基于快速增量的时间触发以太网优化调度技术
2023-03-11袁海英王翌晨
袁海英,王翌晨
(北京工业大学信息学部,北京 100000)
0 引言
航电网络负责航电系统各组件之间的互连通信,执行任务时,网络通信必须保持稳定性、耐久性和安全性[1]。时间触发以太网(TTE)在标准以太网IEEE 802.3基础上,加入时间触发(TT)机制,建立全局时钟同步,具有高带宽和高实时特点,从而广泛应用于安全关键系统中[2],成为新一代航空航天网络技术发展的新趋势。TTE消息由TT消息、速率受限(RC)消息和尽力传(BE)消息构成。服务质量要求最高的TT消息,根据静态调度表执行发送和转发任务,确保通信具有严格的时间确定性。较低优先级的RC消息,利用TT消息传输的空闲时隙发送,最低优先级的BE消息尽力传输,从而满足不同服务质量要求的信息传输需求。兼顾其他消息传输性能,合理建立TT消息静态调度表是TTE调度问题的研究热点。
文献[3]提出SMT求解法,通过建立一组约束条件,实现静态调度表求解。基于高性能SMT求解器生成静态调度表的方法有Z3[4]和Boolector[5]。在SMT基础上,文献[6]提出了逐级迭代冲突回溯方法,进一步优化了调度结果;文献[7-8]采用启发式算法生成静态调度表,求解速度更快,但求解结果不一定为最优解;文献[9]创新性地使用了IBM Ilog Cplex求解器求解调度表;文献[10-11]分别通过对TT流量进行增量化调度和对实时任务调度时间进行分块,将调度模型转化为一个具有更少决策变量的约束规划模型,相较于SMT大幅度提升了求解速度。上述方法在建立TT消息调度表时忽略TT消息对RC消息的影响。文献[12]通过对各端系统的时刻调度表进行分区,整合网络资源,减少了RC流量的延迟;文献[13]在SMT求解的基础上,采用基于贪婪随机自适应搜索法的TTE通信调度算法,降低了RC消息的端到端延迟。
基于约束规划的TTE调度算法设计思想,本文提出了一种基于快速增量的TTE优化调度技术,有效提升RC消息传输性能。
1 问题抽象建模
1.1 网络模型
TTE在各个通信设备间采用双工通信,星型网络拓扑结构如图1所示。该网络具有6个通信设备节点,其中,交换机节点1个,终端设备节点5个,带有双向箭头的实线代表支持双工通信的物理链路。

图1 TTE网络拓扑Fig.1 TTE network topology
TTE网络模型定义如下。
采用无向图G=(V,E)表示网络拓扑结构。其中,集合V={v1,…,vm}表示该网络具有m个通信设备(终端设备和交换机);集合E= {[va,vb],[vb,vc],…,[vy,vz]}表示该网络数据链路集合,其元素为相邻通信设备组成的数组。
TT消息集合由TM={tm,0,…,tm,n-1}表示,每个TT消息由tm,i={st,m,i,tt,m,i,lt,m,i,ft,m,i}表示。其中:st,m,i表示该消息的帧长;tt,m,i表示该消息的发送周期;lt,m,i表示该消息容忍的最大端到端延迟;ft,m,i表示该消息在网络中的传播路径。
RC消息集合由RM={rm,0,…,rm,n-1}表示,每个RC消息由rm,i={sr,m,i,tr,m,i,lr,m,i,fr,m,i}表示。其中:sr,m,i表示该消息的帧长;tr,m,i表示该消息的发送间隔;lr,m,i表示该消息容忍的最大端到端延迟;fr,m,i表示该消息在网络中的传播路径。
1.2 问题模型
终端v1向交换机v4发送TT消息tm,1和RC消息rm,1,tm,1={12 208, 4.9216E-5, 9.8432E-5,{[v1,v3],[v3,v4]}},rm,1={12 208,4.9216E-5,9.8432E-5,{[v1,v3],[v3,v4]}}。终端v2向交换机v4发送TT消息tm,2,tm,2={12 208,9.8432E-5,9.8432E-5,{[v2,v3],[v3,v4]}}。假设TTE通信速率为1 Gibit/s,则1.2304E-5 s为一个基本调度单元。假设交换机转发延迟为1.2304E-5 s,交换机发送端口的缓冲区所能容纳的最长时间为4.9216E-5 s。
TT消息对RC消息的影响如图2所示。

图2 TT消息对RC消息的影响Fig.2 Influence of TT messages on RC messages
图2(a)展示了未考虑RC消息端到端延迟时生成的TT消息调度情况,RC 消息最大端到端延迟为 4.9216E-5 s。调整tm,2发送偏移量,优化后的消息调度情况见图2(b)。在未改变TT消息端到端延迟的情况下,增加tm,1和tm,2的发送偏移量间隔,减少了rm,1因长时间等待高优先级TT消息传输而造成的端到端延迟,rm,1的最大端到端延迟减少至3.6912E-5 s,平均端到端延迟也随之减小。这表明降低TT消息对RC消息传输性能影响的问题可以转化为:在保障TT消息可调度的前提下,将同一链路上任意两个TT消息的发送间隔尽可能增大,通过缩短RC消息的等待时间,减少RC消息的端到端延迟,提升网络传输性能。
2 静态调度表优化求解设计
基于约束规划思想,设置TT消息传输约束,通过对基本调度单元采取乘二放大和加一放大,更新TT消息调度表,快速增大TT消息的发送偏移量间隔。采用回溯算法修正因基本调度单元增大而导致的延迟误差。回溯时,对TT消息在基本调度单元中的位置进行调整,得到优化后静态调度表。
2.1 TTE约束设置
通常,航空航天综合电子系统等安全关键系统内部各个组件之间通信关键消息的负载较小[11],此时每个通信消息对应一个TT消息。以最长以太网帧的传输时间作为最小基本调度单元进行求解,调度时刻和调度周期皆为基本调度单元的倍数关系。通过将静态调度表求解问题转化为混合整数规划问题,减少约束变量,提高了求解速度。
调度表求解算法通过IBM Ilog Cplex求解器实现,并将其封装为CpoModel模块,求解器需要添加以下3个约束。
1) 链路无冲突约束。任意两个TT消息在数据链路不会发生时间上的冲突,即
(1)
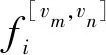
2) 多跳约束。TT消息在本跳的完成时刻应该早于下一跳的开始时刻。多跳约束最大值为交换机的发送缓冲区大小,最小值为交换机的转发延迟,即
(2)
式中,mem_bound和fwd_delay分别为交换机发送端口缓冲区所能容纳的最长时间和交换机转发延迟与基本调度单元的商。
3) 端到端延迟约束。TT消息的端到端延迟小于通信设备上实时应用所能容忍的最大端到端延迟,即
(3)
式中,max_latency为最大端到端延迟与基本调度单元长度的商。
2.2 快速增量过程
快速增量过程如下。
input:networkG,message setMand basic dispatching unitb
output:schedule number setR
1 basic dispatching unittb←b;
2 schedule number setN←NULL;

5foreachmessageminMdo

7ifIsNotInteger(GetDispatchingUnit(m))then

9end
一个燥热的夏日,我握住笔的手微微颤抖,看着满是红叉的试卷,努力控制着情绪。抬眼撞上小宇那玩世不恭的神情,怒火不可遏制地席卷而来。我扬起手,怒目圆睁,他却将脸迎向我,露出无所畏惧的表情,仿佛在说:“你打我又如何?”就这样,伴随着窗外学生嬉笑打闹、穿梭奔跑的喧哗声,师生间进行着没有硝烟的对峙。
10end
11ifi≠Truethen

13end
14else

16N←CpoModel(G,M).solve();
17tb←tb×2;
18end
19whileN=NULL;
20do

22foreachmessageminMdo

24ifIsNotInteger(GetDispatchingUnit(m))then

26end
27end
28ifi≠Truethen

30end
31else

33N←CpoModel(G,M).solve();
34tb←tb+b;
35end
36whileN=NULL;
输入网络拓扑模型G、TT消息模型M和初始基本调度单元长度b,得到静态调度表R。首先对基本调度单元采取乘二放大,即循环放大基本调度单元至当前基本调度单元的2倍。基本调度单元放大时,TT消息周期不变,调度周期会减小,故遍历TT消息,使用GetDispatchingUnit()得到各消息调度周期。若调度周期不为整数,跳过此次放大操作;若为整数,使用UpdateMessage()更新调度周期,然后使用调度表求解模块CpoModel(G,M).solve()解得当前基本调度单元下静态调度表R并保存。停止循环的判断条件为不能得到满足约束的TT消息静态调度表,即R为空。结束乘二放大后,开始加一放大,即在当前基本调度单元的基础上循环增加初始基本调度单元。放大过程以及停止循环的判断条件与乘二放大相同。完成所有放大操作后,该基本调度单元为满足TT消息可调度的最大基本调度单元。在1 Gibit/s传输速率下初始基本调度单元设置为1.2304E-5 s。
2.3 多跳延迟修正
多跳TTE中,每次经过交换机,都将交换机处理延迟计入TT消息调度时间。由于传输时间按照基本调度单元进行切片划分,设置的交换机处理延迟随着基本调度单元的增加而增加,因此需要修正这种偏差。
修正过程采用回溯方式,输入TT消息模型M和静态调度表R。遍历TT消息,使用GetLastLink() 得到各TT消息最后一跳的调度序号传入前端或者后端复位函数Reset()进行处理,然后使用GetPriorLink()回溯至上一跳,每当经过一个交换机时,使用SetTime()函数更新当前TT消息调度时刻以及该TT消息后续跳转的调度时刻,直至回溯至源端通信设备,最终得到优化后的TT消息静态调度表R。
由于基本调度单元不断放大,TT消息实际长度不变,因此需要对TT消息在基本调度单元中的位置进行复位调整。复位函数Reset()可分为前端复位和后端复位。前端复位函数为
r=b×s+d
(4)
后端复位函数为
r=b×s+(b÷d-1)×b
(5)
其中:r为真实调度时刻;b为增量后基本调度单元长度;s为调度序号;d为基本调度单元初始长度。
3 实验仿真与验证
对基于快速增量的TTE优化调度技术进行性能仿真,仿真平台为Windows10,Intel®CoreTMi7-10710U CPU@1.10 GHz,16 GiB RAM。
3.1 基本拓扑网络验证
按照图1构建网络拓扑,目标网络为具有1个交换机和5个终端设备的星形拓扑结构,交换机与终端设备通过数据链路相邻。设置该网络中存在10条广播TT消息,源端设备随机生成,TT消息周期从集合{2.4608E-4, 4.9216E-4}中随机选择。TT消息设置以及基于约束规划和快速增量调度算法的静态调度表见表1,该表仅展示基于两种调度算法的TT消息源端设备发送时刻,而交换机接收、发送时刻可由此推得。
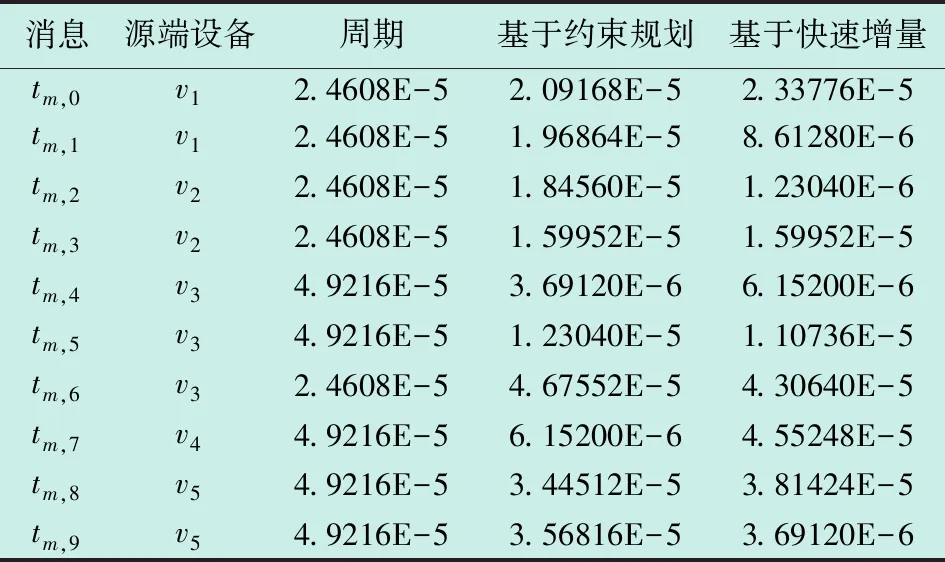
表1 基于两种调度算法的TT消息对比Table 1 Comparison of TT messages based on two scheduling algorithms s
根据网络拓扑、消息情况以及静态调度表设置仿真环境。仿真环境包括开源网络仿真软件OMNeT++5.5.1以及框架INET-Framework和CoRE4INET。为模拟真实网络环境,所有通信节点的晶振最大漂移值设置为200×10-6,晶振周期漂移变化范围为uniform(-100×10-6,100×10-6)。物理链路设置为长10 m、物理传输速率2E+8 m/s的光纤,带宽配置为1 Gibit/s。仿真最小时间单位为16 ns,即各节点的晶振周期为62.5 MHz。
设置5条RC消息,源端设备为v2、末端设备为v4,消息发送间隔从2E-4 s开始依次增加2E-4 s,消息长度从4E+3 bit开始依次减少8E+2 bit。
图3(a)和图3(b)分别为基于约束规划和基于快速增量的调度算法得到的RC消息rm,1的端到端延迟。基于约束规划的调度算法最小延迟和最大延迟时间分别为6.153 8E-5 s和8.516 1E-6 s,平均值为1.557 3E-5 s。基于快速增量的调度算法最小延迟和最大延迟时间分别为2.520 2E-5 s和8.516 3E-6 s,平均值为1.287 8E-5 s。基于快速增量与基于约束规划的调度算法相比,RC消息rm,1的最大端到端延迟降低59.05%,平均端到端延迟降低26.96%。
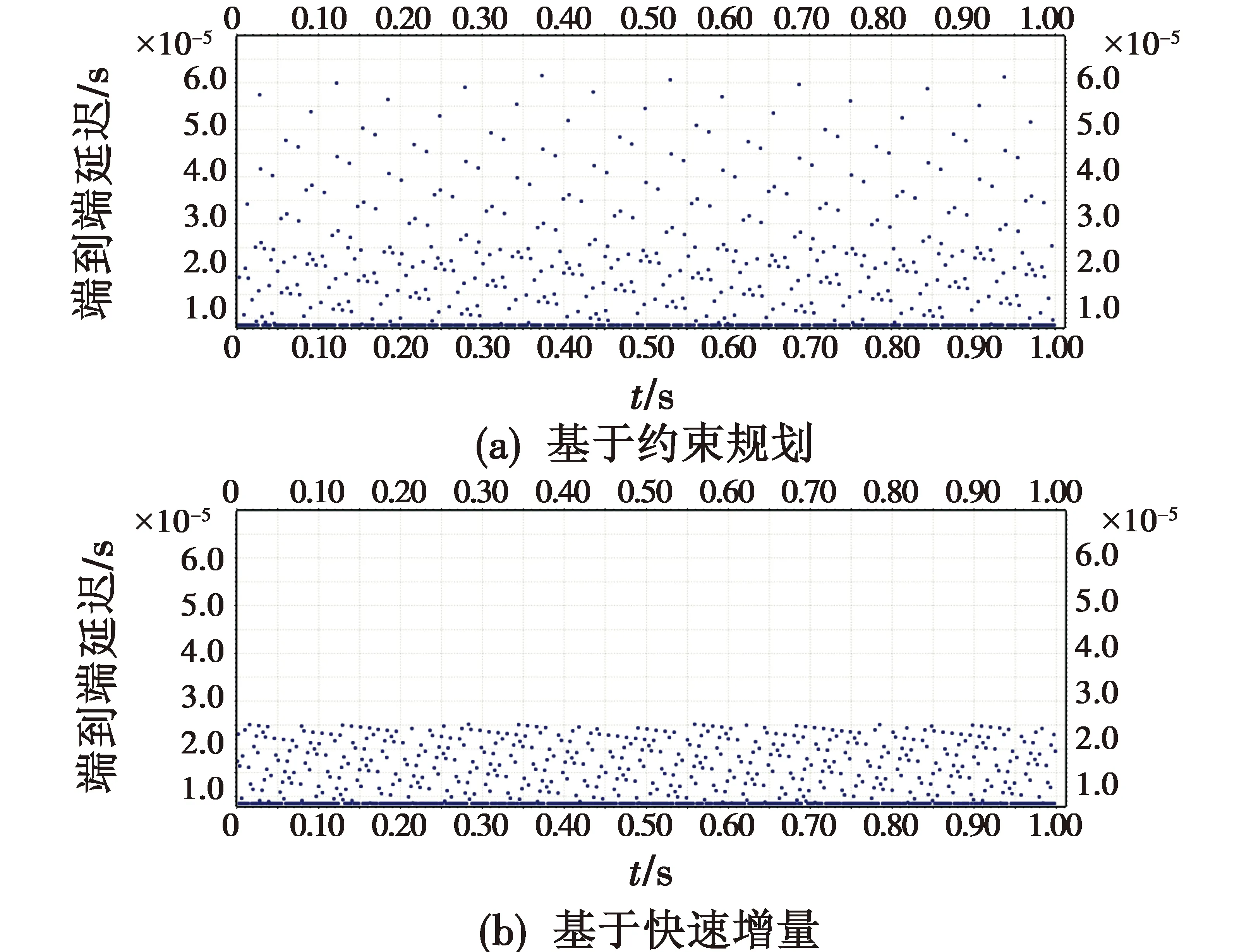
图3 基于两种算法RC消息rm,1的端到端延迟比较Fig.3 End-to-end latency comparison of RC message rm,1 based on two algorithms
采用基于约束规划和快速增量调度算法,RC消息的端到端延迟如图4所示。

图4 基于两种算法RC消息端到端延迟比较Fig.4 End-to-end latency comparison of RC messages based on two algorithms
RC消息的最坏端到端延迟减小44.81%,平均端到端延迟减小17.31%。在小型网络配置中,基于快速增量的TTE优化调度技术有效减小了RC消息的端到端延迟。
3.2 时间触发航电系统网络验证
为了验证算法的扩展性,采用逐次增加网络消息数量的方式检验算法的性能。参考时间触发航电系统架构[14]构建航电系统TTE,其拓扑模型如图5所示,包括11个节点和6个交换机。

图5 航电系统架构TTE拓扑模型
网络中TT消息由10条逐次增加至50条,RC 消息数量为25,TT消息周期与RC消息周期在{2.4608E-4 s,4.9216E-4 s}中随机选择,消息的帧长范围为 64~1518 B,链路带宽配置为1 Gibit/s。
基于两种算法的RC消息平均端到端延迟和最坏端到端延迟如表2所示。
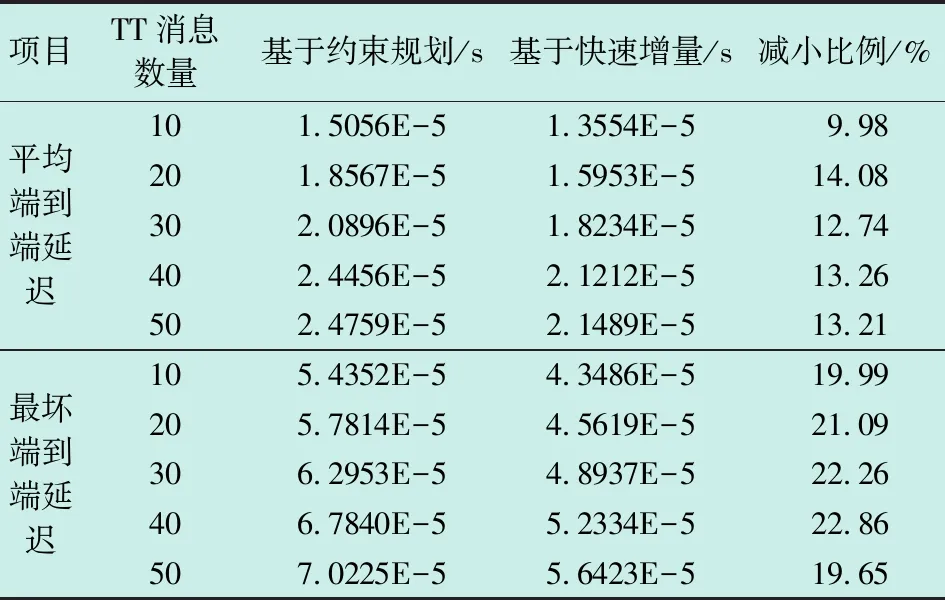
表2 基于两种算法的RC消息端到端延迟对比Table 2 End-to-end latency comparison of RC messages based on two algorithms
相较于约束规划算法,采用快速增量算法可使RC消息平均端到端延迟最高优化14.08%,最坏端到端延迟最高优化22.86%。在网络拓扑更复杂、负载量更大的情况下,该算法可以减少RC消息的端到端延迟,有效提升整网的实时性能。
4 结束语
为了优化TTE网络性能,基于约束规划的TTE调度思想,本文提出了一种基于快速增量的TTE优化调度技术。输入网络拓扑结构和TT消息集合,通过快速增量基本调度单元,回溯修正多跳延迟,得到优化后的TT消息静态调度表。本文算法在保障TT消息可调度前提下,有效提升了RC消息传输性能。经过多组实验验证了算法的有效性和可扩展性:
1) 在基本拓扑网络模型中,RC消息的平均端到端延迟减小了17.31%,最坏端到端延迟减小了24.24%,算法有效提高了网络数据传输性能;
2) 通过TT消息增量化实验可得,该算法适用于负载量更大的时间触发航电系统网络拓扑模型,RC消息的平均端到端延迟最高优化了14.08%,最坏端到端延迟最高优化了22.86%。
