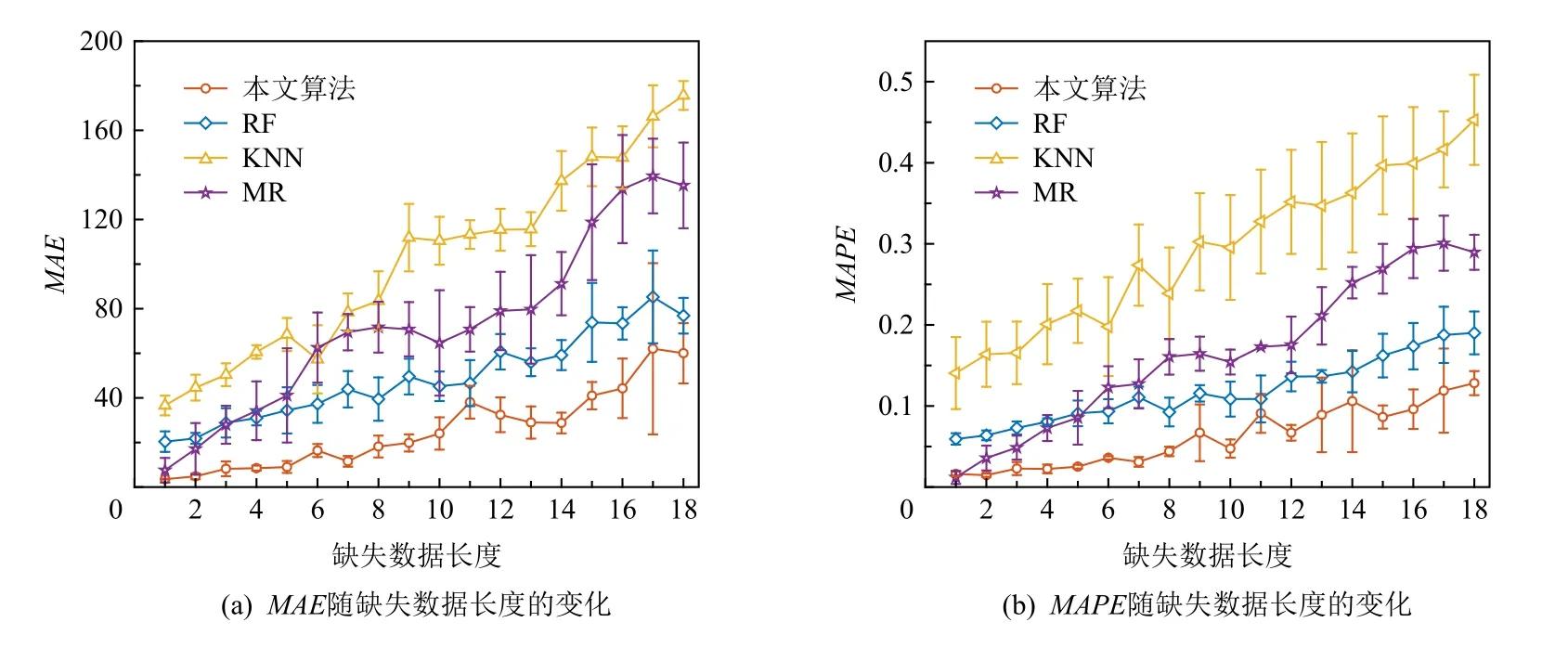
Fig.6 Impact of different missing data lengths on the accuracy of missing sensing data recovery图6 不同缺失数据长度对缺失感知数据恢复精度的影响

Fig.7 Impact of different number of traffic stations on the accuracy of missing sensing data recovery图7 不同交通站点数量对缺失感知数据恢复精度的影响
②评估不同交通站点数量对缺失数据恢复精度的影响.如图7 所示,实验结果表明,随着交通站点数量的增多,缺失数据的恢复精度也不断提高.这是因为随着交通站点数量的增加,矩阵中非缺失元素的比例增加,从而使得缺失数据的恢复精度也不断提高.此外,与RF 算法、MR 算法和KNN 算法比较,本文算法的MAPE指标分别平均降低50.2%,60.9%,43.8%,MAE指标分别平均降低51.2%,64.5%,47.1%.同理,由于KNN 和MR 算法对矩阵中元素非缺失程度的依赖性,使得其在交通站点数量较少时表现出来的性能不够理想.
此外,本文还对SVT 算法的收敛性进行了验证.首先,随机选择24 个交通站点24 天的感知数据组成实验数据矩阵;然后,利用SVT 算法,设定不同迭代次数对矩阵进行恢复,得到的结果如图8(a)所示.可以发现当迭代次数达到90 次后,感知数据的恢复精度基本保持不变.
③评估缺失感知数据自适应恢复的性能.具体地,随机选择16 个交通站点14 天内的感知数据组成组成实验数据矩阵.
首先,在实验前,先探究了该矩阵秩随时间变化的情况,结果如图8(b)所示.可以发现,矩阵秩大小会随时间而产生波动,如第3 天(4 月25 日,澳大利亚退伍老兵日)、第6 天和第7 天(周末)的感知数据矩阵秩产生了较明显的下降.
然后,分别采用本文提出的自适应缺失数据恢复算法,即根据恢复结果,计算非缺失下限并调整采样率和非自适应恢复算法,即采样率不随恢复结果自适应变化,对该矩阵进行数据恢复.实验结果如图9 所示,自适应恢复算法比非自适应恢复算法的MAE指标和MAPE指标分别平均降低40.3%和40.4%.主要原因是感知数据矩阵的秩在随时间波动,即感知数据的相关性程度随时间发生了变化.而非自适应恢复算法并没有根据相关性程度变化及时调整元素采样率,如当相关性程度减小时,提高采样率,增加非缺失元素的比例.而本文所提的自适应恢复算法充分考虑了这一因素,因此保证了数据的恢复精度,提高了系统恢复性能的鲁棒性.
此外,本文基于澳大利亚TVVS 系统中600 个交通站点的感知数据,构建基于边缘智能计算的大规模交通感知数据恢复原型系统,如图10 所示.
5 总结和展望
5.1 工作总结
本文提出一种基于边缘智能计算的城市交通感知数据自适应恢复系统,以解决高计算复杂度的边缘节点部署和高时空动态性的交通感知数据恢复问题.首先,提出具有理论下界的边缘节点次优部署算法,以解决边缘节点部署这个NP-hard 问题.然后,提出基于低秩理论的缺失感知数据自适应恢复算法,利用低秩理论和奇异值分解,基于恢复结果估计感知数据矩阵的非缺失下限,并根据非缺失下限值的反馈,自适应调整交通站点感知数据分配,从而提高数据恢复的精确性和鲁棒性.最后,基于实际大规模交通感知数据集构建原型系统,并进行实验评估,实验结果验证所提算法的有效性和鲁棒性.

Fig.8 Convergence analysis of SVT and the trend of rank for traffic sensing data matrix图8 SVT 收敛性分析和交通感知数据矩阵秩的变化趋势

Fig.9 Evaluation of adaptive recovery performance of missing traffic sensing data图9 缺失交通感知数据自适应恢复性能评估
Fig.10 Large-scale traffic sensing data recovery prototype system图10 大规模交通感知数据恢复原型系统
5.2 研究展望
在将来的工作中,进一步改进和完善本文存在的缺点和不足,主要包括3 个方面:1)交通站点的拓扑关系与它们感知数据的相关性有关,因此,如何利用交通站点道路拓扑图来进一步提高缺失感知数据精度是下一步的研究工作.2)本文只是以交通流量这种典型的交通感知数据作为例子研究交通感知数据恢复且只考虑了来自静态交通感知站点的感知数据.下一步将延伸和扩展到更多不同来源种类的感知数据,如来自无人机感知[44]和人群感知[45]的城市感知数据等.3)本文在恢复交通感知数据时,主要利用感知数据之间的时空相关性,但这些感知数据之间还存在其他多维度的联系,如数据类型等.下一步将结合其他多维相关性进一步提高恢复精度.
致 谢感谢重庆大学计算机学院张乃凡、程梁华、李耀宇对本文所做的贡献!
作者贡献声明:向朝参和程文辉提出了论文创新点,设计了论文实验方案,并撰写了论文;张昭实现了论文算法;焦贤龙、屈毓锛、陈超和戴海鹏指导了论文写作.
