基于深度残差收缩注意力网络的雷达信号识别方法
2023-03-09曹鹏宇杨承志陈泽盛石礼盟
曹鹏宇, 杨承志, 陈泽盛, 王 露, 石礼盟
(1. 空军航空大学航空作战勤务学院, 吉林 长春 130022; 2. 空军航空大学航空基础学院, 吉林 长春 130022; 3. 中国人民解放军93671部队, 河南 南阳 474350)
0 引 言
随着电磁环境日益复杂,雷达侦察感知敌方态势的能力也愈发凸显[1-2]。传统基于脉冲描述字的分选识别方法难以适应现代军事的发展,脉内数据包含的特征更为丰富,因此,以脉内数据作为研究对象是现如今雷达侦察领域研究的重点之一[3-7]。
深度学习由数据驱动,不需要人工设计特征,具备强大的特征学习能力[8-13]。不少专家将其应用于雷达侦察领域,并取得了极大的成功。文献[14]针对低信噪比条件下特征提取困难的问题,提出一种基于时频分析和扩张残差网络的雷达信号识别方法。文献[15]首先采用稀疏自编码器提取特征进行离线训练,训练好的模型后将特征输入到Softmax分类器进行分类,实现低信噪比条件下雷达信号的分类识别。文献[16]提出了一种基于卷积神经网络和深度Q学习的雷达信号识别方法。在实际战场环境中,往往伴随着大量的噪声或者干扰信息,针对低信噪比环境下的雷达信号分类识别就显得格外重要,也对网络能否提取到鲁棒性好、可区分程度高的特征提出了更高的挑战。并且,以上研究都是在训练集与测试集是闭集的前提下开展的,也就是说,网络模型训练好之后所能识别的信号种类就已固定。当新信号扩充到样本库后,使用这些新信号对模型进行测试时,模型仍会将新信号错误识别成扩充前样本库中的某一种信号,不但不具备扩展性,反而提供错误的识别信息,这就促使研究人员寻找策略来解决这个问题。
经过本课题组的研究,应用于行人重识别、人脸识别等领域的度量学习可以解决上述的问题。文献[17]提出将人脸识别领域的三元组损失函数应用于雷达信号识别,使其具有一定的扩展性,但其网络提取信号特征的能力以及损失函数等方面仍具有很大的提升空间。近年来,借鉴人类接收处理信息的过程发展起来的注意力机制,能够作为一种通用的轻量级模块,可以集成到任何网络中实现端到端的训练。文献[18]将软阈值化与注意力机制相结合,构建深度残差收缩网络用于振动信号故障检测,对噪声具有一定的鲁棒性。文献[19]构建融合前馈扫描和反馈的掩码分支作为侧分支加入到主干中,充当主干分支的特征选择器,增强有用特征,抑制无用特征。文献[20]提出压缩-激励网络(squeeze and excitation networks, SENet)进行图像识别,获得每个特征通道的重要程度,据此对特征进行加权,对网络性能的提升有明显的效果。基于以上研究,本文提出了一种深度残差收缩注意力网络用于雷达信号识别方法,主要工作如下:
(1) 以深度残差网络为基础,构建掩码支路充当主干支路的“特征选择器”,同时为了消除过程中的冗余信息或者噪声,将软阈值化的操作融入其中。注意力机制不仅帮助调整特征的权重,同时也能自适应地为网络选取合适的阈值。除此之外,将主干支路以短连接的方式加入到网络中,既能够发挥出注意力机制的优势,也不会出现因网络特征响应值变弱而导致性能下降的问题。
(2) 将度量学习的排序表损失(ranked list loss, RLL)引入雷达信号识别领域,使得识别方法具有扩展性,并且RLL损失函数在最大程度保留了信号的类内特征的同时,弥补了其他度量损失函数只采用部分样本进行相似性度量的缺陷。
(3) 为了使不同类别信号的“分界面”更加明确,提高信号识别准确率,联合分类损失函数与RLL损失函数共同指导网络训练。
1 相关知识
1.1 深度残差网络
在深度学习中,为提高网络性能,往往通过增加网络层数来提高网络提取特征的能力。然而,当层数过多时,梯度消失、梯度爆炸等问题的出现会导致网络难以训练。He等[21]在卷积层和后面对不上中引入跳跃连接搭建了深度残差网络,能够很好地解决层数过深与性能下降之间的矛盾。因此,残差网络的提出在深度学习领域产生深远的影响,不少专家学者以此为基础进行架构优化。
1.2 注意力机制
深度学习中的注意力机制是通过借鉴人类接收处理信息的过程发展起来的[19]。当人类接收信息时,不会同时处理所有信息,而是有倾向性地处理更感兴趣或者与当前任务关联程度更高的一些信息,滤除不重要或者冗余的特征,能够有效提高信号处理的准确率及速度。同理,在深度学习领域,通过对重要特征进行加权处理,能够获得更高的“注意力”,来近似人类接收处理信息的过程。
1.3 软阈值化
现实生活中,噪声信息或者与标签无关的信息的存在,严重降低了信号识别等工作的准确率。软阈值化,是很多信号去噪算法中的关键步骤。一般需要先将原始信号变换到某个域中,这个域需要满足特征值越接近0代表特征越不重要的要求,之后“收缩”信号特征。“收缩”信号特征的具体操作是先设置一个阈值,之后比较特征的绝对值与阈值的大小,低于阈值则将特征值设为0,高于阈值则向0方向调整[18]。具体公式如下所示:

(1)
式中:x为信号特征;T为阈值;soft(x,T)为软阈值化输出的结果。
另外,阈值的设立需要满足以下3个条件:① 必须为正值;② 设置需合理,阈值过大会导致有用特征被滤除掉,过小则难以消除噪声特征;③ 每个样本所含噪声分量不同,需要分别设置不同的阈值。在经典的信号去噪算法中,阈值需要人工提前设置,要求具备信号处理领域的专业知识。即便如此,通常也很难找到合适的值, 并且不同场景下的最优阈值一般不同。注意力机制的发展为阈值的设立提供了新的思路。
1.4 度量学习
度量学习是对样本进行相似度度量,在分类、检索、认证等场景中应用广泛。度量学习重点关注样本类间与类内的样本分布,旨在设计一个合理有效的相似度度量方法,在训练过程中拉大不同类别样本之间的距离(降低相似度),减小相同类别下样本的距离(增大相似度),最终使得样本在类内紧密在类间分离。这与分类问题在本质上有所差别,差别示意图如图1所示。
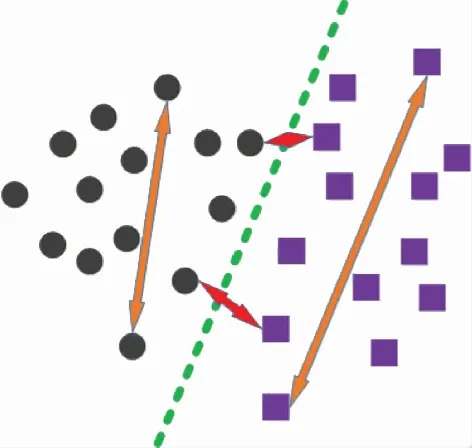
图1 分类问题与度量学习差别示意图Fig.1 Schematic diagram of the difference between classification problem and metric learning
每个图形代表不同的样本,形状不同代表样本的类别不同,图中共有两类不同的样本。度量学习旨在让样本类内相似度(橙色箭头所示)小于样本类间相似度(红色箭头所示)。而分类问题更关注样本的类别信息,旨在找到不同类别之间的分界面(绿色虚线所示)。从图1中也能看出,应用于分类场景下时,单纯采用度量学习对样本的类别间隔关注程度不够。更重要的是,当测试数据的类别在训练的样本库中并未出现时,传统的分类模型会从样本库中选择其中一种作为识别出的种类,此时传统分类模型失效。而度量学习衡量的是样本间的相似度,当测试数据与样本库数据相似度差异较大时,能够判别出测试数据的类别在样本库中没有存档,能够正确识别。
在度量学习中,损失函数的选择决定网络优化的方向,是至关重要的环节。文献[22]提出三元组损失函数并将其应用于人脸识别领域。之后有学者又相继提出改进的三元组、四元组损失函数等。但上述所提损失函数都存在以下两个问题:第一,虽然都提出了通过增加负样本获取更多的信息,但使用的负样本仅是其中一小部分;第二,都追求于将同一类样本集中到一个点上,忽略了样本的类内分布。RLL损失函数对上述损失函数存在的局限性进行了改进。
2 本文方法
2.1 方法概述
本文网络以残差网络为基础,融合注意力机制、软阈值化的思想于其中,搭建了残差收缩注意力模块,以堆叠模块的形式实现特征提取。这些模块产生注意力感知特征。来自不同模块的注意力感知特征随着层的加深而适应性地改变。最终,将输入信号映射到一个32维的向量空间,得到一个特征向量。本文的识别方法在训练阶段和测试阶段有所差异,在训练阶段,将样本库中信号输入到深度残差收缩注意力网络中进行训练,在分类损失函数和度量学习中的RLL损失函数共同指导下控制网络优化的方向。使得网络模型向着同种信号相似度增大异种信号相似度减小的方向调参。训练完成后在测试阶段,将样本库信号和待识别信号同时输入到网络得到各自的特征向量,通过对样本库信号与待识别信号的特征向量采用基于阈值的判断算法进行相似度识别,低于阈值的认为是原样本库中的已知信号,并输出其信号标签,高于阈值的则被认为是样本库中不存在的未知信号。
2.2 网络结构
深度残差收缩注意力网络由模块堆叠而成,每个模块主要由主干支路和掩码支路两部分组成。网络总体网络及模块2中掩码分支的结构如图2所示。
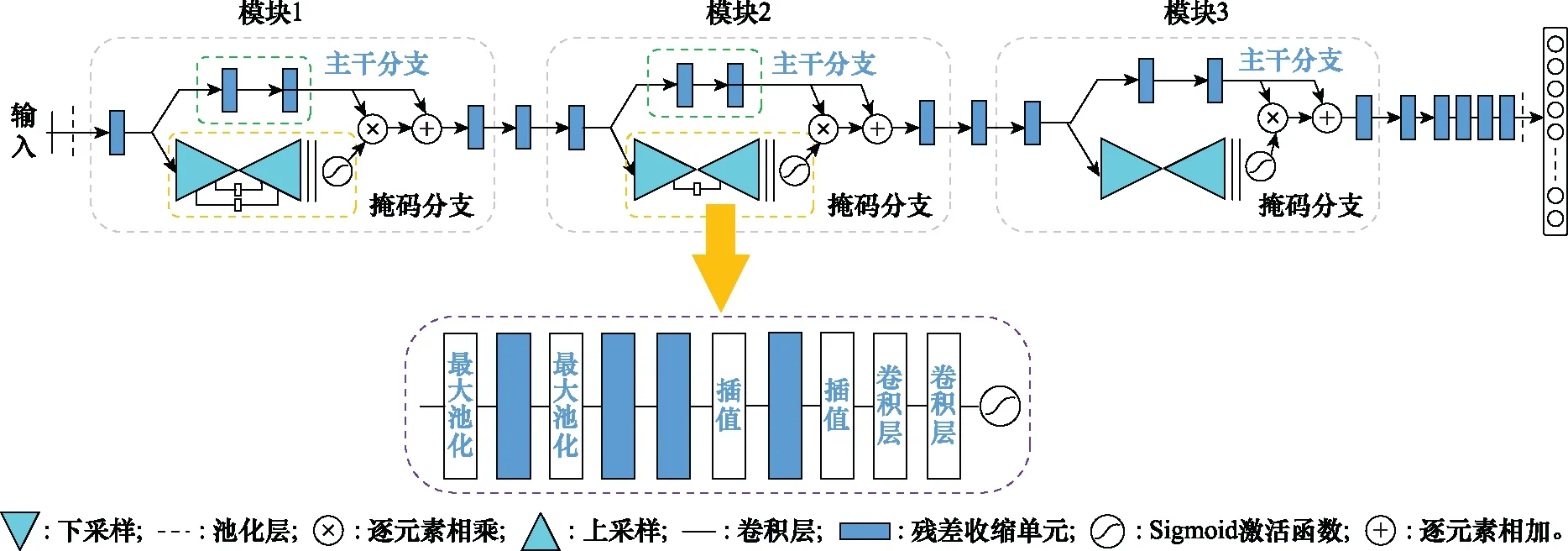
图2 深度残差收缩注意力网络结构Fig.2 Deep residual shrinkage attention network structure
2.2.1 残差收缩单元
在实际战场环境下,噪声或者冗余信息大量存在,为了消除这些信息,构建残差收缩单元,融合恒等映射、软阈值化和注意力机制的思想于其中。首先,利用注意力机制的思想搭建了一个子网络自适应地找到阈值,之后进行软阈值化的操作。网络结构如图3所示。
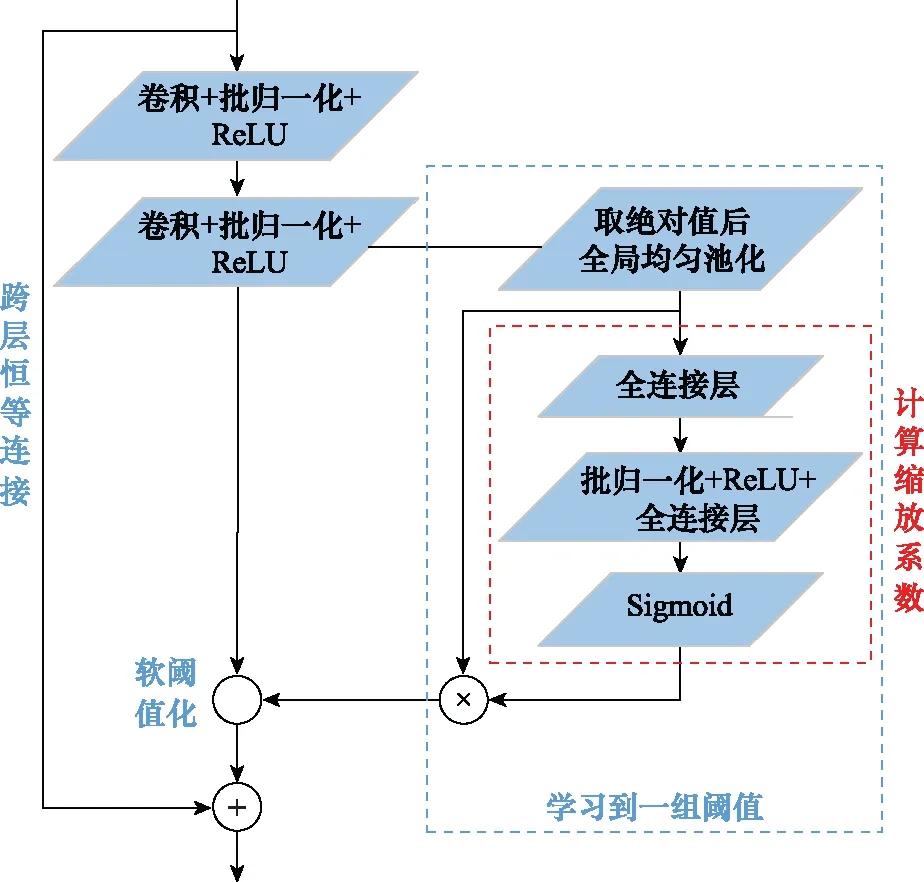
图3 残差收缩单元结构Fig.3 Residual shrinkage unit structure
由图3可知,与残差单元相比,残差收缩单元增加了选取阈值的子网络和进行软阈值化的操作。两个卷积单元提取特征后,通过一个子网络自动选择合适的阈值。具体来说,子网络首先获得特征图绝对值的平均值,之后获得一个缩放系数,二者相乘的结果就是子网络选择出来的阈值,之后进行软阈值化的操作。取绝对值的操作保证找到的阈值为正数,缩放系数的获取保证值不会太大,同时每个阈值都是依据自己的特征图所得到的。这种获得阈值的方式既保证了阈值的唯一性和适用性,也满足阈值设立的3个条件。
2.2.2 主干支路和掩码支路
主干支路以残差收缩单元作为基本单元,实现对特征的提取和对过程中的噪声分量进行抑制。掩码支路采用聚焦式注意力与显著性注意力相结合的方式,包括了自下而上的前馈扫描和自上而下的反馈操作。前馈扫描用于快速收集输入信号的全局信息,反馈操作用于将原始特征图与全局信息相结合。同时,在前馈扫描和反馈操作中添加了跳跃连接,来捕获不同阶段不同比例的信息。在掩码支路中,首先通过残差收缩单元减少过程中的噪声,之后通过两个最大池化层操作快速增大感受野,获得全局信息。达到最低分辨率以后,通过对称的残差收缩单元和双线性插值操作将特征放大回去。其中,双线性插值的数量与最大池化层的数量一致,本文是两个,以确保此时输出与掩码支路输入大小一致。之后,通过两个1×1的卷积层之后,使用Sigmoid层将输出进行归一化,作为主干支路的权重值。
假设输入为x,主干支路输出结果记为Ti,c(x)。掩码支路输出结果为Mi,c(x),形状与Ti,c(x)相同。将掩码分支输出的结果Mi,c(x)作为主干支路输出特征图的权重,点乘后输出Hi,c=Mi,c(x)*Ti,c(x)。如果直接将这个结果作为输出,会导致网络性能明显下降。原因是主干支路的权重经过了归一化,点乘后直接输出会导致网络整体的特征响应值变弱。
因此,将主干支路作为短连接加入,输出变为Hi,c=(1+Mi,c(x))*Ti,c(x)。这样,既能保留了原有的特征提取的优势,经过多层传输之后,感兴趣的信号特征被增强,不重要的特征相对来说占比减少,又解决了输出特征值整体下降的问题。此外,也给了主干网络绕过掩码支路直接前进到顶层的能力,削弱了掩码支路特征选择的能力。同时,还具有优异的梯度回传特性。
2.3 损失函数
2.3.1 RLL
给定一个锚点,对样本空间剩余的所有样本进行相似度排序后得到一个列表。理想状态下,所有的正样本都应在所有的负样本之前。RLL优化的目标不仅要满足这个条件,在正负样本之间还至少要存在一个距离余量m,同时为了避免像其他损失函数一样将锚点与正样本无限接近,严重破坏样本类内的样本分布,RLL将锚点与正样本约束在样本空间的一个超球面内,能够最大程度保留了样本的类内特征。具体来说,RLL优化的最终结果是:以锚点(待查询样本)为圆心,所有的正样本分布在小于α-m的超球面内,所有的负样本分布在大于α的超球面之外。优化目标如图4所示。
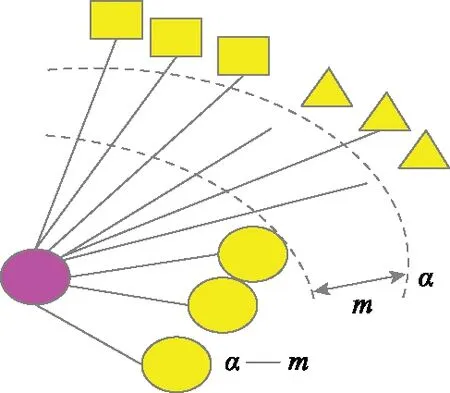
图4 RLL优化结果示意图Fig.4 Schematic diagram of RLL optimization results

以成对余量损失作为基本成对约束来构建基于集合的相似性结构,表达式如下所示:
Lm(xi,xj;f)=(1-yij)[α-dij]++yij[dij-(α-m)]+
(2)
式中:α为设置的距离参数。若yi=yj,则yij=1;否则yij=0。dij=‖f(xi)-f(xj)‖2表示两样本在特征空间的欧式距离差。
在度量学习损失函数中,选取到合适的样本能够加快模型的收敛速度和提高模型性能。分析优化目标,确定采样策略是选取损失函数不为0的样本。正样本的损失函数表达式如下所示:
(3)
由于选取的负样本一般数量较大,并且损失值幅度变化区间也很大,为了提高利用效率,对负样本采取加权的策略。加权的权重取决于样本距离锚点的距离。表达式如下所示:
(4)
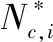
因此,负样本的损失函数如下所示:
(5)
整体的损失函数如下所示:
(6)
2.3.2 分类损失函数
分类损失函数采用基于Softmax的交叉熵损失函数来训练。交叉熵损失函数是衡量实际概率与期望概率之间的距离,损失函数值越小表示预测与期望越接近。表达式为
(7)
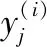
2.3.3 联合损失函数
在训练过程中通过分类损失函数与RLL损失函数共同指导训练来提高模型识别的准确率。

(8)
式中:w表示分类损失函数的权重,经测试w=0.25时效果最好。
2.4 识别方法
训练阶段具体流程如下。
步骤 1样本库构建:在训练样本中从每种雷达信号中挑选数量为n=32的样本组成雷达信号样本库,并找到对应的标签。
步骤 2样本库信号预处理:样本库信号输入网络前进行最值归一化预处理。
步骤 3获取训练前信号特征向量:将样本库信号输入到深度残差收缩注意力网络中,获取训练前的32维空间特征向量。
步骤 4网络训练:在训练过程中,首先将标签转为独热码的形式,之后进行平滑处理,提高模型的泛化能力。联合RLL损失函数和分类损失函数共同优化网络训练的方向,使得同类信号特征向量距离减小,不同类信号特征向量距离增大。待训练完成后保存模型。
测试阶段具体流程如下。
步骤 1待识别信号预处理:将待识别信号进行预处理,一维信号长度统一设置为1 024。
步骤 2提取保存好的模型,将预处理后的信号输入到此模型中,获得特征向量fx。
步骤 3将样本库信号输入到训练好的模型中,获取训练优化后的32维特征向量fs。
步骤 4相似度衡量:计算fx与fs之间N个向量的距离,并将其存放到相似度数组中。
步骤 5计算识别数组:在相似度数组中找到最小的3个值,从样本库中找到对应的标签后存放到识别数组。
步骤 6与阈值比较大小:计算相似度数组的均值后将其与设定好的阈值进行比较,若均值大于阈值,则判定其为样本库中不存在的信号,执行步骤7。反之,执行步骤8。
步骤 7将待识别信号的判别为未知信号,将其类别设置为-1(代表样本库中并未存储过此信号类型),并存入未知雷达信号库。
步骤 8当均值小于阈值,以识别数组出现次数最多的标签作为待识别信号的识别结果。
3 实验与分析
3.1 数据集与实验设置
使用Matlab生成数据,采样频率为600 MHz,脉宽为2 μs,信噪比为-20~10 dB,每隔2 dB产生1 000个样本,其余参数设置如表1所示。调制方式有连续波(continuous wave, CW)、线性调频(linear frequency modulation,LFM)、二进制相移键控(binary phase shift keying,BPSK)、正支相移键控(quadrature phase shift keying,QPSK)。生成已知雷达信号数据以后,每个样本信号长度设置为1 024(过长的信号进行截断处理,过短的信号在末尾补零),之后对应标签组成数据集,以8∶2的比例分为训练集和测试集。
由于本识别方法除测试对已知雷达信号识别的准确率以外,也需要测试当出现样本库中不存在的信号类型时模型能否识别出其为未知信号。因此,需要生成原数据集中不存在的新信号作为未知雷达信号,同测试集一同对网络性能进行测试。为了与样本库中的已知信号区分开,未知信号的标签统一设置为-1,未知雷达下信号数据其余参数设置如表2所示。
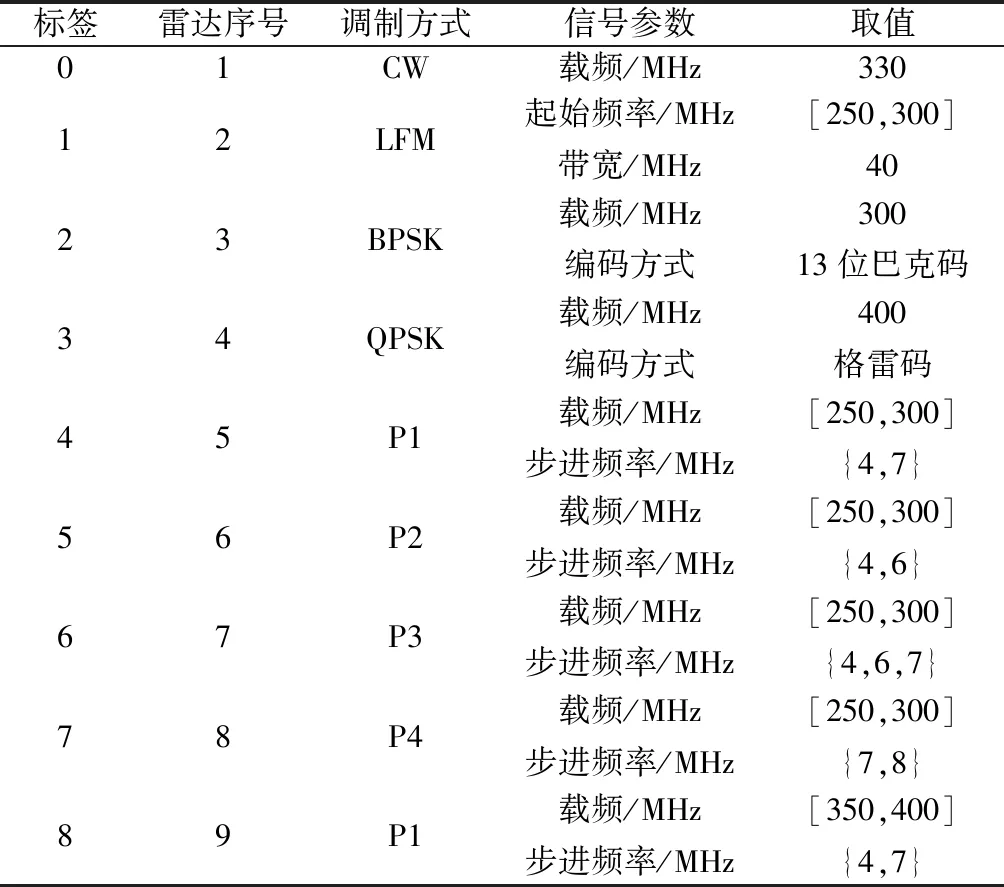
表1 已知雷达信号参数设置
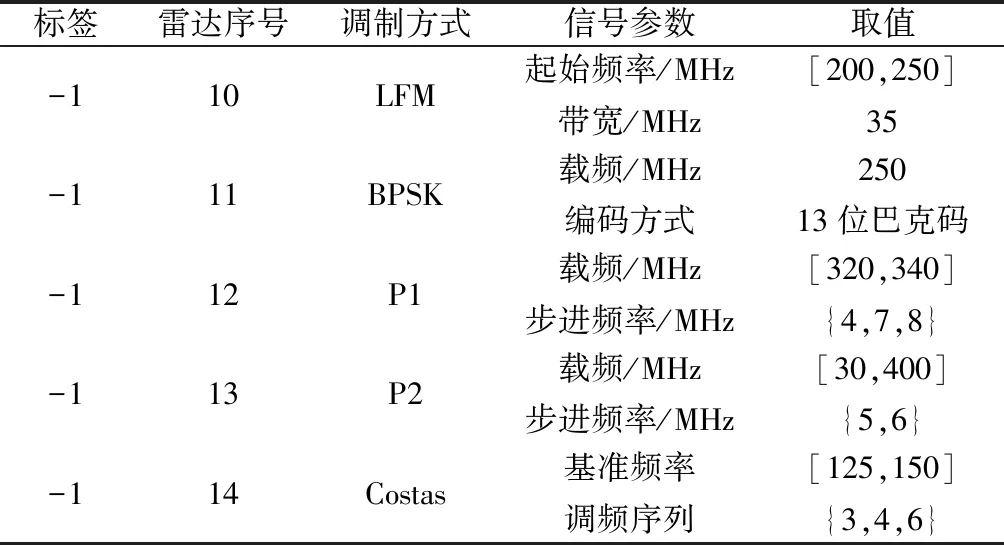
表2 未知雷达信号参数设置
仿真配置如下:CPU为Inter(R)Core(TM) i7-10750H,GPU为NVIDIA GeForce RTX 2060;内存为32G;深度学习框架为tensorflow2.1.0。训练初始设置为:epochs为1 000,batchsize为64。选用RMSProp优化器,衰减为0.9,动量为0.9;批量规范动量参数为0.99;初始学习率设置为0.256,每10个epoch下降0.97倍。
3.2 测试阈值参数设置对识别方法的影响
本文采用基于阈值的判断方法来判断待识别信号是否存在于样本库中。本节旨在选出合适的阈值参数δ。由于需要同时测试网络模型对已知雷达信号和未知雷达信号识别的能力,因此本节使用已知雷达信号测试集和未知雷达信号数据共同进行测试,并且,本节识别的准确率称为综合准确率P,由已知雷达(标签非负)的准确率Pkno和未知雷达(标签为-1)的准确率Punk两部分组成,具体计算如下:
P=0.5·Pkno+0.5·Punk
(9)
δ范围为0.005~0.05,步进0.005。信噪比为0 dB时,不同阈值下准确率对比如图5所示。
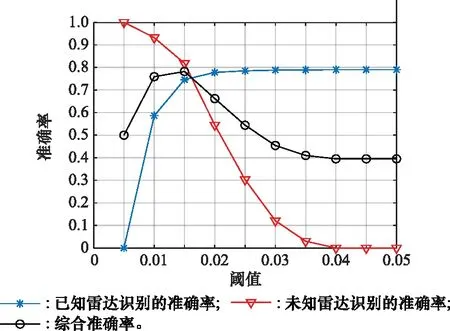
图5 不同阈值设置下准确率对比Fig.5 Comparison of accuracy rates under different threshold settings
由图5可知,当δ值较小时,Punk较高,Pkno较低,并且随着δ值逐渐增大,Punk有明显的下降趋势,Pkno有明显的上升趋势。原因在于当δ较小时,相似度数组的均值一般都高于阈值δ,模型会将其直接归为不属于样本库的未知雷达信号,同理,当δ较大时,相似度数组的均值一般都低于阈值δ,模型会将其认为是属于样本库的已知雷达信号。本文将Pkno和Punk视为同等重要,在此基础上分析综合准确率P,δ=0.015最为合适,因此基于阈值的识别方法中阈值设置为0.015。需要说明的是,在不同的场景下,需要重新讨论阈值设置的最优解。
3.3 消融实验
消融实验是为了研究各部分对性能的影响,因此本节进行的实验都是使用训练集数据进行训练,稳定后保存模型,统一以识别准确率作为评价指标对网络特征提取能力进行对比分析,使用已知雷达信号测试数据进行网络性能的测试。
实验 1为了测试软阈值化、掩码分支的加入对网络识别率的影响,统一采用分类损失函数。将本文网络去除掩码分支,并把残差收缩单元全部替换为残差单元之后的网络作为基础网络记为网络1,基础网络添加掩码分支后记为网络2,将基础网络中的残差单元替换为残差收缩单元后记为网络3,本文网络记为网络4。不同信噪比条件下识别准确率如图6所示。由图6可知,与网络1相比,其他网络在性能上都有明显提高。具体来说,与网络1相比,网络2在-20~-10 dB范围内准确率提高约13.9%,说明掩码支路的添加调整了主干支路的权重,使得网络能够更关注与任务相关的特征信息,在低信噪比条件下能提取到有用的信息。网络3在-20~-8 dB准确率也提高了近10.3%。由于残差收缩单元构建了一个子网络自适应地寻找到合适的阈值进行软阈值化,减少了与任务无关的特征分量。网络4既添加了掩码分支又采用了残差收缩单元进行软阈值化的操作,整体性能最佳,在-20~-10 dB范围内准确率提高约16.8%。并且,本文网络在-4 dB时准确率就已经达到了99.9%以上。

图6 不同网络的准确率对比Fig.6 Accuracy comparison of different networks
实验 2为了分析损失函数对网络性能的影响,以深度残差收缩注意力网络为基础,使用分类损失函数的网络记为分类网络,采用RLL损失函数的网络记为度量网络,使用联合损失函数的网络记为联合网络。不同信噪比条件下识别准确率如图7所示。
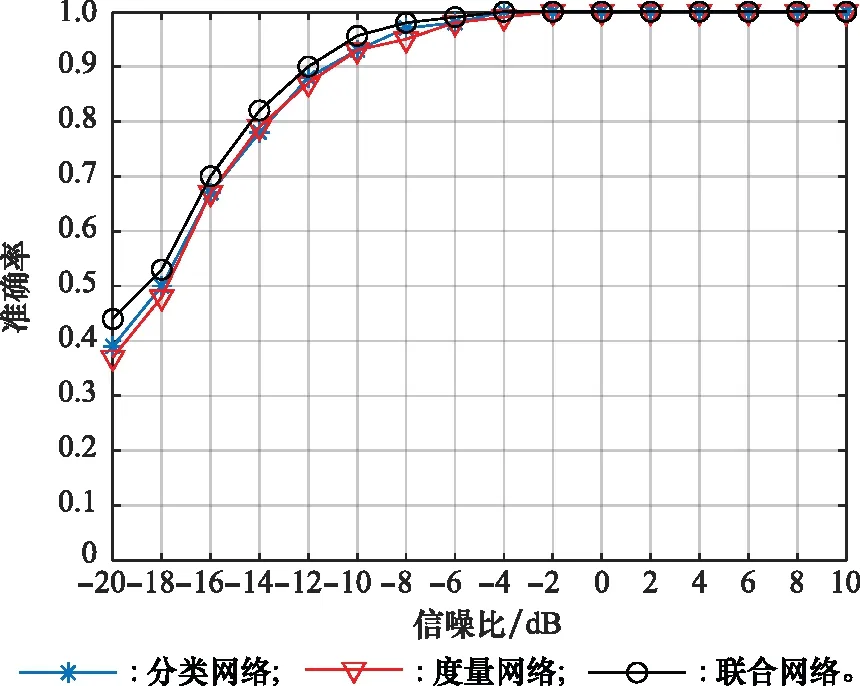
图7 3种网络的准确率对比Fig.7 Accuracy comparison of the three networks
由图7可知,高于-8 dB分类网络和度量网络性能相近,都在98%以上。而低于-6 dB时分类网络的识别准确率总体略高于度量网络,准确率平均提升幅度约1%。这是由于分类网络更关注数据中的类别信息,而度量网络着眼的是数据的相似度衡量,对数据中的分界面关注度不如分类网络,因此在分类任务中度量网络的识别准确率略低于分类网络。联合网络中分类损失函数与RLL损失函数共同指导网络训练,在-20~-12 dB信噪比范围内识别准确率较分类网络和度量网络的平均提升幅度在5%左右。说明共同指导能够提高网络的性能。
3.4 与其他分类网络对比
本节测试本文方法与其他网络在准确率和扩展性上的差异。选取文献[14]、文献[15]和文献[16]与本文方法进行对比分析。
3.4.1 准确率测试
使用已知雷达型号测试集数据进行准确率的测试,在不同信噪比环境下各个模型的识别准确率如图8所示。
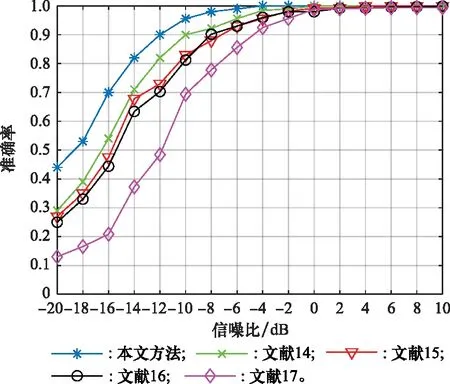
图8 使用已知雷达型号测试数据的准确率对比Fig.8 Accuracy comparison of test set data using known radar models
由图8可知,文献[17]整体性能最差,原因是文献[17]重点关注识别方法的扩展性,搭建的网络较为简单,网络层数较少,特征提取能力比较弱。其余网络相较于文献[17]准确率都有明显提高,在-20~-8 dB准确率都提高了近13%。文献[15]和文献[16]在-20~-10 dB低信噪比条件下识别能力相近,文献[14]在二者的基础上又提高了约5.9%,本文方法识别能力最强,-20~-8 dB信噪比条件下较文献[14]的准备率提高了近6.2%。并且,本文识别方法在-6 dB时准确率就已经达到了99%以上,体现出本文具备很强的特征提取能力。
3.4.2 扩展性测试
使用未知雷达信号数据测试各识别方法的扩展性,从每种雷达信号数据中选取32个样本扩充雷达信号样本库,在样本库中新添加雷达信号的标签对应情况如下所示:雷达10对应样本库标签9,雷达11对应样本库标签10,雷达12对对应一样本库标签11,雷达13对应样本库标签12,雷达14对应样本库标签13。
之后,选取1~5种未知雷达信号对模型进行测试。当信噪比为0 dB时,模型识别准确率与加入新信号的种类数之间的关系如图9所示。其中,当选取雷达10和雷达12的信号进行测试时,五种模型的部分混淆矩阵如图10所示。从图9和图10看出,文献[14]、文献[15]和文献[16]这3种传统的分类网络对新加入到样本库的信号完全没有识别能力,识别的准确率一直为0。由于之前没有训练过这两种新信号,并且受输出层神经元个数固定的限制,会将未知信号误判为原来样本库中存在的信号,表明分类网络不具备识别新信号的能力。而文献[17]与本文方法通过相似度对信号进行衡量,即便之前的训练中从未“见过”新信号,也具备将新信号与样本库原始信号区分的能力。虽然文献[17]与本文方法都具备对新加入到样本库中信号的识别能力,但能够看出本文的识别能力明显优于文献[17],原因在于本文使用的网络对特征的提取能力更强,联合损失函数共同指导下对信号特征向量调整的能力更强,更能满足任务需求。
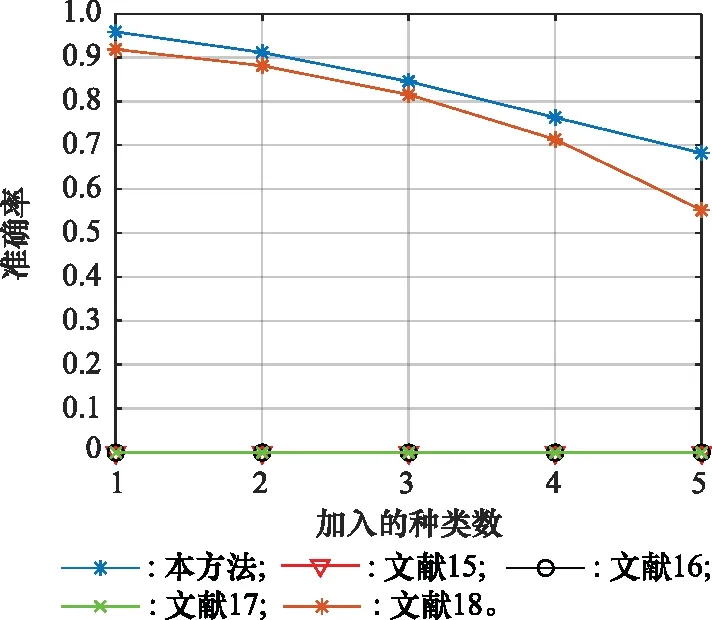
图9 模型准确率随种类数增加的变化情况Fig.9 Model accuracy with the increase of the number of species changes
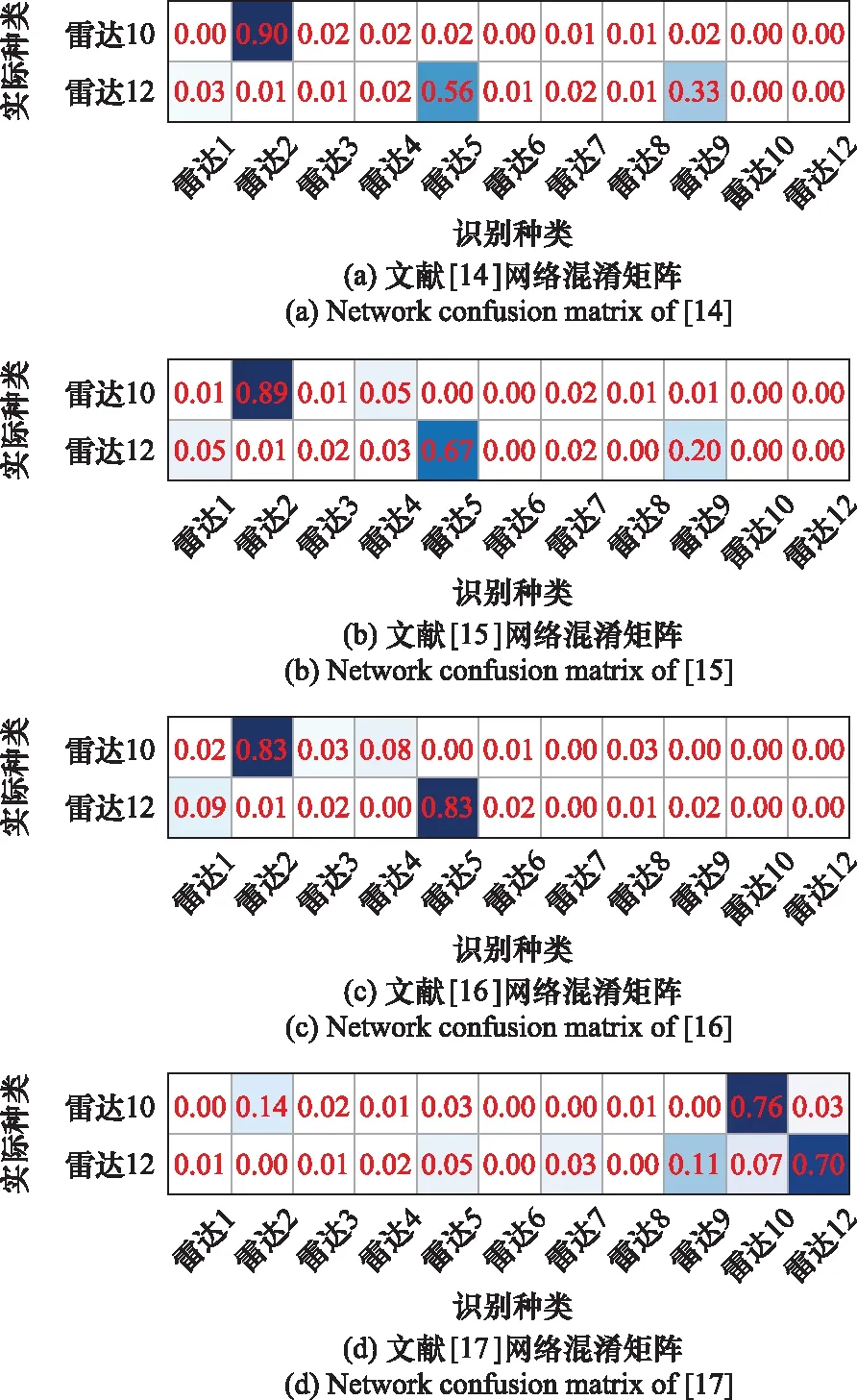

图10 不同模型的混淆矩阵Fig.10 Confusion matrix of different models
4 结 论
本文提出了一种基于深度残差收缩注意力网络的雷达信号识别方法。实验表明,识别方法具备优异的准确率的同时,可识别雷达信号的数量不受模型输出神经元个数的限制,具备分类网络不具备的扩展性。不过,当待识别雷达信号在样本库中并未记录时,本文的识别方法识别出其不属于样本库的未知信号,将其标签设置为-1并存放于未知雷达库后,需要人工从未知雷达库提取出可信样本扩充到雷达信号样本库中,重新分配标签。当网络模型下次再遇到这种型号雷达时,就可以按照已知信号的识别方法进行识别。
