基于深度学习的小目标检测技术发展
2023-03-11赵景波杜保帅
赵景波,杜保帅
(青岛理工大学,山东 青岛 266000)
0 引言
当下目标检测任务中,小目标检测由于尺寸小、可提取的特征信息少等问题导致检测性能一直落后于大、中等目标,为了缓解此问题,国内外众多研究人员着重研究提高小目标检测性能的方法,许多基于深度学习的优化改进算法逐渐被提出,从一定程度上提高了小目标的检测性能,小目标检测技术已经广泛应用于交通标志、行人检测、航空、舰船、农业检测等众多领域,但相比于大、中等目标还有一定的差距。
基于深度学习的目标检测算法作为该领域的研究热点,许多改进策略逐渐被提出,产生了大量基于深度学习的小目标检测算法,并在各领域的数据集上取得了显著的成果,但仍有很多问题没有得到很好的解决,例如,对于大目标和小目标物体聚集在一起的区域检测效果较差;在复杂背景下的小目标物体检测精度不理想等。目前已有较多的关于深度学习的目标检测算法综述,但针对小目标物体检测的综述不多。因此,本文总结了基于深度学习较为主流的目标检测算法,通过对小目标检测在实际检测领域中所遇到的问题进行分析,重点归纳总结了可以有效提升小目标检测和定位精度的基于深度学习的已有算法和改进策略,对前人的工作进行了梳理总结,并对未来的研究重点进行了展望。
1 目标检测算法
目标检测算法主要由传统的人工特征检测算法和基于深度学习的目标检测算法两大类组成,基于深度学习的目标检测算法又分为两阶段(Two-stage)和一阶段(One-stage)检测算法,图1为常见目标检测算法的发展进程。
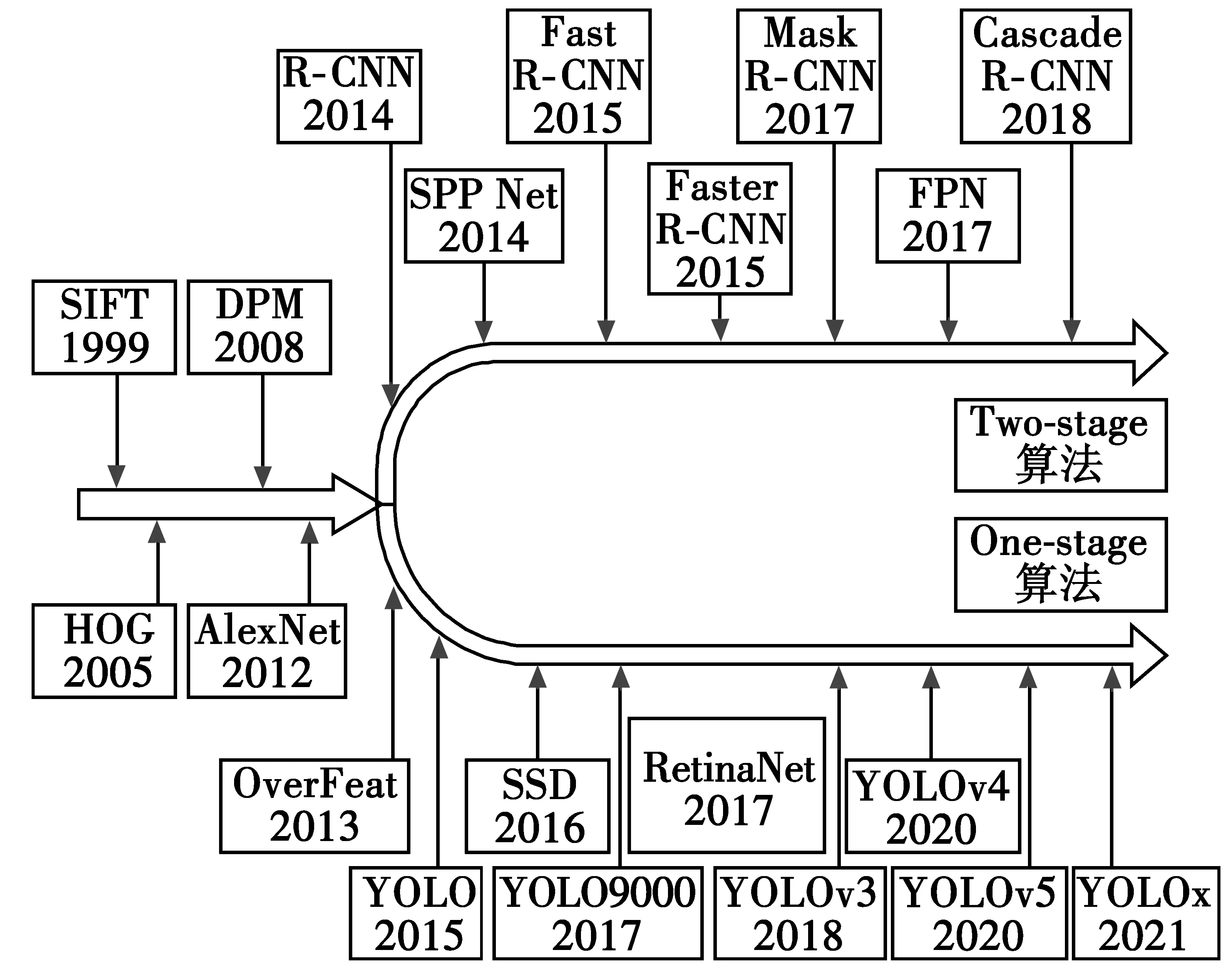
图1 目标检测算法时间轴Fig.1 Timeline of target detection algorithms
1.1 传统目标检测算法
传统的目标检测算法流程:使用大小不同的滑动窗口对输入图像进行遍历,选择出有可能存在目标的候选区域,然后使用手工设计的特征对选择的候选区域进行特征提取,如HOG,DPM和SIFT等,最后将特征输入到SVM或迭代算法等分类器中,对目标进行分类。文献[1]提出了一种基于多特征提取和多核学习SVM的SAR图像舰船目标识别方法,从特征提取和分类器训练两个方面提升目标识别的准确度,准确率由传统SVM的87.18%提高至92.31%。
1.2 两阶段目标检测算法
2012年,KRIZHEVSKY等提出的AlexNet以巨大的优势取得冠军以后,基于深度学习的目标检测方法迅速发展起来,VGGNet,GoogLeNet和DenseNet等卷积神经网络模型被提出,并成为目标检测领域应用的主要对象。2014年,文献[2]首次将候选区域与卷积神经网络结合,提出了R-CNN算法。通过选择性搜索算法生成2000个候选区域送入卷积神经网络分别进行特征提取,使用SVM进行分类及回归,如图2所示。R-CNN算法在PASCAL VOC数据集上获得了极好的检测性能,但选取的多个候选区域之间有重叠现象,对重叠区域进行特征提取导致浪费过多时间且占据空间。
为优化R-CNN目标检测算法,文献[3]通过在全连接层前增加SPP池化层,使任意输入转化为固定的输出,避免了重复运算并加快了训练过程,但每个阶段仍需单独训练。GIRSHICK基于SPP Net提出了Fast R-CNN,特征提取网络对待检测图像使用一次特征计算,对目标的分类不再通过支持向量机,而是使用多任务损失函数对目标直接进行分类与回归,大大节省了时间,缺点在于无法进行端到端的训练。所以,REN等[4]再次对Fast R-CNN进行改进,设计了RPN区域推荐网络,将卷积神经网络提取到的整张特征图送入区域推荐网络进行候选框的选取,实现了特征的共享并省去了大量的运算。由于使用了区域推荐网络,Faster R-CNN 算法不再需要分阶段进行训练,这标志着两阶段算法达到了较为成熟的水平。
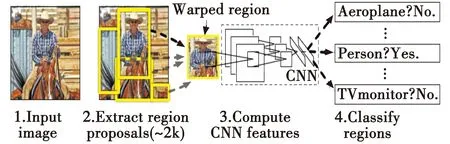
图2 R-CNN架构图Fig.2 Diagram of R-CNN architecture
1.3 一阶段目标检测算法
虽然Faster R-CNN实现了端到端的训练,但两阶段算法的实时性较差。2013年,YANN等提出了著名的OverFeat,通过利用卷积神经网络的特征共享,将对象分类和对象位置集成到一个网络架构中,把分类过程中提取到的特征再次应用于检测等各种任务中,节省了大量的时间。2015 年,REDMON等[5]提出了YOLO算法。把输入图像平均分割成S×S个网格,如果检测目标的中心点落入了某个网格内,那么就由该网格负责检测并把中心点相对于该网格的坐标点、待检测对象的长宽和类别信息进行回归。YOLO与Faster R-CNN都是采用端到端的检测算法,但YOLO没有候选框,因此YOLO的检测速度达到了45 帧/s,检测速度比两阶段检测算法显著提高。
LIU 等[6]在YOLO算法的基础上提出了SSD算法,该算法主张使用全卷积网络并引入了锚点,在不同尺度的特征层上进行预测,最后进行整合。文献[7]对SSD算法进行改进,由特征金字塔网络替代传统CNN网络并进行一系列优化,在COCO2017数据集上AP/APs检测准确率达到48.3%/27.8%。SSD之后,REDMON等[8]提出了YOLOv2,该算法使用DarkNet-19作为主干网络,去除全连接层并对每个卷积层进行批量标准化,通过增加passthrough层使不同深度的特征层进行拼接融合。YOLOv2算法提出之后,REDMON等在其基础上进行了改进,提出了YOLOv3算法。文献[9]采用融合ResNet的DarkNet53作为网络的主干网络,残差块的使用大大减少了有效信息的损失并缓解了深层网络在训练时发生的梯度消失的问题。YOLOv3算法采用特征融合实现了两阶段算法与一阶段算法优点的集成,速度与精度均达到了良好的检测效果。
2 小目标检测
2.1 定义
对目标尺寸评价指标中,小目标物体的定义在目标检测领域一直没有准确的界限。目前主流的定义方式是从绝对尺度和相对尺度两方面来界定。从绝对尺度来说,文献[10]中指出检测目标的像素点小于32×32时,该目标即为小目标物体;从相对尺度来说,当检测目标在原图像中所占比例达到1%时即为小目标物体。
2.2 小目标检测存在的问题
第1章中陈述了目标检测领域中常用的目标检测算法,但无论从两阶段算法还是一阶段算法来说,小目标的检测一直阻碍着目标检测领域的进一步发展,本文将对造成小目标检测性能差的原因进行分析与总结。
1) 目标尺寸过小、可提取特征因素少。由于目标尺寸过小或在整张图像中占比过少,小尺度目标相对于大、中尺度目标存在分辨率低的问题,在经过池化后小目标的信息进一步损失,因此在深层次的网络中小目标可提取的特征变得很少。在一些实际检测对象中,如遥感图像、密集鸟群、车牌等,准确快速检测出目标对象有极大的难度。
2) 检测环境复杂,易造成干扰。常用的小目标应用检测环境较为复杂,如航空图像、水下目标等领域。在复杂的检测环境下,小目标的特征信息会被外部环境所影响,并且有的待检测小目标图像由于尺寸过小、特征不明显等特点与复杂环境融为一体,很难被检测出来。
3) 数据集过少,训练效果差。在当前的目标检测领域中,大部分数据集针对大目标和中等目标检测,现有的小目标数据集普遍适用于某一个领域,例如行人、人脸、遥感数据集等,这些数据集不具备通用性,网络的训练效果并不好。目前发布的数据集中,MS COCO数据集包含较多的小目标图像,占总数的31.62%,但由于其中的图像包含的实例较多,小目标分布得十分不均匀,导致训练出的检测效果也较差。
4) 小目标自身易聚集问题。在一张待检测图像中,中、大目标出现的次数较少而小目标聚集现象较为频繁。当此种现象发生时,输入图像经过卷积神经网络的多次降采样后会在深层次的特征图中显示为一个点,导致无法对其进行检测。
3 小目标检测算法
随着深度学习的快速发展,目标检测领域的学者们开始着重研究使用深度学习来提升小目标检测的性能。本文主要从以下6个方面进行分析归纳。
3.1 基于数据增强策略
小样本检测困难的因素之一是数据集中的样本数量匮乏,通过使用数据增强的方法可以使数据集的样本变得丰富,进而减轻因数据匮乏而造成小目标检测效果差的问题。文献[11]提出一种小样本红外飞机目标数据增强方法,实验证明了所提方法的有效性与先进性。
随着目标检测技术的不断发展,针对数据集增强的方法层出不穷。文献[12]中Mixup使用线性插值的方法将不同类之间的图像混合产生新的样本来达到增大样本集的目的;文献[13]中Random erase在输入图像中随机选择一个矩形区域并把该区域内的像素值更改为随机值进行数据增强;文献[14]中Gridmask通过生成与输入图像分辨率相同的Mask,与原图像相乘得到一个新的图像。数据增强策略促进了小尺度目标在数据集中的丰富性,进而提高了检测精度等。
为解决数据集含有小物体的图片少以及图片中小物体出现得少等问题,文献[15]提出了复制增强的方法,通过调整训练集中小目标图像的数量,使其达到训练时所需要的样本数量。并在将小目标粘贴到其他位置之前,将小目标在±20%范围内进行缩放,在±15°范围内进行旋转增强,增强过程只适用于没有被其他目标遮挡住的小目标,并确保粘贴后不会覆盖其他目标,在MS COCO数据集上进行了实验,相比于Mask R-CNN,对小目标的检测精度提高了7.1%。
Mosaic策略将4张待检测图像缩放后随机拼接并调整成与原始图像尺寸相同时再进行训练。训练、缩放和拼接后的图像改善了数据集中样本分布不均衡现象,使检测目标的背景更加丰富,解决了小目标分布不均匀的问题。文献[16]提出了Stitcher策略,使用4张具有相同尺寸的图像随机进行拼接,将大尺寸和中等尺寸目标缩放为中等尺寸和小尺寸,通过使用4种语义信息不同的图像进行拼接,增加了小目标的数量,使其分布更加均衡,图3为Mosaic与Stitcher方法对比效果。
文献[17]使用Stitcher数据增强方法解决小目标样本分布不均匀的问题后,通过优化主干网络,小目标检测精度提升了7.2%。
3.2 基于多尺度学习策略
卷积神经网络浅层目标因感受野小、分辨率高、位置信息丰富等特点适用于小目标检测,而深层目标因感受野大、分辨率低、语义丰富等特点适用于检测中等及大目标。因此,国内外的学者开始尝试使浅层的特征与深层的特征相结合,在利用浅层特征细节信息丰富的同时结合了深层特征语义信息丰富的特点,进而提高小目标检测的精度。
2016年,文献[18]提出了Inside-Outside算法,如图4所示。Inside-Net将第3~5个卷积层提取的浅层特征图进行拼接固定到特定长度。将第5个卷积层输出的特征输入到两个IRNN进行上下文信息的提取,并经过感兴趣池化固定到特定长度,与前面获得的多尺度特征经过正则化后聚集在一起,经过1×1卷积降维后进行分类与回归,实验证明该算法超过了Faster R-CNN等大多数网络算法。
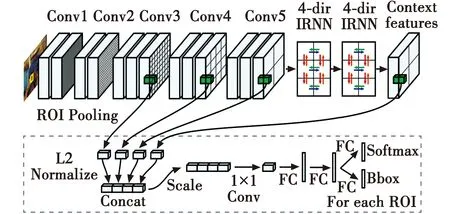
图4 Inside-Outside算法结构Fig.4 Structure of Inside-Outside algorithm
2016年,KONG等[19]提出了HyperNet模型,该算法提取了多个不同尺度网络层的特征图,以中间层作为基准,前一层的特征图使用最大池化的方式达到相应尺寸,后一层的特征图使用反卷积的方式放大到相应尺寸。多尺度的特征图连接后使用局部响应归一化(LRN)方法进行归一化,将其压缩到一个称为超特征的空间,该空间结合了各个特征层的信息,将信息经过感兴趣池化后生成区域建议框进行目标检测,实验证明小目标的检测性能比Faster R-CNN更加精确,mAP提高了3.1%。
在第1章提到的一阶段检测算法中,YOLO系列的算法自YOLOv2起均在颈部网络中使用到了多尺度融合的理念。YOLOv3中颈部结构使用了特征金字塔网络(FPN)[20],由一个自底向上的路径和一个自顶向下的路径构成,两条路径横向连接将尺寸不同的特征图拼接进行多尺度的预测,与FPN不同的是YOLOv3特征图之间的连接是通道融合。文献[21]将YOLOv3模型中降采样后的特征图与第2及第3个残差块的输出进行叠加,以此增强浅层特征信息,改进之后的网络模型有效提高了小目标的检测准确率。
2019年,文献[22]针对检测网络在训练过程中存在的检测框采样、特征图、目标函数不平衡问题进行了探究,提出了Libra R-CNN算法。该算法就特征图层次的问题提出了平衡特征金字塔,利用同样深度整合的均衡语义特征来强化多层次特征,如图5所示,主要由调整规模、整合、细化和强化4个步骤组成。首先将C2~C5特征图的大小调整为同C4大小的尺寸,整合后得到均衡的语义特征,采用高斯非局部注意的方法进行特征的强化,然后进行多尺度预测,在MS COCO数据集上,小目标的检测率达到25.3%。

图5 平衡特征金字塔Fig.5 Balanced feature pyramid
2020年,文献[23]在颈部网络中使用了PAN[24]结构,PAN的优势在于,在FPN层的后面又增加一个自底向上的特征金字塔。FPN的结构自上而下地传递丰富的语义信息,特征金字塔自下而上地传递丰富的定位信息,两种信息相互结合,使小目标的检测精度达到26.7%。文献[25]在YOLOv4-tiny的基础上扩大检测尺度范围,并利用深层语义信息自下而上地与浅层语义信息进行融合以丰富小目标的特征信息,平均精确率比原网络提高了5.09%,具有较好的综合性能。
3.3 基于提高分辨率策略
小目标在图像中所占像素少、分辨率低,为了从根本上解决这个问题,使小目标图像生成高分辨率图像作为检测模型的输入,GOODFELLOW等[26]提出的生成式对抗网络(GAN)成为了提升小目标分辨率的研究热点,GAN主要由生成器和鉴别器组成,两者之间相互博弈共同发挥作用。文献[27]利用生成对抗网络进行特征变换,获取多尺度与旋转角的检测图扩充样本,提升检测精度。
LI等[28]在GAN的基础上提出了Perceptual GAN(结构见图6),利用不断更新的生成器网络和鉴别器网络生成小目标的超分辨率图像以提高检测性能。生成器网络将第一个卷积层的输出作为输入,经过残差网络的学习与第5个卷积层的特征元素进行加操作,目的是生成小目标的超分辨表示。鉴别器网络将生成的超分辨率表示作为输入,将其分为两个分支:对抗分支和感知分支。生成器从较低层次的细粒度细节中学习残差表示,并通过试图欺骗受过良好训练的鉴别器来区分这两种表示,增强小对象的表示以接近大对象的表示。两种网络的替代优化竞争使Perceptual GAN生成小目标的超分辨大目标表示,从而提高小目标检测性能。通过实验证明了Perceptual GAN在检测小物体方面的优势超过了多数算法。
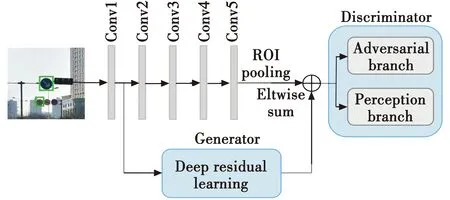
图6 基于感知GAN的目标检测网络Fig.6 Object detection network based on the Perceptual GAN
文献[29]基于GAN 提出了一种多任务结合的小目标检测算法MTGAN,生成器网络将输入的低分辨率图像向上采样到细尺度图像,同时引入了多任务的判别器网络用来对生成器网络输出的超分辨率图像与真实图像进行区分,并预测目标的类别分数与边界框的偏移量。为了使分类和定位更加准确,对分类和回归损失反向传播到生成器中进一步促进生成器网络产生超分辨率图像。由于MTGAN可以使小目标的分辨率大大提高,因此小目标的检测精度在MS COCO数据集上达到25.1%。
3.4 基于上下文信息策略
小目标的尺寸过小导致其可提取的特征信息匮乏,并且极易与图像的背景融为一体,在深度学习提出之前,已有研究证明对上下文建模可以改善目标的检测性能。随着深度学习的应用,一些研究者将目标周围的上下文信息添加到卷积神经网络,取得了较好的成效,因此基于深度学习上下文信息的小目标检测算法被提出。上下文信息是指将目标的特征信息与给定场景下对这些目标施加的上下文约束相结合,进而改善小目标尺寸过小的问题。
局部上下文是指被检测对象周围区域的视觉上下文信息。2017年,文献[30]提出的CoupleNet全卷积网络把RPN区域推荐网络获得的推荐区域送入两个分支,经过位置敏感ROI池化的特征送入局部全卷积网络进行局部信息的提取,经过ROI池化的特征送入全局卷积神经网络,最后将两个分支提取到的信息进行融合对目标进行检测,结构见图7。2018年,GUAN等提出了语义上下文感知网络SCAN,使用金字塔池化的方式将多个不同尺度的全局上下文信息进行融合,并使用了最大池化和平均池化交替使用的策略平衡了检测的准确率和漏检率,增强了小目标的检测性能。

图7 CoupleNet网络架构Fig.7 Architecture of CoupleNet network
全局上下文是指从整个图像或场景级上下文中学习,文献[31]在R-FCN++网络模型中引入了全局上下文模块,使用大且可分离的卷积核提升了分类评分图,小目标检测精度达到25.2%。上下文交互指的是通过视觉元素传递情境信息。LIU等提出了结构推理网络(SIN),SIN将目标检测描述为一个图结构推理问题,通过研究单个图像中的场景上下文信息和对象关系,并利用SIN中的上下文信息提高了小目标的检测性能。文献[32]提出一种轻量物体关系网络(light-weight object relation network),描述了不同物体的外观特征与几何形状之间的相互作用。此外,轻量物体关系网络不需要额外的监督,在小目标检测方面表现出了很大的优势。值得注意的是,以上3种基于上下文的方法都有利于小目标的检测精度。
3.5 基于IOU阈值策略
IOU的定义为待检测目标预测边界框和真实边界框的交并集的比值,作用是衡量物体定位的准确率,大小是可以人为设定的,最常用的数值是0.5。通过提高IOU 的数值来获得更高质量的样本,但有时也会带来一些负面影响,如正负样本比例不均衡、小目标被舍弃等问题。IOU阈值选择得太小会使样本的质量较差,因此,选择合适的IOU阈值可以有效提高小目标检测效果。
实验证明,当设置的IOU阈值变大时,目标检测的网络性能会逐渐变差。当设定为0.5或0.6时,检测精度变化不明显或略有提升,设定为0.7时,网络的检测精度会快速降低。基于此种考虑,文献[33]提出了Cascade R-CNN,其由一系列经过增加IOU阈值训练的检测器组成,增大每个检测器判断正负样本的IOU阈值,使每一个检测器专注于检测IOU在某一范围内的候选框,从而使目标定位准确度越来越高。Cascade R-CNN如图8所示。

图8 Cascade R-CNNFig.8 Cascade R-CNN
图8中,I为输入图像,经过Conv,Pool进行区域特征提取,H1~H3中的IOU阈值分别为0.5,0.6和0.7,最后进行目标分类(C)与边界框(B)的提取,在MS COCO数据集上进行测试,Cascade R-CNN可以使小目标的检测精度达到23.7%。文献[34]提出的FSCascade是标准Cascade R-CNN的一个简单扩展,具有特征共享机制。该结构的优点在于,在低IOU阈值下缩小最后阶段和前面所有阶段之间的差距,并在所有IOU阈值上提高整体性能,只引入可忽略不计的额外参数,进一步提升了小目标检测性能,在MS COCO数据集上检测精度达到25.1%。
3.6 基于多方法融合策略
2021年,文献[35]提出了改进的YOLOx算法,该算法融合了数据增强、尺度融合等多种策略。YOLOx-DarkNet53的基准模型采用的是YOLOv3-SPP,输入端使用Mosaic和Mixup进行改进增强,预测端采用Decoupled Head结构,首先,经过1×1卷积层将特征通道减少到256,使用两个并行分支,每个分支采用2个3×3的卷积层,分别用于分类和回归任务,并在回归分支的基础上增加了IOU分支;其次,通过使用Anchor-free代替原始的anchor机制,将每个位置的预测从3降为1并直接预测网格左上角的两个偏移量和预测框的高与宽,减少了参数量并简化了训练过程,在MS COCO数据集上,小目标检测精度达到27.5%。
除YOLOx-DarkNet53之外,YOLOx系列还有YOLOx-M,YOLOx-L和YOLOx-X等,该系列与YOLOx-DarkNet53采用了同样的特征提取网络和增强方法,不同之处在于使用了缩放规则,通过测试可知,小目标检测精度都有较大的提升,其中YOLOx-X对小目标检测精度达到了31.2%,平均检测精度达到51.2%,检测性能得到很大的提升,并且还较好地保持了一阶段检测算法的检测速度。
3.7 小结
目标检测作为计算机视觉和信号检测领域中一个重要的研究方向,是目标跟踪、图像分割等更深层次的视觉任务的基础部分,并在缺陷检测、航拍图像等诸多领域中发挥着不可或缺的作用。本章主要从6个方面对有关深度学习的小目标检测算法进行了归纳总结,其中,数据增强的策略是提高检测性能的最简单有效的算法,通过增加样本集的大小增强检测模型的稳定性和泛化性,除上文所提到的算法外,常使用的还有CutOut和Hide-and-Seek等;基于多尺度融合、上下文信息、分辨率增强的算法,增强了网络模型对检测目标的特征提取能力,使卷积神经网络可以提取到小目标的更多语义和位置信息,相关算法还有TridentNet和DCGAN等;基于IOU阈值的改进策略主要对网络提取到的候选框进行限制,平衡了模型对小目标的漏检率和误检率;随着各种策略的不断提出,通过实验发现,将各种策略恰当地同时应用于一个网络模型,可以获得更好的检测效果。
基于深度学习的小目标检测算法因检测速度快、适用性高等优点逐渐取代了传统的目标检测算法,经过近几年人们对算法的不断改进,基于深度学习的小目标检测算法的检测性能较以前得到很大改善,成为该领域内首选的算法。为更加详细地阐述基于深度学习的小目标检测算法,对上文列举的小目标检测算法在MS COCO数据集上进行了小目标检测精度(APs)和平均检测精度(AP)的对比分析,如表1所示。由此看出,虽然特征提取主干网络以及使用的增强方法各有差异,但小目标的检测精度都有显著提升;通过平均检测精度的对比可以看出,在改进小目标检测精度的同时也促进了网络对各尺寸目标检测精度的有效改善。
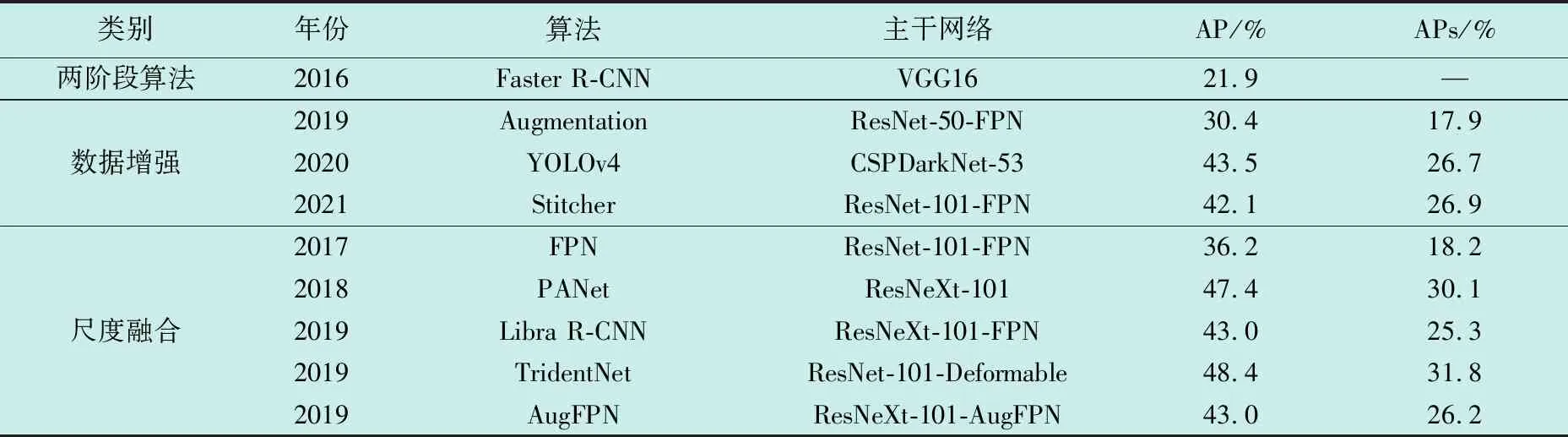
表1 小目标检测算法分析Table 1 Analysis of small target detection algorithms

续表
4 展望与结论
基于深度学习的小目标检测是目标检测领域的重要分支,如何提高小目标检测的精度和效率对其发展具有重要的意义。对比以前,现有的小目标检测技术已经取得了较大的进展,但是相较于大、中等目标还有一定的差距,仍有许多工作要做,本文认为重点应在于以下几个方面。
1) 数据集。针对小目标检测的网络模型已经提出了很多,但由于缺少大规模的数据集,很难去评价检测算法的性能。虽然现有的COCO数据集、VOC数据集包含很多类别的检测对象,但小目标样本的占比仍然不能比拟大、中等目标。此外,现有的小目标检测数据集包含的目标种类过于单一,并不具有普适性,只适用于某种特定类别的检测领域。样本量的不充足、种类单一、样本的不平衡等问题均制约着小目标检测的发展,因此建立更多的大规模、种类较为齐全的小目标数据集对该领域的发展至关重要。
2) 特征融合。特征金字塔的提出使小目标检测上升了一个层次,众多研究者对特征图的多尺度融合方式进行了探究,但不同特征层的语义信息不同,所以存在特征层之间的融合或多或少仍会失去一些语义信息,以及在特征融合期间引入噪声干扰的问题。如何使各个特征层之间不同语义信息充分融合以及消除噪声干扰的问题是提高小目标检测性能的重要研究方向。
3) 多任务学习。多任务学习是一种归纳迁移机制,可以借助辅助任务的信息提高主任务的学习性能,包括提高泛化准确率、学习速度和已学习模型的可理解性。通过使用多任务学习机制,将其他类型的任务(如实例分割)和目标检测联合学习,使用参数共享,使辅助任务提取到的特征用到主任务上,可以大大提升小目标检测的性能。因此,如何借助多任务学习使辅助任务更好地帮助主任务提高检测性能也是未来研究的重点。
4) 引入传统方法。目前大多数目标检测算法是基于深度学习进行研究的,但事实证明,由于小目标尺寸过小,经过卷积神经网络中的池化层后可提取的特征很少,导致小目标的检测性能始终无法达到大、中等目标的精度。因此,在检测过程中可以增加一些传统的特征提取方法对小目标进行特征提取,如上文中所提到的DPM和HOG等,将传统的特征提取算法与深度学习算法相结合,或许可以起到意料之外的效果。
5) 研究新的检测框架。大多数的小目标检测网络是利用在大规模图像分类数据集上的模型权重进行预训练,由于不同的数据集之间具有差异,因此采用训练好的权重并不是最好的办法。目前多数小目标检测算法是基于通用的目标检测算法进行改进,只有小部分进行了新的尝试。因此,专门设计通用的小目标检测框架也不失为一种解决方式。
本文分别从传统的目标检测和基于深度学习的目标检测阐述了该领域的主流算法,通过阐述小目标样本的定义以及分析当前小目标检测所遇到的问题,分别从数据增强、多尺度学习、上下文语义、提高分辨率以及IOU阈值等多个方面分析了现有的研究工作,最后提出了对小目标检测领域未来发展方向的展望,通过本文的分析为今后小目标检测技术的研究工作提供一定的启发和帮助。
