基于逻辑回归分类算法的大学生就业去向模型研究
2023-03-22谭英王闯
谭英,王闯
(江汉大学生命科学学院,湖北武汉 430056)
随着每年应届大学毕业生数量的增长,又适逢我国经济发展的转型时期,对大学生就业指导工作的要求也逐年增高[1]。2022 届高校毕业生规模达1 076 万人,同比增加167 万,规模和增量均创历史新高[2],迫切需要对大学生的就业选择进行科学有效的引导。
高校毕业生存在职业生涯决策困难、就业意向的实现率较低等问题[3],传统的大学生帮扶主要采取谈心谈话的方式,具有一定程度的主观性。2021 届全国普通高校毕业生就业创业工作网络视频会议提出,要更好地发挥就业反馈作用,力促质量提升[4]。对已经毕业的大学毕业生信息进行深入分析,挖掘掩藏在数据背后的特征和规律,将有助于准确发现影响大学生就业去向的主要因素。对毕业大学生进行信息分析首先依赖于大学生基础数据的把握,然而大学生的各类信息是复杂、多维度的,需要整合多方面的资源并采用可靠的技术方法。
近年来,人工智能技术取得了突飞猛进的发展,其中机器学习理论和方法已被广泛应用于解决工程应用和科学领域的复杂问题。机器学习包括无监督学习、监督学习和强化学习等类型。由于毕业生的就业去向大多数是确定的,可以采用监督学习的方法构建学生就业去向的模型,为来年毕业生就业去向的选择提供参考。综上,应用机器学习理论可以作为大学生就业指导工作的新方法,它可以预测学生选择某种就业去向的成功率,帮助学生缩短就业迷茫期,减少慢就业学生比例。
1 研究综述
监督学习是机器学习中最常用也是最成功的机器学习类型之一,解决的问题主要有两种,分别叫作分类与回归,对大学生就业选择的模型构建属于分类问题。监督学习算法包括K 邻近、线性模型、朴素贝叶斯分类器、决策树、决策树集成等。K 临近是一种简单的机器学习算法,但是预测速度慢且不能处理具有很多特征的数据集,因此在实践中往往不会用到。决策树易出现过拟合、泛化性能很差的情况,在实际的使用过程中,大多数会采取决策树集成的方法。
线性模型是在实践中广泛使用的一类模型,几十年来被广泛研究,它既可以应用于回归问题,也可以用于分类问题,最常见的两种线性分类算法是Logistic回归(logistic regression)和线性支持向量机(linear support vector machine,线性SVM),线性模型的训练速度非常快,预测速度也很快。这种模型可以推广到非常大的数据集,对稀疏数据也很有效。
朴素贝叶斯分类器是与线性模型非常相似的一种分类器,它通过单独查看每个特征来学习参数,并从每个特征中收集简单的类别统计数据,它的训练速度往往更快,但泛化能力要比线性分类器稍差。
随机森林是解决决策树过拟合问题的一种方法,它本质上是许多决策树的集合,其中每棵树都和其他树略有不同,可以对每棵树的结果取平均值来降低过拟合,但对于维度非常高的稀疏数据,随机森林的表现往往不是很好[5]。
1.1 国外研究现状
国外对于大学生就业选择方面的研究文献较少,在方法上以回归分析为主。STONER,J.C.通过对四年制中西部研究机构的住院助理进行调查,利用定性数据分析方法评估了研究变量(情绪衰竭、自我感丧失、个人成就感)在不同性别、工作年限、是否继续雇佣中群体之间的差异,并探讨了它们之间的关系[6]。Peter A Bamberger 等人研究了学生饮酒行为对就业的影响,采用逻辑回归分析方法,假设正常数量和频率的饮酒,以及酗酒(HED)对毕业后的就业概率产生不利影响,收集了来自美国4 所不同地理位置大学的827 名毕业生的数据,发现正常饮酒对毕业后就业的可能性没有负面影响,但酗酒对求职有显著的负面影响[7]。Dernat等人报告了一项关于农村兽医学生在教育过程中职业选择的研究结果。根据社会表象理论,研究了学生在课程中构建的代表性项目是如何受到其生涯的社会空间因素(包括童年和工作地点)的影响[8]。Arranz N 等人以安达卢西亚大学1 053 名本科生为样本,研究大学生的创业意向以及大学生在创业过程中所感受到的障碍。该研究采用回归分析的方法,发现经济障碍、缺乏经验和培训是学生创业的主要障碍[9]。
Mohammed 研究影响学生就业选择的不同就业因素的相对重要性,探讨了影响就业选择的因素。这项研究是在大学的会计专业本科生中进行的,采用主成分分析法,发现起薪、独立工作能力和未来前景是影响大学生就业选择的最主要变量[10],该方法是机器学习中无监督学习的经典方法。
1.2 国内研究现状
国内对大学生就业去向的研究主要包括两个方面的内容,一是大学生就业意愿的研究,一是实际的大学生就业去向数据。在方法的使用上,对于就业意愿的研究多以传统的回归分析方法为主,周骏宇用二分变量逻辑回归的方式对影响大学生是否愿意“先就业后择业”的因素进行了分析[11],朱生玉、周晓蕾基于我国中西部地区10 个省份的数据,并运用回归分析方法,对影响我国大学生就业期望的因素进行分析[12],在指标的选择上二者都包括了个体、家庭背景和学科背景。
机器学习理论被更多地运用于实际的大学生就业去向的模型构建中,刘哲、赵志刚利用决策树,对辽宁省内部分高校的毕业生信息进行了分析,通过分类规则寻找影响毕业生就业单位性质的主要因素,在指标的选择上考虑了学生成绩和学生基础信息,但未考虑学生个人兴趣等指标[13]。李冬梅、路春艳、张雅惠以哈尔滨商业大学经济学院2017 级毕业生信息为基础,根据其数据特征模拟数据库,分析非学生的实际就业信息,准确率达到62.3%[14]。夏朋斌基于校园大数据(如:一卡通信息、成绩信息、就业信息等),对学生在校行为进行分析和计算,最后利用随机森林算法建立大学生就业预测模型,构建的预测模型准确率达70.8%[15]。李路瑶以层次聚类策略为技术支撑,架构出一种就业去向短期预测系统,该方法是无监督学习的经典方法[16]。孙怡帆等使用机器学习领域的Lasso-logistic 算法,构建了精准度高达70%以上的毕业生去向的预测模型[17]。
2 数据的来源与处理
2.1 数据的来源
本研究选择了来自武汉某省属高校某学院2014-2017 级(即2018-2021 届毕业生)的相关数据,数据来源于学院学生工作办公室、学校教务系统、学校就业管理系统和问卷调查。由图1可以看出2018年-2021年,学院大学毕业生人数呈逐年上涨趋势,大学生的主要就业去向仍然是升学或者就业。不同年份中的大学生去向有细微的变化,反映在2018年、2019年有少部分学生毕业选择创业而近两年选择创业学生减少,与之相反,近两年选择自由职业的学生增多,由于非升学和协议就业的学生人数较少,很难进行统计分析,所以不在本研究范围内,仅选取协议就业和升学作为研究对象。由于很难对已经毕业的学生做问卷调查,本研究选取2021 届毕业学生进行研究分析。
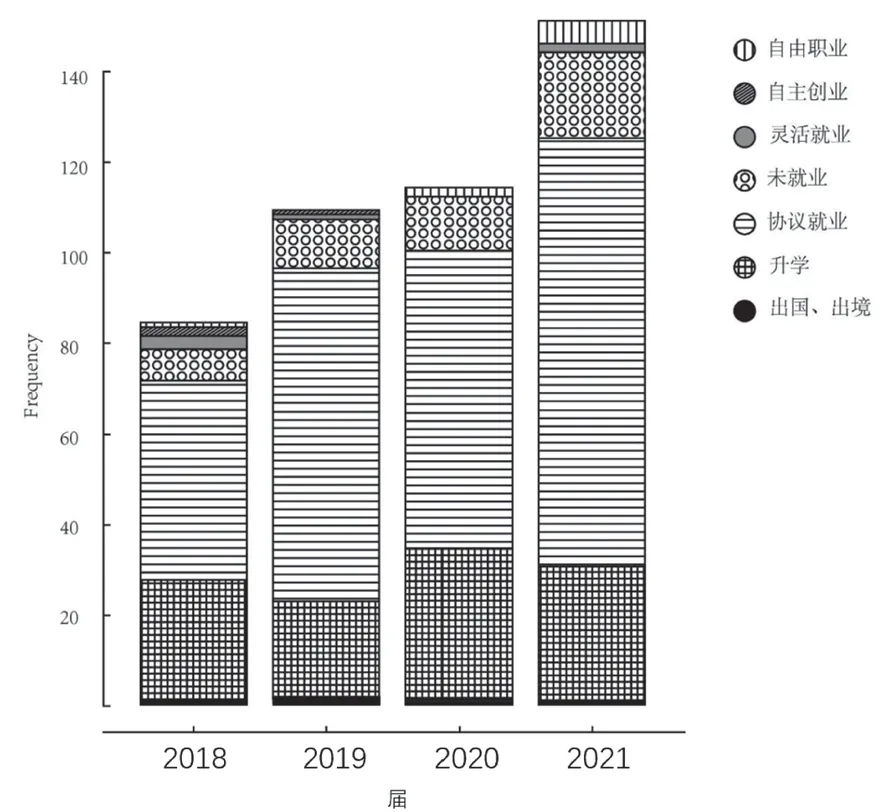
图1 从2018-2021 届毕业生就业去向柱形图,不同颜色代表不同就业去向人数
2.2 分类指标的选取和数据处理
大学生的就业去向受性别、家庭经济背景、学科背景、城乡背景等多种因素影响[12],也有学者从个体属性特征、家庭环境、学习背景和学生人力资本因素四方面来考查大学生就业期望的内在影响关系[18],本研究在已有的研究成果上,从个体属性、家庭环境、学习背景、在校表现这四个方面选取了10 个指标,构建了学生就业去向模型构建的指标体系(见表1),其中6 个指标为定性指标,4 个指标为定量指标。

表1 学生就业去向模型构建指标
根据学生工作办公室已有的数据和问卷调查数据,确定定性指标的分类,其中性格的测定采用霍兰德职业性格测试的方法,选用北森生涯职业测评问卷,根据性格测试分数,将学生的主要性格分为研究型(I)、艺术型(A)、社会型(S)、企业型(E)、传统型(C)、现实型(R)六个维度(表2)。

表2 定性指标分类
学生的助学金等级、平均学分绩点、获得社会奖励和综合奖励为定量指标,其中毕业后的平均学分绩点经过教务系统查询获得,其余的指标计算方式按照学生大学四年获得相应奖励或者助学金等级进行计算。在对各项综合奖励和社会实践奖励的赋值中,对学生在校期间的获奖难度进行赋值,后进行累加。对助学金等级的赋值中,对不同等级的助学金进行不同分数赋值,然后将各年度的助学金分数取平均数。通过以上方式,在一定程度上能够更加科学地衡量学生的定量指标(见表3)。

表3 定量指标计算方法
在指标的选择过程中,有一个需要注意的问题是各指标不应有显著相关性,为了避免上述问题,将学生获得综合奖励和平均学分绩点进行了相关性分析,通过Pearson 相关性分析得知,学生获得综合奖励和平均学分绩点的相关系数为0.40,属于弱相关,这是由于本校在奖学金评定时按照综合测评成绩进行评定,学习成绩占综合测评成绩的70%,且体测成绩不达标的学生无法获得高等级的奖学金或者无法获得奖学金,故学生的平均学分绩和获得综合奖励可以同时作为分类指标。
2.3 各项指标的单因素分析结果
为了初步了解各单个因素对学生就业选择的影响,分别对各分类指标和定量指标进行了卡方检验和T 检验。对各项分类指标进行的卡方检验显示,不同性格类别和学生是否入党对学生最终是否考研有较大的相关性(见表4),入党的学生和研究型性格的学生更倾向于考研。

表4 不同定性指标对于大学生就业选择影响的卡方检验结果
通过对各个定量指标的T 检验可以看到,学生获得综合奖励和平均学分绩点对于学生进一步深造有着非常重要的影响,而学生是否在社会实践活动中获得奖励则对就业去向没有影响(见表5)。

表5 不同定量指标对于大学生就业去向影响的学生T 检验结果
为了更加直观地观察各定量指标对学生就业选择的影响,本研究绘制了箱线图,平均学分绩点高、获得综合奖励多的学生更多地考取了研究生(见图2),值得注意的是家庭困难情况在统计上虽然对学生没有显著的影响,但是在实际的工作中仍然能够看到家庭困难情况对学生有一定程度的影响。

图2 不同定量指标下的就业去向箱线图:a)基于平均学分绩点,b)基于综合奖励,c) 基于助学金等级,d) 基于社会实践奖励
通过对四个定量指标做热力图并聚类,可以看到不同就业去向的学生的家庭困难情况、获得综合奖励、获得社会实践奖励和平均学分绩点情况(见图3)。通过图3可以看到,2021年选择协议就业的学生中获得综合奖励的学生有一半获得过助学金,而往年家庭困难的学生的升学率比非困难的学生升学率更高,这在一定程度上说明了家庭困难情况对学生就业选择的影响是随时间变化的。因此,本研究认为,对学生就业去向的建模应该基于同一年度的数据,而不应该横跨多个年份。

图3 不同年度基于不同就业去向的定量指标热力图:a)2021,b)2020年,c) 2019年
3 模型的构建
3.1 逻辑回归(Logistic Regression)和线性支持向量机(SVM)模型
本研究调用Python 语言的scikit-learn 项目完成,Logistic 回归在linear_model.LogisticRegression 中实现,线性支持向量机在 svm.LinearSVC(SVC 代表支持向量分类器)中实现。
3.2 随机森林(Random Forest)和朴素贝叶斯 (Naive Bayes) 模型
随机森林是机器学习算法的经典代表,采用RandomForestClassifier,首先对数据进行自助采集,然后选择特征个数,确保随机森林的每棵树不同。
scikit-learn 中实现了三种朴素贝叶斯分类器:GaussianNB、BernoulliNB 和MultinomialNB,本研究采用GaussianNB 进行。
4 模型的评价、对比和检验
4.1 模型的评价
本研究采取了逻辑回归(Logistic Regression)分类算法对大学生的就业去向进行了识别,将样本分为10组,其中9 组作为训练集,构建大学生就业去向识别模型,剩余一组作为测试集,运用混淆矩阵方法测试所构建模型的精准度和误差率,通过计算得知,在对125 个毕业生的就业去向识别过程中,有4 个学生预测为升学但实际选择了就业,还有15 名学生预测为就业但实际上选择了升学(见表6)。
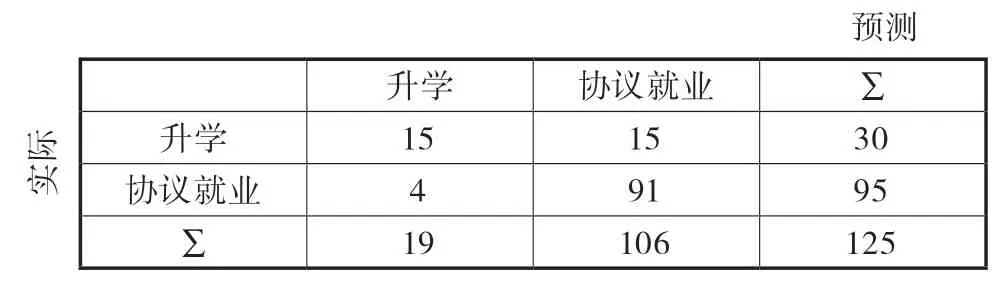
表6 逻辑回归(Logistic Regression)混淆矩阵
4.2 模型的对比
为了对逻辑回归(Logistic Regression)构建的模型进行横向对比,本研究还采取了线性支持向量机(SVM)、随机森林(Random Forest)和朴素贝叶斯 (Naive Bayes)这三种分类算法,对大学生的就业去向进行了识别,并应用以下指标对各个模型进行评价。
AUC:Area Under the Curve,ROC 曲线(受试者工作特征曲线)与横坐标之间的面积。
准确率(accuracy):正确预测的正反例数/总数(分母为定数)。
精确率(precision):也称查准率,正确预测的正例数/预测正例总数。
召回率(recall):也称查全率,正确预测的正例数 /实际正例总数(分母为定数)。
F_1 值(F_1 score):是精确率与召回率的调和平均值。
通过分析,逻辑回归(Logistic Regression)分类算法较其他三种算法有较好的表现,精准率和召回率均在85%以上,表明基于逻辑回归分类算法的模型具有更好的分类效果(见表7)。

表7 各个模型识别效果评价
4.3 逻辑回归(Logistic Regression)模型的合理性检验
从均匀分布的角度来看,AUC 的一致性作为聚合分类效果的衡量办法是被证实的,因此就四种模型AUC 的一致性进行了计算(见表8),表8显示了行中模型的得分高于列中模型得分的概率,较小的数字表示差异可以忽略不计的可能性。通过计算可以看到,采用逻辑回归(Logistic Regression)和线性支持向量机(SVM)的方法预测的结果具有较高的相似性,达到了82.8%,也进一步证实可以优先选择逻辑回归分类算法(Logistic Regression)构建大学生就业选择的模型。
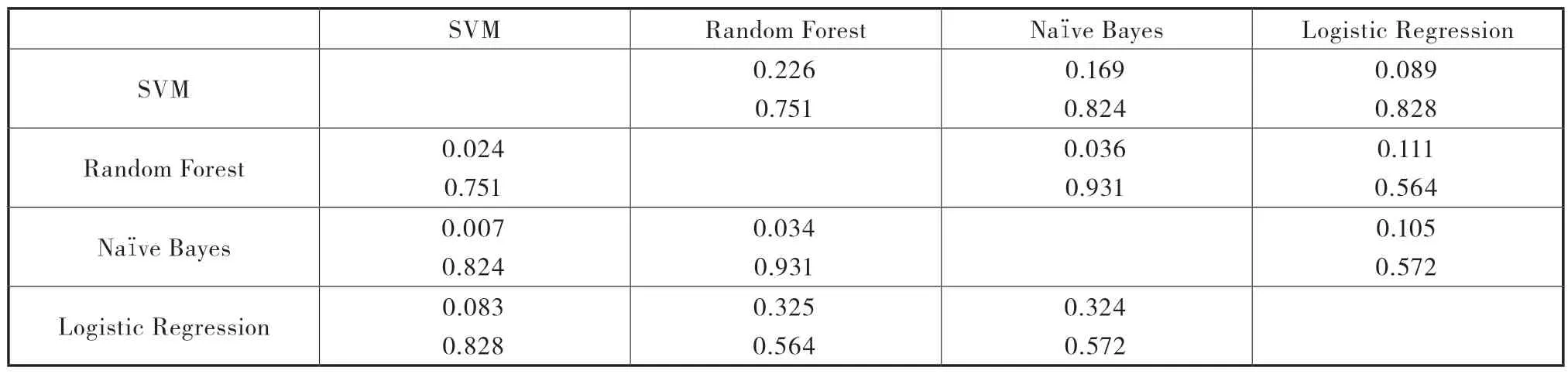
表8 各个模型的AUC 一致性比较
5 讨论
5.1 整合多方面资源,构建就业去向评估体系
对大学毕业生就业去向的模型构建依赖对学生大学四年详细的数据,目前很多高校虽然已经建立了学生信息化管理平台,但在具体的使用过程中,各管理部门与学院之间未能实现数据共享,导致院系工作层面缺乏统一的工作平台[19]。与此同时,高校也缺乏对大学生数据的深入分析,很多隐藏的高价值信息未能得到发掘与利用,少数研究者采用较为简单的规则运算或者较少的指标进行了分析[15,20],总体而言,目前高校对于大学生数据的利用率不理想。
本研究整合了学校、学院各个平台的学生数据,并结合问卷调查对学生职业性格进行了调查,但是由于条件的限制,对学生各方面的数据还掌握得不够全面,如在学生个人属性中没有考虑价值观和兴趣,在家庭背景中没有考虑城乡差异,在学生在校表现中主要依赖获奖情况,缺乏对学生在校行为的分析和计算,也没有对学生受处分情况予以考虑。
5.2 线性模型对大学生就业去向有更好的预测能力
本研究通过和另外几个机器学习算法的比较,发现逻辑回归分类算法(Logistic Regression)和线性支持向量机(SVM)相较其他的分类算法准确度更高,可靠性也较强,且二者预测的一致性也较高。究其原因,可能是因为这两个算法均属于线性模型,线性模型更加适合于变量和结果之间可能存在线性关系的情况。通过查阅文献发现,在对肿瘤的判断、就业去向预测等领域中,线性模型相比随机森林更具优势[17,21]。
比较逻辑回归分类算法(Logistic Regression)和线性支持向量机(SVM),从目标函数来看,区别在于逻辑回归采用的是logistical loss,SVM 采用的是hinge loss。这两个损失函数的目的都是增加对分类影响较大的数据点的权重,减少与分类关系较小的数据点的权重。在本研究中,由于特征变量相对于样本量来说比较大,采用逻辑回归,相较于线性支持向量更具有优势[22]。
5.3 模型仅适用于本学院的就业去向预测
由于影响大学生就业去向的因素非常复杂,模型是否合理,将直接影响给予的择业建议的准确性。本研究的数据是根据本学院大学生的数据分解生成的,适用于本学院近1-2年学生就业去向的预测。由于不同学校层次、专业、地理位置的差异,本模型不适用于其他学校或者学院学生就业去向的预测,但其他高校在模型构建的方法上可以采用逻辑回归分类等线性模型。
在实际的就业指导工作中,教师应在深入了解大学生实际情况的基础上进行就业指导。另外,毕业生的就业选择是一个不断变化的过程,需要不断的试错,调整自己的职业期望,找到属于自己的发展路径。随着经济和社会的发展,大学生就业选择将发生变化,指标也会发生相应改变,分类方法和手段也会日益丰富,尤其是高校信息技术的运用,可获得的学生指标将会更加精细,分类结果将会更加精准。
6 结语
本研究构建了大学生就业去向模型,并将其应用于所在学院的就业指导工作中,具体结论如下。
6.1 整合多个部门的数据是就业去向模型构建的基础
模型构建的基础是数据,在数据的采集工作中,需要整合方方面面的学生数据,尽可能地用数据对每一个大学毕业生进行翔实的“画像”。本研究中大学生就业去向信息数据库依据本校招就处、教务系统、学生工作办公室以及问卷调查的数据建立。
6.2 确定就业去向评估体系是建立就业去向模型的重要工作
大学生就业去向的评估需要选取合适的参数,本研究从个体属性、家庭环境、学习背景、在校表现四个方面建立了基于大学生就业去向的指标体系,实际的工作中还可以考虑学生兴趣、价值观、学生行为分析等多方面因素。
6.3 逻辑回归算法具有较好的大学生就业去向预测能力
本研究采用逻辑回归(LR)分类算法构建了大学生就业去向模型,同时用线性支持向量机(SVM)、随机森林(Random Forest)和朴素贝叶斯 (Naive Bayes)做对比,验证几种模型的优劣。相比于线性支持向量机、随机森林和朴素贝叶斯,逻辑回归分类方法具有更高的训练精度,评价结果最为理想,能有效地应用于学生就业去向模型的建构中,为大学生就业去向的指导提供技术参考。
